Chez
People & Screens, nous travaillons depuis de nombreuses années avec des entreprises en ligne en tant que partenaire publicitaire. Lorsque nous avons eu l'idée d'évaluer la contribution de la publicité display aux ventes des boutiques en ligne, cela semblait irréalisable et même fou. Dès que nous avons réalisé que tous les éléments de la mosaïque peuvent être retrouvés et assemblés, nous avons décidé de l'essayer. Les premières hypothèses ont commencé à être confirmées, avec
Data Insight, nous avons approfondi cette histoire et en quelques mois de travail minutieux
, nous avons créé une telle étude, qui, en fait, est un outil de travail appliqué - un modèle pour évaluer la performance publicitaire dans 12 catégories de produits de commerce électronique. Dans cet article, nous parlerons des résultats et des méthodes d'analyse utilisées.
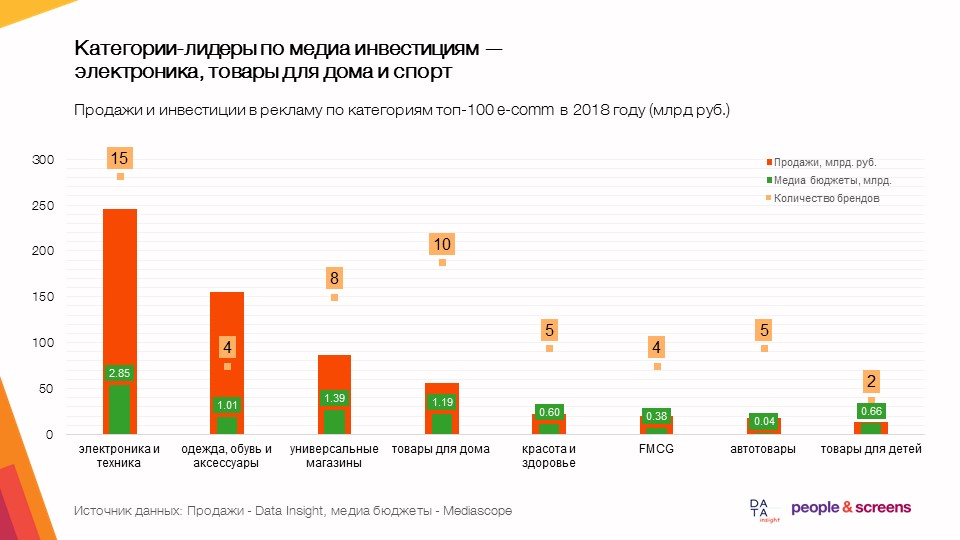
Objectifs et résultats de la recherche
L'hypothèse clé de notre étude: la publicité display, le développement de la marque d'une boutique en ligne, augmente la conversion dans l'ensemble de l'entonnoir de vente. Dans l'analyse des données de vente, de publicité et des données externes des quatre dernières années, l'hypothèse a été confirmée. En conséquence, nous avons construit des modèles de vente économétriques pour 60 magasins en ligne dans 12 catégories de produits.
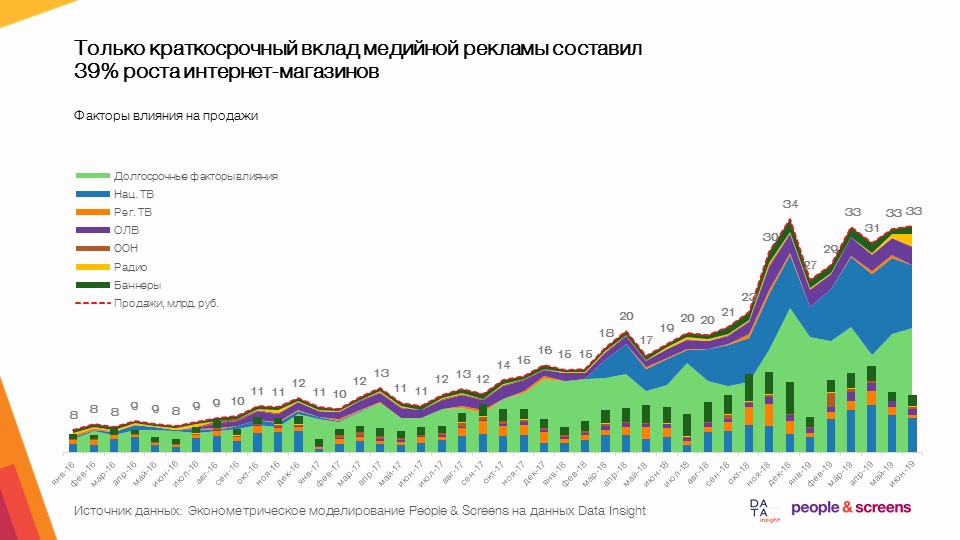
- Seule la contribution à court terme de la publicité display représente 39% de la croissance des boutiques en ligne avec une dynamique de marché moyenne de 50-60%.
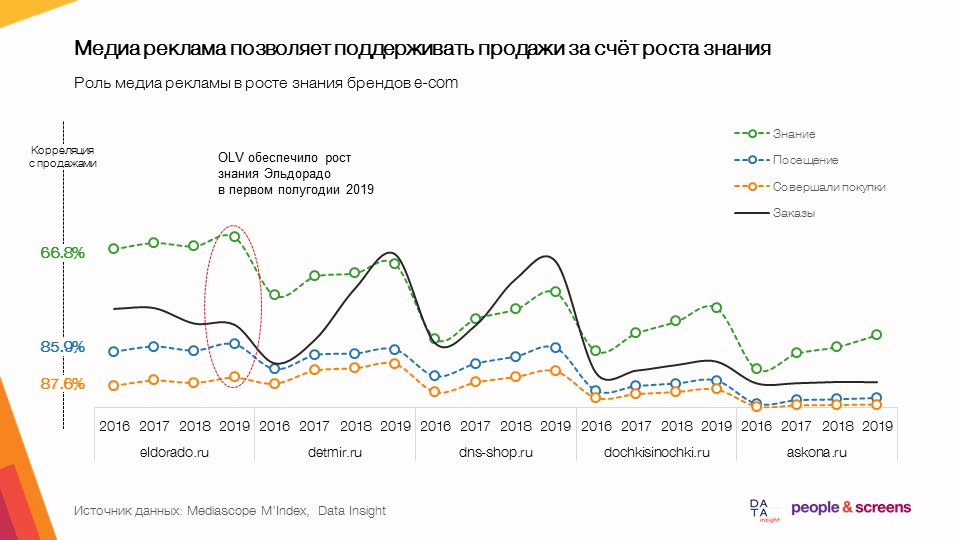
- La publicité display vous permet de soutenir les ventes grâce à une meilleure connaissance.
- Le plus grand retour sur l'ensemble dans le commerce électronique provient de la publicité vidéo en ligne.
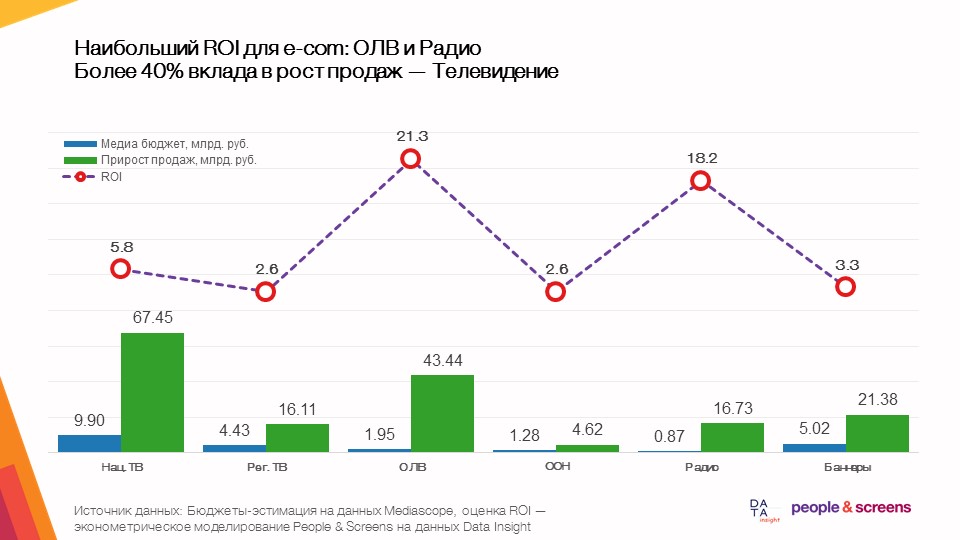
- L'efficacité des médias dépend fortement de la catégorie: dans les catégories des vêtements et des hypermarchés en ligne, la télévision a montré une efficacité élevée, dans les produits électroniques et automobiles - publicité vidéo en ligne.
Ce que nous avons analysé
La collecte des données pour l'étude a été réalisée par les deux sociétés participant à l'étude. People & Screens a collecté les données suivantes:
- Afficher les sorties d'annonces. Nous avons utilisé des téléchargements à partir des bases de données Mediascope auxquelles tous les groupes d'annonces ont accès. Nous avons déchargé les frais de publicité pour tous les médias et contacts publicitaires auprès d'un large public cible (18 ans et plus) en détail par jour (pour la publicité à la télévision, à la radio, dans la presse, sur Internet) et par mois (pour la publicité extérieure) à partir de janvier 2016 jusqu'en juin 2019. Pour maximiser la vitesse de travail à ce stade, nous avons utilisé le développement interne de Dentsu Aegis Network Russia pour travailler avec des données industrielles, en particulier la plate-forme Atomizer.
- Déchargement quotidien des données de SimilarWeb au cours des 18 derniers mois. Nous avons regardé la dynamique par jours de Visites sur Desktop / Mobile, la dynamique par jours de trafic desktop par source (canal), et la dynamique des installations sur Android.
- Dynamique des connaissances / visites / achats de la base de données TGI / Marketing Index 2016-2019 par trimestre. Il s'agit d'un téléchargement du logiciel industriel Gallileo de Mediascope.
- Requêtes de recherche Google Trends pour janvier 2016 - juillet 2019 dans toute la Russie.
Du côté de Data Insight, les données suivantes ont été collectées et fournies:
- La dynamique des commandes de 72 boutiques en ligne du TOP 100 par mois pour la période de janvier 2016 à août 2019.
- Les données du compteur li.ru pour la période de janvier 2018 à août 2019 (trafic vers le site, total séparé, uniquement en Russie et uniquement mobile) pour les sites TOP-11.
- Les données du compteur mail.ru pour la période de juin 2017 à septembre 2019 pour 53 sites.
- Données de compteur Rambler pour la période de juin 2017 à septembre 2019 pour 38 sites.
- Yandex Wordstat recherche des données de recherche pendant 24 mois d'octobre 2017 à septembre 2019.
- Évaluation des contrôles moyens des 100 meilleures boutiques en ligne en 2018.
Algorithme de données
La collecte des données pour l'étude a été réalisée en plusieurs étapes. Nous laisserons en dehors du champ de l'article le travail que nos collègues de Data Insight ont réalisé pour générer les données nécessaires à l'étude, mais nous vous dirons quel travail a été fait du côté de People & Screens:
- Recherchez toutes les boutiques en ligne du classement TOP-100 dans les bases de données industrielles à notre disposition et compilez des dictionnaires de correspondance de noms. Pour cela, nous avons utilisé le moteur de recherche sémantique Elasticsearch .
- Formation de modèles et téléchargement de données sur eux. À ce stade, le plus important était de penser à l'avance l'architecture des tableaux de données.
- Combinaison de données de toutes les sources en un seul ensemble de données (ensemble de données).
Pour ce faire, nous avons utilisé le traitement des données téléchargées en Python à l'aide des packages pandas et sqlalchemy . L'ensemble des hacks de vie ici est assez standard:
Lors du traitement des données brutes des tables csv supérieures à 1 million de lignes, nous avons d'abord téléchargé les noms des colonnes de la table avec une requête du formulaire:
col_names = pd.read_csv(FILE_PATH,sep=';', nrows=0).columns
puis les types de données ont été ajoutés via le dictionnaire:
types_dict = {'Cost RUB' : int } types_dict.update({col: str for col in col_names if col not in types_dict})
et les données elles-mêmes chargées
pd.read_csv(FILE_PATH, sep=';', usecols=col_names, dtype=types_dict, chunksize=chunksize)
Les résultats de la conversion ont été téléchargés sur PostgreSQL. - Validation croisée de la dynamique des commandes basée sur l'analyse de la dynamique du trafic, les requêtes de recherche et les ventes réelles à travers le pool de clients de l'agence People & Screens. Ici, nous avons construit des matrices de corrélation à l'aide de df.corr () sur différents ensembles de données au sein d'un site fixe, puis nous avons analysé en détail la série «suspecte» avec les valeurs aberrantes. C'est l'une des étapes clés de l'étude, au cours de laquelle nous avons vérifié la fiabilité de la dynamique des indicateurs étudiés.
- Construction de modèles économétriques sur données validées. Ici, nous avons utilisé les transformées de Fourier directes et inverses du package numpy (fonctions np.fft.fft et np.fft.ifft ) pour extraire la saisonnalité, une approximation par morceaux pour estimer la tendance et le modèle linear_model du package sklearn pour estimer la contribution de la publicité. Lors du choix d'une classe de modèles pour cette tâche, nous sommes partis du fait que le résultat de la simulation devait être facilement interprété et utilisé pour évaluer numériquement l'efficacité de la publicité en tenant compte de la qualité des données. Nous avons étudié la fiabilité des modèles en divisant les données en échantillons de formation et d'essai d'un intervalle de temps variable. C'est-à-dire nous avons comparé comment le modèle formé sur les données de janvier 2016 à décembre 2018 se comporte dans l'intervalle de temps de test de janvier à août 2019, puis nous avons formé le modèle dans l'intervalle de temps de janvier 2016 à janvier 2019 et regardé comment le modèle se comportait sur les données de février à Août 2019. La qualité des modèles a été étudiée par la stabilité de la contribution des facteurs publicitaires dans différents échantillons de formation comme la prévision sur l'échantillon test
- La dernière étape consistait à préparer une présentation basée sur les résultats. Ici, nous avons jeté un pont de modèles mathématiques vers des conclusions commerciales pratiques et une fois de plus testé les modèles du point de vue du bon sens des résultats.
Les spécificités de l'analyse du e-commerce et les difficultés qui se posent dans le processus
- Au stade de la collecte des données, des difficultés ont surgi avec la bonne évaluation de l'intérêt pour la recherche dans la ressource. Dans Google Trends, il n'y a aucun moyen de regrouper les requêtes de recherche et d'utiliser des mots clés à exclure comme dans Yandex Wordstat. Il était important d'étudier le noyau sémantique de chaque boutique en ligne et de télécharger la demande centrale. Par exemple, M.Video doit être écrit en russe - c'est la demande centrale pour ce site.
Pour les magasins qui vendent des marchandises en ligne et hors ligne, les collègues de Data Insight ont adopté l'approche suivante dans les données wordstat de Yandex:
Assurez-vous qu'il n'y a pas de questions non pertinentes (l'essentiel n'est pas d'estimer le volume de la demande, mais de suivre les changements de dynamique). Nous avons assez de difficulté pour filtrer les mots de recherche. Lorsqu'il y avait un risque par le nom de la marque de prendre des demandes inappropriées, nous avons pris des statistiques sur les combinaisons de touches. Par exemple, «magasin d'ozone» au lieu d '«ozone» - avec cette approche, la popularité de recherche du détaillant est sous-estimée, mais la dynamique de la demande est mesurée de manière plus fiable et se débarrasse du «bruit». En ce qui concerne les statistiques de recherche, il existe un problème méthodologique qui n'a apparemment pas de solution fiable - pour de nombreux détaillants, ces statistiques sont déformées par des outils de référencement qui optimisent les résultats de la recherche grâce à des facteurs comportementaux, mais déforment les statistiques sur la demande réelle. - Au stade de la combinaison des données provenant de différentes sources, il est devenu nécessaire de regrouper les données dans une seule granularité: les données sur la publicité télévisée et le trafic de SimilarWeb étaient quotidiennes, les données pour les requêtes de recherche étaient hebdomadaires et les données sur les commandes et les données des compteurs étaient mensuelles. En conséquence, nous avons formé une base de données distincte avec des champs de date qui vous permettent d'agréger les données au niveau requis et une base de données d'agrégation mensuelle en cache pour continuer à travailler avec tous les détails des données de vente.
- Au stade de la validation croisée des données, nous avons constaté des écarts notables dans la dynamique des ventes avec nos propres données. Cela a nécessité une discussion de la situation avec des collègues de Data Insight. En conséquence, grâce à une compréhension précise des mois au cours desquels les erreurs les plus importantes se produisent, les analystes ont identifié deux erreurs qui sont profondément en bas de l'algorithme pour évaluer la dynamique des ventes mensuelles.
- Au stade du développement du modèle, plusieurs difficultés sont apparues. Pour évaluer correctement l'effet de la publicité, il a fallu isoler les facteurs externes. Toute dynamique de vente (et le commerce électronique ne fait pas exception) est associée non seulement à la publicité, mais aussi à de nombreux autres facteurs: changements UX / UI sur le site, prix, assortiment, concurrence, fluctuations monétaires, etc.
Pour résoudre ce problème, nous avons utilisé une approche basée sur une analyse de régression des données sur une longue période - de janvier 2016 à août 2019. Dans le cadre de cette approche, nous avons analysé les changements (poussées) dans la dynamique des commandes qui peuvent être attribués à la publicité durant cette période.
Il est important de comprendre que si à un moment donné une publicité a commencé, mais que la valeur attendue des ventes, selon le modèle, n'était pas supérieure à la valeur réelle, le modèle montrera que cette publicité n'a pas fonctionné pendant cette période. Bien sûr, un tel comportement de vente peut être une superposition de plusieurs facteurs (par exemple, des augmentations de prix / lancement de concurrents en même temps que la campagne publicitaire démarre, ou le site "est tombé" de l'afflux de clients).
Étant donné que nous faisons la moyenne des effets sur une longue période de temps sur un grand nombre de marques, l'effet de ces coïncidences aléatoires devrait être égalisé sur un large échantillon, bien qu'il puisse conduire à des effets surestimés ou sous-estimés pour des marques individuelles. Par conséquent, cela nous a permis de déterminer des règles et des modèles généraux pour la catégorie du commerce électronique dans son ensemble. Dans le même temps, pour une analyse détaillée de l'influence de la publicité au sein des marques individuelles, il est bien sûr encore nécessaire d'étudier l'ensemble des facteurs d'influence.
Conclusion
Dans le cadre de cette étude, nous nous sommes fixé pour objectif d'obtenir les résultats les plus fiables à partir de données issues de sources hétérogènes. En elles-mêmes, ces données ne sont pas des valeurs exactes, mais seulement une évaluation de ces valeurs au moyen d'un suivi tiers (suivi des sorties publicitaires, de la dynamique du trafic, des intérêts de recherche et, enfin, des commandes).
Chaque lien a des limites sur la qualité des données, et c'est un problème auquel les analystes et les chercheurs sont confrontés à une échelle ou une autre chaque jour. Nous espérons que dans le cadre de cet article nous avons pu montrer quelles méthodes peuvent assurer la fiabilité des conclusions d'une étude analytique, tout en préservant le pouvoir explicatif des résultats.