Bonjour à tous! Je m'appelle Denis Oleynik, je travaille en tant que directeur technique chez 1Service.
Dans notre entreprise, nous consacrons beaucoup de temps à travailler avec les exigences. Au fur et à mesure que nous avons acquis de l'expérience, nous avons commencé à réaliser que les outils couramment utilisés dans le développement de produits logiciels nous conduisaient à un état où nous ne pouvons pas dire que nous avons réalisé exactement ce que le client attendait de nous. Précisément parce qu'à un moment donné, il existe un écart entre les exigences initialement collectées et leur mise en œuvre logicielle et les tests ultérieurs.

Cette ligne se situe quelque part entre les exigences enregistrées dans Confluence et les tâches pour leur implémentation dans Jira. Une autre ligne va entre les cas de test dans l'outil de test et les mêmes exigences dans Confluence, avec un œil sur le code associé aux tâches dans Jira. L'absence de réponses claires aux questions: «pourquoi / pourquoi l'avons-nous fait de cette façon» ou «avons-nous fait tout ce que le client attendait de nous» - nous a causé une vive inquiétude.
Et à un moment donné, il nous a semblé que le concept de «documentation est code» (la documentation comme code) nous permettra de trouver des réponses à ces questions. Le concept «la documentation est du code» suppose que nous stockons les exigences, les solutions architecturales, les instructions d'utilisation sous la forme de fichiers texte simples qui peuvent être versionnés en utilisant des systèmes de classe
(D) VCS , idéalement les modèles de données d'entrée-sortie devraient également être stockés dans un appartement forme de texte. De vrais documents «lisibles» (ainsi que des modules exécutables) apparaîtront à la suite de l'assemblage du projet. Dans ce cas, la documentation technique évoluera avec le développement de l'ensemble du projet sur les mêmes principes de versioning du code, ce qui lui permettra de répondre aux critères de traçabilité, de vérification et de pertinence de bout en bout. De plus, cette approche résout nativement le problème de l'organisation de la "version de base des exigences" (lignes de base), qui pour de nombreux systèmes de gestion des exigences devient un vrai problème. En particulier, dans Confluence, il est recommandé de résoudre ce problème en créant une copie de l'espace d'origine dans lequel les exigences ont été établies, tandis que toute connexion et l'hérédité des exigences sont perdues. En fait, cet article est consacré à la recherche sur le terrain de ce concept dans notre entreprise.
Contexte
Ce qui, à notre avis, arrête l'utilisation répandue de ce concept parmi les masses, c'est la misère des outils de représentation visuelle et de gestion des exigences sous forme de texte plat. Cela signifie que vous n'afficherez pas les fichiers de texte plats Product Owner pour qu'il y voit la portée du projet, vous ne pouvez pas afficher les fichiers texte sur la page de présentation pour les parties prenantes, ils n'ont pas de graphiques, de graphiques et de photos au stade de l'édition - et cela dégoûte déjà les analystes commerciaux qui devrait essentiellement générer du contenu. Et seuls les développeurs sont contents et crient: «cool! seulement hardcore! plus de commits! »et d'autres hérésies.
Il y a un autre point assez subtil. Pour une raison quelconque, les apologistes du concept «la documentation est du code» sont sûrs que dès que la documentation se trouve à côté du code dans le référentiel, cela entraînera son adaptation et sa synchronisation obligatoires avec les modifications du code, ce qui lui permettra d'être tenu à jour (
section 1.2.1 ) Mais à notre avis, ce moment restera une question de discipline, car personne ne se soucie de changer le code, et la documentation ne change pas. Autrement dit, la pertinence de la documentation avec une telle implémentation du concept est laissée à la gestion du processus de développement, où l'étape obligatoire avant la publication est de «vérifier la pertinence de la documentation». Dans ce cas, «la documentation est un code» ne va pas loin des fichiers Word, si l'on ne prend pas en compte une certaine automatisation en matière de compilation des documents résultants.
Eh bien, oui - premièrement, c'est «gênant, aimé, sec» et deuxièmement, les puces techniques «couvrent avec un chiffon» le problème de la mise à jour de la documentation. Il existe un stéréotype commun: "nous sommes par voie de courrier électronique - mais nous n'avons pas besoin de documentation en ligne!" Pour le dire légèrement, ce n'est pas entièrement vrai. J'aime réfuter cette erreur en comparant les approches de cas d'utilisation et de user story de l'excellent livre de Karl Wigers «Software Requirements Development» [4]. Si nous relions les approches de développement basées sur les User Stories à la méthodologie Agile, alors Wigers formule l'évolution des exigences basées sur les User Stories de cette manière:
Historique utilisateur → (discussions) → Historique utilisateur mis à jour (avec critères d'acceptation) → (discussions) → Tests d'acceptation
(p. 169, fig. 8-1). Ainsi, la documentation de sortie résultant de l'évolution des exigences initiales dans les projets de développement agile est des tests d'acceptation. Aujourd'hui, une technique assez courante pour organiser les tests d'acceptation consiste à utiliser des scripts de test écrits en langage
Gherkin [5], stockés dans ce qu'on appelle des fichiers de fonctionnalités (simples, texte).
Par conséquent, afin
de soutenir la mise en œuvre du concept «la documentation est du code» dans les projets agiles, nous avons besoin d'un outil qui accompagnera l'évolution des exigences du format User Story aux tests d'acceptation , qui, à la suite de leur exécution réussie, généreront une documentation à jour. Malheureusement, à ce jour, il n'existe pas d'outil permettant de soutenir pleinement ce processus (ou du moins de postuler sa volonté de le soutenir).
Architecture des outils de recherche
Donc, il n'y a pas d'outil, mais je veux explorer le concept. Du désespoir, nous avons dû le développer. Si un tel outil (appelons-le StoryMapper) existait déjà, quel type d'architecture aurait-il pour s'intégrer discrètement, avec un minimum de stress, dans un écosystème existant du processus de développement? S'il s'agit déjà d'un processus de développement intégré, alors la boucle
CI / CD y serait probablement déjà exécutée, et le système de contrôle de version, très probablement basé sur git, serait certainement utilisé. Dans ce cas, le diagramme ci-dessous montre la place de StoryMapper pendant le processus de développement:
Fig. 1 Place de l'outil StoryMapper dans la structure du processus de développementAinsi, StoryMapper interagira directement avec les services d'hébergement des référentiels git et avec la boucle
CI / CD . L'intégration avec les services d'hébergement git est nécessaire pour obtenir la collection actuelle de fichiers de fonctionnalités (le cas échéant), ainsi que pour mettre les résultats des modifications dans les fichiers de fonctionnalités, les fichiers de services liés à la documentation de structuration, des exemples de données d'entrée et de sortie dans le référentiel, etc. . etc. Interaction avec le contour
CI / CD nécessaire pour être en mesure d'exécuter les tests de scénarios de montage (manuelle ou programmée), et les résultats des tests ultérieurs - pour les faire correspondre avec les fichiers de fonction correspondante ( par exemple Obra e vérifierons et vérifier la pertinence de la documentation).
Vous devez comprendre que StoryMapper n'a pratiquement pas à revendiquer le titre de «encore un autre éditeur Gherkin». Oui, la capacité de base pour éditer les fichiers de fonctionnalités doit être définie, mais nous sommes clairement conscients que si
BA ou
QA ont opté pour VSC, Sublime, Notepad ++ ou même vi (pourquoi pas?), Convainquez-les de travailler avec des exigences uniquement dans StoryMapper la tâche n'est pas si ingrate, mais plutôt incorrecte. Par conséquent, nous supposons que la possibilité d'une utilisation diversifiée de StoryMapper doit être posée, en particulier: le développement de fonctionnalités dans votre éditeur préféré, et StoryMapper est utilisé pour structurer des fichiers de fonctionnalités prêts à l'emploi. Plus à ce sujet dans la section sur les directions de recherche.
Fonctionnalité minimale requise
Puisque StoryMapper est actuellement à l'état MVP, ce sont les exigences très minimales que nous avons faites pour qu'il puisse vraiment commencer à être utilisé:
- Cartographie d'histoire basée sur Git;
- Éditeur de cornichons;
- Lancement de l'assemblage des tests de scénarios (manuellement et selon le planning);
- Réflexion des résultats des tests de scénarios sur la carte des user stories.
Je ne m'attarderai pas sur la fonctionnalité de l'outil, puisque le sujet de cet article est le déroulement de l'opération, et non le scalpel du chirurgien.
Domaines de recherche
L'idée principale est la suivante:
si, en utilisant le concept de «la documentation est du code», vous ne vous éloignez pas des exigences du client et n'écrivez pas une sorte de documentation arbitraire pendant que vous écrivez du code, alors cette documentation mourra et perdra sa pertinence aussi rapidement que la version avec des fichiers au format MS Parole Par conséquent, nous avons voulu réfléchir et explorer la possibilité d'utiliser le concept en relation avec le cycle de développement complet. D'autre part, nous nous sommes également intéressés au moment de transition où l'équipe n'utilise pas le concept «la documentation est un code», mais il y a une volonté de l'appliquer - comment agir dans ce cas?
Donc, StoryMapper est un outil, il ne réglemente pas le seul vrai cas d'utilisation. Au contraire, chaque utilisateur potentiel peut voir ses options d'utilisation de l'outil. Nous nous sommes concentrés sur trois domaines principaux:
- Développement flexible: d'une carte d'histoire aux tests d'acceptation;
- Structurer et visualiser une collection de fichiers d'entités;
- Suivi de la productivité.
Ci-dessous, je décrirai en détail les résultats que nous avons obtenus dans chaque direction.
Développement flexible: des cartes récits aux tests d'acceptation
Cette direction implique le développement d'un nouveau produit ou le raffinement d'un produit existant. Les travaux dans ce sens se sont déroulés sous le nom de code "BDDSM": en tant que combinaison de la technique Story Mapping et de la méthodologie de développement
BDD . Et cela a pris racine.
Ainsi, pour commencer, un référentiel git est créé pour les fichiers de fonctionnalités, une branche y est allouée pour interagir avec StoryMapper. Un projet est créé dans StoryMapper, il est connecté à des analystes métier qui travailleront sur le projet. En communiquant avec les parties prenantes, les analystes commerciaux commencent à formuler une vision commune du produit et à la fixer sous la forme d'un squelette de carte utilisateur [1,2], d'abord un croquis du premier niveau d'
UF :
 Fig. 6 Squelette de niveau supérieur de la carte des user stories (cliquable)
Fig. 6 Squelette de niveau supérieur de la carte des user stories (cliquable)Et puis remplir progressivement le deuxième niveau d'activités des utilisateurs:
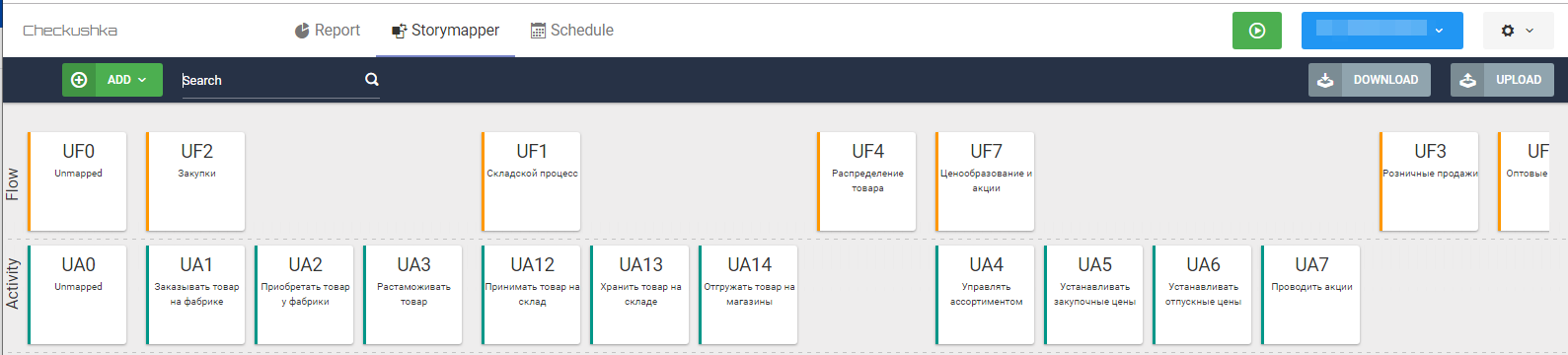 Fig. 7 Squelette de deuxième niveau de la carte des user stories
Fig. 7 Squelette de deuxième niveau de la carte des user storiesÉtant donné que chaque carte est un fichier texte, soit au stade de la collecte des exigences (si la carte est compilée au cours de la communication avec l'utilisateur), soit au stade du post-traitement des entretiens, les résultats de la communication sont transférés directement sur les cartes
UF et
UA . C'est la base d'une décomposition plus poussée des exigences au niveau des user stories.
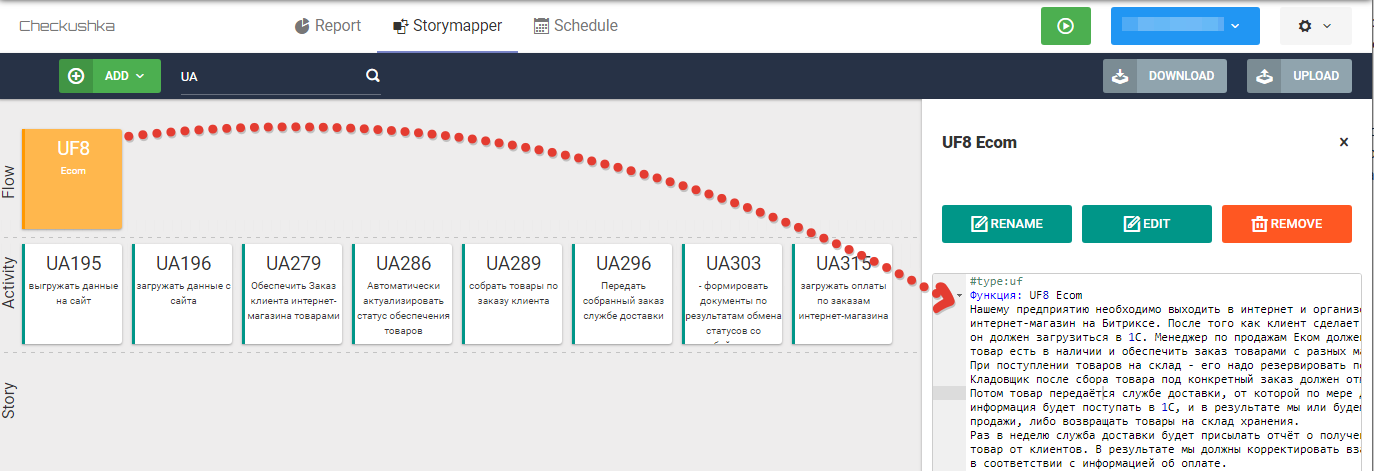 Fig. 8 Texte d'exigences sans syntaxe Gherkin au niveau UF
Fig. 8 Texte d'exigences sans syntaxe Gherkin au niveau UFEnsuite, les analystes commerciaux réalisent comment décomposer les activités des utilisateurs en user stories et forment un troisième niveau de carte dans StoryMapper -
US . L'isolement des
États-Unis est associé à la formulation de critères d'acceptation, c'est-à-dire que si «vous en tant que quelqu'un voulez quelque chose», nous vérifierons ensuite que vous l'avez reçu [3]. Les critères d'acceptation pour les débutants peuvent également être fixés aux
États -
Unis sous forme de texte plat.
Une fois les critères d'acceptation établis et convenus avec les parties prenantes, les analystes commerciaux les mettent sous forme de scripts en langage Gherkin. En fait, le texte «Scénario: KP-No» est ajouté à chaque critère d'acceptation, ce qui transforme l'histoire utilisateur jusqu'ici abstraite en un fichier de fonctionnalités.
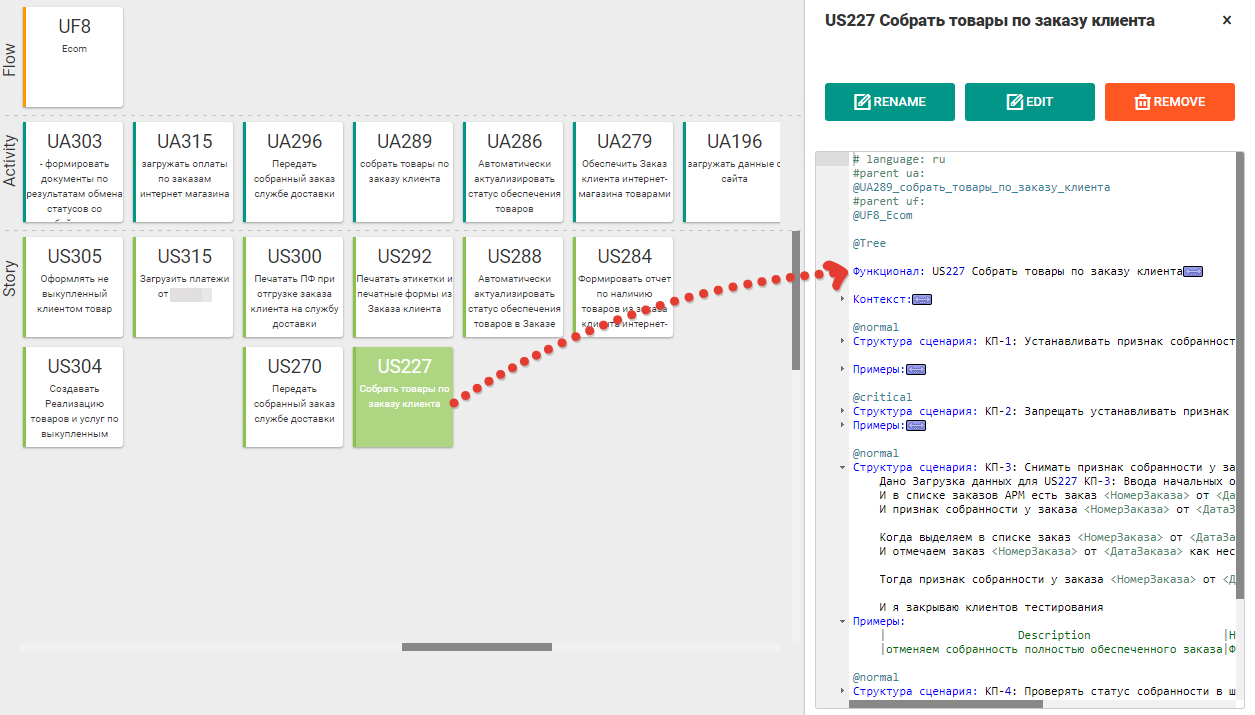 Fig. 8.1 Critères d'acceptation des user stories en tant que scripts sur Gherkin
Fig. 8.1 Critères d'acceptation des user stories en tant que scripts sur GherkinAprès cela, chaque scénario est déchiffré par plusieurs étapes agrandies qui révèlent exactement comment un critère d'acceptation spécifique sera vérifié. De plus, ces étapes sont soit programmées par les développeurs, soit tapées à partir de la bibliothèque d'étapes du framework Gherkin utilisé et exportées pour exporter des scripts.
Parallèlement à cela, un banc de test est organisé sur lequel le serveur d'assemblage exécutera des tests fonctionnels et attendra le moment où les
États -
Unis avec les scripts seront prêts. Lorsque le produit et les scénarios qui implémentent les critères d'acceptation sont prêts, le serveur d'assemblage commence à émettre des rapports au format Allure et Cucumber et à les envoyer à StoryMapper, qui à son tour projette le résultat de l'assemblage au format Cucumber sur la carte de la user story:
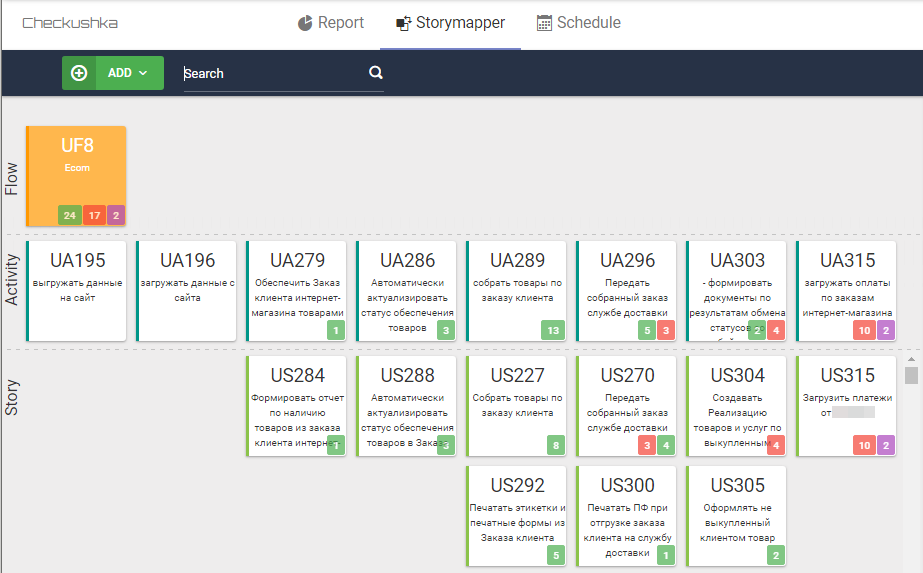 Fig. 9 Carte des user stories avec les résultats des scripts
Fig. 9 Carte des user stories avec les résultats des scriptsDans le même temps, StoryMapper fournit trois niveaux de compréhension de la préparation du produit: UF est le niveau supérieur qui affiche le nombre de scripts fonctionnant correctement (répondant aux critères d'acceptation), travaillant avec des erreurs et pas encore prêt. En fait, le niveau supérieur est un indicateur de la préparation du produit et un indicateur de ce qu'il reste à faire (c'est le niveau du propriétaire du produit). Les niveaux inférieurs vous permettent de déterminer exactement quel type d'activités utilisateur il y a des difficultés, et où vous devez faire des efforts pour mener à bien le produit (c'est le niveau des maîtres Scrum dans une plus grande mesure et le propriétaire du produit dans une moindre mesure). Le niveau inférieur des
États -
Unis est le niveau auquel les analystes commerciaux, les développeurs et l'AQ interagissent, développant conjointement exactement le produit que les parties prenantes attendent d'eux.
De plus, dans l'une des dernières étapes de la chaîne de montage, une documentation automatique est créée. Vous pouvez en savoir plus à ce sujet avec vos
collègues . Ce n'est pas la seule option, nous prévoyons d'inclure le package
Pickles dans notre outil - la norme de facto dans le monde de la «documentation en direct».
Structurer et visualiser une collection de fichiers d'entités
En travaillant dans ce sens, nous avons considéré un tel cas. L'équipe de développement, dans le sillage du battage médiatique autour du thème du BDD, des tests fonctionnels et des normes de développement de l'industrie, s'est engagée à écrire des fichiers de fonctionnalités. Et percer les épines, a accumulé une collection assez importante dans le référentiel. Cependant, lorsque vous avez 10 fichiers dans votre collection, le rapport au format Allure donne toujours une image fiable de l'état du produit. Mais si le nombre de fichiers d'entités est mesuré en dizaines, et parfois en centaines, vous voudrez tôt ou tard les structurer. La première chose qui me vient à l'esprit est de les trier dans des dossiers thématiques. Et pour quoi? Par parties prenantes, par métadonnées, par sous-systèmes? Ce sont loin d'être des questions inutiles. Et s'il s'avère plus tard que les fichiers de fonctionnalités ont été initialement écrits comme Dieu le mettrait à l'âme, et qu'il existe des scripts liés à plusieurs dossiers à la fois, alors comment?
Ainsi, ce cas d'utilisation implique une volonté de nettoyer votre documentation afin de passer de «fonctionnalités séparément, documentation séparément» à «documentation est un code». Lorsqu'un tel référentiel est connecté à StoryMapper, tous les fichiers de fonctionnalités tombent dans la première colonne sous UF0 et UA0. L'étape suivante de la structuration consiste à composer le squelette de la structure. Dans StoryMapper, ce sont tous les mêmes
UF et
UA , mais personne n'insiste pour les considérer uniquement sous cet angle. Ils peuvent être considérés simplement comme 2 niveaux de hiérarchie, sous lesquels il est possible de placer des fichiers d'entités précédemment non structurés. Une fois la structure définie, les fichiers d'entités de la première colonne sont séparés sous l'
AU correspondant. Sans aucun doute, ce processus provoque une attaque de réflexion et de refactorisation de fonctionnalités, car au fur et à mesure que vous faites glisser, toute la profondeur du chaos qui a eu lieu lors de leur écriture initiale devient claire. Parfois, il suffit de transférer le script d'un fichier à un autre, parfois de diviser un gros fichier en plusieurs pour restaurer la connectivité sémantique, et parfois de le jeter à la poubelle, car d'anciens manuscrits non exécutables se trouvaient dans le référentiel.
Si la chaîne d'assemblage a déjà été configurée (enfin, puisqu'il existe un référentiel de fichiers de fonctionnalités, ils doivent être collectés quelque part), vous devez ajouter une étape pour envoyer les résultats de l'assemblage à StoryMapper. Le résultat final sera la dernière image de la section précédente (Fig. 9): des fichiers de caractéristiques structurés avec des marques sur les résultats de leurs scripts.
Comment utiliser une telle image? Il peut être présenté à l'équipe de direction afin de rendre compte des résultats de l'équipe et de démontrer le degré de préparation / qualité du produit. Il peut être utilisé par l'équipe dans le cadre d'une rétrospective pour corriger le
DoD ou pour corriger en quelque sorte le processus. Il peut être utilisé pour le nettoyage du backlog, mais cela nécessite déjà un travail selon le scénario décrit dans la section précédente, lorsque, après la structuration initiale des exigences, le développement ultérieur sera effectué dans un cycle complet (ou du moins en tenant compte) de StoryMapper.
Suivi des produits
Un autre cas d'utilisation secondaire qui a pris racine dans notre pratique. En fait, c'est un sujet moderne et à la mode - tester directement dans le produit pourquoi pas. Après tout, il n'y a pas d'erreur, non, et oui, ils le feront. Cela devient particulièrement pertinent si l'activité informatique n'est pas un profil pour l'entreprise et que le développement est externalisé, en particulier, il s'agit de petites et moyennes boutiques en ligne.
Comme nous le voyons. Une option simple: parmi l'ensemble des tests fonctionnels, un certain sous-ensemble de tests de base de données non modifiables est sélectionné et vérifie le front-end.
La deuxième option: les scénarios qui testent la logique métier sont mis en évidence, tandis que la session dans laquelle le test démarre est lancée dans un mode spécial de test, où la modification des données n'est pas reflétée dans la base de données, ne gâche pas les statistiques et ne participe pas à l'échange avec les systèmes comptables. Lorsque cet ensemble de scripts a été compilé, il est lié à un planning et, avec une fréquence donnée, est exécuté directement sur le produit. Le résultat de l'exécution se reflète également dans StoryMapper et Allure, mais plus important encore, s'il y a des erreurs dans cette suite de tests, les personnes intéressées par l'entreprise recevront une notification par e-mail, et ainsi, elles pourront naviguer en ligne sur la façon dont la prochaine version de ses fournisseurs Les services informatiques rompent son principal outil métier.Si les étapes des scripts incluent la vérification de la durée de leur exécution, et en cas de violation du temps de contrôle, arrêtez l'exécution des scripts avec une erreur, alors ces scripts refléteront les exigences de performances non fonctionnelles. En conséquence, si des modifications du code, une augmentation de la charge, une dégradation des performances d'hébergement ont affecté la vitesse du produit, une personne financièrement intéressée par la capacité de travail en sera avertie.Ainsi, afin d'organiser le suivi des produits, vous devez préparer:- référentiel avec un ensemble de scripts adaptés au produit;
- une chaîne de montage qui fournit des scripts dans le produit, avec un crochet configuré pour s'exécuter;
- StoryMapper avec un référentiel connecté et un hook configuré pour recevoir les résultats des tests;
- StoryMapper a configuré le calendrier de démarrage et la notification d'erreur.
Orientations de développement
Encore une fois, StoryMapper est actuellement dans l'état MVP. Néanmoins, il a autorisé la réalisation d '"expériences sur des personnes", qui, à mon avis, ont été menées à bien plus de succès. Eh bien, à la sortie, bien sûr, est venu le même «appétit avec de la nourriture». Voici une liste incomplète de ce que je voudrais ajouter à l'outil:- afficher dans l'outil de la «documentation vivante» qui devrait être le résultat final du concept «la documentation est du code»;
- discussion des scénarios entre les participants au projet (commentaires, collaboration, etc.);
- exporter / importer des cartes d'histoire personnalisées vers / depuis Excel;
- une sorte d'intégration avec Jira (mais il y a plus de questions que de réponses).
, , , . , .
( ), , ( !) —
telegram , .
- Jeff Patton, histoires personnalisées. L'art du développement de logiciels agiles, Saint-Pétersbourg, Peter, 2017.
- Mike Cohn, Histoires personnalisées. Développement logiciel flexible, M.-SPb.-K, Williams, 2012.
- Gojko Adjic, Specification by Example, NY, publication Manning, 2011.
- Karl Wigers, Joy Beatty, Développement d'exigences logicielles, M.: Édition russe; SPb.: BHV-Petersburg, 2014.
- L'article d'introduction BDD de Dan North «Qu'y a-t-il dans une histoire»
- Informations sur le concept «La documentation est du code» dans la communauté «Écrire les documents»
- La mise en œuvre du concept de « Documentation - ce code » dans le projet « docToolchain »