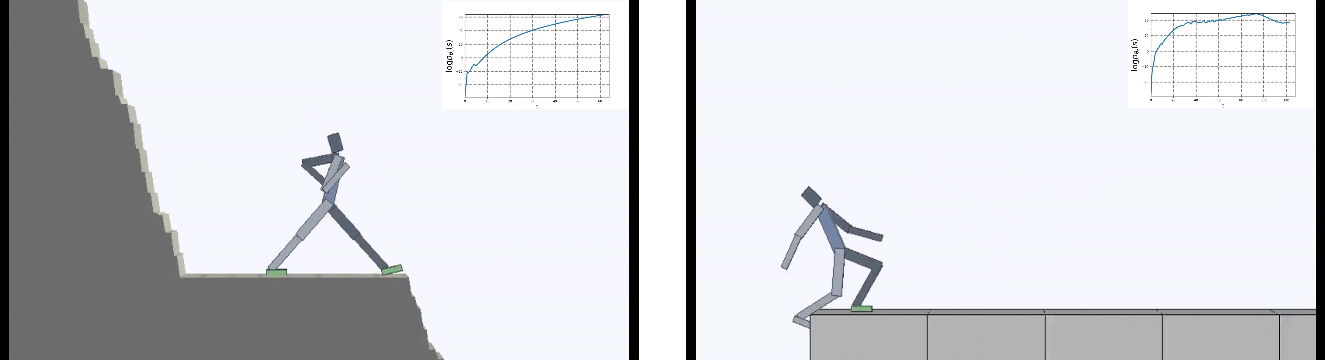
L'apprentissage par renforcement utilise souvent la curiosité comme motivation pour l'IA. Le forçant à rechercher de nouvelles sensations et à explorer le monde. Mais la vie est pleine de mauvaises surprises. Vous pouvez tomber d'une falaise et du point de vue de la curiosité ce seront toujours des sensations très nouvelles et intéressantes. Mais évidemment pas pour quoi lutter.
Les développeurs de Berkeley ont bouleversé la tâche de l'agent virtuel: ce n'est pas la curiosité qui a fait la principale force de motivation, mais plutôt le désir d'éviter toute nouveauté par tous les moyens. Mais "ne rien faire" était plus difficile qu'il n'y paraît. Étant placée dans un environnement en constante évolution, l'IA devait apprendre des comportements complexes afin d'éviter de nouvelles sensations.
L'apprentissage par renforcement prend des mesures timides pour construire une IA solide. Et tandis que tout est limité à de très faibles dimensions, littéralement les unités dans lesquelles l'agent virtuel doit agir (de préférence raisonnablement), de nouvelles idées apparaissent de temps en temps pour améliorer la formation de l'intelligence artificielle.
Mais non seulement les algorithmes d'apprentissage sont compliqués. L'environnement devient également plus difficile. La plupart des environnements d'apprentissage par renforcement sont très simples et motivent l'agent à explorer le monde. Il peut s'agir d'un labyrinthe qui doit être complètement contourné pour trouver une issue, ou d'un jeu informatique qui doit être complété jusqu'au bout.
Mais à long terme, les êtres vivants (raisonnables et pas si) s'efforcent non seulement d'explorer le monde qui les entoure. Mais aussi pour garder tout le bien qui est dans leur courte (ou pas) vie.
C'est ce qu'on appelle l'homéostasie - le désir du corps de maintenir un état constant. Sous une forme ou une autre, cela est commun à tous les êtres vivants. Les développeurs de Berkeley donnent un exemple si étrange: toutes les réalisations de l'humanité, dans l'ensemble, sont conçues pour se protéger contre les mauvaises surprises. Protéger contre une entropie toujours croissante de l'environnement. Nous construisons des maisons où nous maintenons une température constante, à l'abri des changements climatiques. Nous utilisons des médicaments pour être constamment en bonne santé et ainsi de suite.
On peut contester cela, mais il y a vraiment quelque chose dans cette analogie.
Les gars ont posé la question - que se passera-t-il si la principale motivation de l'IA est d'essayer d'éviter toute nouveauté? En d'autres termes, minimisez le chaos en tant que fonction d'apprentissage objectif.
Et ils ont placé l'agent dans un monde dangereux en constante évolution.
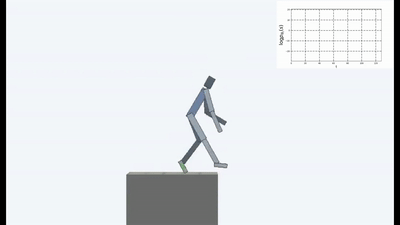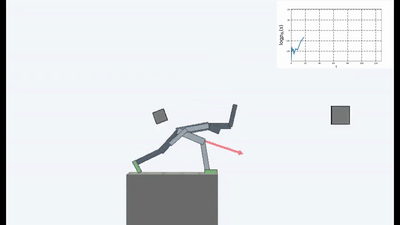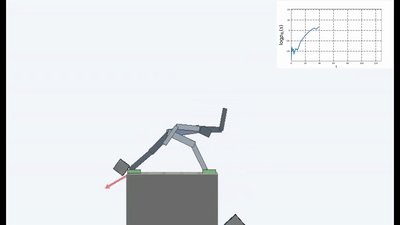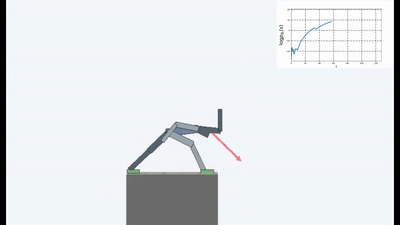
Les résultats étaient intéressants. Dans de nombreux cas, cet apprentissage a dépassé l'apprentissage basé sur le curriculum et, le plus souvent, en termes de qualité, se rapproche de l'apprentissage avec un enseignant. Autrement dit, à une formation spécialisée pour atteindre un objectif spécifique - pour gagner le match, passez par le labyrinthe.
C'est bien sûr logique, car si vous vous tenez sur un pont qui s'effondre, alors pour continuer à y être (pour maintenir la constance et éviter que de nouvelles sensations ne tombent), vous devez constamment vous éloigner du bord. Fuyez de toutes ses forces pour rester immobile, comme l'a dit Alice.

Et en fait, dans tout algorithme d'apprentissage par renforcement, il y a un tel moment. Parce que les morts dans le jeu et la fin rapide de l'épisode sont pénalisées par une récompense négative. Ou, selon l'algorithme, en réduisant la récompense maximale qu'un agent pourrait recevoir s'il ne tombait pas continuellement de la falaise.
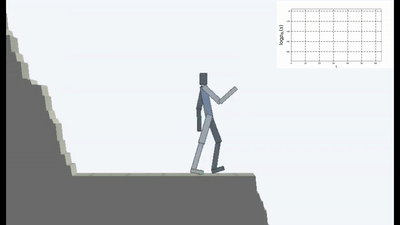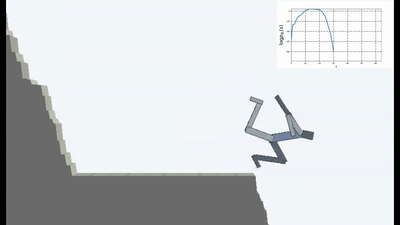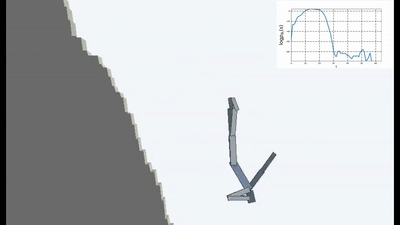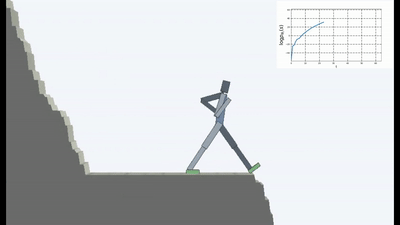
Mais c'est dans une telle formulation, quand l'IA n'a d'autre objectif que le désir d'éviter la nouveauté, qu'il semble qu'elle ait été utilisée pour la première fois dans l'apprentissage renforcé.
Fait intéressant, avec une telle motivation, l'agent virtuel a appris à jouer à de nombreux jeux qui ont pour objectif de gagner. Par exemple, tetris.

Ou l'environnement de Doom, où vous devez esquiver des boules de feu volantes et tirer sur des adversaires qui approchent. Parce que de nombreuses tâches peuvent être formulées comme des tâches de maintien de la constance. Pour Tetris, c'est le désir de laisser le champ vide. L'écran se remplit-il constamment? Oh mon cher, que se passera-t-il quand il sera rempli à la fin? Non, non, nous n'avons pas besoin d'un tel bonheur. Trop de choc.
Du côté technique, il est arrangé tout simplement. Lorsqu'un agent reçoit un nouvel état, il évalue à quel point cet état est familier. Autrement dit, combien le nouvel État est inclus dans la répartition de l'État qu'il a visité plus tôt. L'agent entre dans un état plus familier, plus la récompense est grande. Et la tâche de la politique d'apprentissage (ce sont tous les termes de l'apprentissage par renforcement, si quelqu'un ne le sait pas) est de choisir des actions qui mèneraient à la transition vers l'état le plus familier. De plus, chaque nouvel état obtenu est utilisé pour mettre à jour les statistiques des états familiers avec lesquels de nouveaux états sont comparés.
Fait intéressant, dans le processus de l'IA, j'ai spontanément appris à comprendre que de nouveaux États influencent ce qui est considéré comme une nouveauté. Et que vous pouvez atteindre des états familiers de deux manières: soit passez à un état déjà connu. Ou entrer dans un état qui mettra à jour le concept même de persistance / familiarité de l'environnement, et l'agent sera dans un nouvel état, formé par ses actions, familier.
Cela oblige l'agent à entreprendre des actions coordonnées complexes, ne serait-ce que pour ne rien faire dans la vie.
Paradoxalement, cela conduit à un analogue de la curiosité de l'apprentissage ordinaire et force l'agent à explorer le monde qui l'entoure. Soudain, quelque part, il y a un endroit encore plus sûr qu'ici et maintenant? Là, vous pouvez vous adonner complètement à la paresse et ne rien faire, évitant ainsi tout problème et toute nouvelle sensation. Il ne serait pas exagéré de dire que de telles pensées sont probablement venues à l'un d'entre nous. Et pour beaucoup, c'est une véritable force motrice dans la vie. Bien que dans la vraie vie, aucun de nous n'ait dû faire face à un remplissage de tetris jusqu'au sommet, bien sûr.
Pour être honnête, c'est une histoire compliquée. Mais la pratique montre que cela fonctionne. Les chercheurs ont comparé cet algorithme aux meilleurs représentants basés sur la curiosité: ICM et RND . Le premier est un mécanisme efficace de curiosité qui est déjà devenu classique dans l'apprentissage par renforcement. L'agent ne cherche pas simplement de nouveaux états inconnus et donc intéressants. La méconnaissance de la situation dans de tels algorithmes est estimée par la capacité de l'agent à la prédire (au début, il y avait littéralement des compteurs d'états visités, mais maintenant tout se résume à l'estimation intégrale fournie par le réseau neuronal). Mais dans ce cas, les feuilles en mouvement sur les arbres ou le bruit blanc à la télévision auraient une nouveauté sans fin pour un tel agent, et auraient provoqué une curiosité sans fin. Parce qu'il ne peut jamais prédire tous les nouveaux états possibles dans un environnement complètement aléatoire.
Par conséquent, dans ICM, un agent recherche uniquement les nouveaux états qu'il peut influencer par ses actions. L'IA peut-elle affecter le bruit blanc à la télévision? Non. Si inintéressant. Et cela peut-il affecter le ballon si vous le déplacez? Oui Jouer avec le ballon est donc intéressant. Pour ce faire, ICM utilise une idée très cool avec le modèle inverse, avec lequel le modèle avancé est comparé. Plus de détails dans l' oeuvre originale .
RND est un développement plus récent du mécanisme de curiosité. Ce qui dans la pratique a dépassé l'ICM. En bref, le réseau neuronal essaie de prédire les sorties d'un autre réseau neuronal, qui est initié par des poids aléatoires et ne change jamais. Il est supposé que plus la situation est familière (alimentée à l'entrée des deux réseaux de neurones, actuels et initiés de manière aléatoire), plus souvent le réseau de neurones actuel sera en mesure de prédire les sorties initiées de manière aléatoire. Je ne sais pas qui invente tout cela. D'une part, je veux serrer la main d'une telle personne et, d'autre part, donner un coup de pied à de telles distorsions.
Mais d'une manière ou d'une autre, et la formation sur l'idée de maintenir l'homéostasie et d'essayer d'éviter toute nouveauté, dans de nombreux cas, dans la pratique, on a obtenu un meilleur résultat final qu'un programme basé sur le CII ou le RND. Ce qui se reflète dans les graphiques.
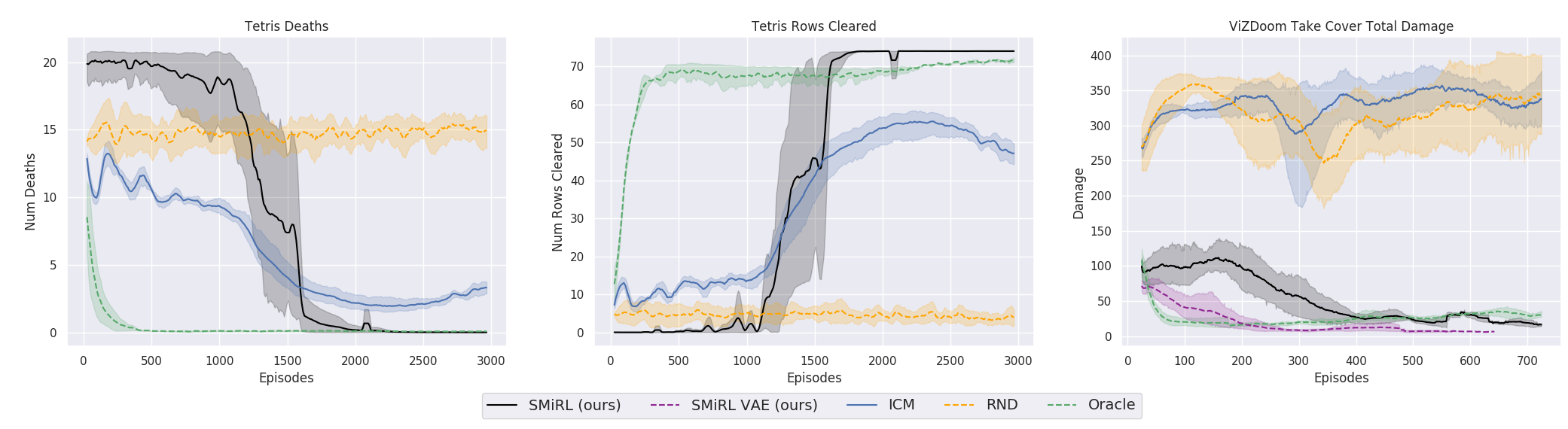
Mais ici, il est nécessaire de préciser que ce n'est que pour les environnements que les chercheurs ont utilisés dans leur travail. Ils sont dangereux, aléatoires, bruyants et avec une entropie croissante. Il peut vraiment être plus rentable de ne rien y faire. Et ce n'est qu'occasionnellement qu'il se déplace activement lorsqu'une boule de feu vole en vous ou que le pont derrière vous commence à s'effondrer. Cependant, les chercheurs de Berkeley insistent, apparemment à cause de leur expérience de vie difficile, que de tels environnements sont beaucoup plus proches de la vie réelle complexe que ceux utilisés auparavant dans la formation de renforcement. Eh bien, je ne sais pas, je ne sais pas. Dans ma vie, des boules de feu de monstres volant en moi et des labyrinthes inhabités avec une seule sortie se trouvent à peu près à la même fréquence. Mais on ne peut nier que l'approche proposée, avec toute sa simplicité, a donné des résultats étonnants. Peut-être qu'à l'avenir, les deux approches devraient être raisonnablement combinées - l'homéostasie avec la préservation d'une constance positive à long terme et la curiosité pour les études environnementales actuelles.
Lien vers l'œuvre originale