
Le but de cet article est d'apprendre au réseau neuronal à jouer au jeu Life sans lui enseigner les règles du jeu.
Bonjour, Habr! Je vous présente la traduction de l'article "Utiliser un réseau de neurones convolutionnels pour jouer au jeu de la vie de Conway avec Keras" par kylewbanks.
Si vous n'êtes pas familier avec le jeu appelé Life ( c'est un automate cellulaire inventé par le mathématicien anglais John Conway en 1970 ), les règles sont les suivantes.
L'univers du jeu est une grille infinie et bidimensionnelle de cellules carrées, dont chacune est dans l'un des deux états possibles: vivant ou mort (ou habité et inhabité, respectivement). Chaque cellule interagit avec ses huit voisins horizontalement, verticalement ou en diagonale. À chaque pas de temps, les transitions suivantes se produisent:
- Toute cellule vivante avec moins de deux voisins vivants meurt.
- Toute cellule vivante avec deux ou trois voisins vivants survit à la génération suivante.
- Toute cellule vivante avec plus de trois voisins vivants meurt.
- Toute cellule morte avec exactement trois voisins vivants devient une cellule vivante.
La première génération est créée en appliquant les règles ci-dessus simultanément à chaque cellule dans l'état initial, la naissance et la mort se produisent simultanément à des moments discrets. Chaque génération est une pure fonction de la précédente. Les règles continuent de s'appliquer à la nouvelle génération pour créer la prochaine génération.
Voir Wikipedia pour plus de détails.
Pourquoi faire ça? Principalement pour le divertissement et pour en savoir un peu plus sur les réseaux de neurones convolutifs.
Alors ...
Logique du jeu
La première chose à faire est de définir une fonction qui prend le terrain de jeu en entrée et renvoie l'état suivant.
Heureusement, de nombreuses implémentations sont disponibles sur Internet, telles que: https://jakevdp.imtqy.com/blog/2013/08/07/conways-game-of-life/ .
En fait, il prend la matrice du terrain de jeu en entrée, où 0 représente une cellule morte, et 1 représente une cellule vivante et renvoie une matrice de la même taille, mais contenant l'état de chaque cellule à la prochaine itération du jeu.
import numpy as np def life_step(X): live_neighbors = sum(np.roll(np.roll(X, i, 0), j, 1) for i in (-1, 0, 1) for j in (-1, 0, 1) if (i != 0 or j != 0)) return (live_neighbors == 3) | (X & (live_neighbors == 2)).astype(int)
Génération de terrains de jeu
Suivant la logique du jeu, nous avons besoin d'un moyen de générer aléatoirement des champs de jeu et un moyen de les visualiser.
La fonction generate_frames crée num_frames champs de jeu aléatoires avec une certaine forme et une probabilité prédéterminée que chaque cellule sera "en direct", et render_frames dessine côte à côte des images de deux champs de jeu pour comparaison (les cellules vivantes sont blanches et les cellules mortes sont noires):
import matplotlib.pyplot as plt def generate_frames(num_frames, board_shape=(100,100), prob_alive=0.15): return np.array([ np.random.choice([False, True], size=board_shape, p=[1-prob_alive, prob_alive]) for _ in range(num_frames) ]).astype(int) def render_frames(frame1, frame2): plt.subplot(1, 2, 1) plt.imshow(frame1.flatten().reshape(board_shape), cmap='gray') plt.subplot(1, 2, 2) plt.imshow(frame2.flatten().reshape(board_shape), cmap='gray')
Voyons à quoi ressemblent ces champs:
board_shape = (20, 20) board_size = board_shape[0] * board_shape[1] probability_alive = 0.15 frames = generate_frames(10, board_shape=board_shape, prob_alive=probability_alive) print(frames.shape)
(10, 20, 20)
print(frames[0])
[[0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1], [1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], [1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0]])
Ensuite, une représentation entière du terrain de jeu est prise et affichée sous forme d'image.
L'état suivant du terrain de jeu est également affiché à droite à l'aide de la fonction life_step :
ender_frames(frames[1], life_step(frames[1]))

Création de kits de formation et de test
Nous pouvons maintenant générer des données pour la formation, la vérification et les tests.
Chaque élément dans les y_train / y_val / y_test représentera le champ de jeu suivant pour chaque image du champ dans X_train / X_val / X_test .
def reshape_input(X): return X.reshape(X.shape[0], X.shape[1], X.shape[2], 1) def generate_dataset(num_frames, board_shape, prob_alive): X = generate_frames(num_frames, board_shape=board_shape, prob_alive=prob_alive) X = reshape_input(X) y = np.array([ life_step(frame) for frame in X ]) return X, y train_size = 70000 val_size = 10000 test_size = 20000
print("Training Set:") X_train, y_train = generate_dataset(train_size, board_shape, probability_alive) print(X_train.shape) print(y_train.shape)
Training Set: (70000, 20, 20, 1) (70000, 20, 20, 1)
print("Validation Set:") X_val, y_val = generate_dataset(val_size, board_shape, probability_alive) print(X_val.shape) print(y_val.shape)
Validation Set: (10000, 20, 20, 1) (10000, 20, 20, 1)
print("Test Set:") X_test, y_test = generate_dataset(test_size, board_shape, probability_alive) print(X_test.shape) print(y_test.shape)
Test Set: (20000, 20, 20, 1) (20000, 20, 20, 1)
Construction de réseaux de neurones convolutifs
Maintenant, nous pouvons faire le premier pas vers la construction d'un réseau de neurones convolutionnels en utilisant Keras. Le point clé ici est la taille du noyau (3, 3) et l'étape 1. Ils indiquent à CNN d'utiliser une matrice 3x3 de cellules environnantes pour chaque cellule du champ qu'il regarde, y compris la cellule actuelle.
Par exemple, si ce qui suit était un champ de jeu et que nous étions dans la cellule du milieu x , elle regarderait toutes les cellules marquées d'un point d'exclamation ! et la cellule
0 0 0 0 0 0! ! ! 0 0! x ! 0 0! ! ! 0 0 0 0 0 0
Le reste du réseau est assez simple, donc je n'entrerai pas dans les détails. Si vous êtes intéressé par quelque chose, je vous recommande de lire la documentation.
from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Conv2D, MaxPool2D
Jetez un œil à la sortie de la fonction de summary :
model.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_9 (Conv2D) (None, 20, 20, 50) 500 _________________________________________________________________ dense_17 (Dense) (None, 20, 20, 100) 5100 _________________________________________________________________ dense_18 (Dense) (None, 20, 20, 1) 101 _________________________________________________________________ activation_9 (Activation) (None, 20, 20, 1) 0 ================================================================= Total params: 5,701 Trainable params: 5,701 Non-trainable params: 0 _________________________________________________________________
Formation et sauvegarde d'un modèle
Après avoir construit CNN, entraînons le modèle et l'enregistrons sur le disque:
def train(model, X_train, y_train, X_val, y_val, batch_size=50, epochs=2, filename_suffix=''): model.fit( X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_val, y_val) ) with open('cgol_cnn{}.json'.format(filename_suffix), 'w') as file: file.write(model.to_json()) model.save_weights('cgol_cnn{}.h5'.format(filename_suffix)) train(model, X_train, y_train, X_val, y_val, filename_suffix='_basic')
Train on 70000 samples, validate on 10000 samples Epoch 1/2 70000/70000 [==============================] - 27s 388us/step - loss: 0.1324 - acc: 0.9651 - val_loss: 0.0833 - val_acc: 0.9815 Epoch 2/2 70000/70000 [==============================] - 27s 383us/step - loss: 0.0819 - acc: 0.9817 - val_loss: 0.0823 - val_acc: 0.9816
Ce modèle offre une précision d'un peu plus de 98% pour les ensembles d'entraînement et de test, ce qui est très bon pour la première passe. Essayons de découvrir où nous commettons des erreurs.
Essayez
Regardons les prévisions pour un terrain de jeu aléatoire et comment cela fonctionne. Tout d'abord, créez un terrain de jeu et regardez la prochaine image correcte:
X, y = generate_dataset(1, board_shape=board_shape, prob_alive=probability_alive) render_frames(X[0].flatten().reshape(board_shape), y)

Ensuite, faisons la prédiction et voyons combien de cellules ont été incorrectement prédites:
pred = model.predict_classes(X) print(np.count_nonzero(pred.flatten() - y.flatten()), "incorrect cells.")
4 incorrect cells.
Ensuite, comparons la prochaine étape correcte avec l'étape prévue:
render_frames(y, pred.flatten().reshape(board_shape))
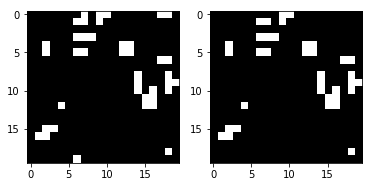
Ce n'est pas effrayant, mais vous voyez où la prédiction a échoué? Il semble que le réseau ne puisse pas prédire les cellules aux bords du terrain de jeu. Voyons où les valeurs non nulles indiquent des prédictions incorrectes:
print(pred.flatten().reshape(board_shape) - y.flatten().reshape(board_shape))
[[ 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 -1 -1 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 0 0 0 0]]
Comme vous pouvez le voir, toutes les valeurs non nulles sont situées sur les bords du terrain de jeu. Examinons la suite de tests complète et confirmons que cette observation est vraie.
Afficher les bogues à l'aide de la suite de tests
Nous allons écrire une fonction qui affiche une carte thermique montrant où le modèle fait des erreurs, et l'appeler en utilisant la suite de tests entière:
def view_prediction_errors(model, X, y): y_pred = model.predict_classes(X) sum_y_pred = np.sum(y_pred, axis=0).flatten().reshape(board_shape) sum_y = np.sum(y, axis=0).flatten().reshape(board_shape) plt.imshow(sum_y_pred - sum_y, cmap='hot', interpolation='nearest') plt.show() view_prediction_errors(model, X_test, y_test)

Toutes les erreurs sur les bords et les coins. Ce qui est logique, car CNN ne peut pas regarder autour de lui, mais la logique du jeu dans life_step fait. Par exemple, considérez ce qui suit. En regardant la cellule de bord x ci-dessous, CNN ne voit que x et ! cellules:
0 0 0 0 0 ! ! 0 0 0 x ! 0 0 0 ! ! 0 0 0 0 0 0 0 0
Mais ce que nous voulons vraiment et ce life_step fait life_step c'est regarder les cellules du côté opposé:
0 0 0 0 0 ! ! 0 0 ! x ! 0 0 ! ! ! 0 0 ! 0 0 0 0 0
Une situation similaire dans les coins:
x ! 0 0 ! ! ! 0 0 ! 0 0 0 0 0 0 0 0 0 0 ! 0 0 0 !
Pour résoudre ce problème, Conv2D doit en quelque sorte regarder du côté opposé du terrain de jeu. Alternativement, chaque champ de saisie peut être prétraité pour remplir les bords du côté opposé, puis Conv2D peut simplement supprimer la première ou la dernière colonne et ligne. Étant donné que nous sommes à la merci de Keras et que la fonctionnalité de remplissage qu'il propose ne prend pas en charge ce que nous recherchons, nous devrons recourir à l'ajout de notre propre remplissage.
Correction des défauts d'arête par remplissage
Nous devons compléter chaque terrain de jeu avec une valeur opposée pour imiter le fonctionnement de life_step pour les valeurs de bord. Nous pouvons utiliser np.pad avec mode = 'wrap' pour cela. Par exemple, considérez le tableau suivant et la sortie augmentée ci-dessous:
x = np.array([ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]) print(np.pad(x, (1, 1), mode='wrap'))
[[9, 7, 8, 9, 7], [3, 1, 2, 3, 1], [6, 4, 5, 6, 4], [9, 7, 8, 9, 7], [3, 1, 2, 3, 1]]
Notez que la première colonne / ligne et la dernière colonne / ligne reflètent le côté opposé de la matrice d'origine, et la matrice 3x3 du milieu est la valeur x origine. Par exemple, la cellule [1] [1] a été copiée du côté opposé dans la cellule [4] [1] et, de la même manière que [0] [1], elle contient [3] [1]. Dans toutes les directions et même dans les coins, le réseau a été corrigé de sorte qu'il contenait le côté opposé. Cela permettra à CNN d'examiner l'ensemble du terrain de jeu et de gérer correctement les cas extrêmes.
Maintenant, nous pouvons écrire une fonction pour remplir toutes nos matrices d'entrée:
def pad_input(X): return reshape_input(np.array([ np.pad(x.reshape(board_shape), (1,1), mode='wrap') for x in X ])) X_train_padded = pad_input(X_train) X_val_padded = pad_input(X_val) X_test_padded = pad_input(X_test) print(X_train_padded.shape) print(X_val_padded.shape) print(X_test_padded.shape)
(70000, 22, 22, 1) (10000, 22, 22, 1) (20000, 22, 22, 1)
Tous les jeux de données sont désormais complétés par des colonnes / lignes enveloppées, ce qui permet à CNN de voir le côté opposé du terrain de jeu, comme le fait life_step . Pour cette raison, chaque terrain de jeu a maintenant une taille de 22x22 au lieu du 20x20 d'origine.
Ensuite, CNN doit être reconstruit pour supprimer le remplissage en utilisant padding = 'valid' (qui indique à Conv2D de supprimer les bords, bien que ce ne soit pas immédiatement évident), et de gérer la nouvelle input_shape . Ainsi, lorsque nous sautons les champs de lecture avec une taille de 22x22, nous obtenons toujours une taille de 20x20 en sortie, car nous supprimons la première et la dernière colonne / ligne. Le reste reste identique:
model_padded = Sequential() model_padded.add(Conv2D( filters, kernel_size, padding='valid', activation='relu', strides=strides, input_shape=(board_shape[0] + 2, board_shape[1] + 2, 1) )) model_padded.add(Dense(hidden_dims)) model_padded.add(Dense(1)) model_padded.add(Activation('sigmoid')) model_padded.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model_padded.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_10 (Conv2D) (None, 20, 20, 50) 500 _________________________________________________________________ dense_19 (Dense) (None, 20, 20, 100) 5100 _________________________________________________________________ dense_20 (Dense) (None, 20, 20, 1) 101 _________________________________________________________________ activation_10 (Activation) (None, 20, 20, 1) 0 ================================================================= Total params: 5,701 Trainable params: 5,701 Non-trainable params: 0 _________________________________________________________________
Maintenant, nous pouvons apprendre en utilisant le champ aligné:
train( model_padded, X_train_padded, y_train, X_val_padded, y_val, filename_suffix='_padded' )
Train on 70000 samples, validate on 10000 samples Epoch 1/2 70000/70000 [==============================] - 27s 389us/step - loss: 0.0604 - acc: 0.9807 - val_loss: 4.5475e-04 - val_acc: 1.0000 Epoch 2/2 70000/70000 [==============================] - 27s 382us/step - loss: 1.7058e-04 - acc: 1.0000 - val_loss: 5.9932e-05 - val_acc: 1.0000
La précision de la prédiction est de 98% à 100%, que nous avons reçue avant d'ajouter l'indentation. Regardons l'erreur sur le cas de test:
view_prediction_errors(model_padded, X_test_padded, y_test)

Super! La carte de chaleur noire indique qu'il n'y a pas de différences de valeurs, ce qui signifie que nous avons réussi à prédire chaque cellule pour chaque jeu.
C'était un petit exercice amusant de jouer avec des réseaux de neurones convolutifs sans utiliser un grand ensemble de données. N'hésitez pas à vérifier sur GitHub .