Il a longtemps été une idée de voir ce que vous pouvez faire avec ELK et des sources improvisées de journaux et de statistiques. Sur les pages du Habr, je prévois de montrer un exemple pratique de la façon dont, en utilisant un mini-serveur domestique, vous pouvez faire, par exemple, un pot de miel avec un système d'analyse de journal basé sur la pile ELK. Dans cet article, je vais vous parler de l'exemple le plus simple d'analyse des journaux de pare-feu à l'aide de la pile ELK. À l'avenir, je voudrais décrire les paramètres d'environnement pour analyser le trafic Netflow et les vidages PCAP par Zeek.
Si vous avez une adresse IP publique et un appareil plus ou moins intelligent comme passerelle / pare-feu, vous pouvez organiser un pot de miel passif en configurant des demandes entrantes pour des ports TCP et UDP «délicieux». Il existe un exemple de configuration d'un routeur Mikrotik sous un chat, mais si vous avez un routeur de fournisseur différent (ou un autre système de sécurité) à portée de main, il vous suffit de comprendre un peu de formats de données et de paramètres spécifiques au fournisseur, et vous obtiendrez le même résultat.
Clause de non-responsabilité
L'article ne prétend pas être original, il ne traite pas des questions de tolérance aux pannes des services, de sécurité, de bonnes pratiques, etc. Il est nécessaire de considérer ce matériel comme académique, il convient à la connaissance des fonctionnalités de base de la pile ELK et du mécanisme d'analyse des journaux du périphérique réseau. Cependant, cela pourrait aussi être intéressant pour un novice.
Le projet est lancé à partir du fichier docker-compose, et il est très facile de déployer votre environnement similaire, même si vous avez un routeur de fournisseur différent sous la main, il vous suffit de comprendre un peu les formats de données et les paramètres spécifiques au fournisseur. Pour le reste, j'ai essayé de décrire autant que possible toutes les nuances associées à la configuration des pipelines Logstash et des mappages Elasticsearch dans la version actuelle d'ELK. Tous les composants de ce système sont hébergés sur
github , y compris les configurations de service. À la fin de l'article, je ferai la section Dépannage, qui décrira les étapes pour diagnostiquer les problèmes courants des nouveaux arrivants dans cette entreprise.
Présentation
Sur le serveur lui-même, j'ai installé le système de virtualisation Proxmox, sur celui-ci dans les conteneurs Docker de la machine KVM sont lancés. On suppose que vous savez comment fonctionnent Docker et Docker-compose, l'avantage de définir des exemples d'utilisation sur Internet est suffisant. Je n'aborderai pas les problèmes d'installation de Docker, j'écrirai un peu sur docker-compose.
L'idée de lancer Honeypot est née lors de l'étude d'Elasticsearch, Logstash et Kibana. Dans ma carrière professionnelle, je n'ai jamais été impliqué dans l'administration et l'utilisation générale de cette pile, mais j'ai des projets de loisirs, grâce auxquels j'ai développé un grand intérêt à explorer les possibilités offertes par le moteur de recherche Elasticsearch et Kibana, avec lesquelles vous pouvez analyser et visualiser des données.
Mon pas le plus récent mini-serveur NUC avec 8 Go de RAM est juste suffisant pour démarrer la pile ELK avec un nœud Elastic. Dans les environnements de production, cela, bien sûr, n'est pas recommandé, mais juste pour la formation. Concernant la question de la sécurité, il y a une remarque à la fin de l'article.
Internet regorge d'instructions pour installer et configurer la pile ELK pour des tâches similaires (par exemple,
analyser les attaques par force brute sur ssh à l'aide de Logstash version 2 ,
analyser les journaux Suricata à l'aide de Filebeat version 6 ), mais dans la plupart des cas, l'attention n'est pas accordée aux détails, à cela 90 pour cent du matériel sera pour les versions 1 à 6 (au moment de la rédaction, la version actuelle d'ELK est 7.5.0). Ceci est important, car à partir de la version 6, Elasticsearch a
décidé de supprimer l' entité de type de mappage, modifiant ainsi la syntaxe de la requête et la structure de la carte. Le modèle de mappage dans Elastic est généralement un objet très important, et pour que plus tard il n'y ait plus de problèmes avec l'échantillonnage et la visualisation des données, je vous conseille de ne pas vous impliquer dans le copier-coller et d'essayer de comprendre ce que vous faites. De plus, je vais essayer d'expliquer clairement ce que signifient les opérations et les configurations décrites.
Configuration du routeur
Pour le réseau domestique, j'utilise Mikrotik comme routeur, donc un exemple sera pour lui. Mais presque n'importe quel système peut être configuré pour envoyer syslog à un serveur distant, que ce soit un routeur, un serveur ou un autre système de sécurité pouvant se connecter.
Envoi de messages Syslog à un serveur distant
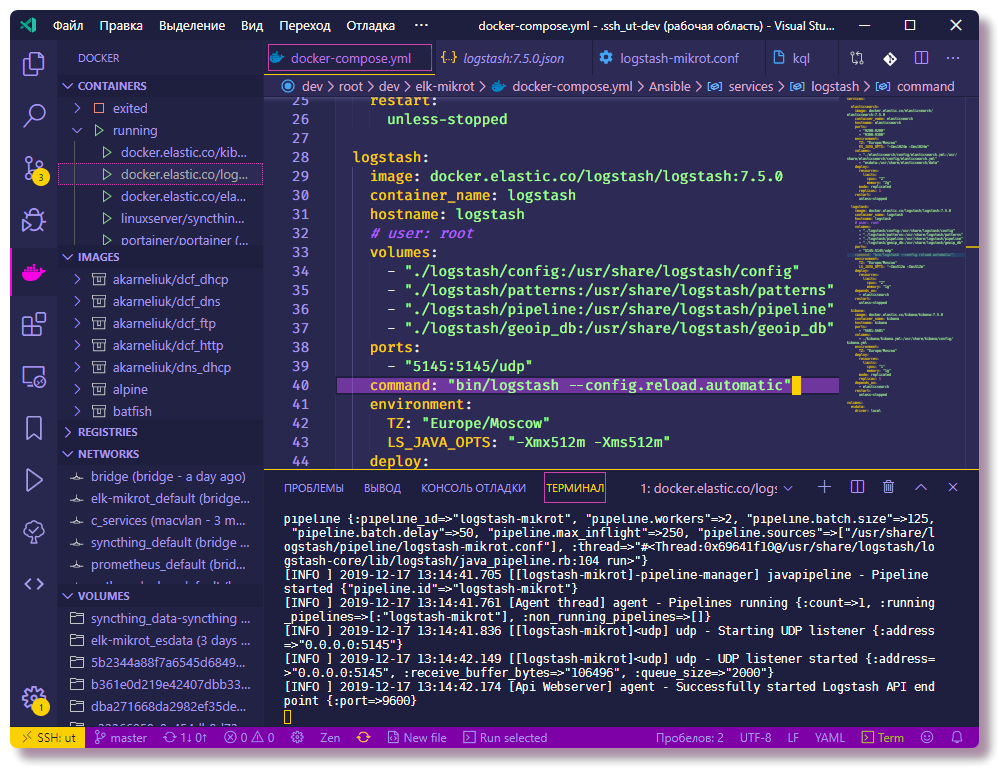
Dans Mikrotik, pour configurer la journalisation sur un serveur distant via la CLI, entrez simplement quelques commandes:
/system logging action add remote=192.168.88.130 remote-port=5145 src-address=192.168.88.1 name=logstash target=remote /system logging add action=logstash topics=info
Configuration des règles de pare-feu avec journalisation
Nous ne sommes intéressés que par certaines données (nom d'hôte, adresse IP, nom d'utilisateur, URL, etc.), à partir desquelles vous pouvez obtenir une belle visualisation ou sélection. Dans le cas le plus simple, pour obtenir des informations sur les analyses de port et les tentatives d'accès, vous devez configurer le composant pare-feu pour consigner les déclencheurs de règles. Sur Mikrotik, j'ai mis en place les règles dans la table NAT, pas Filter, car à l'avenir je vais mettre des chanipots qui imiteront le travail des services, cela me permettra d'enquêter plus d'informations sur le comportement des botnets, mais c'est un scénario plus avancé et pas à cette époque.
Attention! Dans la configuration ci-dessous, le port TCP standard du service SSH (22) est bouclé dans le réseau local. Si vous utilisez SSH pour accéder au routeur de l'extérieur et que les paramètres disposent du port 22 (
impression du service ip dans la CLI et des
services ip> dans Winbox), vous devez réaffecter le port pour la gestion SSH, ou n'entrez pas la dernière règle dans le tableau.
En outre, selon le nom de l'interface WAN (si le pont WAN n'est pas utilisé), vous devez modifier le paramètre dans l'
interface en celui approprié.
/ip firewall nat add action=netmap chain=dstnat comment="HONEYPOT RDP" dst-port=3389 in-interface=bridge-wan log=yes log-prefix=honeypot_rdp protocol=tcp to-addresses=192.168.88.201 to-ports=3389 add action=netmap chain=dstnat comment="HONEYPOT ELASTIC" dst-port=9200 in-interface=bridge-wan log=yes log-prefix=honeypot_elastic protocol=tcp to-addresses=192.168.88.201 to-ports=9211 add action=netmap chain=dstnat comment=" HONEYPOT TELNET" dst-port=23 in-interface=bridge-wan log=yes log-prefix=honeypot_telnet protocol=tcp to-addresses=192.168.88.201 to-ports=2325 add action=netmap chain=dstnat comment="HONEYPOT DNS" dst-port=53 in-interface=bridge-wan log=yes log-prefix=honeypot_dns protocol=udp to-addresses=192.168.88.201 to-ports=9953 add action=netmap chain=dstnat comment="HONEYPOT FTP" dst-port=21 in-interface=bridge-wan log=yes log-prefix=honeypot_ftp protocol=tcp to-addresses=192.168.88.201 to-ports=9921 add action=netmap chain=dstnat comment="HONEYPOT SMTP" dst-port=25 in-interface=bridge-wan log=yes log-prefix=honeypot_smtp protocol=tcp to-addresses=192.168.88.201 to-ports=9925 add action=netmap chain=dstnat comment="HONEYPOT SMB" dst-port=445 in-interface=bridge-wan log=yes log-prefix=honeypot_smb protocol=tcp to-addresses=192.168.88.201 to-ports=9445 add action=netmap chain=dstnat comment="HONEYPOT MQTT" dst-port=1883 in-interface=bridge-wan log=yes log-prefix=honeypot_mqtt protocol=tcp to-addresses=192.168.88.201 to-ports=9883 add action=netmap chain=dstnat comment="HONEYPOT SIP" dst-port=5060 in-interface=bridge-wan log=yes log-prefix=honeypot_sip protocol=tcp to-addresses=192.168.88.201 to-ports=9060 add action=dst-nat chain=dstnat comment="HONEYPOT SSH" dst-port=22 in-interface=bridge-wan log=yes log-prefix=honeypot_ssh protocol=tcp to-addresses=192.168.88.201 to-ports=9922
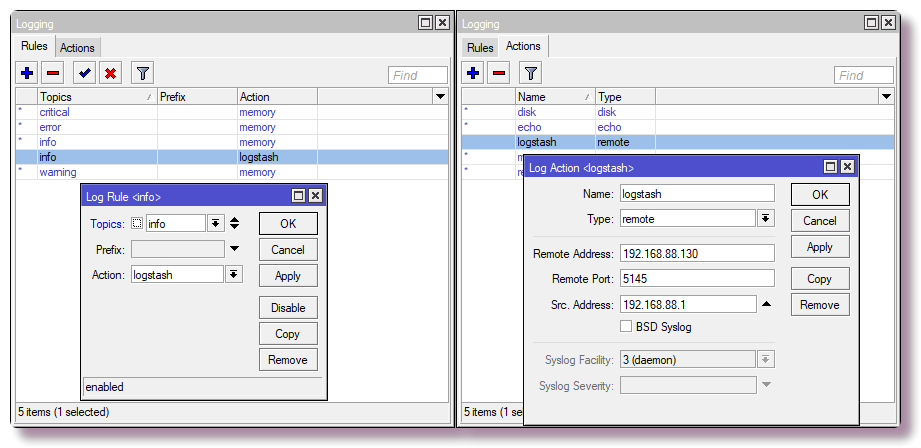
Dans Winbox, le même est configuré dans l'
onglet IP> Pare-feu> NAT .
Maintenant, le routeur redirige les paquets reçus vers l'adresse locale 192.168.88.201 et le port personnalisé. À l'heure actuelle, personne n'écoute sur ces ports, donc les connexions seront interrompues. À l'avenir, dans Docker, vous pouvez exécuter Honeypot, dont il existe de nombreux pour chaque service. Si cela n'est pas prévu, au lieu de règles NAT, vous devez écrire une règle avec l'action de suppression dans la chaîne de filtrage.
Démarrage d'ELK avec docker-compose
Ensuite, vous pouvez commencer à configurer le composant qui traitera les journaux. Je vous conseille de vous entraîner immédiatement et de cloner le référentiel pour voir complètement les fichiers de configuration. Toutes les configurations décrites peuvent être vues ici, dans le texte de l'article, je ne copierai qu'une partie des configurations.
❯❯ git clone https://github.com/mekhanme/elk-mikrot.git
Dans un environnement de test ou de développement, il est plus pratique d'exécuter des conteneurs Docker à l'aide de Docker-compose. Dans ce projet, j'utilise le fichier docker-compose de la dernière
version 3.7 pour le moment, il nécessite la version 18.06.0+ du moteur docker, donc cela vaut la peine de mettre à jour le
docker , ainsi que
docker-compose .
❯❯ curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose ❯❯ chmod +x /usr/local/bin/docker-compose
Étant donné que dans les versions récentes de docker-compose, le paramètre mem_limit a été
supprimé et
déployé a été ajouté, qui ne s'exécute qu'en mode
swarm (
docker stack deploy ), le lancement de la configuration
docker-compose up avec des limites entraîne une erreur. Comme je n'utilise pas swarm et que je veux avoir des limites de ressources, je dois le démarrer avec l'option
--compatibility , qui convertit les limites des nouvelles versions composées par docker en équivalent non-weld.
Test de tous les conteneurs (en arrière-plan -d):
❯❯ docker-compose --compatibility up -d
Vous devrez attendre que toutes les images soient téléchargées, et une fois le lancement terminé, vous pouvez vérifier l'état des conteneurs avec la commande:
❯❯ docker-compose --compatibility ps
En raison du fait que tous les conteneurs seront sur le même réseau (si vous ne spécifiez pas explicitement le réseau, un nouveau pont est créé, ce qui convient dans ce scénario) et docker-compose.yml contient le paramètre container_name pour tous les
conteneurs , les conteneurs auront déjà une connectivité via le DNS intégré docker. Par conséquent, il n'est pas nécessaire d'enregistrer les adresses IP dans les configurations de conteneurs. Dans la configuration Logstash, le sous-réseau 192.168.88.0/24 est enregistré comme local, plus loin dans la configuration, il y aura des explications plus détaillées, selon lesquelles vous pouvez dévier l'exemple de la configuration avant de commencer.
Configurer les services ELK
De plus, il y aura des explications sur la façon de configurer la fonctionnalité des composants ELK, ainsi que d'autres actions qui devront être effectuées sur Elasticsearch.
Pour déterminer les coordonnées géographiques par adresse IP, vous devrez télécharger la base de données
GeoLite2 gratuite de MaxMind:
❯❯ cd elk-mikrot && mkdir logstash/geoip_db ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-City-CSV.zip && unzip GeoLite2-City-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-City-CSV.zip ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-ASN-CSV.zip && unzip GeoLite2-ASN-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-ASN-CSV.zip
Configuration de Logstash
Le fichier de configuration principal est
logstash.yml , où j'ai enregistré l'option pour recharger automatiquement la configuration, les autres paramètres de l'environnement de test ne sont pas significatifs. La configuration du traitement des données (journaux) dans Logstash est décrite dans des fichiers de
configuration séparés, généralement stockés dans le répertoire du
pipeline . Dans le schéma, lorsque
plusieurs pipelines sont utilisés, le fichier
pipelines.yml décrit les
pipelines activés. Un pipeline est une chaîne d'actions sur des données non structurées afin de recevoir des données avec une structure spécifique en sortie. Un schéma avec
pipelines.yml configuré séparément est facultatif, vous pouvez vous en passer en téléchargeant toutes les configurations à partir du répertoire de
pipeline monté.Cependant, avec un fichier
pipelines.yml spécifique, la configuration est plus flexible, car vous pouvez activer et désactiver les fichiers de
configuration à partir du répertoire de
pipeline configs nécessaires. De plus, le rechargement des configurations ne fonctionne que dans le schéma de pipelines multiples.
❯❯ cat logstash/config/pipelines.yml - pipeline.id: logstash-mikrot path.config: "pipeline/logstash-mikrot.conf"
Vient ensuite la partie la plus importante de la configuration Logstash. La description du pipeline se compose de plusieurs sections - au début, les plugins sont indiqués dans la section
Input à l'aide de laquelle Logstash reçoit des données. Le moyen le plus simple de collecter syslog à partir d'un périphérique réseau est d'utiliser les plugins d'entrée
tcp /
udp . Le seul paramètre requis pour ces plugins est le
port , il doit être spécifié de la même manière que dans les paramètres du routeur.
La deuxième section est
Filtre , qui prescrit d'autres actions avec des données qui n'ont pas encore été structurées. Dans mon exemple, les messages syslog inutiles d'un routeur avec un certain texte sont supprimés. Cela se fait à l'aide de la condition et de l'action de
suppression standard, qui supprime l'intégralité du message si la condition est remplie. Dans la
condition , le champ de
message est vérifié pour la présence de certains textes.
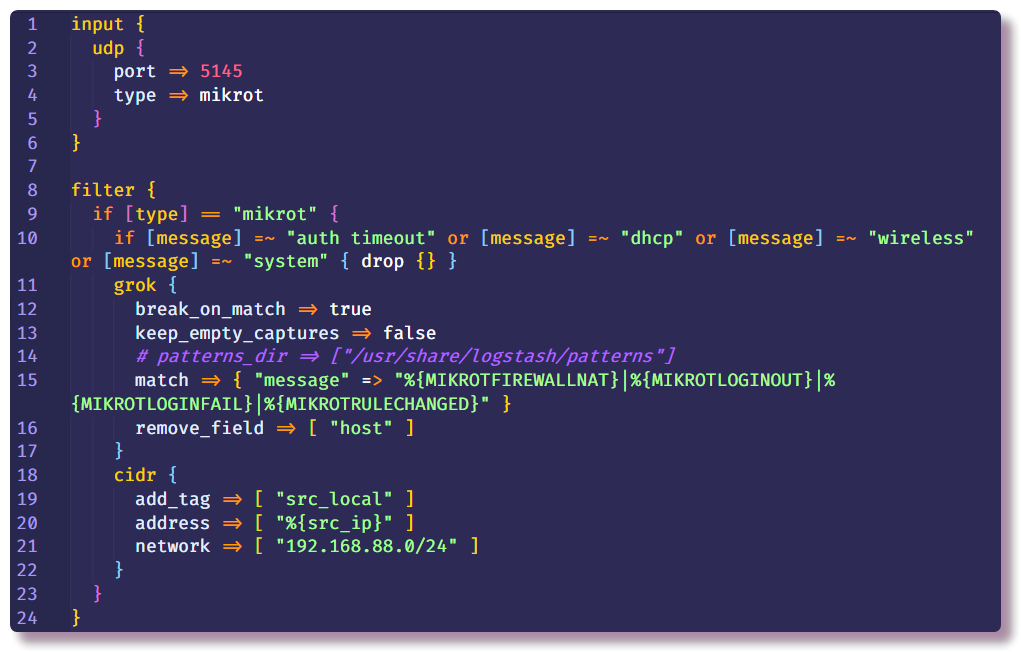
Si le message ne tombe pas, il descend plus bas dans la chaîne et entre dans le filtre
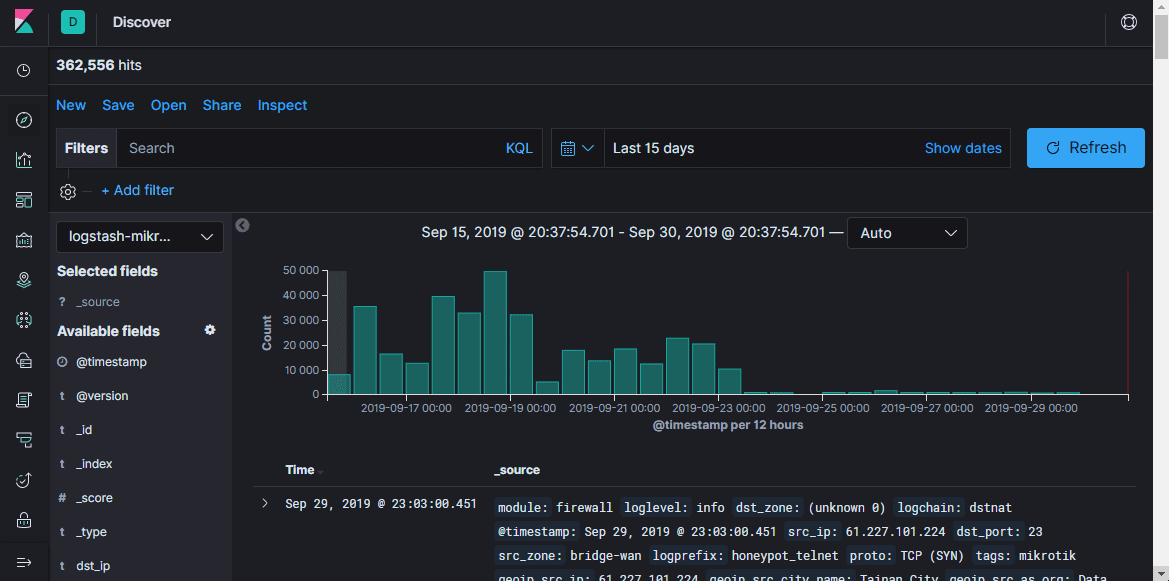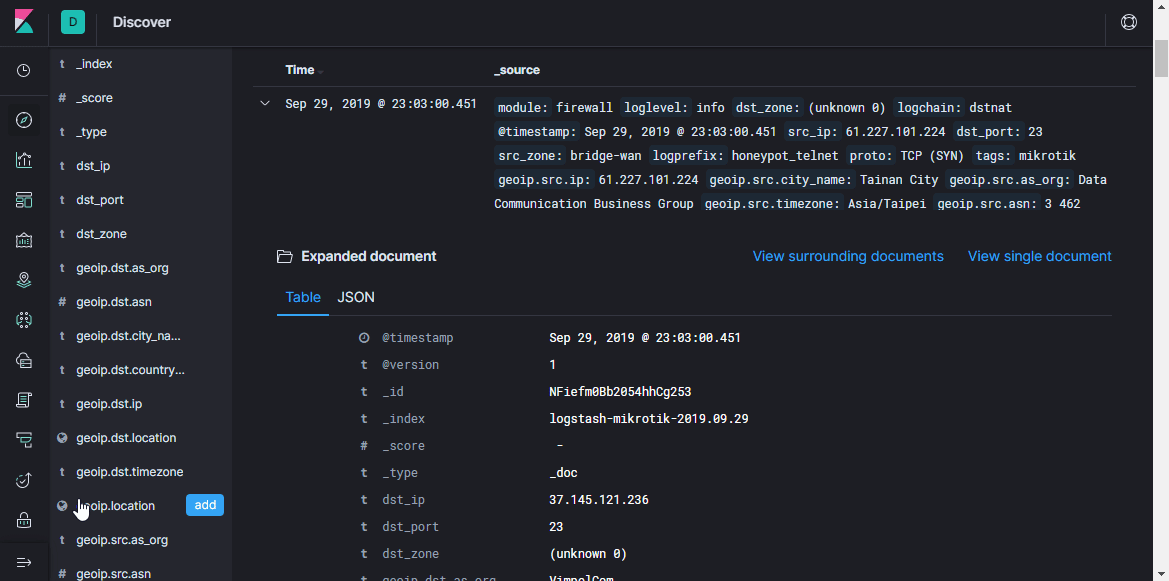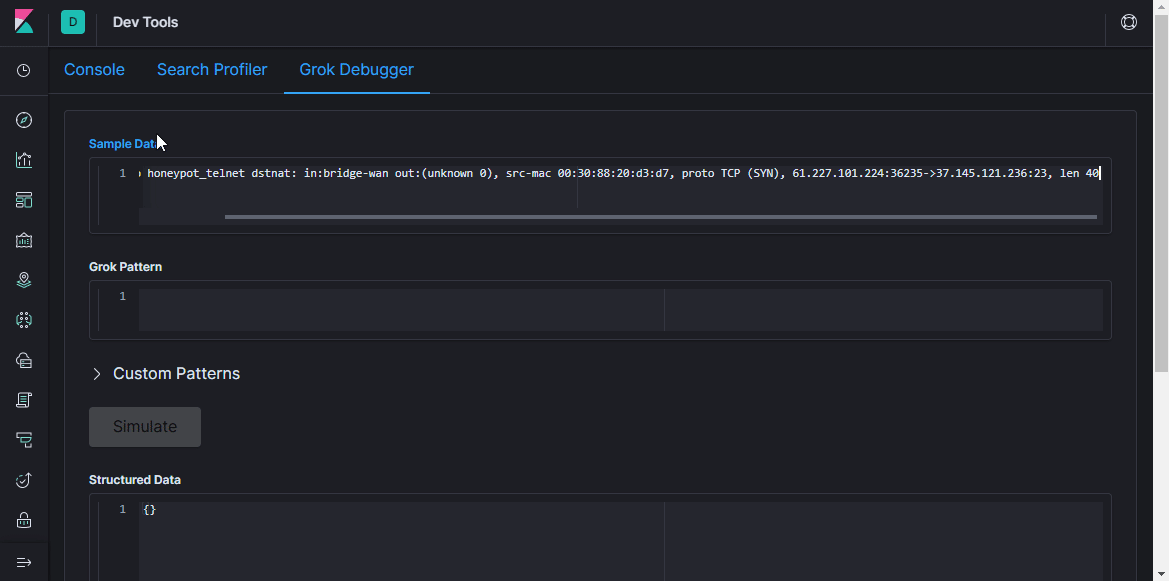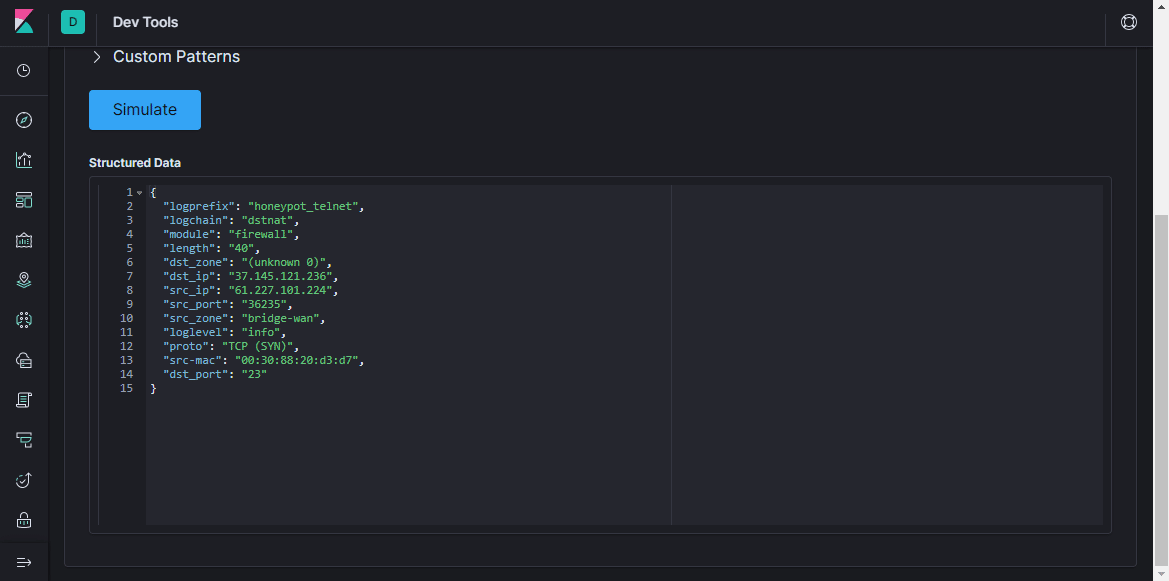
grok . Comme le dit la documentation,
grok est un excellent moyen d'analyser les données de journal non structurées en quelque chose de structuré et interrogeable . Ce filtre est utilisé pour traiter les journaux de différents systèmes (linux syslog, serveur Web, base de données, périphériques réseau, etc.). Sur la
base de modèles prêts à l'
emploi, vous pouvez, sans passer beaucoup de temps, créer un analyseur pour une séquence plus ou moins répétitive. Il est pratique d'utiliser un
analyseur en ligne pour la validation (dans la dernière version de Kibana, des fonctionnalités similaires se trouvent dans la section
Dev Tools ).
Le volume
"./logstash/patterns:/usr/share/logstash/patterns" est enregistré dans
docker-compose.yml , dans le répertoire
patterns il y a un fichier avec des modèles de communauté standard (juste pour plus de commodité, voir si j'ai oublié), ainsi qu'un fichier avec modèles de plusieurs types de messages Mikrotik (modules
Firewall et
Auth) , par analogie, vous pouvez ajouter vos propres modèles pour les messages d'une structure différente.
Les options standard
add_field et
remove_field vous permettent d'ajouter ou de supprimer des champs du message en cours de traitement dans n'importe quel filtre. Dans ce cas, le champ
hôte est supprimé, qui contient le nom d'hôte à partir duquel le message a été reçu. Dans mon exemple, il n'y a qu'un seul hôte, il n'y a donc aucun intérêt dans ce domaine.
De plus, dans la même section
Filtre , j'ai enregistré le filtre
cidr , qui vérifie le champ avec l'adresse IP pour la conformité avec la condition d'entrée dans le sous-réseau donné et place la balise. Sur la base de la balise de la chaîne suivante, des actions seront exécutées ou non (si cela est spécifique, afin de ne pas faire de recherche de geoip pour les adresses locales à l'avenir).
Il peut y avoir un certain nombre de sections de
filtre , de sorte qu'il y ait moins de conditions dans une section, dans la nouvelle section j'ai défini des actions pour les messages sans la balise
src_local , c'est-à-dire que les événements de pare-feu sont traités ici dans lesquels nous sommes intéressés par l'adresse source.
Maintenant, nous devons parler un peu plus d'où Logstash obtient les informations GeoIP. Logstash prend en charge les bases de données GeoLite2. Il existe plusieurs options de base de données, j'utilise deux bases de données: GeoLite2 City (qui contient des informations sur le pays, la ville, le fuseau horaire) et GeoLite2 ASN (informations sur le système autonome auquel appartient l'adresse IP).

Le plugin
geoip est également impliqué dans l'ajout d'informations GeoIP au message. À partir des paramètres, vous devez spécifier le champ qui contient l'adresse IP, la base utilisée et le nom du nouveau champ dans lequel les informations seront écrites. Dans mon exemple, la même chose se fait pour l'adresse IP de destination, mais jusqu'à présent dans ce scénario simple, ces informations ne seront pas intéressantes, car l'adresse de destination sera toujours l'adresse du routeur. Cependant, à l'avenir, il sera possible d'ajouter des journaux à ce pipeline non seulement à partir du pare-feu, mais également à partir d'autres systèmes où il sera pertinent d'examiner les deux adresses.
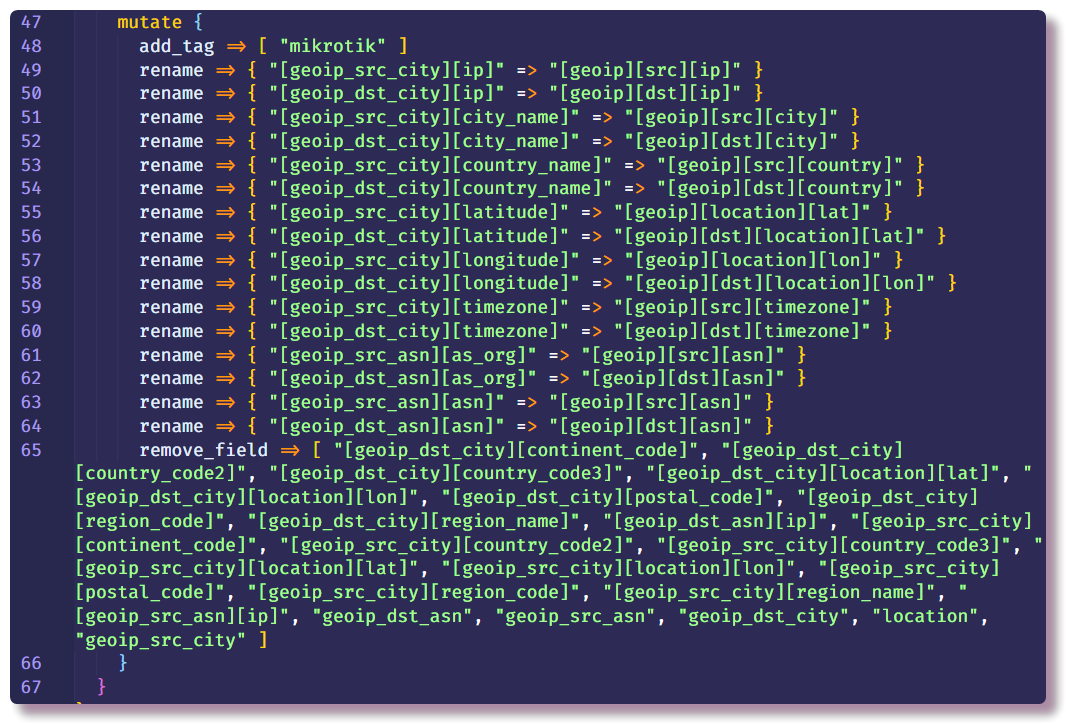
Le filtre
mutate vous permet de changer les champs de message et de modifier le texte dans les champs lui-même; la documentation décrit en détail de nombreux exemples de ce que vous pouvez faire. Dans ce cas, il est utilisé pour ajouter une balise, renommer des champs (pour une visualisation plus approfondie des journaux dans Kibana, un certain format de l'objet
géo-point est requis, je reviendrai sur ce sujet) et supprimer les champs inutiles.
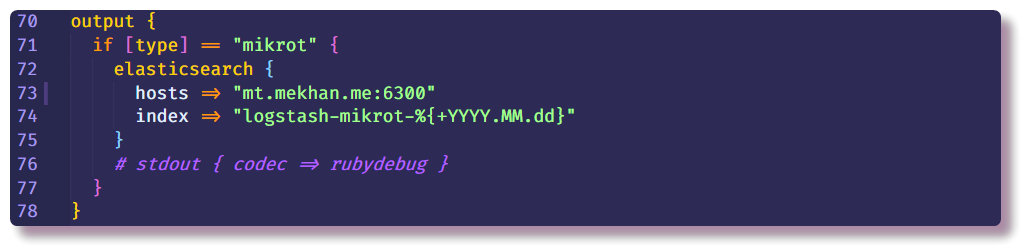
Cela met fin à la section de traitement des données et ne peut qu'indiquer où envoyer un message structuré. Dans ce cas, Elasticsearch collectera des données, il vous suffit de saisir l'adresse IP, le port et le nom d'index. Il est recommandé de saisir l'index avec un champ de date variable afin qu'un nouvel index soit créé chaque jour.
Configuration d'Elasticsearch
Retour à Elasticsearch. Vous devez d'abord vous assurer que le serveur est opérationnel. Elastic est le plus efficacement interagi avec l'API Rest dans la CLI. En utilisant curl, vous pouvez voir l'état du nœud (remplacez localhost par l'adresse IP du docker hôte):
❯❯ curl localhost:9200
Ensuite, vous pouvez essayer d'ouvrir Kibana à
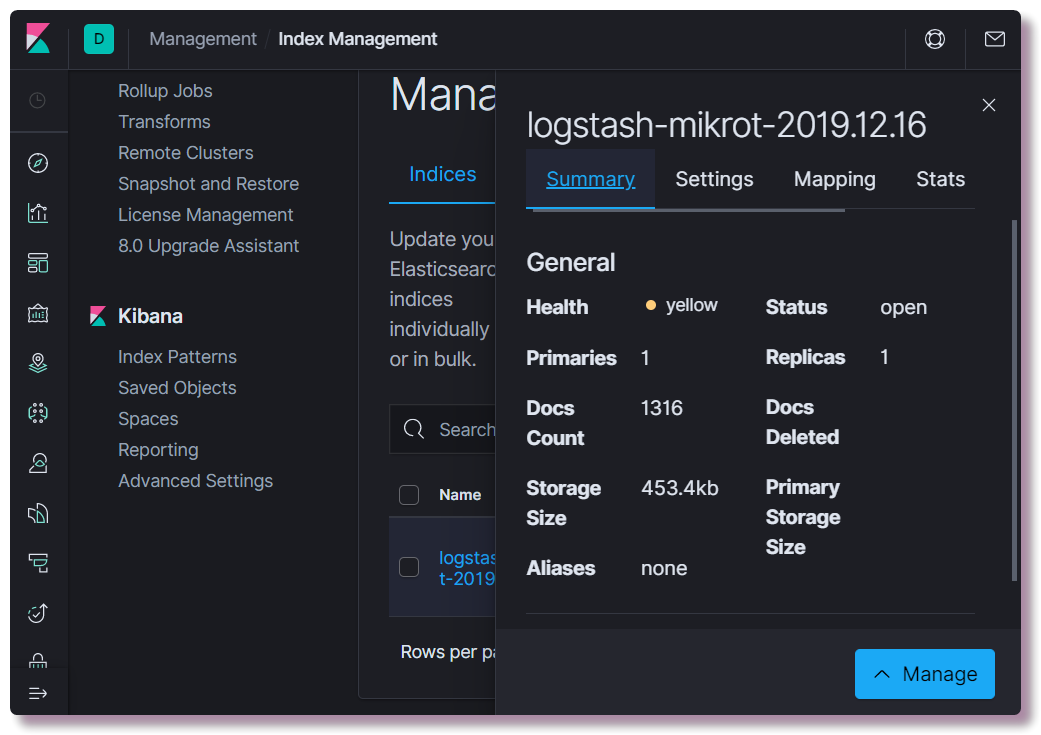
localhost : 5601. Il n'est pas nécessaire de configurer quoi que ce soit dans l'interface Web de Kibana (à moins de changer le thème en sombre). Nous souhaitons savoir si un index a été créé. Pour ce faire, ouvrez la section
Gestion et sélectionnez
Elasticsearch Index Management en haut à gauche. Ici, vous pouvez voir combien de documents sont indexés, combien cela prend d'espace disque, vous pouvez également consulter des informations sur le mappage d'index à partir d'informations utiles.
À ce moment, vous devez enregistrer le modèle de mappage correct. Ces informations sont nécessaires pour Elastic afin qu'il comprenne à quels types de données quels champs appartiennent. Par exemple, pour effectuer des sélections spéciales en fonction des adresses IP, pour le champ
src_ip ,
vous devez spécifier explicitement le type de données
ip et pour déterminer l'emplacement géographique, vous devez définir le champ
geoip.location dans un format spécifique et enregistrer le type
geo_point . Tous les champs possibles n'ont pas besoin d'être décrits, car pour les nouveaux champs, le type de données est déterminé automatiquement en fonction de modèles dynamiques (
long pour les nombres et
mot -
clé pour les chaînes).
Vous pouvez écrire un nouveau modèle soit en utilisant curl, soit directement depuis la console Kibana (section
Dev Tools ).
❯❯ curl -X POST -H "Content-Type: application/json" -d @elasticsearch/logstash_mikrot-template.json http://192.168.88.130:9200/_template/logstash-mikrot
Après avoir modifié le mappage, vous devez supprimer l'index:
❯❯ curl -X DELETE http://192.168.88.130:9200/logstash-mikrot-2019.12.16
Lorsqu'au moins un message arrive dans l'index, vérifiez le mappage:
❯❯ curl http://192.168.88.130:9200/logstash-mikrot-2019.12.16/_mapping
Pour une utilisation ultérieure des données dans Kibana, vous devez créer un
modèle dans
Gestion> Modèle d'index Kibana . Saisissez le
nom de l'
index avec le symbole * (
logstash-mikrot *) pour que tous les indices correspondent, sélectionnez le champ d'
horodatage comme champ avec la date et l'heure. Dans le champ
ID de modèle d'index personnalisé , vous pouvez entrer l'ID de modèle (par exemple,
logstash-mikrot ), à l'avenir, cela peut simplifier l'accès à l'objet.
Analyse et visualisation des données dans Kibana
Une fois que vous avez créé le
modèle d'index , vous pouvez passer à la partie la plus intéressante - l'analyse et la visualisation des données. Kibana a beaucoup de fonctionnalités et de sections, mais jusqu'à présent, nous ne serons intéressés que par deux.
Découvrir
Ici, vous pouvez afficher des documents dans des index, filtrer, rechercher et afficher les informations reçues. Il est important de ne pas oublier la chronologie, qui définit le délai dans les conditions de recherche.
Visualisez
Dans cette section, vous pouvez créer une visualisation basée sur les données collectées. Le plus simple est d'afficher les sources de balayage des réseaux de zombies sur une carte géographique, soit en pointillés, soit sous forme de carte thermique. Il existe également de nombreuses façons de créer des graphiques, d'effectuer des sélections, etc.
À l'avenir, je prévois de parler plus en détail du traitement des données, éventuellement de la visualisation, peut-être d'autre chose d'intéressant. En cours d'étude, je vais essayer de compléter le tutoriel.
Dépannage
Si l'index n'apparaît pas dans Elasticsearch, vous devez d'abord consulter les journaux Logstash:
❯❯ docker logs logstash --tail 100 -f
Logstash ne fonctionnera pas s'il n'y a pas de connectivité avec Elasticsearch, ou une erreur dans la configuration du pipeline est la principale raison et cela devient clair après une étude minutieuse des journaux écrits par défaut dans json docker.
S'il n'y a aucune erreur dans le journal, vous devez vous assurer que Logstash intercepte les messages sur son socket configuré. À des fins de débogage, vous pouvez utiliser
stdout en
sortie :
stdout { codec => rubydebug }
Après cela, Logstash écrira des informations de débogage lorsque le message sera reçu directement dans le journal.
La vérification d'Elasticsearch est très simple - il suffit de faire une boucle de demande GET sur l'adresse IP et le port du serveur, ou sur un point de terminaison API spécifique. Par exemple, regardez l'état des index dans une table lisible par l'homme:
❯❯ curl -s 'http://192.168.88.130:9200/_cat/indices?v'
Kibana ne démarre pas non plus s'il n'y a pas de connexion à Elasticsearch, il est facile de voir cela dans les journaux.
Si l'interface Web ne s'ouvre pas, vous devez vous assurer que le pare-feu est correctement configuré ou désactivé sous Linux (dans Centos, il y avait des problèmes avec
iptables et
docker , ils ont été résolus sur les conseils de la
rubrique ). Il convient également de considérer que sur des équipements peu productifs, tous les composants peuvent se charger pendant plusieurs minutes. Avec un manque de mémoire, les services peuvent ne pas se charger du tout. Afficher l'utilisation des ressources de conteneur:
❯❯ docker stats
Si soudainement quelqu'un ne sait pas comment modifier correctement la configuration des conteneurs dans le
fichier docker-compose.yml et redémarrer les conteneurs, cela se fait en modifiant
docker-compose.yml et en utilisant la même commande avec les mêmes paramètres, redémarre:
❯❯ docker-compose --compatibility up -d
Dans le même temps, dans les sections modifiées, les anciens objets (conteneurs, réseaux, volumes) sont effacés et de nouveaux sont recréés selon la configuration. Les données des services ne sont pas perdues en même temps, car des
volumes nommés sont utilisés , qui ne sont pas supprimés avec le conteneur, et les configurations sont montées à partir du système hôte, Logstash peut même surveiller les fichiers de configuration et redémarrer la configuration du pipeline lorsque le fichier est modifié.
Vous pouvez redémarrer le service séparément avec la
commande docker restart (il n'est pas nécessaire d'être dans le répertoire avec
docker-compose.yml) :
❯❯ docker restart logstash
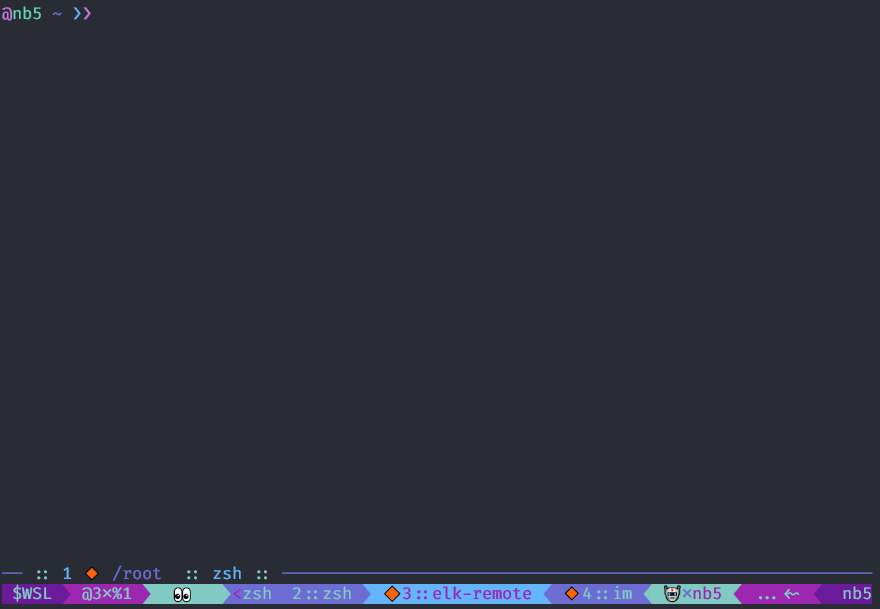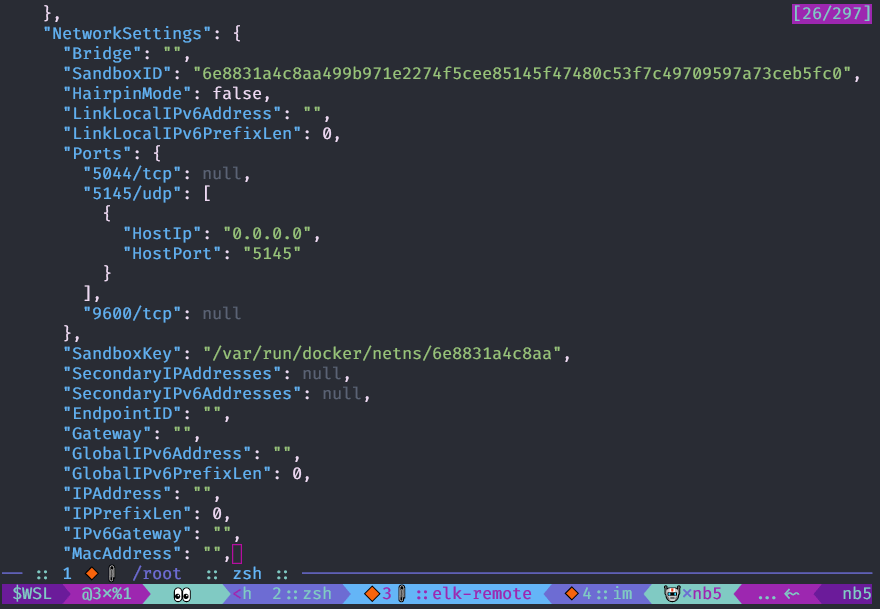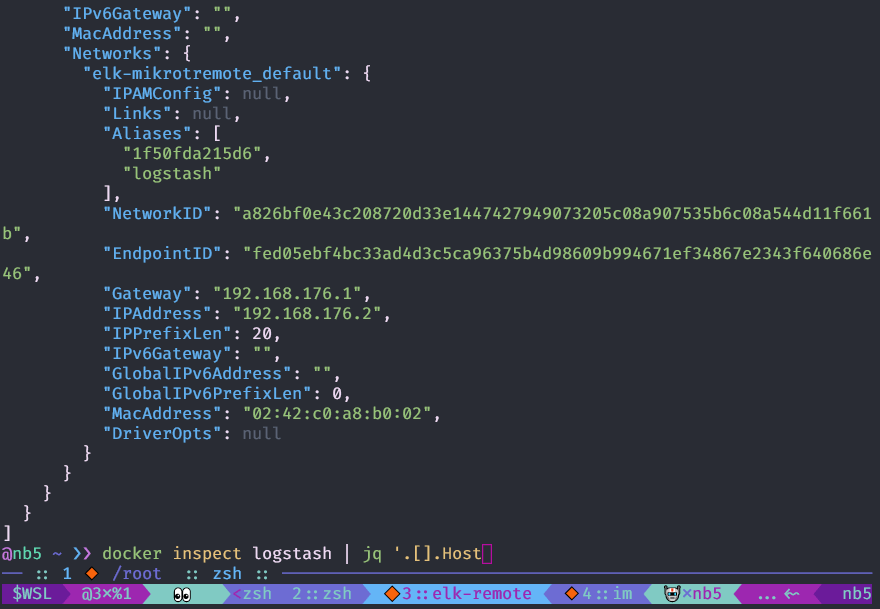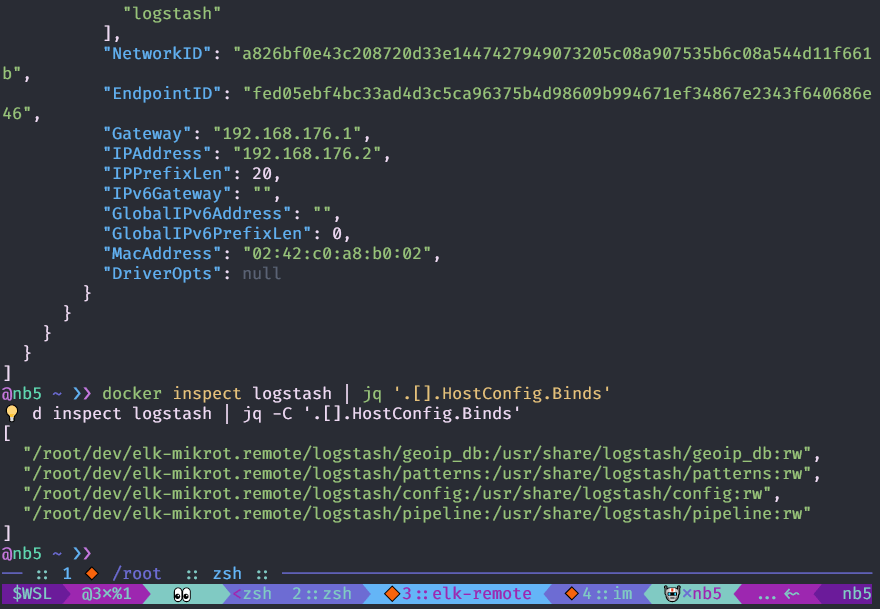
Vous pouvez voir la configuration de l'objet
docker avec la
commande docker inspect , il est plus pratique de l'utiliser avec
jq .
Conclusion
Je tiens à noter que la sécurité de ce projet n'a pas été signalée car il s'agit d'un environnement de test (dev) et il n'est pas prévu de le sortir en dehors du routeur. Si vous le déployez pour une utilisation plus sérieuse, vous devez suivre les meilleures pratiques, installer des certificats pour HTTPS, effectuer des sauvegardes, une surveillance normale (qui ne démarre pas à côté du système principal). Soit dit en passant, Traefik s'exécute dans mon docker sur mon serveur, qui est un proxy inverse pour certains services, et met également fin à TLS sur lui-même et effectue l'authentification. Autrement dit, grâce au DNS configuré et au proxy inverse, il devient possible d'accéder à l'interface Web de Kibana à partir d'Internet avec HTTPS non configuré et un mot de passe (si je comprends bien, dans la version communautaire, Kibana ne prend pas en charge la protection par mot de passe pour l'interface Web). Je prévois de décrire plus en détail mon expérience dans la configuration de Traefik pour une utilisation sur un réseau domestique avec Docker.