 Source
SourceBonjour, Habr! Je m'appelle Maxim Pchelin et je dirige le développement de BI-DWH chez MyGames (division des jeux du groupe Mail.ru). Dans cet article, je vais vous expliquer comment et pourquoi nous avons créé un stockage DataLake orienté client.
L'article se compose de trois parties. Je vais d'abord expliquer pourquoi nous avons décidé d'implémenter DataLake. Dans la deuxième partie, je décrirai quelles technologies et solutions nous utilisons pour que le stockage puisse fonctionner et être rempli de données. Et dans la troisième partie, je décrirai ce que nous faisons pour améliorer la qualité de nos services.
Ce qui nous a amenés à DataLake
Chez MyGames, nous travaillons dans le département BI-DWH et proposons des services de deux catégories: un référentiel pour les analystes de données et des services de reporting réguliers pour les utilisateurs professionnels (managers, marketeurs, développeurs de jeux, etc.).
Pourquoi un tel stockage non standard?
En règle générale, BI-DWH n'implique pas l'implémentation du stockage DataLake; cela ne peut pas être appelé une solution typique. Et comment alors ces services sont-ils construits?
Habituellement, une entreprise a un projet - dans notre cas, c'est un jeu. Le projet dispose d'un système de journalisation qui écrit le plus souvent des données dans la base de données. En plus de cette base, des vitrines sont créées pour les agrégats, les métriques et d'autres entités pour de futures analyses. Les rapports réguliers sont construits sur la base de vitrines utilisant n'importe quel outil de BI approprié, ainsi que des systèmes d'analyse ad hoc, commençant par des requêtes SQL simples et des tableaux Excel, et se terminant par le Jupyter Notebook pour DS et ML. L'ensemble du système est pris en charge par une équipe de développement.
Supposons qu'une autre entreprise naisse dans une entreprise. Avoir une autre équipe de développement et une infrastructure sous elle est attrayant, mais coûteux. Ainsi, le projet doit être «branché». Cela peut être fait de différentes manières: au niveau de la base de données, au niveau de la vitrine ou au moins au niveau de l'affichage - le problème est résolu.
Et si l'entreprise a un troisième projet? Le «partage» peut déjà mal se terminer: il peut y avoir des problèmes d'allocation des ressources ou des droits d'accès. Par exemple, l'un des projets est réalisé par une équipe externe qui n'a pas besoin de connaître les deux premiers projets. La situation devient plus risquée.
Imaginez maintenant qu'il n'y a pas trois projets, mais bien plus. Et il se trouve que c'est exactement notre cas.
MyGames est l'une des plus grandes divisions du groupe Mail.ru, nous avons 150 projets dans notre portefeuille. De plus, ils sont tous très différents: leur propre développement et achetés pour des opérations en Russie. Ils fonctionnent sur différentes plateformes: PC, Xbox, Playstation, iOS et Android. Ces projets sont développés dans dix bureaux à travers le monde avec des centaines de décideurs.

Pour les entreprises, c'est formidable, mais cela complique la tâche de l'équipe BI-DWH.
Dans nos jeux, de nombreuses actions des joueurs sont enregistrées: quand il est entré dans le jeu, où et comment il a atteint les niveaux, avec qui et avec quel succès il s'est battu, quoi et pour quelle devise il a acheté. Nous devons collecter toutes ces données pour chacun des jeux.
Nous en avons besoin pour que l'entreprise puisse recevoir des réponses à ses questions sur les projets. Que s'est-il passé la semaine dernière après le lancement de l'action? Quelles sont nos prévisions de revenus ou d'utilisation des capacités des serveurs de jeux pour le mois prochain? Que peut-on faire pour influencer ces prévisions?
Il est important que MyGames n'impose pas de paradigme de développement aux projets. Chaque studio de jeux enregistre les données car il les considère plus efficaces. Certains projets génèrent des journaux côté client, d'autres côté serveur. Certains projets utilisent RDBMS pour les collecter, tandis que d'autres utilisent des outils complètement différents: Kafka, Elasticsearch, Hadoop, Tarantool ou Redis. Et nous nous tournons vers ces sources pour les données afin de les télécharger dans le référentiel.
Que voulez-vous de notre BI-DWH?
Tout d'abord, le département BI-DWH souhaite recevoir des données sur tous nos jeux pour résoudre à la fois les tâches opérationnelles quotidiennes et stratégiques. En partant du nombre de vies pour donner un terrible monstre à la fin du niveau, et en terminant par la façon de répartir correctement les ressources au sein de l'entreprise: quels projets devraient donner plus de développeurs ou qui devrait allouer un budget marketing.
La fiabilité est également attendue de nous. Nous travaillons dans une grande entreprise et ne pouvons pas vivre selon le principe "Hier, nous avons travaillé, mais aujourd'hui, le système est en place, et il ne montera que dans une semaine si nous trouvons quelque chose."
Ils veulent des économies de notre part. Nous serions heureux de résoudre tous les problèmes en achetant du fer ou en embauchant des gens. Mais nous sommes une organisation commerciale et nous ne pouvons pas nous le permettre. Nous essayons de faire profiter l'entreprise.
Surtout, ils veulent que nous nous concentrions sur le client. Les clients dans ce cas sont nos consommateurs, nos clients: managers, analystes, etc. Nous devons nous adapter à nos jeux et travailler de manière à ce qu'il soit pratique pour les clients de coopérer avec nous. Par exemple, dans certains cas, lorsque nous achetons des projets sur le marché asiatique pour des opérations, avec le jeu, nous pouvons obtenir des bases avec des noms en chinois. Et la documentation de ces bases en chinois. Nous pourrions chercher un développeur ETL connaissant le chinois ou refuser de télécharger des données sur le jeu, mais à la place, l'équipe et moi nous enfermons dans la salle de réunion, prenons le chronomètre et commençons à jouer. Entrez et sortez du jeu, achetez, tirez, mourez. Et nous regardons ce qui et quand apparaît dans tel ou tel tableau. Ensuite, nous écrivons la documentation et sur sa base, nous construisons ETL.
Dans ce cas, il est important de sentir le bord. Creuser dans la journalisation unique d'un jeu avec une DAU de 50 personnes, lorsque vous devez aider un projet avec une DAU de 500 000 à proximité, est un luxe inadmissible. Donc, bien sûr, nous pouvons consacrer beaucoup d'efforts à la création d'une solution personnalisée, mais uniquement si les entreprises en ont vraiment besoin.
Cependant, dès que les développeurs, en particulier les débutants, apprennent qu'ils devront s'adapter de cette manière, ils ont le désir de ne jamais le faire. Tout développeur veut créer une architecture idéale, ne jamais la changer et écrire des articles à ce sujet sur Habr.
Mais que se passe-t-il si nous arrêtons de nous adapter à nos jeux? Supposons que nous commencions à leur demander d'envoyer des données à une seule API d'entrée? Le résultat sera un - tout le monde commencera à se disperser.
- Certains projets vont commencer à couper leurs solutions BI-DWH, avec préférence et poétesses. Cela entraînera une duplication des ressources et des difficultés dans l'échange de données entre les systèmes.
- D'autres projets ne tireront pas la création de leur BI-DWH, mais ils ne voudront pas non plus s'adapter au nôtre. Et d'autres encore cesseront d'utiliser les données, ce qui est encore pire.
- Eh bien et surtout, la direction ne disposera pas d'informations systématiques à jour sur ce qui se passe dans les projets.
Pourrions-nous implémenter le stockage de manière simple?
150 projets, c'est beaucoup. Mettre en œuvre la solution immédiatement pour tous est trop long. Les entreprises n'attendront pas un an pour que les premiers résultats apparaissent. Par conséquent, nous avons pris 3 projets qui apportent un revenu maximum et mis en œuvre le premier prototype pour eux. Nous voulions en collecter les données clés et créer des tableaux de bord de base avec les mesures les plus populaires - DAU, MAU, revenus, inscriptions, rétention, ainsi qu'un peu d'économie et de prévisions.
Nous ne pouvions pas utiliser les bases de jeu des projets eux-mêmes pour cela. Premièrement, cela rendrait l'analyse croisée plus difficile en raison de la nécessité d'agréger les données de plusieurs bases de données. Deuxièmement, les jeux eux-mêmes fonctionnent au-dessus de ces bases de données, ce qui est important pour que les maîtres et les répliques ne soient pas surchargés. Enfin, tous les jeux suppriment à un moment donné tout l'historique des données dont ils n'ont pas besoin dans leurs bases de données, ce qui est inacceptable pour l'analyse.
Par conséquent, la seule option est de rassembler tout ce dont vous avez besoin pour l'analyse en un seul endroit. À ce stade, n'importe quelle base de données relationnelle ou référentiel de texte brut nous convenait. Nous visions BI et construisions des tableaux de bord. Il existe de nombreuses options pour les combinaisons de ces solutions:

Mais nous avons compris que plus tard, nous devions couvrir tous les 150 autres jeux. Peut-être qu'une base de données relationnelle de cluster peut gérer la quantité de données générées. Mais les sources ne sont pas seulement situées dans des systèmes complètement différents, mais ont également des structures de données très différentes. Nous rencontrons des structures relationnelles, Data Vault et autres. Il ne fonctionnera pas de mettre tout cela dans une seule base de données sans astuces complexes et laborieuses.
Tout cela nous a amenés à comprendre que nous devons construire un DataLake.
Implémentation de DataLake
Tout d'abord, le stockage DataLake est adapté à nos conditions, car il nous permet de stocker des données non structurées. DataLake peut devenir un point d'entrée unique pour toutes les sources diverses, des tables du SGBDR au JSON, que nous expédions depuis Kafka ou Mongo. Par conséquent, DataLake peut devenir la base d'analyses de conception croisée implémentées sur la base d'interfaces pour divers consommateurs: SQL, Python, R, Spark, etc.
Passer à Hadoop
Pour DataLake, nous avons choisi la solution évidente - Hadoop. Plus précisément, son assemblage de Cloudera. Hadoop vous permet de travailler avec des données non structurées et est facilement évolutif en ajoutant des nœuds de données. De plus, ce produit a été bien étudié, donc la réponse à toute question peut être trouvée sur Stackoverflow, et ne pas dépenser de ressources en R&D.
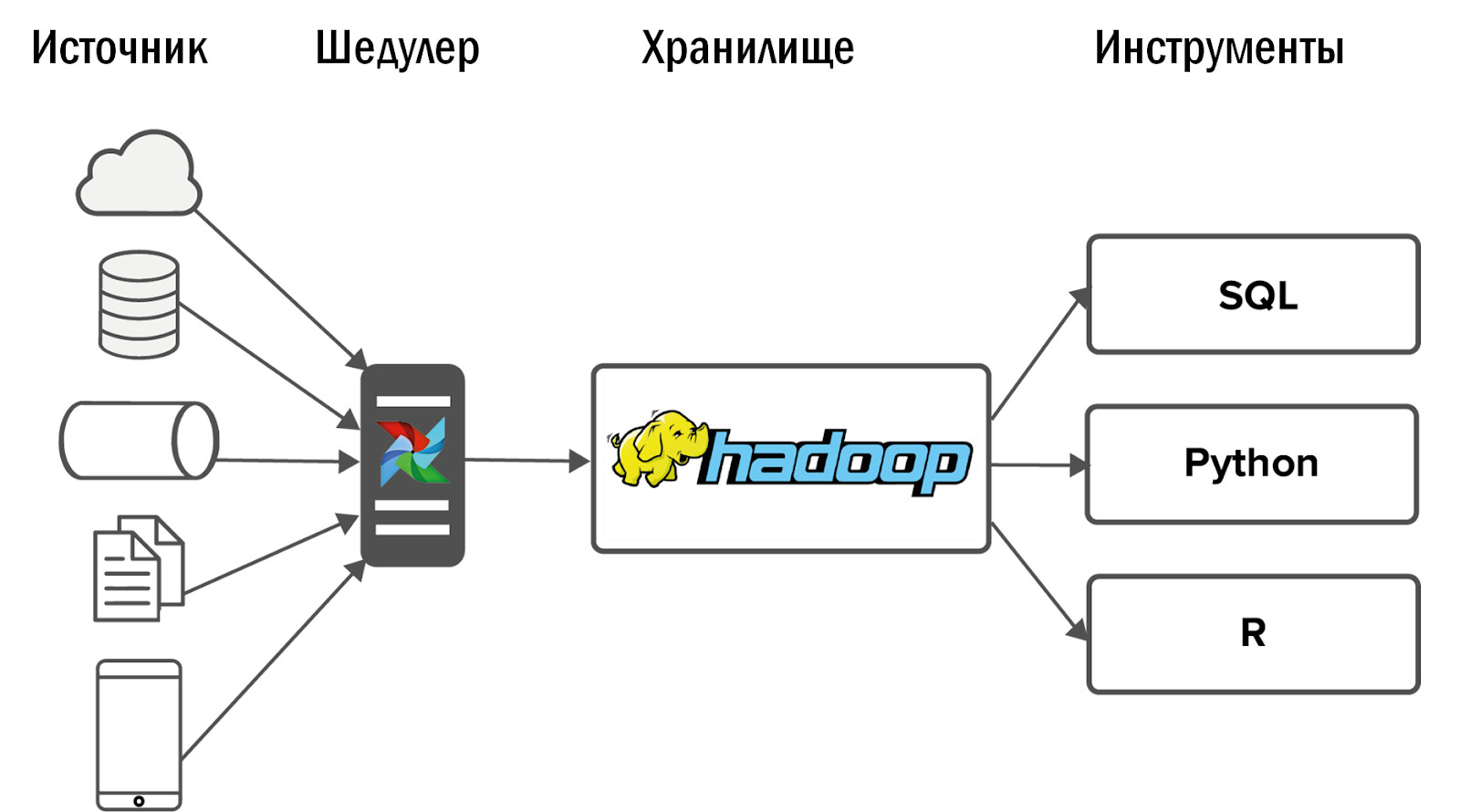
Après avoir implémenté Hadoop, nous avons obtenu le diagramme suivant de notre premier stockage unifié:

Les données ont été collectées dans Hadoop à partir d'un petit nombre de sources, puis plusieurs interfaces y ont été opposées: outils et services de BI pour les analyses ad hoc.
D'autres événements se sont développés de manière inattendue: notre Hadoop a parfaitement démarré et les consommateurs pour lesquels les données ont circulé dans le magasin ont abandonné les anciens systèmes analytiques et ont commencé à utiliser le nouveau produit quotidiennement pour leur travail.
Mais un problème est survenu: plus vous en faites, plus ils attendent de vous. Très rapidement, les projets déjà intégrés à Hadoop ont commencé à demander plus de données. Et ces projets qui n'ont pas encore été ajoutés, ont commencé à le demander. Les exigences de stabilité ont commencé à augmenter fortement.
Dans le même temps, il n'est pas raisonnable d'augmenter simplement l'équipe de manière linéaire. Si deux développeurs DWH font face à deux projets, alors pour quatre projets, nous ne pouvons pas embaucher deux développeurs supplémentaires. Par conséquent, nous sommes d'abord allés dans l'autre sens.
Etablissement de processus
Avec des ressources limitées, la solution la moins chère est de régler les processus. De plus, dans une grande entreprise, il est impossible de proposer une architecture de stockage et de la mettre en œuvre. Je dois négocier avec un grand nombre de personnes.
- Tout d'abord, avec des représentants commerciaux qui allouent des ressources pour l'analyse. Vous devrez prouver que vous ne devez mettre en œuvre que les tâches de vos clients qui bénéficieront à l'entreprise.
- Vous devez également négocier avec les analystes afin qu'ils vous donnent quelque chose en échange des services que vous leur fournissez - analyse du système, analyse commerciale, tests. Par exemple, nous avons donné l'analyse des systèmes de nos sources de données aux analystes. Bien sûr, ils ne sont pas contents, mais sinon, il n'y aura simplement personne pour le faire.
- Enfin et surtout, vous devez négocier avec les développeurs de jeux: installez des SLA et convenez d'une structure de données. Si les champs disparaissent, apparaissent et sont renommés en permanence, quelle que soit la taille de l'équipe, vos mains vous manqueront toujours.
- Vous devez également négocier avec votre propre équipe: rechercher un compromis entre des solutions idéales que tous les développeurs veulent créer et des solutions standard qui ne sont pas si intéressantes, mais qui peuvent être rivetées à moindre coût et rapidement.
- Il faudra convenir avec les administrateurs de la surveillance de l'infrastructure. Bien que, dès que vous disposez de ressources supplémentaires, il est préférable d'engager votre propre spécialiste DevOps dans l'équipe de stockage.
À ce stade, je pourrais terminer l'article si une telle variante du référentiel répondait à tous les objectifs fixés. Mais ce n'est pas le cas. Pourquoi?
Avant Hadoop, nous pouvions fournir des données et des statistiques pour cinq projets. Avec l'implémentation de Hadoop et sans augmentation de l'équipe, nous avons pu couvrir 10 projets. Après avoir établi les processus, notre équipe a déjà servi 15 projets. C'est cool, mais nous avons 150 projets, nous avions besoin de quelque chose de nouveau.
Implémentation du flux d'air
Initialement, nous avons collecté des données à partir de sources utilisant Cron. Deux projets, c'est normal. 10 - ça fait mal, mais ok. Cependant, environ 12 000 processus sont désormais chargés quotidiennement pour le chargement de 150 projets dans DataLake. Cron n'est plus adapté. Pour ce faire, nous avons besoin d'un outil puissant pour gérer les flux de téléchargement de données.
Nous avons choisi le gestionnaire de tâches open source Airflow. Il est né dans les entrailles d'Airbnb, après quoi il a été transféré à Apache. Il s'agit d'un outil pour ETL piloté par code. Autrement dit, vous écrivez un script en Python, et il est converti en DAG (graphe acyclique dirigé). Les DAG sont parfaits pour maintenir les dépendances entre les tâches - vous ne pouvez pas créer une vitrine à l'aide de données qui n'ont pas encore été chargées.
Airflow a un excellent gestionnaire d'erreurs. Si un processus plante ou s'il y a un problème avec le réseau, le répartiteur redémarre le processus le nombre de fois que vous spécifiez. S'il y a beaucoup d'échecs, par exemple, la table dans la source a changé, alors un message de notification arrive.
Airflow a une excellente interface utilisateur: il affiche facilement quels processus sont en cours d'exécution, lesquels se sont terminés avec succès ou avec une erreur. Si les tâches sont tombées avec des erreurs, vous pouvez les redémarrer à partir de l'interface et contrôler le processus via la surveillance sans entrer dans le code.
Airflow est personnalisable, il est construit au-dessus des opérateurs - ce sont des plugins pour travailler avec des sources spécifiques. Certains opérateurs sortent des sentiers battus, beaucoup ont écrit la communauté Airflow. Si vous le souhaitez, vous pouvez créer votre propre opérateur, l'interface pour cela est très simple.
Comment utilisons-nous le flux d'air?
Par exemple, nous devons charger une table de PostgreSQL dans Hadoop. La tâche
sql_sensor_battle_log vérifie si la source a les données dont nous avons besoin pour hier. Si tel est le cas, la tâche
load_stg_data_from_battle_log les données de la PG et les ajoute à Hadoop. Enfin,
load_oda_data_from_battle_log effectue le traitement initial: par exemple, la conversion du temps Unix en temps lisible par l'homme.
Dans une telle chaîne de tâches, les données sont extraites d'une entité dans une source:

Et donc - de toutes les entités dont nous avons besoin d'une seule source:
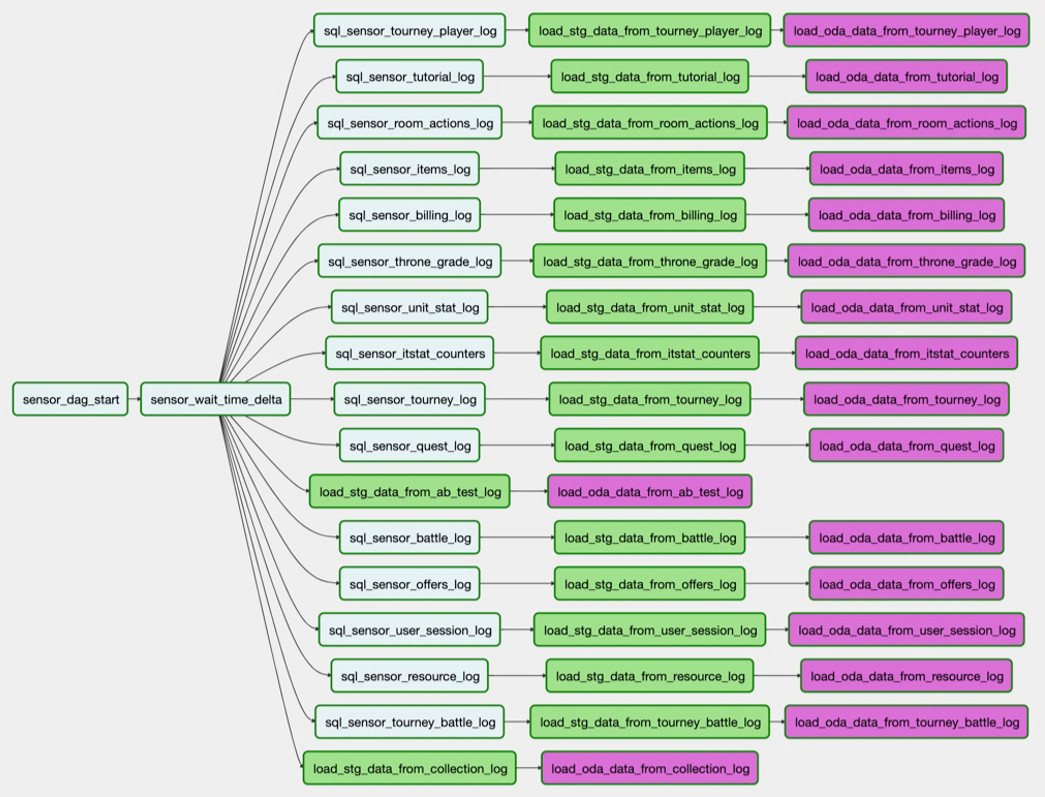
Cet ensemble de téléchargements est le DAG. Et à l'heure actuelle, nous avons 250 de ces DAG pour le chargement de données brutes, le traitement, la transformation et la création de vitrines sur celui-ci.
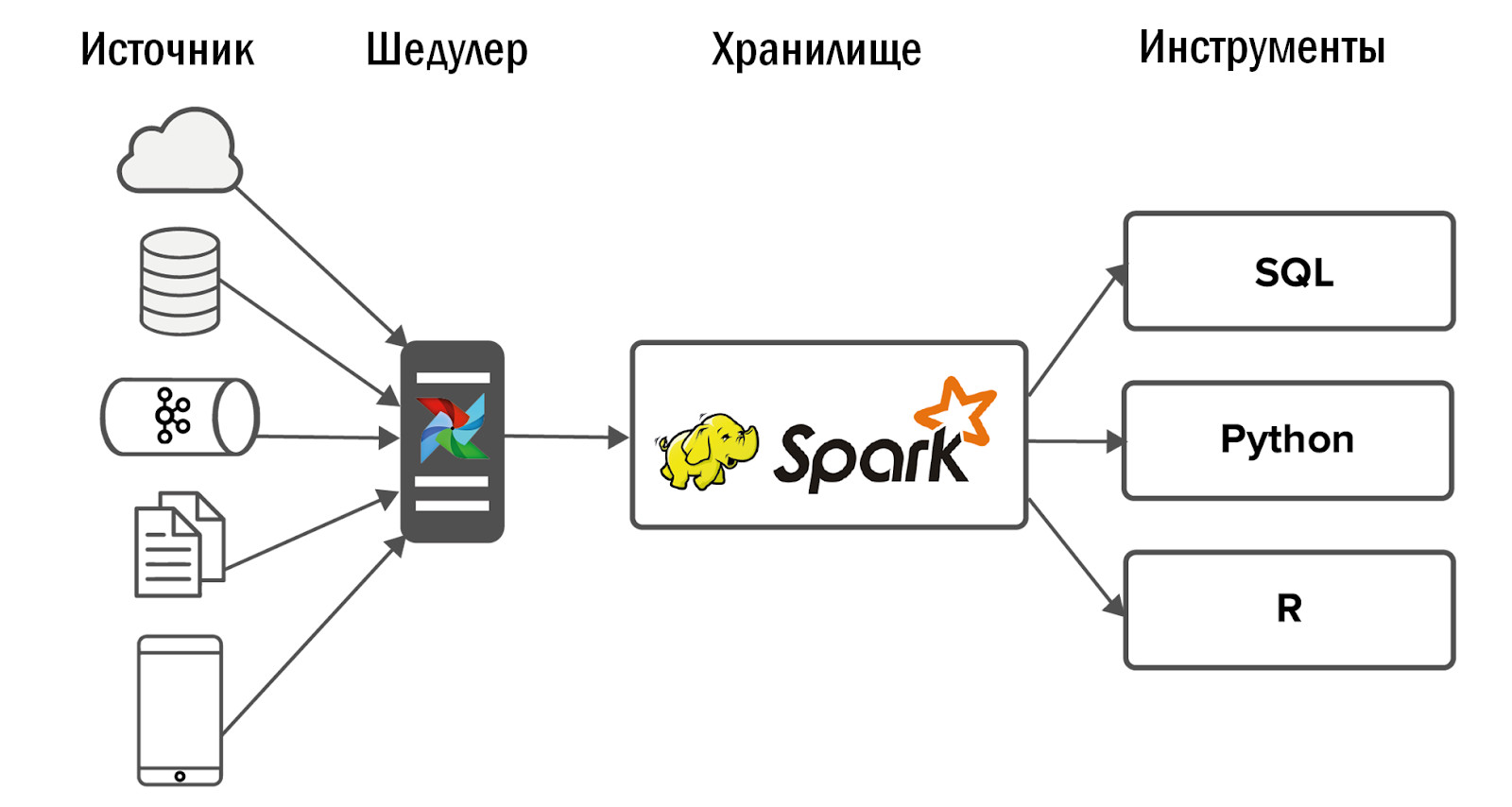
Le schéma de stockage unifié mis à jour est le suivant:
- Après l'introduction d'Airflow, nous avons pu nous permettre une forte augmentation du nombre de sources - jusqu'à 400 pièces. Les sources de données sont à la fois internes (de nos jeux) et externes: systèmes de statistiques achetés, API hétérogènes. C'est Airflow qui nous permet d'exécuter et de contrôler quotidiennement 12 mille processus qui traitent les données de tous nos 150 jeux.
- Plus en détail sur notre flux d'air, Dean Safina a écrit dans son article ( https://habr.com/ru/company/mailru/blog/344398/ ). Et rejoignez également la communauté Airflow sur Telegram ( https://t.me/ruairflow ). De nombreuses questions sur Airflow peuvent être résolues à l'aide de la documentation, mais parfois des demandes plus personnalisées apparaissent: comment puis-je intégrer Airflow dans Docker, pourquoi ne fonctionne pas le troisième jour et tout cela. Cela peut être répondu dans cette communauté.
Quoi améliorer dans DataLake
À ce stade, les développeurs DWH sont convaincus que tout est prêt et que vous pouvez maintenant vous calmer. Malheureusement ou heureusement, il y a encore quelque chose à resserrer dans DataLake.
Qualité des données
Avec un grand nombre de tables dans DataLake, la qualité des données est la première à souffrir. Par exemple, prenez un tableau avec les paiements. Il contient user_id, montant, date et heure de paiement:
Environ 10 000 paiements sont effectués chaque jour:

Une fois dans le tableau de la journée, il n'y a eu que 28 entrées. Oui, et user_id est tout vide:
Si quelque chose se casse soudainement dans notre source, alors, grâce à Airflow, nous le saurons immédiatement. Mais s'il y a formellement des données, et même dans le bon format, alors nous ne sommes pas immédiatement informés de la ventilation et déjà des consommateurs de données. Il n'est pas réaliste de vérifier nos 5000 tables de nos propres mains.
Pour éviter cela, nous avons développé notre propre système de contrôle de la qualité des données (DQ). Chaque jour, il surveille les téléchargements clés vers notre référentiel: il suit les changements soudains du nombre de lignes, recherche les champs vides et vérifie la duplication des données. Le système applique également des vérifications personnalisées des analystes. Sur cette base, elle envoie des notifications par courrier électronique sur ce qui s'est mal passé et où. Les analystes se rendent sur les projets et découvrent pourquoi, par exemple, il y a trop peu de données, éliminons les raisons et nous rechargeons les données.
Prioriser les téléchargements
Avec le nombre croissant de tâches de chargement de données dans DataLake, un conflit de priorité survient rapidement. La situation habituelle: certains projets moins importants ont pris toutes les ressources avec leurs téléchargements la nuit, et les tables nécessaires au calcul des métriques pour la direction n'ont pas le temps de se charger au début de la journée de travail. Nous traitons cela de plusieurs manières.
- Surveillance des téléchargements de clés. Airflow possède son propre système SLA, qui vous permet de déterminer si toutes les clés sont arrivées à temps. Si certaines données ne sont pas chargées, nous le saurons quelques heures plus tôt que les utilisateurs et aurons le temps de le corriger.
- Définition des priorités. Pour ce faire, nous utilisons la file d'attente Airflow et le système de priorité. Il nous permet de déterminer l'ordre de chargement des DAG et le nombre de processus parallèles en eux. Cela n'a aucun sens de télécharger des journaux qui sont analysés une fois par trimestre, avant de télécharger des données pour les mesures de gestion supérieure.
Suivi de la durée du lot de nuit
Nous avons un stockage par lots. La nuit, nous sommes en train de le construire, et il est important pour nous de nous assurer qu'il y a suffisamment de nuit pour traiter le lot quotidien. Sinon, pendant les heures de travail, les analystes n'auront pas suffisamment de ressources de stockage pour travailler. Nous résolvons régulièrement ce problème de plusieurs manières:
- Mise à l'échelle inversée. Nous n'expédions pas toutes les données, mais seulement ce dont les analystes ont besoin. Nous surveillons toutes les tables chargées, et si l'une d'entre elles n'est pas utilisée pendant six mois, nous désactivons son chargement.
- Renforcement des capacités. Si nous comprenons que nous sommes limités par les capacités du réseau, le nombre de cœurs ou la capacité du disque, alors nous ajoutons des nœuds de données à Hadoop.
- Optimisation du flux d'air des travailleurs. Nous faisons tout pour que chaque partie de notre système soit utilisée au maximum à chaque instant de la construction du stockage.
- Refactorisation de processus non optimaux. Par exemple, nous considérons l'économie d'un nouveau jeu, et cela nous prend 5 minutes. Mais après un an, les données augmentent et la même demande est traitée pendant 2 heures. À un moment donné, nous devons nous réadapter au recalcul progressif, bien qu'au tout début cela puisse sembler une complication inutile.
Contrôle des ressources
Il est important non seulement d'avoir le temps de terminer la préparation du référentiel pour le début de la journée de travail, mais également de surveiller la disponibilité de ses ressources par la suite. Avec cela, des difficultés peuvent survenir avec le temps. Tout d'abord, la raison en est que les analystes écrivent des requêtes sous-optimales. Encore une fois, les analystes eux-mêmes deviennent de plus en plus. La chose la plus simple dans ce cas: augmenter la capacité matérielle. Cependant, une demande non optimale prendra toujours toutes les ressources disponibles. Autrement dit, tôt ou tard, vous commencerez à dépenser de l'argent en fer sans avantage significatif. Par conséquent, nous utilisons plusieurs autres approches.
- Devis: nous laissons aux utilisateurs au moins un peu de ressources. Oui, les demandes seront exécutées lentement, mais au moins elles le seront.
- Surveillance des ressources consommées: combien de cœurs sont utilisés par les demandes des utilisateurs, qui ont oublié d'utiliser des partitions dans Hadoop et ont pris toute la RAM, etc. lui. Si nous avions peu de projets, nous suivrions nous-mêmes la consommation des ressources. Mais avec un si grand nombre, nous devions embaucher une équipe de surveillance distincte en constante expansion. Et à long terme, c'est déraisonnable.
- Formation des utilisateurs volontaire-obligatoire. Le travail des analystes n'est pas d'écrire des requêtes de qualité dans votre référentiel. Leur travail consiste à répondre aux questions des entreprises. Et à part nous-mêmes - l'équipe du référentiel - personne ne se soucie de la qualité des demandes des analystes. Par conséquent, nous créons des FAQ et des présentations, menons des conférences pour nos analystes, expliquons comment nous pouvons travailler avec notre DataLake et comment.
En fait, passer du temps à rendre les données disponibles est beaucoup plus important que de les remplir. S'il y a des données dans le stockage, mais qu'elles ne sont pas disponibles, du point de vue commercial, elles sont toujours là et vos efforts de téléchargement ont déjà été dépensés.
Flexibilité de l'architecture
Il est important de ne pas oublier la flexibilité du DataLake intégré et de ne pas avoir peur de changer l'architecture lors de la modification des facteurs d'entrée: quelles données doivent être téléchargées sur le stockage, qui les utilise et comment. Nous ne pensons pas que notre architecture restera toujours inchangée.
Par exemple, nous avons lancé un nouveau jeu mobile. Elle écrit JSON à Nginx à partir de clients, Nginx envoie des données à Kafka, nous les analysons à l'aide de Spark et les mettons dans Hadoop. Tout fonctionne, la tâche est close.
Quelques mois se sont écoulés et dans le stockage, tous les processus du lot de nuit ont commencé à fonctionner plus longtemps. Nous commençons à comprendre quel est le problème: il se trouve que le jeu a «tiré», 50 fois plus de données ont été générées et Spark n'a pas pu faire face à l'analyse JSON, entraînant la moitié des ressources de stockage. Initialement, toutes les données ont été envoyées à un sujet Kafka, et Spark les a triées en différentes entités. Nous avons demandé aux développeurs de jeux de partager des données sur les clients avec différentes entités et de les verser dans des sujets Kafka distincts. C'est devenu plus facile, mais pas pour longtemps. Nous avons ensuite décidé de passer de l'analyse JSON quotidienne à l'analyse horaire. Cependant, l'installation de stockage a commencé à être construite non seulement la nuit, mais 24 heures sur 24, ce qui n'était pas souhaitable pour nous. Après de telles tentatives, pour résoudre ce problème, nous avons abandonné Spark et implémenté ClickHouse.

Il dispose d'un excellent moteur d'analyse JSON qui décompose instantanément les données en tableaux. Nous envoyons d'abord des informations de Kafka à ClickHouse, puis nous les récupérons à Hadoop. Cela a complètement résolu notre problème.
Bien sûr, nous essayons de ne pas reproduire les systèmes de zoo dans notre stockage DataLake, mais nous essayons de sélectionner les technologies les plus appropriées pour des tâches spécifiques.
Cela en valait-il la peine?
Cela valait-il la peine de déployer Hadoop, un système de contrôle de la qualité, de gérer Airflow et d'établir des processus commerciaux? Bien sûr, cela valait la peine:
- L'entreprise dispose d'informations à jour sur tous les projets, disponibles en services uniques.
- Les utilisateurs de notre système, des concepteurs de jeux aux gestionnaires, ont cessé de prendre des décisions uniquement sur la base de l'intuition et sont passés à des approches basées sur les données.
- Nous avons donné aux analystes les outils nécessaires pour créer leur propre science des fusées. Désormais, ils répondent à des demandes commerciales complexes, construisent des modèles de prévision, des systèmes de recommandation, améliorent les jeux. En fait, pour cela, nous travaillons en BI-DWH.