
Lorsque nous cessons de contrôler la taille de la table, la maintenance et la mise à disposition des données deviennent une tâche non triviale. J'ai déjà rencontré un tel problème en production, il y a plus de données tous les jours, la table ne tient pas en mémoire, les serveurs répondent depuis longtemps, mais une solution a été trouvée.
Bonjour, Habr! Je m'appelle Diamond et maintenant je veux partager une méthode qui m'a aidé à implémenter le partitionnement.
Partitionnement dans PostgreSql
Le partitionnement (ou, comme ils l'appellent, le partitionnement) est le processus de division d'une grande table logique en plusieurs sections physiques plus petites. C'est ce qui nous aide à gérer nos données.
Exemple: nous avons une table «ventes», qui est divisée par un intervalle d'un mois, et ces sections peuvent être divisées en sous-sections encore plus petites par région.
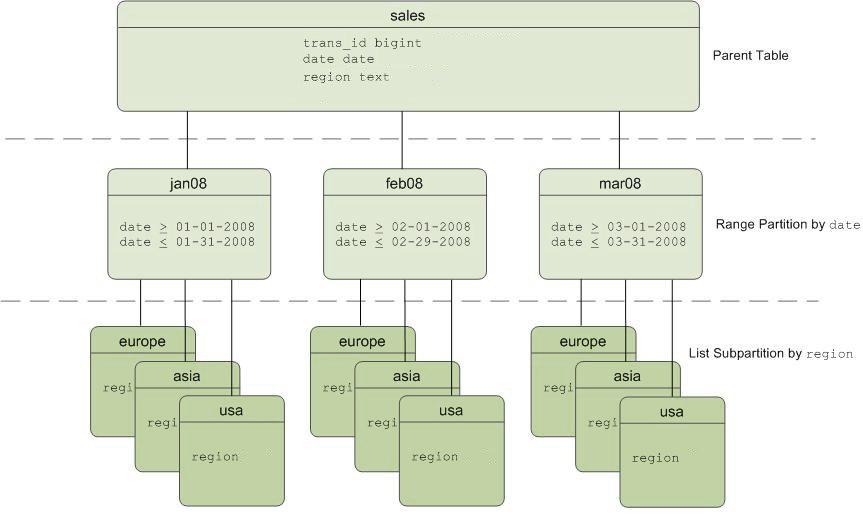 Schéma «ventes» de la table partitionnée
Schéma «ventes» de la table partitionnéeInconvénients de cette approche:
- Structure de base de données compliquée. Chaque section des définitions de base de données est une table, bien qu'elle fasse partie d'une entité logique.
- Vous ne pouvez pas convertir une table existante en une table partitionnée et vice versa.
- Il n'y a pas de support complet dans Postgres version 11.
Avantages:
+ Performance. Dans certains cas, nous pouvons travailler avec un ensemble limité de sections sans parcourir la table entière, même la recherche d'index pour les grandes tables sera plus lente. Augmente la disponibilité des données.
+ Téléchargement en masse et suppression de données avec les commandes ATTACH / DETACH. Cela nous évite des frais généraux sous forme de vide. ce qui vous permet de maintenir plus efficacement la base de données.
+ Possibilité de spécifier TABLESPACE pour la section. Cela nous donne la possibilité de transférer des données vers d'autres sections, mais nous travaillons toujours dans la même instance et les métadonnées du répertoire principal contiendront des informations sur les sections (à ne pas confondre avec le partitionnement).
2 façons d'implémenter le partitionnement dans PostgreSql:
1. Héritage de tables (HÉRITAGES)Lors de la création d'une table, nous disons "hériter d'une autre table (parent)". Dans le même temps, nous ajoutons des restrictions pour la gestion des données dans le tableau. Par cela, nous soutenons la logique de fractionnement des données, mais ce sont logiquement des tables différentes.
Il convient de noter ici l'extension développée par Postgres Professional pg_pathman, qui implémente le partitionnement, également par héritage de table.
CREATE TABLE orders_y2010 ( CHECK (log_date >= DATE '2010-01-01) ) INHERITS (orders);
2. Approche déclarative (PARTITION)Une table est définie comme partitionnée de manière déclarative. Cette solution est apparue dans la version 10 de PostgreSql.
CREATE TABLE orders (log_date date not null, …) PARTITION BY RANGE(log_date);
J'ai choisi une approche déclarative. Cela donne un gros avantage - nativité, plus de fonctionnalités sont prises en charge par le noyau. Considérez le développement de PostgreSQL dans cette direction:
 Source
SourceMais PostgreSql continue d'évoluer et la version 12 prend en charge la liaison à une table partitionnée. C'est une grande percée.
Mon chemin
Compte tenu de ce qui précède, un
script a été écrit en PL / pgSQL, ce qui crée une table partitionnée basée sur la table existante et «jette» tous les liens vers la nouvelle table. Ainsi, nous obtenons une table partitionnée basée sur la table existante et continuons à travailler avec elle comme avec une table standard.
Le script ne nécessite pas de dépendances supplémentaires et s'exécute dans un circuit séparé qu'il crée lui-même. Enregistre également les actions de rétablissement et d'annulation. Ce script résout deux tâches principales: crée une table partitionnée et implémente des liens externes vers celle-ci via les déclencheurs de déclenchement.
Exigence de script: PostgreSql v.:11 et supérieur.
Passons maintenant en revue le script plus en détail. L'interface est très simple:
Il y a deux procédures qui font tout le travail.
1. Le principal défi - à ce stade, nous ne changeons pas le tableau principal, mais tout le nécessaire pour la coupe sera créé dans un schéma distinct:
call partition_run();
2. Appelez les tâches différées qui étaient prévues pendant les travaux principaux:
call partition_run_jobs();
Le travail peut être lancé dans plusieurs threads. Le nombre optimal de threads est proche du nombre de tables partitionnées.
Paramètres d'entrée pour le script (enregistrement _pt)

Le script de l'intérieur, les principales actions:
- Créer une table partitionnée
perform _partition_create_parent_table(_pt);
- Créer des sections
perform _partition_create_child_tables(_pt);
- Copiez les données dans la section
perform _partition_copy_data(_pt);
- Ajouter des restrictions (travail)
perform _partition_add_constraints(_pt);
- Restaurer les liens vers des tables externes
perform _partition_restore_referrences(_pt);
- Restaurer les déclencheurs
perform _partition_restore_triggers(_pt);
- Créer un déclencheur d'événement
perform _partition_def_tr_on_delete(_pt);
- Créer des index (job)
perform _partition_create_index(_pt);
- Remplacer les vues, les liens de section (travail)
perform _partition_replace_view(_pt);
La durée d'exécution du script dépend de nombreux facteurs, mais les principaux sont la taille des tables cibles, le nombre de relations, les index et les caractéristiques du serveur. Dans mon cas, une table de 300 Go a été partitionnée en moins d'une heure.
Résultat
Qu'avons-nous obtenu? Regardons le plan de requête:
EXPLAIN ANALYZE select * from “sales” where dt BETWEEN '01.01.2019'::date and '14.01.2019'::date

Nous avons obtenu le résultat de la table partitionnée plus rapidement et utilisé moins de ressources de notre serveur par rapport à la requête vers une table régulière.
Dans cet exemple, les tables régulières et partitionnées sont sur la même base et ont environ 200 millions d'enregistrements. C'est un bon résultat, étant donné que nous avons, sans réécrire le code de l'application, accéléré. Les requêtes sur d'autres index fonctionnent également bien, mais n'oubliez pas: chaque fois que nous pouvons déterminer une section, le résultat sera plusieurs fois plus rapide, car PostgreSql peut supprimer des sections supplémentaires au stade de la planification de la demande (
définissez enable_partition_pruning sur on ).
Résumé
J'ai réussi à implémenter le partitionnement sur des tables qui ont de nombreuses relations et à assurer l'intégrité de la base de données. Le script est indépendant de structures de données spécifiques et peut être réutilisé.
PostgreSQL est la base de données relationnelle open source la plus avancée au monde!Merci à tous!
Lien vers la source