 Quoi?
Quoi? Un codec vidéo est un logiciel / matériel qui compresse et / ou décompresse la vidéo numérique.
Pour quoi? Malgré certaines limitations en termes de bande passante,
et en termes d'espace de stockage, le marché a besoin de plus en plus de vidéo de haute qualité. Rappelez-vous comment dans le dernier article, nous avons calculé le minimum nécessaire pour 30 images par seconde, 24 bits par pixel, avec une résolution de 480x240? Reçu 82,944 Mbps sans compression. La compression est le seul moyen de transférer HD / FullHD / 4K vers les écrans de télévision et Internet. Comment y parvient-on? Nous allons maintenant examiner brièvement les principales méthodes.

La traduction a été réalisée avec le soutien d'EDISON Software.
Nous sommes engagés dans l' intégration de systèmes de vidéosurveillance , ainsi que dans le développement d'un microtomographe .
Codec vs Container
Une erreur courante pour les novices est de confondre un codec vidéo numérique et un conteneur vidéo numérique. Un conteneur est un certain format. Un wrapper contenant des métadonnées vidéo (et éventuellement audio). La vidéo compressée peut être considérée comme une charge utile de conteneur.
En règle générale, une extension de fichier vidéo indique un type de conteneur. Par exemple, le fichier video.mp4 est très probablement un
conteneur MPEG-4 Part 14 , et le fichier nommé video.mkv est très probablement une
poupée russe. Pour être totalement sûr du codec et du format de conteneur, vous pouvez utiliser
FFmpeg ou
MediaInfo .
Un peu d'histoire
Avant d'arriver à
Comment? , plongeons dans un peu d'histoire pour mieux comprendre certains anciens codecs.
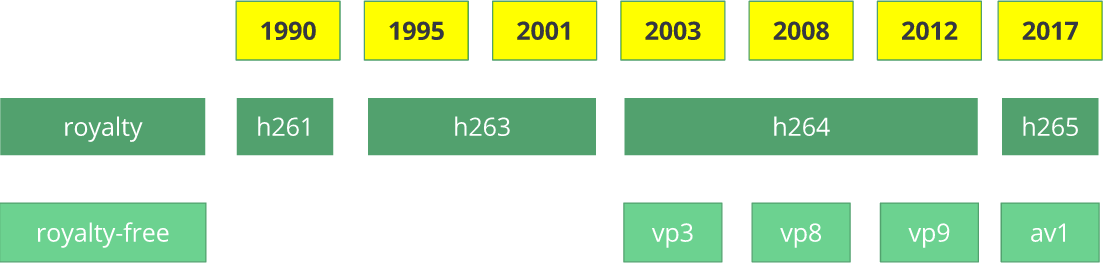
Le codec vidéo
H.261 est apparu en 1990 (techniquement - en 1988) et a été créé pour fonctionner avec un taux de transfert de données de 64 Kbps. Il a déjà utilisé des idées telles que le sous-échantillonnage des couleurs, les macroblocs, etc. En 1995, la norme de codec vidéo
H.263 a été publiée, qui s'est développée jusqu'en 2001.
En 2003, la première version de
H.264 / AVC a été achevée. La même année, TrueMotion a publié son codec vidéo gratuit qui compresse la vidéo avec perte appelée
VP3 . En 2008, Google a acheté cette société, libérant
VP8 la même année. En décembre 2012, Google a publié
VP9 , et il est pris en charge dans environ les ¾ du marché des navigateurs (y compris les appareils mobiles).
AV1 est un nouveau codec vidéo open source gratuit développé
par l'Open Media Alliance (
AOMedia ), qui comprend des sociétés bien connues telles que Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel et Cisco . La première version du codec 0.1.0 a été publiée le 7 avril 2016.
Naissance d'AV1
Début 2015, Google a travaillé sur
VP10 , Xiph (qui appartient à Mozilla) a travaillé sur
Daala , et Cisco a créé son codec vidéo gratuit appelé
Thor .
Ensuite,
MPEG LA a d' abord annoncé des limites annuelles pour
HEVC (
H.265 ) et des frais 8 fois plus élevés que pour H.264, mais ils ont bientôt changé les règles à nouveau:
pas de limite annuelle,
frais de contenu (0,5% du chiffre d'affaires) et
les coûts unitaires sont environ 10 fois plus élevés que pour le H.264.
L'Open Media Alliance a été créée par des entreprises de divers domaines: fabricants d'équipements (Intel, AMD, ARM, Nvidia, Cisco), fournisseurs de contenu (Google, Netflix, Amazon), fabricants de navigateurs (Google, Mozilla) et autres.
Les entreprises avaient un objectif commun: un codec vidéo sans redevances. Vient ensuite
AV1 avec une licence de brevet beaucoup plus simple. Timothy B. Terriberry a fait une présentation étonnante, qui est devenue la source du concept actuel d'AV1 et de son modèle de licence.
Vous serez surpris d'apprendre que vous pouvez analyser le codec AV1 via un navigateur (les personnes intéressées peuvent aller sur
aomanalyzer.org ).

Codec universel
Analysons les mécanismes de base qui sous-tendent le codec vidéo universel. La plupart de ces concepts sont utiles et utilisés dans les codecs modernes tels que
VP9 ,
AV1 et
HEVC . Je vous préviens que beaucoup de choses expliquées seront simplifiées. Des exemples concrets seront parfois utilisés (comme c'est le cas avec H.264) pour démontrer la technologie.
1ère étape - fractionnement de l'image
La première étape consiste à diviser le cadre en plusieurs sections, sous-sections, etc.

Pour quoi? Il y a plusieurs raisons. Lorsque nous divisons l'image, nous pouvons prédire plus précisément le vecteur de mouvement à l'aide de petites sections pour les petites pièces mobiles. Alors que pour un arrière-plan statique, vous pouvez vous limiter à des sections plus grandes.
En règle générale, les codecs organisent ces sections en sections (ou fragments), macroblocs (ou blocs d'une arborescence de codage) et de nombreuses sous-sections. La taille maximale de ces partitions varie, HEVC définit 64x64, tandis qu'AVC utilise 16x16, et les sous-sections peuvent être divisées en 4x4.
Rappelez-vous les variétés de cadres du dernier article?! La même chose peut être appliquée aux blocs, nous pouvons donc avoir un fragment I, un bloc B, un macrobloc P, etc.
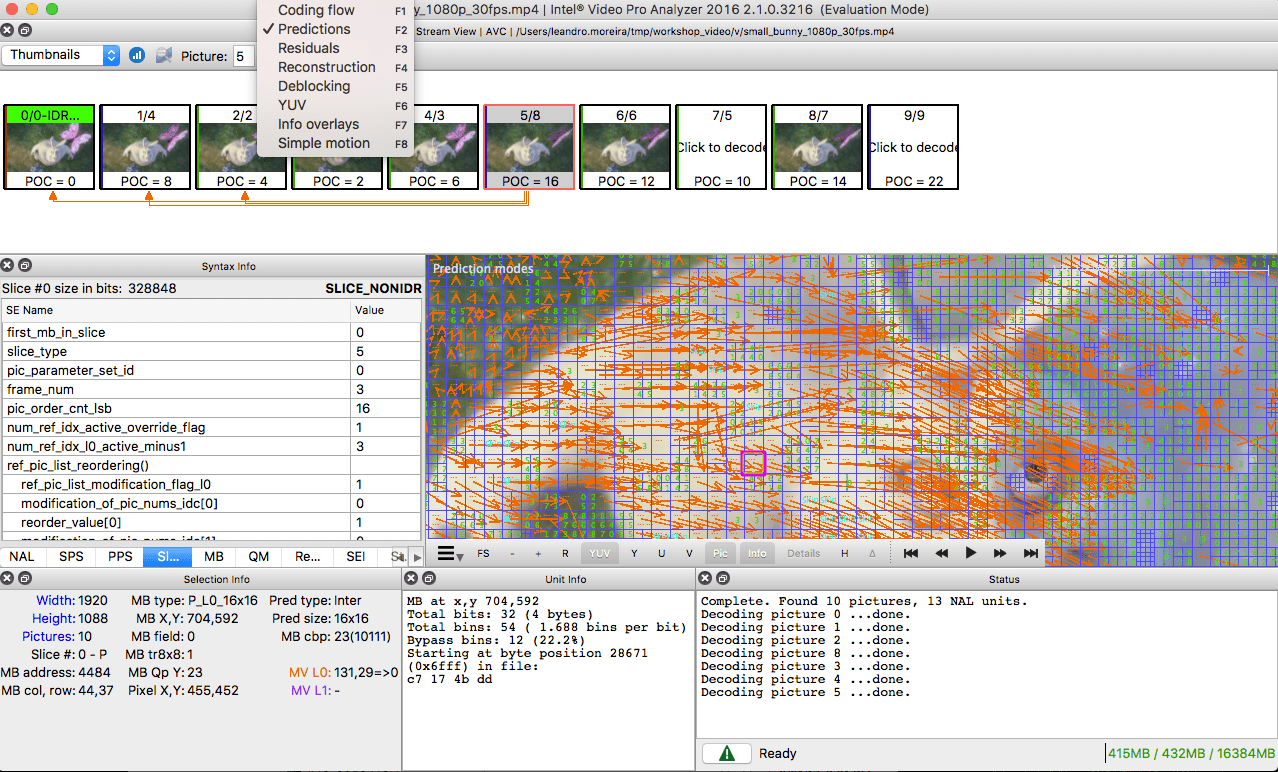
Pour ceux qui veulent s'entraîner, regardez comment l'image sera divisée en sections et sous-sections. Pour ce faire, vous pouvez utiliser
Intel Video Pro Analyzer déjà mentionné dans l'article précédent (celui qui est payé, mais avec une version d'essai gratuite, qui a une limite sur les 10 premières images). Les sections de
VP9 sont analysées ici:

2e étape - prévision
Dès que nous avons des sections, nous pouvons y faire des prévisions
astrologiques . Pour la
prédiction INTER, il est nécessaire de transférer
les vecteurs de mouvement et le reste, et pour la prédiction INTRA, la
direction de la prévision et le reste sont transmis.
3e étape - conversion
Après avoir obtenu le bloc résiduel (la section prédite → la section réelle), il est possible de le transformer de manière à savoir quels pixels peuvent être supprimés, tout en conservant la qualité globale. Certaines transformations fournissent un comportement précis.
Bien qu'il existe d'autres méthodes, considérons plus en détail la
transformée en cosinus discrète (
DCT - à partir
de la transformée en cosinus discrète ). Caractéristiques clés de DCT:
- Convertit des blocs de pixels en blocs de coefficients de fréquence de taille égale.
- Scelle l'alimentation, contribuant à éliminer la redondance spatiale.
- Assure la réversibilité.
2 février 2017 Sintra R.J. (Cintra, RJ) et Bayer F.M. (Bayer FM) a publié un article sur la conversion de type DCT pour la compression d'image, ne nécessitant que 14 ajouts.
Ne vous inquiétez pas si vous ne comprenez pas les avantages de chaque article. Maintenant, avec des exemples concrets, nous allons vérifier leur valeur réelle.
Prenons un bloc de 8x8 pixels comme celui-ci:
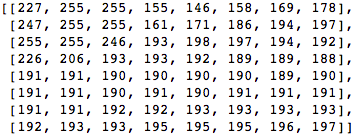
Ce bloc est rendu dans l'image suivante 8 par 8 pixels:
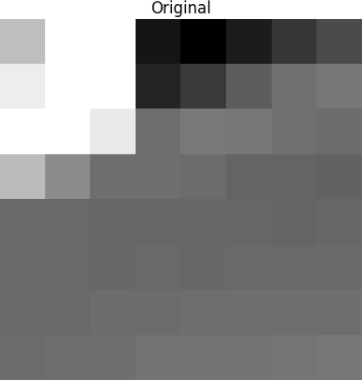
Appliquez DCT à ce bloc de pixels et obtenez un bloc de coefficients de taille 8x8:
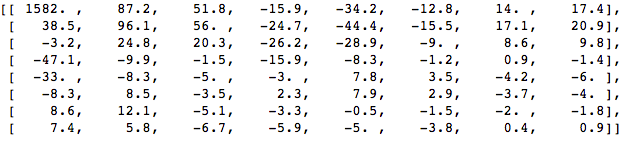
Et si nous rendons ce bloc de coefficients, nous obtenons l'image suivante:
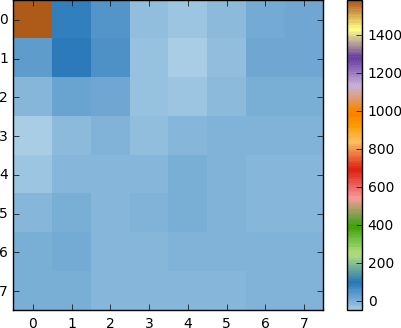
Comme vous pouvez le voir, cela ne ressemble pas à l'image d'origine. Vous remarquerez peut-être que le premier coefficient est très différent de tous les autres. Ce premier coefficient est connu sous le nom de coefficient DC représentant tous les échantillons du tableau d'entrée, quelque chose de similaire à la valeur moyenne.
Ce bloc de coefficients a une propriété intéressante: il sépare les composants haute fréquence de ceux basse fréquence.
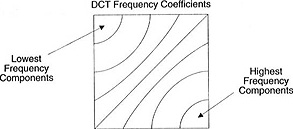
Dans l'image, la majeure partie de la puissance est concentrée à des fréquences plus basses.Par conséquent, si vous convertissez l'image en ses composantes de fréquence et supprimez les coefficients de fréquence plus élevés, vous pouvez réduire la quantité de données nécessaires pour décrire l'image sans sacrifier trop la qualité de l'image.
La fréquence signifie à quelle vitesse le signal change.
Essayons d'appliquer les connaissances acquises dans l'exemple de test en convertissant l'image d'origine à sa fréquence (bloc de coefficients) à l'aide de DCT, puis en supprimant certains des coefficients les moins importants.
Tout d'abord, convertissez-le dans le domaine fréquentiel.
Ensuite, nous éliminons une partie (67%) des coefficients, principalement le côté inférieur droit.
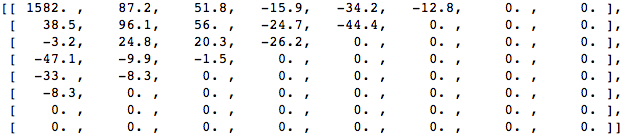
Enfin, nous restaurons l'image à partir de ce bloc de coefficients rejeté (rappelez-vous, elle doit être réversible) et comparons avec l'original.
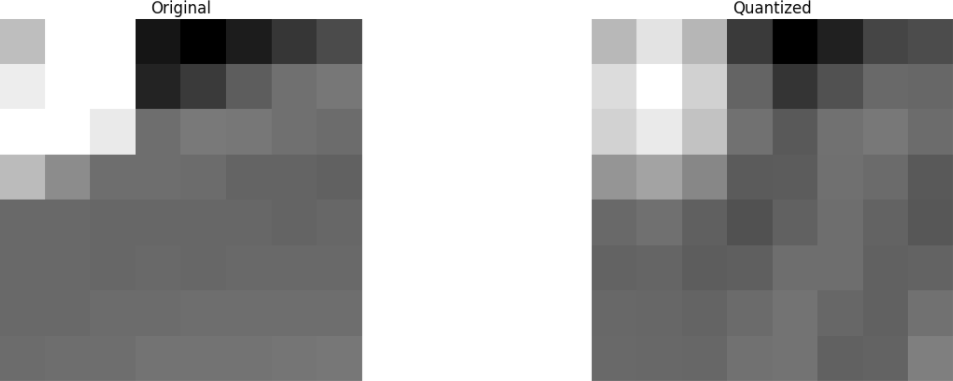
Nous voyons qu'elle ressemble à l'image d'origine, mais il existe de nombreuses différences par rapport à l'original. Nous avons lancé 67,1875% et avons toujours obtenu quelque chose qui ressemble à la source d'origine. Vous pouvez plus délibérément supprimer les coefficients pour obtenir une image de qualité encore meilleure, mais c'est le sujet suivant.
Chaque coefficient est généré en utilisant tous les pixels.
Important: chaque coefficient n'est pas directement affiché sur un pixel, mais est une somme pondérée de tous les pixels. Ce graphique étonnant montre comment les premier et deuxième coefficients sont calculés en utilisant des poids uniques à chaque indice.
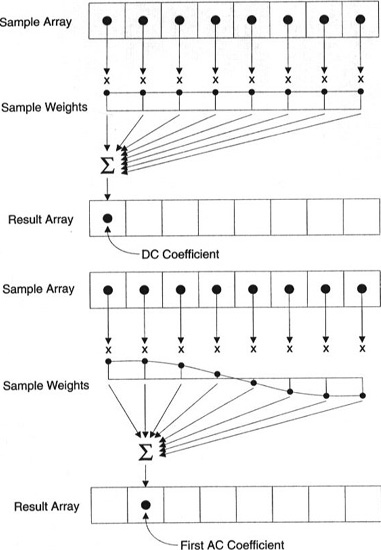
Vous pouvez également essayer de visualiser le DCT en regardant une imagerie simple basée sur celui-ci. Par exemple, voici le symbole A généré en utilisant chaque poids de coefficient:

4ème étape - quantification
Après avoir jeté quelques coefficients à l'étape précédente, à la dernière étape (transformation), nous produisons une forme de quantification spéciale. À ce stade, il est permis de perdre des informations. Ou, plus simplement, nous quantifierons les coefficients pour réaliser la compression.
Comment quantifier un bloc de coefficients? L'une des méthodes les plus simples sera la quantification uniforme, lorsque nous prenons un bloc, le divisons par une valeur (par 10) et arrondissons ce qui s'est passé.
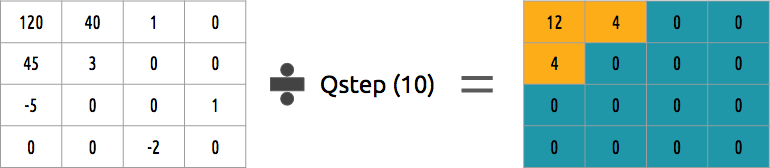
Pouvons-nous inverser ce bloc de coefficients? Oui, nous pouvons, en multipliant par la même valeur que nous avons divisée par.
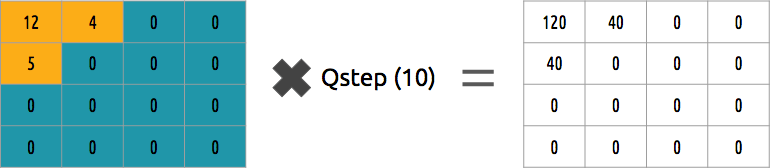
Cette approche n'est pas la meilleure, car elle ne prend pas en compte l'importance de chaque coefficient. On pourrait utiliser la matrice de quantification au lieu d'une seule valeur, et cette matrice pourrait utiliser la propriété DCT, quantifiant la majeure partie du coin inférieur droit et une minorité du coin supérieur gauche.
5 étapes - codage entropique
Après avoir quantifié les données (blocs d'images, fragments, cadres), nous pouvons toujours les compresser sans perte. Il existe de nombreuses méthodes algorithmiques pour compresser les données. Nous allons brièvement vous familiariser avec certains d'entre eux, pour une compréhension plus approfondie, vous pouvez lire le livre "
Comprendre la compression: compression de données pour les développeurs modernes " ("
Comprendre la compression: compression de données pour les développeurs modernes ").
Encodage vidéo avec VLC
Supposons que nous ayons un flux de caractères:
a ,
e ,
r et
t . La probabilité (allant de 0 à 1) de la fréquence à laquelle chaque symbole apparaît dans le flux est présentée dans ce tableau.
Nous pouvons attribuer des codes binaires uniques (de préférence petits) aux codes les plus probables, et les plus grands moins probables.
Nous compressons le flux, en supposant qu'à la fin nous dépensons 8 bits pour chaque caractère. Sans compression sur un caractère, 24 bits seraient nécessaires. Si chaque caractère est remplacé par son code, nous réalisons des économies!
La première étape consiste à coder le caractère
e , qui est 10, et le deuxième caractère est
a , qui est ajouté (pas mathématiquement): [10] [0], et enfin, le troisième caractère
t , ce qui rend notre flux binaire compressé final égal [10] [0] [1110] ou
1001110 , qui ne nécessite que 7 bits (3,4 fois moins d'espace que dans l'original).
Veuillez noter que chaque code doit être un code unique avec un préfixe.
L'algorithme de Huffman vous aidera à trouver ces nombres. Bien que cette méthode ne soit pas sans défauts, il existe des codecs vidéo qui offrent toujours cette méthode algorithmique de compression.
L'encodeur et le décodeur doivent avoir accès à la table des symboles avec leurs codes binaires. Par conséquent, il est également nécessaire d'envoyer une table en entrée.
Codage arithmétique
Supposons que nous ayons un flux de caractères:
a ,
e ,
r ,
s et
t , et leur probabilité est représentée par ce tableau.
Avec ce tableau, nous construisons des plages contenant tous les caractères possibles, triées par le plus grand nombre.

Maintenant, codons un flux de trois caractères:
manger .
Tout d'abord, sélectionnez le premier caractère
e , qui se situe dans la sous-plage de 0,3 à 0,6 (non compris). On reprend cette sous-gamme et on la divise à nouveau dans les mêmes proportions qu'avant, mais déjà pour cette nouvelle gamme.

Continuons à coder notre flux de
manger . Maintenant, nous prenons le deuxième symbole
a , qui est dans la nouvelle sous-gamme de 0,3 à 0,39, puis nous prenons notre dernier symbole
t et, en répétant le même processus à nouveau, nous obtenons la dernière sous-gamme de 0,354 à 0,372.
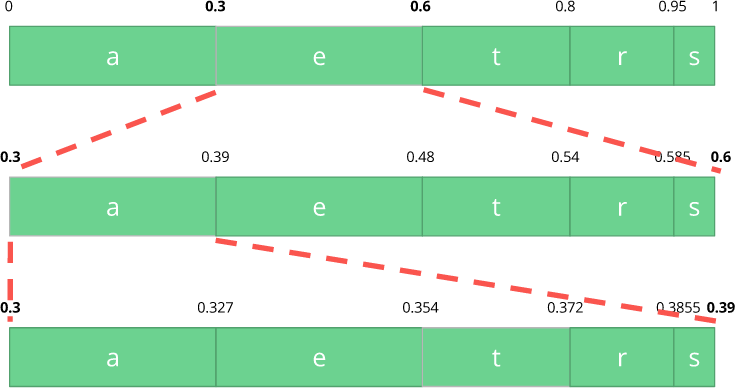
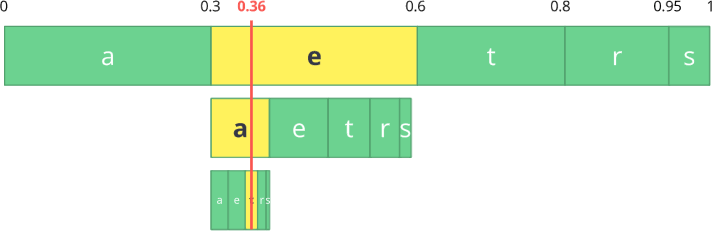
Nous avons juste besoin de sélectionner un nombre dans la dernière sous-plage de 0,354 à 0,372. Choisissons 0,36 (mais vous pouvez choisir n'importe quel autre nombre dans cette sous-plage). Ce n'est qu'avec ce nombre que nous pouvons restaurer notre flux d'origine. C'est comme si nous dessinions une ligne à l'intérieur des plages pour encoder notre flux.
L'opération inverse (c'est-à-dire le
décodage ) est tout aussi simple: avec notre nombre 0,36 et notre plage initiale, nous pouvons démarrer le même processus. Mais maintenant, en utilisant ce numéro, nous révélons le flux encodé en utilisant ce numéro.
Avec la première plage, nous remarquons que notre nombre correspond à une tranche, c'est donc notre premier caractère. Encore une fois, nous partageons cette sous-bande, effectuant le même processus que précédemment. Ici, vous pouvez voir que 0,36 correspond au caractère
a , et après avoir répété le processus, nous arrivons au dernier caractère
t (formant notre flux codé d'origine
eat ).
Le codeur et le décodeur doivent tous deux avoir une table de probabilités de symboles, il est donc nécessaire de l'envoyer dans les données d'entrée.
Assez élégant, non? Quelqu'un qui a trouvé cette solution était sacrément intelligent. Certains codecs vidéo utilisent cette technique (ou, dans tous les cas, la proposent en option).
L'idée est de compresser un train de bits quantifié sans perte. Certes, dans cet article, il n'y a pas de tonnes de détails, de raisons, de compromis, etc. Mais vous, si vous êtes développeur, devez en savoir plus. De nouveaux codecs essaient d'utiliser différents algorithmes de codage entropique, tels que
ANS .
6 étapes - format bitstream
Après avoir fait tout cela, il reste à décompresser les trames compressées dans le cadre des étapes franchies. Le décodeur doit être explicitement informé des décisions prises par le codeur. Le décodeur doit être fourni avec toutes les informations nécessaires: profondeur de bits, espace colorimétrique, résolution, informations sur les prévisions (vecteurs de mouvement, prédiction INTER directionnelle), profil, niveau, fréquence d'images, type de trame, numéro de trame et bien plus encore.
Nous allons jeter un œil au flux binaire
H.264 . Notre première étape consiste à créer un flux binaire H.264 minimum (FFmpeg ajoute par défaut tous les paramètres d'encodage, tels que
SEI NAL - un peu plus loin, nous découvrirons ce que c'est). Nous pouvons le faire en utilisant notre propre référentiel et FFmpeg.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264Cette commande va générer un
train de bits
H.264 brut avec une trame, résolution 64x64, avec l'espace colorimétrique
YUV420 . L'image suivante est utilisée comme cadre.

Flux binaire H.264
La
norme AVC (
H.264 ) définit que les informations seront envoyées dans des macro-trames (dans la compréhension du réseau) appelées
NAL (c'est un tel niveau d'abstraction du réseau). L'objectif principal de NAL est de fournir une présentation vidéo «conviviale». Cette norme devrait fonctionner sur les téléviseurs (basés sur les flux), sur Internet (basés sur les packages).

Il existe un marqueur de synchronisation pour définir les limites des éléments NAL. Chaque marqueur de synchronisation contient la valeur
0x00 0x00 0x01, à l'exception du tout premier, qui est
0x00 0x00 0x00 0x01. Si nous
exécutons hexdump pour le flux binaire H.264 généré, nous identifierons au moins trois modèles NAL au début du fichier.
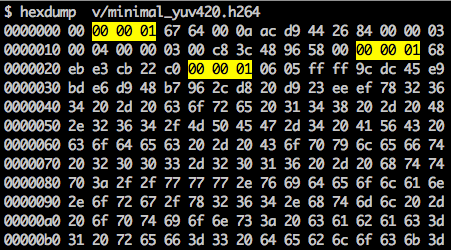
Comme indiqué, le décodeur doit connaître non seulement les données d'image, mais aussi les détails de la vidéo, la trame, la couleur, les paramètres utilisés et bien plus encore. Le premier octet de chaque NAL définit sa catégorie et son type.
Habituellement, le premier flux binaire NAL est
SPS . Ce type de NAL est chargé de signaler les variables de codage courantes, telles que le profil, le niveau, la résolution, etc.
Si nous sautons le premier jeton de synchronisation, nous pouvons décoder le premier octet pour savoir quel type de NAL est le premier.
Par exemple, le premier octet après le marqueur de synchronisation est
01100111 , où le premier bit (
0 ) est dans le champ f
orbidden_zero_bit . Les 2 bits suivants (
11 ) nous
indiquent le champ
nal_ref_idc, qui indique si ce NAL est un champ de référence ou non. Et les 5 bits restants (
00111 ) nous
indiquent le champ
nal_unit_type, dans ce cas il s'agit d'un bloc NAL SPS (
7 ).
Le deuxième octet (
binaire =
01100100 ,
hex =
0x64 ,
dec =
100 ) dans SPS NAL est le champ
profile_idc, qui montre le profil utilisé par l'encodeur. Dans ce cas, un profil haut limité a été utilisé (c'est-à-dire un profil haut sans support pour un segment B bidirectionnel).

Si nous nous familiarisons avec la spécification du flux binaire
H.264 pour SPS NAL, nous trouverons de nombreuses valeurs pour le nom, la catégorie et la description du paramètre. Par exemple, regardons les
champs pic_width_in_mbs_minus_1 et
pic_height_in_map_units_minus_1 .
Si nous effectuons des opérations mathématiques avec les valeurs de ces champs, nous obtenons la permission. Vous pouvez imaginer
1920 x 1080 en utilisant
pic_width_in_mbs_minus_1 avec une valeur de
119 ((119 + 1) * macroblock_size = 120 * 16 = 1920) . Encore une fois, pour économiser de l'espace, au lieu de coder 1920, ils l'ont fait avec 119.
Si nous continuons à vérifier notre vidéo créée sous forme binaire (par exemple:
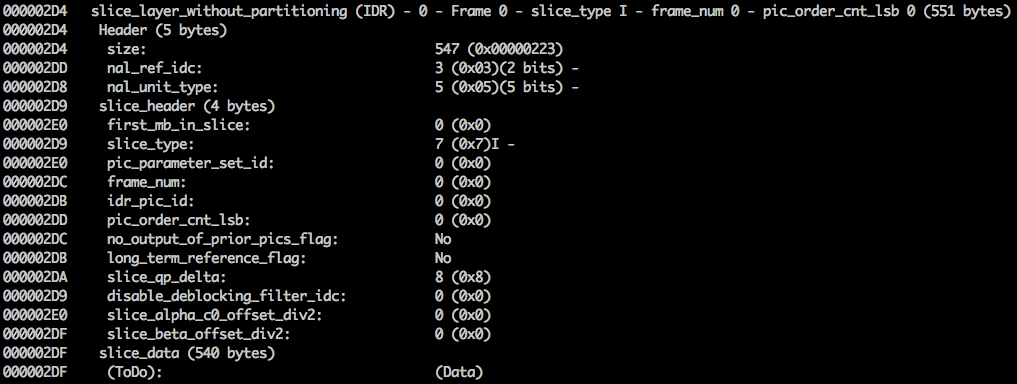
xxd -b -c 11 v / minimal_yuv420.h264 ), alors nous pouvons passer au dernier NAL, qui est l'image elle-même.

Ici, nous voyons ses 6 premières valeurs d'octets:
01100101 10001000 10000100 00000000 00100001 11111111 . Comme il est connu que le premier octet indique le type de NAL, dans ce cas (
00101 ), il s'agit d'un fragment IDR (5), et il sera alors possible de l'étudier davantage:

En utilisant les informations de spécification, il sera possible de décoder le type de fragment (
slice_type ) et le numéro de trame (
frame_num ) parmi d'autres champs importants.
Pour obtenir les valeurs de certains champs (
ue (
v ),
me (
v ),
se (
v ) ou
te (
v )), nous devons décoder le fragment à l'aide d'un décodeur spécial basé sur le
code exponentiel de Golomb . Cette méthode est très efficace pour coder des valeurs de variable, en particulier lorsqu'il existe de nombreuses valeurs par défaut.
Les valeurs
slice_type et
frame_num de cette vidéo sont 7 (I-fragment) et 0 (première image).
Le bitstream peut être considéré comme un protocole. Si vous souhaitez en savoir plus sur le flux binaire, vous devez vous référer à la spécification
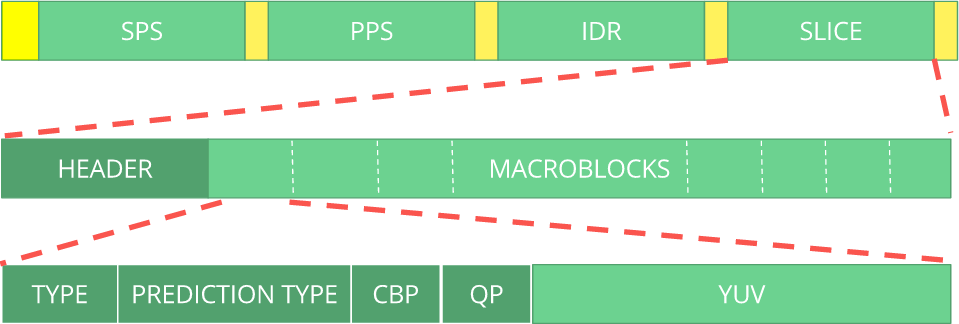
UIT H.264 . Voici une macro montrant où se trouvent les données d'image (
YUV sous forme compressée).
Vous pouvez explorer d'autres flux binaires, tels que
VP9 ,
H.265 (
HEVC ), ou même notre nouveau meilleur flux binaire
AV1 . Sont-ils tous pareils? Non, mais en avoir traité au moins un est beaucoup plus facile à comprendre le reste.
Envie de pratiquer? Explorez le flux binaire H.264
Vous pouvez générer une vidéo à image unique et utiliser MediaInfo pour examiner le flux binaire H.264 . En fait, rien ne vous empêche même de regarder le code source qui analyse le flux binaire H.264 ( AVC ).
Pour vous entraîner, vous pouvez utiliser Intel Video Pro Analyzer (j'ai déjà dit que le programme est payant, mais existe-t-il une version d'essai gratuite avec une limite de 10 images?).
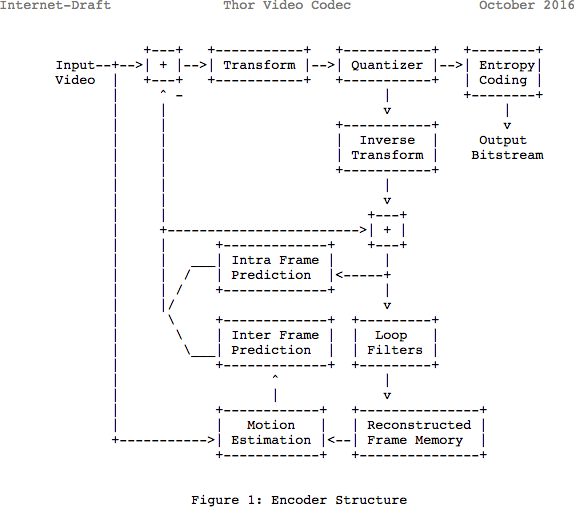
Revue
Notez que de nombreux codecs modernes utilisent le même modèle qu'ils viennent d'apprendre. Ici, jetons un coup d'œil au diagramme du codec vidéo
Thor . Il contient toutes les mesures que nous avons prises. L'intérêt de cet article est pour vous de mieux comprendre les innovations et la documentation dans ce domaine.
Auparavant, il était estimé que 139 Go d'espace disque seraient nécessaires pour stocker un fichier vidéo d'une heure avec une qualité de 720p et 30 ips. Si vous utilisez les méthodes qui ont été discutées dans cet article (prévisions inter-trames et internes, conversion, quantification, codage entropique, etc.), alors vous pouvez réaliser (en supposant que nous dépensons 0,031 bits par pixel), la vidéo est de qualité assez satisfaisante, ce qui prend seulement 367,82 Mo, pas 139 Go de mémoire.
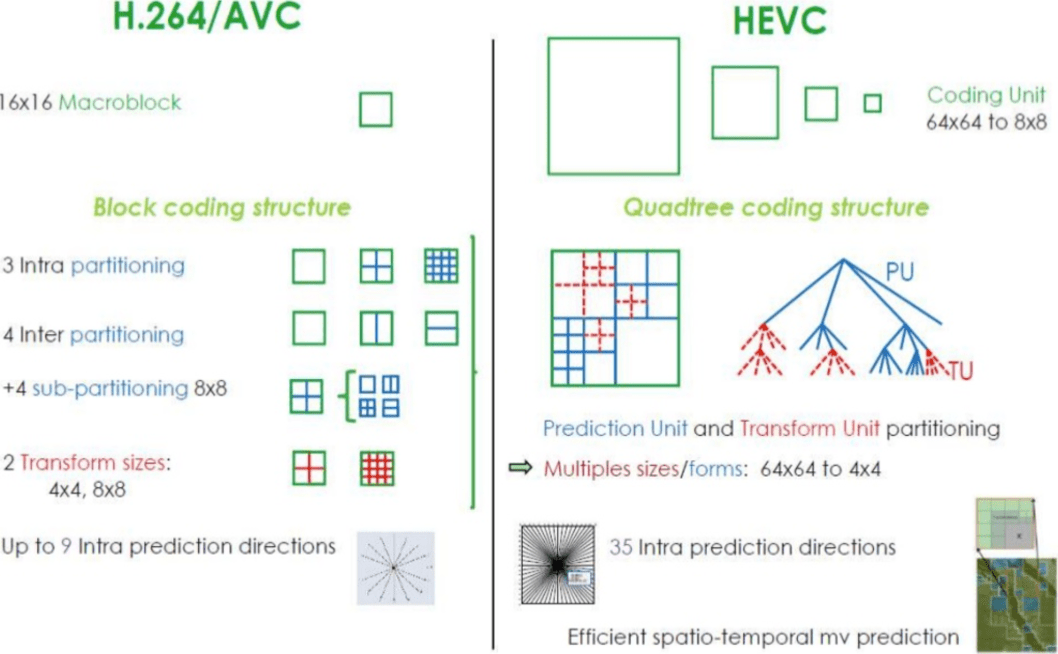
Comment le H.265 atteint-il un meilleur taux de compression que le H.264?
Maintenant que vous en savez plus sur le fonctionnement des codecs, il est plus facile de comprendre comment les nouveaux codecs peuvent fournir une résolution plus élevée avec moins de bits.
Lorsque vous comparez
AVC et
HEVC , vous ne devez pas oublier que c'est presque toujours un choix entre une charge CPU et un taux de compression plus élevés.
HEVC a plus d'options pour les sections (et sous-sections) que
AVC , plus de directions pour les prévisions internes, un codage entropique amélioré, et bien plus encore. Toutes ces améliorations ont rendu
H.265 capable de compresser 50% de plus que
H.264 .

Lisez aussi le blog
Société EDISON:
20 bibliothèques pour
application iOS spectaculaire