Salut, Habrovsk. Aujourd'hui, les cours commenceront dans le premier groupe du cours PostgreSQL . À cet égard, nous voulons vous expliquer comment s'est déroulé le webinaire ouvert pour ce cours.
Dans la
prochaine leçon ouverte, nous avons parlé des défis auxquels les bases de données SQL étaient confrontées à l'ère des nuages et de Kubernetes. Et en même temps, nous avons examiné comment les bases de données SQL s'adaptent et muent sous l'influence de ces appels.
Le webinaire a été organisé par
Valery Bezrukov , Google Cloud Practice Delivery Manager chez EPAM Systems.
Quand les arbres étaient petits ...
Pour commencer, rappelons comment le choix d'un SGBD a commencé à la fin du siècle dernier. Cependant, cela ne sera pas difficile, car le choix d'un SGBD à cette époque a commencé et s'est terminé avec
Oracle .

À la fin des années 90 - au début des années 2000, en fait, il n'y avait pas de choix spécial, si nous parlons de bases de données évolutives industrielles. Oui, il y avait IBM DB2, Sybase et certaines autres bases de données qui sont apparues et ont disparu, mais en général, elles n'étaient pas si visibles contre Oracle. En conséquence, les compétences des ingénieurs de l'époque étaient en quelque sorte liées au seul choix qui existait.
Oracle DBA devrait pouvoir:
- Installer Oracle Server à partir de la distribution
- configurer Oracle Server:
- créer:
- espaces table
- Schémas
- les utilisateurs
- sauvegarder et restaurer;
- effectuer un suivi;
- traiter les demandes sous-optimales.
Dans le même temps, Oracle DBA n'était pas particulièrement requis:
- pouvoir choisir le SGBD optimal ou une autre technologie de stockage et de traitement des données;
- fournir une haute disponibilité et une évolutivité horizontale (ce n'était pas toujours un problème de DBA);
- Bonne connaissance du domaine, de l'infrastructure, de l'architecture appliquée, du système d'exploitation;
- effectuer le chargement et le déchargement des données, la migration des données entre différents SGBD.
En général, si nous parlons du choix à cette époque, cela ressemble à un choix dans un magasin soviétique à la fin des années 80:

Notre temps
Depuis lors, bien sûr, les arbres ont grandi, le monde a changé et il est devenu en quelque sorte comme ceci:

Le marché du SGBD a également changé, comme le montre clairement le dernier rapport Gartner:

Et ici, il convient de noter que les nuages occupaient leur niche, dont la popularité augmente. Si vous lisez le même rapport Gartner, nous verrons les conclusions suivantes:
- De nombreux clients sont sur le point de migrer leurs applications vers le cloud.
- Les nouvelles technologies apparaissent d'abord dans le cloud et non le fait qu'elles passeront jamais à une infrastructure sans cloud.
- Le modèle de tarification par répartition est devenu familier. Tout le monde ne veut payer que pour ce qu'il utilise, et ce n'est même pas une tendance, mais simplement un constat.
Et maintenant
Aujourd'hui, nous sommes tous dans le cloud. Et ces questions que nous avons sont des questions de choix. Et c'est énorme, même si nous ne parlons que du choix des technologies de SGBD au format local. Nous avons également géré des services et du SaaS. Ainsi, le choix se complique chaque année.
Outre les questions de choix,
des facteurs restrictifs s'appliquent également:
- le prix . De nombreuses technologies coûtent encore de l'argent;
- compétences . Si nous parlons de logiciels libres, la question des compétences se pose, car les logiciels libres nécessitent des personnes qui les déploient et les exploitent avec des compétences suffisantes;
- fonctionnel . Tous les services disponibles dans le cloud et construits, par exemple, même sur la base des mêmes Postgres, n'ont pas les mêmes fonctionnalités que Postgres On-premises. C'est un facteur essentiel que vous devez connaître et comprendre. De plus, ce facteur devient plus important que la connaissance de certaines fonctionnalités cachées d'un seul SGBD.
Qu'attendent de DA / DE:- une bonne compréhension du domaine et de l'architecture appliquée;
- la possibilité de choisir la bonne technologie de SGBD, en tenant compte de la tâche;
- la capacité de sélectionner la méthode optimale pour mettre en œuvre la technologie sélectionnée dans le contexte des limitations existantes;
- capacité d'effectuer la migration et la migration des données;
- la capacité de mettre en œuvre et d'exploiter les solutions sélectionnées.
L'exemple suivant
basé sur GCP montre comment le choix d'une technologie particulière pour travailler avec des données est organisé en fonction de sa structure:

Notez que PostgreSQL manque dans le schéma, et tout cela parce qu'il se cache sous la terminologie de
Cloud SQL . Et lorsque nous entrons dans Cloud SQL, nous devons refaire un choix:

Il convient de noter que ce choix n'est pas toujours clair, donc les développeurs d'applications sont souvent guidés par l'intuition.
Total:- Plus loin, plus la question du choix est pertinente. Et même si vous ne regardez que GCP, les services gérés et SaaS, une mention du SGBDR n'apparaît qu'à la 4ème étape (et il y a Spanner à proximité). De plus, le choix de PostgreSQL apparaît en général à la 5ème étape, et à côté il y a aussi MySQL et SQL Server, c'est-à-dire qu'il y en a beaucoup, mais vous devez choisir .
- Il ne faut pas oublier les restrictions sur fond de tentations. La plupart du temps, tout le monde veut une clé, mais c'est cher. En conséquence, une requête typique ressemble à ceci: "Veuillez faire Spanner pour nous, mais pour le prix de Cloud SQL, eh bien, vous êtes des professionnels!"

Que faire?
Sans prétendre être la vérité ultime, disons ce qui suit:
Besoin de changer l'approche de l'apprentissage:- apprendre, comme enseigné avant DBA, cela n'a aucun sens;
- la connaissance d'un produit ne suffit plus;
- mais en connaître des dizaines au niveau d'un est impossible.
Vous devez savoir non seulement et pas combien le produit, mais:
- cas d'utilisation de son application;
- différentes méthodes de déploiement;
- avantages et inconvénients de chaque méthode;
- des produits similaires et alternatifs pour faire des choix éclairés et optimaux et pas toujours en faveur d'un produit familier.
Vous devez également pouvoir migrer les données et comprendre les principes de base de l'intégration avec ETL.
Cas réel
Dans un passé récent, vous deviez créer un backend pour une application mobile. Au moment où il a commencé à travailler dessus, le backend avait déjà été développé et était prêt pour la mise en œuvre, et l'équipe de développement a passé environ deux ans sur ce projet. Les tâches suivantes ont été définies:
- construire CI / CD;
- revoir l'architecture;
- mettre tout en service.
L'application elle-même était un microservice et le code Python / Django a été développé à partir de zéro et immédiatement dans GCP. En ce qui concerne le public cible, il a été supposé qu'il y aurait deux régions - États-Unis et UE, et le trafic était distribué via l'équilibreur de charge mondial. Toutes les charges de travail et les charges de travail de calcul ont fonctionné dans le moteur Google Kubernetes.
Quant aux données, il y avait 3 structures:
- Stockage dans le cloud
- Datastore;
- Cloud SQL (PostgreSQL).
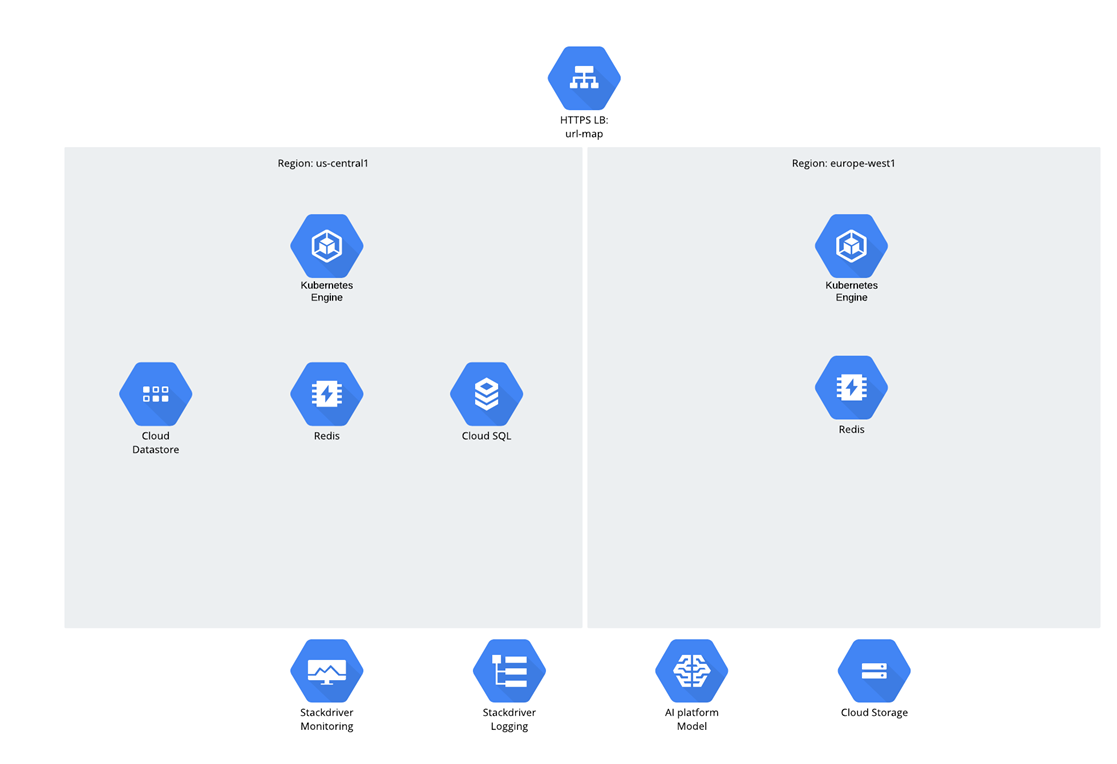
Vous vous demandez peut-être pourquoi Cloud SQL a été sélectionné? Pour dire la vérité, une telle question au cours des dernières années a provoqué une pause gênante - on a le sentiment que les gens ont commencé à être timides des bases de données relationnelles, mais néanmoins ils continuent de les utiliser activement ;-).
Pour notre cas, Cloud SQL a été choisi pour les raisons suivantes:
- Comme mentionné, l'application a été développée à l'aide de Django, et elle dispose d'un modèle pour mapper les données persistantes d'une base de données SQL aux objets Python (Django ORM).
- Le framework lui-même supportait une liste assez finie de SGBD:
- PostgreSQL
- MariaDB;
- MySQL
- Oracle
- SQLite
En conséquence, PostgreSQL a été choisi intuitivement dans cette liste (enfin, ce n'est pas Oracle, en fait).
Ce qui manquait:- l'application n'a été déployée que dans 2 régions, et des plans sont apparus 3e (Asie);
- La base de données se trouvait dans la région nord-américaine (Iowa);
- de la part du client, il y avait des inquiétudes concernant d'éventuels retards d'accès depuis l'Europe et l'Asie et des interruptions de service en cas de panne du SGBD.
Malgré le fait que Django lui-même puisse travailler avec plusieurs bases de données en parallèle et les diviser par lecture et écriture, il n'y avait pas tellement d'enregistrements dans l'application (plus de 90% - lecture). Et en général, et en général, si vous pouviez faire une
réplique en lecture de la base principale en Europe et en Asie , ce serait une solution de compromis. Eh bien, qu'est-ce qui est si compliqué?
Et la difficulté était que le client ne voulait pas refuser d'utiliser les services managés et Cloud SQL. Et les possibilités de Cloud SQL sont actuellement limitées. Cloud SQL prend en charge la haute disponibilité (HA) et le réplica en lecture (RR), mais le même RR est pris en charge dans une seule région. Après avoir créé une base de données dans la région américaine, il est impossible de faire une réplique en lecture dans la région européenne à l'aide de Cloud SQL, bien que postgres lui-même n'interfère pas. La correspondance avec les employés de Google n'a abouti à rien et s'est terminée par des promesses dans le style "nous connaissons le problème et y travaillons, un jour le problème sera résolu".
Si vous répertoriez les possibilités de thèse de Cloud SQL, cela ressemblera à ceci:
1. Haute disponibilité (HA):- au sein d'une même région;
- via la réplication de disque
- Les mécanismes PostgreSQL ne sont pas utilisés;
- contrôle automatique et manuel possible - basculement / rétablissement;
- lors de la commutation, le SGBD n'est pas disponible pendant plusieurs minutes.
2. Lisez la réplique (RR):- au sein d'une même région;
- veille à chaud;
- Réplication de streaming PostgreSQL.
De plus, comme d'habitude, lors du choix d'une technologie, vous rencontrez toujours certaines
limitations :
- le client ne voulait pas produire d'entités et utiliser l'IaaS, sauf via GKE;
- le client ne voudrait pas déployer PostgreSQL / MySQL en libre service;
- eh bien, en général, Google Spanner serait tout à fait approprié si ce n'était pas pour son prix, cependant, Django ORM ne peut pas fonctionner avec, et donc la chose est bonne.
Compte tenu de la situation, le client a reçu une question de renvoi:
"Pouvez-vous faire quelque chose de similaire pour le faire comme Google Spanner, mais cela fonctionne également avec Django ORM?"Option n ° 0
La première chose qui m'est venue à l'esprit:
- Restez dans CloudSQL
- il n'y aura aucune réplication intégrée entre les régions sous quelque forme que ce soit;
- essayez de visser la réplique au Cloud SQL existant par PostgreSQL;
- quelque part et en quelque sorte démarrer l'instance PostgreSQL, mais au moins master ne touche pas.
Hélas, il s'est avéré que cela ne peut pas être fait, car il n'y a pas d'accès à l'hôte (il est dans un autre projet) - pg_hba et ainsi de suite, et il n'y a toujours pas d'accès sous superutilisateur.
Option n ° 1
Après une réflexion plus approfondie et compte tenu des circonstances précédentes, le courant de pensée a quelque peu changé:
- nous essayons toujours de rester dans le champ d'application de CloudSQL, mais nous passons à MySQL, car Cloud SQL by MySQL a un maître externe, qui:
- est un proxy pour MySQL externe;
- ressemble à une instance MySQL;
- inventé pour la migration de données à partir d'autres nuages ou sur site.
Étant donné que la configuration de la réplication MySQL ne nécessite pas d'accès à l'hôte, tout a fonctionné, mais c'est très instable et peu pratique. Et quand nous sommes allés plus loin, cela est devenu complètement effrayant, car nous avons déployé toute la structure avec terraform, et soudain, il s'est avéré que le maître externe n'était pas pris en charge par terraform. Oui, Google a une CLI, mais pour une raison quelconque, tout fonctionnait de temps en temps - il est créé, il n'est pas créé. Peut-être parce que la CLI a été inventée pour la migration des données à l'extérieur, et non pour les répliques.
En fait, cela montre clairement que Cloud SQL ne correspond pas du tout au mot. Comme on dit, nous avons fait tout notre possible.
Option 2
Comme cela ne fonctionnait pas pour rester dans Cloud SQL, nous avons essayé de formuler des exigences pour une solution de compromis. Les exigences étaient les suivantes:
- travail dans Kubernetes, utilisation maximale des ressources et capacités de Kubernetes (DCS, ...) et GCP (LB, ...);
- le manque de ballast d'une pile de choses inutiles dans le cloud comme proxy HA;
- la possibilité d'exécuter HA PostgreSQL ou MySQL dans la région principale; dans les autres régions - HA du RR de la région principale plus sa copie (pour la fiabilité);
- multi master (ne voulait pas le contacter, mais ce n'était pas très important)
.
À la suite de ces exigences, à l'horizon sont finalement apparues
des options et des liaisons de SGBD appropriées :
- MySQL Galera;
- CockroachDB;
- Outils PostgreSQL
:
- pgpool-II;
- Patroni.
MySQL Galera
La technologie MySQL Galera a été développée par Codership et est un plugin pour InnoDB. Caractéristiques:
- multi maître;
- réplication synchrone
- lecture à partir de n'importe quel nœud;
- enregistrer sur n'importe quel nœud;
- mécanisme HA intégré;
- Il y a un tableau Helm de Bitnami.
Cockroachdb
Selon la description, la chose est complètement explosive et est un projet open source écrit en Go. Le principal participant est Cockroach Labs (fondé par des immigrants de Google). Ce SGBD relationnel a été créé à l'origine pour être distribué (avec une mise à l'échelle horizontale prête à l'emploi) et tolérant aux pannes. Ses auteurs de l'entreprise ont souligné l'objectif de «combiner la richesse des fonctionnalités SQL avec la disponibilité horizontale familière aux solutions NoSQL».
Le bon bonus est la prise en charge du protocole de connexion postgres.
Pgpool
Il s'agit d'un module complémentaire pour PostgreSQL, en fait, une nouvelle entité qui prend en charge toutes les connexions et les traite. Il possède son propre équilibreur et analyseur de chargeur, sous licence BSD. Il offre de nombreuses opportunités, mais il semble quelque peu effrayant, car la présence d'une nouvelle entité pourrait devenir une source d'aventures supplémentaires.
Patroni
C'est la dernière chose sur laquelle l'œil est tombé et, en fin de compte, pas en vain. Patroni est un utilitaire open source, qui, en substance, est un démon Python qui vous permet de servir automatiquement les clusters PostgreSQL avec différents types de réplication et de changement de rôle automatique. La pièce s'est avérée très intéressante, car elle s'intègre bien avec le cuber et ne porte pas de nouvelles entités.
Ce qui a finalement choisi
Le choix n'a pas été facile:
- CockroachDB - feu, mais muet;
- MySQL Galera n'est pas mal non plus, il est beaucoup utilisé où, mais MySQL;
- Pgpool - beaucoup d'entités supplémentaires, intégration so-so avec le cloud et les K8;
- Patroni - excellente intégration avec K8, pas d'entités supplémentaires, s'intègre bien avec GCP LB.
Ainsi, le choix s'est porté sur Patroni.
Conclusions
Le moment est venu de résumer. Oui, le monde de l'infrastructure informatique a considérablement changé, et ce n'est que le début. Et si auparavant les nuages n'étaient qu'un autre type d'infrastructure, maintenant tout est différent. De plus, les innovations dans les nuages apparaissent constamment, elles apparaîtront et, peut-être, elles n'apparaîtront que dans les nuages, et alors seulement, grâce aux forces des startups, elles seront transférées sur site.
Quant à SQL, SQL vivra. Cela signifie que PostgreSQL et MySQL doivent être connus et que vous devez pouvoir travailler avec eux, mais plus important encore, pour pouvoir les appliquer correctement.