
Lors d'une conférence des développeurs de systèmes et d'outils logiciels - OS DAY 2016, qui s'est tenue à Innopolis du 9 au 10 juin 2016 (Kazan) lors de la discussion d'un rapport sur l'architecture multicellulaire, l'idée a été exprimée qu'elle serait la plus efficace pour résoudre les problèmes d'intelligence artificielle. Les conditions pour le développement d'un nouveau processeur polyvalent axé sur les tâches d'IA se sont développées cette année.
Le neuroprocesseur S2 Multiclet, dont le projet a été présenté pour la première fois au Huawei Innovation Forum 2019, est un nouveau développement de l'architecture multicellulaire. Il diffère des multicellules précédemment créées avec un système de commandes, à savoir l'introduction de nouveaux types de données de petite taille (à virgule fixe et flottante) et les opérations avec celles-ci. Le nombre de cellules a été augmenté - 256 et la fréquence - 2,5 GHz, ce qui devrait fournir une performance de pointe de 81,9 TFlops à 16F et, en conséquence, le rendre comparable, en termes de calculs neuronaux, aux capacités des TPU ASIC spécialisés modernes (TPU-3: 90 TFlops à 16F).
Étant donné que l'efficacité de l'utilisation des processeurs dépend largement de l'optimalité du compilateur, un schéma d'optimisation de code développé a été développé.
Examinons-le plus en détail.
L'
article précédent mentionnait les optimisations du compilateur qui méritent d'être implémentées. Vous y trouverez des matériaux sur l'architecture multicellulaire si vous ne la connaissez pas déjà.
Génération de commandes à deux arguments avec deux constantes
Un nouveau format d'instruction a été introduit avec le processeur S1, permettant aux deux arguments d'être spécifiés comme une valeur constante. Cela vous permet de réduire le nombre de commandes dans le code, en supprimant les commandes inutiles telles que les constantes de chargement à chargement dans le commutateur.
Par exemple:
load_l func wr_l @1, #SP
peut être remplacé par:
wr_l func, #SP
Ou même deux équipes à la fois:
load_l [foo] load_l [bar] add_l @1, @2
Il y a deux adresses constantes, et leur lecture peut également être substituée directement dans les arguments de la commande:
add_l [foo], [bar]
Cette optimisation a été mise en œuvre pour tous ceux qui prennent en charge ce format. Malheureusement, cela s'est avéré très inefficace, pour deux raisons:
- Le nombre de situations où une telle optimisation peut être réalisée est très faible. Dans le code d'arbitrage, les situations se produisent rarement lorsque vous devez traiter en quelque sorte deux valeurs connues à l'avance. Le plus souvent, de telles choses sont décidées au stade de la compilation, et il ne reste que peu à faire pendant l'exécution. Habituellement, ce sont des opérations sur les adresses, encore une fois, constantes.
- La suppression de la commande de chargement ne libère pas le processeur du processus de génération de la constante, mais uniquement de la récupération d'une commande de chargement distincte, qui ne donne qu'une faible accélération, et même pas toujours.
Optimisation du transfert des registres virtuels entre les unités de base
Dans LLVM, les blocs de base sont des sections linéaires dans lesquelles le code est exécuté sans branchement. Les paragraphes d'une architecture multicellulaire remplissent exactement la même fonction, par conséquent, le plus souvent lors de la génération d'un code, un paragraphe reflète un bloc de base. Dans le processeur R1, tout transfert de registres virtuels entre paragraphes a été effectué par la mémoire en écrivant la valeur du registre souhaité dans la pile et en la relisant dans le paragraphe qui a besoin de ce registre. Ce mécanisme est divisé en 2 parties: transfert du registre virtuel vers un autre paragraphe pour une utilisation directe et transfert du registre virtuel comme paramètre pour le nœud phi.
Les nœuds Phi sont une conséquence de la forme
SSA (Static Single Assignment) dans laquelle le langage de présentation LLVM est représenté. Sous cette forme, une variable (ou, comme dans le cas de LLVM IR - registres virtuels) ne peut être écrite qu'une seule fois. Par exemple, ce pseudo code:
a = 1; if (v < 10) a = 2; else a = 3; b = a;
non présenté sous forme SSA, car la valeur de la variable
a peut être écrasée. Le code peut être réécrit sous cette forme, si vous utilisez le nœud phi:
a1 = 1; if (v < 10) a2 = 2; else a3 = 3; b = phi(a2, a3);
Le nœud phi sélectionne a2 ou a3, selon la provenance du flux de contrôle:
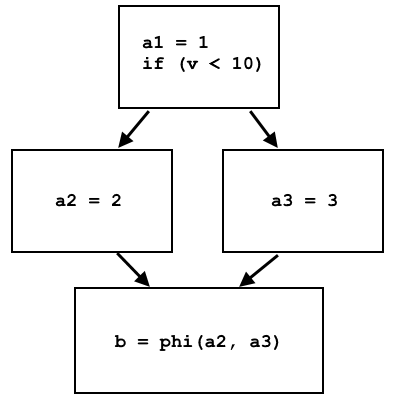
Dans LLVM IR phi, les nœuds sont implémentés comme une instruction distincte, qui sélectionne différents registres virtuels en fonction de l'unité de base d'où provient le contrôle. La mise en œuvre sur le processeur de cette instruction via la mémoire est assez simple: différents blocs de base écrivent des données différentes dans la même cellule de mémoire, et au niveau du nœud phi du site, cette cellule de mémoire est lue, et les données seront différentes en fonction du bloc de base précédent.
Le formulaire SSA implique que lorsque le registre est initialisé, la valeur y sera toujours la même. Lors du transfert direct de registres virtuels, lorsque la valeur de chaque registre virtuel est écrite dans sa propre cellule mémoire séparée, la condition SSA est remplie sans problème: les données sont en mémoire jusqu'à ce qu'elles soient écrasées. Cependant, si nous voulons transférer le registre via le commutateur, nous devons nous rappeler: sa taille n'est que de 63 cellules et toute valeur disparaît lorsque 63 commandes sont exécutées. Par conséquent, si le registre virtuel est écrit dans un premier paragraphe et est utilisé une fois que des centaines d'autres sont terminés, il est impossible de le transférer via le commutateur; il ne reste que la mémoire.
La mise en œuvre de cette optimisation a été démarrée précisément avec l'optimisation des nœuds phi, car, contrairement au transfert direct des registres virtuels, les valeurs des paramètres pour le nœud phi sont toujours initialisées directement dans les paragraphes précédents (blocs de base), ce qui vous permet de ne pas trop penser si le commutateur est suffisamment grand si nous voulons passer ces paramètres à travers elle.
L'assembleur multicellulaire vous permet d'attribuer des noms aux résultats des commandes et d'utiliser leurs résultats sous ce nom. Au lieu que chaque programmeur doive calculer combien de commandes ce résultat a été obtenu, l'assembleur le calcule lui-même:
result := add_l [A], [B] ; ; ; wr_l @result, C
Ce mécanisme fonctionne parfaitement dans le paragraphe actuel, car il s'agit d'une section linéaire et l'ordre des commandes y est connu. Ceci est activement utilisé lorsque le compilateur génère du code: toutes les commandes reçoivent des noms et le compilateur n'a pas à se soucier de la numérotation des commandes. Plus précisément, cela n'était pas nécessaire, car si nous voulons obtenir le résultat d'une commande exécutée dans un autre paragraphe, alors le mécanisme ne fonctionne pas: au stade de l'assemblage, il est impossible de savoir quel paragraphe a été réellement exécuté par le précédent s'il y a plusieurs entrées dans le courant. Par conséquent, la seule option est d'accéder aux résultats des équipes via le numéro. Pour cette raison, vous ne pouvez pas simplement supprimer des enregistrements / lectures supplémentaires de la mémoire dans les paragraphes voisins et remplacer les références de registre de la commande de lecture par la commande du paragraphe précédent.
Ici, il convient de prêter attention à une conséquence très importante: si un paragraphe a plusieurs entrées, alors
@ 1 dans la première commande de cette section peut faire référence à des résultats complètement différents, selon le paragraphe qui était le précédent. Le nœud Phi est une telle situation. Auparavant, dans tous les blocs de base initialisant le nœud phi, les données étaient écrites dans la même cellule de mémoire, et à la place du nœud phi, il y avait une lecture dans cette cellule. Ainsi, ce n'était absolument pas important l'endroit où il y avait un enregistrement dans cette cellule dans les paragraphes précédents, tout comme l'endroit où cette cellule était lue. Si vous vous débarrassez de l'utilisation de la mémoire - cela change.
Pour permettre aux hôtes phi d'utiliser un commutateur au lieu de la mémoire, les opérations suivantes ont été effectuées:
- Tous les nœuds phi dans l'unité de base actuelle sont comptés (et il peut y en avoir plusieurs), sont marqués d'un numéro de série et sont disposés dans cet ordre
- Pour chaque nœud phi, les blocs de base l'initialisant sont contournés; des commandes pour charger les valeurs dans le commutateur ( loadu_q ), marquées par le numéro de série du nœud phi correspondant, leur sont ajoutées
- L'instruction phi du nœud lui-même est également remplacée par loadu_q avec son numéro de série
- Toutes les commandes ajoutées sont réorganisées dans l'ordre donné
Le quatrième point est nécessaire pour la raison déjà indiquée: si nous voulons que la commande
loadu_q @ 3 accède au résultat spécifiquement pour son nœud phi, alors tous les paragraphes d'initialisation de la commande qui charge les données dans le commutateur doivent être exactement dans le même ordre. Donnons un exemple du résultat réel de la compilation de code dans lequel il y a deux nœuds phi dans une unité de base.
Paragraphes avec initialiseurs phi nœuds:
LBB1_27: LBB1_30: SR4 := loadu_q @1 setjf_l @0, LBB1_31 setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8] SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP] SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff SR7 := add_l @SR6, [@SR4] loadu_q @SR5 wr_l @SR7, @SR4 loadu_q @SR6 loadu_q @SR6 complete loadu_q @SR5 complete
Un paragraphe avec deux nœuds phi:
LBB1_31: SR4 := loadu_q @2 SR5 := loadu_q @2 SR6 := loadu_l [#SP + 124] SR7 := loadu_l [#SP + 120] setjf_l @0, @SR7 setrg_q #RETV, @SR4 wr_l @SR5, @SR6 setrg_q #SP, #SP + 120 complete
Auparavant, au lieu des commandes
loadu_q, il y avait des écritures dans la mémoire et des lectures à partir de celle-ci.
Dans le processus de mise en œuvre de cette optimisation, il y a également eu des problèmes qui n'étaient pas prévus à l'avance:
- Certaines optimisations de code existantes réorganisent les commandes à certains endroits, par exemple en plaçant l'adresse du paragraphe suivant au tout début du paragraphe actuel, ou l'emplacement des commandes de lecture / écriture en mémoire au début / à la fin du paragraphe, respectivement. Ces optimisations se produisent après des opérations avec des nœuds phi (les instructions dites d'abaissement LLVM avant les instructions du processeur), de sorte qu'elles perturbent souvent l'ordre de construction des commandes loadu_q . Afin de ne pas perturber le travail de ces optimisations, j'ai dû créer une passe LLVM distincte, qui organise les commandes pour les nœuds phi dans le bon ordre après toutes les autres manipulations avec les commandes.
- Il s'est avéré qu'une situation peut se produire dans laquelle une unité de base initialise des nœuds phi pour deux unités de base différentes. Autrement dit, en suivant l'algorithme indiqué, ces blocs de base seront ajoutés à la commande d'initialisation loadu_q pour chaque nœud phi. Dans ce cas, même s'ils n'ont qu'un seul nœud phi, dans la section d'initialisation, il y aura 2 commandes loadu_q , qui, logiquement, les deux devraient être à la dernière place, ce qui, bien sûr, est impossible. Heureusement, de telles situations sont assez rares, donc s'il existe une telle unité de base dans laquelle les nœuds phi sont initialisés pour plus d'une autre unité de base, alors seul le premier utilise le commutateur selon l'algorithme, pour le reste - comme auparavant, via la mémoire.
Toute cette optimisation des nœuds phi peut être complétée un peu plus. Par exemple, si vous regardez le paragraphe
LBB1_30 ci-dessus, vous pouvez voir que les
commandes loadu_q chargent des valeurs qui ne sont utilisées nulle part ailleurs. Autrement dit, si vous supprimez
loadu_q et définissez les commandes qui créent ces valeurs dans le même ordre, les commandes
loadu_q @ 2 de la section suivante chargeront également les valeurs correctes.
Repères
Les résultats d'optimisation actuels ont été testés sur les benchmarks CoreMark et WhetStone, dont une description se trouve dans l'
article précédent . Commençons par les résultats CoreMark sur le noyau S2 en comparaison avec les anciens résultats (version précédente du compilateur sur le noyau S1).
Les valeurs relatives CoreMark / MHz sont affichées dans l'histogramme:

Pour obtenir une estimation de l'accélération uniquement due à l'optimisation des nœuds phi, vous pouvez recalculer l'indicateur CoreMark sur une multicellule sur les cœurs S1 et S2 pour une fréquence de 1600 MHz: ils sont respectivement de 1147 et 1224, ce qui signifie une augmentation de 6,7%.
Avec WhetStone, la situation est quelque peu différente. Les changements dans le noyau ont ici influencé le résultat.En outre, cette référence fonctionne sur un cœur (multicellulaire) et est calculée en mégahertz, de sorte que la fréquence du processeur ne joue aucun rôle.
Tableau de bord Whetstone:
Maintenant, il est clair que même lors de l'utilisation de la version précédente du compilateur sur le noyau S1, l'index global est plus élevé, principalement en raison des tests en virgule flottante MFLOPS1-3. Cet inconvénient a été constaté lors des tests et est dû au fait que le convoyeur interne du bloc à virgule flottante en S2, par rapport à S1, est un pas de plus. En conséquence, les chaînes successives de commandes liées aux données ont perdu une mesure sur chaque commande. La nécessité de cette étape a été causée par une réduction de la durée du cycle d'horloge (une augmentation de la fréquence du processeur de 1,6 GHz à 2,5 GHz et une augmentation de la nomenclature des commandes, par exemple, l'apparition de la commande de multiplication avec l'accumulation de MAC). Cette décision est provisoire. Des travaux visant à réduire la longueur du pipeline sont en cours et, à l'avenir, ils seront corrigés, mais des tests ont été effectués sur la version actuelle de S2.
Pour évaluer l'accélération de l'optimisation du compilateur, WhetStone a également été compilé sur une version précédente et lancé sur la version actuelle de S2. L'indicateur total était de 0,3068 MWIPS / MHz contre 0,32267 MWIPS / MHz sur le nouveau compilateur, soit ce qui montre une accélération de 6,5% en raison des optimisations ci-dessus.
Le système d'optimisation développé et testé vous permet de mettre en œuvre à l'avenir le prochain schéma d'optimisation, à savoir le transfert direct des registres virtuels via le commutateur. Comme déjà mentionné, toutes les copies du registre virtuel ne peuvent pas être effectuées via le commutateur. En raison de la taille limitée du commutateur et de l'impossibilité d'accéder correctement aux résultats des paragraphes précédents s'il y a plusieurs points d'entrée vers celui en cours (cela est partiellement résolu par les nœuds phi), la seule option possible est de copier les registres virtuels d'un paragraphe directement au suivant, mais il n'y en a qu'un précédent . De tels cas, en fait, ne sont pas si rares, il est souvent nécessaire de transférer des données aussi directement, bien que la quantité d'accélération de code qu'elle donnera à dire à l'avance soit, bien sûr, difficile.