
Je me suis assis paisiblement lors d’un séminaire, j’ai écouté le rapport d’un étudiant sur un article du
CVPR précédent
, et j'ai consulté le sujet en même temps sur Google.
- Les avantages de l'article incluent la disponibilité du code source ....
J'ai dû intervenir:
- La présence de quoi, excusez-moi?
- Euh ... Code source ...
"L'avez-vous regardé?"
- Non, mais l'article dit ...
(mère-mère-mère ... fait écho habituellement)ㅡ Avez-vous suivi le lien?
L'article est en effet très encourageant: "Le code et le modèle sont accessibles au public sur la page du projet ... / imtqy.com / ...", cependant, dans le commit il y a deux ans, l'inspirant "Code et modèle sera bientôt présenté". :
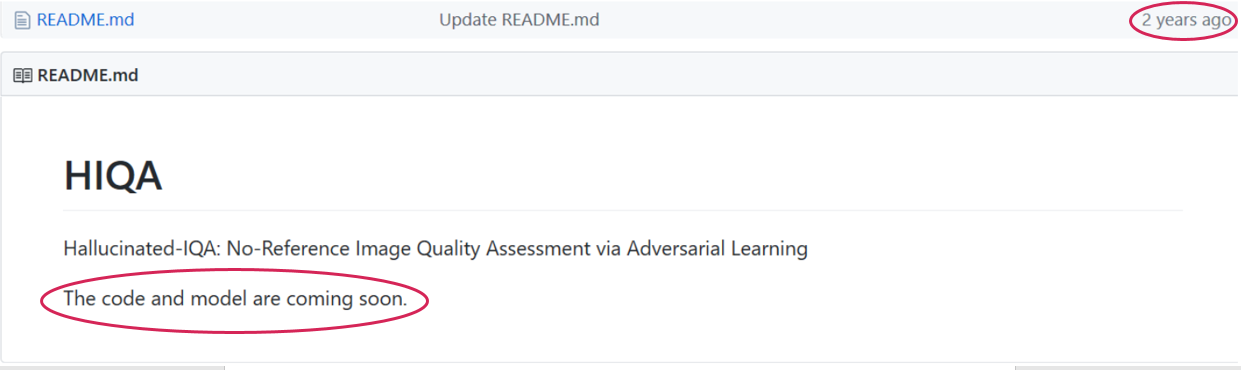
Rechercher et trouver, frapper et ouvrir ... Peut-être ... Ou peut-être pas. Sur la base de ma triste expérience, je le mettrais sur le second, car la situation s'est répétée dernièrement, oh, oh, très souvent. Même sur CVPR. Et ce n'est qu'une partie du problème! Les sources peuvent être disponibles, mais, par exemple, uniquement un modèle, sans scripts de formation. Et il peut y avoir des scripts d'apprentissage, mais pendant plusieurs mois avec des lettres aux auteurs, il est impossible d'obtenir le même résultat. Ou, pendant un an sur un autre ensemble de données avec des appels Skype réguliers, un auteur aux États-Unis n'est pas en mesure de reproduire son résultat, obtenu dans le laboratoire le plus célèbre de l'industrie sur ce sujet ... Une sorte de Tryndets.
Et, apparemment, jusqu'à présent, nous ne voyons que des fleurs. Dans un avenir proche, la situation va se détériorer de façon spectaculaire.
Peu importe
ce qui est arrivé à l'étudiant où se dirige le monde scientifique, y compris par la «faute» de l'apprentissage en profondeur, bienvenue au chat!
Crise de reproductibilité
EN 2016,
Y A-T-IL UNE CRISE DE REPRODUCTIBILITÉ? (Y a-t-il une crise de reproductibilité maintenant)? , qui a cité les résultats d'une enquête auprès de 1576 chercheurs:
 Source: Ce graphique et les graphiques suivants de cette section sont un article de Nature.
Source: Ce graphique et les graphiques suivants de cette section sont un article de Nature.Selon les résultats de l'enquête, 52% des chercheurs pensent qu'il existe une crise importante, 38% - une crise bénigne (90% au total au total!), 3% - qu'il n'y a pas de crise et 7% - n'ont pas été déterminés.
La version conspiratrice de l'auteur - compte tenu de l'ampleur de la catastrophe, ces derniers ne veulent tout simplement pas attirer l'attention "excessive" sur la question:

Si vous regardez les disciplines, il s'avère que la chimie est en premier lieu, la biologie en deuxième et la physique en troisième:
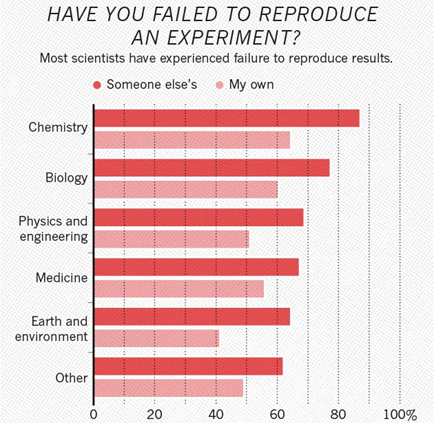
Fait intéressant, en chimie, par exemple, plus de 60% des chercheurs ont trouvé impossible de reproduire leurs propres recherches. En physique, ce sont également plus de 50%.
Il est également très intéressant de savoir
ce qui, du point de vue des chercheurs, apporte la plus grande contribution à la crise d'irréproductibilité:

En premier lieu, le «reporting sélectif». Pour l'informatique, il s'agit d'une situation où l'auteur, par exemple, sélectionne les meilleurs exemples de publication sur lesquels l'algorithme fonctionne et ne décrit pas en détail où et ce qui ne fonctionne pas.
Fait intéressant, le second est «Pression pour publier». Il s'agit d'un principe très connu de «publier ou périr».
Un article sur Wikipédia en anglais décrit bien le problème. Il n'y a pas d'article dans Wikipédia russe à ce sujet, bien que dans les endroits où le travail scientifique est très rémunéré, le problème devient pertinent. Par exemple, dans une université supérieure avec un bon salaire (hélas, je ne parle pas de mon Université d'État de Moscou natale), des scores de publication élevés sont essentiels pour la recertification, et si vous souhaitez continuer à travailler, veuillez publier. Une carcasse, un épouvantail, peu importe, mais pour que les points soient.
A noter également que «Méthodes, code indisponible» est courant dans 45% des cas, et parfois dans 82%. Eh bien, la fraude directe comme raison est indiquée dans 40% des cas, c'est-à-dire assez souvent. J'ai récemment parlé avec un professeur chinois travaillant dans le domaine des algorithmes de compression vidéo. Il a dit qu'à l'intérieur de la Chine, il y a beaucoup d'articles avec une fraude consciente, ils sont juste devenus un fléau. Les publications étrangères frauduleuses y sont rapidement rejetées, alors elles essaient de s'y conformer, mais un cauchemar se crée à l'intérieur (voir par exemple l'article
«Publier ou périr en Chine» dans Nature). Un cauchemar, y compris pour la raison suivante sur la liste des «examens par les pairs insuffisants» - il n'y a pas assez de force pour un examen croisé de haute qualité.
Un gros problème distinct, que je ne mentionnerai que brièvement: si le résultat n'a pas pu être reproduit, alors un article à ce sujet est presque impossible à publier ...

Tout le monde est intéressé par les nouvelles réalisations, les nouvelles contributions et les nouvelles idées, et ce qui est ancien ne fonctionne pas - quelle différence cela fait-il. Cela augmente naturellement la part des résultats non reproductibles, y compris la fraude délibérée. Très probablement, personne ne comprendra, ce n'est pas accepté. Il est évident que lorsque d'autres commencent à être basés sur un seul faux résultat, l'ensemble du système devient instable, ce qui affecte finalement tout le monde:
 Vos paris
Vos paris - avez le
temps de l'esquiver ou de l'écraser?Total:
- Selon une enquête auprès de 1 576 chercheurs publiée dans Nature, 52% pensent qu'il existe désormais une crise de reproductibilité importante, et 90% conviennent qu'il existe une telle crise.
- De plus, la situation actuelle est toujours florissante et bientôt tout va empirer, surtout en informatique. Pourquoi? Découvrez maintenant.
Reproductibilité en informatique
À l'Arizona State University (qui, soit dit en passant, est 2 fois plus grande que l'Université d'État de Moscou en termes de nombre d'étudiants), un site spécial
http://repeatability.cs.arizona.edu/ a été créé au département du programmeur dédié à l'étude de la reproductibilité de leurs résultats dans 601 articles de revues et conférences
ACM . Le résultat a été l'image suivante:

 Source: Répétabilité en informatique
Source: Répétabilité en informatiqueIls n'ont pas vérifié 106 articles parce qu'ils ne voulaient pas violer la pureté de l'expérience (ils ont écrit aux auteurs et demandé le code), dans les autres:
- dans 93 articles (19%) il n'y a pas de code, ou il y avait du matériel avec lequel ils ne pouvaient pas être comparés,
- dans 176 articles (35%), les auteurs n'ont pas fourni de code,
- dans 226 articles (46%) le code était, dans 9 (2%) il n'était pas possible de le collecter, et dans 87 (64 + 23) articles (18%) il a fallu plus d'une demi-heure pour résoudre les problèmes d'assemblage du projet (dans 23 cas les problèmes ont été éliminés a échoué, mais l'auteur a assuré que «faire plus d'efforts» tout aurait rassemblé).
Je dois dire que dans notre expérience après l'assemblée, le plus intéressant ne fait que commencer, mais dans l'étude, ils ont décidé de s'arrêter à ce stade, et avec tant d'entre eux, vous pouvez comprendre. En tout état de cause, les statistiques sont très révélatrices et 35% des refus de fournir le code sont assez proches de la ligne «Méthodes, code indisponible» de l'étude précédente (troisième graphique).
En général, le sujet est assez bien déterré. En particulier, le «Gold Standard» est la disponibilité de code et de données sur lesquelles il est facile de répéter complètement le résultat, et la pire approche est la soumission d'articles uniquement:
 Source: conceptualisation, mesure et étude de la reproductibilité
Source: conceptualisation, mesure et étude de la reproductibilitéPourquoi cela se produit-il?
Il y a plusieurs raisons, comme tout phénomène complexe:
- En Occident, la mention «Publier ou périr» est très influente. Lors de séminaires et d'ateliers, les jeunes étudiants diplômés verts sont complètement guidés avec sérieux et sans équivoque - «Une idée est venue, commencez par la publier! Et alors seulement, vérifiez! »(Qui a dit de la sauvagerie? Une dure réalité, messieurs!) La priorité en science est vraiment importante (y compris pour la citation notoire), donc quand une idée intéressante arrive, elle est publiée en premier (parfois avec de fausses données) , parfois non) et seulement alors ils commencent à programmer quelque chose pendant longtemps douloureusement, tirant souvent un hibou sur le globe. L'article cité comme premier exemple au début de ce texte ne semble être qu'un de ceux-ci (réseaux neuronaux hallucinogènes ... Je me demande ce qu'ils ont fumé? Mais c'est venu au CVPR!). Le résultat est un animal à fourrure blanche en surpoids, alors que la situation continue de se détériorer:

- Conventionnellement, l'État donne la moitié de l'argent de la recherche (quelque part de plus, quelque part de moins). Et l'argent du gouvernement provoque la folie de la publication (une fois publié, juste pour publier). L'autre moitié de l'argent provient des entreprises, et les entreprises parlent clairement de restrictions de publication. Une entreprise coréenne populaire, qui a proposé à des scientifiques russes de travailler, selon l'expression appropriée d'un collègue, «pour des perles» était surtout connue pour ses conditions
nègres pour les instituts et les universités. Oui, maintenant, ils ont même brisé le marché dans le domaine des réseaux de neurones dans la course aux salaires, mais en général, la première chose à offrir un contrat terrible est l'identité d'entreprise de ces entreprises asiatiques. Et quand un article bien écrit n'est pas autorisé à être publié, puis un autre, et plus encore - cela démotive fortement, bien sûr. Cela même après quelques années n'est pas oublié.
En conséquence, le résultat va aux brevets avec un minimum d'articles. Il est intéressant que j'ai parlé avec des collègues de Finlande, des États-Unis, de France, etc. Là-bas, beaucoup de gens s'assoient étroitement sur les subventions, mais ceux qui ont de nombreuses entreprises ne publient pas tous les résultats, et s'ils publient, ils réduisent en quelque sorte (culturellement parlant) la description de l'approche, ce qui complique naturellement la reproduction. Car cela a déjà été payé.
Total:
- Même après des demandes urgentes, le code est envoyé dans un maximum de 46% des cas (à propos, lisez l' étude , il existe des exemples intéressants d '"excuses", selon notre expérience, exactement celles-ci sont essentiellement envoyées).
- Le système de financement de la science lui-même motive la publication des résultats non vérifiés le plus rapidement possible ou limite les publications, y compris en termes de divulgation complète. Dans les deux cas, la reproductibilité diminue.
Pourquoi l'apprentissage automatique aggrave les choses
Mais ce n'est pas tout! Récemment, l'apprentissage automatique en général et les réseaux de neurones en particulier se sont rapidement répandus. C'est génial. Cela fonctionne très bien. L'hier complètement impossible devient possible aujourd'hui! Juste une sorte de vacances! Alors?
Non. Les réseaux de neurones ont ajouté à l'informatique un nouveau cycle d'immersion dans l'abîme de l'irréproductibilité.
Voici un exemple simple: il ressemble à la fonction de perte pour
ResNet-56 sans passer les connexions (visualisation de quelques paramètres de plusieurs dizaines de millions). Notre tâche pour un nombre raisonnable d'itérations (ères) est de trouver le point le plus profond:
 Source: Visualisation du paysage de perte des réseaux neuronaux
Source: Visualisation du paysage de perte des réseaux neuronauxVous pouvez clairement voir la mer des minima locaux, dans laquelle notre descente de gradient "tombe joyeusement" et "ne peut pas" sortir de là. Oui, il est clair que c'est pour ResNet que cet exemple est utilisé comme une excellente illustration, qui est fournie par des
connexions de saut (après l'introduction de laquelle l'apprentissage en réseau est considérablement amélioré):
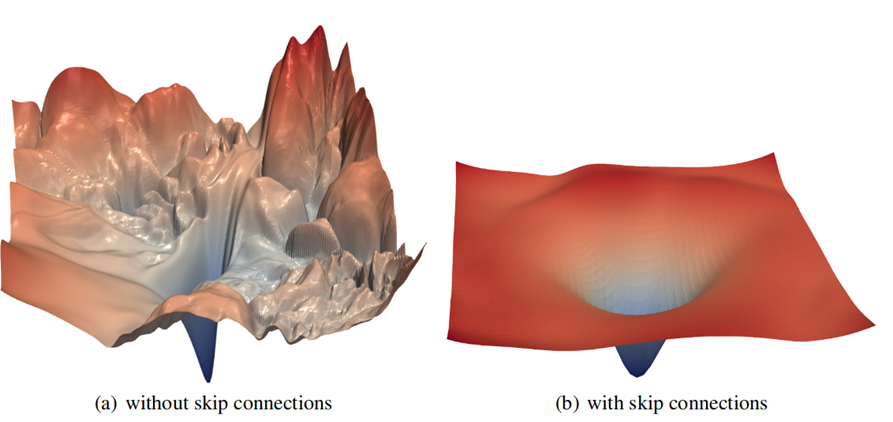
Car c'est une chose que d'essayer de trouver un minimum dans un paysage complexe (et seule la dimension globale prohibitive de l'espace de recherche aide), et c'est tout autre chose de voir un minimum global qui est relativement relativement facile à trouver avec des gradients.
L'histoire est belle, mais dans notre dure réalité avec un grand nombre de couches encore et encore, nous devons faire face au fait que le réseau n'apprend pas. Généralement.
Et encore plus intéressant - à un moment donné, il est possible de le former (l'erreur diminue fortement), mais après un certain temps, lorsque vous essayez de reproduire le résultat à partir de zéro (par exemple, lorsque ces coefficients sont perdus), il n'est pas possible de répéter la mise au point, et il y a un parcours douloureux évident du réseau dans la distance d'un minimum. Des centaines d'
époques se succèdent et le chariot reste en place. La fleur de pierre ne sort pas de Danila le maître.
Il était assez difficile d'imaginer une situation où un chercheur ne pourrait pas reproduire ses propres résultats en informatique. Aujourd'hui, il est devenu monnaie courante, comme il l'a été depuis longtemps en physique, chimie, biologie et plus loin sur la liste.
Avec les réseaux de neurones, l'informatique est soudainement devenue une science expérimentale! Bienvenue dans ce monde merveilleux. Désormais, vous serez de plus en plus confronté à l'incapacité de reproduire votre
propre résultat (comme 64% des chimistes, 60% des biologistes, voir le deuxième graphique de cet article).
Mais ce ne sont pas toutes des joies. Plus sera plus amusant!
En général, pendant un certain temps, j'étais assez sceptique sur les réseaux de neurones, car les algorithmes basés sur eux ne fonctionnaient pas. Eh bien ... Ils ont en quelque sorte fonctionné, bien sûr, mais ont perdu de gros échantillons au profit des algorithmes de pointe "classiques" (ce qui ne les a pas empêchés d'être publiés en masse). Cela est arrivé parce que les réseaux de neurones sont extrêmement pratiques pour toutes sortes de fraudes. L'essentiel est de sélectionner correctement un exemple de formation pour des exemples et vous pouvez naturellement démontrer des miracles. Il s'avère de belles photos (et parfois de beaux graphismes), et l'article se passe bien. Vous pouvez même disposer le code (il semble être devenu à la mode), cela ne change pas l'essence. Ça ne marche pas. Mais quand le gros coq rouge
PoP- avec un énorme bec pointu se profile derrière ... l'article est une figue-figue et va imprimer.

Un autre problème majeur concerne les domaines où il n'y a pas de gros échantillons de formation. Des collègues de la médecine se plaignent - un cauchemar complet se produit. Ils collectent des ensembles de données depuis des années. Et il y a même des dizaines de milliers d'exemples. Mais les étudiants diplômés avec des réseaux de neurones profonds arrivent. Figak-figak et a dépassé tout le monde ... Beau! Les géants de la science! Et avec des visages brillants et heureux rapporter les résultats. On leur demande:
- Qu'avez-vous fait pour éviter le sur-ajustement?
- Pourquoi, désolé?
- Pourquoi n'avez-vous pas de recyclage?
Et un homme raconte très sérieusement comment il a pris le bon réseau et l'a formé strictement selon le manuel de formation, et donc tout va bien pour lui. C'est-à-dire les jeunes (massivement!) ne comprennent pas ce qu'est la reconversion! Pas un, pas deux, mais juste une part notable des rapports de troisième cycle. La voici, une nouvelle vague de jeunes révolutionnaires du réseau neuronal. Nous nous souvenons du
professeur Preobrazhensky , nous soupirons fortement à propos de l'analphabétisme traditionnel des jeunes révolutionnaires. Nous tirons des conclusions.
Mais ça va. Lors du récent
SITI 2019, Mikhail Belyaev a donné de merveilleux exemples de la façon dont cette approche se rend assez bien dans la production médicale! Dans de vraies entreprises proposant des analyses utilisant des réseaux de neurones, ils ont réussi des tests de contrôle et ont reçu des résultats étonnamment tristes. La raison en est que les investisseurs ont également senti une révolution, et si une personne promet de nouveaux horizons basés sur des réseaux de neurones, alors ils lui donnent de l'argent (Anatoly Levenchuk perspicace en a
averti dès 2015, six mois après l'invention de l'
indice de référence et six mois avant ResNet, lorsque de nombreuses couches sont encore mal formées). Et payez-vous, chers messieurs! Et, oui, il serait préférable d'expérimenter avec des souris d'abord, mais les souris, comme l'a dit un cynique familier, n'ont pas de portefeuille! Par conséquent, les données pour la formation sont désormais collectées (exprimées culturellement) avec l'argent des consommateurs, c'est-à-dire sur votre argent. Les gens, soyez vigilants!
Il est clair que ce ne sont pas les réseaux de neurones qui sont à blâmer. La grande question est de savoir comment obtenir une quantité suffisante de données adjacentes, les
ajuster sur un petit échantillon, éviter l’
oubli catastrophique, et c’est tout. Mais, même si vous avez des chercheurs compétents, cela prendra du temps. Et l'investisseur veut un résultat
ici et hier . Alors, réjoui de la vague de succès des réseaux de neurones?
Nous obtenons une grande
mousse d'une grosse
vague , lorsque des méthodes inopérantes ont en fait entraîné le surf des grosses vagues à une utilisation réelle. Payez la facture, s'il vous plaît!
Total: Les réseaux de neurones aggravent la situation en informatique dans trois domaines:
- Avec la formation de réseaux de neurones, CS de l'ancien devient une science expérimentale avec tous les inconvénients qui en découlent.
- L'ajustement de l'échantillon de formation à celui de test vous permet de démontrer tout résultat arbitrairement merveilleux (exacerbant la principale raison de l'irréproductibilité - le rapport sélectif).
- Et, enfin, dans les zones où les échantillons d'apprentissage sont petits, il est extrêmement difficile d'éviter de se recycler, que beaucoup ne savent pas comment attraper et travailler (officiellement, le résultat est excellent sur l'ensemble de données, mais en fait l'algorithme ne fonctionne pas).
Que peut-on faire?
Si vous (une personne heureuse!) Travaillez dans des zones bien creusées, souvent tout le travail consiste à préparer des ensembles de données et à les alimenter en réseaux. A moins que cela ne vaut la peine de regarder les architectures. Dans ce cas, cela n'a aucun sens de regarder des articles sans code. Et ce sont de vraies vacances! Ressentez votre bonheur, tout le monde n'a pas autant de chance!
Il existe même un tel site,
PapersWithCode.com , qui dans le domaine de l'apprentissage automatique recueille volontairement des articles, analyse automatiquement la note de leurs référentiels depuis GitHub, répertorie tout par catégorie et ajoute des repères et des ensembles de données. En général - tout est pour les gens! Soit dit en passant, selon leurs calculs, le code n'est désormais disponible que pour 17 à 19% des articles:
 Source: Pourcentage d'articles publiés qui ont au moins une implémentation de code
Source: Pourcentage d'articles publiés qui ont au moins une implémentation de codeMais eux, si nous sommes distraits pendant une seconde (et que nous continuons de faire la publicité de ces bons gars), il y a un calendrier très intéressant pour changer la popularité des frameworks ML / DL au cours des 4 dernières années:
 Source: mises en œuvre papier regroupées par cadre
Source: mises en œuvre papier regroupées par cadreTorche à cheval, TF (qui aurait pensé récemment!) Perd du terrain. Cependant, c'est une autre histoire ...
Par expérience, il est clair que ces 17 à 20% d'articles avec du code aussi (pour les raisons décrites) tout n'est pas magique, mais au moins vous pouvez vérifier leur travail un ordre de grandeur plus rapidement. Et c'est génial.
Une autre recette vraiment efficace est la création d'ensembles de données et de repères assez volumineux. L'essor des réseaux de neurones a commencé en vain avec
ImageNet avec 14 millions d'images, réparties en plus de 20 000 classes. Oui, c'est difficile, mais avec un apprentissage approfondi, vous ne pouvez travailler qu'avec de
très grands ensembles. Même si leur création est douloureuse et difficile.
Par exemple, il y a quelque temps, nous avons créé une
référence pour mettre en évidence des objets translucides dans une vidéo (laine, cheveux, tissus, fumée et autres joies de la vie non triviales). Initialement, il était prévu de le conserver lors de sa création dans 3 mois. Des servocommandes ont été trouvées, un écran, un bon appareil photo
, un ruban électrique bleu a été acheté , un million de peluches ont été réquisitionnées de toutes les filles qu'elles connaissaient, un mannequin avec de vrais cheveux a été trouvé sur lequel les coiffeurs forment les coiffeurs. Et ...
 Source: matériaux de l'auteur ... Le ruban électrique bleu, comme on peut le voir clairement, joue un rôle de soutien clé
Source: matériaux de l'auteur ... Le ruban électrique bleu, comme on peut le voir clairement, joue un rôle de soutien cléTout (non, pas si ... TOUT!) S'est mal passé. , ( ), ( ), ( , ). .. ..
( ), , . , ! , - , , .
— . , . , , , (. ,
25 Kaggle).
:
, , , … . , , ,
.
, , .
Replication crisis ( , , ) , — , :
 : The Reproducibility Crisis in Psychological Science: One Year Later , , , , , … , Computer Science ...
: The Reproducibility Crisis in Psychological Science: One Year Later , , , , , … , Computer Science ...! 20 ,
Computer Science , (
), - . — , .

Et le dernier. , . , . !
!Lisez aussi:
The replication crisis Science for Sale: The Other Problem With Corporate Money .
, :
- . .. ,
- , , , , ,
- , , ,
- , , , , , , , , , , !