Il est connu que la compétence CTO n'est testée que pour la deuxième fois que ce rôle est joué. Parce que c'est une chose de travailler dans une entreprise pendant plusieurs années, d'évoluer avec elle et, étant dans le même contexte culturel, de prendre progressivement plus de responsabilités. Et c’est tout autre chose - de prendre immédiatement le poste de directeur technique dans une entreprise avec des bagages hérités et un tas de problèmes remarqués sous le tapis.
En ce sens, l'expérience de Leon Fire, qu'il a partagée sur
DevOpsConf , n'est pas tellement unique, mais multipliée par l'expérience et le nombre de rôles différents qu'il a réussi à essayer pour lui-même pendant 20 ans est très utile. Sous la coupe, une chronologie des événements sur 90 jours et beaucoup de contes qui plaisent à rire quand ils arrivent à quelqu'un d'autre, mais qui ne sont pas si amusants à affronter en personne.
Leon est très coloré en russe, donc si vous avez 35-40 minutes, je vous recommande de regarder la vidéo. Version texte pour gagner du temps ci-dessous.
La première version du rapport était une description bien structurée du travail avec les personnes et les processus, contenant des recommandations utiles. Mais elle n'a pas transmis toutes les surprises rencontrées en cours de route. Par conséquent, j'ai changé le format et décrit les problèmes que la nouvelle entreprise a surgi devant moi comme un enfer d'une tabatière, et les méthodes pour les résoudre dans l'ordre chronologique.
Un mois avant
Comme beaucoup de bonnes histoires, celle-ci a commencé avec de l'alcool. Nous nous sommes assis avec des amis dans le bar, et comme il se doit parmi les informaticiens, tout le monde a pleuré sur leurs problèmes. L'un d'eux vient de changer d'emploi et a parlé de ses problèmes avec la technologie, avec les gens et avec l'équipe. Plus j'écoutais, plus je réalisais qu'il avait juste besoin de m'engager, car ce sont précisément ces problèmes que je résolvais depuis 15 ans. Je le lui ai dit et le lendemain, nous nous sommes déjà rencontrés dans un environnement de travail. L'entreprise s'appelait Teaching Strategies.
Teaching Strategies domine le marché des programmes éducatifs pour les très jeunes enfants - de la naissance à trois ans. La société traditionnelle «papier» a déjà 40 ans et la version numérique SaaS de la plateforme 10. Relativement récemment, le processus d'adaptation de la technologie numérique aux normes de l'entreprise a commencé. La «nouvelle» version a été lancée en 2017 et ressemblait presque à l'ancienne, mais elle fonctionnait moins bien.
La chose la plus intéressante est que le trafic de cette entreprise est très prévisible - de jour en jour, d'année en année, vous pouvez très clairement prédire combien de personnes viendront et quand. Par exemple, entre 13 heures et 15 heures, tous les enfants des jardins d'enfants s'endorment et les enseignants commencent à saisir des informations. Et cela se produit tous les jours sauf le week-end, car le week-end, presque personne ne travaille.
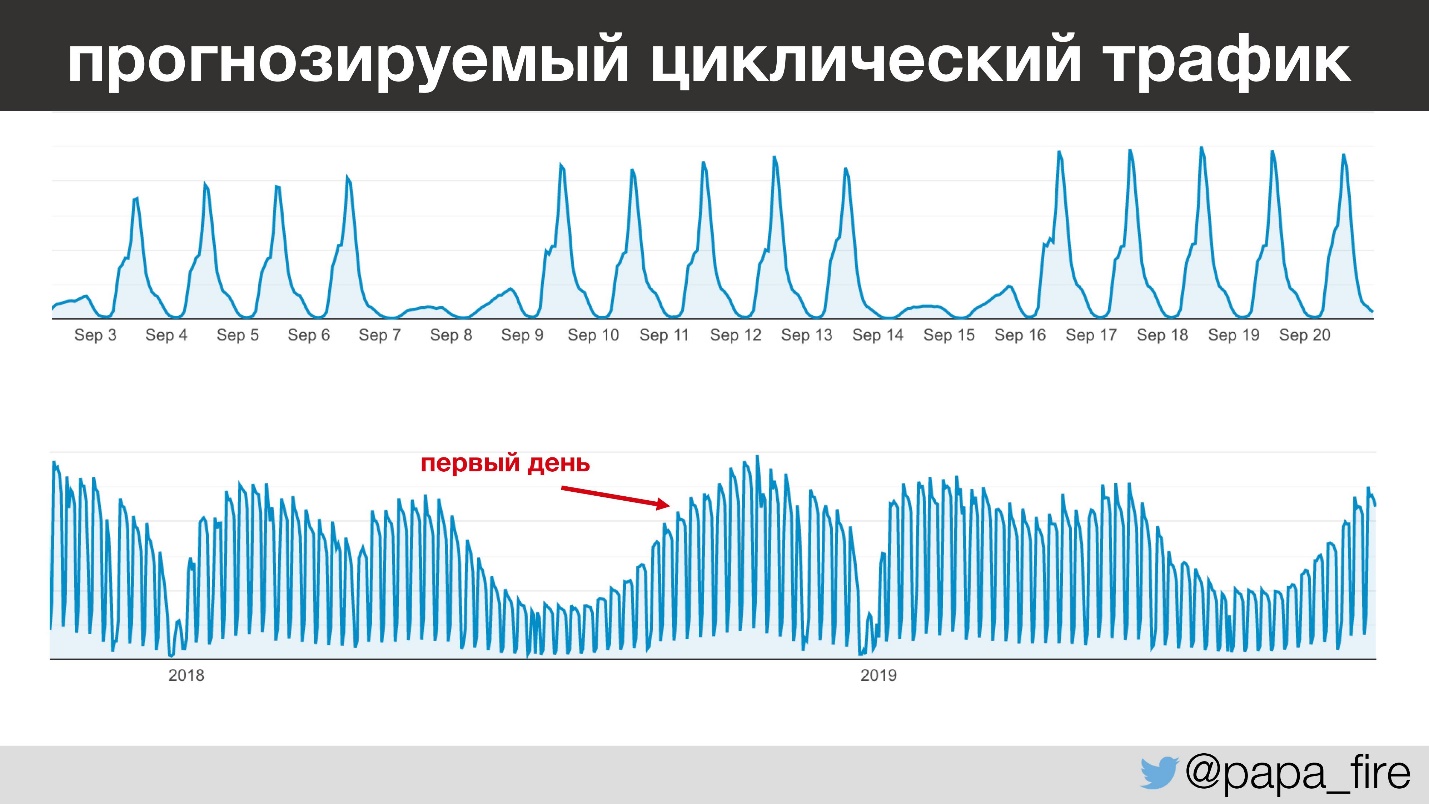
Regardant un peu plus loin, j'ai commencé mon travail pendant la période de trafic annuel le plus important, ce qui est intéressant pour diverses raisons.
La plateforme, qui ne semblait avoir que 2 ans, avait une pile particulière: ColdFusion et SQL Server 2008. ColdFusion, si vous ne le savez pas, mais probablement ne le sait pas, est un tel PHP d'entreprise qui est sorti au milieu des années 90, et depuis, je n'en ai même plus entendu parler. Il y avait aussi: Ruby, MySQL, PostgreSQL, Java, Go, Python. Mais le monolithe principal fonctionnait sur ColdFusion et SQL Server.
Les problèmes
Plus je parlais avec les employés de l'entreprise du travail et des problèmes rencontrés, plus je me rendais compte que les problèmes n'étaient pas seulement de nature technique. D'accord, la technologie est ancienne - et ils n'y travaillaient pas, mais il y avait des problèmes avec l'équipe et les processus, et l'entreprise a commencé à comprendre cela.
Traditionnellement, les techniciens étaient assis dans un coin et faisaient une partie de leur travail. Mais de plus en plus d'entreprises ont commencé à passer par la version numérique. Par conséquent, dans l'entreprise au cours de la dernière année avant le début de mon travail, de nouveaux membres sont apparus: le conseil d'administration, CTO, CPO et QA-director. Autrement dit, la société a commencé à investir dans le domaine technologique.
Des traces d'un lourd héritage n'étaient pas seulement présentes dans les systèmes. L'entreprise avait des processus hérités, des personnes héritées, une culture héritée. Tout cela devait être changé. J'ai pensé que ce ne serait certainement pas ennuyeux et j'ai décidé de l'essayer.
Deux jours avant
Deux jours avant de commencer un nouvel emploi, je suis arrivée au bureau, j'ai rempli les derniers papiers, j'ai fait connaissance avec l'équipe et j'ai constaté que l'équipe était aux prises avec le problème à ce moment-là. Elle consistait en ce que le temps de chargement moyen des pages passait à 4 s, soit 2 fois.
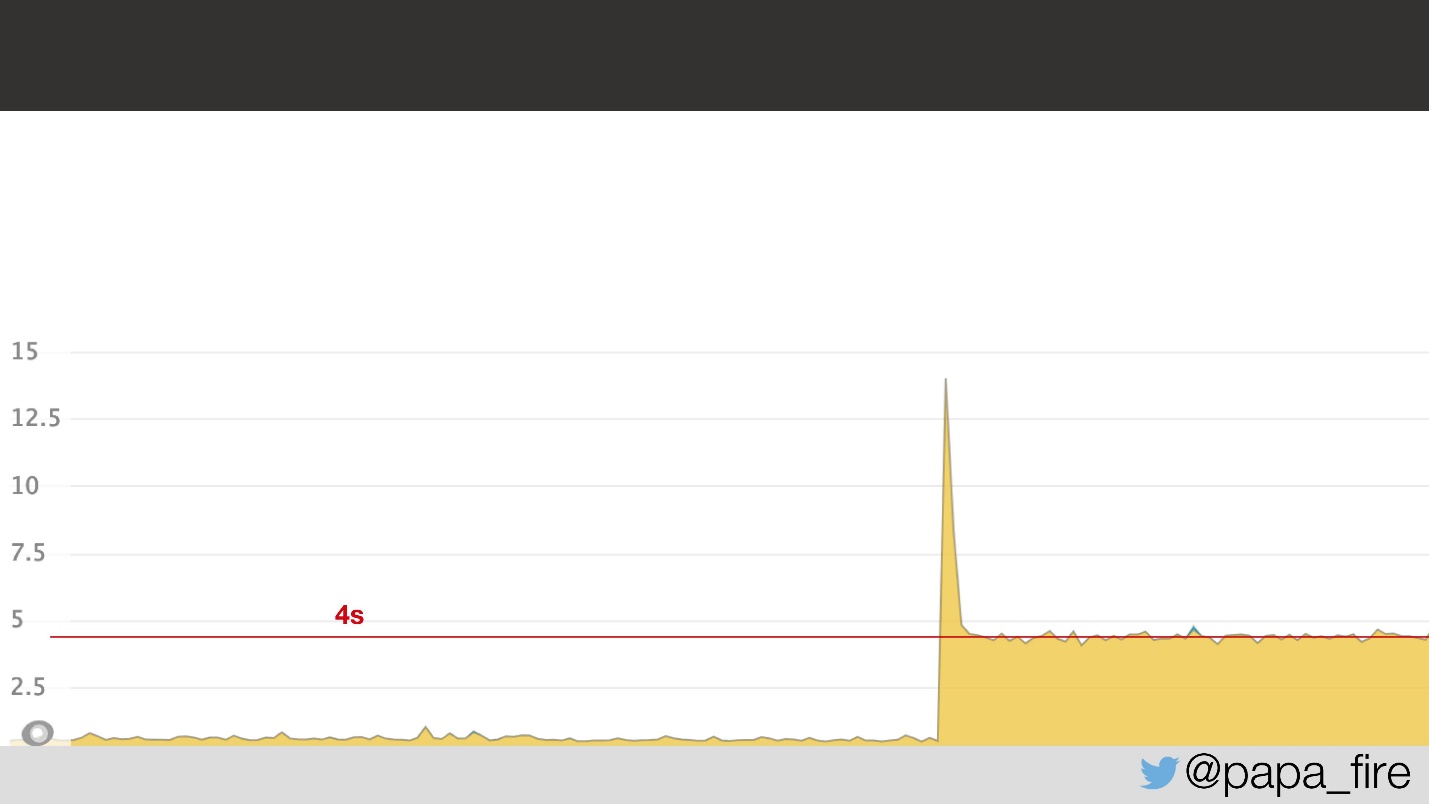
À en juger par le calendrier, il est évident que quelque chose s'est produit, et on ne sait pas quoi. Il s'est avéré que le problème était lié à la latence du réseau dans le centre de données: une latence de 5 ms dans le centre de données a été convertie en 2 s pour les utilisateurs. Pourquoi cela s'est-il produit, je ne le savais pas, mais en tout cas, on a su que le problème était dans le centre de données.
Premier jour
Deux jours se sont écoulés et le premier jour de travail, j'ai découvert que le problème ne s'était pas résorbé.
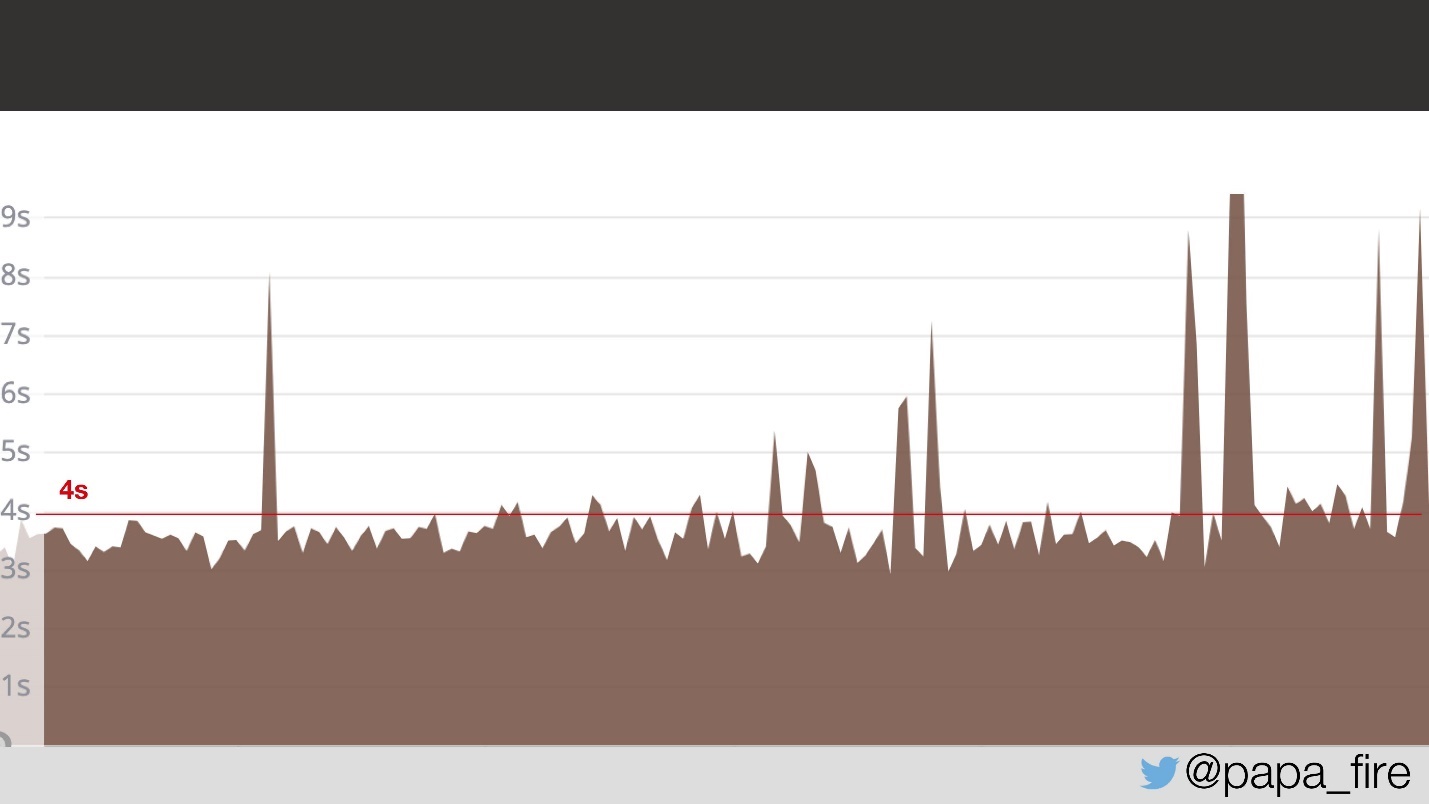
Pendant deux jours, les utilisateurs de la page se chargent en moyenne 4 s. Je leur demande s'ils ont trouvé le problème.
- Oui, nous avons ouvert un ticket.
- Et?
"Eh bien, ils ne nous ont pas encore répondu."Puis j'ai réalisé que tout ce qu'on m'avait dit auparavant n'était que la petite pointe de l'iceberg avec laquelle je devais me battre.
Il y a une bonne citation qui convient très bien à ce cas:
«Parfois, vous devez changer l'organisation pour changer la technologie.»
Mais depuis que j'ai commencé à travailler dans la période la plus occupée de l'année, j'ai dû examiner les deux options pour résoudre le problème: à la fois rapide et à long terme. Et commencez par ce qui est critique en ce moment.
Troisième jour
Ainsi, le chargement prend 4 secondes, et de 13 à 15 les plus grands pics.
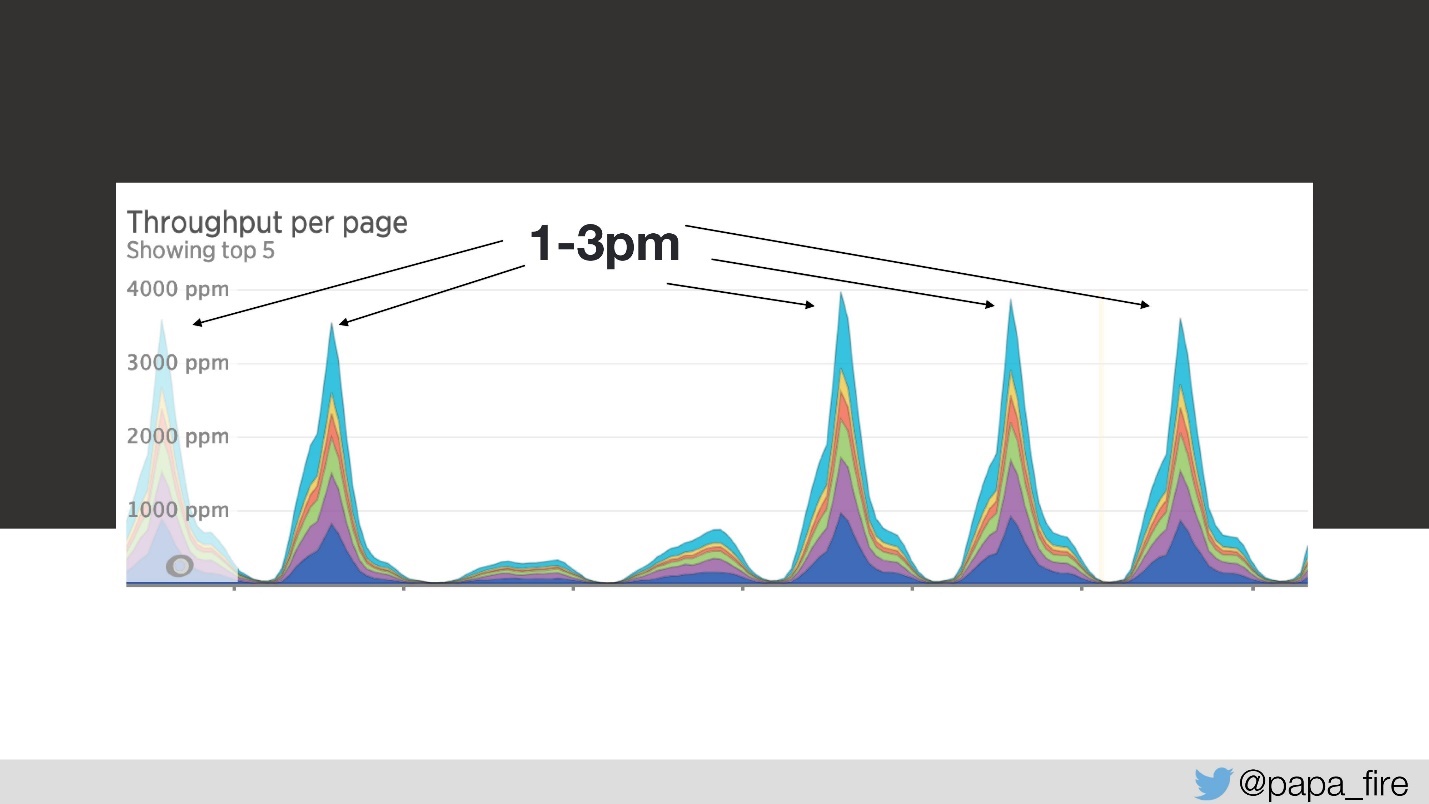
Le troisième jour, à cet intervalle de temps, la vitesse de téléchargement ressemblait à ceci:
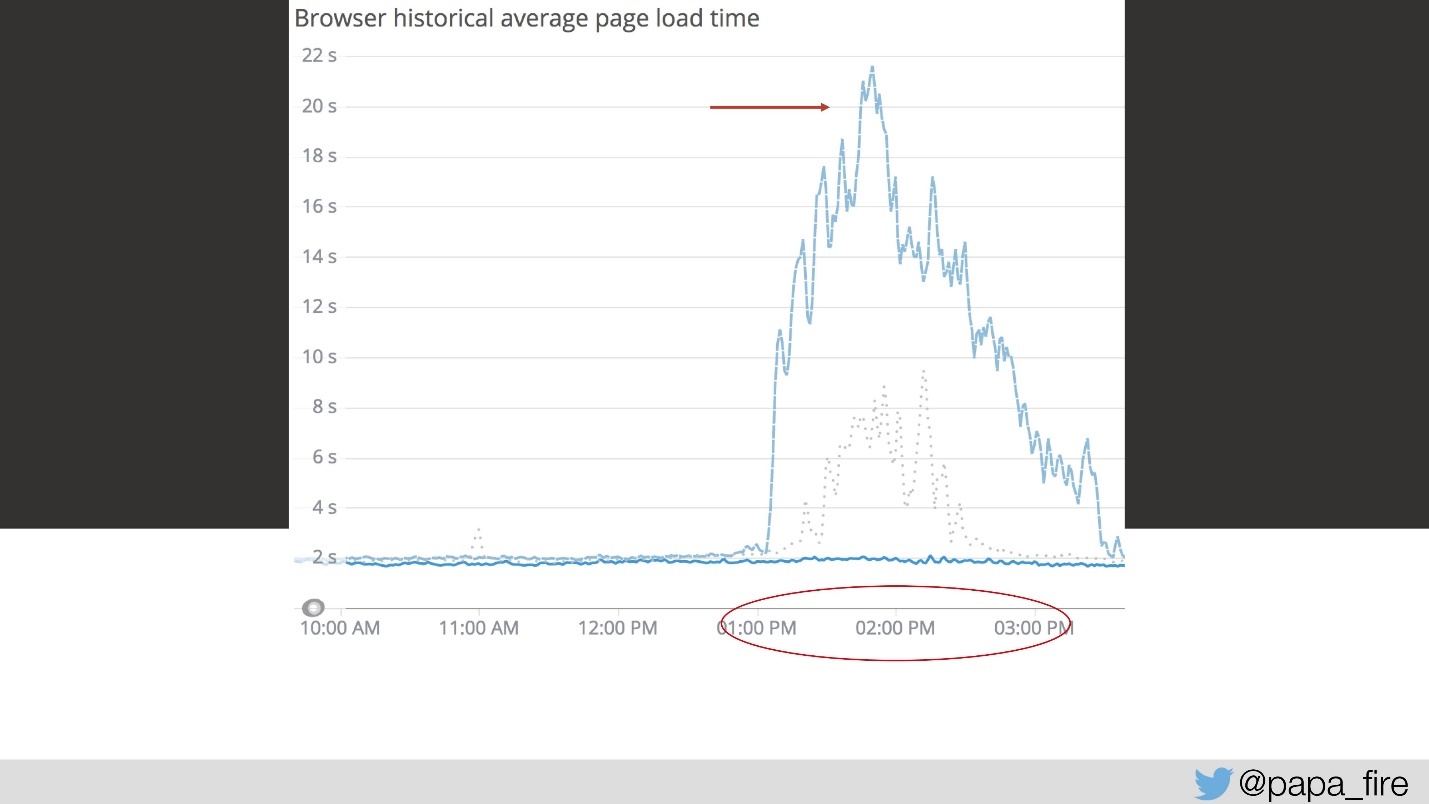
De mon point de vue, rien n'a fonctionné du tout. Du point de vue de tout le monde, cela a fonctionné un peu plus lentement que d'habitude. Mais cela ne se produit pas de cette façon - c'est un problème grave.
J'ai essayé de convaincre l'équipe, à laquelle ils ont répondu qu'ils avaient juste besoin de plus de serveurs. Ceci, bien sûr, est la solution au problème, mais en aucun cas toujours la seule et la plus efficace. J'ai demandé pourquoi il n'y avait pas assez de serveurs, combien de trafic. J'ai extrapolé les données et obtenu que nous avons environ 150 demandes par seconde, ce qui correspond essentiellement à des limites raisonnables.
Mais nous ne devons pas oublier qu'avant d'obtenir la bonne réponse, vous devez vous poser la bonne question. Ma question suivante était: combien de serveurs frontaux avons-nous? La réponse "m'a laissé perplexe" - nous avions 17 serveurs frontaux!
- Je suis gêné de demander, 150 divisé par 17, cela se terminera-t-il par 8? Vous voulez dire que chaque serveur saute 8 requêtes par seconde, et si demain il y a 160 requêtes par seconde, nous aurons besoin de 2 serveurs supplémentaires?Bien sûr, nous n'avions pas besoin de serveurs supplémentaires. La solution était dans le code lui-même, et en surface:
var currentClass = classes.getCurrentClass(); return currentClass;
Il y avait une fonction
getCurrentClass() , parce que tout sur le site fonctionne dans le contexte de la classe - correctement. Et pour cette seule fonction sur chaque page, il y avait
plus de 200 demandes .
La solution de cette manière était très simple, il n'était pas nécessaire de réécrire quoi que ce soit: il suffit de ne plus demander les mêmes informations.
if ( !isDefined("REQUEST.currentClass") ) { var classes = new api.private.classes.base(); REQUEST.currentClass = classes.getCurrentClass(); } return REQUEST.currentClass;
J'étais très content car j'ai décidé que ce n'est que le troisième jour que j'ai trouvé le problème principal. Comme j'étais naïf, ce n'était qu'un des nombreux problèmes.
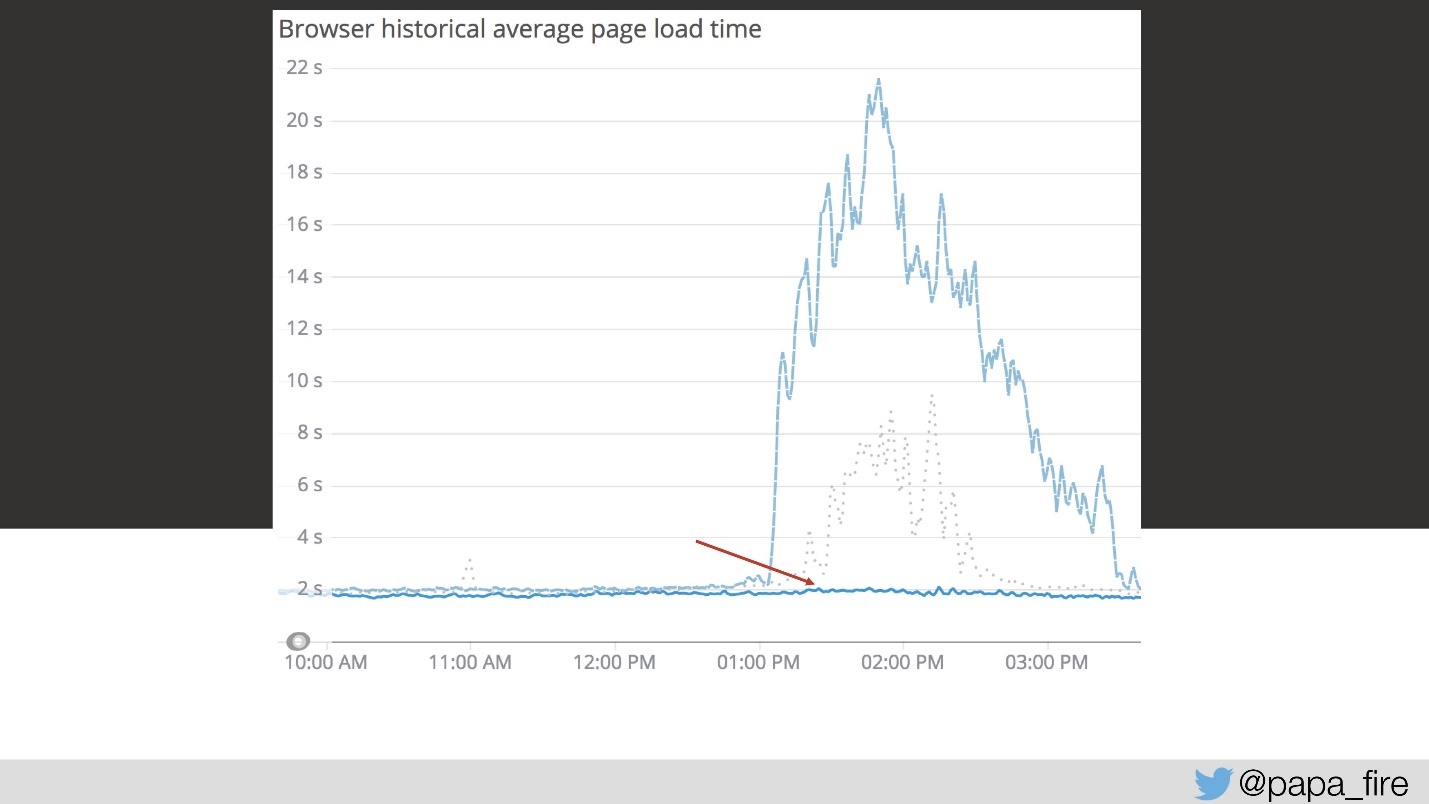
Mais la solution à ce premier problème a abaissé le calendrier beaucoup plus bas.
Dans le même temps, nous avons engagé d'autres optimisations. En vue, il y avait beaucoup de tout ce qui peut être réparé. Par exemple, le même troisième jour, j'ai découvert qu'il y avait encore un cache dans le système (au début, je pensais que toutes les demandes partaient directement de la base de données). Quand je pense à un cache, j'introduis le standard Redis ou Memcached. Mais seulement je le pensais, car pour la mise en cache sur ce système, MongoDB et SQL Server ont été utilisés - le même à partir duquel les données venaient d'être lues.
Dixième jour
La première semaine, je faisais face à des problèmes qui devaient être résolus maintenant. Quelque part au cours de la deuxième semaine, je suis d'abord venu me lever pour parler avec l'équipe, voir ce qui se passe et comment tout le processus se déroule.
Encore une fois, une chose intéressante a été découverte. L'équipe était composée de: 18 développeurs; 8 testeurs; 3 gestionnaires; 2 architectes. Et ils ont tous participé à des rituels communs, c'est-à-dire que plus de 30 personnes se sont levées chaque matin et ont dit ce qu'elles faisaient. Il est clair que la réunion n'a pas duré 5 ou 15 minutes. Personne n'a écouté personne, car tout le monde travaille sur des systèmes différents. Sous cette forme, 2-3 tickets par heure à la séance de toilettage étaient déjà un bon résultat.
La première chose que nous avons faite a été de diviser l'équipe en plusieurs le long de la gamme de produits. Pour différentes sections et systèmes, nous avons identifié des équipes distinctes comprenant des développeurs, des testeurs, des chefs de produit, des analystes commerciaux.
En conséquence, nous avons reçu:
- Réduction des stand-up et rallyes.
- Connaissance des produits.
- Un sentiment d'appartenance. Avant, les gens parlaient toujours des systèmes, ils savaient que quelqu'un d'autre devrait probablement travailler avec leurs bogues, mais pas eux-mêmes.
- Collaboration entre groupes. Vous ne pouvez pas dire que QA ne communiquait pas beaucoup avec les programmeurs auparavant, le produit a fait sa propre chose, etc. Maintenant, ils ont un point de responsabilité commun.
Nous nous sommes principalement concentrés sur l'efficacité, la productivité et la qualité - ce sont les problèmes que nous avons essayé de résoudre par la transformation de l'équipe.
Onzième jour
En train de changer la structure de l'équipe, j'ai découvert comment les
Story Points sont comptés. 1 SP était égal à un jour, et chaque ticket qu'ils contenaient à la fois pour le développement et l'AQ, c'est-à-dire au moins 2 SP.
Comment ai-je trouvé ça?
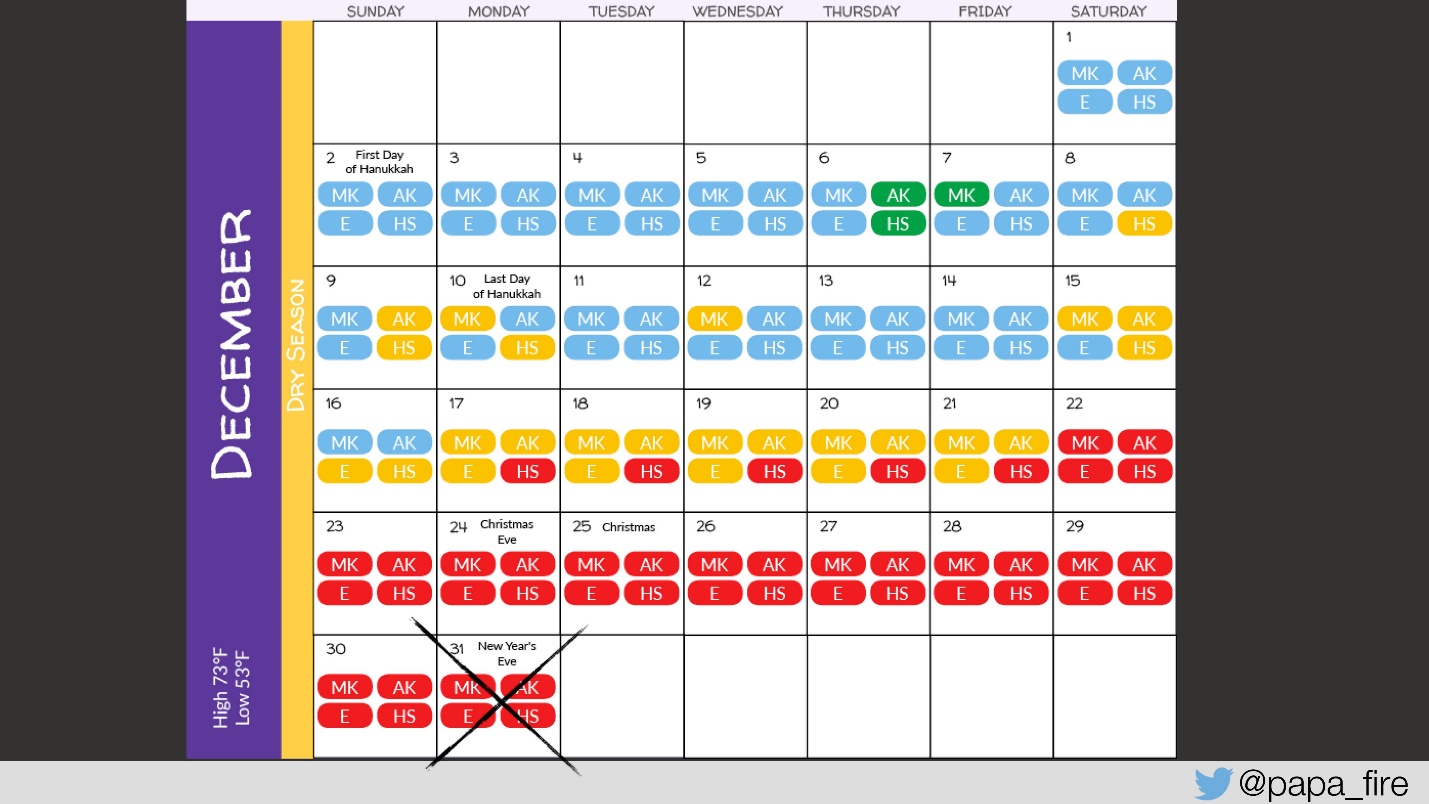
Trouvé un bug: dans l'un des rapports, où la date de début et de fin de la période pour laquelle le rapport est nécessaire est entrée, le dernier jour n'est pas pris en compte. Autrement dit, quelque part dans la demande n'était pas <=, mais simplement <. On m'a dit que ce sont trois Story Points, soit
3 jours .
Après cela, nous:
- Révision du système de notation des Story Points. Désormais, la correction de bugs mineurs qui peuvent être rapidement transmis via le système atteint rapidement l'utilisateur.
- Nous avons commencé à combiner les tickets associés pour le développement et les tests. Auparavant, chaque ticket, chaque bug était un écosystème fermé, qui n'était attaché à rien d'autre. La modification de trois boutons sur une page peut représenter trois tickets différents avec trois processus d'assurance qualité différents au lieu d'un test automatique sur une page.
- Ils ont commencé à travailler avec les développeurs sur une approche pour évaluer les coûts de main-d'œuvre. Trois jours pour changer un bouton n'est pas drôle.
Vingtième jour
Quelque part au milieu du premier mois, la situation s'était un peu stabilisée, j'ai compris ce qui se passait principalement et j'ai déjà commencé à regarder vers l'avenir et à réfléchir à des solutions à long terme.
Objectifs à long terme:
- Plateforme gérée Des centaines de demandes sur chaque page - ce n'est pas grave.
- Tendances prévisibles. Il y avait des pics de trafic périodiques qui, à première vue, n'étaient pas en corrélation avec d'autres mesures - il était nécessaire de comprendre pourquoi cela se produit et d'apprendre à prédire.
- Extension de plateforme. Les affaires sont en croissance constante, de plus en plus d'utilisateurs arrivent, le trafic augmente.
Il a souvent été dit dans le passé: "Réécrivons tout dans [langage / framework], tout fonctionnera mieux!"
Dans la plupart des cas, cela ne fonctionne pas, eh bien, si la réécriture fonctionne. Par conséquent, nous devions créer une feuille de route - une stratégie concrète qui illustre pas à pas comment les objectifs commerciaux seront atteints (ce que nous ferons et pourquoi), qui:
- reflète la mission et les objectifs du projet;
- priorise les objectifs clés;
- contient un calendrier pour leur réalisation.
Avant cela, personne n'avait discuté avec l'équipe de l'objectif des modifications apportées. Cela nécessite les bons taux de réussite. Pour la première fois dans l'histoire de l'entreprise, nous avons défini des KPI pour un groupe technique, et ces indicateurs étaient liés à ceux de l'organisation.
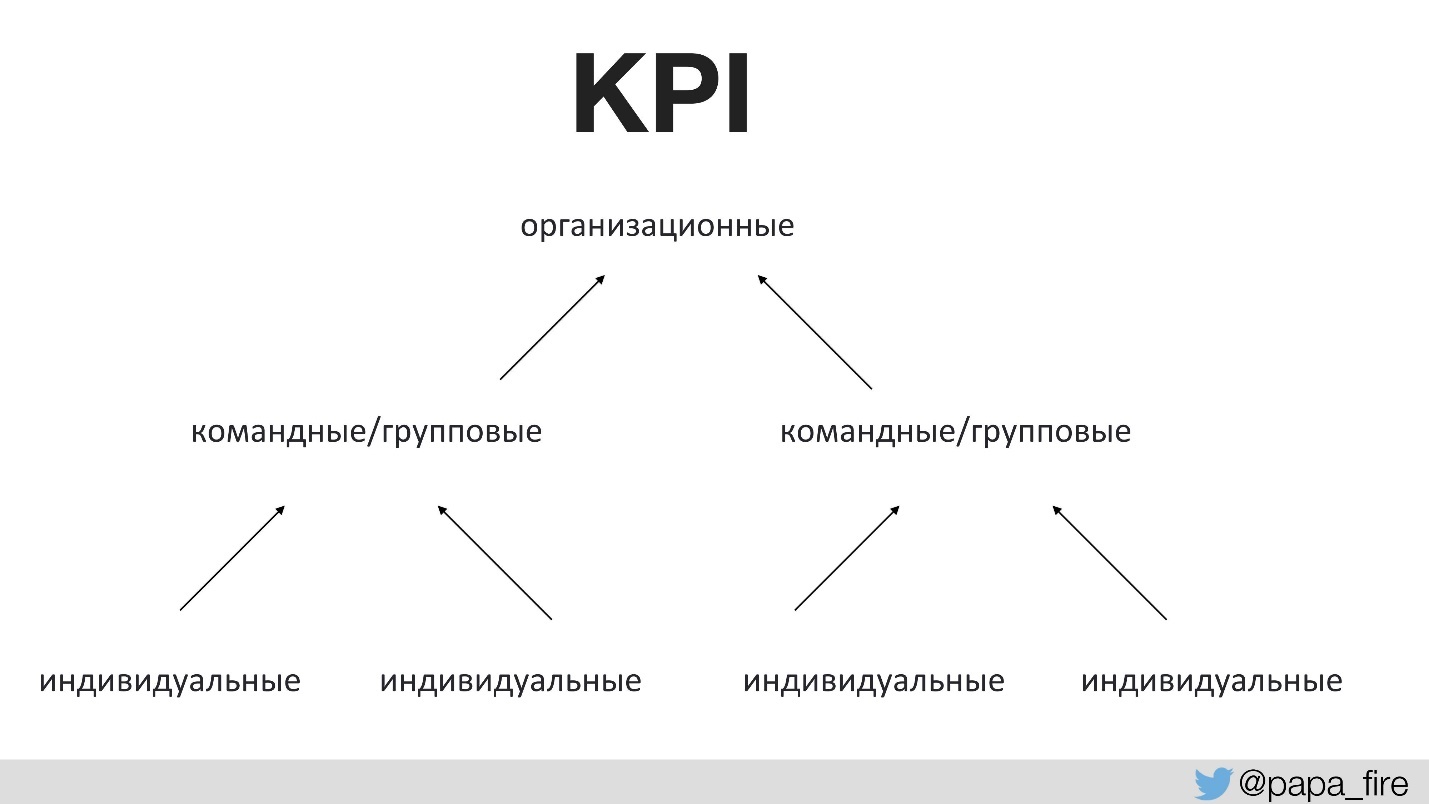
Autrement dit, les indicateurs de performance organisationnels sont pris en charge par les équipes, et les indicateurs de performance d'équipe sont déjà pris en charge par les individus. Sinon, si les KPI technologiques ne sont pas d'accord avec ceux de l'organisation, alors tout le monde tire la couverture sur lui.
Par exemple, l'un des KPI organisationnels consiste à augmenter la part de marché grâce à de nouveaux produits.
Comment pouvez-vous soutenir l'objectif d'avoir plus de nouveaux produits?
- Premièrement, nous voulons passer plus de temps à développer de nouveaux produits au lieu de corriger des bugs. Il s'agit d'une solution logique facile à mesurer.
- Deuxièmement, nous voulons soutenir une augmentation du volume des transactions, car plus la part de marché est importante, plus il y a d'utilisateurs et, par conséquent, plus de trafic.
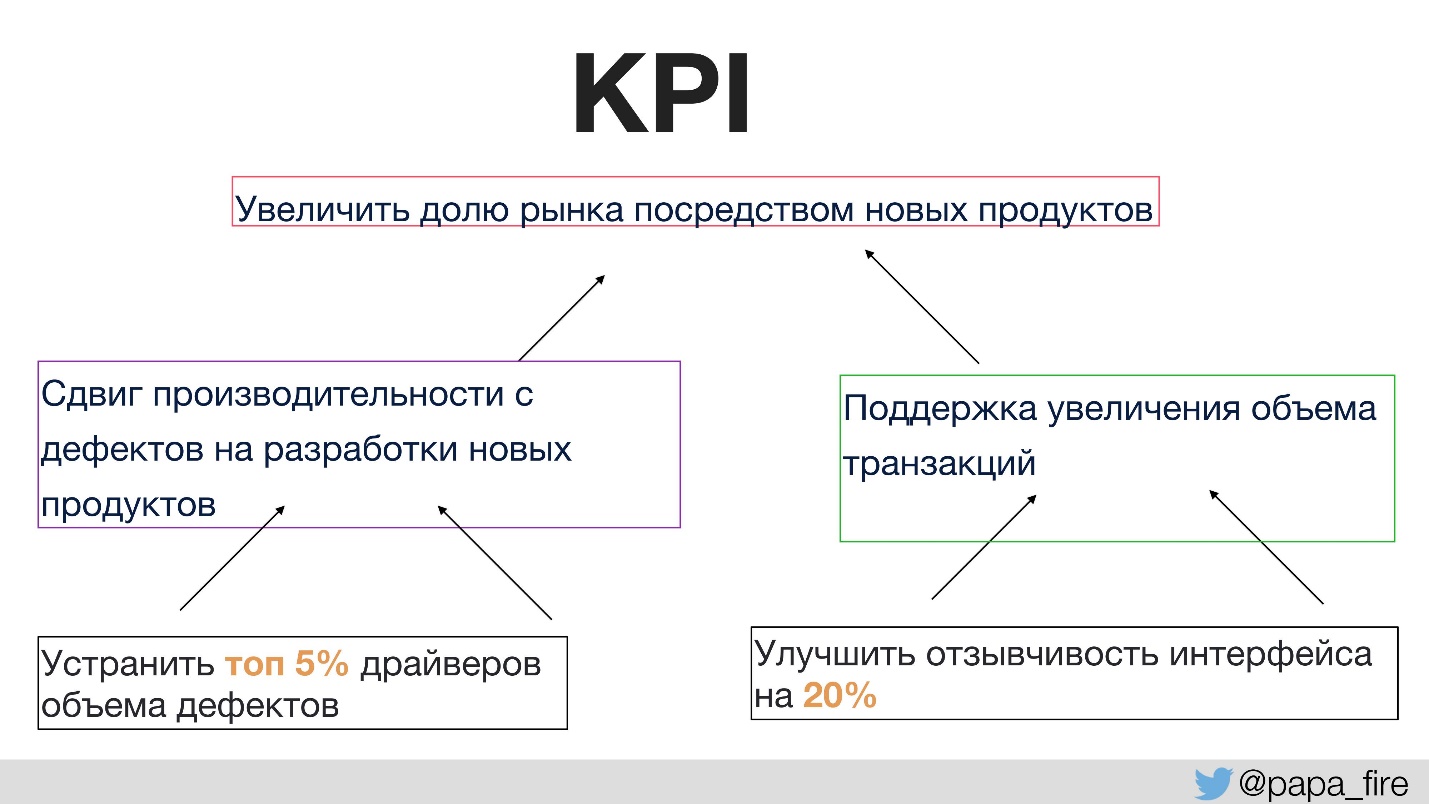
Ensuite, les KPI individuels qui peuvent être exécutés au sein du groupe seront, par exemple, à l'endroit d'où proviennent les principaux défauts. Si vous vous concentrez sur cette section particulière, vous pouvez réduire le nombre de défauts, puis augmenter le temps pour développer de nouveaux produits et pour prendre en charge les KPI organisationnels.
Ainsi, chaque décision, y compris la réécriture du code, doit soutenir les objectifs spécifiques que l'entreprise s'est fixés pour nous (croissance de l'organisation, nouvelles fonctions, recrutement).
Au cours de ce processus, une chose intéressante est apparue qui est devenue une nouvelle non seulement pour les techniciens, mais généralement dans l'entreprise: tous les billets doivent être axés sur au moins un indicateur de performance clé. Autrement dit, si le produit dit qu'il souhaite créer une nouvelle fonctionnalité, la première question doit être posée: «Quel KPI cette fonctionnalité prend-elle en charge?» Si aucune, alors je suis désolé - il semble que ce soit une fonctionnalité inutile.
Trentième jour
À la fin du mois, j'ai découvert une nuance de plus qu'aucune de mes équipes Ops n'avait jamais vu les contrats que nous concluons avec les clients. Vous pouvez demander pourquoi voir les contacts.
- Tout d'abord parce que les SLA sont enregistrés dans des contrats.
- Deuxièmement, les SLA sont tous différents. Chaque client est venu avec ses exigences et le service commercial a signé sans regarder.
Une autre nuance intéressante - dans le contrat avec l'un des plus grands clients, il est écrit que toutes les versions de logiciels prises en charge par la plate-forme doivent être n-1, c'est-à-dire pas la dernière version, mais l'avant-dernière.
Il est clair à quelle distance nous étions du n-1 si la plate-forme était sur ColdFusion et SQL Server 2008, qui en juillet a cessé d'être pris en charge.
Quarante-cinquième jour
Quelque part au milieu du deuxième mois, j'ai eu assez de temps libre pour m'asseoir et faire une
cartographie complète des
flux de valeur pour l'ensemble du processus. Ce sont les étapes nécessaires à suivre, de la création du produit à sa livraison au consommateur, et vous devez les peindre le plus en détail possible.
Vous divisez le processus en petits morceaux et voyez ce qui prend trop de temps, ce qui peut être optimisé, amélioré, etc. Par exemple, combien de temps prend la demande du produit, en passant par le toilettage, quand elle atteint le ticket que le développeur peut prendre, le contrôle qualité, etc. Vous regardez chaque étape en détail et pensez que vous pouvez optimiser.
Quand j'ai fait cela, deux choses ont attiré mon attention:
- pourcentage élevé de tickets de retour de QA aux développeurs;
- L'examen de la demande de retrait a pris trop de temps.
Le problème était qu'il s'agissait de conclusions telles que: cela semble prendre beaucoup de temps, mais nous ne savons pas combien.
«Il est impossible d'améliorer ce qui ne peut pas être mesuré.»
Comment justifier la gravité du problème? Cela passe-t-il des jours ou des heures?
Pour mesurer cela, nous avons ajouté quelques étapes au processus Jira: «prêt pour le développement» et «prêt pour l'AQ», pour mesurer combien de temps chaque ticket attend et combien de fois il revient à une certaine étape.
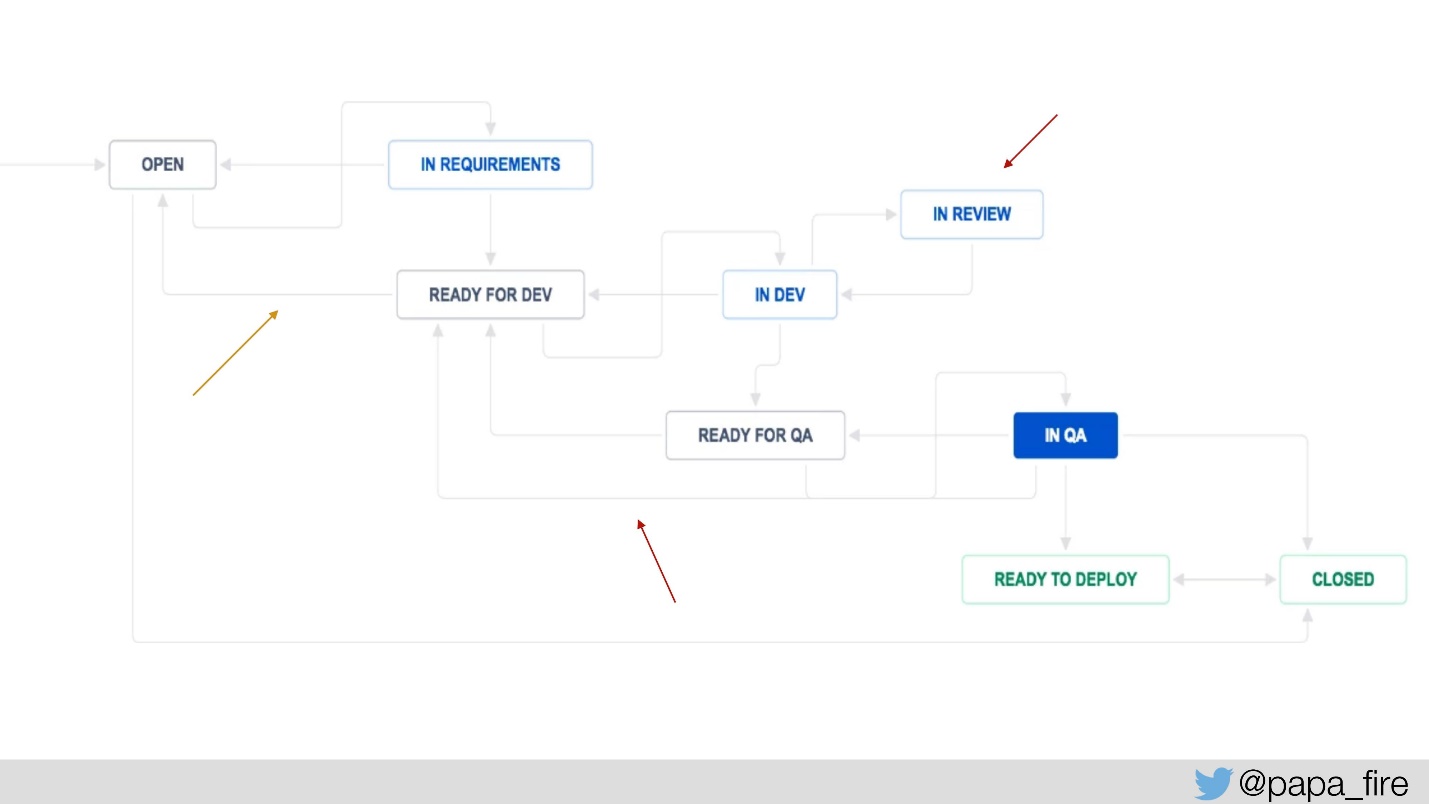
Nous avons également ajouté «en révision» pour savoir combien de billets sont en moyenne en révision, et c'est pourquoi ils dansent déjà. Nous avions des mesures système, maintenant nous avons ajouté de nouvelles mesures et avons commencé à mesurer:
- Efficacité des processus: performance et planifié / livré.
- Qualité du processus: nombre de défauts, défauts du contrôle qualité.
Cela aide vraiment à comprendre ce qui se passe bien et ce qui est mauvais.
Cinquantième jour
Bien sûr, tout cela est bon et intéressant, mais vers la fin du deuxième mois, quelque chose s'est produit qui, en principe, était prévisible, même si je ne m'attendais pas à une telle échelle. Les gens ont commencé à partir, car le sommet a changé. De nouvelles personnes sont arrivées à la direction qui ont commencé à tout changer, et les anciennes ont démissionné. Et généralement dans une entreprise qui a plusieurs années, tous les amis et tous se connaissent.
C'était prévu, mais l'ampleur des licenciements était inattendue. Par exemple, en une semaine, deux chefs d'équipe ont déposé simultanément leur propre licenciement. Par conséquent, je n'ai pas dû oublier d'autres problèmes, mais me concentrer sur la
création d'une équipe . C'est un problème long et difficile, mais elle a dû y faire face parce qu'elle voulait sauver les personnes qui restaient (ou la plupart d'entre elles). Il fallait en quelque sorte réagir au fait que les gens soient partis afin de maintenir la moralité dans l'équipe.
En théorie, c'est bien: une nouvelle personne arrive avec une carte blanche complète qui peut évaluer les compétences de l'équipe et remplacer le personnel. En fait, vous ne pouvez pas simplement faire venir de nouvelles personnes pour autant de raisons.
Il faut toujours un équilibre.- Ancien et nouveau. Nous devons garder les personnes âgées qui peuvent changer et soutenir la mission. Mais en même temps, nous devons apporter du sang neuf, nous en parlerons un peu plus tard.
- Expérience. J'ai beaucoup parlé avec de bons juniors qui brûlaient et voulaient travailler pour nous. Mais je ne pouvais pas les prendre, car il n'y avait pas assez de seigneurs pour soutenir les juniors et être des mentors pour eux. Il fallait d'abord gagner le sommet et ensuite seulement la jeunesse.
- Carotte et bâton.
Je n'ai pas de bonne réponse à la question de savoir quel équilibre est bon, comment le maintenir, combien de personnes quitter et combien pousser. Il s'agit d'un processus purement individuel.
Jour cinquante et unième
J'ai commencé à regarder de près l'équipe pour comprendre qui je suis et je me souviens encore une fois:
"La plupart des problèmes sont des problèmes avec les gens."
J'ai trouvé que dans l'équipe, en tant que telle - les développeurs et les opérations - ont trois gros problèmes:
- Satisfaction de l'état actuel des choses.
- Manque de responsabilité - car personne n'a jamais apporté les résultats du travail des artistes interprètes ou exécutants pour influencer l'entreprise.
- Peur du changement.

Le changement vous fait toujours sortir de votre zone de confort, et plus les jeunes le sont, plus ils n'aiment pas le changement parce qu'ils ne comprennent pas pourquoi et ne comprennent pas comment. La réponse la plus courante que j'ai entendue était: "Nous n'avons jamais fait ça." Et cela arriva au point d'absurdité totale - les moindres changements ne passèrent pas sans que quelqu'un ne s'indigne. Et peu importe à quel point les changements concernaient leur travail, les gens ont dit: «Non, pourquoi? Cela ne fonctionnera pas. "
Mais vous ne pouvez pas vous améliorer sans rien changer.
J'ai eu une conversation absolument absurde avec un employé, je lui ai dit mes idées d'optimisation, auxquelles il m'a dit:
- Ah, tu n’as pas vu ce que nous avions l’année dernière!
"Et alors?"
"Maintenant beaucoup mieux qu'il ne l'était."
"Alors ça ne pourrait pas être mieux?"
- Pourquoi?Bonne question - pourquoi? Comme si, si c'est mieux maintenant qu'il ne l'était, alors tout va bien. Cela conduit à un manque de responsabilité, ce qui est tout à fait normal en principe. Comme je l'ai dit, l'équipe technique était un peu distante. L'entreprise pensait qu'ils devraient l'être, mais
personne n'a jamais fixé de normes . Ils n'ont jamais vu SLA dans le support technique, donc c'était tout à fait «acceptable» pour le groupe (et cela m'a le plus frappé):
- 12 secondes de téléchargement;
- 5 à 10 minutes d'interruption à chaque version;
- Le dépannage critique prend des jours et des semaines;
- absence de service 24x7 / sur appel.
Personne n'a jamais essayé de demander pourquoi nous ne devrions pas le faire mieux, et personne n'a jamais réalisé que cela ne devrait pas l'être.
En prime, il y avait un autre problème: le
manque d'expérience . Les seniors sont partis et la jeune équipe restante a grandi sous le régime précédent et a été empoisonnée par celui-ci.
Pour tout cela, les gens avaient aussi peur d'échouer, de paraître incompétents. Cela s'exprime dans le fait que, premièrement,
ils n'ont en aucun cas demandé de l'aide . Combien de fois avons-nous parlé en groupe et individuellement, et j'ai dit: "Posez une question si vous ne savez pas comment faire quelque chose." J'ai confiance en moi et je sais que je peux résoudre n'importe quel problème, mais cela prendra du temps. Par conséquent, si vous pouvez demander à quelqu'un qui sait comment le résoudre en 10 minutes, je vous le demanderai. Moins vous avez d'expérience, plus vous avez peur de demander parce que vous pensez que vous serez considéré comme incompétent.
Cette peur de poser une question se manifeste sous des formes intéressantes. Par exemple, vous demandez: «Comment faites-vous avec cette tâche?» - «Il reste quelques heures, je la termine déjà.» Le lendemain, vous demandez à nouveau, vous obtenez la réponse que tout va bien, mais il y avait un problème, il sera prêt d'ici la fin de la journée. Un autre jour passe, et jusqu'à ce que vous appuyiez contre le mur et obligiez quelqu'un à parler, tout continue. Une personne veut résoudre le problème lui-même, il pense que s'il ne le résout pas, ce sera un gros échec.
C'est pourquoi les
développeurs ont exagéré . C'est cette blague quand ils ont discuté d'une tâche spécifique, ils m'ont donné un tel chiffre que j'ai été très surpris. À laquelle on m'a dit que dans les estimations, le développeur inclut le temps que le ticket reviendra de QA, car ils y trouveront des erreurs, et le temps que PR prendra, et le temps que les personnes qui ont besoin de le voir seront occupées - c'est-à-dire tout c'est seulement possible.
Deuxièmement, les personnes qui ont peur de paraître incompétentes
analysent inutilement . Lorsque vous dites ce qui doit être fait exactement, cela commence: «Non, mais si nous pensons ici?» En ce sens, notre entreprise n'est pas unique, c'est un problème standard pour les jeunes.
En réponse, j'ai introduit les pratiques suivantes:
- La règle est de 30 minutes. Si, en une demi-heure, vous ne pouvez pas résoudre le problème, demandez à quelqu'un de vous aider. Cela fonctionne avec un succès variable, car les gens ne demandent toujours pas, mais au moins le processus a commencé.
- Exclure tout, sauf l'essentiel , pour estimer le terme de la tâche, c'est-à-dire ne considérer que le temps qu'il faut pour écrire le code.
- Formation continue pour ceux qui analysent trop. C'est juste un travail constant avec les gens.
Soixantième jour
Pendant que je faisais tout cela, il est temps de trouver le budget. Bien sûr, j'ai trouvé beaucoup de choses intéressantes dans l'endroit où nous avons dépensé l'argent. Par exemple, nous avions un rack entier dans un centre de données séparé, sur lequel il y avait un serveur FTP utilisé par un client. Il s'est avéré que "... nous avons déménagé, mais il est resté, nous ne l'avons pas changé." C'était il y a 2 ans.
La facture du service cloud était particulièrement intéressante. Je suis sûr que la principale raison de la facture importante des services cloud est que les développeurs ont un accès illimité aux serveurs pour la première fois de leur vie. Ils n'ont pas besoin de demander: «Donnez-moi un serveur de test», peuvent-ils accepter. De plus, les développeurs veulent toujours construire un système aussi cool pour que Facebook avec Netflix envie.
Mais les développeurs n'ont aucune expérience dans l'achat de serveurs et la capacité de déterminer la bonne taille de serveurs, car ils n'en avaient pas besoin auparavant. Et généralement, ils ne comprennent pas complètement la différence entre l'évolutivité et les performances.
Résultats de l'inventaire:
- Nous avons quitté un centre de données.
- Résiliation du contrat avec 3 services de journalisation. Parce que nous en avions 5 - chaque développeur qui a commencé à jouer avec quelque chose en a pris un nouveau.
- Désactivé 7 systèmes AWS. Encore une fois, personne n'a arrêté les projets morts, ils ont tous continué à travailler.
- Coûts logiciels réduits de 6 fois.
Soixante-quinzième jour
Le temps a passé et après deux mois et demi, j'ai dû rencontrer le conseil d'administration. Notre conseil d'administration n'est ni meilleur ni pire que les autres, il veut tout savoir comme tous les conseils d'administration. Les gens investissent de l'argent et veulent comprendre dans quelle mesure ce que nous faisons s'inscrit dans les KPI définis.
Le conseil d'administration reçoit chaque mois de nombreuses informations: le nombre d'utilisateurs, leur croissance, les services qu'ils utilisent et comment, la productivité et la productivité, et enfin la vitesse moyenne de chargement des pages.
Le seul problème est que je crois que la valeur moyenne est du mal pur. Mais le conseil d'administration est très difficile à expliquer. Ils sont habitués à fonctionner avec des nombres agrégés, et non par exemple par l'étalement du temps de chargement par seconde.
À cet égard, il y avait des points intéressants. Par exemple, j'ai dit que vous devez répartir le trafic entre les différents serveurs Web en fonction du type de contenu.

Autrement dit, ColdFusion passe par Jetty et nginx et lance des pages. Et les images, JS et CSS passent par un nginx distinct avec leurs propres configurations. Il s'agit d'une pratique assez standard que j'ai
écrite il y a quelques années. , … 200 .
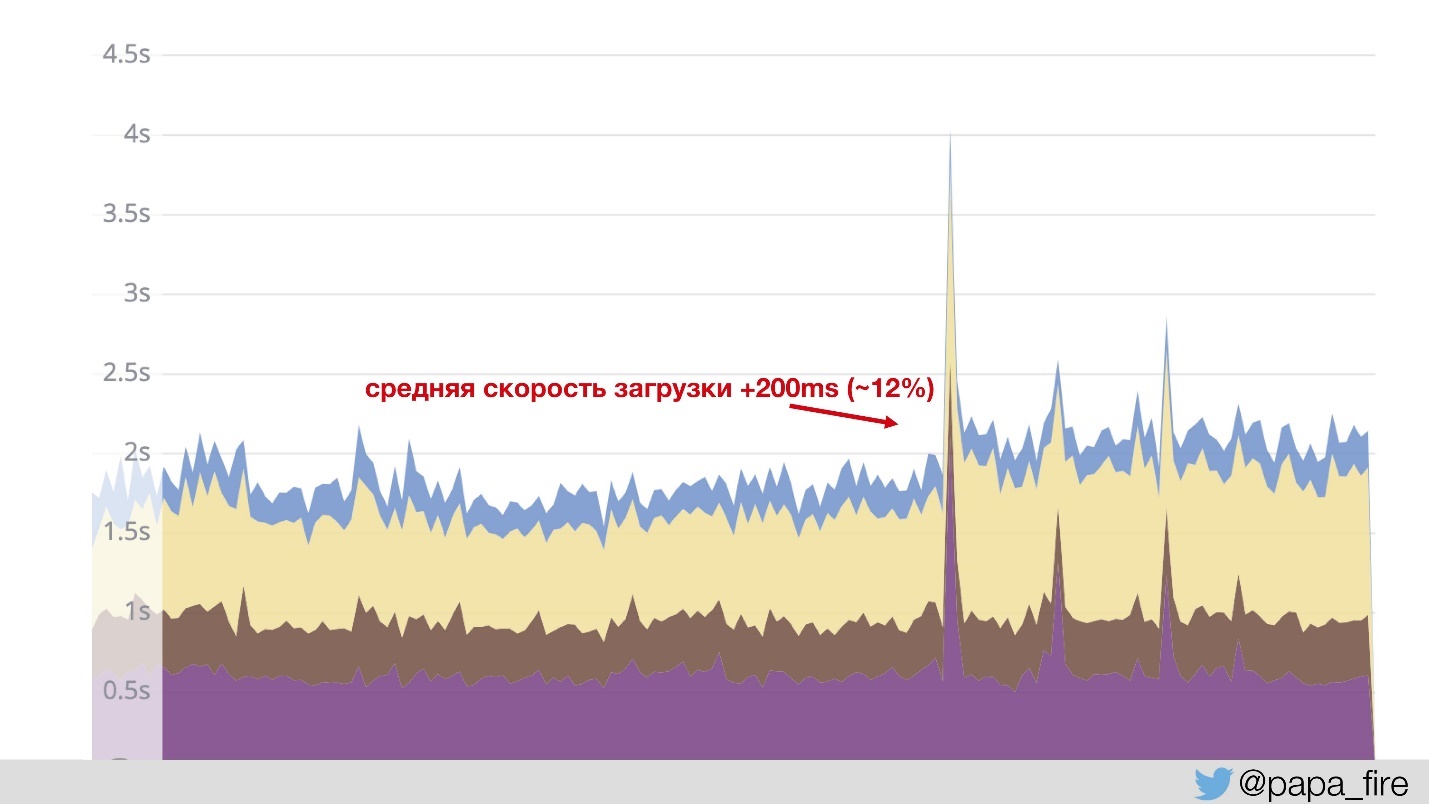
, , Jetty. — . , , , - 12%?
, — . , , .

— , . . - , .
Conclusion
. , , , . , ,
SEQUENCE .
nextID , .
, . , , — .

. , :
.
twitter ,
facebook medium .
legacy : , . c DevOpsConf , . youtube , , DevOps.