
Nous avons déjà présenté la
cartouche Tarantool qui vous permet de développer et d'emballer des applications distribuées. Voyons maintenant comment déployer et contrôler ces applications. Pas de panique, tout est sous contrôle! Nous avons rassemblé toutes les meilleures pratiques de travail avec Tarantool Cartridge et écrit un
rôle Ansible , qui déploiera le package sur les serveurs, démarrera et joindra les instances dans des jeux de réplicas, configurera l'autorisation, bootstrap vshard, activera le basculement automatique et la configuration du cluster de correctifs.
Intéressant, hein? Plongez, vérifiez les détails sous la coupe.
Commencer avec un échantillon
Laissez-nous vous guider à travers seulement certaines des fonctions du rôle. Vous pouvez toujours trouver une description complète de toutes ses fonctionnalités et paramètres d'entrée dans la
documentation . Cependant, essayer une fois est mieux que de le voir cent fois, alors déployons une petite application.
Tarantool Cartridge a un
tutoriel pour créer une petite application Cartridge qui stocke des informations sur les clients bancaires et leurs comptes, ainsi que fournit une API pour la gestion des données via HTTP. À cet effet, l'application décrit deux rôles possibles qui peuvent être attribués aux instances:
api et
storage .
La cartouche elle-même ne dit rien sur la façon de démarrer les processus - elle ne fournit qu'une opportunité de configurer les instances en cours d'exécution. Donc, le reste dépend de l'utilisateur: distribution des fichiers de configuration, exécution des services et configuration de la topologie. Mais nous n'allons pas faire tout cela - Ansible le fera pour nous.
Passer à l'action
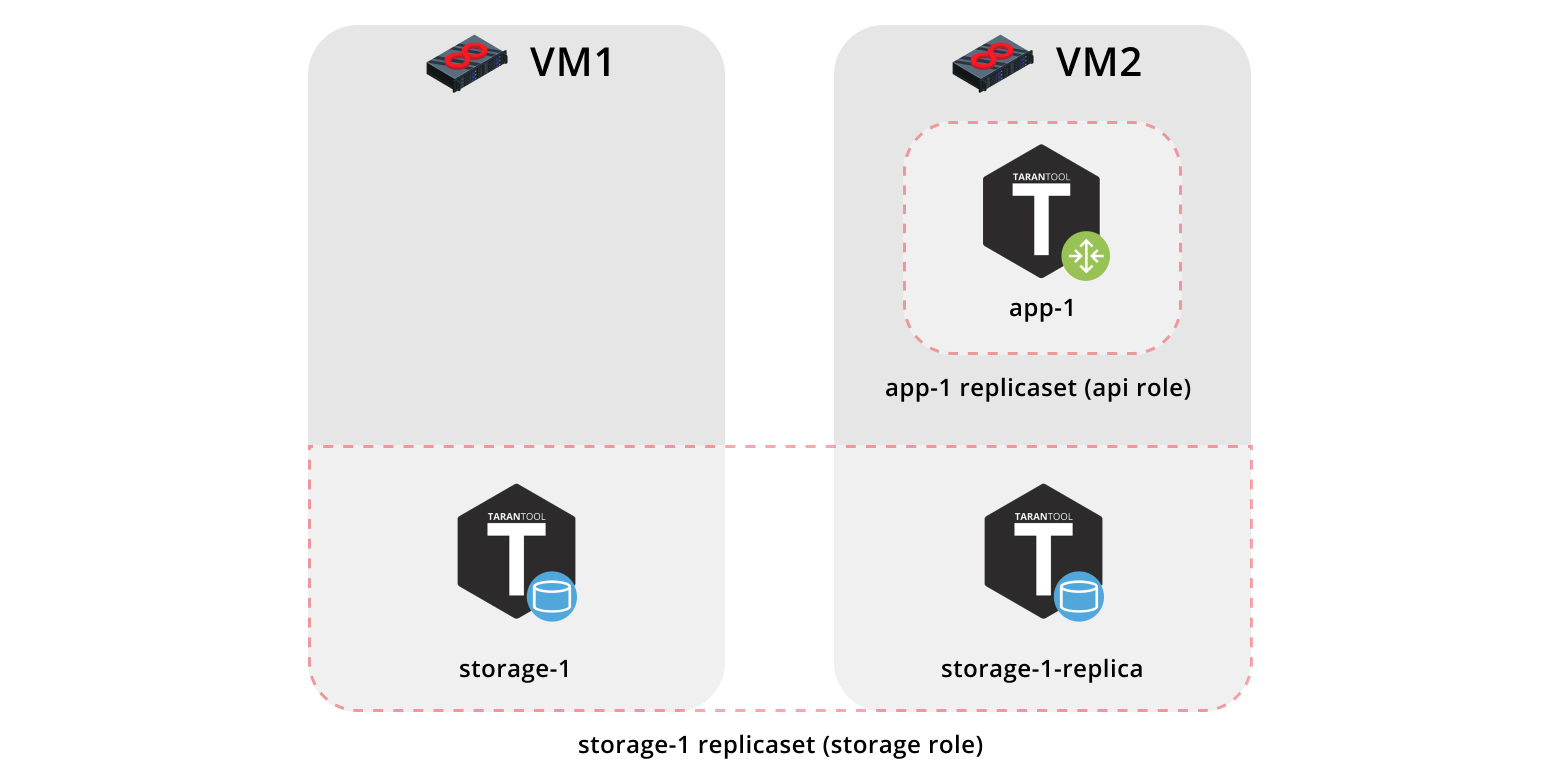
Tout d'abord, déployons notre application sur deux machines virtuelles et mettons en place une topologie simple:
- Le jeu de réplicas
app-1 représentera le rôle api qui contient le rôle vshard-router . Il n'y aura qu'une seule instance. - Le jeu de réplicas
storage-1 représentera le rôle de storage (y compris le rôle vshard-storage ) - ici, nous ajouterons deux instances de machines différentes.
Pour exécuter l'exemple, nous aurons besoin de
Vagrant et
Ansible (version 2.8 ou supérieure).
Le rôle lui-même est stocké dans
Ansible Galaxy - un référentiel qui vous permet de partager votre travail et d'utiliser les rôles prêts à l'emploi.
Maintenant, clonez l'exemple de référentiel:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git $ cd deploy-tarantool-cartridge-app && git checkout 1.0.0
Déployez ensuite les machines virtuelles:
$ vagrant up
Après cela, installez le rôle Tarantool Cartridge Ansible:
$ ansible-galaxy install tarantool.cartridge,1.0.1
Et démarrez le rôle installé:
$ ansible-playbook -i hosts.yml playbook.yml
Attendez maintenant la fin du processus du livre de lecture, accédez à
http: // localhost: 8181 / admin / cluster / dashboard et profitez des résultats:
Vous pouvez télécharger les données maintenant. Génial, non?
Voyons maintenant comment travailler avec, et nous pouvons aussi bien ajouter un autre jeu de répliques à la topologie.
Approfondir les détails
Alors, que s'est-il passé?
Nous avons installé et exécuté deux machines virtuelles et lancé le playbook Ansible qui a configuré notre cluster. Regardons maintenant à l'intérieur du fichier
playbook.yml :
--- - name: Deploy my Tarantool Cartridge app hosts: all become: true become_user: root tasks: - name: Import Tarantool Cartridge role import_role: name: tarantool.cartridge
Rien d'intéressant ne se passe ici;
tarantool.cartridge rôle Ansible appelé
tarantool.cartridge .
Les éléments les plus importants (à savoir la configuration du cluster) se
hosts.yml dans le fichier d'inventaire
hosts.yml :
--- all: vars: # common cluster variables cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package cartridge_cluster_cookie: app-default-cookie # cluster cookie # common ssh options ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no' # INSTANCES hosts: storage-1: config: advertise_uri: '172.19.0.2:3301' http_port: 8181 app-1: config: advertise_uri: '172.19.0.3:3301' http_port: 8182 storage-1-replica: config: advertise_uri: '172.19.0.3:3302' http_port: 8183 children: # GROUP INSTANCES BY MACHINES host1: vars: # first machine connection options ansible_host: 172.19.0.2 ansible_user: vagrant hosts: # instances to be started on the first machine storage-1: host2: vars: # second machine connection options ansible_host: 172.19.0.3 ansible_user: vagrant hosts: # instances to be started on the second machine app-1: storage-1-replica: # GROUP INSTANCES BY REPLICA SETS replicaset_app_1: vars: # replica set configuration replicaset_alias: app-1 failover_priority: - app-1 # leader roles: - 'api' hosts: # replica set instances app-1: replicaset_storage_1: vars: # replica set configuration replicaset_alias: storage-1 weight: 3 failover_priority: - storage-1 # leader - storage-1-replica roles: - 'storage' hosts: # replica set instances storage-1: storage-1-replica:
Tout ce que nous devons faire est d'apprendre à gérer les instances et les jeux de réplicas en modifiant ce fichier. Plus tard, nous y ajouterons de nouvelles sections. Afin d'éviter toute confusion lors de l'ajout des sections, consultez la version finale de ce fichier, ou
hosts.updated.yml , qui se trouve dans le référentiel d'exemples.
Gérer les instances
En termes Ansible, chaque instance est un hôte (à ne pas confondre avec un serveur physique), c'est-à-dire le nœud d'infrastructure qu'Ansible va gérer. Pour chaque hôte, nous pouvons spécifier des paramètres de connexion (tels que
ansible_host et
ansible_user ) et la configuration d'instance. La description de l'instance se trouve dans la section des
hosts .
Examinons la configuration de l'instance de
storage-1 :
all: vars: ... # INSTANCES hosts: storage-1: config: advertise_uri: '172.19.0.2:3301' http_port: 8181 ...
Dans la variable de
config , nous avons spécifié les paramètres d'instance:
advertise URI et le
HTTP port .
Vous trouverez ci-dessous les paramètres des instances de
storage-1-replica app-1 et
storage-1-replica .
Nous devons fournir à Ansible des paramètres de connexion pour chaque instance. Il semble raisonnable de regrouper les instances par machines virtuelles. À cette fin, les instances sont regroupées sous
host1 et
host2 , et chaque groupe de la section
vars contient les valeurs des paramètres
ansible_host et
ansible_user pour une seule machine virtuelle. Et la section des hôtes contient des hôtes (ou des instances) inclus dans ce groupe:
all: vars: ... hosts: ... children: # GROUP INSTANCES BY MACHINES host1: vars: # first machine connection options ansible_host: 172.19.0.2 ansible_user: vagrant hosts: # instances to be started on the first machine storage-1: host2: vars: # second machine connection options ansible_host: 172.19.0.3 ansible_user: vagrant hosts: # instances to be started on the second machine app-1: storage-1-replica:
Commençons à éditer
hosts.yml . Nous ajoutons maintenant deux autres instances:
storage-2-replica sur la première machine virtuelle et
storage-2 sur la seconde:
all: vars: ... # INSTANCES hosts: ... storage-2: # <== config: advertise_uri: '172.19.0.3:3303' http_port: 8184 storage-2-replica: # <== config: advertise_uri: '172.19.0.2:3302' http_port: 8185 children: # GROUP INSTANCES BY MACHINES host1: vars: ... hosts: # instances to be started on the first machine storage-1: storage-2-replica: # <== host2: vars: ... hosts: # instances to be started on the second machine app-1: storage-1-replica: storage-2: # <== ...
Démarrez le playbook Ansible:
$ ansible-playbook -i hosts.yml \ --limit storage-2,storage-2-replica \ playbook.yml
Notez l'option
--limit . Étant donné que chaque instance de cluster est un hôte en termes d'Ansible, nous pouvons spécifier explicitement quelles instances doivent être configurées lors de l'exécution du playbook.
Nous revenons donc à l'interface utilisateur Web à l'
adresse http: // localhost: 8181 / admin / cluster / dashboard et examinons nos nouvelles instances:
Ensuite, maîtrisons la gestion de la topologie.
Gérer la topologie
Regroupons nos nouvelles instances dans le jeu de réplicas
storage-2 , ajoutons un nouveau groupe de
replicaset_storage_2 et décrivons les paramètres du jeu de réplicas dans les variables comme nous l'avons fait pour
replicaset_storage_1 . Dans la section des
hosts , nous spécifions les instances à inclure dans ce groupe (c'est-à-dire notre jeu de réplicas):
--- all: vars: ... hosts: ... children: ... # GROUP INSTANCES BY REPLICA SETS ... replicaset_storage_2: # <== vars: # replicaset configuration replicaset_alias: storage-2 weight: 2 failover_priority: - storage-2 - storage-2-replica roles: - 'storage' hosts: # replicaset instances storage-2: storage-2-replica:
Ensuite, nous exécutons à nouveau le playbook:
$ ansible-playbook -i hosts.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets \ playbook.yml
Cette fois, nous passons le nom du groupe correspondant à notre jeu de répliques dans le paramètre
--limit .
Regardons l'option
tags .
Notre rôle exécute successivement diverses tâches marquées des balises suivantes:
cartridge-instances : gestion des instances (configuration, appartenance);cartridge-replicasets : gestion de la topologie (gestion des jeux de réplicas et suppression permanente (expulsion) des instances du cluster);cartridge-config : contrôle des autres paramètres du cluster (amorçage vshard, basculement automatique, paramètres d'autorisation et configuration de l'application).
Nous pouvons explicitement spécifier quelle partie du travail que nous voulons faire - et le rôle sautera le reste des tâches. Dans ce cas, nous voulons uniquement travailler avec la topologie, nous spécifions donc des
cartridge-replicasets .
Évaluons le résultat de nos efforts. Recherchez le nouveau jeu de réplicas sur
http: // localhost: 8181 / admin / cluster / dashboard .
Ouais
Essayez de modifier la configuration des instances et des jeux de réplicas et voyez comment la topologie du cluster change. Vous pouvez essayer différents cas d'utilisation, tels que la
mise à jour continue ou l'augmentation
memtx_memory . Le rôle essaierait de le faire sans redémarrer l'instance pour réduire le temps d'arrêt possible de votre application.
N'oubliez pas d'exécuter un
vagrant halt pour arrêter les machines virtuelles lorsque vous avez terminé avec elles.
Qu'y a-t-il à l'intérieur?
Ici, je vais vous en dire plus sur ce qui s'est passé sous le capot du rôle Ansible lors de nos tests.
Examinons les étapes du déploiement d'une application de cartouche.
Installation du package et démarrage des instances
La première chose à faire est de livrer le package au serveur et de l'installer. Maintenant, le rôle peut fonctionner avec les packages RPM et les packages DEB.
Ensuite, nous lançons les instances. C'est très simple: chaque instance est un service
systemd distinct. Par exemple:
$ systemctl start myapp@storage-1
Cette commande lance l'instance de
storage-1 de
myappapplication. L'instance en cours d'exécution recherche sa
configuration dans
/etc/tarantool/conf.d/ . Vous pouvez afficher les journaux d'instance à l'aide de
journald .
Le fichier Unit
/etc/systemd/systemd/myapp@.sevice pour le service systemd est livré avec le package.
Ansible a des modules intégrés pour installer des packages et gérer les services systemd, nous n'avons donc rien inventé de nouveau ici.
Configuration de la topologie de cluster
Les choses les plus excitantes se produisent ici. Je suis sûr que vous conviendrez qu'il est étrange de s'embêter avec un rôle Ansible spécial pour l'installation de packages et l'exécution de services
systemd .
Vous pouvez configurer le cluster manuellement:
- La première option consiste à ouvrir l'interface utilisateur Web et à cliquer sur les boutons. Il est tout à fait approprié pour un démarrage unique de plusieurs instances.
- La deuxième option consiste à utiliser l'API GraphQL. Ici, vous pouvez déjà automatiser quelque chose, par exemple, écrire un script en Python.
- La troisième option est pour les courageux: allez sur le serveur, connectez-vous à l'une des instances à l'aide de
tarantoolctl connect et effectuez toutes les actions nécessaires avec le module cartridge Lua.
La tâche principale de notre invention est de faire cette partie la plus difficile du travail pour vous.
Ansible vous permet d'écrire votre propre module et de l'utiliser dans votre rôle. Notre rôle utilise ces modules pour gérer les différents composants du cluster.
Comment ça marche? Vous décrivez l'état souhaité du cluster dans une configuration déclarative et le rôle donne à chaque module sa propre section de configuration en entrée. Le module reçoit l'état actuel du cluster et le compare à l'entrée. Ensuite, le code de l'état de cluster nécessaire est lancé à l'aide du socket de l'une des instances.
Résultats
Aujourd'hui, nous vous avons montré comment déployer votre application Tarantool Cartridge et configurer une topologie simple. Pour ce faire, nous avons utilisé Ansible, un outil puissant qui est facile à utiliser et vous permet de configurer plusieurs nœuds d'infrastructure en même temps (dans notre cas, les instances de cluster).
Ci-dessus, nous avons examiné l'une des nombreuses façons de décrire la configuration du cluster à l'aide d'Ansible. Une fois que vous vous sentez prêt à en savoir plus, apprenez les
meilleures pratiques pour écrire des livres de lecture. Vous pouvez trouver plus facile de gérer la topologie avec
group_vars et
host_vars .
Très prochainement, nous vous expliquerons comment supprimer (expulser) définitivement des instances de la topologie, amorcer vshard, gérer le basculement automatique, configurer l'autorisation et configurer la configuration du cluster. En attendant, vous pouvez consulter la
documentation vous-même et essayer de modifier les paramètres du cluster.
En cas de problème, assurez-vous de
nous informer du problème. Nous ferons de notre mieux pour résoudre tout problème!