
C'était en 2019, et nous n'avons toujours pas de solution standard pour l'agrégation de journaux dans Kubernetes. Dans cet article, nous souhaitons, à partir d'exemples tirés de la pratique, partager nos recherches, les problèmes rencontrés et leurs solutions.
Cependant, pour commencer, je ferai une réservation pour que différents clients comprennent des choses très différentes en collectant des journaux:
- quelqu'un veut voir les journaux de sécurité et d'audit;
- quelqu'un - enregistrement centralisé de l'ensemble de l'infrastructure;
- et pour quelqu'un, il suffit de collecter uniquement les journaux d'application, à l'exclusion, par exemple, des équilibreurs.
À propos de la façon dont nous avons mis en œuvre divers «Wishlist» et quelles difficultés nous avons rencontrées, sous la coupe.
Théorie: à propos des outils de journalisation
Contexte des composants du système de journalisation
La journalisation a parcouru un long chemin, grâce à laquelle nous avons développé des méthodologies de collecte et d'analyse des journaux, que nous utilisons aujourd'hui. Dans les années 1950, Fortran a introduit un analogue des flux d'E / S standard qui a aidé le programmeur à déboguer son programme. Ce sont les premiers journaux informatiques qui ont simplifié la vie des programmeurs de l'époque. Aujourd'hui, nous voyons en eux le premier élément du système d'exploitation forestière - la
source ou le «producteur» des grumes .
L'informatique ne s'est pas arrêtée: des réseaux informatiques sont apparus, les premiers clusters ... Des systèmes complexes constitués de plusieurs ordinateurs ont commencé à fonctionner. Les administrateurs système étaient désormais contraints de collecter les journaux de plusieurs machines et, dans des cas particuliers, ils pouvaient ajouter des messages du noyau du système d'exploitation au cas où ils auraient besoin d'enquêter sur une défaillance du système. Pour décrire les systèmes centralisés de collecte de journaux, la
RFC 3164 est sortie au début des années 2000, qui normalisait remote_syslog. Un autre élément important est donc apparu: le
collecteur (collecteur) de journaux et leur stockage.
Avec l'augmentation du volume des journaux et l'adoption généralisée des technologies Web, la question s'est posée de savoir quels journaux devraient être facilement affichés aux utilisateurs. Les outils de console simples (awk / sed / grep) ont été remplacés par des visualiseurs de
journaux plus avancés - le troisième composant.
Dans le cadre de l'augmentation du volume des journaux, une autre chose est devenue claire: les journaux sont nécessaires, mais pas tous. Et différents journaux nécessitent différents niveaux de sécurité: certains peuvent être perdus tous les deux jours, tandis que d'autres doivent être stockés pendant 5 ans. Ainsi, un composant de filtration et de routage pour les flux de données a été ajouté au système de journalisation - appelons-le un
filtre .
Les référentiels ont également fait un bond en avant: ils sont passés de fichiers normaux à des bases de données relationnelles, puis à des référentiels orientés documents (par exemple, Elasticsearch). Le stockage était donc séparé du collecteur.
En fin de compte, le concept du journal lui-même s'est étendu à un flux abstrait d'événements que nous voulons conserver pour l'histoire. Plus précisément, dans le cas où il est nécessaire de mener une enquête ou d'établir un rapport d'analyse ...
En conséquence, sur une période de temps relativement courte, la collecte de journaux est devenue un sous-système important, qui peut à juste titre être appelé l'une des sous-sections du Big Data.
 Si jadis des impressions ordinaires pouvaient suffire à un «système d'enregistrement», la situation a maintenant beaucoup changé.
Si jadis des impressions ordinaires pouvaient suffire à un «système d'enregistrement», la situation a maintenant beaucoup changé.Kubernetes et journaux
Lorsque Kubernetes est entré dans l'infrastructure, le problème existant de collecte des journaux ne lui est pas passé. Dans un sens, c'est devenu encore plus douloureux: la gestion de la plateforme d'infrastructure a été non seulement simplifiée, mais aussi compliquée. De nombreux anciens services ont commencé à migrer vers des pistes de microservices. Dans le contexte des journaux, cela a entraîné un nombre croissant de sources de journaux, leur cycle de vie spécial et la nécessité de suivre à travers les journaux les interconnexions de tous les composants du système ...
Pour l'avenir, je peux dire que, malheureusement, il n'existe actuellement aucune option de journalisation standardisée pour Kubernetes qui serait avantageusement différente de tout le monde. Les programmes les plus populaires dans la communauté sont les suivants:
- quelqu'un déploie une pile EFK (Elasticsearch, Fluentd, Kibana);
- quelqu'un essaie le Loki récemment sorti ou utilise l' opérateur Logging ;
- nous (et peut-être pas seulement nous? ..) sommes largement satisfaits de notre propre développement - loghouse ...
En règle générale, nous utilisons ces bundles dans les clusters K8s (pour les solutions auto-hébergées):
Cependant, je ne m'attarderai pas sur les instructions d'installation et de configuration. Au lieu de cela, je me concentrerai sur leurs lacunes et sur des conclusions plus globales sur la situation des journaux en général.
Entraînez-vous avec les journaux dans les K8

"Journaux quotidiens", combien d'entre vous? ..
La collecte centralisée des journaux avec une infrastructure suffisamment grande nécessite des ressources considérables qui seront consacrées à la collecte, au stockage et au traitement des journaux. Au cours de l'exploitation de divers projets, nous avons été confrontés à diverses exigences et aux problèmes opérationnels qui en ont résulté.
Essayons ClickHouse
Regardons un référentiel centralisé sur un projet avec une application qui génère pas mal de logs: plus de 5000 lignes par seconde. Commençons à travailler avec ses journaux, en les ajoutant à ClickHouse.
Dès que le temps réel maximum est requis, le serveur ClickHouse à 4 cœurs sera déjà surchargé sur le sous-système de disque:

Ce type de téléchargement est dû au fait que nous essayons d'écrire dans ClickHouse le plus rapidement possible. Et la base de données répond à cela avec une charge de disque accrue, ce qui peut provoquer les erreurs suivantes:
DB::Exception: Too many parts (300). Merges are processing significantly slower than insertsLe fait est que les
tables MergeTree dans ClickHouse (elles contiennent des données de journal) ont leurs propres difficultés lors des opérations d'écriture. Les données qui y sont insérées génèrent une partition temporaire, qui fusionne ensuite avec la table principale. En conséquence, l'enregistrement est très exigeant sur le disque, et la restriction s'applique à lui, dont nous avons reçu la notification ci-dessus: pas plus de 300 sous-partitions peuvent fusionner en 1 seconde (en fait, c'est 300 insert'ov par seconde).
Pour éviter ce problème, vous devez
écrire dans ClickHouse en morceaux aussi grands que possible et pas plus d'une fois en 2 secondes. Cependant, l'écriture en lots importants suggère que nous devrions écrire moins souvent dans ClickHouse. Ceci, à son tour, peut entraîner des débordements de tampon et la perte de journaux. La solution consiste à augmenter le tampon Fluentd, mais la consommation de mémoire augmentera.
Remarque : Un autre problème avec notre solution ClickHouse était que le partitionnement dans notre cas (loghouse) était implémenté via des tables externes liées par une table Merge . Cela conduit au fait que lors de l'échantillonnage de grands intervalles de temps, une quantité excessive de RAM est requise, car le métatable traverse toutes les partitions - même celles qui ne contiennent évidemment pas les données nécessaires. Cependant, cette approche peut désormais être déclarée obsolète en toute sécurité pour les versions actuelles de ClickHouse (depuis 18.16 ).En conséquence, il devient clair que loin de chaque projet aura suffisamment de ressources pour collecter les journaux en temps réel dans ClickHouse (plus précisément, leur distribution ne sera pas opportune). De plus, vous devrez utiliser une
batterie , à laquelle nous reviendrons. Le cas décrit ci-dessus est réel. Et à cette époque, nous ne pouvions pas offrir une solution fiable et stable qui conviendrait au client et permettrait de collecter les journaux avec un délai minimum ...
Et Elasticsearch?
Elasticsearch est connu pour gérer de lourdes charges. Essayons-le dans le même projet. Maintenant, la charge est la suivante:
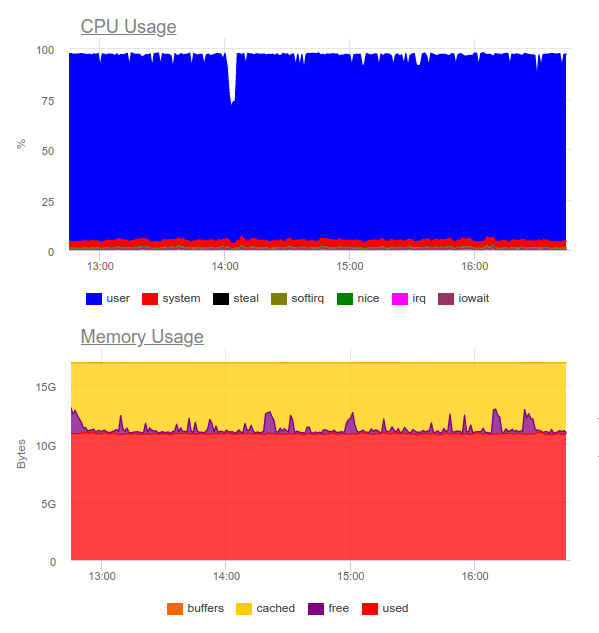
Elasticsearch a pu digérer le flux de données, cependant, y écrire de tels volumes utilise beaucoup le CPU. Ceci est décidé par l'organisation du cluster. Purement techniquement, ce n'est pas un problème, mais il s'avère que seulement pour le fonctionnement du système de collecte de journaux, nous utilisons déjà environ 8 cœurs et avons un composant supplémentaire très chargé dans le système ...
Conclusion: cette option peut être justifiée, mais uniquement si le projet est important et que sa direction est prête à consacrer des ressources importantes à un système de journalisation centralisé.
Une question logique se pose alors:
Quels journaux sont vraiment nécessaires?

Essayons de changer l'approche elle-même: les journaux doivent être informatifs en même temps et ne pas couvrir
tous les événements du système.
Disons que nous avons une boutique en ligne prospère. Quels journaux sont importants? Rassembler autant d'informations que possible, par exemple, à partir d'une passerelle de paiement est une excellente idée. Mais tous les journaux ne sont pas critiques pour nous du service de découpage d'images dans le catalogue de produits: seules les erreurs et la surveillance avancée suffisent (par exemple, le pourcentage de 500 erreurs que ce composant génère).
Nous sommes donc arrivés à la
conclusion que
la journalisation centralisée est loin d'être toujours justifiée . Très souvent, le client souhaite collecter tous les journaux en un seul endroit, bien qu'en fait, seuls 5% des messages critiques pour l'entreprise soient requis pour l'ensemble du journal:
- Parfois, il suffit de configurer, par exemple, uniquement la taille du journal du conteneur et du collecteur d'erreurs (par exemple, Sentry).
- Pour enquêter sur les incidents, des alertes d'erreur et un grand journal local lui-même peuvent souvent suffire.
- Nous avions des projets qui ne coûtaient que des tests fonctionnels et des systèmes de collecte d'erreurs. Le développeur n'avait pas besoin des journaux en tant que tels - ils ont tout vu sur les traces d'erreur.
Illustration de la vie
Un bon exemple est une autre histoire. Nous avons reçu une demande de l'équipe de sécurité d'un des clients qui disposait déjà d'une solution commerciale développée bien avant l'implémentation de Kubernetes.
Il a fallu «se faire des amis» un système centralisé de collecte de journaux avec un capteur d'entreprise pour détecter les problèmes - QRadar. Ce système est capable de recevoir des journaux en utilisant le protocole syslog, pour les prendre depuis FTP. Cependant, son intégration avec le plugin remote_syslog pour fluentd n'a pas fonctionné tout de suite
(il s'est avéré que nous ne sommes pas les seuls ) . Les problèmes de configuration de QRadar étaient du côté de l'équipe de sécurité du client.
En conséquence, une partie des journaux critiques pour l'entreprise a été téléchargée sur FTP QRadar, et l'autre partie a été redirigée via un syslog distant directement à partir des nœuds. Pour ce faire, nous avons même écrit un
tableau simple - peut-être que cela aidera quelqu'un à résoudre un problème similaire ... Grâce au schéma résultant, le client lui-même a reçu et analysé les journaux critiques (en utilisant ses outils préférés), et nous avons pu réduire le coût du système de journalisation, en ne gardant que le dernier mois.
Un autre exemple montre bien comment ne pas le faire. L'un de nos clients pour gérer
chaque événement provenant de l'utilisateur, a fait une
sortie d' information
non structurée multiligne dans le journal. Comme vous pouvez le deviner, ces journaux étaient extrêmement difficiles à lire et à stocker.
Critères pour les journaux
De tels exemples conduisent à la conclusion que, en plus de choisir un système de collecte de journaux, vous devez également
concevoir les journaux eux-mêmes ! Quelles sont les exigences ici?
- Les journaux doivent être dans un format lisible par machine (par exemple JSON).
- Les journaux doivent être compacts et pouvoir changer le degré de journalisation afin de déboguer d'éventuels problèmes. Dans le même temps, dans les environnements de production, vous devez exécuter des systèmes avec un niveau de journalisation comme Avertissement ou Erreur .
- Les journaux doivent être normalisés, c'est-à-dire que dans l'objet journal, toutes les lignes doivent avoir le même type de champ.
Les journaux non structurés peuvent entraîner des problèmes lors du chargement des journaux dans le référentiel et de l'arrêt complet de leur traitement. Pour illustrer, voici un exemple avec une erreur 400, que beaucoup ont sûrement rencontré dans les journaux fluentd:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"Une erreur signifie que vous envoyez un champ dont le type est instable à l'index avec un mappage prêt. L'exemple le plus simple est un champ dans le journal nginx avec la variable
$upstream_status . Il peut avoir un nombre ou une chaîne. Par exemple:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}Les journaux montrent que le serveur 10.100.0.10 a répondu avec l'erreur 404e et la demande est allée à un autre magasin de contenu. En conséquence, dans les journaux, la signification est devenue la suivante:
"upstream_response_time": "0.001, 0.007"Cette situation est si répandue qu'elle a même gagné une
mention distincte
dans la documentation .
Et la fiabilité?
Il y a des moments où tous les journaux sont vitaux sans exception. Et avec cela, les schémas de collecte de journaux typiques pour les K8 proposés / discutés ci-dessus ont des problèmes.
Par exemple, fluentd ne peut pas collecter de bûches dans des conteneurs de courte durée. Dans l'un de nos projets, le conteneur avec la migration de la base de données a vécu moins de 4 secondes, puis a été supprimé - selon l'annotation correspondante:
"helm.sh/hook-delete-policy": hook-succeededPour cette raison, le journal de migration n'est pas entré dans le référentiel. La politique de
before-hook-creation peut aider dans ce cas.
Un autre exemple est la rotation des journaux Docker. Supposons qu'il existe une application qui écrit activement dans les journaux. Dans des conditions normales, nous parvenons à traiter tous les journaux, mais dès qu'un problème survient - par exemple, comme décrit ci-dessus avec le mauvais format - le traitement s'arrête et Docker fait pivoter le fichier. Conclusion - les journaux critiques peuvent être perdus.
C'est pourquoi
il est important de séparer le flux de journaux , en intégrant l'envoi des plus précieux directement dans l'application pour assurer leur sécurité. De plus, il ne sera pas superflu de créer une sorte de
«batterie» de journaux qui puisse survivre à la brève indisponibilité du stockage tout en conservant les messages critiques.
Enfin, n'oubliez pas
qu'il est important de surveiller tout sous-système de manière qualitative . Sinon, il est facile de rencontrer une situation dans laquelle fluentd est dans l'état
CrashLoopBackOff et n'envoie rien, ce qui promet la perte d'informations importantes.
Conclusions
Dans cet article, nous ne considérons pas les solutions SaaS comme Datadog. Bon nombre des problèmes décrits ici ont déjà été résolus d'une manière ou d'une autre par des sociétés commerciales spécialisées dans la collecte de journaux, mais tout le monde ne peut pas utiliser le SaaS pour diverses raisons
(les principales sont le coût et la conformité avec 152-) .
La collecte centralisée des journaux ressemble à première vue à une tâche simple, mais elle ne l'est pas du tout. Il est important de se rappeler que:
- La journalisation détaillée n'est que des composants critiques, et pour d'autres systèmes, vous pouvez configurer la surveillance et la collecte des erreurs.
- Les grumes en production doivent être minimisées afin de ne pas donner une charge supplémentaire.
- Les journaux doivent être lisibles par machine, normalisés, avoir un format strict.
- Les journaux vraiment critiques doivent être envoyés dans un flux distinct, qui doit être séparé des principaux.
- Il vaut la peine d'envisager une batterie de journaux, qui peut économiser des rafales de charge élevée et rendre la charge sur le stockage plus uniforme.

Ces règles simples, si elles étaient appliquées partout, permettraient aux circuits décrits ci-dessus de fonctionner - même s'ils manquent de composants importants (batterie). Si vous n'adhérez pas à ces principes, la tâche vous mènera facilement, vous et l'infrastructure, vers un autre composant très chargé (et en même temps inefficace) du système.
PS
Lisez aussi dans notre blog: