Au cours des dernières années, j'ai conçu et fabriqué une machine capable de reconnaître et de trier les pièces LEGO. La partie la plus importante de la machine est l'
unité de capture , un petit compartiment presque entièrement clos dans lequel se trouvent un tapis roulant, un éclairage et une caméra.
L'éclairage que vous verrez un peu plus bas.La caméra prend des photos des pièces LEGO passant par le convoyeur, puis transfère les images sans fil à un serveur qui exécute un algorithme d'intelligence artificielle pour reconnaître la pièce parmi des milliers d'éléments LEGO possibles. Je vais vous en dire plus sur l'algorithme d'IA dans de futurs articles, et cet article se concentrera sur le traitement qui se produit entre la sortie brute de la caméra vidéo et l'entrée sur le réseau neuronal.
Le principal problème que je devais résoudre était de convertir le flux vidéo du convoyeur en images distinctes de parties qu'un réseau neuronal pouvait utiliser.
Le but ultime: passer d'une vidéo brute (à gauche) à un ensemble d'images de même taille (à droite) pour les transférer sur un réseau neuronal. (par rapport au travail réel, le gif est environ la moitié du temps)Il s'agit d'un excellent exemple d'une tâche qui à première vue semble simple, mais qui pose en réalité de nombreux obstacles uniques et intéressants, dont beaucoup sont propres aux plates-formes de vision industrielle.
La récupération des bonnes parties d'une image de cette manière est souvent appelée détection d'objet. C’est exactement ce que je dois faire: reconnaître la présence d’objets, leur emplacement et leur taille, afin de pouvoir générer des
rectangles de délimitation pour chaque pièce sur chaque cadre.
La chose la plus importante est de trouver de bonnes boîtes de délimitation (indiquées ci-dessus en vert)J'examinerai trois aspects de la résolution du problème:
- Se préparer à éliminer les variables inutiles
- Création d'un processus à partir d'opérations de vision industrielle simples
- Maintenir des performances suffisantes sur une plate-forme Raspberry Pi avec des ressources limitées
Élimination des variables inutiles
Dans le cas de telles tâches, il est préférable d'éliminer autant de variables que possible avant d'utiliser des techniques de vision industrielle. Par exemple, je ne devrais pas me soucier des conditions environnementales, des différentes positions de la caméra, de la perte d'informations due au chevauchement de certaines parties par d'autres. Bien sûr, il est possible (bien que très difficile) de résoudre toutes ces variables par programme, mais heureusement pour moi, cette machine est créée à partir de zéro. Je peux moi-même préparer une solution réussie, en éliminant toutes les interférences avant même de commencer à écrire du code.
La première étape consiste à fixer fermement la position, l'angle et la mise au point de la caméra. Avec cela, tout est simple - dans le système, la caméra est montée au-dessus du convoyeur. Je n'ai pas besoin de m'inquiéter des interférences d'autres parties; les objets indésirables n'ont presque aucune chance d'entrer dans l'unité de capture. Un peu plus compliqué, mais il est très important d'assurer
des conditions d'éclairage constantes . Je n'ai pas besoin de l'outil de reconnaissance d'objets pour interpréter par erreur l'ombre d'une partie mobile le long de la bande comme un objet physique. Heureusement, l'unité de capture est très petite (tout le champ de vision de la caméra est plus petit qu'une miche de pain), donc j'avais plus que suffisamment de contrôle sur les conditions environnantes.
Unité de capture, vue intérieure. La caméra se trouve dans le tiers supérieur du cadre.Une solution consiste à rendre le compartiment entièrement fermé afin qu'aucun éclairage extérieur n'entre. J'ai essayé cette approche en utilisant des bandes LED comme source d'éclairage. Malheureusement, le système s'est avéré être de mauvaise humeur - un seul petit trou dans le boîtier suffit et la lumière pénètre dans le compartiment, ce qui rend impossible de reconnaître les objets.
Au final, la meilleure solution a été de «colmater» toutes les autres sources lumineuses en remplissant le petit compartiment d'une forte lumière. Il s'est avéré que les sources lumineuses qui peuvent être utilisées pour éclairer des locaux résidentiels sont très bon marché et faciles à utiliser.
Obtenez les ombres!Lorsque la source est dirigée dans le minuscule compartiment, elle obstrue complètement toute interférence lumineuse externe potentielle. Un tel système a également un effet secondaire pratique: en raison de la grande quantité de lumière dans l'appareil photo, vous pouvez utiliser une vitesse d'obturation très élevée, obtenant des images parfaitement nettes des pièces même lorsque vous vous déplacez rapidement le long du convoyeur.
Reconnaissance d'objets
Comment ai-je réussi à transformer cette belle vidéo avec un éclairage uniforme dans les boîtes englobantes dont j'avais besoin? Si vous travaillez avec l'IA, vous pourriez suggérer que j'implémente un réseau de neurones pour la reconnaissance d'objets comme
YOLO ou
Faster R-CNN . Ces réseaux de neurones peuvent facilement faire face à la tâche. Malheureusement, j'exécute du code de reconnaissance d'objet sur
Raspberry pi . Même un ordinateur puissant aurait des problèmes pour exécuter ces réseaux de neurones convolutifs à la fréquence dont j'avais besoin d'environ 90FPS. Et Raspberry pi, qui n'a pas de GPU compatible avec l'IA, ne pouvait pas faire face à une version très allégée de l'un de ces algorithmes d'IA. Je peux diffuser de la vidéo de Pi vers un autre ordinateur, mais la transmission vidéo en temps réel est un processus très changeant, et les retards et les limitations de bande passante causent de graves problèmes, surtout lorsque vous avez besoin d'une vitesse de transfert de données élevée.
YOLO est très cool! Mais je n'ai pas besoin de toutes ses fonctions.Heureusement, j'ai pu éviter une solution basée sur l'IA difficile en utilisant les techniques de vision industrielle «à l'ancienne». La première technique est la
soustraction d'arrière -
plan , qui essaie d'isoler toutes les parties modifiées de l'image. Dans mon cas, la seule chose qui bouge dans le champ de vision de la caméra, ce sont les détails LEGO. (Bien sûr, la bande se déplace également, mais comme elle a une couleur uniforme, elle semble immobile par rapport à la caméra). Séparez ces détails LEGO de l'arrière-plan et la moitié du problème est résolu.
Pour que la soustraction d'arrière-plan fonctionne, les objets de premier plan doivent être sensiblement différents de l'arrière-plan. Les détails LEGO ont une large gamme de couleurs, j'ai donc dû choisir la couleur d'arrière-plan très soigneusement afin qu'elle soit aussi éloignée que possible des couleurs LEGO. C'est pourquoi le ruban sous la caméra est en papier - non seulement il doit être très homogène, mais il ne doit pas non plus être composé de LEGO, sinon il aura la couleur d'une des pièces que je dois reconnaître! J'ai choisi le rose pâle, mais toute autre couleur pastel, contrairement aux couleurs LEGO ordinaires, fera l'affaire.
La merveilleuse bibliothèque OpenCV possède déjà plusieurs algorithmes de soustraction d'arrière-plan. MOG2 Background Subtractor est le plus complexe d'entre eux, et en même temps, il fonctionne incroyablement rapidement même sur framboise pi. Cependant, l'alimentation directe des images vidéo en MOG2 ne fonctionne pas très bien. Les chiffres gris clair et blanc sont trop proches de la luminosité d'un fond pâle et s'y perdent. J'avais besoin de trouver un moyen de séparer plus clairement la bande des parties qu'elle contient, en ordonnant au soustracteur d'arrière-plan de regarder de plus près la
couleur et non la
luminosité . Pour ce faire, il me suffisait d'augmenter la saturation des images avant de les transférer sur un soustracteur de fond. Les résultats se sont considérablement améliorés.
Après avoir soustrait l'arrière-plan, je devais utiliser des opérations morphologiques pour éliminer le plus de bruit possible. Pour trouver les contours des zones blanches, vous pouvez utiliser la fonction findContours () de la bibliothèque OpenCV. En appliquant diverses heuristiques pour dévier les boucles contenant du bruit, vous pouvez facilement convertir ces boucles en boîtes englobantes prédéfinies.
Performances
Un réseau de neurones est une créature vorace. Pour de meilleurs résultats dans le classement, elle a besoin d'images de résolution maximale et en aussi grande quantité que possible. Cela signifie que je dois les photographier à une fréquence d'images très élevée, tout en conservant la qualité et la résolution de l'image. Je dois tirer le maximum possible de la caméra et du GPU Raspberry PI.
Une
documentation très détaillée
pour picamera indique que la puce de la caméra V2 peut produire des images de 1280x720 pixels avec une fréquence maximale de 90 images par seconde. Il s'agit d'une quantité incroyable de données, et bien que l'appareil photo puisse les générer, cela ne signifie pas qu'un ordinateur peut les gérer. Si je devais traiter des images RVB 24 bits brutes, je devrais transférer des données à une vitesse d'environ 237 Mo / s, ce qui est trop pour le mauvais GPU de l'ordinateur Pi et la SDRAM. Même lors de l'utilisation de la compression accélérée GPU en JPEG, 90 ips ne peuvent pas être atteints.
Le Raspberry Pi est capable d'afficher des images YUV brutes et non filtrées. Bien qu'il soit plus difficile de travailler qu'avec RVB, YUV a en fait de nombreuses propriétés pratiques. Le plus important d'entre eux est qu'il ne stocke que 12 bits par pixel (pour RVB c'est 24 bits).
Tous les quatre octets de Y ont un octet U et un octet V, c'est-à-dire 1,5 octet par pixel.Cela signifie que par rapport aux images RVB, je peux traiter
deux fois plus d' images YUV, sans compter le temps supplémentaire que le GPU économise lors de la conversion en image RVB.
Cependant, cette approche impose des restrictions uniques sur le processus de traitement. La plupart des opérations avec une image vidéo de taille réelle consomment une très grande quantité de mémoire et de ressources CPU. Dans mes limites de temps strictes, il n'est même pas possible de décoder une image YUV en plein écran.
Heureusement, je n'ai pas besoin de traiter tout le cadre! Pour la reconnaissance d'objets, les rectangles de délimitation n'ont pas besoin d'être précis, une précision approximative est suffisante, de sorte que l'ensemble du processus de reconnaissance d'objets peut être effectué avec un cadre beaucoup plus petit. L'opération de zoom arrière n'est pas nécessaire pour prendre en compte tous les pixels d'un cadre de taille normale, de sorte que les cadres peuvent être réduits très rapidement et sans frais. Ensuite, l'échelle des rectangles de délimitation résultants augmente à nouveau et est utilisée pour couper des objets à partir d'un cadre YUV de taille normale. Grâce à cela, je n'ai pas besoin de décoder ou de traiter autrement l'ensemble du cadre haute résolution.
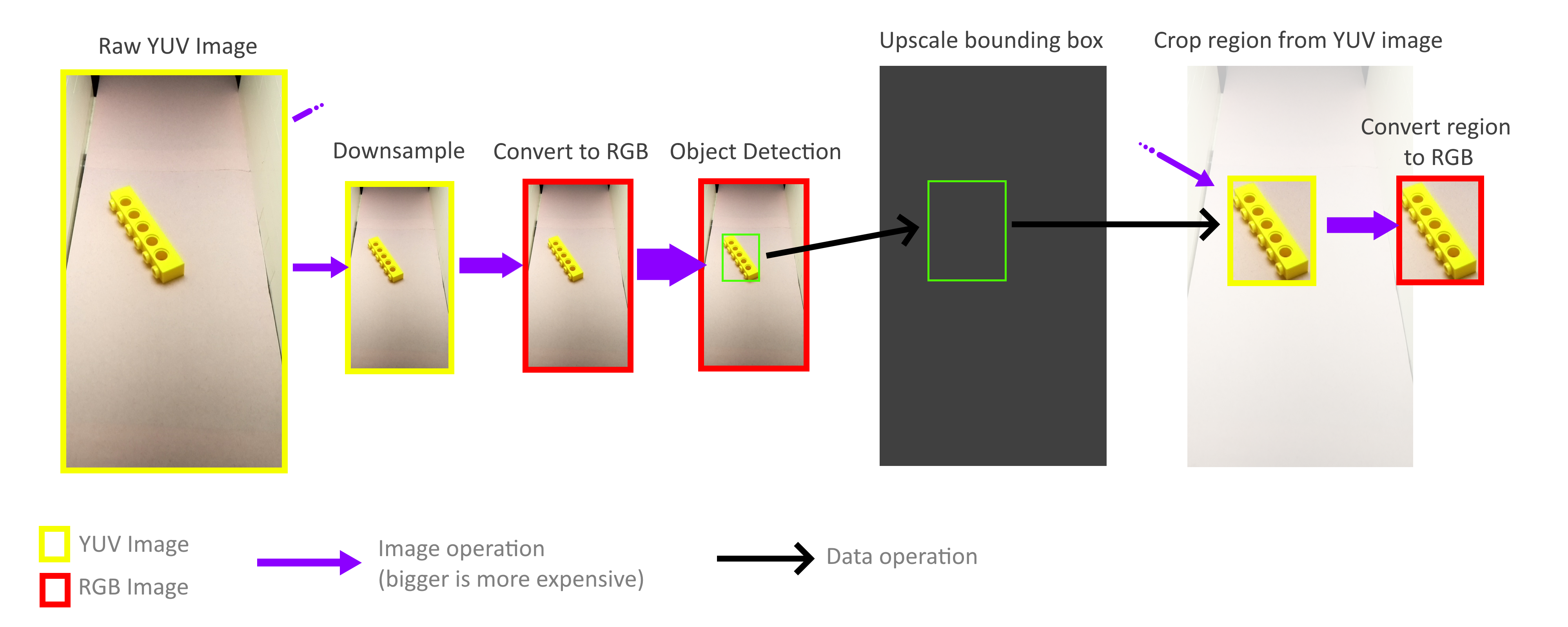
Heureusement, grâce à la méthode de stockage de ce format YUV (voir ci-dessus), il est très facile d'implémenter des opérations de recadrage et de zoom rapides qui fonctionnent directement avec le format YUV. De plus, l'ensemble du processus peut être parallélisé à quatre cœurs Pi sans aucun problème. Cependant, j'ai découvert que tous les cœurs ne sont pas utilisés à leur plein potentiel, ce qui nous indique que la bande passante mémoire est toujours le goulot d'étranglement. Mais même ainsi, j'ai réussi à atteindre 70-80FPS dans la pratique. Une analyse plus approfondie de l'utilisation de la mémoire pourrait accélérer encore plus les choses.
Si vous voulez en savoir plus sur le projet, lisez mon article précédent,
"Comment j'ai créé plus de 100 mille images LEGO pour l'apprentissage .
"Vidéo du fonctionnement de l'ensemble de la machine de tri: