Tôt ou tard, tout service en pleine croissance doit évaluer ses capacités techniques. Combien de visiteurs pouvons-nous servir? Quelle est la capacité du système? Avons-nous atteint la limite et ne tomberons pas si nous attirons plusieurs milliers d'utilisateurs supplémentaires? Combien de ressources informatiques supplémentaires sont budgétisées pour l'année prochaine pour répondre aux plans de croissance?
Les réponses peuvent être obtenues de manière analytique en adressant des questions à un développeur / DevOps / SRE / admin expérimenté. La fiabilité de l'évaluation dépend d'un grand nombre de facteurs: à partir du rythme de remplissage du système avec des fonctionnalités et du graphique des relations entre les composants et se terminant par le temps que l'expert a passé la matinée dans la circulation. Plus le système est complexe, plus il y a de doute sur l'adéquation de l'évaluation analytique.
Je m'appelle Maxim Kupriyanov, depuis cinq ans maintenant je travaille chez Yandex.Market. Aujourd'hui, je vais dire aux lecteurs de Habr comment nous avons appris à évaluer la capacité de nos services et ce qui en est ressorti.
Nous allons à la position
La structure des composants du marché est plutôt compliquée, nous avons donc décidé d'évaluer la capacité des services les plus importants et les plus chers en matière de mise à l'échelle. De plus, le nombre quotidien de demandes en la matière devrait clairement dépendre de la taille de l'audience quotidienne du Marché (utilisateurs actifs quotidiens, DAU). Pourquoi exactement de DAU? Parce que les analystes, faisant des prévisions pour les mois et les années à venir, calculent toujours la taille future de l'audience, et nous profiterons de cette circonstance agréable.
Parlons maintenant sans lequel il est impossible de construire des évaluations objectives: sur les métriques du service. Si le nombre de demandes de service dépend de la DAU, alors nous avons certainement besoin de la métrique "demandes par seconde" (demandes par seconde, RPS). De plus, pour évaluer la qualité du service, vous devez connaître le pourcentage d'erreurs et les temps de réponse (délais de demande). L'erreur sera considérée comme une réponse avec un code HTTP de 500 ou supérieur. Les erreurs de la gamme 4xx sont côté client et, dans un système fonctionnant normalement, ne disent généralement rien des problèmes de service. En ce qui concerne les délais, il est habituel pour nous de calculer et de stocker les 80e, 95e, 99e et 99,9e centiles de temps de réponse, mais un ensemble spécifique peut différer légèrement d'un service à l'autre.
Nous avons donc des mesures de la fréquence des demandes, du pourcentage d'erreurs et d'un ensemble de centiles de temps de réponse. Et nous connaissons également le service DAU pour chaque jour et pour les périodes futures (sous forme de prévisions). Étant donné que les modèles moyens de comportement des utilisateurs ne changent pas trop d'un jour à l'autre, disons ce qui suit: connaissant le RPS dans la période la plus active de la journée de travail (pic RPS), nous pouvons prédire le pic RPS pour les périodes futures, à condition que nous ayons une prévision DAU. Et vice versa: si nous savons combien de demandes par seconde le système peut supporter sans violer l'accord sur le temps de réponse et le pourcentage d'erreurs, alors nous pouvons estimer le public que nous pouvons servir, c'est-à-dire que nous connaissons la capacité du système.
Eh bien, nous avons décidé de la tâche: fixer les délais de réponse et le pourcentage d'erreurs sous forme d'accords et trouver le RPS maximum que le système peut supporter dans ces conditions. Comment allons-nous décider?
Nous tirons sur la cible
Voici une approche classique pour résoudre le problème: nous collectons un site de test, prenons les journaux système de l'environnement de production, en faisons des cartouches et déclenchons le système, augmentant la fréquence des demandes, jusqu'à ce que le site montre une dégradation significative des délais de réponse et / ou des erreurs. À ce stade, nous nous arrêtons et fixons la fréquence des demandes (le même RPS). Victoire Peu importe comment. Et voici pourquoi:
- le site de test, en règle générale, n'est pas identique à la plate-forme sous le service dans l'environnement de production;
- le code service change tous les jours, voire plus souvent;
- les expériences peuvent influencer la charge;
- la gravité des demandes des utilisateurs dépend de l'heure de la journée et d'autres conditions;
- les services modernes fonctionnent rarement de manière isolée, le plus souvent ils font des sous-requêtes à d'autres services, et cela devra être pris en compte d'une manière ou d'une autre.
Amélioration: nous lancerons le service automatiquement tous les jours, en collectant les cartouches dans les magazines aux heures de pointe. Et afin de ne pas gaspiller les ressources sur un site de test, nous allons commencer à décortiquer à tour de rôle les composants qui nous intéressent sur le même stand. Cela semble compliqué et ne résout pas tous les problèmes. Mais quelles sont les autres options?
Simuler la réalité
L'idée générale est la suivante: nous copions une partie du trafic des équilibreurs sur le site, où nous collectons l'analogue complet de l'environnement de production en miniature et, en ajustant le volume du trafic copié, nous recherchons le point de dégradation. L'idée est belle, et nous sur le marché faisons cela pour tester de nouvelles fonctionnalités et comparer le comportement des nouvelles versions avec les anciennes. Mon collègue Eugene en a
parlé en détail - voir la section sur le cluster fantôme. Mais il y a aussi des difficultés évidentes:
- le problème de l'interaction avec les composants externes n'est pas résolu, car il est très coûteux de faire une copie de tout l'environnement de production;
- les journaux de demande du système miroir peuvent accidentellement se mélanger avec les journaux de l'environnement de production, ce qui signifie qu'il est nécessaire de construire un système avec marquage du trafic miroir afin qu'il puisse ensuite être trouvé et nettoyé;
- les demandes sont généralement reflétées en totalité ou en pourcentage du total, et une telle précision ne nous convient pas (mais cela peut être résolu, nous travaillons dans ce sens).
En général, l'imitation de la production est une approche très bonne et prometteuse, mais très coûteuse et avec des limitations importantes.
Test directement en production
Et puis nous sommes enfin arrivés au délicieux. Pour chaque composant testé, nous créons une instance distincte en production, dont la fréquence des demandes est régulée à partir de l'équilibreur avec une grande précision. La dernière fois, les
lecteurs nous ont demandé : «HAProxy est-il suffisant pour vous? Avait-on besoin d'écrire quelque chose de ton côté? » C'est donc le cas très rare où ce n'était pas suffisant et j'ai dû écrire.
Dans le même temps, il existe un service distinct qui surveille étroitement les métriques de l'instance chargée et, lorsque les indicateurs approchent des valeurs critiques, il ferme la vanne sur l'équilibreur, réduisant la fréquence des demandes. Si le service fonctionne dans des limites acceptables, la vanne s'ouvre au contraire. Bien sûr, les seuils de synchronisation et d'erreurs lors du chargement d'un service en direct sont sensiblement plus conservateurs (généralement de 5 à 10%) que sur le terrain d'entraînement, car nous ne voulons pas aggraver l'interaction avec les utilisateurs. Ainsi, l'instance chargée fonctionne toujours à la limite. Nous fixons ces indicateurs. Et puis nous avons l'arithmétique: nous connaissons le nombre de cœurs de service sous charge à chaque instant, nous connaissons la DAU hier. À partir de là, nous considérons le recyclage, les réserves de capacité et les options de comportement du système lors de la désactivation de l'un ou l'autre emplacement. Tout cela se trouve dans la base à partir de laquelle de beaux graphismes sont construits. Sur la base de ces données, lorsque la capacité tombe en dessous du seuil, des alertes sont déclenchées.
Regardons les graphiques
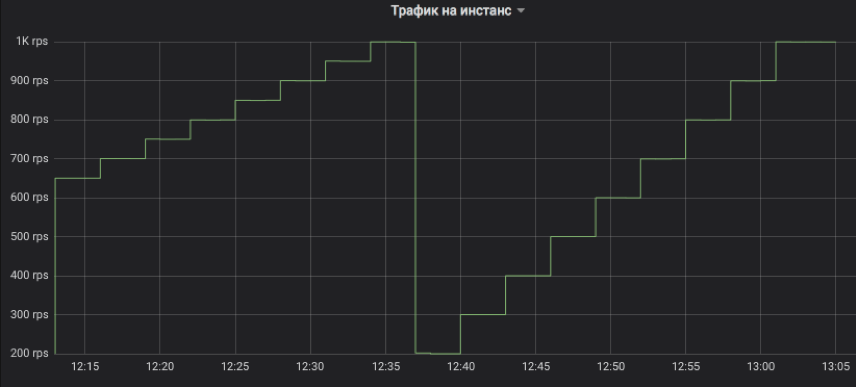
C'est ainsi que nous contrôlons le flux de trafic vers l'instance testée. L'étape peut être un multiple de 1 RPS. Sur le graphique, à titre d'illustration, nous avons modélisé une montée avec un intervalle de trois minutes: d'abord, de 650 à 1K RPS par incréments de 50, puis de 200 à 1K RPS par incréments de 100. Permettez-moi de vous rappeler qu'il s'agit d'un trafic utilisateur réel auquel les clients ont reçu des réponses.
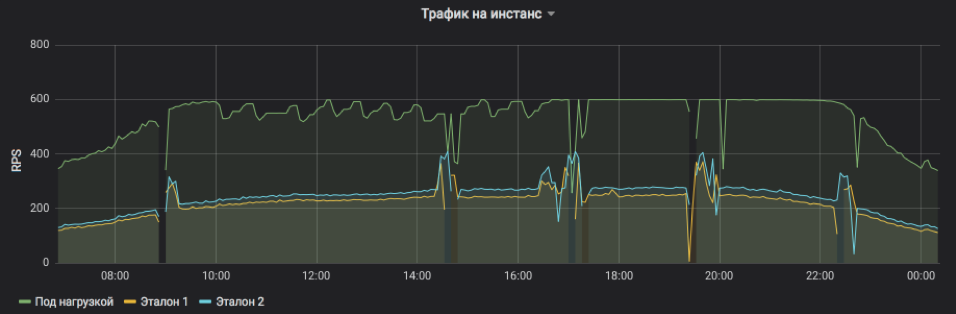
Cela montre RPS pour trois instances: une sous charge et deux sous contrôle. Le sujet a été artificiellement fixé une limite supérieure de 600 RPS. Le service est peut-être plus, mais il devient trop instable et dépend des influences extérieures. On voit bien que dans la première moitié de la journée, les demandes de service sont en moyenne plus lourdes et l'instance ne peut atteindre sa capacité de pointe dans des conditions acceptables, mais vers le soir, tout revient à la normale. Les rafales et les omissions sur le graphique sont des redémarrages d'instance pour la présentation des versions et d'autres mises à jour (elles sont toutes en cours d'équilibrage, personne n'a été blessé). Et les ajustements RPS étape par étape sur le sujet du test ne sont que le travail d'un algorithme qui cherche la limite des possibilités.

La fréquence des demandes de service et la charge qu'une instance peut supporter sont clairement visibles.
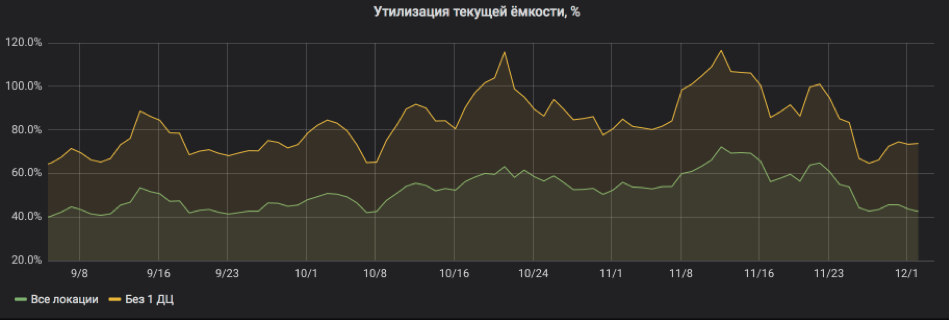
Et ici, nous recalculons tout en pourcentage d'utilisation. Le graphique montre que le service était assez lourdement chargé et lorsque l'un des emplacements était désactivé, il y avait des risques de partir pour SLA. Mais maintenant tout va bien: des ressources ont été ajoutées au service, le recyclage est revenu à des limites acceptables.
Ainsi, les tests de charge en production vous permettent d'évaluer rapidement la capacité du système et de prédire la consommation des ressources pour les périodes futures. Dans le même temps, le système n'ajoute en fait pas de dépenses appréciables et vous pouvez travailler en toute sécurité avec des services avec état, car nous ne générons pas de nouveau trafic, mais redistribuons avec précision celui qui l'est. Et enfin: pour fonctionner, en règle générale, il n'est pas nécessaire de modifier le code du système expérimental lui-même, ce qui permet de tester même les applications héritées.
Réfléchir
Cette méthodologie n'a pas fonctionné sur le marché depuis plus d'un an, et nous pouvons partager des observations et des recommandations:
- À côté de l'instance chargée, il doit y avoir un contrôle ordinaire, et de préférence de la vapeur, car la dégradation se produit souvent non pas parce que l'instance est surchargée, mais à cause de problèmes généraux avec le service dans son ensemble.
- La technique ne fonctionne bien qu'avec les composants dont la charge est supérieure à des centaines de requêtes par seconde pour un emplacement. La raison est assez simple: nous devons charger à la fois l'instance testée et une ou deux commandes. S'il n'y a pas assez de trafic, nous n'atteindrons pas la saturation ou nous ne pourrons pas comparer honnêtement. Et si le RPS limite par instance est très petit, alors l'étape minimale de changement de la fréquence de demande à 1 RPS peut être trop difficile.
- Il est préférable de tester les fronts et les backends à différents emplacements, afin que les artefacts des backends de test de charge n'affectent pas l'estimation de la capacité des fronts.
- Lorsque nous analysons les délais de réponse et recherchons des signes de dégradation, nous prenons généralement des agrégats de cinq minutes et comptons la médiane afin de ne pas réagir aux rafales aléatoires.
- La principale raison pour laquelle l'instance chargée du service se bloque est l'espace disque pour les fichiers journaux (journaux). Ils l'oublient toujours.
- La journalisation sur le disque chargé des E / S des serveurs Web est une raison très courante d'aggravation des délais, même sur les SSD. Activez toujours la mise en mémoire tampon, l'enregistrement asynchrone et toute autre chose, juste pour ne pas attendre la fin de l'enregistrement.
- La charge de nuit n'est pas indicative, car les demandes sont en moyenne plus lourdes en raison de la part plus importante de robots. Par conséquent, pour estimer la capacité, il est préférable de fixer la plage à partir de l'heure conventionnelle de la journée, et la nuit uniquement pour réduire le flux de demandes si des signes de dégradation apparaissent.
- Le 99,9e centile des délais de réponse est inutile pour l'estimation de la capacité, car les garanties de disponibilité du réseau dépassent rarement 99%.
- Démarrez une chronologie et enregistrez les versions de service et autres événements importants. Il aide à trouver ce qui a conduit à une diminution de la capacité.
- Dans une analyse détaillée des causes de la dégradation, le traçage est également utile: un en-tête de marqueur est ajouté à chaque demande de service, qui va de l'avant au dernier backend et entre tous les journaux. De cette façon, vous pouvez suivre l'intégralité du chemin de demande et comprendre les causes des retards.