Parfois, une tâche survient pour «coller» une sélection intégrale avec les mêmes données «en colonnes» à partir des tableaux linéaires passés en tant que paramètres dans la requête SQL.
Comment cela se fait-il parfois:
WITH T1 AS ( SELECT row_number() OVER() rn , unnest v1 FROM unnest('{1,2,3,4}'::integer[]) ) , T2 AS ( SELECT row_number() OVER() rn , unnest v2 FROM unnest('{5,6}'::integer[]) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);
v1 | v2 ------- 1 | 5 2 | 6 3 | 4 |
Autrement dit, au début, chacun des tableaux a été «étendu» dans l'échantillon, numéroté, puis ce numéro a été utilisé comme clé de connexion CTE ...
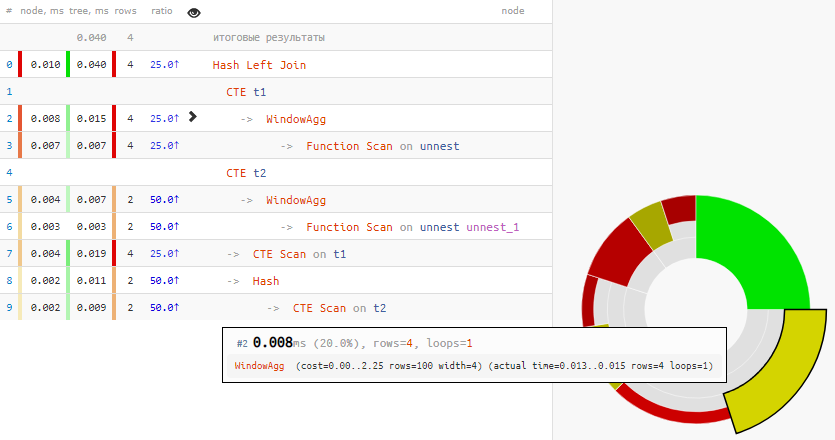 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]AVEC ORDINALITÉ
Plus d'un quart de tout le temps a été consacré à quelques WindowAgg!
Mais si nous utilisons une version de PG non inférieure à 9.4, nous
pouvons utiliser WITH ORDINALITY pour numéroter les résultats de tout SRF, y compris unnest:
WITH T1 AS ( SELECT * FROM unnest('{1,2,3,4}'::integer[]) WITH ORDINALITY T(v1, rn) ) , T2 AS ( SELECT * FROM unnest('{5,6}'::integer[]) WITH ORDINALITY T(v2, rn) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);
 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru] .
Ainsi, nous nous sommes complètement débarrassés de l'utilisation des fonctions de fenêtre.
UNNEST multi-arguments
Mais du point de vue de l'efficacité, tout n'est pas bon jusqu'à présent - presque la moitié du temps est allée à Hash Left Join.
Et l'auteur part clairement de l'hypothèse que le premier tableau est exactement plus long - c'est pourquoi il a utilisé LEFT JOIN. Mais cette hypothèse n'est pas toujours correcte et peut poser des problèmes.
Pour le contourner, nous utiliserons
unnest pour plusieurs tableaux en même temps , qui est apparu à partir de la même version 9.4:
SELECT * FROM unnest( '{1,2,3,4}'::integer[] , '{5,6}'::integer[] ) T(v1, v2);
En conséquence, il ne restait presque rien de la demande et du plan:
Function Scan on t (cost=0.01..1.00 rows=100 width=8) (actual time=0.006..0.007 rows=4 loops=1)
Par conséquent, les chances de faire une erreur sont bien moindres. Oui, et le temps d'exécution a été amélioré plusieurs fois - et sur des tableaux plus longs, l'effet sera encore plus perceptible.