Plus le système est complexe, plus il grandit avec toutes sortes d'alertes. Et il faut répondre à ces alertes, les agréger et les visualiser. Je pense à une situation familière à beaucoup avant une tique nerveuse.
La décision qui sera discutée n'est pas la plus inattendue, mais la recherche ne produit pas un article complet sur ce sujet.
Par conséquent, j'ai décidé de partager l'expérience de FunCorp et de parler de la façon dont le processus de devoir est construit, qui appelle, pourquoi et comment vous pouvez regarder tout cela.

Qu'est-ce que PagerDuty?
Donc, pour résoudre tous ces problèmes, nous avons commencé à chercher un outil pratique. Après une courte recherche, nous avons opté pour PagerDuty. PD nous a semblé une solution assez complète et concise avec beaucoup d'intégrations et de paramètres. Comment est-elle?
En bref, PagerDuty est une plate-forme de traitement des incidents qui peut gérer les incidents entrants via diverses intégrations, ajuster l'ordre des tâches puis alerter l'ingénieur de service en fonction du niveau de l'incident (à haut niveau - appel, à faible - push depuis l'application / sms) .
Qui est la personne en service?
C'est probablement la première chose à commencer à configurer un PD.
FunCorp, comme d'autres sociétés, a un poste honorifique en service. Il est transmis d'ingénieur en ingénieur une fois par jour. Il existe ce qu'on appelle la première et la deuxième ligne de réponse aux alertes de PagerDuty. Supposons qu'une alerte de priorité élevée arrive, et si 10 minutes après l'appel à l'opératrice de la première ligne, il n'y a aucune réaction à son égard (c'est-à-dire qu'il n'est pas transféré à l'état d'acquittement ou de résolution), l'appel est dirigé vers le deuxième ingénieur de garde. Ceci est configuré dans PagerDuty lui-même via des stratégies d'escalade.
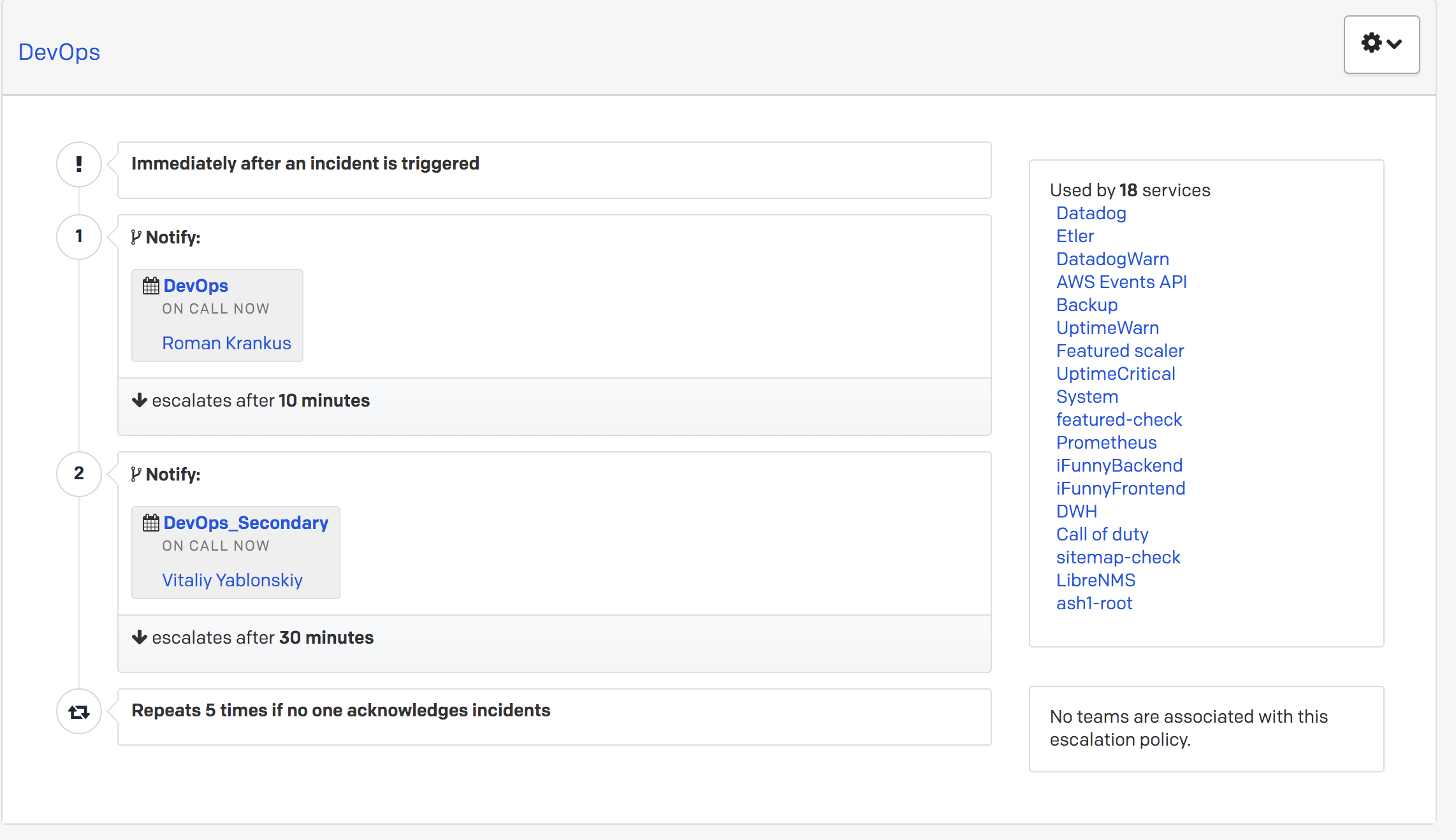
Si le deuxième standardiste ne répond pas, la notification revient au standardiste
principal .
Ainsi, aucune alerte entrante de haute priorité ne peut rester non traitée.
Voyons maintenant d'où peuvent provenir les incidents.
Quelles intégrations utilisons-nous?
Un grand nombre d'incidents divers provenant de divers services sont versés dans PD. Nous avons maintenant environ 25 de ces services, et pour leur traitement, nous utilisons des intégrations toutes faites.
Le principal système de collecte métrique est Prométhée. Beaucoup a été écrit à ce sujet dans Habré, je dirai simplement que nous en avons plusieurs pour des environnements différents: l'un collecte les métriques des machines virtuelles et des dockers, l'autre des services Amazon, le troisième des «machines à repasser». Telegraf est principalement utilisé comme exportateur de métriques.
Ici aussi, je pense que tout est clair d'après le nom. Cette intégration est utilisée pour envoyer des notifications à partir de certains scripts exécutés sur la couronne. PD vous donne une certaine adresse à laquelle vous envoyez des lettres. Lors de la création d'un service avec cette intégration, vous pouvez définir des priorités dans quel ordre les incidents entrants seront traités, comment créer une alerte (pour chaque lettre entrante, pour une lettre entrante + une certaine règle, etc.).

À mon avis, une intégration très intéressante. Il y a des moments où quelque chose se produit, mais n'est pas couvert par des incidents. Par conséquent, nous avons ajouté l'intégration de Slack pour créer l'incident. Autrement dit, dans Slack d'entreprise, vous pouvez écrire
/ callofduty tout ralentit et bientôt il se casse et PD traite cela et envoie l'incident à l'ingénieur de service.
Nous faisons:

On voit:

Intégration HTTP. Ici, en fait, il n'y a rien de particulièrement intéressant, juste une requête POST avec un corps au format JSON. Par exemple, d'un point intéressant: nous l'utilisons pour la surveillance externe en utilisant
https://www.statuscake.com/ . Ce service vérifie la disponibilité de nos sites du monde entier. Dans le cas où nous obtenons un code de réponse inacceptable (par exemple, 502), un incident est créé, puis tout suit la chaîne décrite ci-dessus. StatusCake lui-même a la capacité de surveiller les URL internes, l'expiration d'un certificat ou d'un domaine SSL.
Il s'agit d'un autre système de surveillance, plus d'informations à ce sujet peuvent être trouvées sur leur site Web
https://www.librenms.org/ . Avec son aide, nous surveillons les interfaces réseau et iDRAC à partir des serveurs.
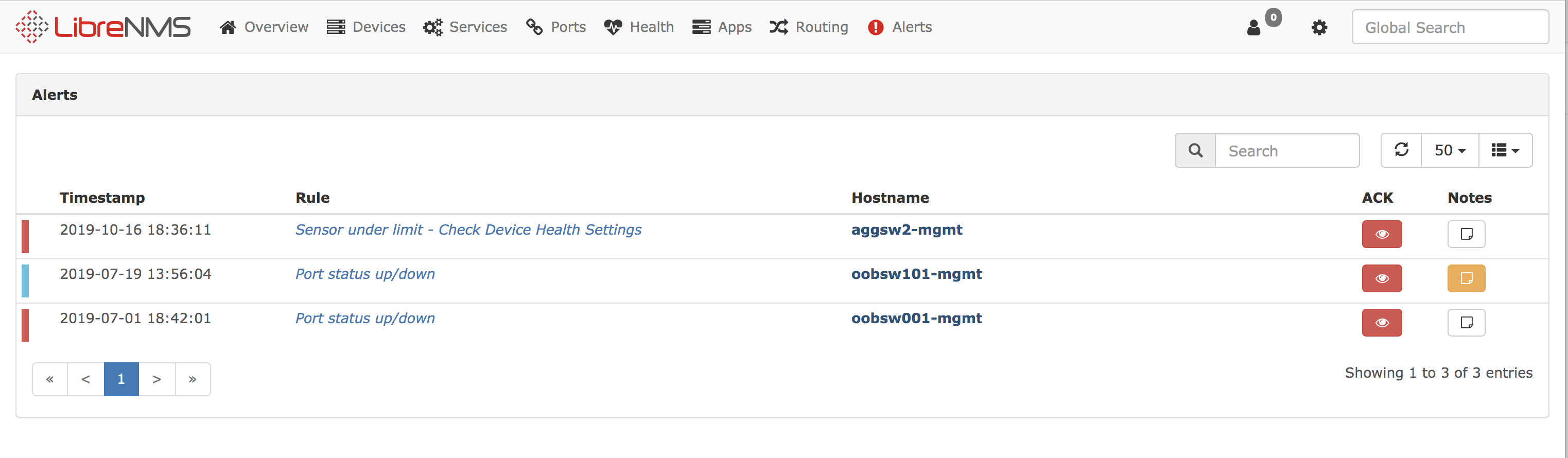
Il y avait également des intégrations telles que Datadog, CloudWatch. Pour en savoir plus sur ce qu'ils sont devenus,
cliquez ici .
Visualisation
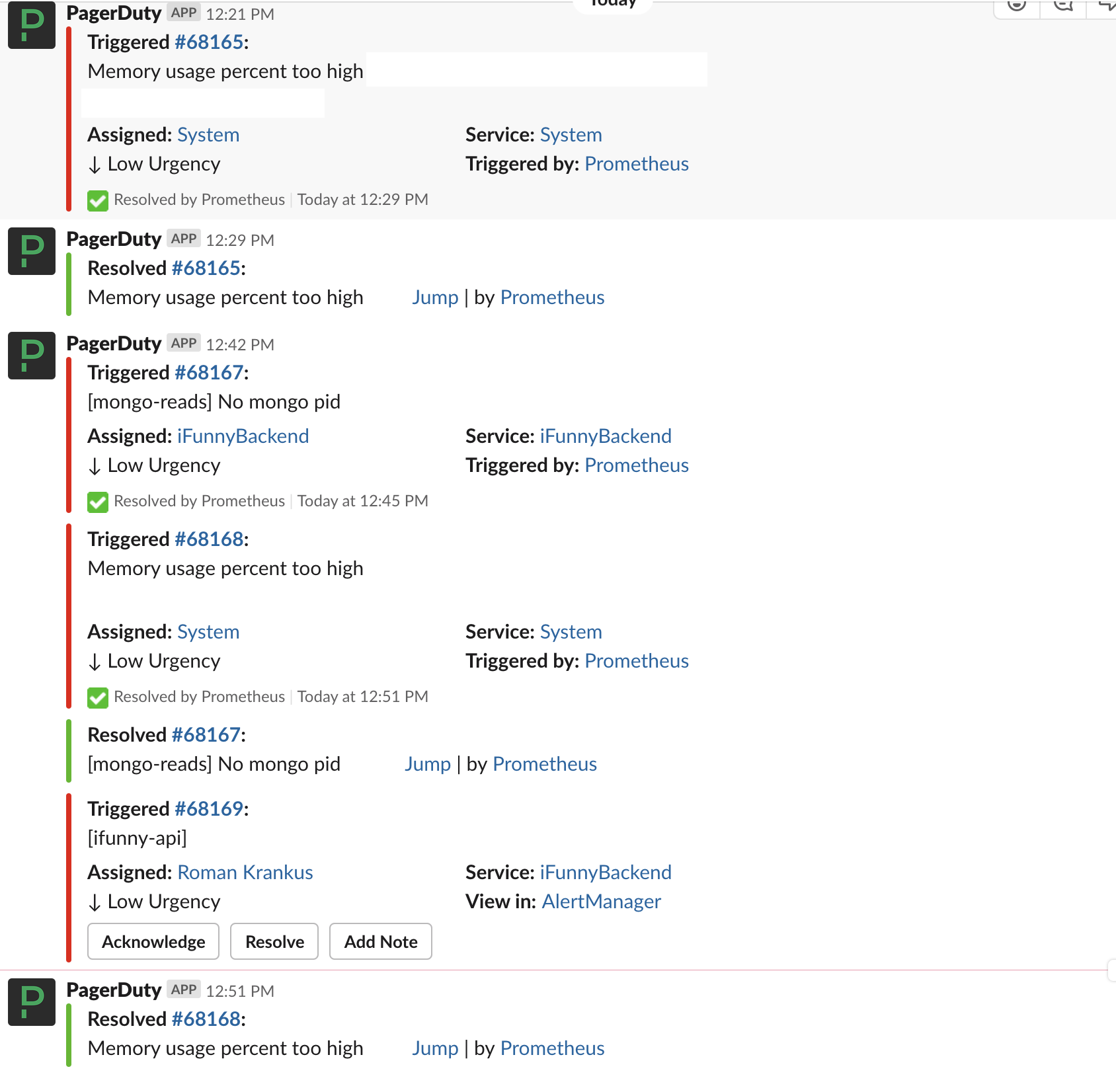
Le principal système de signalement des incidents est Slack. Tous les incidents qui arrivent sur PD sont écrits dans un chat spécial, et si leur statut change, cela est également affiché dans le chat.
Quand il est devenu possible d'afficher des données utiles sur les écrans de moniteurs suspendus sous le plafond, nous avons soudain réalisé que nous (dans la section devops) n'avons rien à afficher sur eux. Il y a un merveilleux Grafana, mais il ne peut tout simplement pas être couvert, et les employés répondent aux alertes, pas aux graphiques.
Après une recherche approfondie mais infructueuse sur GitHub pour un «tableau» concis et informatif pour PD, nous avons décidé d'écrire le nôtre - uniquement avec ce dont nous avions besoin. Bien qu'au départ, il y avait une idée d'afficher l'interface PD elle-même, cela semblait encore plus gênant.
Pour l'écrire, il vous suffit d'obtenir la clé de PD avec des droits en lecture seule.
Et voici ce que nous avons obtenu:
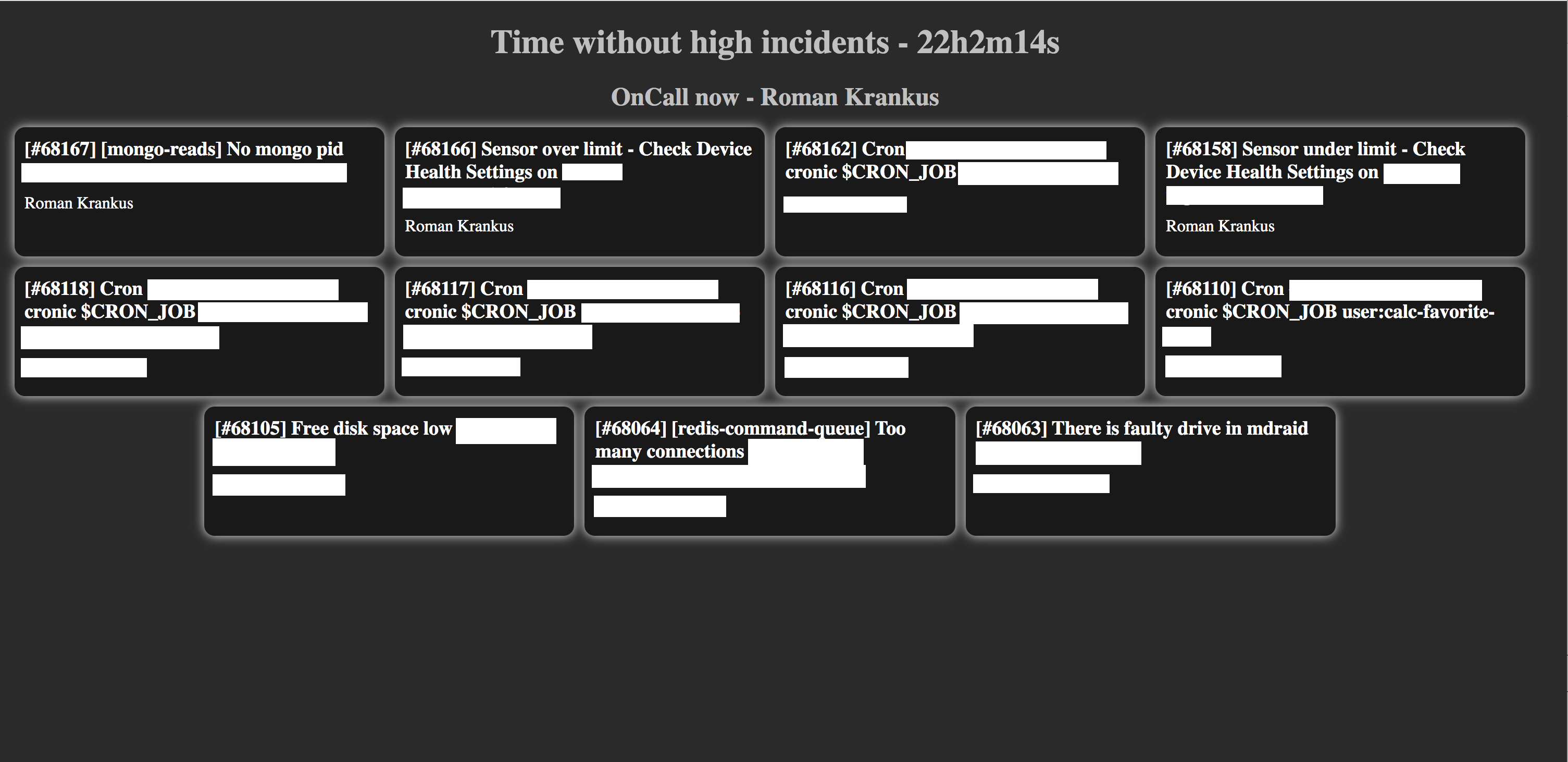
L'écran affiche les incidents ouverts actuels, le nom de l'ingénieur de service actuel du programme sélectionné et le temps sans incident de haute priorité (le panneau avec l'incident de haute priorité sera mis en surbrillance en rouge).
Voir le code source de cette implémentation ici .
En conséquence, nous avons obtenu un tableau de bord pratique pour visualiser tous nos incidents. Je serais heureux si l'un d'entre vous bénéficierait de notre expérience.