D'un traducteur : pendant mon travail à la fintech nigériane, j'ai dû créer un système de paiement à partir de zéro. À cette époque, je ne comprenais vraiment rien à la comptabilité, à la meilleure façon de stocker les paiements et les soldes. Mais on soupçonnait que l'option primitive avec un chiffre de solde dans le compte de l'utilisateur était trop simple pour être correcte.
Cet article m'a aidé à comprendre et à éviter un tas de râteaux dans cette affaire. Dans le même temps, les informations sur le thème "comment créer son propre système de paiement" sont assez petites, et il n'est pas si facile pour un programmeur de comprendre des livres sur la comptabilité (et très fastidieux). J'espère que ce matériel sera utile à ceux qui vont simplement faire quelque chose comme ça.
Je m'excuse immédiatement pour d'éventuelles inexactitudes en termes financiers russophones - je suis toujours programmeur, pas comptable, et je ne connais pas la terminologie russe dans ce domaine.
Présentation
De nombreux systèmes informatiques qui utilisent des bases de données relationnelles stockent une sorte d'informations financières sur les soldes et les transactions. De plus, la conception et le développement d'une telle base de données soulève souvent la question de savoir comment stocker ces informations. Habituellement, le choix est entre un «enregistrement simple» bon marché et un «enregistrement double» plus complexe.

Luca Pacioli, auteur du plus ancien livre (XVe siècle) survivant décrivant les principes de la double entrée
Dans un système «d'enregistrement simple», les valeurs numériques ne sont enregistrées qu'une seule fois. Dans un système à double entrée, chaque valeur est enregistrée deux fois en crédit (valeur positive) et en débit (valeur négative). Il existe un ensemble de règles qui déterminent la relation entre ces valeurs. Ces règles vous seront facilement décrites par tout comptable expérimenté, bien qu'il ne puisse même pas imaginer comment elles peuvent être représentées dans une base de données relationnelle.
Les règles de base sont les suivantes:
- Chaque entrée du système doit être équilibrée, c'est-à-dire la somme de toutes les valeurs en une seule opération doit donner zéro.
- La somme de toutes les valeurs dans l'ensemble du système à un moment donné doit donner zéro (la règle de la "balance d'essai").
- Les valeurs déjà entrées dans la base de données ne peuvent pas être modifiées ou supprimées. Si des corrections sont nécessaires, l'opération doit d'abord être annulée par une autre opération avec le signe opposé, puis répétée avec la valeur correcte. Cela vous permet de mettre en place une piste d'audit fiable (un journal complet de toutes les transactions, souvent requis lors des inspections).
Applicabilité de la double comptabilité
Au début d'un projet, le faible prix d'un simple enregistrement est toujours tentant, et le coût de mise en œuvre et la complexité d'un double enregistrement à part entière semblent inutiles. Cependant, en réalité, l'utilisation d'un simple enregistrement est souvent une fausse économie.
Si les informations comptables du système informatique ne copient que les enregistrements papier existants stockés en dehors de la base de données en cours de développement, un simple enregistrement a toujours droit à la vie. Cependant, si au moins un des faits concernant le système ci-dessous est vrai, alors la double entrée doit être utilisée dès le début:
- Si jamais un audit comptable des informations est nécessaire
- Si les informations du système sont la seule source d'informations sur la propriété
- Si les informations concernent des objets de grande valeur
- Si le système devrait être sérieusement développé à l'avenir
Exemple de double entrée
L'idée clé de la double entrée est l'existence d'un compte spécial "livre de caisse" ( environ. Trad.: Je n'ai pas trouvé comment l'appeler correctement en russe, quelqu'un peut-il me le dire? ). Ce compte contient des enregistrements effectués lorsque des objets de valeur (tels que de l'argent) sont déposés ou retirés de notre système comptable. Ainsi, le solde actuel de ce compte reflète le nombre total de valeurs dans le système.
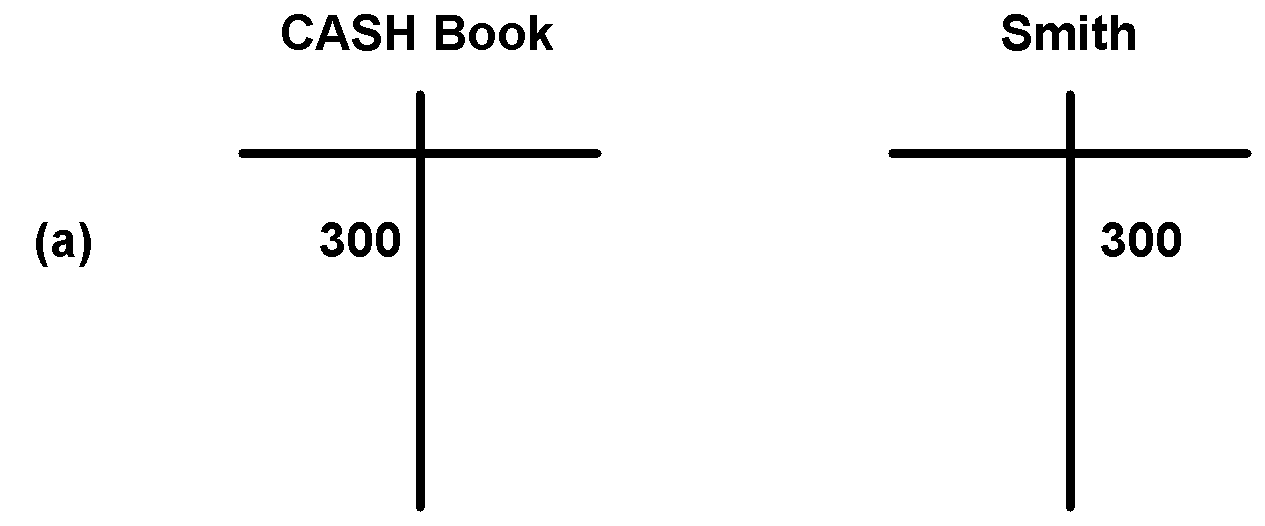
Voici un exemple simple avec deux comptes, "livre de caisse" et "Smith".
(a) 300 £ sont saisis dans le système et déposés sur le compte de Smith. Un prêt de 300 £ est créé sur le compte de Smith (crédit à droite, débit à gauche). Pour niveler ce montant, un débit de 300 £ est créé dans le compte de livre de caisse.
(b) Smith déduit ensuite 50 £ du système. Nous créons un débit pour ce montant dans le compte de Smith et un crédit dans le livre de caisse.
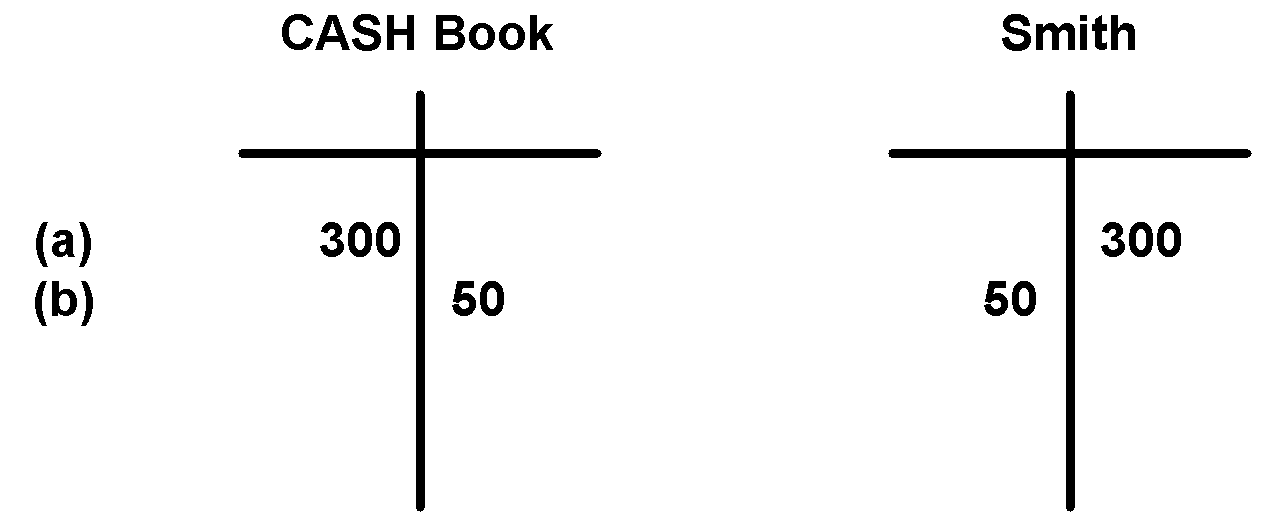
(c) Ajoutez un autre compte Pattel et transférez-lui 100 £ de Smith. Pour ce faire, nous devons créer un débit pour ce montant avec Smith et un prêt avec Pattel.
(d) Comme touche finale, laissez Pattel retirer maintenant 60 £ du système. Nous créons un débit dans son compte et un crédit dans le livre de caisse.
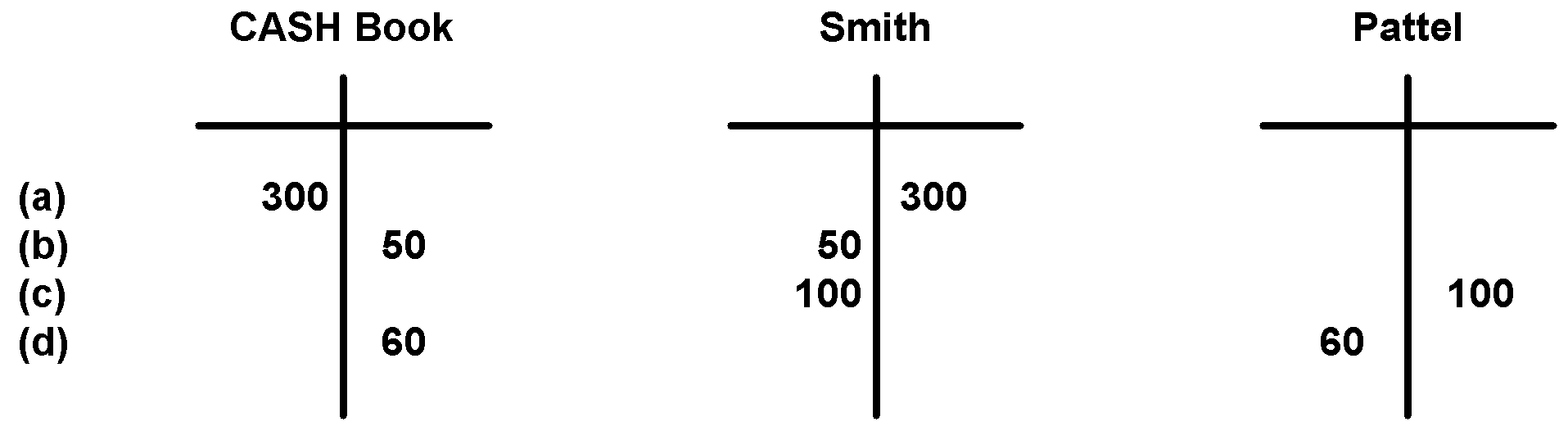
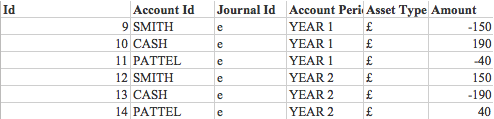
À la suite de toutes ces opérations, nous pouvons calculer que le solde total de Smith est de 150 £, Pattela 40 £ et dans le Cash Book -190 £, la somme négative des soldes de tous les autres comptes. Sur la base de ces règles et opérations simples à l'avenir, vous pouvez créer un système de contrôle de valeur très complet.
Modèle de données
La structure d'un modèle de données simple qui peut être utilisé pour représenter toutes ces informations:
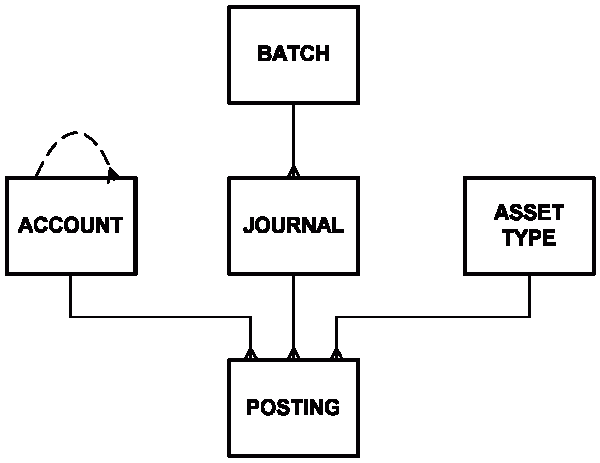
La table POSTING contient les doubles entrées elles-mêmes. Le stockage de tous les nombres dans une table simplifie considérablement tous les calculs. Un compteur à augmentation monotone doit être utilisé comme clé primaire. Les valeurs doivent aller dans une rangée, dans ce cas, par le nombre, vous pouvez toujours vous assurer qu'aucun enregistrement n'a été supprimé. Les tables BATCH et JOURNAL sont utilisées pour contrôler et saisir des données dans cette table POSTING.
Chaque entrée de la table JOURNAL représente une transaction (d'un point de vue commercial) qui génère des entrées doubles. Une telle transaction est une unité de travail terminée ou un processus opérationnel. Soit tous les enregistrements POSTING associés à l'enregistrement JOURNAL doivent être terminés avec succès, soit aucun d'entre eux. La somme de tous les enregistrements POSTING dans une même transaction doit être nulle. Chaque opération de transfert de l'exemple ci-dessus est représentée par son entrée dans la table JOURNAL
L'entrée dans la table BATCH est faite pour la commodité de la saisie des données. Il est utilisé pour regrouper les enregistrements JOURNAL dans des packages pratiques, par exemple, un ensemble de contrôles pour entrer dans le système, une sorte de processus commercial mondial, comme facturer des intérêts à tous les utilisateurs à la fois, etc.
La table ACCOUNT stocke des données sur les propriétaires de valeurs dans le système.
La table ASSET TYPE contient des informations sur les types de valeurs utilisées dans le système. En ajoutant un type de valeur à la clé primaire de la table POSTING, vous pouvez créer un système qui fonctionne sur plusieurs types de valeurs à la fois (par exemple, le traitement de plusieurs devises).
Voici à quoi pourrait ressembler une telle base de données pour l'exemple ci-dessus sous la forme la plus simplifiée:

Le solde de la colonne Montant dans le tableau AFFICHAGE est toujours nul après la fin de toute transaction de JOURNAL (le logiciel doit s'assurer qu'il n'y a aucun enregistrement de transactions incomplètes dans la base de données).
La somme des opérations pour le compte Cash Book donne -190, ce qui est égal à la somme des soldes de Smith et Pattel de signe opposé.
Pour démontrer le fonctionnement multi-devises, un nouveau type de valeur a été ajouté. Si Smith veut échanger 20 livres contre des dollars au taux de 1 pour 1,5, la transaction sera effectuée via le livre de caisse de cette manière:

Périodes de facturation
Le modèle que nous avons obtenu a l'air génial, mais en réalité, il cassera très rapidement sous une charge élevée car nous ne pouvons rien supprimer et sommes obligés de recompter constamment le nombre toujours croissant d'enregistrements dans POSTING.
La plupart des systèmes comptables ont le concept d'une période de facturation - généralement un mois, trois mois ou un an. Une telle période suggère des points pratiques pour diviser le flux de données. Habituellement, un point pratique est la fin de l'année, le calendrier ou les finances.
Nous pouvons ajouter une colonne avec un indicateur de période à la table POSTING et à sa clé primaire, divisant les données en groupes qui peuvent être traités indépendamment. Si dans l'exemple ci-dessus certains des enregistrements tombaient sur une nouvelle période de facturation, les soldes des comptes seraient reportés comme suit.
Premièrement, les soldes de la période précédente seraient apurés.

Et puis ils seraient transférés à une nouvelle période

Après un certain temps, tous les enregistrements de la période de l'année 1 peuvent être envoyés à l'archive et supprimés du système sans perdre son intégrité.
Agrégation de transactions
Certaines opérations du système comptable peuvent toucher plusieurs, voire tous les utilisateurs à la fois. Par exemple, les intérêts versés à tous les utilisateurs sous la forme d'une part de leur solde actuel.
Ces opérations peuvent être traitées dans le cadre d'une seule transaction dans la table JOURNAL et vous pouvez agréger toutes les opérations avec le livre de caisse dans un enregistrement commun dans la table POSTING (au lieu de créer une opération distincte pour chaque compte). Cela vous permettra de respecter toutes les règles comptables ci-dessus tout en réduisant de moitié le nombre d'enregistrements dans la base de données. En utilisant cette approche, la fin de l'année dans la base de données ressemblera à ceci:
Traitement par lots
Le traitement par lots est souvent utilisé pour simplifier la saisie des données dans le système comptable.
Historiquement, le traitement des chèques a fonctionné comme ceci. Le comptable a reçu un paquet de dix chèques, le numéro du paquet et le montant total de tous les chèques. Lors de la première étape, les chèques sont saisis dans le système sous la forme d'entrées "non autorisées". Dans ce cas, via la table BATCH, leur quantité et leur montant total sont vérifiés et ce n'est que s'ils correspondent à la valeur correcte que l'utilisateur est autorisé à valider le paquet. Après cela, le pack est envoyé à un autre employé qui en vérifie la validité puis «autorise» si tout est correctement saisi.
Ce processus est appelé "fabricant / vérificateur" et peut être utilisé pour entrer toutes les données pertinentes dans le système.
Dans ce cas, les enregistrements «non autorisés» dans une table distincte du jeu principal d'enregistrements doubles dans la table POSTING seront corrects. Vous pouvez également disposer d'un certain nombre de ces tables pour différents processus métier. Par exemple, dans le cas de chèques par lesquels de l'argent est entré ou retiré du système, le comptable n'aura besoin de vérifier qu'un seul compte. Depuis le second, Cash Book, dans de telles opérations est toujours implicite implicitement. Dans ce cas, dans la table CHECK, il sera possible de gérer une seule colonne avec le compte, tandis que dans la table hypothétique TRANSFERT DE FONDS, deux colonnes seront nécessaires: "expéditeur" et "destinataire".
C'est là que survient le malentendu fondamental des principes du double enregistrement. La plupart des gens dans la vie ordinaire ne rencontrent que de simples livres comptables papier. Dans un tel livre papier, par exemple, pour rendre compte des finances d'un certain club d'intérêt, vous n'avez besoin que d'une entrée pour chaque opération. Cependant, il a toujours une double entrée implicite, car il y a toujours un compte de livre de caisse implicite (dans ce cas, c'est le club), car tous les flux de trésorerie sont toujours soit des entrées (paiement des frais par les participants) soit des retraits d'argent du système (dépenses club).
La deuxième raison des idées fausses est que dans les relevés de compte personnels, l'argent déposé dans le compte sera considéré comme un «prêt», car une personne prête essentiellement à une banque qui reçoit son argent. Bien que si cette personne avait conservé son grand livre, cette inscription y aurait été enregistrée comme «débit» - puisque la banque doit cet argent à son client. Cet argent est retiré du "système de paiement" de l'utilisateur et entré dans le système bancaire.
Architecture logicielle
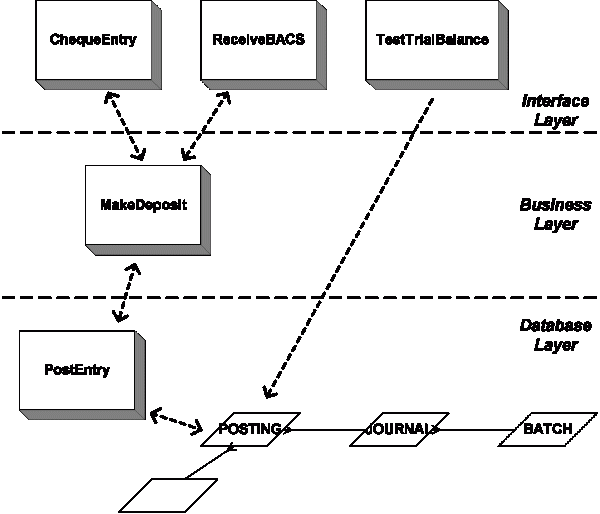
Il est préférable de développer un logiciel qui implémente un tel système de comptabilité à double entrée en utilisant la POO et une approche à plusieurs niveaux. Les niveaux sont les suivants:
- Interface externe
- Logique métier
- Travailler avec une base de données
Bien sûr, l'architecture du système dépendra de ce que ce système devrait faire exactement, cependant, nous pouvons supposer la présence des modules suivants:
PostEntry: un module qui contrôle la création de doubles entrées dans la table POSTING. Il est responsable de l'insertion des enregistrements, de l'attribution des identifiants et des horodatages. Le module ne peut pas supprimer ou modifier des enregistrements et aucun autre module ne doit supprimer ou modifier ces enregistrements, à l'exception de la suppression possible d'anciens enregistrements archivés pour des périodes de facturation déjà non pertinentes. La table POSTING doit être en lecture seule pour tous les autres modules.
MakeDeposit, MakeWithdrawal, MakeTransfer: ces modules implémentent la logique métier de base pour les opérations de transfert de fonds. Ils utiliseront le module PostEntry pour entrer leurs résultats dans la base de données.
ChequeEntry et ChequeAuthorisation, ReceiveBACS ( remarque: BACS est un système de paiement interbancaire ): ces modules connecteront le système au monde extérieur et fourniront une interface de haut niveau. Ils utiliseront les modules de la couche métier pour exécuter leurs fonctions. Dans ce cas, vous pouvez garantir le traitement correct quelle que soit la méthode de saisie des données, car ChequeEntry et ReceiveBACS fonctionneront via le même MakeDeposit
Cette méthodologie de séparation des couches peut être appliquée dans une plus ou moins large mesure, en fonction de la complexité du système et de la pureté souhaitée de l'utilisation des principes de conception d'objet. Dans le même temps, il peut être judicieux, par exemple, d'autoriser le module de génération de rapports (par exemple TestTrialBalance) à accéder directement à la base de données au niveau de l'interface - au lieu de créer des modules intermédiaires sur les couches métier et base de données.
Balance d'essai
"Balance de vérification" - le principal moyen de vérifier l'intégrité du système comptable. Si toutes les entrées ont été entrées dans le système selon les règles de double entrée et qu'il n'y a eu aucune erreur, la somme de toutes les entrées doit être nulle. La probabilité que plusieurs erreurs distinctes s'additionnent et donnent un total de zéro sur une base non valide est généralement si faible qu'elle est négligée.
La meilleure façon de vérifier est un mouvement constant du niveau supérieur vers le bas. Les contrôles ont un sens dans cet ordre:
- Somme de toutes les valeurs de la colonne POSTING.Amount
Si une erreur est trouvée (la valeur n'est pas nulle), alors: - Somme de toutes les valeurs POSTING.Amount, mais calculées séparément pour différents types de valeurs et de périodes de règlement
À ce stade, il devrait devenir plus clair dans quelle partie du système une erreur s'est produite. - Vérification des opérations individuelles dans la table JOURNAL. Étant donné que la somme de tous les POSTING.Account dans chaque transaction de la table JOURNAL doit également donner zéro, vous pouvez suivre la transaction problématique spécifique.
Types de publication JOURNAL
Le tableau JOURNAL contient une représentation simple d'entités, qui s'avèrent cependant souvent plus complexes et impliquées dans diverses relations.
Parfois, il est logique de diviser une table en plusieurs. Par exemple, sur MATERIALIZED et DEMATERIALIZED, qui peuvent avoir un ensemble différent de colonnes, par exemple, les entités matérielles peuvent exiger des données sur leur emplacement actuel.
Ou, dans un tableau, différents sous-types de valeurs, tels que des devises ou des titres, peuvent être stockés, chaque sous-type peut avoir son propre ensemble de propriétés et d'attributs.
Les entités ayant à la fois des sous-types et des supertypes peuvent être organisées dans la base de données de quatre manières (c'est une situation assez standard pour n'importe quelle base de données):
- Une grande table commune avec de nombreuses colonnes facultatives pour les attributs de sous-type
- Tableau séparé pour chaque sous-type, avec duplication de toutes les colonnes communes
- Entités distinctes afin que le supertype soit stocké dans une table distincte et se joint à d'autres tables contenant uniquement des colonnes spécifiques aux sous-types
- Identique à 3, mais avec duplication des colonnes de supertype dans les tables de sous-type
Chacune des quatre options a ses avantages et ses inconvénients. D'un point de vue à double entrée, il est utile d'avoir un tableau commun pour POSTER les entrées. L'option 1 est mieux adaptée à un système de comptabilité simple (comme dans les exemples de cet article, où la seule différence dans les types de valeurs est déterminée par la colonne JOURNAL.Type). L'option 3 est probablement mieux adaptée aux systèmes complexes qui fonctionnent avec une large gamme de valeurs très différentes.