Mon collègue Rafael Grigoryan eegdude a récemment écrit un article sur les raisons pour lesquelles l'humanité avait besoin d'EEG et quels phénomènes importants peuvent y être enregistrés. Aujourd'hui, dans la continuité du sujet des interfaces neuronales, nous utilisons l'un des ensembles de données ouverts enregistrés sur un jeu utilisant la mécanique P300 pour visualiser le signal EEG, voir la structure des potentiels appelés, construire les principaux classificateurs, évaluer la qualité avec laquelle nous pouvons prédire la présence d'un tel potentiel appelé.
Permettez-moi de vous rappeler que P300 est un potentiel appelé (VP), une réponse spécifique du cerveau associée à la prise de décision et à des stimuli distinctifs (que nous verrons ci-dessous). Il est généralement utilisé pour construire des BCI modernes.
Pour faire la classification EEG, vous pouvez appeler des amis, écrire un jeu sur les ratons laveurs et les démons en VR, écrire vos propres réactions et écrire un article scientifique (j'en parlerai une autre fois), mais heureusement, des scientifiques du monde entier mené quelques expériences pour nous et il ne reste plus qu'à télécharger les données.
Une analyse de la façon de construire une interface neuronale sur le P300 avec du code étape par étape et des visualisations, ainsi qu'un lien vers le référentiel se trouvent sous le chat.
L'article ne montre que les principaux points du code, la version entièrement reproductible dans le cahier jupyter à rechercher ici
Du point de vue d'un EEG, le P300 n'est qu'une rafale à un certain moment dans certains canaux. Il existe de nombreuses façons de l'appeler, par exemple, si vous vous concentrez sur un seul objet et qu'il est activé à un moment aléatoire (change de forme, de couleur, de luminosité ou saute quelque part). Voici comment il a été mis en œuvre dans les temps anciens.
D'une manière générale, le schéma est le suivant: il existe plusieurs (généralement de 3 à 7) stimuli dans le champ de vision d'une personne. Une personne en choisit une et se concentre dessus (une bonne façon est de compter le nombre d'activations), puis chaque objet clignote dans un ordre aléatoire. Connaissant le temps d'activation de chaque stimulus, nous pouvons maintenant regarder le prochain EEG et déterminer s'il y avait un pic caractéristique (nous le verrons dans les visualisations ci-dessous). Étant donné que la personne s'est concentrée sur un seul stimulus, le pic devrait être de un. Ainsi, dans ces interfaces neuronales, l'une des nombreuses options est sélectionnée (lettres pour l'écriture, actions dans le jeu, et Dieu sait quoi d'autre). S'il y a plus de sept options, vous pouvez les placer sur la grille et réduire la tâche à la sélection d'une ligne + colonne. C'est ainsi que l'orthographe P300 à matrice classique, illustrée ci-dessus.
Dans le cas de l'ensemble de données considéré aujourd'hui, la partie visuelle (ainsi que le nom) a été empruntée aux fameux inviders de l'espace de jeu. Cela ressemblait à quelque chose comme ça

En fait, c'est la même orthographe, seules les lettres sont remplacées par des extraterrestres de jeu.
La vidéo du processus de jeu et les rapports techniques ont également été conservés.
D'une manière ou d'une autre, les données collectées à l'aide de ce jeu sont apparues sur Internet et nous pouvons y accéder. Les données se composent de 16 canaux EEG et d'un canal d'événement, montrant à quels moments les incitations cibles (faites par le joueur) et non cibles ont été activées, et nous travaillerons avec eux.
La plupart des ensembles de données pour BCI ont été enregistrés par des neurophysiologistes, et ce sont des gars qui ne se soucient pas vraiment de la compatibilité, donc les formats de données sont très divers: des différentes versions des fichiers .mat aux formats "standard" .edf et .gdf .
La chose la plus importante que vous devez savoir sur ces formats est que vous ne voulez pas les analyser ou travailler directement avec eux.
Heureusement, un groupe de passionnés de NeuroTechX a écrit des téléchargeurs pour certains jeux de données directement dans numpy.
Ces bootloaders font partie du projet moabb qui prétend être une solution universelle pour BCI.
Télécharger le jeu de données brutes
import moabb.datasets sampling_rate = 512 m_dataset = moabb.datasets.bi2013a( NonAdaptive=True, Adaptive=True, Training=True, Online=True, ) m_dataset.download() m_data = m_dataset.get_data()
À ce stade, nous avons obtenu une structure RawEDF contenant des enregistrements EEG. Il s'agit d'une structure du package mne , les biologistes l'utilisent généralement pour interagir avec les signaux: cette structure a des méthodes intégrées pour filtrer, visualiser, stocker les étiquettes, et on ne sait jamais. Mais nous n'irons pas de cette façon puisque l'interface du package a tendance à être instable (la version actuelle est 0.19 , mais nous utiliserons 0.17 puisque le jeu de données n'est plus lu par la nouvelle version) et mal documenté, à travers cela nos résultats peuvent devenir irreproductibles.
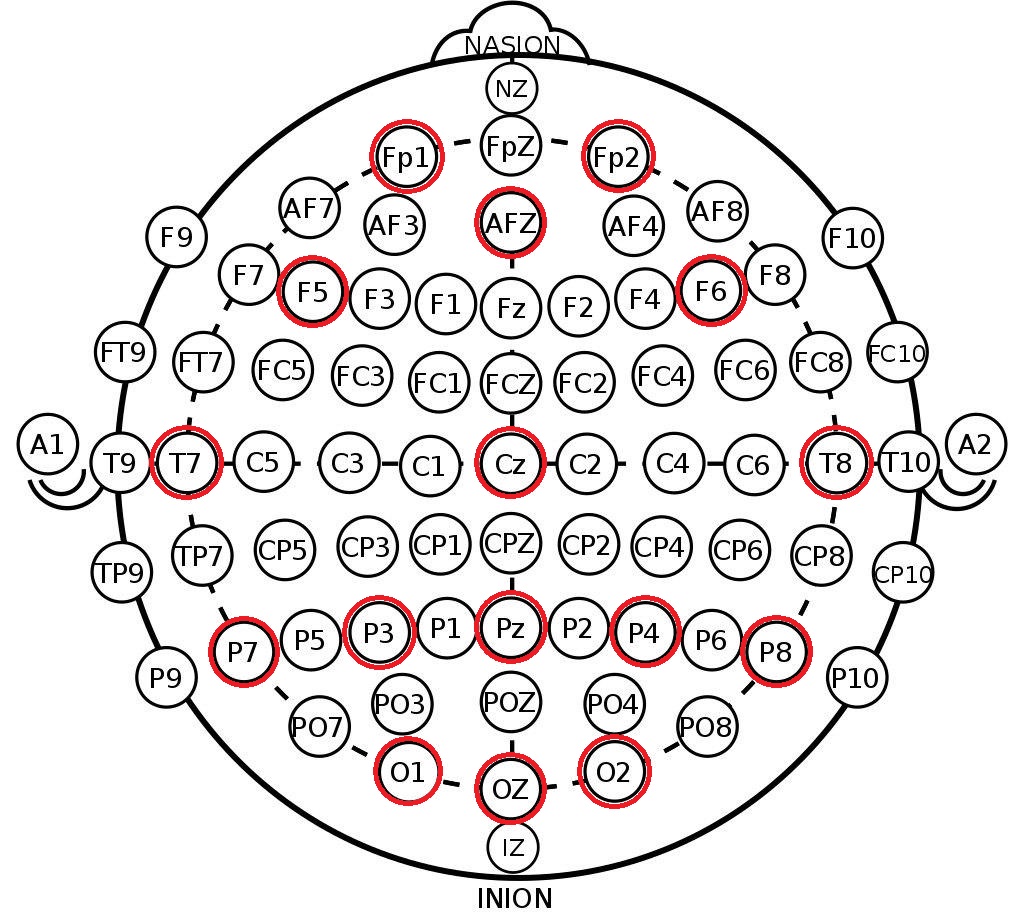
Ce que nous prenons de la structure résultante sont les étiquettes de canaux dans le système 10-20 . Il s'agit d'un arrangement international d'électrodes sur la tête d'une personne, créé pour que les scientifiques puissent corréler les zones du cerveau et l'emplacement des canaux EEG. Vous trouverez ci-dessous la disposition des électrodes dans le système 10-10 (diffère de 10-20 par deux fois la densité de marquage) et les canaux qui ont été enregistrés dans ce jeu de données sont marqués en rouge.
print(m_data[1]['session_1']['run_1'])
Tout d'abord, à partir des données téléchargées pour chaque sujet, nous allouons des tableaux d'EEG continu pendant 16 secondes et toutes les étiquettes pour cet intervalle (dans les données, c'est juste un autre canal dans lequel les débuts des événements qui nous intéressent sont notés).
À ce stade, nous conservons la longueur maximale de l'EEG continu afin de ne pas rencontrer d'effets de bord lors d'un filtrage ultérieur.
raw_dataset = [] for _, sessions in sorted(m_data.items()): eegs, markers = [], [] for item, run in sorted(sessions['session_1'].items()): data = run.get_data() eegs.append(data[:-1]) markers.append(data[-1]) raw_dataset.append((eegs, markers))
Filtrage et séparation
En général, pour revoir les méthodes de prétraitement et de classification de l'EEG, je peux recommander une excellente vue d' ensemble des maîtres des interfaces de neuro-ordinateurs. Il n'y a pas si longtemps, une revue plus récente des tests de réseau neuronal a été publiée.
Le prétraitement minimum du signal EEG pour la classification comprend 3 étapes:
- décimation
- filtrage
- mise à l'échelle
Pour implémenter ces étapes, nous utiliserons le bon vieux sklearn et son paradigme pour les transformateurs et les pipelines afin que notre prétraitement puisse être facilement extensible.
Le code des transformateurs est placé dans un fichier séparé, ci-dessous, nous décrirons quelques détails.
Décimation
Pour une raison quelconque, dans certains articles et exemples de traitement, j'ai rencontré une diminution de la fréquence du signal en jetant simplement des échantillons dans le style eeg = eeg[:, ::10] . C'est complètement incorrect (pourquoi - voir n'importe quel livre sur le traitement du signal). Nous utilisons l' scipy standard scipy .
Filtrage
Ici, nous nous appuyons également sur des filtres scipy en sélectionnant un filtre passe-bande Butterworth de 4 ordres et en l'appliquant dans le sens avant et arrière ( filtfilt ) pour maintenir la phase. Fréquences de coupure - de 0,5 à 20 Hz, c'est la plage standard pour notre tâche.
Mise à l'échelle
Nous avons utilisé un StandardScaler par canal (soustrait la moyenne, divise par l'écart-type), qui voit tous les signaux de l'échantillon. En fait, une petite fuite de données est introduite à ce stade. formellement, le scaler voit également les données de l'échantillon de test, mais avec des volumes de données suffisamment importants, la moyenne et l'écart sont les mêmes.
La masturbation est effectuée canal par canal afin qu'au sein d'un même ensemble de données, il soit possible d'agréger les données de différents capteurs ayant des ordres de grandeur et de nature différents (par exemple, réaction galvanique cutanée (RAG) )
En plus des opérations ci-dessus, il était également possible de distinguer des artefacts dans l'EEG (clignotement, mouvements de mastication, mouvements de tête), mais cet ensemble de données est déjà très propre, alors laissons-le jusqu'à la prochaine fois.
reload(transformers) decimation_factor = 10 final_rate = sampling_rate // decimation_factor epoch_duration = 0.9
Ensuite, nous appliquerons le pipeline de prétraitement à nos données et couperons le signal EEG continu en époques. Nous appellerons l'époque la période de temps immédiatement après l'activation du stimulus avec une durée caractéristique de 0,5 à 1 seconde, dans notre cas, la durée est de 900 ms, bien qu'elle puisse être raccourcie.
Dans notre ensemble de données, il y a 16 canaux EEG, après application de la décimation, la fréquence tombera à 50 Hz, donc une époque sera décrite par une matrice (16, 45) - 900 ms à 50 Hz correspondent à 45 échantillons de temps.
Les balises de cet ensemble de données ne sont que des binaires - elles marquent les signaux cible (masqués par le joueur, actifs, 1) et non cibles (vides, 0).
for eegs, _ in raw_dataset: eeg_pipe.fit(eegs) dataset = [] for eegs, markers in raw_dataset: epochs = [] labels = [] filtered = eeg_pipe.transform(eegs) markups = markers_pipe.transform(markers) for signal, markup in zip(filtered, markups): epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]]) labels.extend(markup[:, 1]) dataset.append((np.array(epochs), np.array(labels)))
dataset[0][0].shape, dataset[0][1].shape
Nous avons donc obtenu un Pytorch de Pytorch style Pytorch dans lequel le premier indice compte différentes personnes. Avec une telle structure, nous pouvons à la fois effectuer une validation croisée dans les données d'une personne et tester la tolérance du classificateur entre différentes personnes (ce que l'on appelle l'apprentissage par transfert, la prédiction sans calibration). Les données d'une personne se composent d'un tableau d'époques et d'étiquettes de classe. Le nombre d'époques pour chaque personne varie légèrement en raison des caractéristiques de l'enregistrement.
Recherche et visualisation de données
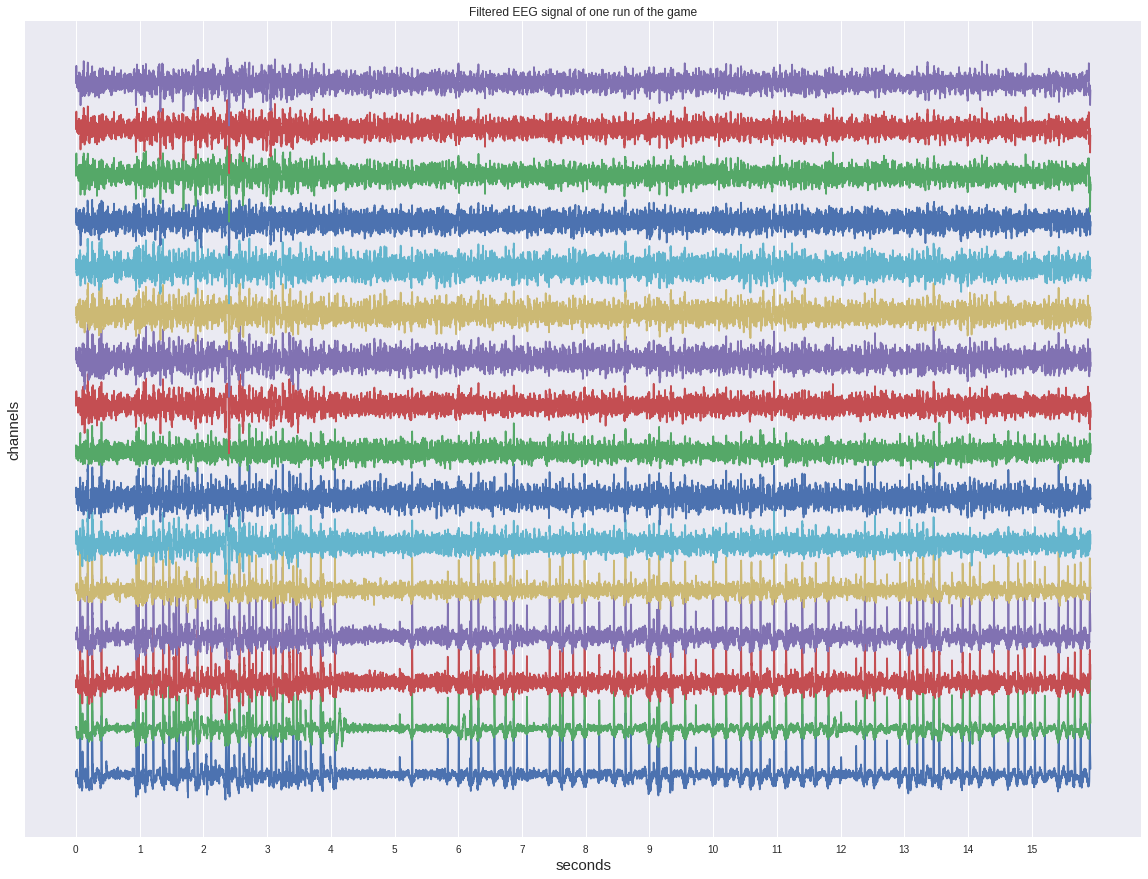
Tout d'abord, jetez un œil à l'un des signaux continus avant de découper les époques.
Malgré le fait qu'il ait déjà été filtré, il ne montre aucune activation sur l'œil et ressemble plus à une sorte de bruit.
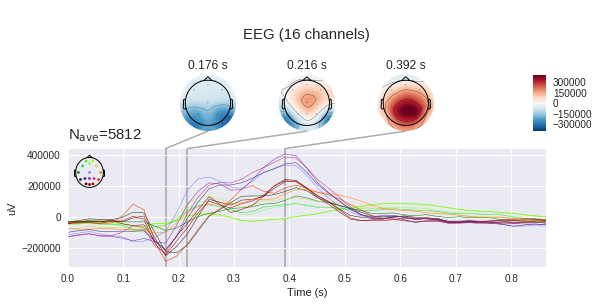
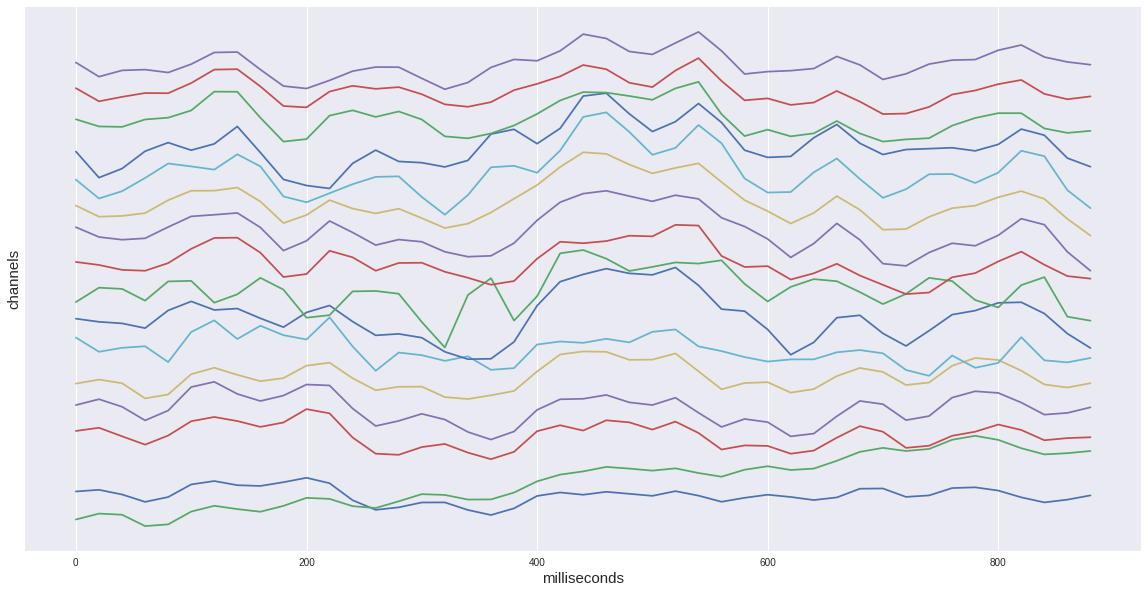
Si nous considérons une seule époque cible de notre ensemble de données, nous verrons alors une augmentation caractéristique de l'intervalle 400-600 ms. C'est notre potentiel recherché P300.
Au total, dans notre ensemble de données, il y a environ 35 000 époques, c'est-à-dire l'activation du stimulus. Chaque personne en a environ 1300 à 1750 (cela est dû au fait que quelqu'un a abattu des extraterrestres plus rapidement et plus lentement).
Il existe également un déséquilibre notable dans les classes: 1 à 5 en faveur des stimuli vides. nous avons 6 lignes et colonnes dans la matrice et une seule d'entre elles est la cible. Plus tard, nous y reviendrons lorsque nous discuterons des mesures obtenues.
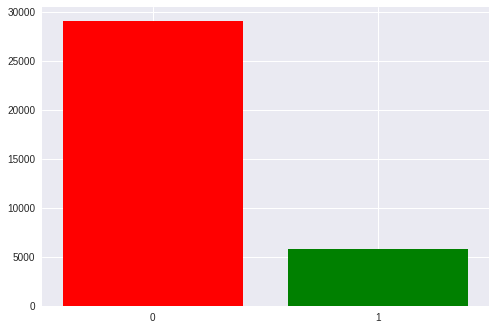
Il est maintenant temps de regarder la différence entre le signal cible et le non cible
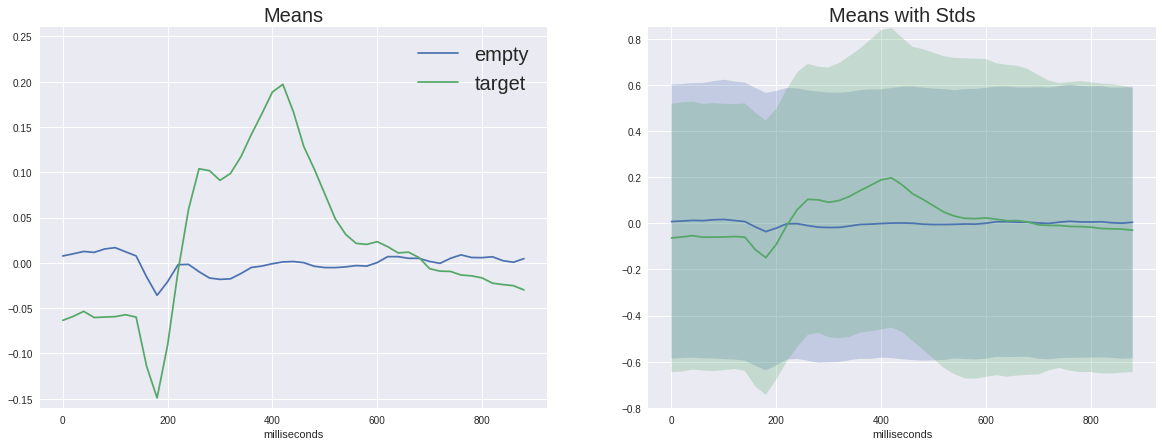
Sur le graphique de gauche, vous pouvez voir que les signaux moyens varient beaucoup, et les deux ont une réponse non spécifique dans la région de 180 ms, mais celle cible est beaucoup plus d'amplitude, la cible a également une bosse caractéristique de 250 à 500 ms - c'est le fameux P300.
Avec une telle différence dans le signal, notre tâche peut sembler insignifiante, mais si nous ajoutons l'écart type à chaque point du graphique, nous verrons que l'image n'est pas si rose - le signal est assez bruyant. Et cela malgré le fait que le rapport signal / bruit pour le P300 est considéré comme l'un des plus élevés en neurophysiologie.
(En fait, ces graphiques ne sont pas construits assez honnêtement, car le signal vide est moyenné sur cinq fois plus d'échantillons différents, donc les écarts aléatoires sont supprimés davantage, mais comme nous pouvons le voir à partir de la dispersion du même ordre, cela n'aide pas trop)

Il est également utile de regarder les signaux moyens d'une personne.
Ici se trouve la remarque précédente sur la moyenne «malhonnête» - le signal vide est sensiblement plus d'amplitude qu'avec la moyenne sur tous. En outre, le pic de P300 chez une personne est plus élevé en raison d'une moyenne moindre.
Il est important de noter une autre caractéristique du signal d'une personne - il a une forme légèrement différente de celle généralisée. La variabilité interpersonnelle des réactions neurophysiologiques est assez élevée, on verra encore l'influence de ce facteur dans le travail des classificateurs. Cependant, les différences intrapersonnelles (une personne d'humeur différente, niveau de stress, fatigue) sont également assez importantes.

Ensuite, nous voyons le balayage canal par canal des signaux. Le point de vue ici coïncide avec l'image ci-dessus, qui représente la position des électrodes - nez au-dessus, etc.
La réponse de chaque partie de la tête est différente. À Fp1,2, deux pics négatifs précédant le pic positif sont prononcés. De plus, dans certains canaux, il y a deux pics positifs et dans certains - un ou quelque chose de transition entre les deux.
Différents canaux ont une importance différente pour déterminer la présence de P300, elle peut être estimée en utilisant différentes méthodes - en calculant des informations mutuelles ou en ajoutant-supprimant (aka régression pas à pas). L'application de ces méthodes nous traiterons une autre fois.
Il convient de rappeler que nous mesurons la différence de potentiel entre les électrodes avec des électrodes, ce qui signifie que nous pouvons construire des cartes de tension pour la tête entière à certains moments dans le temps en utilisant des changements de tension à des points individuels. Il est clair que s'il y a 16 électrodes, la précision d'une telle carte laisse beaucoup à désirer, mais une certaine compréhension doit être acquise. (par défaut, mne s'attend à voir des microvolts, mais nous avons déjà appliqué une mise à l'échelle, donc les valeurs absolues ne sont pas correctes)

Classification
Enfin, il est temps d'appliquer des méthodes d'apprentissage automatique à notre échantillon.
Plusieurs éléments de base ont été choisis comme classificateurs - un journal. régression, la méthode des vecteurs de support (SVM) et plusieurs méthodes utilisant l'analyse de corrélation du package pyriemann (les détails de chaque méthode peuvent être trouvés dans la documentation), il convient de noter que ces méthodes ont été spécialement développées pour être appliquées à l'EEG et avec leur aide, plusieurs concours ont été remportés. kaggle.
clfs = { 'LR': ( make_pipeline(Vectorizer(), LogisticRegression()), {'logisticregression__C': np.exp(np.linspace(-4, 4, 9))}, ), 'LDA': ( make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'SVM': ( make_pipeline(Vectorizer(), SVC()), {'svc__C': np.exp(np.linspace(-4, 4, 9))}, ), 'CSP LDA': ( make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')), {'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')}, ), 'Xdawn LDA': ( make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'ERPCov TS LR': ( make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), 'ERPCov MDM': ( make_pipeline(ERPCovariances(), MDM()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), }

Le schéma d'interfaces neuronales le plus courant est "étalonnage + travail", c'est-à-dire Tout d'abord, il est nécessaire qu'une personne se concentre sur les stimuli précédemment indiqués pendant un certain temps, et seulement après cela, nous prédisons son choix. Cette approche présente l'inconvénient évident d'une étape initiale ennuyeuse.
Pour évaluer les performances de nos méthodes dans ce mode, nous procéderons à une validation croisée au sein des époques d'une seule personne.
La métrique de précision dans ce cas n'est pas pertinente en raison du déséquilibre de l'ensemble de données (la ligne de base est ici de 5/6 ~ 83%), donc je préfère regarder la précision-rappel-f1 trois.
Pour examiner l'intégralité de l'ensemble de données, nous faisons la moyenne des résultats d'une telle validation croisée entre toutes les personnes. En général, les performances des meilleurs modèles sont assez élevées par rapport à ce que nous avons chez Neiry dans les conditions "terrain" d'un parc d'attractions (je rappelle que cet ensemble de données a été enregistré en laboratoire).
Dans cet ensemble de données, il n'y a que des étiquettes binaires pour les données. En général, nous devons résoudre le problème multiclasse de choisir l'un des stimuli (soit dit en passant, il est équilibré puisque chaque stimulus est activé le même nombre de fois). Pour le résoudre, le nombre d'activations de chaque stimulus est généralement fixe (par exemple, 6 stimuli de 5 activations chacun) et tous les stimuli sont activés aléatoirement (30 fois), 30 époques sont obtenues et les probabilités de ses activations sont ajoutées pour être ciblées, après quoi le stimulus qui a atteint le maximum le montant est reconnu comme cible. Nous démontrerons la mise en œuvre de cette approche dans un prochain article sur un ensemble de données approprié.

Le deuxième schéma est appelé apprentissage par transfert, c'est-à-dire le transfert du classificateur entre les personnes. Le fait est que lorsque nous procédons à l'étalonnage, nous nous recyclons en fait à la forme maximale d'une personne, de sorte que nous pouvons bien le prédire dans les tests ultérieurs. En l'absence d'étalonnage, un classificateur pré-formé devrait être capable d'isoler le concept P300 sans connaître à l'avance la forme d'onde d'une personne en particulier.
Nous allons mener deux expériences - nous formerons le classificateur sur une personne et nous en prédirons cinq, puis nous augmenterons l'échantillon de formation à 10 personnes et comparerons les résultats pour nous assurer que les modèles ont pu augmenter leur capacité de généralisation
Formation pour 1 personne

Formation pour 10 personnes
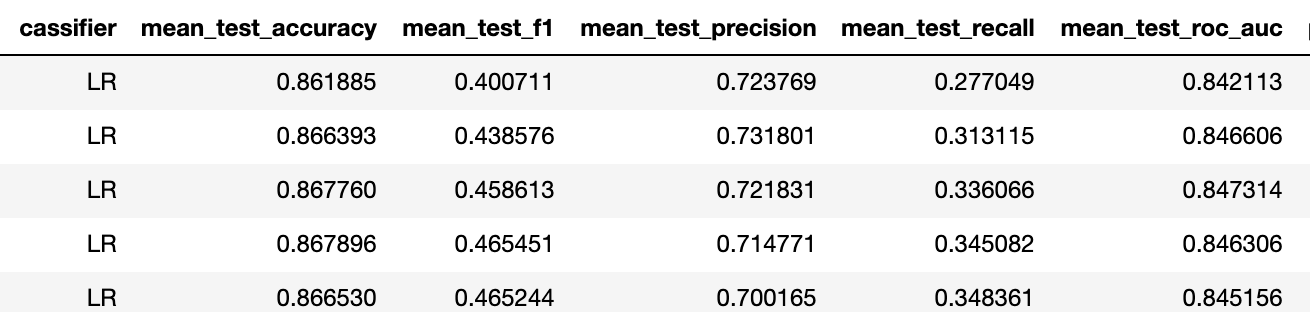
Donc f1 est passé de 0,23 à 0,4 pour un meilleur classifieur (dans les deux cas c'est une régression logarithmique avec la même régularisation).
Cela signifie que la capacité de prédiction est passée de «non» à «acceptable». D'après notre expérience, avec de telles métriques du problème binaire, 5 activations de chaque stimulus suffisent pour atteindre la précision du problème multiclasse d'environ 75%.
En fin de compte, je tiens à noter que la méthode ci-dessus est assez primitive, ce qui peut être vu, par exemple, à partir du haut degré de régularisation de la régression logarithmique - les canaux dans les données sont assez fortement corrélés et il existe plusieurs approches pour résoudre cette circonstance.
Conclusion
Aujourd'hui, nous nous sommes familiarisés avec le potentiel évoqué du P300 et avons construit un pipeline simple pour l'interface neuronale. Je recommande aux personnes intéressées d'ouvrir un ordinateur portable par elles-mêmes (situé dans le référentiel ) et d'expérimenter avec des options de visualisation et des classificateurs.
Ayant une compréhension de base des méthodes de travail avec le signal EEG, nous serons en mesure d'approfondir ce sujet plus en profondeur - d'appliquer des méthodes de prétraitement avancées, ainsi que des réseaux de neurones, pour résoudre les problèmes de construction d'interfaces neuronales. À suivre ...