Toute
image raster peut être représentée comme une
matrice à deux dimensions . En ce qui concerne les couleurs, l'idée peut être développée en regardant l'image sous la forme d'une
matrice tridimensionnelle , dans laquelle des mesures supplémentaires sont utilisées pour stocker des données pour chacune des couleurs.
Si nous considérons la couleur finale comme une combinaison de ce qu'on appelle couleurs primaires (rouge, vert et bleu), dans notre matrice tridimensionnelle, nous déterminons trois plans: le premier pour le rouge, le second pour le vert et le dernier pour le bleu.
Nous appellerons chaque point de cette matrice un pixel (élément image). Chaque pixel contient des informations d'intensité (généralement sous la forme d'une valeur numérique) de chaque couleur. Par exemple, un
pixel rouge signifie qu'il a 0 vert, 0 bleu et rouge maximum.
Un pixel rose peut être formé en utilisant une combinaison de trois couleurs. En utilisant une plage numérique de 0 à 255, le pixel rose est défini comme
Rouge = 255 ,
Vert = 192 et
Bleu = 203 .

Cet article a été publié avec le soutien d'EDISON.
Nous développons des applications de vidéosurveillance, de streaming vidéo , ainsi que d' enregistrement vidéo en salle d'opération .
Techniques alternatives de codage couleur
Pour représenter les couleurs qui composent l'image, il existe de nombreux autres modèles. Par exemple, vous pouvez utiliser une palette indexée dans laquelle un seul octet est nécessaire pour représenter chaque pixel, au lieu des trois nécessaires lors de l'utilisation du modèle RVB. Dans un tel modèle, vous pouvez utiliser une matrice 2D au lieu d'une matrice 3D pour représenter chaque couleur. Cela économise de la mémoire, mais donne moins de couleurs.

RVB
Par exemple, regardez cette image ci-dessous. La première face est entièrement peinte. Les autres sont les plans rouge, vert et bleu (l'intensité des couleurs correspondantes est indiquée en niveaux de gris).

Nous voyons que les nuances de rouge dans l'original seront aux mêmes endroits où les parties les plus brillantes de la deuxième personne sont observées. Alors que l'apport du bleu ne se voit principalement qu'aux yeux de Mario (le dernier visage) et des éléments de ses vêtements. Remarquez où les trois plans de couleur apportent le moins de contribution (les parties les plus sombres des images) - c'est la moustache de Mario.
Pour stocker l'intensité de chaque couleur, un certain nombre de bits est requis - cette valeur est appelée
profondeur de bits . Disons que 8 bits sont dépensés (sur la base d'une valeur de 0 à 255) sur un plan de couleur. Ensuite, nous avons une profondeur de couleur de 24 bits (8 bits * 3 plan R / G / B).
Une autre propriété de l'image est la
résolution , qui est le nombre de pixels dans une dimension. Il est souvent appelé
largeur × hauteur , comme ci-dessous dans l'exemple d'image 4 par 4.

Une autre propriété que nous traitons lorsque nous travaillons avec des images / vidéo est le
rapport d'aspect , qui décrit la relation proportionnelle habituelle entre la largeur et la hauteur d'une image ou d'un pixel.
Lorsqu'ils disent qu'un film ou une image mesure 16 x 9, cela se réfère généralement au
rapport d'aspect de l'affichage (
DAR - de
Display Aspect Ratio ). Cependant, il peut parfois y avoir différentes formes de pixels individuels - dans ce cas, nous parlons du
rapport des pixels (
PAR - de
Pixel Aspect Ratio ).


Note à l'hôtesse: le DVD correspond au DAR 4 par 3
Bien que la résolution réelle du DVD soit de 704x480, il conserve néanmoins un rapport d'aspect de 4: 3 puisque le PAR est réglé à 10:11 (704x10 / 480x11).
Et enfin, nous pouvons définir une
vidéo comme une séquence de
n images sur une période de
temps , qui peut être considérée comme une dimension supplémentaire. Et
n est alors la fréquence d'images ou le nombre d'images par seconde (
FPS - à partir d'
images par seconde ).

Le nombre de bits par seconde requis pour afficher une vidéo est son
débit binaire .
bitrate = largeur * hauteur * profondeur de bits * images par seconde
Par exemple, pour des vidéos avec 30 images par seconde, 24 bits par pixel, résolution 480x240, 82 944 000 bits par seconde ou 82 944 Mbit / s (30x480x240x24) seraient nécessaires - mais c'est le cas si vous n'utilisez aucune des méthodes de compression.
Si le débit binaire est
presque constant , il est alors appelé
débit binaire constant (
CBR - à partir d'
un débit binaire constant ). Mais il peut également varier, dans ce cas, il est appelé un
débit binaire variable (
VBR - à partir du
débit binaire variable ).
Ce graphique montre un VBR limité lorsque pas trop de bits sont dépensés dans le cas d'une trame complètement sombre.

Initialement, les ingénieurs ont développé une méthode pour doubler la fréquence d'images perçue d'un affichage vidéo sans utiliser de bande passante supplémentaire. Cette méthode est connue sous le nom de
vidéo entrelacée ; en gros, il envoie la moitié de l'écran dans la première "trame", et l'autre moitié dans la "trame" suivante.
Actuellement, la visualisation des scènes est principalement réalisée à l'aide de
la technologie de balayage progressif . Il s'agit d'une méthode d'affichage, de stockage ou de transmission d'images animées dans laquelle toutes les lignes de chaque image sont dessinées séquentiellement.

Eh bien! Nous savons maintenant comment l'image est représentée sous forme numérique, comment ses couleurs sont organisées, combien de bits par seconde nous dépensons pour montrer la vidéo si la vitesse de transmission est constante (CBR) ou variable (VBR). Nous connaissons une résolution donnée en utilisant une fréquence d'images donnée, nous nous sommes familiarisés avec de nombreux autres termes, tels que vidéo entrelacée, PAR et quelques autres.
Suppression de la redondance
Il est connu que la vidéo sans compression ne peut pas être utilisée normalement. La vidéo horaire avec une résolution de 720p et une fréquence de 30 images par seconde occuperait 278 Go. On arrive à cette valeur en multipliant 1280 x 720 x 24 x 30 x 3600 (largeur, hauteur, bits par pixel, FPS et temps en secondes).
L'utilisation
d'algorithmes de compression sans perte comme DEFLATE (utilisé dans PKZIP, Gzip et PNG) ne réduira pas suffisamment la bande passante requise. Vous devez chercher d'autres moyens de compresser la vidéo.
Pour cela, vous pouvez utiliser les fonctionnalités de notre vision. On distingue une meilleure luminosité que les couleurs. Une vidéo est un ensemble d'images séquentielles qui se répètent au fil du temps. Il existe de petites différences entre les images adjacentes de la même scène. De plus, chaque cadre contient de nombreuses zones qui utilisent la même couleur (ou similaire).
Couleur, luminosité et nos yeux
Nos yeux sont plus sensibles à la luminosité qu'à la couleur. Vous pouvez voir par vous-même en regardant cette photo.
Si vous ne voyez pas que dans la moitié gauche de l'image les couleurs des carrés
A et
B sont en fait les mêmes, alors c'est normal. Notre cerveau nous fait porter plus d'attention au clair-obscur qu'à la couleur. Sur le côté droit entre les carrés marqués, il y a un cavalier de la même couleur - donc nous (c'est-à-dire notre cerveau) pouvons facilement déterminer qu'en fait, la même couleur est là.
Voyons (simplifié) comment nos yeux fonctionnent. L'œil est un organe complexe composé de nombreuses parties. Cependant, nous sommes plus intéressés par les cônes et les bâtons. L'œil contient environ 120 millions de bâtonnets et 6 millions de cônes.
Considérez la perception de la couleur et de la luminosité comme des fonctions distinctes de certaines parties de l'œil (en fait, tout est un peu plus compliqué, mais nous allons simplifier). Les cellules en bâtonnet sont principalement responsables de la luminosité, tandis que les cellules en cône sont responsables de la couleur. Les cônes sont divisés en trois types, selon le pigment contenu: cônes S (bleu), cônes M (vert) et cônes L (rouge).
Comme nous avons beaucoup plus de bâtonnets (luminosité) que de cônes (couleur), nous pouvons conclure que nous sommes plus capables de distinguer les transitions entre l'obscurité et la lumière que les couleurs.

Fonctions de sensibilité au contraste
Les chercheurs en psychologie expérimentale et dans de nombreux autres domaines ont développé de nombreuses théories de la vision humaine. Et l'un d'eux est appelé fonctions de sensibilité au contraste . Ils sont associés à un éclairage spatial et temporel. En bref, il s'agit du nombre de changements nécessaires avant que l'observateur ne les voie. Notez le pluriel du mot «fonction». Cela est dû au fait que nous pouvons mesurer les fonctions de sensibilité pour contraster non seulement avec les images en noir et blanc, mais aussi avec la couleur. Les résultats de ces expériences montrent que dans la plupart des cas, nos yeux sont plus sensibles à la luminosité qu'à la couleur.
Puisqu'il est connu que nous sommes plus sensibles à la luminosité de l'image, vous pouvez essayer d'utiliser ce fait.
Modèle de couleur
Nous avons compris comment travailler avec des images en couleur en utilisant le schéma RVB. Il existe d'autres modèles. Il existe un modèle qui sépare la luminance de la couleur et est connu sous le nom de
YCbCr . Soit dit en passant, il existe d'autres modèles qui font une séparation similaire, mais nous ne considérerons que celui-ci.
Dans ce modèle de couleur,
Y est une représentation de la luminosité et deux canaux de couleur sont utilisés:
Cb (bleu saturé) et
Cr (rouge saturé). YCbCr peut être obtenu à partir de RGB, ainsi que la transformation inverse est possible. En utilisant ce modèle, nous pouvons créer des images en couleur, comme nous le voyons ci-dessous:

Convertir entre YCbCr et RGB
Quelqu'un objectera: comment est-il possible d'obtenir toutes les couleurs si le vert n'est pas utilisé?
Pour répondre à cette question, convertissez RVB en YCbCr. Nous utilisons les coefficients adoptés dans la
norme BT.601 , qui a été recommandée par l'unité
UIT-R . Cette unité définit les normes vidéo numériques. Par exemple: qu'est-ce que la 4K? Quelle devrait être la fréquence d'images, la résolution, le modèle de couleur?
Tout d'abord, nous calculons la luminosité. Nous utilisons les constantes proposées par l'UIT et remplaçons les valeurs RVB.
Y = 0,299
R + 0,587
G + 0,114
BAprès avoir obtenu la luminosité, nous séparerons les couleurs bleues et rouges:
Cb = 0,564 (
B -
Y )
Cr = 0,713 (
R -
Y )
Et nous pouvons également reconvertir et même passer au vert avec YCbCr:
R =
Y + 1,402
CrB =
Y + 1,772
CbG =
Y - 0,344
Cb - 0,714
CrEn règle générale, les écrans (moniteurs, téléviseurs, écrans, etc.) utilisent uniquement le modèle RVB. Mais ce modèle peut être organisé de différentes manières:

Sous-échantillonnage des couleurs
Avec l'image présentée comme une combinaison de luminosité et de couleur, nous pouvons utiliser une sensibilité plus élevée du système visuel humain à la luminosité qu'à la couleur si nous supprimons sélectivement des informations. Le sous-échantillonnage des couleurs est une méthode d'encodage d'images utilisant une résolution plus faible pour la couleur que pour la luminosité.
Est-il acceptable de réduire la résolution des couleurs?! Il s'avère qu'il existe déjà quelques schémas qui décrivent comment gérer la résolution et la fusion
(couleur finale = Y + Cb + Cr).Ces schémas sont connus sous le nom de
systèmes de sous-échantillonnage et sont exprimés sous la forme d'un rapport triple -
a :
x :
y , qui détermine le nombre d'échantillons de signaux de luminance et de différence de couleur.
a - échantillonnage horizontal standard (généralement égal à 4)
x - le nombre d'échantillons de couleur dans la première rangée de pixels (résolution horizontale par rapport à
a )
y est le nombre de changements dans les échantillons de couleurs entre les première et deuxième rangées de pixels.
L'exception est 4 : 1 : 0 , qui fournit un échantillon de couleur dans chaque bloc de résolution de luminosité 4 x 4.
Schémas courants utilisés dans les codecs modernes:
- 4 : 4 : 4 (sans sous-échantillonnage)
- 4 : 2 : 2
- 4 : 1 : 1
- 4 : 2 : 0
- 4 : 1 : 0
- 3 : 1 : 1
YCbCr 4: 2: 0 - Exemple de fusion
Voici le fragment d'image combiné utilisant YCbCr 4: 2: 0. Veuillez noter que nous ne dépensons que 12 bits par pixel.
Voici à quoi ressemble la même image encodée par les principaux types de sous-échantillonnage des couleurs. La première ligne est le YCbCr final, la ligne du bas montre la résolution des couleurs. Des résultats très décents, compte tenu de la faible perte de qualité.

Rappelez-vous, nous avons compté 278 Go d'espace de stockage pour un fichier vidéo d'une heure avec une résolution de 720p et 30 images par seconde? Si nous utilisons YCbCr 4: 2: 0, cette taille sera réduite de moitié - 139 Go. Jusqu'à présent, c'est encore loin d'un résultat acceptable.
Vous pouvez obtenir l'histogramme YCbCr vous-même avec FFmpeg. Dans cette image, le bleu prévaut sur le rouge, qui est clairement visible sur l'histogramme lui-même.

Couleur, luminosité, gamme de couleurs - examen vidéo
Il est recommandé de regarder cette superbe vidéo. Cela explique ce qu'est la luminosité, et en effet, tous les points sont placés au- dessus de la luminosité et de la couleur.
Types de montures
Nous continuons. Essayons d'éliminer la redondance dans le temps. Mais d'abord, définissons une terminologie de base. Supposons que nous ayons un film avec 30 images par seconde, voici ses 4 premières images:




Nous pouvons voir de nombreuses répétitions dans les cadres: par exemple, un fond bleu qui ne change pas d'un cadre à l'autre. Pour résoudre ce problème, nous pouvons les classer de manière abstraite en trois types de trames.
Cadre I (cadre I ntro)
La trame I (trame de référence, trame clé, trame interne) est autonome. Indépendamment de ce qui doit être visualisé, le cadre en I est, en fait, une photographie statique. La première image est généralement une I-frame, mais nous observerons régulièrement des I-frames loin des premières images.
Cadre P (cadre P reddit)
L'image P (image prédite) tire parti du fait que presque toujours l'image actuelle peut être lue en utilisant l'image précédente. Par exemple, dans la deuxième image, le seul changement est la balle avant. Nous pouvons obtenir l'image 2 en modifiant légèrement l'image 1, en utilisant uniquement la différence entre ces images. Pour construire le cadre 2, reportez-vous au cadre 1 qui le précède.
←

Trame B (trame B i-prédictive)
Qu'en est-il des liens non seulement vers les images passées, mais aussi vers les images futures, pour une compression encore meilleure? Il s'agit essentiellement d'une trame B (trame bidirectionnelle).
←
→
Retrait intermédiaire
Ces types de trames sont utilisés pour fournir la meilleure compression. Nous verrons comment cela se produit dans la section suivante. En attendant, on note que l'image I est la plus «chère» en termes de mémoire, l'image P est beaucoup moins chère, mais l'image B est l'option la plus rentable pour la vidéo.

Redondance temporelle (prédiction inter-trames)
Voyons quelles opportunités nous avons pour minimiser les répétitions de temps. Ce type de redondance peut être résolu en utilisant les méthodes de prévision mutuelle.
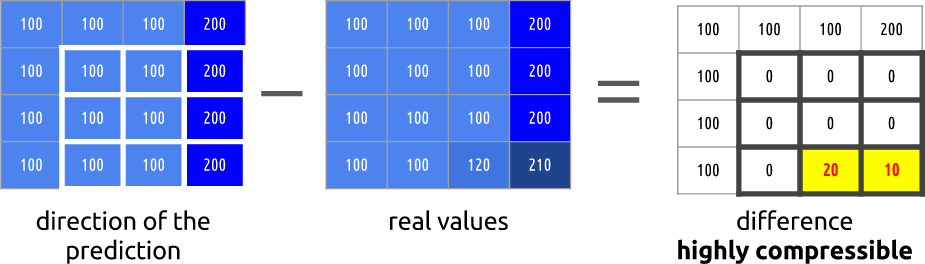
Nous allons essayer de dépenser le moins de bits possible pour encoder une séquence de trames 0 et 1.

Nous pouvons
soustraire , simplement soustraire l'image 1 de l'image 0. Nous obtenons l'image 1, nous utilisons uniquement la différence entre celle-ci et l'image précédente, en fait, nous encodons uniquement le reste résultant.

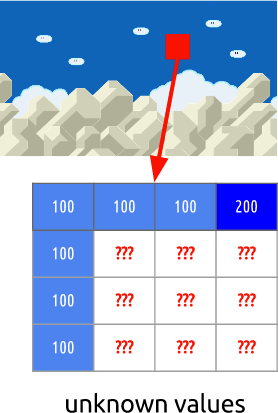
Mais que se passe-t-il si je vous dis qu'il existe une méthode encore meilleure qui utilise encore moins de bits?! Tout d'abord, décomposons l'image 0 en une grille claire de blocs. Et puis nous essayons de comparer les blocs de l'image 0 avec l'image 1. En d'autres termes, nous évaluons le mouvement entre les images.
De Wikipedia - compensation de mouvement de bloc
La compensation de mouvement de bloc divise la trame actuelle en blocs disjoints et le vecteur de compensation de mouvement signale l'origine des blocs (une idée fausse commune est que la trame précédente est divisée en blocs disjoints, et les vecteurs de compensation de mouvement indiquent où vont ces blocs. Mais en fait, pas le précédent n'est analysé le cadre, et le suivant, il s'avère non pas où les blocs se déplacent, mais d'où ils viennent). En règle générale, les blocs source se chevauchent dans le cadre source. Certains algorithmes de compression vidéo collectent l'image actuelle à partir de parties non seulement d'une, mais de plusieurs images précédemment transmises.

Dans le processus d'évaluation, nous voyons que la balle est passée de
( x = 0,
y = 25) à
( x = 6,
y = 26), les valeurs de
x et
y déterminent le vecteur de mouvement. Une autre étape que nous pouvons prendre pour enregistrer les bits est de coder uniquement la différence des vecteurs de mouvement entre la dernière position du bloc et celle prédite, de sorte que le vecteur de mouvement final sera
(x = 6-0 = 6, y = 26-25 = 1).Dans une situation réelle, cette balle serait divisée en
n blocs, mais cela ne change pas l'essence de la question.
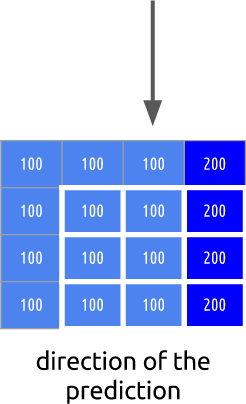
Les objets dans le cadre se déplacent en trois dimensions, donc lorsque la balle se déplace, elle peut devenir visuellement plus petite (ou plus si elle se déplace vers le spectateur). Il est normal qu'il n'y ait pas de correspondance parfaite entre les blocs. Voici une vue combinée de notre évaluation et de l'image réelle.

Mais nous voyons que lorsque nous appliquons l'estimation de mouvement, les données pour l'encodage sont sensiblement inférieures à celles de la méthode plus simple de calcul du delta entre les images.

À quoi ressemblera la compensation de mouvement réelle
Cette technique s'applique immédiatement à tous les blocs. Souvent, notre balle en mouvement conditionnelle sera divisée en plusieurs blocs à la fois.

,
Jupyter .
ffmpeg .
 ffmpeg") Intel Video Pro Analyzer
Intel Video Pro Analyzer ( , , ).
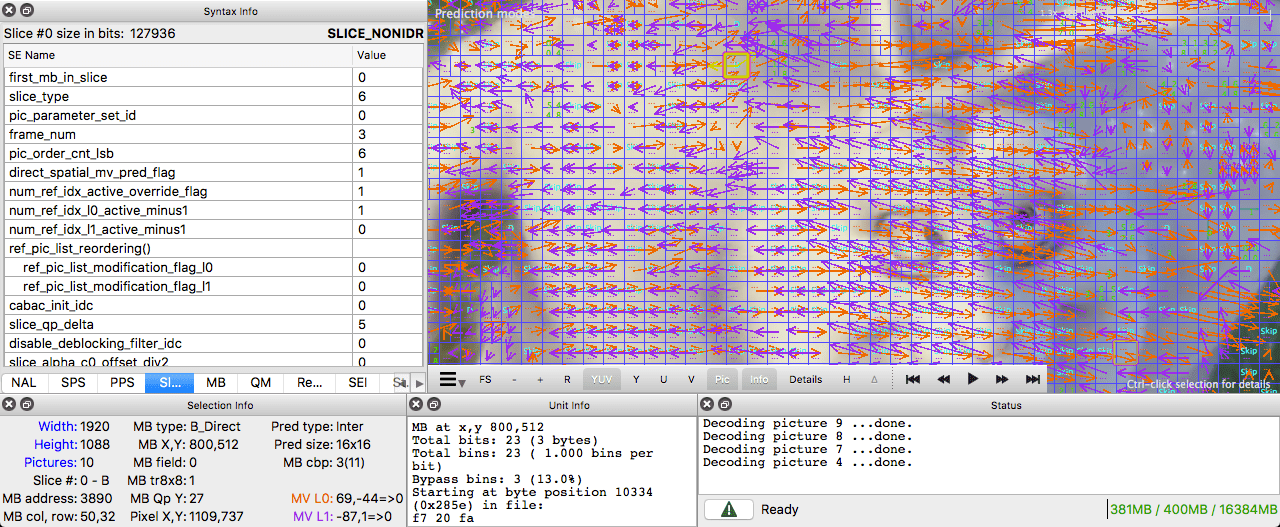
( )
, .

. .

I-. , . . , , - .
, . , .
. ( ), . , .
, ffmpeg. ffmpeg.
 ffmpeg")
Intel Video Pro Analyzer ( , 10 , ).

:

Lisez aussi le blog
Société EDISON:
20 bibliothèques pour
application iOS spectaculaire