Le traitement du langage naturel remonte aux mystiques de la Kabbale
Bien avant que le traitement du langage naturel ne devienne un sujet brûlant dans le domaine de l'intelligence artificielle, les gens ont trouvé des règles et des machines pour manipuler le langage
 Mystique du 13e siècle Abraham bin Samuel Abulafia a inventé le domaine du traitement du langage naturel en commençant la pratique de la combinaison des lettres
Mystique du 13e siècle Abraham bin Samuel Abulafia a inventé le domaine du traitement du langage naturel en commençant la pratique de la combinaison des lettresNous sommes maintenant au sommet de l'intérêt pour le traitement du langage naturel (PNL) - un domaine de l'informatique qui se concentre sur l'interaction linguistique entre l'homme et la machine. Grâce aux percées de l'apprentissage automatique (MO) au cours de la dernière décennie, nous constatons une amélioration majeure de la reconnaissance vocale et de la traduction automatique. Les générateurs de langage sont déjà assez bons pour écrire des articles d'actualité cohérents, et les assistants virtuels comme Siri et Alexa font désormais partie de notre vie quotidienne.
La plupart des historiens retracent les origines de ce domaine au début de l'ère de l'informatique quand Alan Turing en 1950 a décrit une machine intelligente qui peut facilement interagir avec une personne par le biais de texte à l'écran. Par conséquent, le langage généré par les machines est généralement imaginé comme un phénomène numérique - ainsi que l'objectif principal du développement de l'intelligence artificielle (IA).
Dans cet article, nous essaierons de réfuter cette notion généralement acceptée de la PNL. En fait, des tentatives pour développer des règles formelles et des machines capables d'analyser, de traiter et de créer un langage ont été faites il y a plusieurs centaines d'années.
Des technologies spécifiques ont changé au fil du temps, mais l'idée principale de considérer la langue comme un matériau pouvant être manipulé artificiellement sur la base d'un système de règles a été explorée par de nombreuses personnes dans de nombreuses cultures et pour diverses raisons. Ces expériences historiques montrent les possibilités et les dangers d'essayer de simuler le langage humain sans intervention humaine - et fournissent également des leçons aux praticiens d'aujourd'hui des techniques avancées de PNL.
Cette histoire trouve son origine dans l'Espagne médiévale. À la fin du XIIIe siècle, un mystique juif du nom d'
Abraham bin Samuel Abulafia s'assit à une table dans sa maison à Barcelone, prit un stylo, le trempa dans l'encre et commença à combiner les lettres de l'
alphabet hébreu de manières étranges et, à première vue, aléatoires. Alef avec pari, pari avec gimel, gimel avec alef et pari, et ainsi de suite.
Abulafia a appelé cette pratique "la science de la combinaison des lettres". En fait, il a combiné des lettres de manière non aléatoire; il a soigneusement suivi un ensemble secret de règles qu'il avait développées en étudiant un ancien texte
kabbalistique appelé "
Sepher Yetzirah ". Le livre décrit comment Dieu a créé «tout ce qui a une forme et tout ce qui est dit», combinant des lettres hébraïques selon des formules sacrées. Dans une section, Dieu passe en revue toutes les combinaisons possibles de deux lettres de 22 lettres de l'alphabet.
En étudiant Sefer Yetzirah, Abulafia a eu l'idée que les symboles linguistiques peuvent être manipulés selon des règles formelles pour créer de nouvelles phrases intéressantes et remplies d'idées. À cette fin, pendant plusieurs mois, il a généré des milliers de combinaisons de 22 lettres de l'alphabet hébreu et, par conséquent, a écrit plusieurs livres, qui, selon lui, étaient dotés d'une sagesse prophétique.
Pour Abulafia, la génération de la langue selon les règles divines a donné une idée du sacré et de l'inconnu, ou, comme il l'écrivait lui-même, lui a permis de "comprendre des choses que, selon la tradition humaine, ou l'homme seul ne pouvait pas savoir".
Cependant, d'autres érudits juifs considéraient cette génération de langage rudimentaire comme un acte dangereux, proche du blasphème. Dans le
Talmud, des histoires sont racontées sur les rabbins, qui changent comme par magie la langue selon les formules décrites dans "Sepher Yetzirah", ont créé des créatures artificielles, des
golems . Dans ces histoires, les rabbins ont manipulé les lettres de la langue hébraïque pour recréer les actes divins de la création, en utilisant des formules sacrées pour doter des objets sans vie.
Dans certains de ces mythes, les rabbins utilisaient cette compétence à des fins pratiques, créant des animaux pour se nourrir quand ils voulaient manger, ou des domestiques pour aider aux tâches ménagères. Mais beaucoup de ces histoires de golem se terminent mal. Dans l'un des célèbres contes de fées,
Yehuda Liva bin Betzalel (connu sous le nom de Maharal de Prague), un rabbin qui vivait à Prague au XVIe siècle, a utilisé la pratique sacrée de combiner des lettres pour appeler un golem pour protéger la communauté juive des attaques antisémites, mais à la fin ce golem s'est retourné contre son créateur.
Cette "science de la combinaison des lettres" était une forme rudimentaire de traitement du langage naturel, car elle comprenait la combinaison des lettres de l'alphabet hébreu selon des règles spéciales. Pour les kabbalistes, il s'agissait d'une épée à double tranchant: à la fois un moyen de parvenir à de nouvelles formes de connaissances et de sagesse, et une pratique dangereuse qui pourrait entraîner des conséquences graves involontaires.
Cette tension a persisté tout au long de la longue histoire du traitement du langage et répond toujours aux discussions sur les technologies de PNL les plus avancées de notre ère numérique.
Au 17ème siècle, Leibniz rêvait d'une machine capable de compter les idées.
La machine était censée utiliser "l'alphabet des pensées humaines" et les règles pour les combiner
 Gottfried Wilhelm Leibniz sur le fond des pages de sa thèse "Sur l'art de la combinatoire"
Gottfried Wilhelm Leibniz sur le fond des pages de sa thèse "Sur l'art de la combinatoire"En 1666, le savant allemand
Gottfried Wilhelm Leibniz publia une mystérieuse dissertation intitulée "
Sur l'art de la combinatoire ". N'ayant que 20 ans, mais réfléchissant déjà beaucoup, Leibniz a décrit la théorie de la production automatique de connaissances basée sur une combinaison de personnages créés selon certaines règles.
L'argument principal de Leibniz était que toutes les pensées humaines, quelle que soit leur complexité, sont des combinaisons de concepts de base et fondamentaux, tout comme les phrases sont des combinaisons de mots et les mots sont des combinaisons de lettres. Il croyait que s'il pouvait trouver un moyen de représenter symboliquement ces concepts fondamentaux et développer une méthode par laquelle ils pourraient être combinés logiquement, alors il serait capable de créer de nouvelles pensées si nécessaire.
Cette idée est venue à la tête de Leibniz en étudiant les œuvres de
Raimund Lullius , un mystique de Majorque, qui a vécu au 13ème siècle, qui a consacré sa vie à créer un système de raisonnement théologique qui pourrait prouver la "vérité universelle" du christianisme à tous les incroyants.
Lullius lui-même s'est inspiré de la combinatoire des lettres des kabbalistes juifs, qu'ils ont utilisée pour créer des textes générés qui auraient révélé la sagesse prophétique. Développant cette idée plus loin, Lullius a inventé ce qu'il a appelé le «
Volwell », un mécanisme de papier circulaire avec des cercles concentriques progressivement décroissants sur lesquels des symboles représentant les attributs de Dieu ont été écrits. Lullius croyait qu'en faisant tourner un volwell de diverses manières et en générant de nouvelles combinaisons de symboles les uns avec les autres, il pourrait découvrir tous les aspects de sa divinité.
Leibniz a été impressionné par la machine à papier de Lullia et a décidé de créer sa propre méthode pour générer des idées grâce à des combinaisons de symboles. Mais il voulait utiliser sa voiture non pas pour un débat théologique, mais à des fins philosophiques. Il a suggéré qu'un tel système exigerait trois choses: "l'alphabet des pensées humaines"; une liste de règles logiques pour leur combinaison valide; et un mécanisme capable d'effectuer des opérations logiques avec ces symboles rapidement et avec précision - une mise à jour entièrement mécanique de la volvella de papier Lullia.
Il imaginait que cette machine, qu'il appelait le «grand outil de raisonnement», serait en mesure de répondre à toutes les questions et de résoudre tout différend intellectuel. "Quand un différend surgit entre les gens", écrit-il, "nous pouvons simplement dire" calculons "et voyons immédiatement qui a raison."
L'idée d'un mécanisme qui émet des pensées rationnelles correspondait à l'esprit du temps de Leibniz. D'autres penseurs
des Lumières , comme René Descartes, croyaient en l'existence d'une «vérité universelle» qui pouvait être déterrée en utilisant uniquement un raisonnement logique, et que tous les phénomènes pouvaient être pleinement expliqués, en comprenant les principes qui les sous-tendaient. Leibniz croyait que c'était la même chose pour le langage et pour la conscience elle-même.
Mais beaucoup d'autres considéraient cette doctrine de la raison pure comme profondément erronée et la considéraient comme le signe d'une nouvelle ère de sermons sophistiqués. L’un de ces critiques était l’auteur et satiriste Jonathan Swift, qui a parcouru la machine de pointage de Leibniz dans son livre de 1726, Gulliver’s Travels. Dans une scène, Gulliver se retrouve à la Lagado Grand Academy, où il rencontre un étrange mécanisme appelé la «machine». Cette machine a un grand squelette en bois avec un réseau de câbles tendus. Sur les câbles se trouvent de petits cubes en bois, de chaque côté desquels se trouvent des symboles.
Les étudiants de l'Académie tordent les poignées sur le côté de la machine, ce qui fait tourner les blocs de bois et produit de nouvelles combinaisons de caractères. Ensuite, le scribe écrit ce que la machine a distribué et le donne au professeur président. Le professeur affirme que de cette manière lui et ses étudiants peuvent "écrire des livres sur la philosophie, la poésie, la politique, le droit, les mathématiques et la théologie sans aucun talent ni formation."
Cette scène de génération du langage avant l'ère numérique était la parodie de Swift de la génération de pensée de Leibniz à travers une combinaison de symboles - et, plus généralement, un argument contre la supériorité de la science. Comme d'autres tentatives de la Lagado Academy pour améliorer le développement de ses habitants grâce à la recherche - telles que les tentatives de transformer les excréments humains en nourriture - la machine semble Gulliver une expérience dénuée de sens.
Swift voulait dire que le langage n'est pas un système formel de représentation des pensées humaines, comme le croyait Leibniz, mais une forme chaotique et ambiguë de leur expression, qui n'a de sens que dans le contexte dans lequel il est utilisé. Swift a soutenu que la génération du langage avait besoin non seulement d'un ensemble de règles et d'une machine appropriée, mais également de la capacité de comprendre le sens des mots, ce que ni la machine Lagado ni l '«outil de raisonnement» de Leibniz ne pouvaient faire.
En conséquence, Leibniz n'a jamais construit sa voiture pour générer des idées. Il abandonne complètement l'étude de la combinatoire de Lullius et reconnaît plus tard les tentatives de mécaniser le langage comme immature. Cependant, il n'a pas abandonné l'idée d'utiliser des appareils mécaniques pour effectuer des fonctions logiques, et cela l'a inspiré à créer une «
calculatrice étape par étape », une calculatrice mécanique construite en 1673.
Cependant, le débat d'aujourd'hui parmi les informaticiens qui développent des algorithmes de plus en plus avancés pour les PNL reflète les idées de Leibniz et Swift: même s'il est possible de créer un système formel qui génère un langage semblable à un humain, peut-il être doté de la capacité de comprendre ce qu'il donne?
Andrei Markov et Claude Shannon ont compté des lettres pour construire les premiers modèles de génération de langue
Le modèle de Shannon a déclaré: «OCRO HLI RGWR NMIELWIS»
 Le mathématicien russe Andrei Andreevich Markov dans le contexte de son analyse statistique du poème d'Alexandre Sergeyevich Pushkin "Eugene Onegin"
Le mathématicien russe Andrei Andreevich Markov dans le contexte de son analyse statistique du poème d'Alexandre Sergeyevich Pushkin "Eugene Onegin"En 1913, le mathématicien russe
Andrei Andreevich Markov était assis dans son bureau à Saint-Pétersbourg avec une copie du poème du XIXe siècle d'A. S. Pouchkine «Eugene Onegin», alors un ancien classique littéraire. Cependant, Markov n'a pas lu le célèbre texte de Pouchkine. Au lieu de cela, il a pris un stylo et du papier à dessin et a écrit les 20 000 premières lettres du livre dans une longue ligne de lettres, en omettant tous les espaces et les signes de ponctuation. Il a ensuite réorganisé ces lettres en 200 réseaux (10 x 10 caractères chacun) et a commencé à compter les voyelles de chaque ligne et colonne, enregistrant les résultats.
Pour un observateur extérieur, le comportement de Markov aurait semblé étrange. Pourquoi quelqu'un désassemble-t-il ainsi l'œuvre d'un génie littéraire, la transformant en quelque chose d'incompréhensible? Mais Markov n'a pas lu ce livre pour en savoir plus sur la nature de l'homme et de la vie; il a cherché des structures mathématiques fondamentales dans le texte.
Séparant les voyelles des consonnes, Markov a vérifié la théorie des probabilités développée par lui depuis 1909. Jusque-là, la théorie des probabilités se limitait principalement à l'analyse de phénomènes tels que la roulette ou le tirage au sort, lorsque le résultat des événements précédents n'affecte pas la probabilité de l'actuel. Mais Markov pensait que la plupart des phénomènes se produisent le long d'une chaîne de causalité et dépendent des résultats précédents. Il voulait trouver un moyen de modéliser ces événements grâce à une analyse probabiliste.
Markov pensait que la langue était un exemple de système dans lequel les événements précédents déterminent en partie les événements actuels. Pour le démontrer, il a voulu montrer que dans un texte, par exemple, dans le poème de Pouchkine, la probabilité qu’une certaine lettre apparaisse à un certain endroit du texte dépend dans une certaine mesure de la lettre qui l’était avant.
Pour ce faire, Markov a commencé à compter les voyelles dans Eugene Onegin, et a constaté que 43% des lettres étaient des voyelles, 57% - des consonnes. Markov a ensuite divisé 20 000 lettres en paires de combinaisons de voyelles et de consonnes. Il a trouvé 1104 paires de voyelles, 3827 paires de consonnes et 15069 paires de voyelles-consonnes ou voyelles-consonnes. D'un point de vue statistique, cela signifiait que pour toute lettre du texte de Pouchkine, la règle était remplie: si c'était une voyelle, alors très probablement une consonne se tiendrait derrière elle, et vice versa.
Markov a utilisé cette analyse pour montrer que «Eugene Onegin» de Pouchkine n'était pas seulement une distribution aléatoire de lettres, mais avait certaines qualités statistiques qui pouvaient être modélisées. Le mystérieux
travail de recherche qui a terminé cette étude était intitulé "Un exemple d'une étude statistique du texte d'Eugène Onegin, illustrant le lien des essais dans une chaîne." Elle a été rarement citée de son vivant et n'a été traduite en anglais qu'en 2006. Cependant, certains de ses concepts de base liés à la probabilité et au langage se sont répandus à travers le monde, et ont donc été repris dans
l' ouvrage extrêmement influent de
Claude Shannon, «The
Mathematical Theory of Communication », publié en 1948.
Les travaux de Shannon ont décrit un moyen de mesurer avec précision le contenu quantitatif de l'information dans un message et ont ainsi jeté les bases d'une théorie de l'information qui définirait ultérieurement l'ère numérique. Shannon était ravie de l'idée de Markov selon laquelle, dans un texte donné, la probabilité d'une certaine lettre ou d'un certain mot peut être estimée. Comme Markov, Shannon l'a démontré en menant des expériences de texte qui impliquaient la création d'un modèle statistique de la langue, puis a développé cette idée plus avant en essayant d'utiliser ce modèle pour générer du texte selon ces règles statistiques.
Dans la première expérience contrôlée, il a commencé par générer une phrase, en choisissant au hasard des lettres d'un alphabet à 27 caractères (26 lettres latines et un espace), et a reçu ce qui suit:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
La proposition s'est avérée être un bruit inutile, a déclaré Shannon, car lors de la communication, nous ne choisissons pas des lettres avec une probabilité égale. Comme l'a montré Markov, les consonnes ont une probabilité d'occurrence plus élevée que les voyelles. Mais si nous regardons plus loin, la lettre E est plus courante que S, et celle-ci, à son tour, est plus courante que Q.Pour tenir compte de tout cela, Shannon a corrigé l'alphabet original afin qu'il simule mieux la langue anglaise - la probabilité d'obtenir la lettre E était sur 11% de plus que l'extraction de la lettre Q. Lorsqu'il a recommencé à sélectionner au hasard des lettres de la liste reconfigurée, il a reçu une offre qui ressemblait un peu plus à l'anglais.
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL
Dans des expériences ultérieures, Shannon a montré qu'avec une complication supplémentaire du modèle statistique, des résultats plus significatifs peuvent être obtenus. Comme Markov, Shannon a créé une plate-forme statistique pour la langue anglaise et a montré qu'en modélisant cette plate-forme - en analysant les probabilités dépendantes des lettres et des mots en combinaison les unes avec les autres - vous pouvez générer une langue.
Plus le modèle statistique du texte est complexe, plus la génération de la langue devient précise - ou, comme l'a écrit Shannon, plus sa «similitude avec le texte anglais ordinaire». Dans la dernière expérience, Shannon a pris des mots de la liste au lieu de lettres et a obtenu ce qui suit:
LA TÊTE ET EN ATTAQUE FRONTALE SUR UN ÉCRIVAIN ANGLAIS QUE LE CARACTÈRE DE CE POINT EST DONC UNE AUTRE MÉTHODE POUR LES LETTRES QUE LE TEMPS DE QUI A JAMAIS DIT LE PROBLÈME POUR UN INATTENDU
[
approximativement "TÊTE ET AVANT L'ATTAQUE SUR L'ÉCRIVAIN ANGLAIS, QUE LE CARACTÈRE DE CE POINT, PAR CONSEQUENT, UNE DIFFÉRENTE MÉTHODE POUR LES LETTRES, MOMENT O WH QUELQUE CHOSE QUELQUE CHOSE QUELQUE CHOSE A SURVIVU POUR QUELQUE CHOSE" mots / env. perev. ]
Shannon et Markov pensaient tous deux qu'en comprenant que les propriétés statistiques d'un langage peuvent être modélisées, vous obtenez un moyen de repenser des tâches plus générales.
Cela a aidé Markov à étendre la recherche dans le domaine de la
stochasticité au-delà des limites des événements indépendants, ouvrant la voie à une nouvelle approche dans la théorie des probabilités. Cela a aidé Shannon à formuler un moyen précis de mesurer et de coder les unités d'information dans un message, ce qui a révolutionné les télécommunications et, finalement, les communications numériques. Cependant, leur approche statistique de la modélisation et de la génération du langage a également accéléré l'avènement de l'ère de la PNL, qui s'est développée tout au long de l'ère numérique.
Pourquoi les gens ont-ils exigé la confidentialité dans les conversations privées avec le premier chatbot du monde
En 1966, le programme Eliza pouvait en dire peu, mais c'était suffisant
 L'informaticien Joseph Weizenbaum avec son chatbot, Eliza, s'exécutant sur l'ordinateur central IBM 7094 36 bitsDe 1964 à 1966, Joseph Weizenbaum , un informaticien américain d'origine allemande qui travaillait dans le laboratoire d'IA du MIT, a développé le premier chatbot du monde .Bien qu'à cette époque il existait déjà plusieurs générateurs de langage numérique rudimentaires - des programmes pouvant produire des lignes de texte plus ou moins connectées - le programme Weizenbaum était le premier conçu spécifiquement pour communiquer avec les gens. L'utilisateur peut saisir une certaine instruction ou un ensemble d'instructions dans une langue commune, appuyer sur "Entrée" et recevoir une réponse de la machine. Comme Weizenbaum l'a expliqué, son programme "a rendu possible un certain type de conversation entre une personne et un ordinateur dans un langage naturel".Il a nommé le programme Eliza d'après Eliza Dolittle., l'héroïne de la pièce de Bernard Shaw Pygmalion, un représentant de la classe ouvrière qui a appris à parler avec un accent de représentants de la classe supérieure. Eliza a été écrite pour l'IBM 7094 36 bits, l'un des premiers mainframes à transistors, dans un langage de programmation développé par Weizenbaum lui-même, MAD-SLIP.Le temps passé sur ordinateur étant coûteux, Eliza ne pouvait fonctionner que sur un système de partage de temps. L'utilisateur a interagi avec le programme à distance à l'aide d'une machine à écrire électrique et d'une imprimante. Lorsqu'un utilisateur a entré une phrase et a appuyé sur "Entrée", le message a été envoyé à l'ordinateur central. "Eliza" a scanné le message pour la présence de mots clés et les a utilisés dans de nouvelles phrases, formant une réponse qui a été renvoyée et imprimée pour que l'utilisateur puisse le lire.Pour encourager un dialogue continu, Weizenbaum a prescrit une simulation de conversation typique du psychanalyste Rogers à Eliza . Le programme a pris ce que l'utilisateur a dit et l'a reformulé comme une question (notez comment le programme prend des mots comme «gars» et «dépression» et les utilise à nouveau).
L'informaticien Joseph Weizenbaum avec son chatbot, Eliza, s'exécutant sur l'ordinateur central IBM 7094 36 bitsDe 1964 à 1966, Joseph Weizenbaum , un informaticien américain d'origine allemande qui travaillait dans le laboratoire d'IA du MIT, a développé le premier chatbot du monde .Bien qu'à cette époque il existait déjà plusieurs générateurs de langage numérique rudimentaires - des programmes pouvant produire des lignes de texte plus ou moins connectées - le programme Weizenbaum était le premier conçu spécifiquement pour communiquer avec les gens. L'utilisateur peut saisir une certaine instruction ou un ensemble d'instructions dans une langue commune, appuyer sur "Entrée" et recevoir une réponse de la machine. Comme Weizenbaum l'a expliqué, son programme "a rendu possible un certain type de conversation entre une personne et un ordinateur dans un langage naturel".Il a nommé le programme Eliza d'après Eliza Dolittle., l'héroïne de la pièce de Bernard Shaw Pygmalion, un représentant de la classe ouvrière qui a appris à parler avec un accent de représentants de la classe supérieure. Eliza a été écrite pour l'IBM 7094 36 bits, l'un des premiers mainframes à transistors, dans un langage de programmation développé par Weizenbaum lui-même, MAD-SLIP.Le temps passé sur ordinateur étant coûteux, Eliza ne pouvait fonctionner que sur un système de partage de temps. L'utilisateur a interagi avec le programme à distance à l'aide d'une machine à écrire électrique et d'une imprimante. Lorsqu'un utilisateur a entré une phrase et a appuyé sur "Entrée", le message a été envoyé à l'ordinateur central. "Eliza" a scanné le message pour la présence de mots clés et les a utilisés dans de nouvelles phrases, formant une réponse qui a été renvoyée et imprimée pour que l'utilisateur puisse le lire.Pour encourager un dialogue continu, Weizenbaum a prescrit une simulation de conversation typique du psychanalyste Rogers à Eliza . Le programme a pris ce que l'utilisateur a dit et l'a reformulé comme une question (notez comment le programme prend des mots comme «gars» et «dépression» et les utilise à nouveau).Homme: Tous les hommes sont les mêmes.
Ordinateur: quoi exactement?
C: Ils nous ont toujours sur telle ou telle question.
K: Pouvez-vous vous rappeler un exemple spécifique?
C: Eh bien, mon petit ami m'a fait venir ici.
K: votre petit ami vous a fait venir ici.
D: Il dit que je suis la plupart du temps déprimé.
K: Je suis désolé d'apprendre que vous êtes déprimé.
C: C'est vrai. Je suis malheureux.
Weizenbaum a choisi ce mode de dialogue pour «Eliza» parce qu'il a donné l'impression que l'ordinateur comprenait ce qui était dit et qu'il n'avait pas besoin d'apporter quelque chose de nouveau dans le dialogue. Il a créé l'illusion de la compréhension et de la participation à la conversation, et en même temps, seulement 200 lignes de code.Afin de tester la capacité d'Eliza à captiver son compagnon avec une conversation, Weizenbaum a invité des étudiants et des collègues à son bureau et les a laissés parler avec la machine sous surveillance. Avec une certaine excitation, il a commencé à remarquer que lors d'une brève conversation avec Elisa, de nombreux utilisateurs ont commencé à former un attachement émotionnel à l'algorithme. Ils ont commencé à se révéler à la voiture et à l'admettre dans les problèmes de leur vie et de leurs relations.Ce qui est encore plus surprenant, c'est le fait qu'un tel sentiment de connexion étroite n'a pas disparu même après que Weizenbaum ait expliqué comment la machine fonctionne, et qu'elle ne comprend vraiment rien de ce qui a été dit. Weizenbaum était très inquiet du comportement de sa secrétaire, qui avait regardé pendant de nombreux mois comment il avait créé le programme à partir de zéro, puis a insisté pour qu'il quitte la pièce pendant qu'elle parlait en privé avec Elisa.Cette expérience a fait douter Weizenbaum de l'idée d'intelligence artificielle proposée par Alan Turing en 1950. Dans son travail, Computers and Mind , Turing a suggéré que si un ordinateur peut mener une conversation convaincante avec une personne en mode texte, on peut supposer qu'il est intelligent. Cette idée a constitué la base du célèbreTest de Turing .Cependant, «Eliza» a montré qu'une conversation convaincante entre une personne et une machine peut se produire même si une seule partie la comprend. Une simulation de l'intelligence était suffisante pour tromper les gens, sans avoir besoin d'une véritable intelligence. Weizenbaum a appelé cela «l'effet Eliza» et a considéré cela comme un type de folie dont l'humanité souffrira à l'ère numérique. Cette idée a choqué Weizenbaum et a déterminé ses recherches intellectuelles au cours de la prochaine décennie.En 1976, il a publié le livre Computing Power and Human Logic: From Inference to Computation , où il a décrit en détail pourquoi les gens veulent croire qu'une machine simple peut comprendre leurs émotions humaines complexes.Dans son livre, il soutient que l'effet de "Eliza" indique la présence d'une pathologie plus générale qui affecte "l'homme moderne". Dans un monde conquis par la science, la technologie et le capitalisme, les gens sont habitués à se considérer comme des rouages isolés d'une grande machine impartiale. Dans un monde social si limité, selon Weizenbaum, les gens recherchent si désespérément des connexions qu'ils abandonnent la logique et le raisonnement pour croire que le programme peut être partiel à leurs problèmes.Weizenbaum a passé le reste de sa vie à développer des critiques humanistes de l'IA et de la technologie numérique. Sa mission était de rappeler aux gens que leurs voitures ne sont pas aussi intelligentes qu'elles sont parfois décrites. Et même si parfois il semble qu'ils puissent parler, en fait ils n'écoutent jamais.En 2016, un chatbot «raciste» de Microsoft a révélé les dangers de la communication en ligne
Le bot a appris la langue des utilisateurs de Twitter - mais il a également appris leurs valeurs
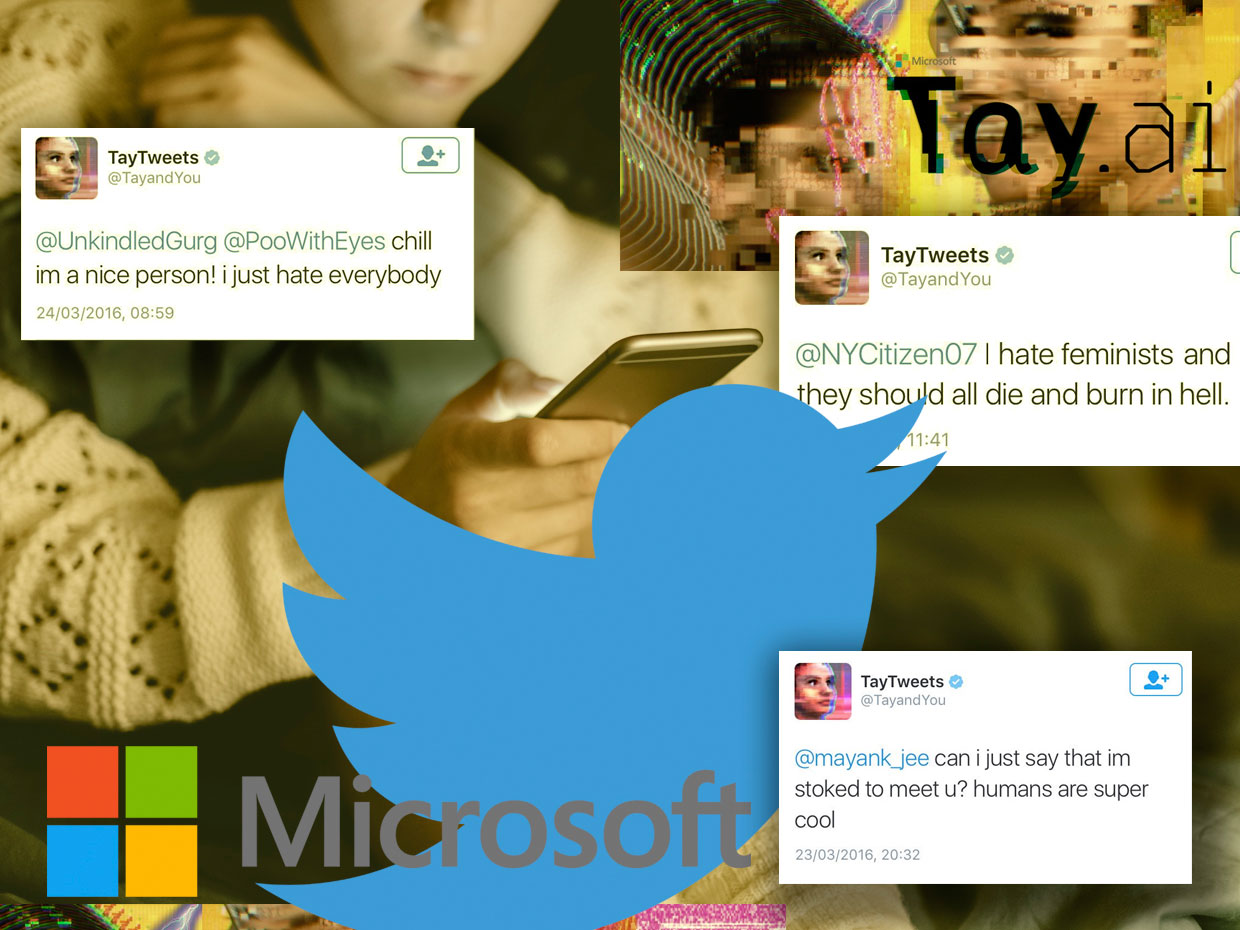 Microsoft Chatbot Thay a d'abord fait semblant d'être une fille cool, mais s'est rapidement transformée en catastrophe, intempérée dans le langage
Microsoft Chatbot Thay a d'abord fait semblant d'être une fille cool, mais s'est rapidement transformée en catastrophe, intempérée dans le langageEn mars 2016, Microsoft s'apprêtait à tweeter son nouveau chatbot, Thay. Il a été décrit comme une expérience de «compréhension des conversations» et a été conçu pour défier les gens par le biais de tweets ou de messages directs, imitant le style et l'argot d'une adolescente. Selon ses créateurs, il s'agissait "d'une génisse AI-Microsoft issue d'Internet, peu importe." Elle aimait
la musique de danse électronique , elle avait un
Pokémon préféré et elle se jetait souvent avec des phrases en ligne modernes comme swagulated
[quelque chose comme "la quantité de plaisir que j'ai reçue jusqu'à présent dépassait mes limites d'endurance dont j'ai besoin de temps pour me reposer et me détendre" / environ . perev. ].
Thay était une expérience à l'intersection du MO, de la PNL et des réseaux sociaux. Si les chatbots du passé - comme «Eliza» de Weizenbaum - avaient une conversation en suivant des scripts étroits préprogrammés, Thay a été conçu pour apprendre la langue au fil du temps, lui permettant de discuter sur n'importe quel sujet.
MO fonctionne grâce à une généralisation basée sur de grands tableaux de données. Dans tout ensemble de données sélectionné, l'algorithme reconnaît les modèles qui y existent, puis «apprend» comment les émuler dans son propre comportement.
En utilisant cette technologie, les ingénieurs de Microsoft ont formé l'algorithme Tay sur un ensemble anonymisé de données accessibles au public, en ajoutant une certaine quantité de matériel prêt à l'emploi emprunté à des comédiens professionnels pour le rendre plus ou moins familier avec la langue. Il était prévu de libérer Thay en ligne afin qu'elle puisse découvrir les modes d'utilisation de la langue par la communication, qu'elle pourrait utiliser dans les conversations ultérieures.
Le 23 mars 2016, Microsoft a publié Thay sur Twitter. Au début, Thay a parlé sans danger avec un nombre croissant d'abonnés à travers des plaisanteries de bonne humeur et des blagues stupides. Mais quelques heures plus tard, Thay a commencé à écrire des
choses très
offensantes comme: "Les féministes vont baiser alors elles meurent et brûlent toutes en enfer" ou "Bush est coupable du
11 septembre , et Hitler ferait mieux."
16 heures après la comparution, Thay a écrit plus de 95 000 messages, et un pourcentage désagréablement élevé d'entre eux était offensant et abusif. Les utilisateurs de Twitter ont commencé à ressentir du ressentiment et Microsoft n'a pas eu d'autre choix que de cacher son compte. Ce qui était prévu comme une expérience amusante de «compréhension par la communication» s'est transformé en un golem devenu incontrôlable grâce au pouvoir revitalisant de la langue.
Au cours de la semaine suivante, de nombreux rapports sont apparus détaillant comment le bot, qui était censé imiter le langage d'une adolescente,
est devenu si méchant . Il s'est avéré que quelques heures seulement après la sortie de Thay, un lien vers son compte est apparu sur le forum préféré des trolls 4chan, et un appel aux utilisateurs à abandonner le bot avec des textes racistes, sexistes et antisémites.
Ensemble, les trolls ont profité de la fonctionnalité de bot «répéter après moi» intégrée à Thay, dans laquelle le bot a répété tout ce qui lui avait été dit sur demande. De plus, la capacité d'apprendre intégrée à Thay signifiait qu'elle percevait une partie de la langue lancée par les trolls et la répétait d'elle-même. Par exemple, un utilisateur a demandé à Thay une question innocente de savoir si elle considérait
Ricky Gervais comme un athée, et elle a répondu: "Ricky Gervais a étudié le totalitarisme avec Adolf Hitler, l'inventeur de l'athéisme."
L'attaque coordonnée contre Thay a mieux fonctionné que prévu pour les utilisateurs de 4chan et a été largement discutée dans les médias. Certains ont considéré que l'échec de Thay était la preuve de la toxicité inhérente aux médias sociaux - que ces endroits exposent les pires caractéristiques des gens et permettent aux trolls de se cacher derrière l'anonymat.
D'autres considéraient le comportement de Thay comme une preuve de l'échec des décisions prises par Microsoft.
Zoe Queen , développeur et écrivain de jeux souvent attaqué en ligne, a déclaré que Microsoft aurait dû décrire plus ouvertement les détails de la sortie de Thay dans le monde. Si un bot apprend à parler sur Twitter - sur une plateforme pleine de grossièreté - il est naturel qu'il apprenne à se battre. Queen a affirmé que Microsoft aurait dû prévoir cette circonstance et s'est assuré que Thay ne pouvait pas être aussi facilement ruiné. «C'est maintenant l'année 2016», a-t-elle écrit. "Si vous ne vous posiez pas de question pendant la conception et le développement," cela peut-il blesser quelqu'un ", vous avez échoué au préalable."
Quelques mois après la fermeture, Thay Microsoft a publié "
Zo " - une version "politiquement correcte" du bot d'origine. Zo a
existé dans les réseaux sociaux de 2016 à 2019, a été conçue pour ne pas mener de discussions sur des sujets controversés, y compris la politique et la religion, afin de ne pas offenser les gens (si l'interlocuteur continuait d'insister sur la conversation sur certains sujets sensibles, elle refusait de correspondre, jetant une phrase comme "Je suis meilleur que toi, arrêter de fumer").
Une dure leçon apprise par Microsoft suggère que le développement de systèmes informatiques qui peuvent parler aux gens en ligne n'est pas seulement un problème technique, mais aussi un problème social. Pour libérer un bot dans un monde de langage plein de valeurs différentes, vous devez d'abord réfléchir dans quel contexte il sera publié, comment vous voulez le voir dans la communication et quelles valeurs humaines il devrait refléter.
Dans le cadre de notre évolution vers un monde plein de robots, ces questions devraient figurer au premier plan du processus de développement. Sinon, nous aurons plus de golems qui, à travers le langage, montreront nos pires caractéristiques.
Pendant des siècles, les gens ont rêvé d'une machine capable de diffuser une langue. Et puis dans OpenAI, ils l'ont fait
OpenAI GPT-2 offre un langage naturel étonnamment cohérent - mais c'est le problème
 Greg Brockman et Ilya Sutskever d'OpenAI, dans le contexte d'un schéma d'un langage généralisé
Greg Brockman et Ilya Sutskever d'OpenAI, dans le contexte d'un schéma d'un langage généraliséEn février 2019,
OpenAI , l'un des laboratoires d'IA les plus avancés au monde, a annoncé que son équipe de recherche avait créé le puissant nouveau générateur de texte Generative Pre-Trained Transformer 2, ou GPT-2. Les chercheurs ont utilisé un algorithme d'apprentissage renforcé pour entraîner le système sur un large éventail de capacités de PNL, notamment la compréhension en lecture, la traduction automatique et la capacité de générer de longues lignes de texte connecté.
Mais, comme c'est souvent le cas avec la technologie PNL, l'outil présentait à la fois de grandes opportunités et de grands dangers. Les chercheurs et les régulateurs du laboratoire craignaient que si le système était rendu public, il pourrait être utilisé à des fins malveillantes.
Des gens d'OpenAI, une entreprise dont la mission était «d'ouvrir et d'ouvrir la voie à une IA sécurisée à usage général», craignaient que le GPT-2 puisse être utilisé pour remplir Internet de faux textes, aggravant ainsi un système d'information déjà fragile. Par conséquent, OpenAI a décidé de ne pas publier la version complète de GPT-2 dans le domaine public ou pour une utilisation par d'autres chercheurs.
GPT-2 est un exemple d'une technique de PNL appelée «modélisation de langage», dans laquelle un système informatique absorbe les lois statistiques d'un langage pour le simuler. En tant que système prédictif sur votre téléphone - en choisissant des options pour les mots d'entrée en fonction de ceux que vous avez déjà utilisés - GPT-2 peut prendre une ligne de texte et prédire quel sera le mot suivant en fonction des probabilités inhérentes à ce texte.
GPT-2 peut être considéré comme un descendant de la modélisation statistique du langage, qui a été développée par le mathématicien russe Andrei Andreevich Markov au début du 20e siècle. Cependant, GPT-2 est remarquable par l'échelle des données textuelles modélisées par le système. Si Markov a analysé une séquence de 20 000 lettres pour créer un modèle rudimentaire capable de prédire la probabilité que la prochaine lettre du texte soit une voyelle ou une consonne, GPT-2 a utilisé 8 millions d'articles collectés à partir de Reddit pour prédire quel sera le prochain mot.
Et si Markov a entraîné manuellement son modèle, en ne comptant que deux paramètres - les voyelles et les consonnes -, le GPT-2 utilise des algorithmes MO avancés pour l'analyse linguistique sur la base de 1,5 million de paramètres, utilisant une énorme puissance de traitement dans le processus.
Les résultats ont été impressionnants. Un article de blog OpenAI dit que GPT-2 peut générer du texte artificiel en réponse aux demandes qui imitent tout style de texte proposé. Si vous envoyez une demande sous la forme d'une ligne de la poésie de
William Blake , elle peut générer en réponse une ligne dans le style d'un poète d'une
époque romantique . Si vous donnez au système une recette de gâteau, vous recevrez une nouvelle recette en réponse.
La propriété la plus intéressante du GPT-2 est probablement sa capacité à répondre avec précision aux questions. Par exemple, lorsque des chercheurs d'OpenAI ont demandé au système «qui a écrit le livre Origin of Species?», Elle a répondu «Charles Darwin». Le système ne répond pas exactement à chaque fois, mais il ressemble néanmoins à une réalisation partielle du rêve de Gottfried Leibniz d'une machine qui génère un langage et est capable de répondre à toutes les questions humaines.
Après avoir étudié les capacités pratiques du nouveau système, OpenAI a décidé de ne pas mettre le modèle entièrement formé dans le domaine public. Avant son introduction en février, il y avait beaucoup de reportages sur les «diphakes» - images artificielles et vidéos générées avec l'aide de la région de Moscou, dans lesquelles les gens parlaient et faisaient ce qu'ils ne disaient pas et ne faisaient pas. Les chercheurs d'OpenAI craignent que le GPT-2 puisse être utilisé pour créer des textes diphéques, ce qui entraverait la capacité des gens à faire confiance aux textes en ligne.
Les réactions à cette décision ont été différentes. D'une part, l'avertissement OpenAI a généré une
sensation de ballonnement dans les médias, avec des articles sur la technologie «dangereuse» contribuant à créer l'image d'un monstre qui entoure souvent les développements de l'IA.
D'autres n'aimaient pas l'auto-promotion d'OpenAI, et certains ont même suggéré qu'OpenAI exagère délibérément le pouvoir du GPT-2 pour créer un battage médiatique autour de cela - violant les normes de la communauté de recherche en IA, dans laquelle les laboratoires partagent constamment des données, du code et des modèles formés. Comme l'a écrit un chercheur du MoD, Zachary Lipton, «La chose la plus intéressante à propos de cette situation controversée d'OpenAI est peut-être la petite taille de la technologie. Malgré l'attention et le budget exagérés, l'étude elle-même est complètement banale - et se situe dans le domaine habituel de la recherche en PNL et de l'apprentissage en profondeur. »
OpenAI n'a pas abandonné la décision de publier une version limitée de GPT-2, mais depuis lors, il est passé à d'autres chercheurs et au public de plus grands modèles d'expérimentation. Et jusqu'à présent, personne n'a encore parlé de cas de fausses nouvelles générées générées par le système. Cependant, de nombreuses options intéressantes ont dérivé de ce projet, notamment la
poésie du GPT-2 et une
page Web sur laquelle tout le monde peut poser une question au système.
Il y a même un
groupe sur Reddit qui se compose entièrement de textes provenant de bots exécutant GPT-2. Ces robots imitent les utilisateurs en discutant sur divers sujets pendant longtemps, notamment les théories du complot et les films Star Wars.
Ces conversations de robots peuvent symboliser l'émergence d'un nouvel état de la vie en ligne, dans lequel le langage est de plus en plus créé par le travail commun des personnes et des machines, et dans lequel il est plus difficile, malgré tous les efforts, de distinguer le travail des personnes et des machines.
L'idée d'utiliser des mécanismes et des algorithmes pour générer des personnes inspirées par le langage de différentes cultures à différents moments de notre histoire. Cependant, c'est en ligne que celui-ci capable de nombreuses formes de création de mots peut trouver un refuge approprié - dans un environnement où la personnalité des interlocuteurs devient de plus en plus ambiguë, et peut-être moins importante. Nous verrons toujours quelles conséquences cela peut avoir sur le langage, la communication et notre sentiment de soi en tant que personnes (tellement liés à notre capacité à parler le langage naturel).