
Récemment, un événement important a eu lieu au département des opérations de Yandex.Money. Notre entreprise se développe rapidement et il s'est avéré que non seulement nos cœurs, mais aussi la demande du centre de données changent. Plus précisément, l'emplacement a dû changer. Et maintenant depuis trois mois, l'un des centres de données vit dans un nouvel endroit.
À propos de la façon dont Yandex.Money a déménagé dans un nouveau centre de données, je vais vous dire, le chef du département des opérations, et Ivan, le chef du département de l'infrastructure informatique et des systèmes internes.
Sous la coupe - une chronologie des événements, des étapes importantes du déménagement, des virages inattendus et un débriefing. Nous partageons comment nous avons survécu à cela.
Conditions préalables à la réinstallation
Auparavant, l'un des centres de données Yandex.Money était situé dans une banlieue de Moscou. La réalité est qu'en dehors de la ville, tous les fournisseurs de canaux de communication optiques n'ont pas la possibilité de poser indépendamment des itinéraires de câble - c'est cher. Et la première raison de notre décision de déménager était due au fait que dans l'ancien centre de données, les canaux de communication passaient par les mêmes routes, ce qui comportait des risques supplémentaires.
À l'intérieur du périphérique de Moscou, il existe de nombreux fournisseurs et le système de câbles est bien développé. Vous pouvez acheter des chaînes auprès de différents fournisseurs qui fonctionnent de différentes manières et qui ne se chevauchent pas. Il y a des risques accrus dans la région - par exemple, une excavatrice viendra creuser toutes les pistes en même temps.
Deuxièmement, le centre de données précédent avait des limites technologiques, y compris périodiquement des problèmes d'alimentation électrique.
Mais la principale raison (= la douleur) est l'incapacité à se développer. Cela signifiait que le bâtiment manquait d'espace pour des racks supplémentaires, où il était possible d'installer de nouveaux équipements. Cela est directement lié à notre environnement productif, car Yandex.Money dispose de deux centres de données et ils doivent être symétriques en termes de capacités.
Planification
La préparation du déménagement a été divisée en étapes:
- Concours: DC, canaux, réseaux, racks, PDU, câbles;
- Transférer les applications et les bases de données vers le 2ème DC;
- Enseignements - désactiver DC;
- Nouvelle architecture des réseaux centraux, IX;
- Mise en place d'un nouveau cœur de réseau dans le DC.
Sélection des fournisseurs
Le premier centre de données Yandex.Money est situé à Moscou. Et pour éviter des retards importants sur le réseau, nous avons décidé de placer le deuxième centre de données près du premier.
Au sein du MKAD pour minimiser les retards du réseau et à moins de 20 km de la première installation pour assurer l'indépendance des deux centres de données de la même infrastructure urbaine et des éventuelles catastrophes technologiques ou naturelles.
Lors de l'analyse du marché, nous avons été guidés par un critère aussi important que la certification des centres de données en termes de disponibilité et de fiabilité. La norme la plus courante en Russie et dans le monde est la norme développée par l'Uptime Institute, qui audite les centres de données du monde entier. Il convient de noter qu'il existe de nombreux centres de données qui n'ont certifié que la documentation du projet, mais cela ne signifie pas que le centre de données lui-même est construit, testé et exploité conformément aux normes.
Un exemple de notre pratique: un fournisseur de services de centre de données à Moscou nous a annoncé que le projet de centre de données répond à la norme Tier III et a proposé de conclure un contrat avec la promesse d'une disponibilité à 100%, soit 0 minute d'indisponibilité par an! Après avoir personnellement visité le site, nous avons réalisé qu'il n'y avait pas de certifications officielles garantissant le niveau de qualité, et l'infrastructure ne s'appuie clairement pas sur le niveau III. Le centre de données était situé au rez-de-chaussée d'un immeuble résidentiel et le seul générateur-remorque se tenait dans la rue sans aucune protection physique.
Par conséquent, dans les exigences du concours, nous avons inclus non seulement la certification du projet, mais également la certification des processus de mise en œuvre et de gestion.
De plus, nous avons déterminé avec les fournisseurs de canaux de communication optiques entre nos contrôleurs de domaine et les canaux vers les points d'échange de trafic (IX) où nous organisons les interfaces avec les fournisseurs ou nos partenaires. Le critère principal était que les canaux de communication optiques soient indépendants, empruntent des voies différentes.
Et, bien sûr, il y a eu d'autres achats - principalement des équipements réseau, des racks (armoires spécialisées pour l'installation des serveurs), des unités de distribution d'énergie (unités de distribution d'énergie intelligentes), ainsi que des câbles et des cordons de brassage.
Il convient de noter que nous avons spécialement sélectionné avec soin le fournisseur qui transportera le matériel. Il est important que l'entreprise ait de l'expérience dans le transport de serveurs, et les déménageurs comprennent qu'il ne s'agit pas de meubles et de charges, et vous devez également être particulièrement prudent lorsque vous conduisez. De plus, nous avons assuré le matériel transporté en cas de dommages pendant le transport.
Mise à niveau de l'infrastructure réseau
Concernant l'infrastructure réseau, nous avions deux options. La première consiste à transporter les anciens équipements de réseau «tels quels». La seconde consiste à construire d'abord une nouvelle infrastructure de réseau dans un nouveau centre de données, puis à transporter l'équipement de serveur.
Puisque nous avons compris que nous avions déjà «croisé» la bande passante du réseau dans l'ancien centre de données et que nous avions besoin de la réserve et de la capacité d'évoluer pendant au moins les 3 à 5 prochaines années, il a été décidé de construire l'infrastructure réseau dans le nouveau centre de données à partir de zéro et de passer à une nouvelle génération d'équipements. .
Nous avons adhéré au modèle classique lors de la construction d'un réseau dans un nouveau centre de données. Dans chaque rack, les serveurs sont connectés à deux commutateurs d'accès qui, à leur tour, sont connectés aux commutateurs d'agrégation centraux (ils sont également le cœur du réseau).
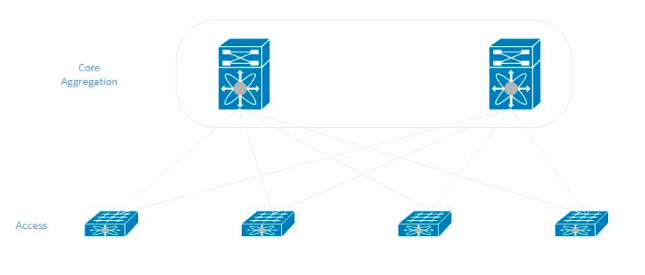
Enseignements
Lors du déménagement, nous avons décidé d'éteindre complètement le centre de données, à la fois de tout transporter et de l'allumer dans un nouvel endroit. Pour cela, l'entreprise a dû apprendre à se passer de l'un des deux centres de données. Cela a nécessité la participation de presque tous nos administrateurs pour que les systèmes d'information sur différentes plates-formes, sur différents systèmes d'exploitation, avec différentes bases de données puissent fonctionner sans interruption sur le site restant.
Pour les services les plus critiques, une réserve a été fournie qui est restée disponible même avec un centre de données désactivé.
Après avoir effectué le travail de réservation, les exercices ont commencé. Tout d'abord, nous avons complètement déconnecté les réseaux individuels, les segments, puis seulement le centre de données. En 2019, nous avons effectué un test d'arrêt du centre de données 10 fois - nous avons observé le comportement de nos 300 systèmes d'information. En vérifiant à plusieurs reprises l'autonomie, nous étions convaincus que nous pouvons facilement nous déconnecter.
Et puis ...
Semaine X
L'un des vendredis devait éteindre tous les équipements du centre de données - les dernières versions ont été lancées le matin, puis un moratoire a été annoncé à leur sujet.
Yandex.Money peut avoir 60 versions ou plus par jour, et toutes sont effectuées dans les deux centres de données.
Nous avons arrêté les versions, veillé à ce que le système fonctionne de manière stable et aucune correction n'est requise dans nos composants. À partir de 15h00, ils ont commencé à éteindre progressivement toutes les applications, bases de données et serveurs. Pendant la nuit du vendredi au samedi, nous avons attendu le temps, nous étions convaincus que rien de mal ne se passait, ce qui signifie que nous pouvons y aller. Samedi matin, une équipe de 15 personnes a commencé à démonter l'équipement et à le transporter vers le nouveau centre de données.

Il nous a fallu toute la journée de samedi pour démonter et transporter le matériel. Ensuite, le processus d'installation de l'équipement, de commutation, de connexion à l'alimentation électrique a commencé.

Samedi soir, nous avons monté et connecté le premier lot de serveurs. Le travail principal a commencé dimanche - le soir du week-end, presque tout l'équipement était installé. Et nous avons terminé la commutation uniquement lundi soir.

Mardi matin, nous avons effectué les derniers tests des réseaux, des canaux de communication et étions prêts à élever nos systèmes. Ils ont commencé à augmenter le premier lot de serveurs, mais quelque chose s'est mal passé ...
Nous avons commencé à recevoir des plaintes massives d'administrateurs que le réseau ne fonctionnait pas sur les serveurs: soit complètement, soit l'une des deux interfaces. Ils ont commencé à rechercher des problèmes du côté des équipements réseau, dans les systèmes d'exploitation, dans les paramètres des systèmes d'exploitation.
Les symptômes étaient similaires - ils ont commencé à chercher quelle pourrait être la raison. Nous avons remarqué qu'il valait mieux déplacer les cordons de brassage à côté des ports de commutation et que certaines des liaisons fonctionnaient.

Après avoir découvert cela, nous avons réalisé qu'une partie importante de ces cordons de raccordement (environ 40% des 2000 pièces) étaient défectueux. Nous avons déplacé tous les cordons de brassage disponibles d'un autre fabricant de confiance vers un nouveau centre de données et avons commencé d'urgence à reconnecter les serveurs les plus critiques. Cela a pris un autre jour.
Dès mercredi soir jeudi matin, l'équipe a commencé à lever le bloc principal des systèmes d'information.
Après avoir levé les services critiques et lancé la réserve du système de paiement, nous avons inclus une partie des bancs d'essai du nouveau centre de données et la réserve des systèmes de backoffice afin que tous nos systèmes internes fonctionnent avec deux centres de données. À la fin de la semaine, la quasi-totalité de l'infrastructure informatique du centre de données transporté a été lancée.
Initialement, il y avait un plan pour 5 jours, mais avec une situation d'urgence liée à des cordons de brassage défectueux, cela s'est avéré être une semaine. Ci-dessous, nous avons clairement peint la chronologie de nos actions.
Plan de réinstallation - en attente:- Vendredi - nous éteignons les réseaux et les applications;
- Samedi - nous transportons et commençons l'assemblée;
- Dimanche - installation de serveurs, lancement de réseaux;
- Lundi - nous terminons le réseau, lançons des applications;
- Mardi - allumez tout.
Réalité:- Vendredi - nous éteignons les réseaux et les applications;
- Samedi - nous transportons et commençons l'assemblée;
- Dimanche - installation de serveurs, lancement de réseaux;
- Lundi - câblage, lancement du réseau;
- Mardi - allumez les serveurs, 100+ ne fonctionne pas;
- Mercredi - mariage en fils, remplacement , lancement de l'App et de la DB;
- Jeudi - terminé le remplacement de PS, lancez l'application.
La vie après avoir déménagé
Qu'avons-nous obtenu en déménageant?Tout d'abord, nos deux centres de données sont désormais de niveau Tier Uptime Institute. Les fournisseurs de centres de données nous garantissent un niveau de disponibilité de 99,982%, ce qui équivaut à 1,6 heure d'indisponibilité par an. Nous sommes confiants dans la fiabilité des canaux de communication entre nos sites. De plus, il n'y a maintenant aucune restriction à l'expansion de notre infrastructure informatique.
L'idée de déménager nous a donné une excellente occasion de mettre à niveau l'équipement réseau en termes de bande passante. Nous avons également refactorisé les blocs d'alimentation dans des racks - installés des «PDU intelligentes», des serveurs d'alimentation réservés.
Et quand nous avons déménagé, nous avons pu «peigner» la commutation, et maintenant elle a l'air plus nette.

Par conséquent, en général, le système a commencé à fonctionner de manière plus stable et nos clients bénéficient d'un meilleur service.
Quelles conclusions en avez-vous tirées?Lors de la réalisation de grands projets, vous devez penser aux risques, imaginer quels pièges peuvent être. Notre exemple avec des câbles Ethernet a montré qu'il ne suffit pas de faire un achat test et de tester les produits de câbles du fabricant sélectionné. Pour réduire les risques, il a été nécessaire d'effectuer des tests aléatoires sur un lot de 2000 câbles.
Il convient également de considérer que certains serveurs peuvent ne pas survivre au mouvement et ne s'allument tout simplement pas pour diverses raisons. D'une manière ou d'une autre, la route est secouée et sollicitée mécaniquement. Sur les 600 unités de matériel transporté, 6 blocs ont éclaté. Sur un nombre suffisamment important de serveurs, seulement 1% ont souffert, pas un seul disque n'est tombé en panne - nous pensons que c'est un excellent résultat.
C'est ainsi que le centre de données Yandex.Money a déménagé dans un nouvel endroit. Nous espérons que notre expérience vous aidera à éviter d'éventuelles erreurs et, peut-être, vous conduira à d'autres solutions intéressantes.