Je vais continuer une analyse sans hâte de l'implémentation des types de base en CPython, les
dictionnaires et les
entiers ont été précédemment considérés. Ceux qui pensent qu'il ne peut y avoir rien d'intéressant et de rusé dans leur mise en œuvre sont encouragés à rejoindre ces articles. Ceux qui les ont déjà lus savent que CPython possède de nombreuses fonctionnalités intéressantes et des fonctionnalités d'implémentation. Ils peuvent être utiles à connaître lors de l'écriture de vos propres scripts, ou comme guide de solutions architecturales et algorithmiques. Les cordes ne font pas exception ici.
Commençons par une courte digression dans l'histoire. Python est apparu en 1990-91. Initialement, lors du développement du codage de base en python, il y avait un bon vieil ascii à un octet. Mais, à peu près au même moment (un peu plus tard), l'humanité en avait assez de s'occuper du «zoo» des encodages, et en 1991 la norme Unicode a été proposée. Cependant, la première fois aussi, cela n'a pas fonctionné. L'introduction des codages à deux octets a commencé, mais très vite, il est devenu clair que deux octets ne suffiraient pas à tout le monde, un codage à 4 octets a été proposé. Malheureusement, l'allocation de 4 octets pour chaque caractère semblait être une perte d'espace disque et de mémoire, en particulier dans les pays où un ascii à un octet était suffisant auparavant. Plusieurs béquilles ont été sciées dans un codage de 2 octets pour prendre en charge plus de caractères, et tout cela a commencé à ressembler à la situation précédente avec le «zoo» des codages.
Mais en 1993, utf-8 a été introduit. Ce qui était un compromis: ascii était un sous-ensemble valide d'utf-8, tous les autres caractères l'ont développé, cependant, pour supporter cette possibilité, j'ai dû me séparer d'une longueur fixe de chaque caractère. Mais c'est lui qui était destiné à
gouverner tout le monde pour devenir exactement Unicode, c'est-à-dire un codage unique pris en charge par la plupart des programmes dans lesquels la plupart des fichiers sont stockés. Cela a été particulièrement influencé par le développement d'Internet, car les pages Web n'utilisaient généralement que utf-8.
La prise en charge de cet encodage a été progressivement introduite dans des langages de programmation qui, comme python, ont été développés avant utf-8, et ont donc utilisé d'autres encodages. Il y a
PEP avec un joli numéro 100 qui a discuté du support Unicode. Et dans
PEP-0263, il est devenu possible de déclarer l'encodage des fichiers source. Ascii était toujours le codage de base, le préfixe «u» était utilisé pour déclarer les chaînes unicode, travailler avec elles n'était toujours pas pratique et assez naturel. Mais il y avait une opportunité de créer l'hérésie suivante:
class 비빔밥: _ = 2 א = 비빔밥() print(א)
Le 3 décembre 2008, un événement historique a eu lieu pour l'ensemble de la communauté python (et compte tenu de l'étendue de ce langage maintenant, alors peut-être pour le monde entier) - python 3 a été publié. Il a été décidé de mettre fin définitivement aux problèmes à cause de de nombreux encodages, et donc Unicode est devenu l'encodage de base. Mais nous nous souvenons que l'encodage est compliqué et ne fonctionne pas la première fois. Cela n'a pas fonctionné cette fois non plus.
Le gros inconvénient de utf-8 est que la longueur du caractère n'est pas fixe, ce qui conduit au fait qu'une opération aussi simple que d'accéder à l'index a une complexité O (N), puisque le décalage de l'élément n'est pas connu à l'avance, en outre, connaissant la taille du tampon, alloué pour stocker une chaîne, vous ne pouvez pas calculer sa longueur en caractères.
Afin d'éviter tous ces problèmes en python, il a été décidé d'utiliser des encodages à 2 et 4 octets (selon la plateforme). La gestion des index a été simplifiée - il a seulement fallu multiplier l'index par 2 ou 4. Cependant, cela posait ses problèmes:
- Chaque plate-forme avait son propre encodage, ce qui pouvait entraîner des problèmes de portabilité du code
- Augmentation de la consommation de mémoire et / ou des problèmes d'encodage pour les caractères délicats qui ne tiennent pas sur deux octets
Une solution à ces problèmes a été proposée dans le
PEP-393 , et nous en parlerons.
Il a été décidé de laisser les lignes sous forme de tableau de caractères, pour faciliter l'accès par index et autres opérations, cependant, la longueur des caractères a commencé à varier. Lors de la création d'une chaîne, l'interpréteur analyse tous les caractères et alloue pour chacun le nombre d'octets nécessaires pour stocker la "plus grande", c'est-à-dire que si vous déclarez une chaîne ascii, tous les caractères seront à un octet, cependant, si vous décidez d'ajouter un caractère à la chaîne en cyrillique, tous les caractères auront déjà deux octets. Il existe trois options possibles: 1, 2 et 4 octets par caractère.
Le type de chaîne (PyUnicodeObject) est déclaré
comme suit :
typedef struct { PyCompactUnicodeObject _base; union { void *any; Py_UCS1 *latin1; Py_UCS2 *ucs2; Py_UCS4 *ucs4; } data; } PyUnicodeObject;
À son tour, PyCompactUnicodeObject représente la
structure suivante (fournie avec quelques simplifications et mes commentaires):
typedef struct { PyASCIIObject _base; Py_ssize_t utf8_length; char *utf8; Py_ssize_t wstr_length; } PyCompactUnicodeObject; typedef struct { PyObject_HEAD Py_ssize_t length; Py_hash_t hash; struct { unsigned int interned:2; unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24; } state; wchar_t *wstr; } PyASCIIObject;
Ainsi 4 représentations linéaires sont possibles:
- chaîne héritée, prête
* structure = PyUnicodeObject structure * : !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 data.any utf8_length = length ascii = 1 * utf8_length = 0 utf8 is NULL * wstr with data.any wstr_length = length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 wstr is NULL
- chaîne héritée, pas prête
* structure = PyUnicodeObject * : kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0
- ascii compact
* structure = PyASCIIObject * : PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — utf8 wstr ) * (data ) * ( ascii utf8 string data)
- compact
* structure = PyCompactUnicodeObject * : PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 data * utf8_length = 0 utf8 is NULL * wstr data wstr_length=length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 wstr is NULL * (data )
Il convient de noter que python 3 prend également en charge la syntaxe de déclaration des chaînes unicode via le préfixe `u`.
>>> b = u"" >>> b ''
Cette fonctionnalité a été ajoutée pour faciliter le portage du code de la deuxième version à la troisième dans
PEP-414 en python 3.3 uniquement en février 2012, permettez-moi de vous rappeler que python 3 a été publié en décembre 2008, mais personne n'était pressé par la transition.
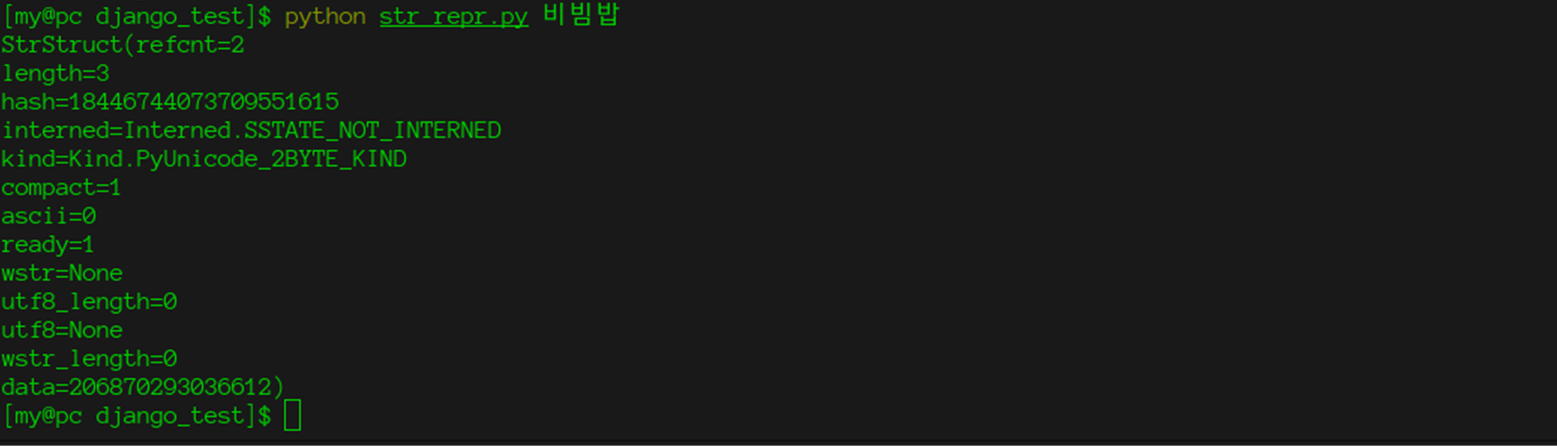
Armés de ces connaissances et du module ctypes standard, nous pouvons accéder aux champs internes de la chaîne.
import ctypes import enum import sys class Interned(enum.Enum):
Et même "casser" l'interprète, comme vous l'avez fait dans la
partie précédente .
AVERTISSEMENT: Le code suivant est fourni tel quel, l'auteur n'assume aucune responsabilité et ne peut garantir l'état de l'interprète, ainsi que la santé mentale de vous et de vos collègues, après avoir exécuté ce code. Le code est testé sur cpython version 3.7 et, malheureusement, ne fonctionne pas avec les chaînes ascii.
Pour ce faire, modifiez le code décrit ci-dessus pour:
def make_some_magic(str1, str2): s1 = StrStruct.from_address(id(str1)) s2 = StrStruct.from_address(id(str2)) s2.data = s1.data if __name__ == '__main__': string = "비빔밥" string2 = "háč" print(string == string2)
Ces exemples utilisent l'interpolation de chaînes ajoutée en
python 3.6 . Python n'est pas immédiatement arrivé à cette méthode de sortie des chaînes: la syntaxe%, le format, quelque chose
comme perl ont été essayés (une description plus détaillée avec des exemples peut être trouvée
ici ).
Ce changement pour l'époque (avant python 3.8 avec son opérateur `: =`) était peut-être le plus controversé. La discussion (et la condamnation) s'est déroulée à la fois sur
reddit et même sous forme de
PEP . Des idées d'amélioration / correction ont été exprimées sous la forme de l'ajout
de lignes i pour lesquelles les utilisateurs pourraient écrire leurs analyseurs, pour un meilleur contrôle et pour éviter les injections SQL et autres problèmes. Cependant, ce changement a été reporté, afin que les gens s'habituent aux lignes f et identifient les problèmes, le cas échéant.
Les lignes F ont une particularité (inconvénient): vous ne pouvez pas spécifier de caractères spéciaux avec des barres obliques, par exemple, '\ n' '\ t'. Cependant, cela peut être facilement contourné en déclarant une ligne séparée contenant des caractères spéciaux et en la passant à la ligne f, ce qui a été fait dans l'exemple ci-dessus, mais vous pouvez utiliser des crochets imbriqués.
>>> number = 2 >>> precision = 3 >>> f"{number:.{precision}f}" 2.000
Comme vous pouvez le voir, les chaînes stockent leur hachage; il a été
suggéré d' utiliser cette valeur pour comparer les chaînes, sur la base d'une règle simple: si les chaînes sont les mêmes, alors elles ont le même hachage, et il s'ensuit que les chaînes avec des hachages différents ne sont pas les mêmes. Cependant, il est resté insatisfait.
Lors de la comparaison de deux chaînes, il est vérifié si les pointeurs vers les chaînes se réfèrent à la même adresse, sinon, une comparaison caractère par caractère ou memcmp est lancée dans les cas où cela est valide.
int PyUnicode_Compare(PyObject *left, PyObject *right) { if (PyUnicode_Check(left) && PyUnicode_Check(right)) { if (PyUnicode_READY(left) == -1 || PyUnicode_READY(right) == -1) return -1; if (left == right) return 0; return unicode_compare(left, right);
Cependant, la valeur de hachage affecte indirectement la comparaison. Le fait est qu'en cpython, les chaînes sont internées, c'est-à-dire stockées dans un seul dictionnaire. Cela n'est pas vrai pour toutes les lignes; toutes les constantes, clés de dictionnaire, champs et variables, et les lignes ascii d'une longueur inférieure à 20 sont internées.
if __name__ == '__main__': string = sys.argv[1] string2 = sys.argv[2] print(id(string) == id(string2))
$ python check_interned.py aa True $ python check_interned.py 비빔밥 비빔밥 False $ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa False
Et la chaîne vide est généralement singleton
static PyUnicodeObject * _PyUnicode_New(Py_ssize_t length) { PyUnicodeObject *unicode; size_t new_size; if (length == 0 && unicode_empty != NULL) { Py_INCREF(unicode_empty); return (PyUnicodeObject*)unicode_empty; } ... }
Comme nous pouvons le voir, cpython a été en mesure de créer une implémentation simple mais efficace du type chaîne. Il a été possible de réduire la mémoire utilisée et d'accélérer les opérations dans certains cas, grâce aux fonctions memcmp, memcpy, au lieu d'opérations caractère par caractère. Comme vous pouvez le voir, le type de chaîne n'est pas du tout aussi simple à implémenter que cela puisse paraître la première fois. Mais les développeurs de Cpython ont approché leur entreprise avec beaucoup de talent et nous pouvons donc l'utiliser et ne même pas penser à ce qui se cache sous le capot.