Nous utilisons les services cloud depuis longtemps: courrier, stockage, réseaux sociaux, messagerie instantanée. Ils fonctionnent tous à distance - nous envoyons des messages et des fichiers, et ils sont stockés et traités sur des serveurs distants. Le cloud gaming fonctionne également: l'utilisateur se connecte au service, sélectionne le jeu et se lance. Ceci est pratique pour le joueur, car les jeux démarrent presque instantanément, ne prennent pas de mémoire et n'ont pas besoin d'un ordinateur de jeu puissant.

Pour un service cloud, tout est différent - il a des problèmes de stockage de données. Chaque jeu peut peser des dizaines ou des centaines de gigaoctets, par exemple, "The Witcher 3" prend 50 Go, et "Call of Duty: Black Ops III" - 113. En même temps, les joueurs n'utiliseront pas le service avec 2-3 jeux, au moins plusieurs dizaines sont nécessaires . En plus de stocker des centaines de jeux, le service doit décider de la quantité de stockage à allouer par joueur et évoluer lorsqu'il y en a des milliers.
Tout cela devrait-il être stocké sur leurs serveurs: combien en ont-ils besoin, où placer les centres de données, comment «synchroniser» les données entre plusieurs centres de données à la volée? Acheter des "nuages"? Utiliser des machines virtuelles? Est-il possible de stocker 5 fois les données utilisateur avec compression et de les fournir en temps réel? Comment exclure toute influence des utilisateurs les uns sur les autres lors d'une utilisation cohérente de la même machine virtuelle?
Toutes ces tâches ont été résolues avec succès dans Playkey.net - une plate-forme de jeu basée sur le cloud.
Vladimir Ryabov (
Graymansama ) - chef du département d'administration système - parlera en détail de la technologie ZFS pour FreeBSD, qui a aidé à cela, et de sa nouvelle version de ZOL (ZFS sur Linux).
Un millier de serveurs de l'entreprise sont situés dans des centres de données distants à Moscou, Londres et Francfort. Il y a plus de 250 jeux dans le service, qui sont joués par 100 000 joueurs par mois.
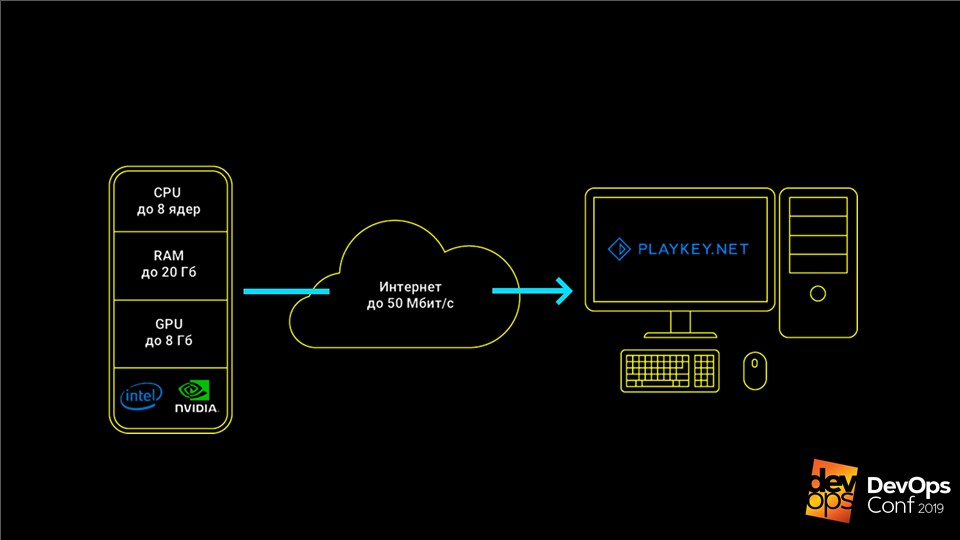
Le service fonctionne comme ceci: le jeu s'exécute sur les serveurs de l'entreprise, l'utilisateur reçoit un flux de commandes du clavier, de la souris ou de la manette de jeu, et un flux vidéo est envoyé en réponse. Cela vous permet de jouer à des jeux haut de gamme modernes sur des ordinateurs avec un matériel faible, des ordinateurs portables avec vidéo intégrée ou sur des Mac pour lesquels ces jeux ne sont pas du tout commercialisés.
Les jeux doivent être stockés et mis à jour
Les principales données du service de jeu en nuage sont les distributions de jeux, qui peuvent dépasser des centaines de Go, et les économies des utilisateurs.
Quand nous étions petits, nous n'avions qu'une douzaine de serveurs et un modeste catalogue de 50 jeux. Nous avons stocké toutes les données localement sur les serveurs, mis à jour manuellement, tout allait bien. Mais le temps est venu de grandir et nous sommes partis
pour les nuages AWS .
Avec AWS, nous avons obtenu plusieurs centaines de serveurs, mais l'architecture n'a pas changé. Ils étaient également des serveurs, mais maintenant virtuels, avec des disques locaux sur lesquels reposaient les distributions de jeux. Cependant, la mise à jour manuelle sur une centaine de serveurs échouera.
Nous avons commencé à chercher une solution. Au début, nous avons essayé de mettre à jour via
rsync . Mais il s'est avéré que cela est extrêmement lent et que la charge sur le nœud principal est trop importante. Mais ce n'est même pas le pire: lorsque nous avions une faible connexion en ligne, nous avons éteint certaines des machines virtuelles afin de ne pas les payer, et lors de la mise à jour, les données n'étaient pas versées sur les serveurs éteints. Tous ont été laissés sans mises à jour.
La solution était des torrents - le programme
BTSync . Il vous permet de synchroniser un dossier sur un grand nombre de nœuds sans spécifier explicitement un nœud central.
Problèmes de croissance
Pendant un certain temps, tout cela a fonctionné à merveille. Mais le service se développait, il y avait plus de jeux et de serveurs. Le nombre de stockages locaux a également augmenté, nous avons dû payer de plus en plus. Dans les nuages, c'est cher, surtout pour les SSD. À un moment donné, même l'indexation habituelle d'un dossier pour démarrer sa synchronisation a commencé à prendre plus d'une heure, et tous les serveurs pouvaient être mis à jour pendant plusieurs jours.
BTSync a créé un autre problème avec un trafic réseau excessif. À cette époque, chez Amazon, il était payé même entre des réseaux virtuels internes. Si le lanceur de jeu classique apporte de petites modifications aux gros fichiers, alors BTSync croit immédiatement que le fichier entier a changé et commence à le transférer entièrement à tous les nœuds. Par conséquent, même une mise à niveau de 15 Mo pourrait générer des dizaines de Go de trafic de synchronisation.
La situation est devenue critique lorsque le stockage est passé à 1 To. Je viens de sortir un nouveau jeu World of Warships. Sa distribution comptait plusieurs centaines de milliers de petits fichiers. BTSync n'a pas pu le digérer et le distribuer à tous les autres serveurs - cela a ralenti la distribution des autres jeux.
Tous ces facteurs ont créé deux problèmes:
- produire un stockage local est coûteux, peu pratique et difficile à mettre à jour;
- les nuages étaient très chers.
Nous avons décidé de revenir au concept de nos serveurs physiques.
Propre système de stockage
Avant de passer aux serveurs physiques, nous devons nous débarrasser du stockage local. Cela nécessite son propre
système de stockage - le stockage . Il s'agit d'un système qui stocke toutes les distributions et les distribue de manière centrale sur tous les serveurs.
Il semble que la tâche soit simple - elle a déjà été résolue à plusieurs reprises. Mais avec les jeux, il y a des nuances. Par exemple, la plupart des jeux refusent tout simplement de fonctionner s'ils disposent d'un accès en lecture seule. Même avec la start-up habituelle, ils aiment écrire quelque chose dans leurs fichiers, et sans cela ils refusent de travailler. Au contraire, si un grand nombre d'utilisateurs ont accès à un ensemble de distributions, ils commencent à battre les fichiers les uns des autres avec un accès compétitif.
Nous avons réfléchi au problème, vérifié plusieurs solutions et
sommes arrivés à
ZFS - Zettabyte File System sur FreeBSD .
ZFS sur FreeBSD
Ce n'est pas un système de fichiers ordinaire. Les systèmes classiques sont initialement installés sur un seul appareil, et pour travailler avec plusieurs disques nécessitent déjà un gestionnaire de volume.
ZFS a été initialement construit sur des pools virtuels.
Ils sont appelés
zpool et se composent de groupes de disques ou de matrices RAID. Le volume entier de ces disques est disponible pour tout système de fichiers dans zpool. C'est parce que ZFS a été initialement développé comme un système qui fonctionnera avec de grandes quantités de données.
Comment ZFS a aidé à résoudre nos problèmes
Ce système possède un merveilleux
mécanisme pour créer des instantanés et des clones . Ils sont créés
instantanément et ne pèsent que quelques Ko. Lorsque nous apportons des modifications à l'un des clones, il augmente du volume de ces modifications. Dans le même temps, les données des clones restants ne changent pas et restent uniques. Cela vous permet de distribuer un disque de
10 To avec un accès exclusif à l'utilisateur final, en ne dépensant que quelques Ko.
Si des clones se développent en cours de modification d'une session de jeu, ne prendront-ils pas autant d'espace que tous les jeux? Non, nous avons constaté que même dans des sessions de jeu assez longues, l'ensemble des changements dépasse rarement 100 à 200 Mo - ce n'est pas critique. Par conséquent, nous pouvons donner un accès complet à un disque dur à haute capacité à part entière à plusieurs centaines d'utilisateurs en même temps, en ne dépensant que 10 To avec une queue.
Fonctionnement de ZFS
La description semble compliquée, mais ZFS fonctionne tout simplement. Analysons son travail avec un exemple simple - créer des
zpool data partir des disques
zpool create data /dev/da /dev/db /dev/dc disponibles
zpool create data /dev/da /dev/db /dev/dc .
Remarque Ce n'est pas nécessaire pour la production, car si au moins un disque meurt, l'ensemble du pool passera dans l'oubli avec lui. Mieux utiliser les groupes RAID.Nous créons le système de fichiers
zfs create data/games , et en lui un périphérique de bloc avec le nom
data/games/disk de 10 To. L'appareil est disponible dans
/dev/zvol/data/games/disk comme un disque normal - vous pouvez effectuer les mêmes manipulations avec lui.
Ensuite, le plaisir commence. Nous remettons ce disque via
iSCSI à notre assistant de mise
à jour - une machine virtuelle classique exécutant Windows. Nous connectons le disque et y mettons les jeux simplement depuis Steam, comme sur un ordinateur personnel ordinaire.
Remplissez le disque avec des jeux. Il reste maintenant à distribuer ces données à
200 serveurs pour les utilisateurs finaux.
- Créez un instantané de ce disque et appelez-le la première version -
zfs snapshot data/games/disk@ver1 . Créez son clone zfs clone data/games/disk@ver1 data/games/disk-vm1 , qui ira à la première machine virtuelle. - Nous donnons le clone via iSCSI et KVM lance une machine virtuelle avec ce disque . Il se charge, entre dans un pool de serveurs accessibles aux utilisateurs et attend un joueur.
- Une fois la session utilisateur terminée, nous prenons toutes les sauvegardes utilisateur de cette machine virtuelle et les plaçons sur un serveur distinct . Nous
zfs destroy data/games/disk-vm1 la machine virtuelle et détruisons le clone - zfs destroy data/games/disk-vm1 . - Nous revenons à la première étape, créons à nouveau un clone et démarrons la machine virtuelle.
Cela nous permet de fournir à chaque utilisateur suivant une
machine toujours propre , sur laquelle il n'y a aucun changement par rapport au lecteur précédent. Le disque après chaque session utilisateur est supprimé et l'espace qu'il occupait sur le système de stockage est libéré. Nous effectuons également des opérations similaires avec le disque système et avec toutes nos machines virtuelles.
Récemment, je suis tombé sur une vidéo sur YouTube, où un utilisateur satisfait lors d'une session de jeu a formaté nos disques durs sur des serveurs, et était très heureux qu'il ait tout cassé. Oui, s'il vous plaît, juste pour payer - il peut jouer et se faire plaisir. Dans tous les cas, le prochain utilisateur obtiendra toujours une machine virtuelle propre et fonctionnelle, quoi que fasse le précédent.
Dans ce cadre, les jeux sont distribués à seulement 200 serveurs. Nous avons calculé le nombre 200 expérimentalement: c'est le nombre de serveurs sur lesquels les charges critiques sur les disques de stockage ne se produisent pas. En effet, les
jeux ont un profil de chargement assez spécifique : ils lisent beaucoup au stade du lancement ou au niveau du chargement, et pendant le jeu, au contraire, n'utilisent pratiquement pas de disque. Si votre profil de charge est différent, le chiffre sera différent.
Dans l'ancien schéma, pour une maintenance simultanée de 200 utilisateurs, nous avions besoin de 2 000 To de stockage local. Maintenant, nous pouvons dépenser un peu plus de 10 To pour l'ensemble de données principal, et il reste encore 0,5 To en stock pour les changements d'utilisateurs. Bien que ZFS aime quand il a au moins 15% d'espace libre dans sa piscine, il me semble que nous avons considérablement économisé.
Et si nous avons plusieurs centres de données?
Ce mécanisme ne fonctionnera qu'à l'intérieur d'un centre de données, où les serveurs avec un système de stockage sont connectés par au moins 10 interfaces gigabits. Que faire s'il y a plusieurs DC? Comment mettre à jour le disque principal avec des jeux (jeu de données) entre eux?
Pour cela, ZFS a sa propre solution -
le mécanisme d'envoi / réception . La commande d'exécution est très simple:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/disk
Le mécanisme vous permet de transférer d'un système de stockage à un autre un instantané du système principal. Pour la première fois, vous devrez envoyer les 10 téraoctets de données écrites sur le nœud maître vers un système de stockage vide. Mais avec les prochaines mises à jour, nous n'enverrons les modifications qu'à partir du moment où nous avons créé l'instantané précédent.
En conséquence, nous obtenons:
- Toutes les modifications sont effectuées de manière centralisée sur un seul système de stockage . Ensuite, ils se dispersent dans tous les autres centres de données en n'importe quelle quantité, et les données sur tous les nœuds sont toujours identiques.
- Le mécanisme d'envoi / réception n'a pas peur d'une déconnexion . Les données ne sont pas appliquées à l'ensemble de données principal tant qu'elles n'ont pas été entièrement transmises au nœud esclave. Si la connexion est perdue, il est impossible d'endommager les données et répétez simplement la procédure d'envoi.
- Tout nœud peut facilement devenir un nœud maître lors d'un accident en quelques minutes, car les données de tous les nœuds sont toujours identiques.
Déduplication et sauvegardes
ZFS a une autre fonctionnalité utile - la
déduplication . Cette fonction permet de
ne pas stocker deux blocs de données identiques . Au lieu de cela, seul le premier bloc est stocké et à la place du second, un lien vers le premier est stocké. Deux fichiers identiques prendront de l'espace en un seul et s'ils correspondent à 90%, ils rempliront 110% du volume d'origine.
La fonction nous a beaucoup aidés à stocker les sauvegardes des utilisateurs. Dans un jeu, différents utilisateurs ont une sauvegarde similaire, de nombreux fichiers sont identiques. Grâce à la déduplication, nous pouvons stocker cinq fois plus de données. Notre taux de déduplication est de 5,22. Physiquement, nous avons 4,43 téraoctets, nous multiplions par un facteur et nous obtenons près de 23 téraoctets de données réelles. Cela économise de l'espace en évitant le stockage en double.
Les instantanés sont bons pour les sauvegardes . Nous utilisons cette technologie sur nos stockages de fichiers. Par exemple, si vous enregistrez une image chaque jour pendant un mois, vous pouvez déployer un clone à tout moment n'importe quel jour de ce mois et extraire les fichiers perdus ou endommagés. Cela élimine le besoin de restaurer l'ensemble du stockage ou d'en déployer une copie complète.
Nous utilisons des clones pour aider nos développeurs . Par exemple, ils veulent vivre une migration potentiellement dangereuse sur une base de combat. Il n'est pas rapide de déployer une sauvegarde classique d'une base de données qui approche les 1 To. Par conséquent, nous supprimons simplement le clone du disque de base et l'ajoutons instantanément à la nouvelle instance. Les développeurs peuvent désormais tout tester en toute sécurité.
API ZFS
Bien sûr, tout cela doit être automatisé. Pourquoi grimper sur les serveurs, travailler avec vos mains, écrire des scripts, si cela peut être donné aux programmeurs? Par conséquent, nous avons écrit notre
API Web simple.
Nous y avons inclus toutes les fonctions ZFS standard, coupé l'accès à celles qui sont potentiellement dangereuses et pourraient casser tout le système de stockage, et avons donné tout cela aux programmeurs. Désormais,
toutes les opérations sur disque sont strictement centralisées et effectuées par code, et nous
connaissons toujours l'état de chaque disque . Tout fonctionne très bien.
ZoL - ZFS sur Linux
Nous avons centralisé le système et pensé, est-ce si bon? En effet, maintenant pour toute extension, nous devons immédiatement acheter plusieurs racks de serveurs: ils sont liés aux systèmes de stockage, et il est irrationnel de diviser le système. Que faire lorsque nous décidons de déployer un petit stand de démonstration pour montrer la technologie à des partenaires dans d'autres pays?
En pensant, nous sommes arrivés à la vieille idée - d'
utiliser des disques locaux , mais seulement avec toute l'expérience et les connaissances que nous avons reçues. Si vous développez l'idée plus globalement, alors pourquoi ne pas donner à nos utilisateurs la possibilité non seulement d'utiliser nos serveurs, mais aussi de louer leurs ordinateurs?
La fourchette relativement récente de
ZFS sur Linux - ZoL nous a beaucoup aidés à cet
égard .
Désormais, chaque serveur dispose de son propre stockage.
Seulement, il ne stocke pas 10 téraoctets de données, comme dans le cas d'une installation centralisée, mais seulement 1-2 distributions des jeux qu'il sert. Un SSD suffit pour cela. Tout cela fonctionne bien: chaque utilisateur suivant obtient toujours une machine virtuelle propre, ainsi qu'une installation de combat.
Cependant, nous avons rencontré ici deux problèmes.
Comment mettre à jour?
Mettre à jour de manière centralisée via SSH, comme nous le faisons dans les centres de données ne fonctionnera pas . Les utilisateurs peuvent être connectés au réseau local ou simplement désactivés, contrairement aux systèmes de stockage, et vous ne voulez pas augmenter autant de connexions SSH.
Nous avons rencontré les mêmes problèmes que lors de l'utilisation de rsync. Cependant, les torrents au-dessus de ZFS ne peuvent plus être obtenus. Nous avons soigneusement réfléchi au fonctionnement du mécanisme d'envoi: il envoie tous les blocs de données modifiés vers le stockage final, où Receive les applique à l'ensemble de données actuel. Pourquoi ne pas écrire les données dans un fichier, au lieu de les envoyer à l'utilisateur final?
Le résultat est ce que nous appelons
diff . Il s'agit d'un fichier dans lequel tous les blocs modifiés entre les deux derniers instantanés sont écrits séquentiellement. Nous avons mis ce diff sur un CDN et l'avons envoyé à tous nos utilisateurs via HTTP: il a allumé la machine, a vu qu'il y avait des mises à jour, l'a dégonflé et l'a appliqué à l'ensemble de données local à l'aide de la réception.
Que faire des chauffeurs?
Les serveurs centralisés ont la même configuration et les
utilisateurs finaux ont toujours des ordinateurs et des cartes vidéo différents . Même si nous remplissons la distribution du système d'exploitation avec tous les pilotes possibles autant que possible, la première fois qu'elle démarre, elle voudra toujours installer ces pilotes, puis elle redémarrera, puis, éventuellement, à nouveau. Puisque chaque fois que nous fournissons un clone propre, tout ce carrousel se produira après chaque session utilisateur - c'est mauvais.
Nous voulions faire un peu d'initialisation: attendre que Windows démarre, installe tous les pilotes, fasse tout ce qu'elle veut, puis seulement opère sur ce lecteur. Mais le problème est que si vous apportez des modifications à l'ensemble de données principal, les mises à jour seront interrompues, car les données sur la source et sur le récepteur seront différentes et les différences ne s'appliqueront tout simplement pas.
Cependant, ZFS est un système flexible et nous a permis de faire une petite béquille.
- Comme d'habitude, créez un snapshot:
zfs snapshot data/games/os@init . - Créez son clone -
zfs clone data/games/os@init data/games/os-init - et exécutez-le en mode d'initialisation. - Nous attendons que tous les pilotes soient installés et tout redémarrera.
- Éteignez la machine virtuelle et reprenez un instantané. Mais cette fois, pas à partir du jeu de données d'origine, mais à partir du clone d'initialisation:
zfs snapshot data/games/os-init@ver1 . - Nous créons un clone de l'instantané avec tous les pilotes installés. Il ne redémarrera plus:
zfs clone data/games/os-init@ver1 data/games/os-vm1 . - Ensuite, nous travaillons sur le bouquet classique.
Maintenant, ce système est au stade des tests alpha. Nous le testons sur de vrais utilisateurs sans connaissance de Linux, mais ils parviennent à tout déployer à la maison. Notre objectif ultime est que tout utilisateur branche simplement un lecteur flash USB amorçable sur son ordinateur, connecte un lecteur SSD supplémentaire et le loue sur notre plateforme cloud.
Nous n'avons discuté que d'une petite partie de la fonctionnalité ZFS. Ce système peut faire des choses beaucoup plus intéressantes et différentes, mais peu de gens connaissent ZFS - les utilisateurs ne veulent pas en parler. J'espère qu'après cet article de nouveaux utilisateurs apparaîtront dans la communauté ZFS.
Abonnez-vous à un canal télégramme ou à une newsletter pour en savoir plus sur les nouveaux articles et vidéos de la conférence DevOpsConf . En plus de la newsletter, nous collectons des informations sur les conférences à venir et disons, par exemple, ce qui sera intéressant pour les fans de DevOps à Saint HighLoad ++ .