
Nous devenons ce que nous voyons. Nous façonnons d'abord les outils, puis les outils nous façonnent.
—Marshal McLuhan
Je tiens à remercier sincèrement et à exprimer ma gratitude à mon bon ami Ricardo Sueiras pour sa revue, sa contribution et pour ne pas m'avoir laissé laisser cet article inachevé. Ricardo, tu n'es qu'une légende!
Il est important de se rappeler que l'ingénierie du chaos ne se produit pas lorsque vous libérez des singes et entrez sans discernement des échecs. L'ingénierie du chaos est une technique d' expérimentation bien définie et formalisée .
"L'ingénierie du chaos implique une observation attentive, un scepticisme sévère à l'égard de l'objet d'observation, car les hypothèses cognitives faussent l'interprétation des résultats. Cette technique implique la formulation d'hypothèses par induction basée sur des observations similaires; des tests expérimentaux et basés sur des mesures de conclusions tirées d'hypothèses similaires; ajustement ou rejet d'hypothèses basées sur des résultats expérimentaux "
—Wikipedia
L'ingénierie du chaos commence par une compréhension de l'état stable du système avec lequel vous avez affaire, la formulation ultérieure de l'hypothèse, et enfin l'expérience qui la confirme, contribuant à augmenter la marge de sécurité du système.
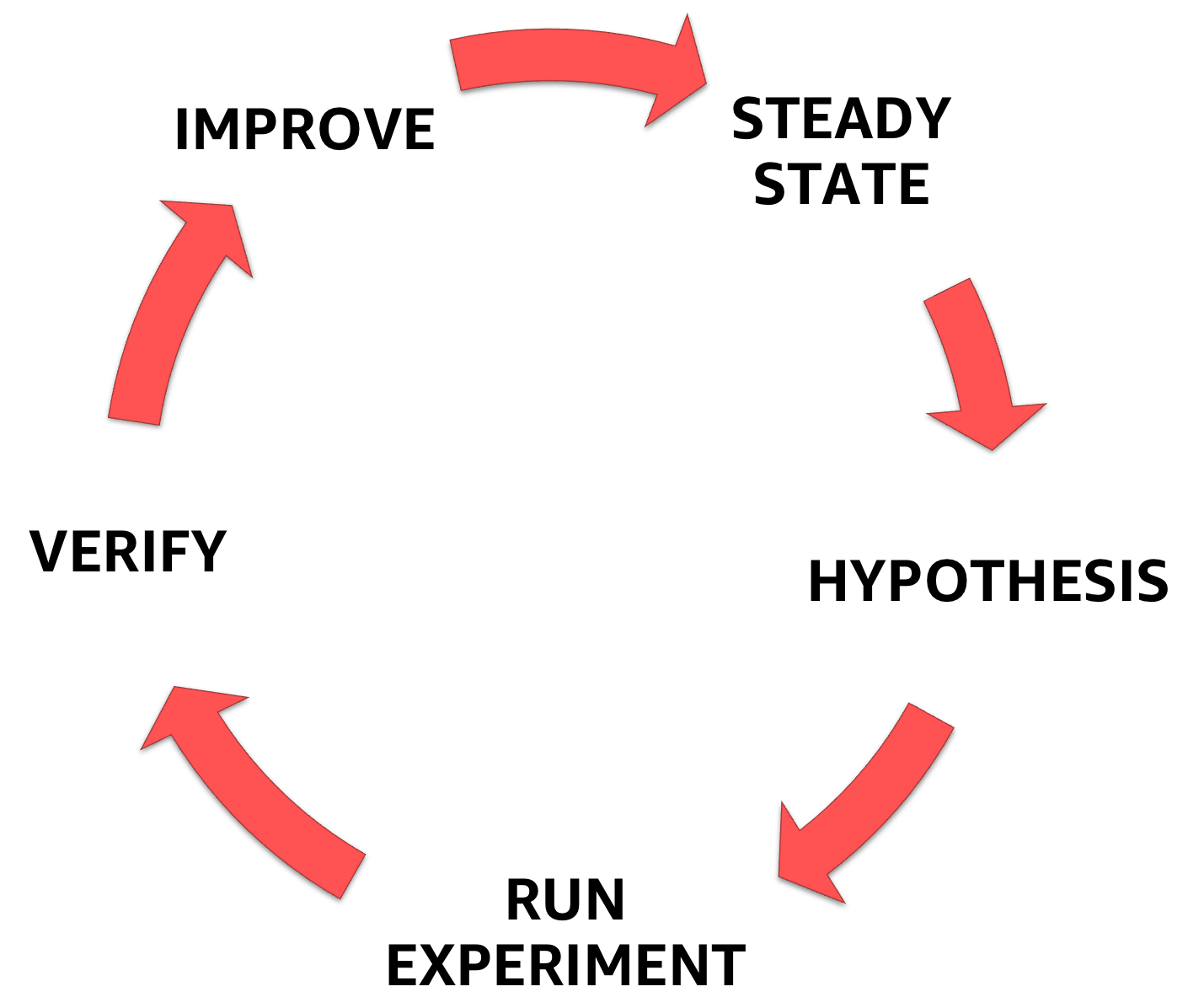
Phases d'ingénierie du chaos
Dans la première partie d'une série d'articles, j'ai présenté l'ingénierie du chaos et discuté de chaque étape de la méthodologie décrite ci-dessus.
Dans la deuxième partie , j'ai examiné les domaines dans lesquels vous devez investir lors de la conception d'expériences sur l'ingénierie du chaos et comment choisir les bonnes hypothèses.
Dans cette troisième partie, je me concentrerai sur l'expérience elle-même et présenterai une sélection d'outils et de méthodes couvrant un large éventail d'échecs.
La liste n'est pas exhaustive, mais pour commencer, et pour alimenter la réflexion, elle devrait suffire.
Introduction de l'échec - qu'est-ce que c'est et à quoi ça sert?
L'échec est utilisé pour vérifier que la réponse du système répond aux spécifications dans des conditions de charge normales. Pour la première fois, cette technique a été utilisée lorsque des défaillances ont été introduites au niveau «fer» - au niveau des contacts, en modifiant les signaux électriques sur les appareils.
En programmation, l'introduction de pannes contribue à améliorer la stabilité du système logiciel et vous permet de corriger les faiblesses de la résistance aux pannes potentielles du système. C'est ce qu'on appelle le dépannage. Il aide également à évaluer les dommages causés par une défaillance - c.-à-d. rayon de dommages, avant même que la défaillance ne se produise dans l'environnement de production. C'est ce qu'on appelle la prédiction de pannes.
L'introduction de défaillances présente plusieurs avantages clés, aidant à:
- Comprendre et pratiquer les réponses aux accidents et incidents.
- comprendre les effets d'échecs réels.
- comprendre l'efficacité et les limites des mécanismes de tolérance aux pannes.
- éliminer les erreurs de conception et détecter les points de défaillance courants.
- comprendre et améliorer l'observabilité du système.
- comprendre le rayon de l'échec de l'échec et le réduire.
- comprendre la propagation des erreurs entre les composants du système.
Catégories d'échec
Il existe 5 catégories d'introduction de l'échec: au niveau de (1) ressource; (2) réseau et dépendances; (3) application, processus et service; (4) les infrastructures; et (5) le niveau humain **.
Ensuite, j'examinerai chacune des catégories et donnerai un exemple d'introduction d'échecs pour chacune d'elles. Je considérerai également un exemple d'introduction d'échecs et d'instruments d'orchestration tout-en-un.
** Important! Dans cet article, je ne parle pas de l'introduction d'échecs au niveau humain, mais je vais l'examiner dans la suite.
1 - Introduction de l'échec au niveau des ressources, alias manque de ressources.
Oui, les technologies cloud nous ont appris que les ressources sont presque illimitées, mais je m'empresse de vous décevoir: elles ne sont pas infinies. Instance, conteneur, fonction, etc. - indépendamment de l'abstraction, les ressources finissent par disparaître. Aller au-delà de l'épuisement maximal autorisé des ressources est appelé épuisement.

Le manque de ressources imite une attaque par déni de service , mais pas celle habituelle, pour infiltrer le serveur prévu. Cette introduction d'échecs est probablement répandue, car, probablement, elle n'est pas difficile à utiliser.
Épuisement des ressources CPU, mémoire et E / S
L'un de mes outils préférés est le stress-ng, la correspondance de l' outil de test de stress original , écrit par Amos Waterland .
Avec stress-ng, les défauts peuvent être saisis en chargeant divers sous-systèmes physiques de l'ordinateur, ainsi qu'en contrôlant les interfaces du cœur du système à l'aide de tests de stress. Les tests de stress suivants sont disponibles: CPU, cache CPU, périphérique, E / S, interruption, système de fichiers, mémoire, réseau, OS, pipeline, planificateur et VM. Les pages de manuel incluent une description complète de tous les tests de résistance disponibles, et il n'y en a que 220!
Voici quelques exemples pratiques d'utilisation du stress-ng:
La charge sur le processeur matrixprod donne le bon mélange d'opérations avec la mémoire, le cache et la virgule flottante. Cela, peut-être. La meilleure façon de bien réchauffer le CPU.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60s
La charge iomix-bytes écrit N-octets pour chaque iomix gestionnaire iomix ; La valeur par défaut est 1 Go et est idéale pour effectuer un test de stress d'E / S. Dans cet exemple, je définirai 80% de l'espace libre sur le système de fichiers.
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s
vm-bytes idéal pour les tests de stress mémoire. Dans cet exemple, stress-ng exécute 9 tests de stress de la mémoire virtuelle, qui consomment ensemble 90% de la mémoire disponible par heure. Ainsi, chaque test tress consomme 10% de la mémoire disponible.
❯ stress-ng --vm 9 --vm-bytes 90% -t 60s
Espace disque insuffisant sur les disques durs
dd est un utilitaire de ligne de commande compilé pour convertir et copier des fichiers. Cependant, dd peut lire et / ou écrire à partir de fichiers de périphériques spéciaux tels que /dev/zero et /dev/random pour des tâches telles que la sauvegarde du secteur de démarrage d'un disque dur et l'obtention d'une quantité fixe de données aléatoires. Ainsi, il peut être utilisé pour introduire des pannes sur le serveur et simuler un débordement de disque. Vos fichiers journaux ont-ils débordé le serveur et abandonné l'application? Donc, dd aidera - et ça fera mal!
Utilisez dd très soigneusement. Entrez la mauvaise commande - et les données sur le disque dur seront effacées, détruites ou écrasées!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &
Ralentissement de l'API d'application
Les performances, la résilience et l'évolutivité de l'API sont importantes. Les API sont essentielles pour créer des applications et développer votre entreprise.
Le test de charge est un excellent moyen de tester votre application avant sa mise en production. C'est aussi une méthode intéressante de chargement de stress, car elle révèle souvent des exceptions et des limitations qui, dans d'autres circonstances, seraient restées invisibles avant de rencontrer un trafic réel.
wrk est un outil d'analyse comparative HTTP qui met à rude épreuve les systèmes. J'aime particulièrement tester les vérifications d'accessibilité des API, surtout en ce qui concerne les vérifications de performances , car elles révèlent beaucoup de choses concernant les décisions de conception au niveau du code développeur: comment le cache est-il configuré? Comment la limite de vitesse est-elle mise en œuvre? Le système priorise-t-il les contrôles d'intégrité concernant les équilibreurs de charge?
Voici par où commencer:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
Cette commande démarre 12 threads et maintient 400 connexions HTTP ouvertes pendant 20 secondes.
2 - Présentation des échecs et des dépendances au niveau du réseau
Le livre de Peter Deutsch , The Eight Fallacies of Distributed Computing, est un ensemble d'hypothèses que les développeurs font lors de la conception de systèmes distribués. Et puis la réponse vole sous forme d'inaccessibilité, et il faut tout refaire. Ces hypothèses erronées sont:
- Le réseau est fiable.
- Le retard est 0.
- La bande passante est infinie.
- Le réseau est sécurisé.
- La topologie ne change pas.
- Il n'y a qu'un seul administrateur.
- Coût de transfert 0.
- Le réseau est homogène.
Cette liste est un bon point de départ pour choisir le basculement si vous testez pour voir si votre système distribué peut gérer les pannes de réseau.
Présentation de la latence, de la perte et de la panne du réseau
Présentation de la latence, de la perte ou de la perte du réseau
tc ( traffic control ) est un outil en ligne de commande Linux utilisé pour configurer le planificateur de lots du noyau Linux. Il définit la façon dont les paquets sont mis en file d'attente pour la transmission et la réception dans l'interface réseau. Les opérations incluent la mise en file d'attente, la définition de stratégie, la classification, la planification, la mise en forme et la perte.
tc peut être utilisé pour simuler le retard et la perte de paquets pour les applications UDP ou TCP ou pour limiter l'utilisation de la bande passante d'un service particulier - pour simuler les conditions du trafic Internet.
- introduction d'un retard de 100 ms
#Start ❯ tc qdisc add dev etho root netem delay 100ms #Stop ❯ tc qdisc del dev etho root netem delay 100ms
- introduction d'un retard de 100 ms avec un delta de 50 ms
#Start ❯ tc qdisc add dev eth0 root netem delay 100ms 50ms #Stop ❯ tc qdisc del dev eth0 root netem delay 100ms 50ms
- dommages à 5% des paquets réseau
#Start ❯ tc qdisc add dev eth0 root netem corrupt 5% #Stop ❯ tc qdisc del dev eth0 root netem corrupt 5%
- 7% de perte de paquets avec une corrélation de 25%
#Start ❯ tc qdisc add dev eth0 root netem loss 7% 25% #Stop ❯ tc qdisc del dev eth0 root netem loss 7% 25%
Important! 7% suffisent pour que l'application TCP ne baisse pas.
Jouer avec "/ etc / hosts" - une table de recherche statique pour les noms d'hôtes
/etc/hosts est un simple fichier texte qui associe les adresses IP aux noms d'hôte, une ligne à la fois. Chaque nœud nécessite une ligne contenant les informations suivantes:
IP_address canonical_hostname [aliases...]
Le fichier d'hôtes est l'un des nombreux systèmes qui accèdent aux nœuds du réseau sur un réseau informatique et traduisent les noms d'hôtes que les utilisateurs comprennent en adresses IP. Et oui, vous l’avez deviné: grâce à lui, il est pratique de tricher sur les ordinateurs. Voici quelques exemples:
- Bloquer l'accès à l'API DynamoDB pour l'instance EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
- Bloquer l'accès à l'API EC2 à partir d'une instance EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
Regardez en direct: premièrement, l'API EC2 est disponible et ec2 describe-instances revient avec succès.
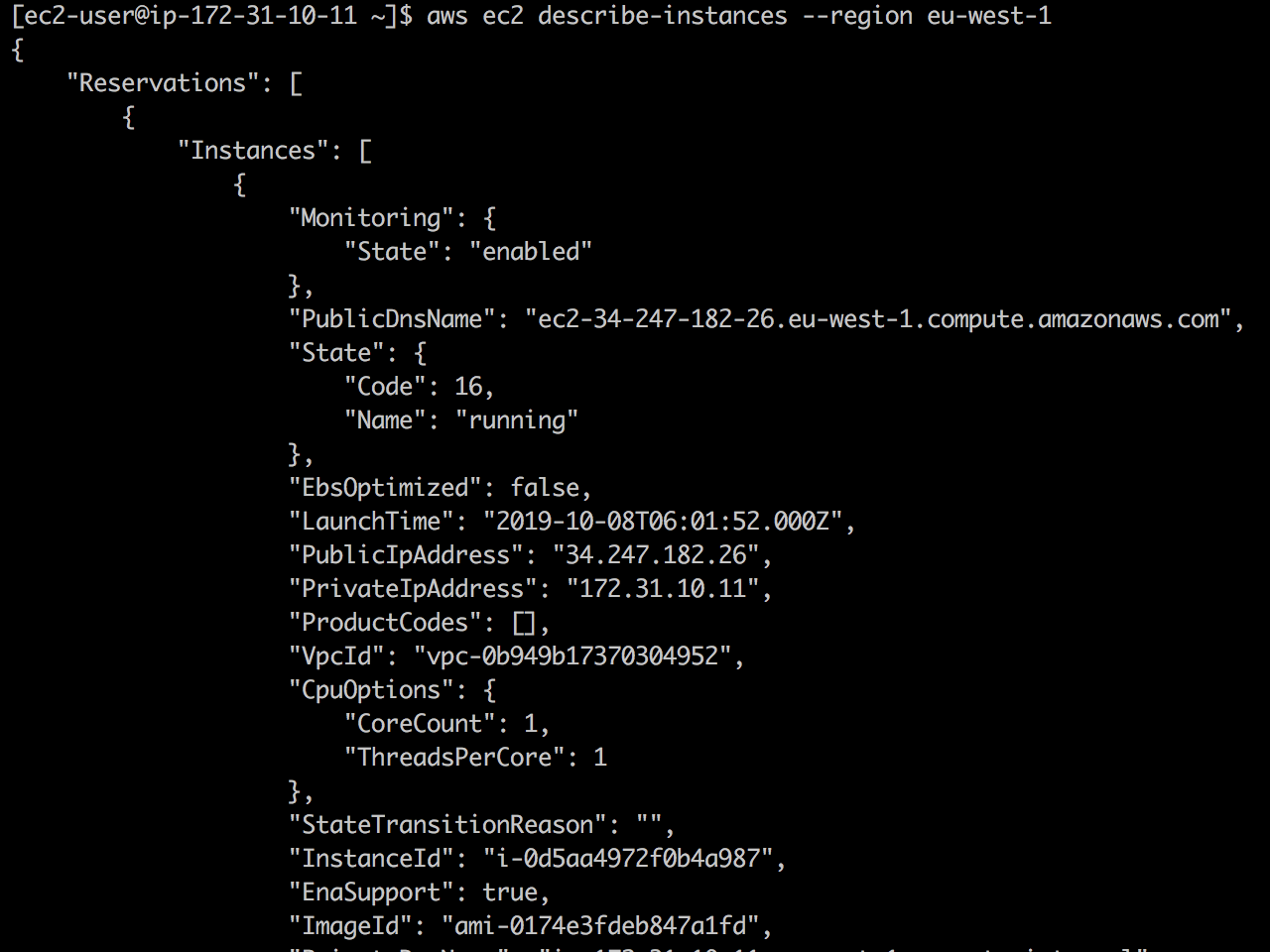
Une fois que j'ai ajouté 127.0.01 ec2.eu-west-1.amazonaws.com à /etc/hosts , et l'appel d'appel EC2 tombe.

Bien sûr, cela fonctionne pour toutes les API AWS.
Je voudrais vous raconter une blague sur le DNS ...

... mais, je le crains, il ne vous parviendra que le deuxième jour. Je veux dire, après 24 heures.
Le 21 octobre 2016, en raison de l' attaque DDoS Dyn, un nombre décent de plateformes et de services en Europe et en Amérique du Nord n'étaient pas disponibles. Selon le rapport ThousandEyes sur les performances DNS dans le monde en 2018 , 60% des entreprises et des fournisseurs SaaS dépendent toujours d'un fournisseur DNS source unique et deviennent ainsi vulnérables aux pannes DNS. Et comme il n'y aura pas d'Internet sans DNS, ce sera formidable de simuler une panne DNS pour évaluer votre résilience à la prochaine panne DNS.
Le Blackholing est une méthode par laquelle ils réduisent traditionnellement les dégâts d'une attaque DDoS . Le mauvais trafic réseau est acheminé vers le trou noir et vidé à vide. La version de /dev/null pour travailler sur le réseau :-) Vous pouvez l'utiliser pour simuler la perte de trafic réseau ou le protocole du même DNS , par exemple.
Pour cette tâche, vous avez besoin de l'outil iptables , qui est utilisé pour configurer, maintenir et vérifier le paquet IP dans le noyau Linux.
Pour obtenir le trafic DNS via le trou noir, essayez ceci:
#Start ❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP #Stop ❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROP
Introduction d'échecs à l'aide de Toxiproxy.
Les outils Linux comme tc et iptables un - mais pas le seul - problème sérieux. Ils nécessitent une autorisation root pour s'exécuter, ce qui crée des problèmes pour certaines organisations et certains environnements. Veuillez aimer et favoriser - Toxiproxy !
Toxiproxy est un proxy TCP open source développé par l'équipe d'ingénieurs Shopify . Il permet de simuler des conditions de réseau et de système chaotiques ou des systèmes réels. Placez-le entre les différents composants de l'architecture comme indiqué ci-dessous.
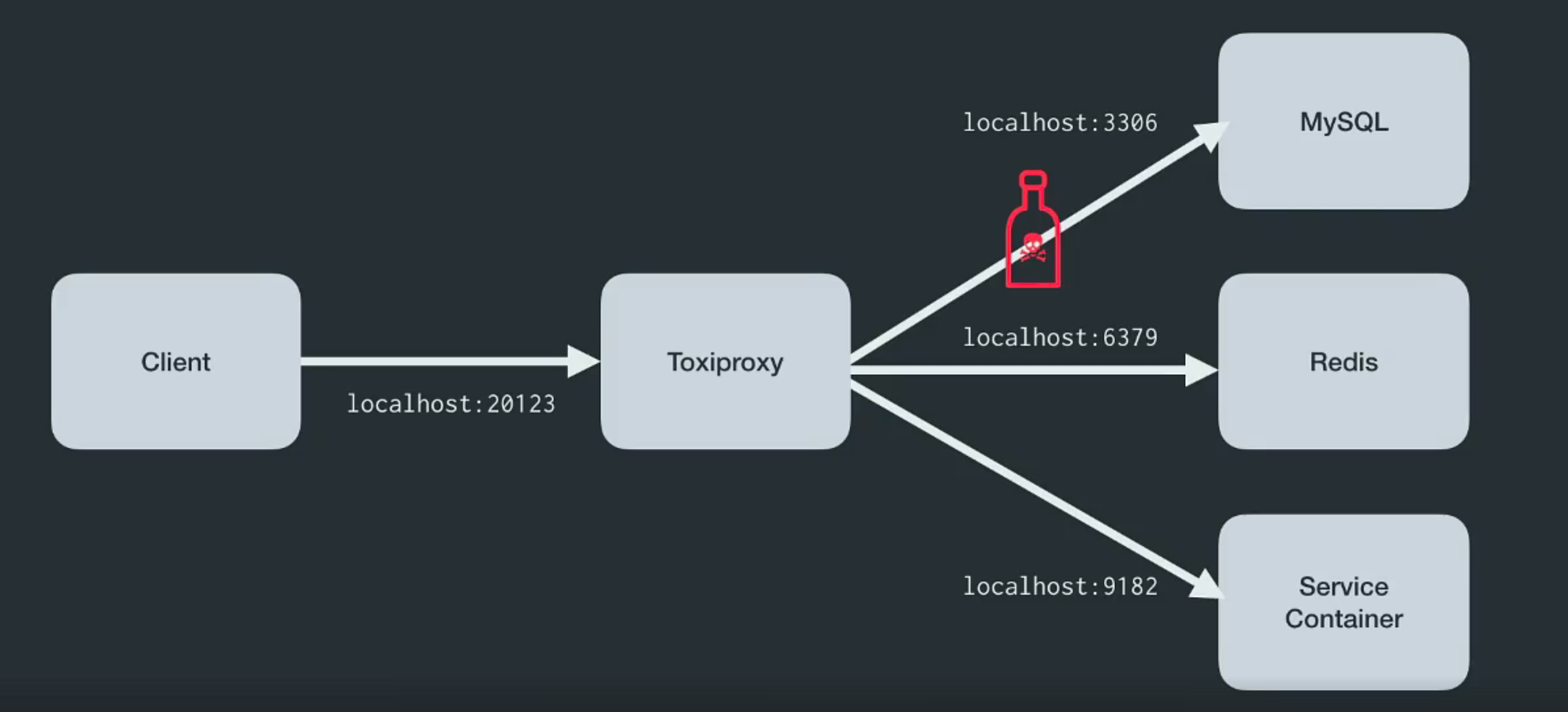
Il a été créé spécifiquement pour les environnements de test, de CI et de développement, et introduit une confusion prédéfinie ou aléatoire contrôlée par les paramètres. Toxiproxy utilise des substances toxiques pour manipuler la relation entre le client et le code développeur, et il peut être configuré via l'API HTTP . Et pour lui, dans le kit, il y a suffisamment de substances toxiques pour commencer.
L'exemple suivant montre comment Toxiproxy fonctionne avec le code client toxics en introduisant un délai de 1000 ms dans la connexion entre mon client Redis, redis-cli et Redis lui-même.
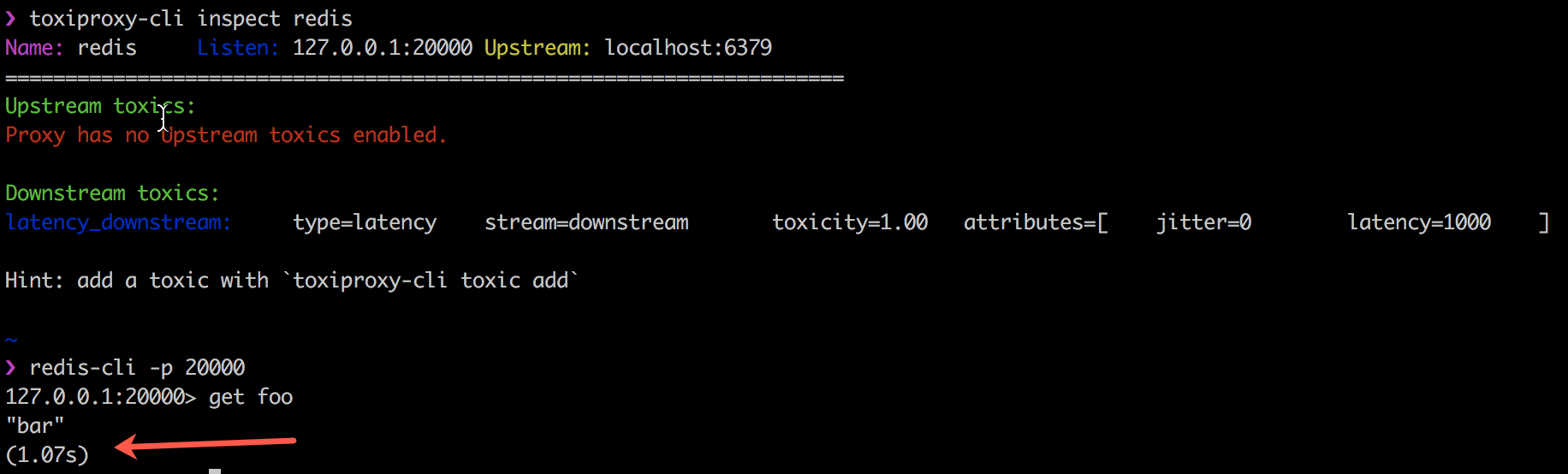
Toxiproxy est utilisé avec succès par Shopify dans tous les environnements de production et de développement depuis octobre 2014. Plus d'informations sur leur blog .
3 - Introduction de défaillances au niveau de l'application, du processus et du service
Le logiciel tombe. C’est un fait. Et tu fais quoi? Dois-je me connecter via SSH sur le serveur et redémarrer le processus ayant échoué? Les systèmes de contrôle de processus fournissent des fonctions de contrôle d'état ou de changement d'état du type démarrage, arrêt, redémarrage. Les systèmes de contrôle sont généralement utilisés pour assurer un contrôle stable du processus. systemd est un tel outil, fournissant les briques de contrôle de processus de base pour Linux. Supervisord offre le contrôle de plusieurs processus sur des systèmes d'exploitation tels qu'UNIX.
Lorsque vous déployez l'application, vous devez utiliser ces outils. Il est certainement bon de tester les dommages causés par la destruction de processus critiques. Assurez-vous de recevoir des alertes et que le processus redémarre automatiquement.
- tuer les processus Java
❯ pkill -KILL -f java #Alternative ❯ pkill -f 'java -jar'
- tuer les processus Python
❯ pkill -KILL -f python
Bien sûr, vous pouvez utiliser la commande pkill pour tuer plusieurs autres processus en cours d'exécution sur le système.
Présentation des échecs de base de données
S'il y a des messages d'échec que les opérateurs n'aiment pas recevoir, ce sont ceux liés aux échecs de la base de données. Les données valent leur pesant d'or et, par conséquent, chaque fois qu'une base de données plante, le risque de perdre les données des clients augmente.

Ce sera juste un entretien facile. Et-et-et-et-et-ainsi ... tout est tombé
Parfois, la capacité de récupérer des données et de mettre la base de données en état de fonctionnement le plus rapidement possible décide de l'avenir de l'entreprise. Malheureusement, il n'est pas toujours facile de se préparer à divers modes de défaillance de la base de données - et beaucoup d'entre eux n'apparaîtront que dans l'environnement de production.
Cependant, si vous utilisez Amazon Aurora , vous pouvez tester la résilience du cluster de base de données Amazon Aurora aux pannes à l'aide de demandes de basculement .
Introduction à Amazon Aurora Crash
Les demandes d'échec sont émises sous forme de commandes SQL vers une instance Amazon Aurora et vous permettent de planifier une simulation de l'un des événements suivants:
- Échec d'une instance de base de données en écriture.
- Échec de la réplique Aurora.
- Échec du disque.
- Surcharge du disque.
Lors de l'envoi d'une demande d'échec, vous devez également spécifier la durée pendant laquelle l'événement d'échec sera simulé.
- Cause l'échec de l'instance Amazon Aurora:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];
- simuler l'échec d'Aurora Replica:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE [ TO ALL | TO "replica name" ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- simuler une panne de disque pour le cluster de base de données Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- simuler une panne de disque pour le cluster de base de données Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION BETWEEN minimum AND maximum MILLISECONDS [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
Crash dans le monde des applications sans serveur
L'échec peut être un véritable défi si vous utilisez des composants sans serveur, car les services sans serveur comme AWS Lambda ne prennent pas en charge nativement le basculement.
Présentation des échecs Lambda
Pour comprendre ce problème, j'ai écrit une petite bibliothèque python et une couche lambda - pour introduire des échecs dans AWS Lambda . Actuellement, les deux prennent en charge le délai, les erreurs, les exceptions et l'introduction d'un code d'erreur HTTP. L'échec est obtenu en réglant le magasin de paramètres AWS SSM comme suit:
{ "isEnabled": true, "delay": 400, "error_code": 404, "exception_msg": "I really failed seriously", "rate": 1 }
Vous pouvez ajouter un décorateur python à la fonction de gestionnaire pour introduire un échec.
- lever une exception:
@inject_exception def handler_with_exception(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_exception('foo', 'bar') Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1 corrupting now Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../chaos_lambda.py", line 316, in wrapper raise _exception_type(_exception_msg) Exception: I really failed seriously
- entrez le code d'erreur "HTTP invalide":
@inject_statuscode def handler_with_statuscode(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_statuscode('foo', 'bar') Injecting Error 404 at a rate of 1 corrupting now {'statusCode': 404, 'body': 'Hello from Lambda!'}
- entrez un délai:
@inject_delay def handler_with_delay(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_delay('foo', 'bar') Injecting 400 of delay with a rate of 1 Added 402.20ms to handler_with_delay {'statusCode': 200, 'body': 'Hello from Lambda!'}
Cliquez ici pour en savoir plus sur cette bibliothèque python.
Présentation de l'échec Lambda via la limitation de concurrence
Lambda par défaut, pour des raisons de sécurité, ajuste l'exécution parallèle de toutes les fonctions dans une région spécifique par compte. Les exécutions parallèles font référence à plusieurs exécutions d'un code de fonction se produisant à un instant unique. Ils sont utilisés pour mettre à l'échelle un appel de fonction à une demande entrante. Mais cela peut servir dans un but opposé: arrêter l'exécution de Lambda.
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0
Cette commande réduira la simultanéité à zéro, provoquant des échecs de requête avec une erreur telle que "freinage" - DTC 429 .
Thundra - Trace de transmission sans serveur
Thundra est un outil de surveillance d'applications sans serveur qui a une capacité intégrée d'injecter des défaillances dans des applications sans serveur. Il crée des gestionnaires d'encapsuleur pour introduire des échecs tels que «aucun gestionnaire d'erreur» pour les opérations avec DynamoDB, «aucune neutralisation d'erreur» pour la source de données ou «aucun délai d'expiration dans les requêtes HTTP sortantes». Je ne l'ai pas essayé moi-même, mais dans ce post pour la paternité de Yan Chui et dans cette magnifique vidéo de Marsha Villalba, le processus est bien décrit. Cela semble prometteur.
Et en conclusion de la section sur les applications sans serveur, je dirai que Yan Chui a un excellent article sur les difficultés de l'ingénierie du chaos par rapport aux applications sans serveur. Je recommande à tout le monde de le lire.
4 - Introduction de défaillances au niveau des infrastructures
Tout a commencé avec l'introduction de défaillances au niveau de l'infrastructure - pour Amazon et Netflix. L'introduction de défaillances au niveau de l'infrastructure - de la déconnexion d'un centre de données entier à l'arrêt aléatoire d'instances - est probablement la plus facile à mettre en œuvre.
Et, bien sûr, l'exemple du « singe du chaos » vient d'abord à l'esprit.
Arrêt des instances EC2 sélectionnées au hasard dans une certaine zone de disponibilité.
À ses débuts, Netflix voulait introduire des règles architecturales strictes. Il a déployé son «chaos monkey» comme l'une des premières applications AWS à installer des microservices sans état à échelle automatique - en ce sens que toute instance peut être détruite ou remplacée automatiquement sans provoquer de perte d'état. Le Chaos Monkey s'est assuré que personne ne violait cette règle.
Le scénario suivant - similaire au «singe du chaos» - consiste à arrêter n'importe quelle instance au hasard, dans une zone de disponibilité spécifique dans la même région.
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")
import boto3 import random REGION = 'eu-west-1' def stop_random_instance(az, tag_name, tag_value, region=REGION): ''' >>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1') ['i-0ddce3c81bc836560'] ''' ec2 = boto3.client("ec2", region_name=region) paginator = ec2.get_paginator('describe_instances') pages = paginator.paginate( Filters=[ { "Name": "availability-zone", "Values": [ az ] }, { "Name": "tag:" + tag_name, "Values": [ tag_value ] } ] ) instance_list = [] for page in pages: for reservation in page['Reservations']: for instance in reservation['Instances']: instance_list.append(instance['InstanceId']) print("Going to stop any of these instances", instance_list) selected_instance = random.choice(instance_list) print("Randomly selected", selected_instance) response = ec2.stop_instances(InstanceIds=[selected_instance]) return response
Avez-vous tag_name tag_value tag_name et tag_value ? Ces petites choses empêcheront l'échec des mauvaises instances. #lessonlearned

Et oui ... redémarrez la base de données - bien joué [oups, pas cette instance]
5 - Introduction à l'échec et outils d'orchestration tout-en-un
Il est probable que vous soyez perdu dans autant d'outils. Heureusement, il existe quelques outils d'introduction de refus et d'orchestration qui incluent la plupart d'entre eux et sont faciles à utiliser.
L'un de mes outils préférés est le Chaos Toolkit , une plate-forme d'ingénierie open source du chaos soutenue commercialement par la grande équipe ChaosIQ . En voici quelques-uns: Russ Miles , Sylvain Helleguarch et Marc Parrien .
Le Chaos Toolkit définit une API déclarative et extensible pour mener facilement une expérience d'ingénierie du chaos. Il comprend des pilotes pour AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humino, Prometheus et Gremlin.
Les extensions sont un ensemble de vérifications et d'actions utilisées pour les expériences comme suit: nous arrêtons une instance sélectionnée au hasard dans une zone de disponibilité spécifique si la tag-key contient une valeur chaos-ready .
{ "version": "1.0.0", "title": "What is the impact of randomly terminating an instance in an AZ", "description": "terminating EC2 instance at random should not impact my app from running", "tags": ["ec2"], "configuration": { "aws_region": "eu-west-1" }, "steady-state-hypothesis": { "title": "more than 0 instance in region", "probes": [ { "provider": { "module": "chaosaws.ec2.probes", "type": "python", "func": "count_instances", "arguments": { "filters": [ { "Name": "availability-zone", "Values": ["eu-west-1c"] } ] } }, "type": "probe", "name": "count-instances", "tolerance": [0, 1] } ] }, "method": [ { "type": "action", "name": "stop-random-instance", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "stop_instance", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] }, "pauses": { "after": 60 } } ], "rollbacks": [ { "type": "action", "name": "start-all-instances", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "start_instances", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] } } ] }
La réalisation de l'expérience ci-dessus est simple:
❯ chaos run experiment_aws_random_instance.json
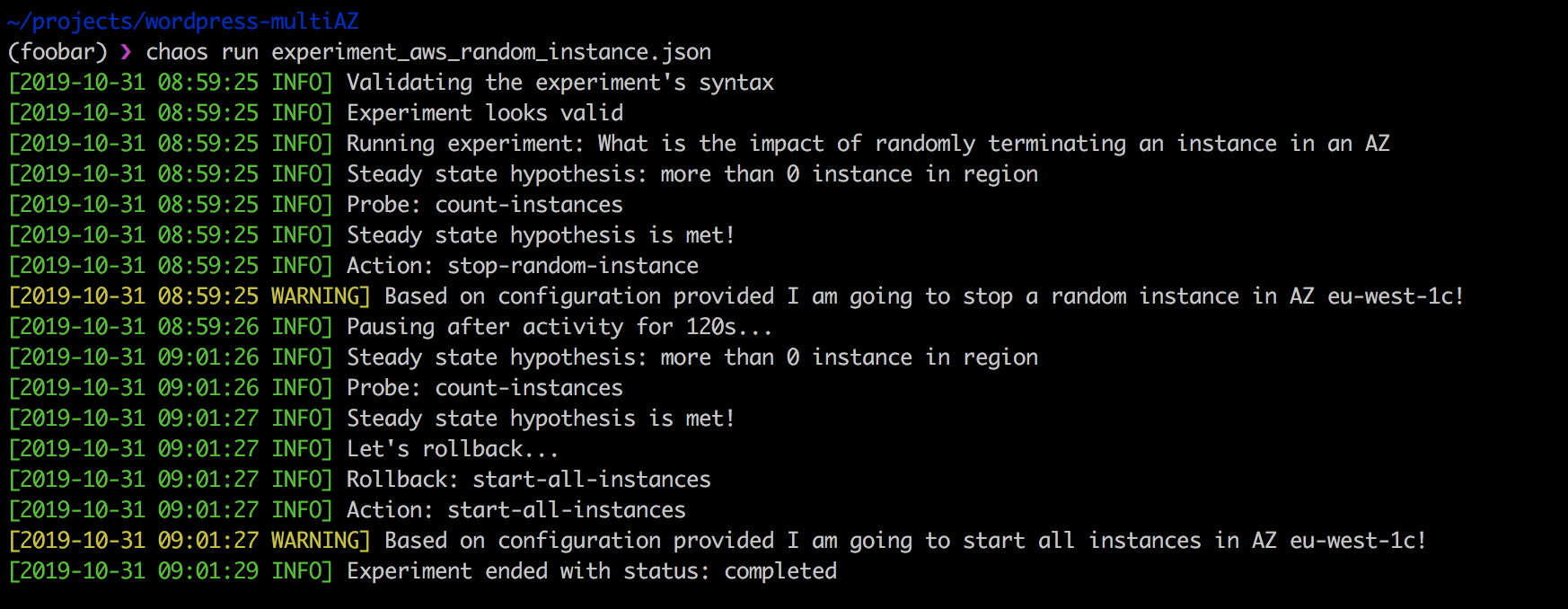
La force du Chaos Toolkit est que, premièrement, il est open source et peut être adapté à vos besoins. Deuxièmement, il s'intègre parfaitement dans le pipeline CI / CD et prend en charge les tests de chaos en continu.
L'inconvénient de Chaos Toolkit est qu'il faut du temps pour le maîtriser. De plus, il n'y a aucune expérience prête à l'emploi, vous devez donc les écrire vous-même. Cependant, je connais l'équipe de ChaosIQ, qui travaille sans relâche, comprenant cette tâche.
Gremlin
Un autre de mes préférés est Gremlin. Il contient un ensemble complet de modes pour introduire des pannes dans un outil simple avec une interface utilisateur intuitive. Un tel Chaos-as-a-Service.
Gremlin prend en charge l'introduction de défaillances au niveau des ressources, du réseau et des requêtes , vous permettant d'expérimenter rapidement avec l'ensemble du système, y compris avec du matériel, divers fournisseurs de cloud, des environnements conteneurisés, y compris Kubernetes, des applications et, dans une certaine mesure, des applications sans serveur.
Plus un bonus - les gars de Gremlin sont de bons gars qui écrivent un excellent contenu pour le blog et sont toujours prêts à aider! En voici quelques-uns: Matthew , Colton , Tammy , Rich , Ana et HML .
Gremlin n'a nulle part où utiliser:
Entrez d'abord dans l'application Gremlin et sélectionnez "Créer une attaque".
Attribuez un objectif - instance.
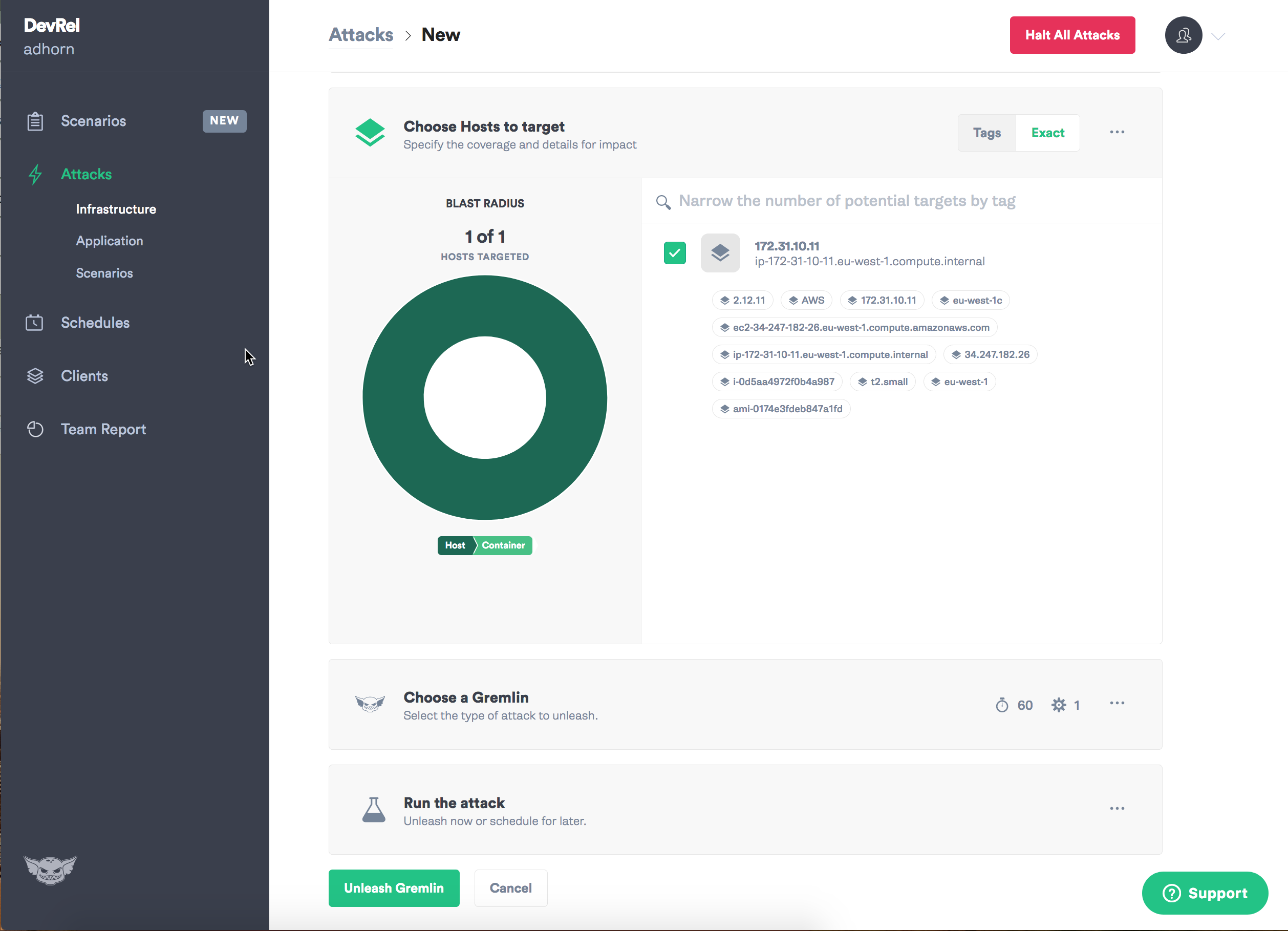
Sélectionnez le type d'échec que vous souhaitez introduire et le chaos peut commencer!
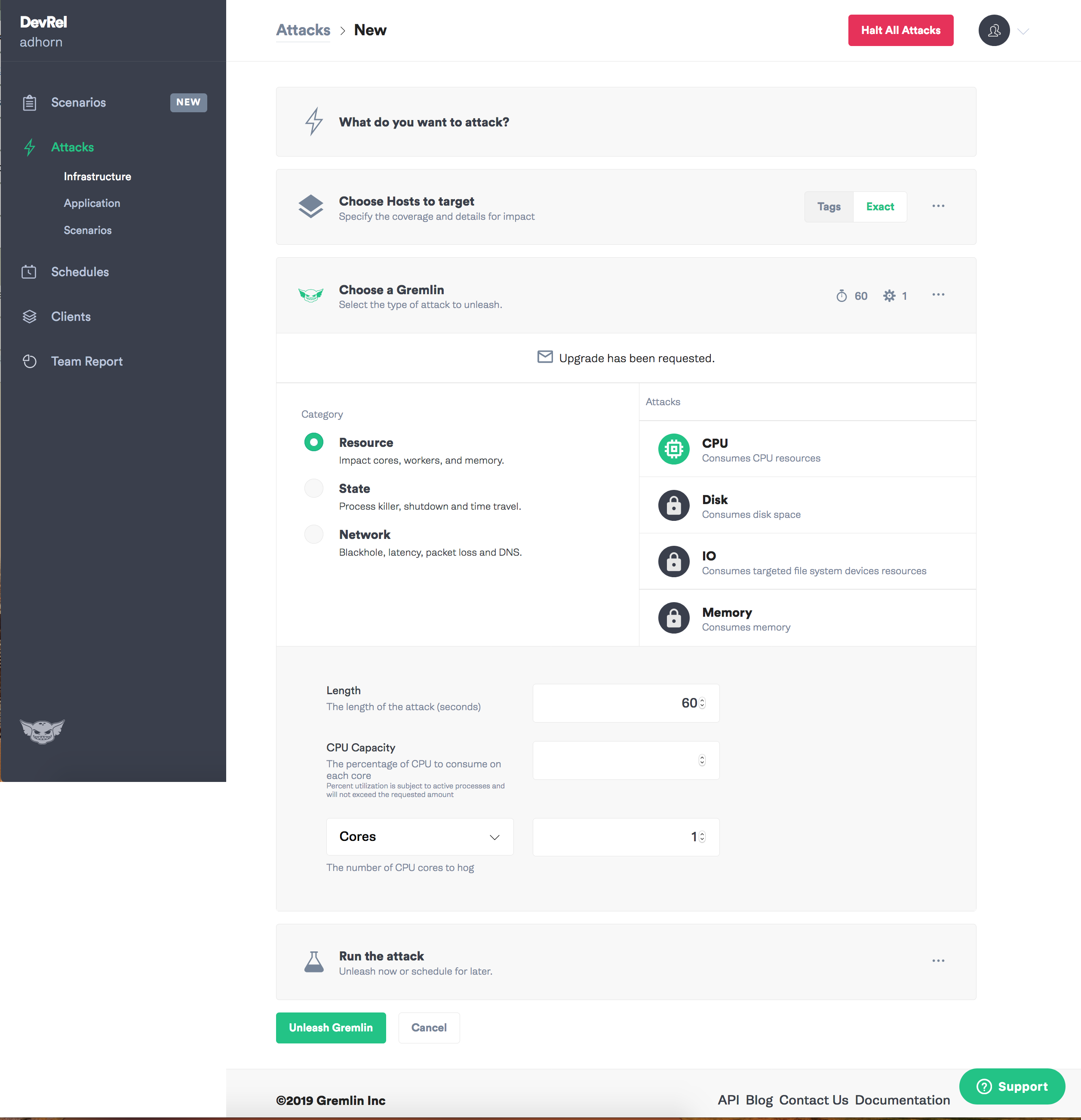
Je dois admettre que j'ai toujours aimé Gremlin: avec lui, les expériences sur l'ingénierie du chaos sont intuitivement simples.
— , . . , Gremlin- daemon , , .
Run Command AWS System Manager
Run command EC2 , 2015 , . — 2, . , , Systems Manager.
Run Command DevOps ad-hoc , .
, Run Command , Windows, -.
AWS System Manager . — !
!
, .
1 — - — , - . . — , — , , . , ! :
" . ".
— , - Amazon Prime Video
2 — , , . , -.
3 — , , .
4 — , , , . , - — , .
, , , . , . , , :-)
—