La nouvelle année se rapproche, les années 2010 se termineront bientôt, donnant au monde la renaissance sensationnelle des réseaux de neurones. J'ai été troublé
et privé de sommeil par une simple pensée: «Comment peut-on estimer rétrospectivement la vitesse de développement des réseaux de neurones?» Pour «Celui qui connaît le passé connaît l'avenir». À quelle vitesse les différents algorithmes ont-ils décollé? Comment évaluer la vitesse des progrès dans ce domaine et estimer la vitesse des progrès de la prochaine décennie?

Il est clair que vous pouvez calculer approximativement le nombre d'articles dans différents domaines. La méthode n'est pas idéale, vous devez prendre en compte les sous-domaines, mais en général, vous pouvez essayer. Je donne une idée, sur
Google Scholar (BatchNorm) c'est bien réel! Vous pouvez envisager de nouveaux ensembles de données, vous pouvez de nouveaux cours. Votre humble serviteur, après avoir
trié plusieurs options, a
opté pour
Google Trends (BatchNorm) .
Mes collègues et moi avons pris les demandes des principales technologies ML / DL, par exemple,
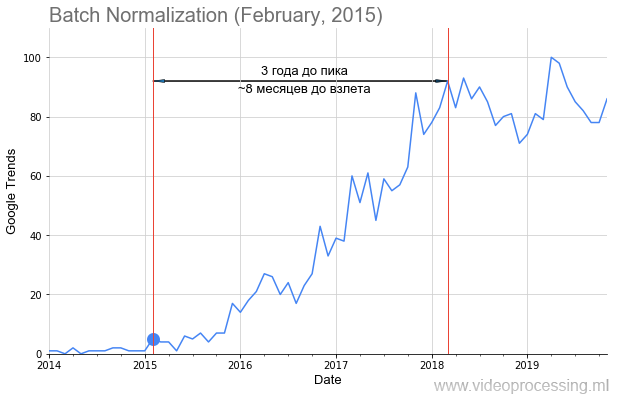
Batch Normalization , comme dans l'image ci-dessus, ajouté la date de publication de l'article avec un point, et obtenu un calendrier assez long pour décoller la popularité du sujet. Mais pas pour tous ceux-là, le
chemin est jonché de roses, le décollage est tellement évident et beau, comme la batnorm. Certains termes, tels que régularisation ou saut de connexion, n'ont pas pu être créés du tout en raison du bruit des données. Mais en général, nous avons réussi à collecter les tendances.
Peu importe ce qui s'est passé - bienvenue dans la coupe!
Au lieu d'introduire ou de reconnaître l'image
Alors! Les données initiales étaient assez bruyantes, parfois il y avait de fortes pointes.
 Source: Andrei Karpaty twitter - les étudiants se tiennent dans les allées d'un vaste public pour écouter une conférence sur les réseaux de neurones convolutifs
Source: Andrei Karpaty twitter - les étudiants se tiennent dans les allées d'un vaste public pour écouter une conférence sur les réseaux de neurones convolutifsConventionnellement, il suffisait à
Andrey Karpaty de donner une conférence sur le légendaire
CS231n: Réseaux de neurones convolutifs pour la reconnaissance visuelle pour 750 personnes avec la vulgarisation du concept de la façon dont un pic pointu va. Par conséquent, les données ont été lissées avec un simple
filtre-boîte (toutes les sorties lissées sont marquées comme lissées sur l'axe). Comme nous voulions comparer le taux de croissance de la popularité - après le lissage, toutes les données ont été normalisées. Cela s'est avéré assez drôle. Voici un graphique des principales architectures en compétition sur ImageNet:
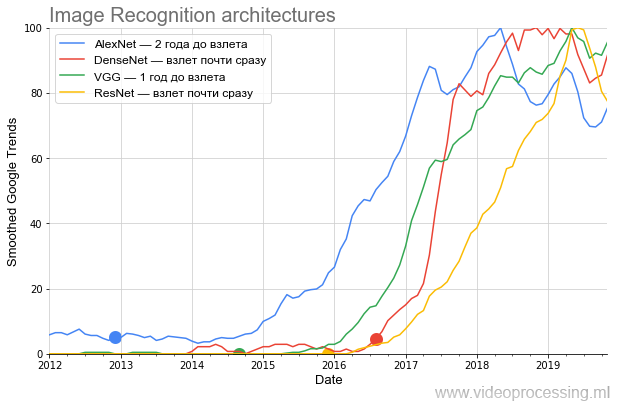 Source: Ci-après - les calculs de l'auteur selon Google Trends
Source: Ci-après - les calculs de l'auteur selon Google TrendsLe graphique montre très clairement qu'après la publication sensationnelle
AlexNet , qui a brassé la bouillie du battage médiatique actuel des réseaux de neurones à la fin de 2012, pendant près de deux ans, il bouillonnait,
contrairement aux affirmations du tas, seul un cercle relativement restreint de spécialistes s'est
joint . Le sujet n'est allé au grand public qu'à l'hiver 2014-2015. Faites attention à la périodicité du calendrier à partir de 2017: de nouveaux sommets chaque printemps.
En psychiatrie, cela s'appelle une exacerbation printanière ... C'est un signe certain que maintenant le terme est principalement utilisé par les étudiants, et en moyenne, l'intérêt pour AlexNet diminue par rapport au pic de popularité.
De plus, au second semestre 2014,
VGG est apparu. Soit dit en passant,
VGG a co-écrit avec le superviseur des
études mon ancienne étudiante
Karen Simonyan , qui travaille maintenant dans Google DeepMind (
AlphaGo ,
AlphaZero , etc.). Pendant ses études à l'Université d'État de Moscou en 3e année, Karen a mis en œuvre un bon
algorithme d'estimation de mouvement , qui sert de référence aux étudiants de 2 ans depuis 12 ans. De plus, les tâches y sont quelque peu insaisissables. Comparez:
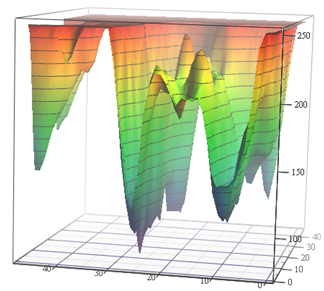
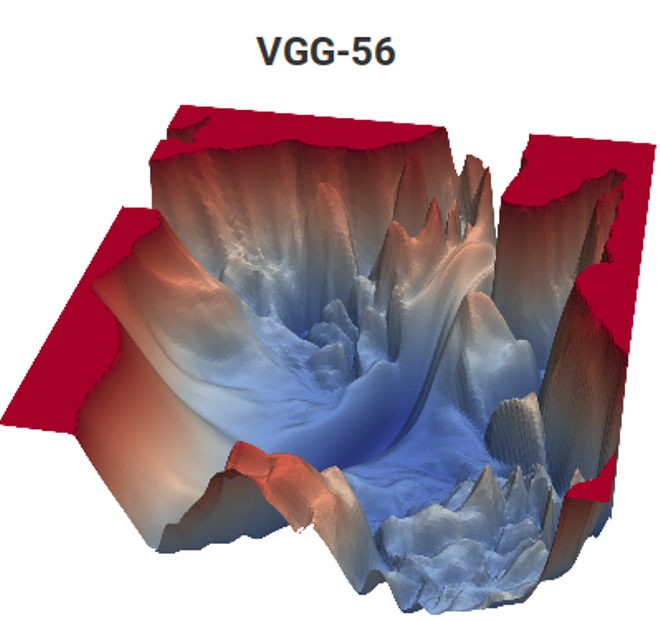 Source: fonction de perte pour les tâches d'estimation de mouvement (matériel d'auteur) et VGG-56
Source: fonction de perte pour les tâches d'estimation de mouvement (matériel d'auteur) et VGG-56Sur la gauche, vous devez trouver le point le plus profond d'une surface non triviale en fonction des données d'entrée pour le nombre minimum de mesures (de nombreux minima locaux sont possibles), et sur la droite, vous devez trouver un point inférieur avec des calculs minimaux (et également un tas de minima locaux, et la surface dépend également des données) . À gauche, nous obtenons le vecteur de mouvement prévu et à droite, le réseau formé. Et la différence est qu'à gauche, il n'y a qu'une mesure implicite de l'espace colorimétrique et à droite, une paire de mesures de centaines de millions. Eh bien, la complexité de calcul à droite est d'environ 12 ordres de grandeur (!) Supérieure. Un peu comme ça ... Mais la deuxième année, même avec une tâche simple, oscille comme ... [coupé par la censure]. Et le niveau de programmation des écoliers d'hier pour des raisons inconnues au cours des 15 dernières années a nettement baissé. Ils doivent dire: "Vous le ferez bien, ils vous emmèneront à DeepMind!" On pourrait dire «inventer le VGG», mais «ils vont se tourner vers DeepMind» pour une raison quelconque, cela motive mieux. Ceci, évidemment, est un analogue moderne avancé du classique "Vous mangerez de la semoule, vous deviendrez astronaute!". Cependant, dans notre cas, si l'on compte le nombre d'enfants dans le pays et la taille du corps des cosmonautes, les chances sont des millions de fois plus élevées, car deux d'entre nous travaillent déjà chez DeepMind depuis notre laboratoire.
Vient ensuite
ResNet , brisant la barre du nombre de couches et commençant à décoller après six mois. Et enfin, DenseNet, qui est venu au début du battage médiatique
, a décollé presque immédiatement, encore plus cool que ResNet.
Si nous parlons de popularité, je voudrais ajouter quelques mots sur les caractéristiques du réseau et les performances, dont dépend également la popularité. Si vous regardez comment la classe
ImageNet est prédite en fonction du nombre d'opérations sur le réseau, la disposition sera la suivante (en haut et à gauche - mieux):
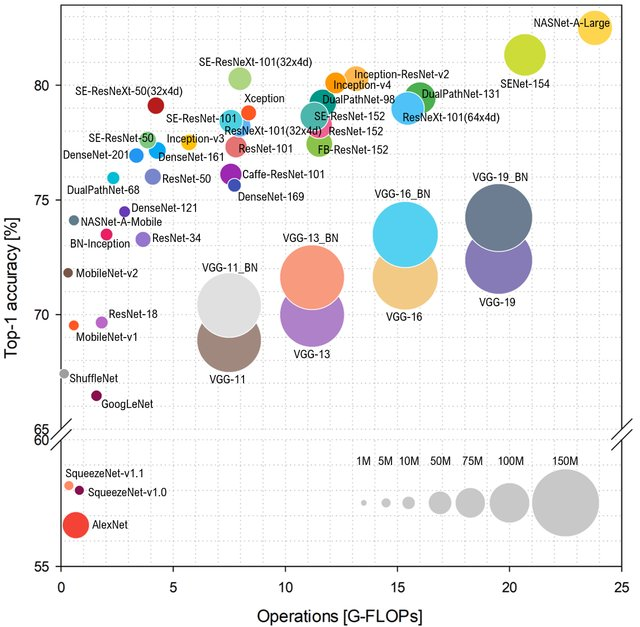 Source: Analyse comparative des architectures représentatives des réseaux de neurones profonds
Source: Analyse comparative des architectures représentatives des réseaux de neurones profondsTapez AlexNet n'est plus un gâteau, et ils gouvernent les réseaux basés sur ResNet. Cependant, si vous regardez l'évaluation pratique du
FPS plus près de mon cœur, vous pouvez clairement voir que VGG est plus proche de l'optimum ici, et en général, l'alignement change sensiblement. Y compris AlexNet de façon inattendue sur l'enveloppe Pareto-optimale (l'échelle horizontale est logarithmique, mieux au-dessus et à droite):
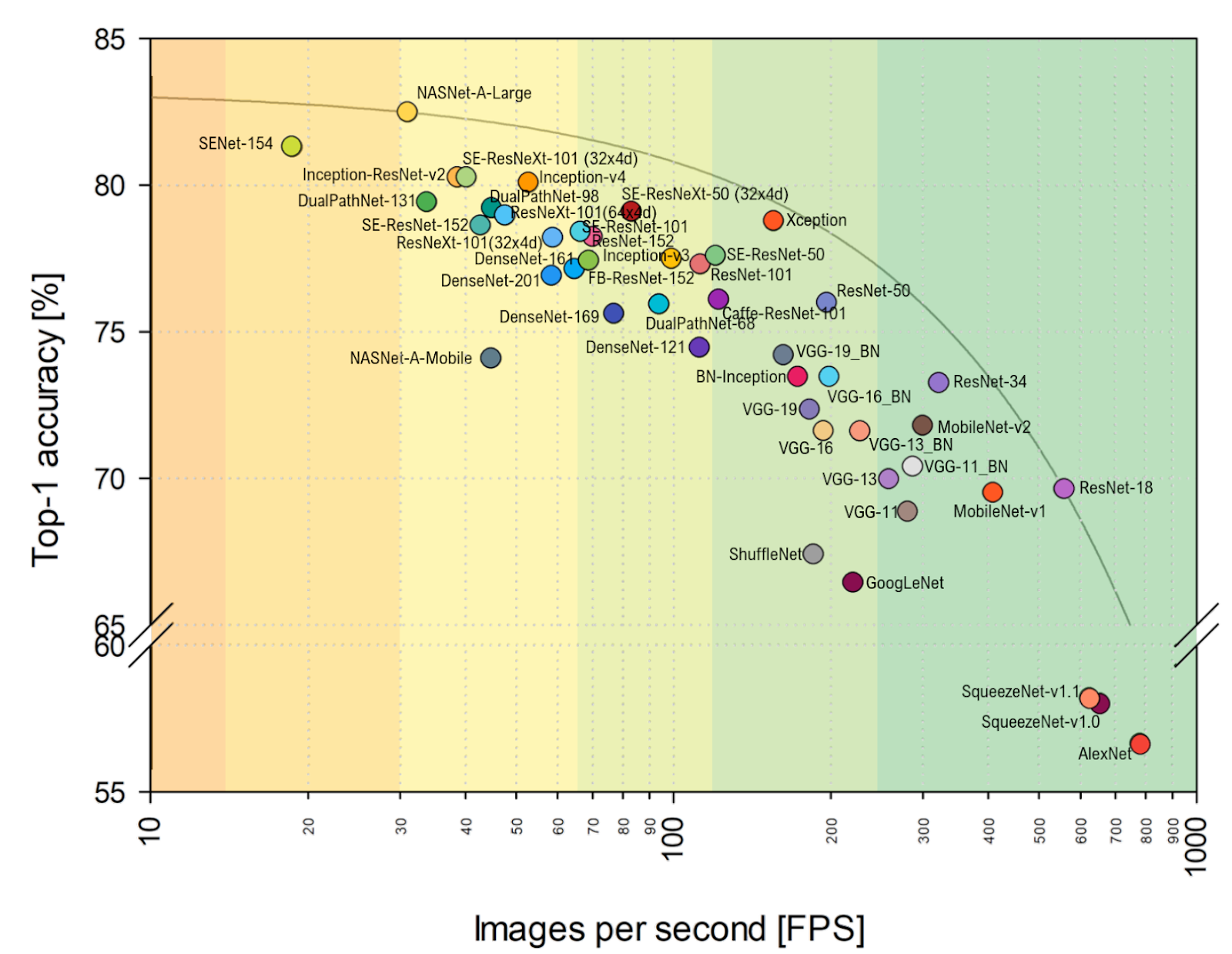 Source: Analyse comparative des architectures représentatives des réseaux de neurones profondsTotal:
Source: Analyse comparative des architectures représentatives des réseaux de neurones profondsTotal:
- Dans les années à venir, l'alignement des architectures à forte probabilité changera de manière très significative en raison de la progression des accélérateurs de réseaux neuronaux , lorsque certaines architectures vont dans des paniers et d'autres décollent soudainement, simplement parce qu'il vaut mieux se reposer sur un nouveau matériel. Par exemple, dans l'article mentionné , une comparaison est effectuée sur la carte NVIDIA Titan X Pascal et la carte NVIDIA Jetson TX1, et la disposition change sensiblement. Dans le même temps, les progrès du TPU, du NPU et d'autres ne font que commencer.
- En tant que praticien, je ne peux m'empêcher de remarquer que la comparaison sur ImageNet est effectuée par défaut sur ImageNet-1k, et non sur ImageNet-22k, simplement parce que la plupart forment leurs réseaux sur ImageNet-1k, où il y a 22 fois moins de classes (ce à la fois plus facile et plus rapide). Le passage à ImageNet-22k, qui est plus pertinent pour de nombreuses applications pratiques, changera également l'alignement (pour ceux qui sont affinés de 1k - beaucoup).
Plus profondément dans la technologie et l'architecture
Mais revenons à la technologie. Le terme
abandon en tant que mot de recherche est assez bruyant, mais une croissance de 5 fois est clairement associée aux réseaux de neurones. Et le déclin de son intérêt est très probable avec un
brevet Google et l'avènement de nouvelles méthodes. Veuillez noter qu'environ un an et demi s'est écoulé entre la publication de l'
article original et le regain d'intérêt pour la méthode:
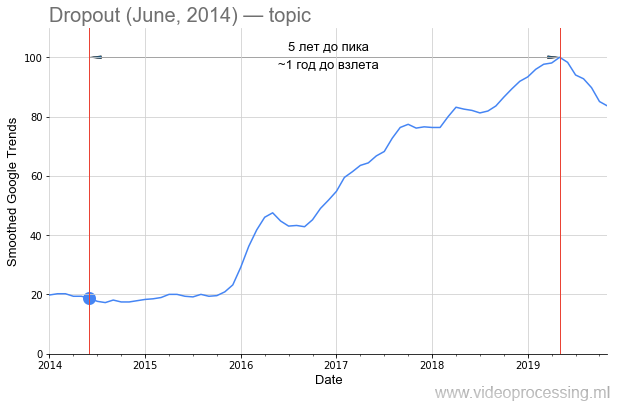
Cependant, si nous parlons de la période précédant la montée en popularité, alors en DL l'une des premières places est clairement prise par
les réseaux récurrents et le
LSTM :
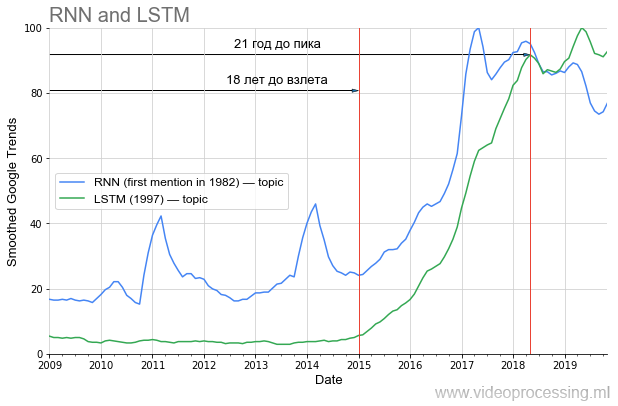
20 ans avant le pic actuel de popularité, et maintenant, avec leur utilisation, la traduction automatique, l'analyse du génome ont été radicalement améliorées, et dans un avenir proche (si vous prenez de ma région), YouTube, le trafic Netflix va baisser deux fois avec la même qualité visuelle. Si vous apprenez correctement les leçons de l'histoire, il est évident qu'une partie des idées de la série d'articles actuelle ne «décollera» qu'après 20 ans. Menez une vie saine, prenez soin de vous et vous le verrez personnellement!
Maintenant plus proche du battage médiatique promis.
Les GAN ont décollé comme ceci:
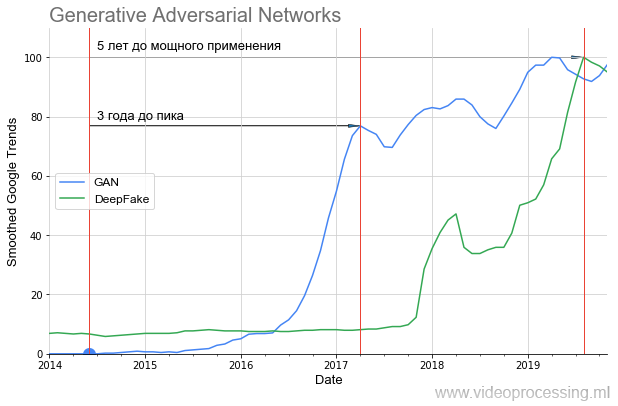
On peut voir clairement que pendant presque un an, il y a eu un silence total et qu'en 2016, après 2 ans, une forte augmentation a commencé (les résultats ont été sensiblement améliorés). Ce décollage un an plus tard a donné le sensationnel DeepFake, qui, cependant, a également décollé de 1,5 an. Autrement dit, même les technologies très prometteuses nécessitent beaucoup de temps pour passer d'une idée à des applications que tout le monde peut utiliser.
Si vous regardez quelles images le GAN a générées dans l'
article original et ce qui peut être construit avec
StyleGAN , il devient assez évident pourquoi il y avait un tel silence. En 2014, seuls les spécialistes ont pu évaluer à quel point c'était cool - faire, en substance, un autre réseau en tant que fonction de perte et les former ensemble. Et en 2019, chaque écolier pourrait apprécier à quel point c'est cool (sans comprendre complètement comment cela se fait):

Il
existe de nombreux problèmes différents résolus avec succès par les réseaux de neurones aujourd'hui, vous pouvez prendre les meilleurs réseaux et créer des graphiques de popularité pour chaque direction, gérer le bruit et les pics de requêtes de recherche, etc. Afin de ne pas répandre mes pensées sur l'arbre, nous terminerons cette sélection par le thème des algorithmes de segmentation, où les idées de
convolution atreuse / dilatée et d'
ASSP au cours de la dernière année et demie se sont tout à fait enflammées
dans l'algorithme de référence :
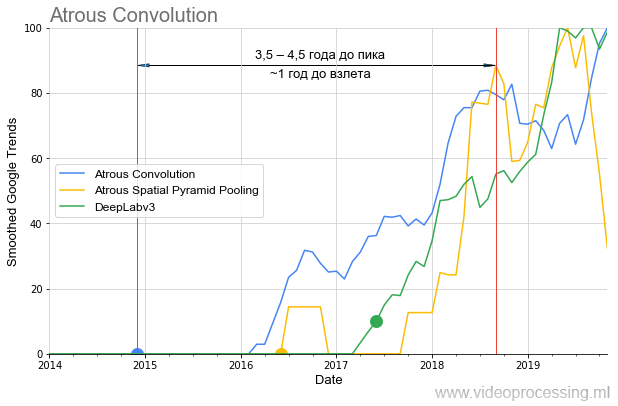
Il convient également de noter que si
DeepLabv1 plus d'un an a «attendu» la montée en popularité,
DeepLabv2 a décollé en un an et
DeepLabv3 presque immédiatement. C'est-à-dire en général, nous pouvons parler d'accélérer la croissance de l'intérêt au fil du temps (enfin, ou d'accélérer la croissance de l'intérêt pour les technologies d'auteurs réputés).
Tout cela ensemble a conduit à la création du problème mondial suivant - une augmentation explosive du nombre de publications sur le sujet:
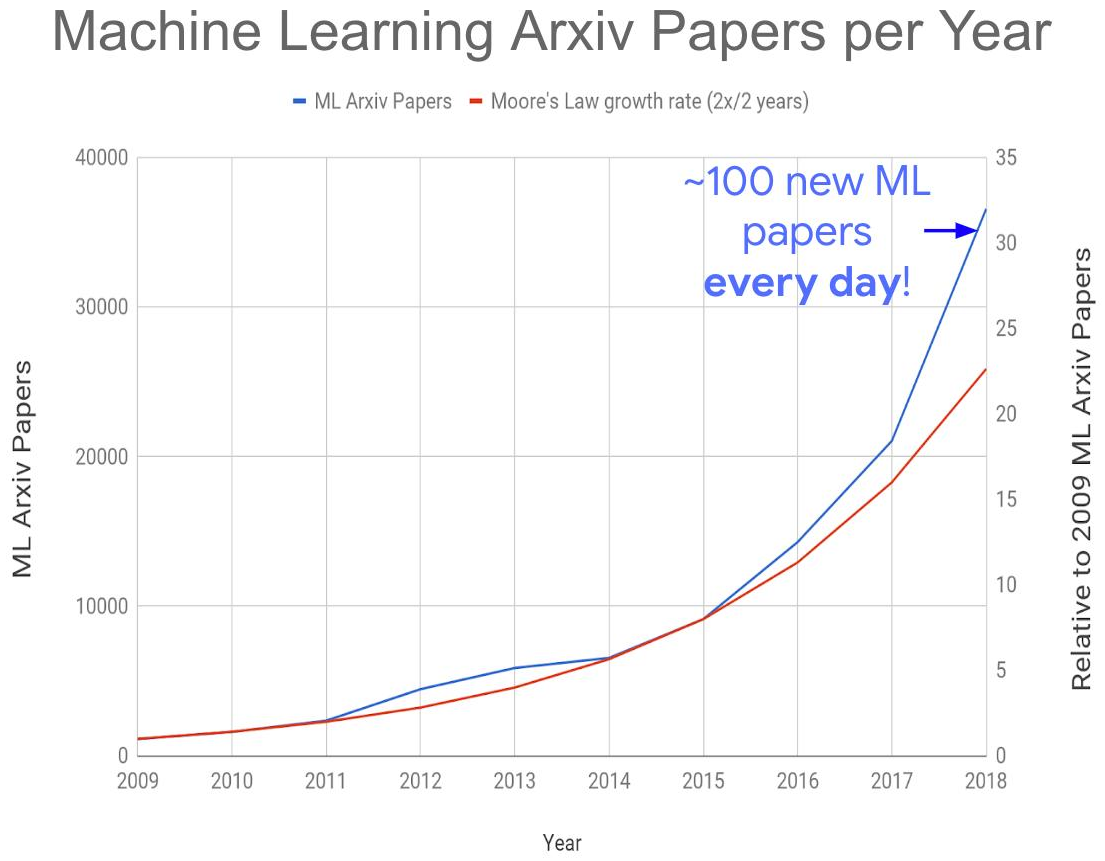 Source: Trop de documents d'apprentissage automatique?
Source: Trop de documents d'apprentissage automatique?Cette année, nous recevons environ 150 à 200 articles par jour, étant donné que tous ne sont pas publiés sur arXiv-e. Aujourd'hui, lire des articles, même dans leur propre sous-domaine, est totalement impossible. En conséquence, de nombreuses idées intéressantes seront certainement enfouies sous les décombres de nouvelles publications, ce qui affectera le moment de leur «décollage». Cependant, l'augmentation
explosive du nombre de spécialistes compétents employés dans la région donne
peu d' espoir de faire face au problème.
Total:
- En plus d'ImageNet et de l'histoire en coulisses des succès du jeu DeepMind, les GAN ont donné naissance à une nouvelle vague de vulgarisation des réseaux de neurones. Avec eux, il était vraiment possible de «filmer» des acteurs sans utiliser d'appareil photo . Et s'il y en aura plus! Sous ce bruit informationnel, des technologies de traitement et de reconnaissance moins sonores, mais tout à fait fonctionnelles seront financées.
- Comme il y a trop de publications, nous attendons avec impatience l'émergence de nouvelles méthodes de réseau neuronal pour une analyse rapide des articles, car elles seules nous sauveront (une blague avec une fraction de blague!).
Robots de travail, homme heureux
Depuis 2 ans maintenant, AutoML gagne en popularité
sur les pages des journaux . Tout a commencé traditionnellement avec ImageNet, dans lequel, dans la précision Top-1, il a commencé à prendre fermement la première place:
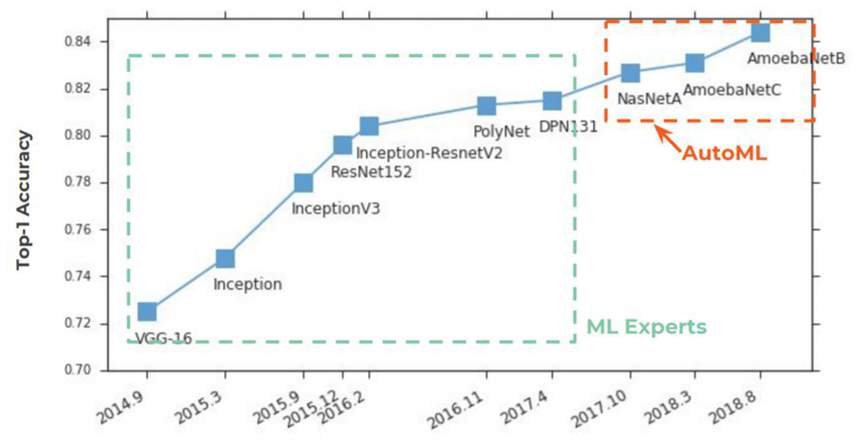
L'essence d'AutoML est très simple, un rêve centenaire de scientifiques des données s'y est réalisé - pour un réseau neuronal de sélectionner des hyper-paramètres. L'idée a été accueillie avec éclat:
Ci-dessous sur le graphique, nous voyons une situation assez rare lorsque, après la publication des premiers articles sur
NASNet et
AmoebaNet , ils commencent à gagner en popularité par rapport aux normes des idées précédentes presque instantanément (un énorme intérêt pour le sujet est affecté):
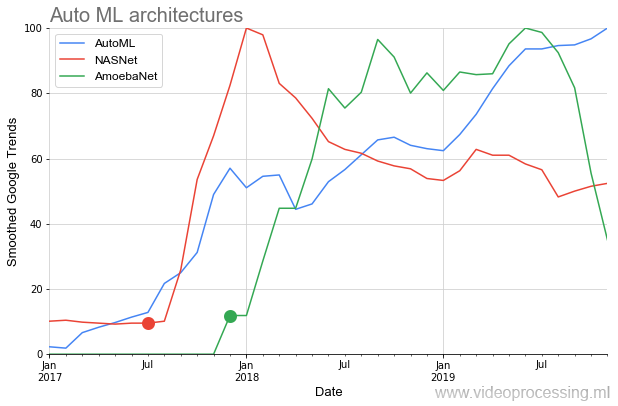
L'image idyllique est quelque peu gâchée par deux points. Tout d'abord, toute conversation sur AutoML commence par la phrase: "Si vous avez un dofigalion GPU ...". Et c'est ça le problème. Google, bien sûr, affirme qu'avec leur
Cloud AutoML, cela est facilement résolu, l'
essentiel est que vous ayez suffisamment d'argent , mais tout le monde n'est pas d'accord avec cette approche. Deuxièmement, cela fonctionne jusqu'à présent
imparfaitement . En revanche, rappelant les GAN, cinq ans ne se sont pas encore écoulés, et l'idée elle-même s'annonce très prometteuse.
Dans tous les cas, le décollage principal d'AutoML commencera avec la prochaine génération d'accélérateurs matériels pour les réseaux de neurones et, en fait, avec des algorithmes améliorés.
 Source: Image de Dmitry Konovalchuk, documents de l'auteurTotal: En fait, les data scientists n'auront pas de vacances éternelles, bien sûr, car pendant très longtemps il restera un gros mal de tête avec les données. Mais avant la nouvelle année et le début des années 2020, pourquoi ne pas rêver?
Source: Image de Dmitry Konovalchuk, documents de l'auteurTotal: En fait, les data scientists n'auront pas de vacances éternelles, bien sûr, car pendant très longtemps il restera un gros mal de tête avec les données. Mais avant la nouvelle année et le début des années 2020, pourquoi ne pas rêver?Quelques mots sur les outils
L'efficacité de la recherche dépend beaucoup des outils. Si pour programmer AlexNet, vous aviez besoin d'une programmation non triviale, aujourd'hui un tel réseau peut être rassemblé en plusieurs lignes dans de nouveaux frameworks.
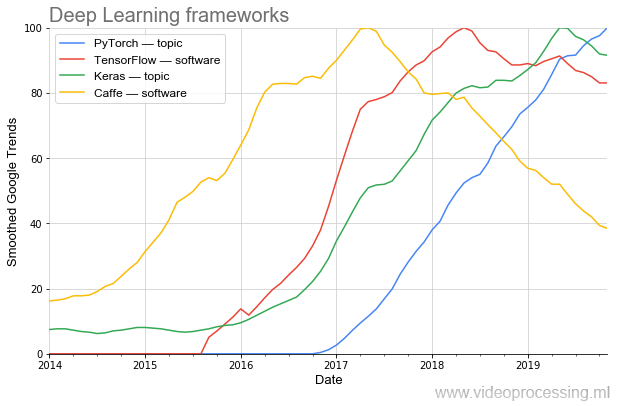
On voit clairement comment la popularité évolue par vagues. Aujourd'hui, le plus populaire (y compris
selon PapersWithCode ) est
PyTorch . Et une fois que le populaire
Caffe sort magnifiquement très bien. (Remarque: le sujet et le logiciel signifient que le filtrage des sujets de Google a été utilisé lors du traçage.)
Eh bien, puisque nous avons abordé les outils de développement, il convient de mentionner les bibliothèques pour accélérer l'exécution du réseau:
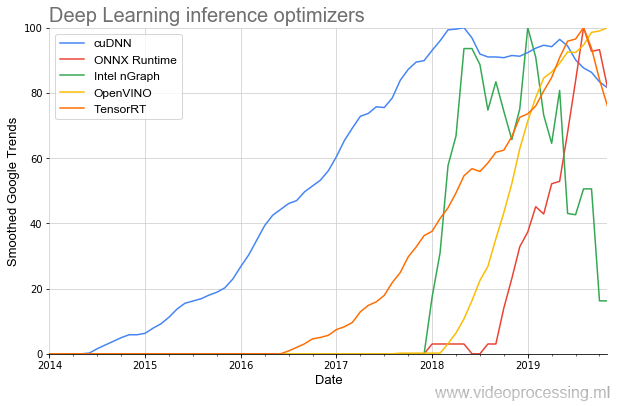
La plus ancienne du sujet est (respect NVIDIA)
cuDNN , et, heureusement pour les développeurs, au cours des dernières années, le nombre de bibliothèques a augmenté plusieurs fois, et le début de leur popularité est devenu nettement plus rapide. Et il semble que tout cela ne soit qu'un début.
Total: Même au cours des 3 dernières années, les outils ont considérablement changé pour le mieux. Et il y a 3 ans, selon les normes d'aujourd'hui, ils ne l'étaient pas du tout. La progression est très bonne!Perspectives promises du réseau neuronal
Mais le plaisir commence plus tard. Cet été, dans un
grand article séparé, j'ai décrit en détail pourquoi le CPU et même le GPU ne sont pas assez efficaces pour fonctionner avec les réseaux de neurones, pourquoi des milliards de dollars affluent dans le développement de nouvelles puces et quelles sont les perspectives. Je ne vais pas me répéter. Vous trouverez ci-dessous une généralisation et l'ajout du texte précédent.
Pour commencer, vous devez comprendre les différences entre les calculs de réseau de neurones et les calculs dans l'architecture von Neumann familière (dans laquelle ils peuvent, bien sûr, être calculés, mais de manière moins efficace):
 Source: Image de Dmitry Konovalchuk, documents de l'auteur
Source: Image de Dmitry Konovalchuk, documents de l'auteurLa fois précédente, la discussion principale a tourné autour du FPGA / ASIC, et les calculs inexacts sont passés presque inaperçus, nous allons donc nous attarder sur eux plus en détail. Les énormes perspectives de réduction des puces des générations futures résident précisément dans la capacité de lire de manière inexacte (et de stocker les données de coefficient localement). Le grossissement, en fait, est également utilisé en arithmétique exacte, lorsque les poids du réseau sont convertis en nombres entiers et quantifiés, mais à un nouveau niveau. À titre d'exemple, considérons un additionneur à un seul bit (l'exemple est assez abstrait):
 Source: conception de multiplicateur 8 bits x 8 bits haute vitesse et faible consommation utilisant de nouvelles portes XOR à deux transistors (2T)
Source: conception de multiplicateur 8 bits x 8 bits haute vitesse et faible consommation utilisant de nouvelles portes XOR à deux transistors (2T)Il a besoin de 6 transistors (il existe différentes approches, le nombre de transistors requis peut être de plus en plus, mais en général, quelque chose comme ça). Pour 8 bits, environ
48 transistors sont nécessaires. Dans ce cas, l'additionneur analogique ne nécessite que 2 (deux!) Transistors, c'est-à-dire 24 fois moins:
 Source: Multiplicateurs analogiques (analyse et conception de circuits intégrés analogiques)
Source: Multiplicateurs analogiques (analyse et conception de circuits intégrés analogiques)Si la précision est plus élevée (par exemple, équivalente à 10 ou 16 bits numériques), la différence sera encore plus grande. Encore plus intéressante est la situation avec la multiplication! Si un multiplexeur numérique 8 bits nécessite environ
400 transistors , alors un analogique 6, c'est-à-dire 67 fois (!) De moins. Bien sûr, les transistors «analogiques» et «numériques» sont sensiblement différents du point de vue des circuits, mais l'idée est claire - si nous parvenons à augmenter la précision des calculs analogiques, nous atteignons facilement la situation lorsque nous avons besoin de deux ordres de grandeur de transistors en moins. Et l’important n’est pas tant de réduire la taille (ce qui est important dans le cadre du «ralentissement de la loi de Moore»), mais de réduire la consommation d’électricité, ce qui est essentiel pour les plates-formes mobiles. Et pour les centres de données, ce ne sera pas superflu.
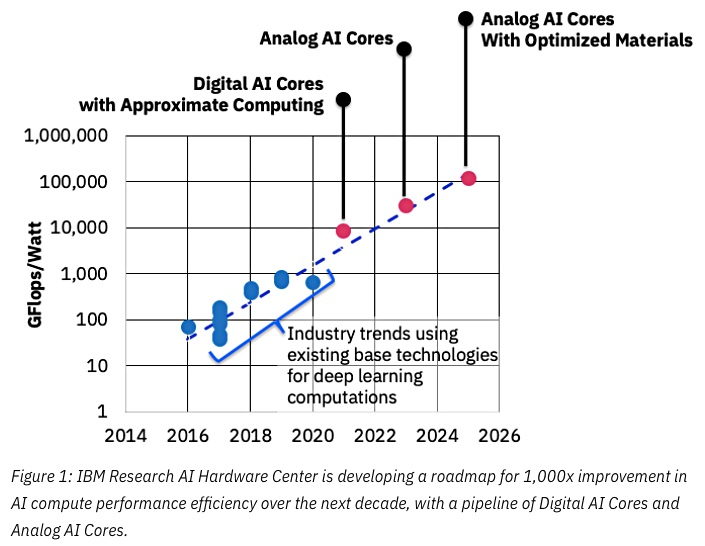 Source: IBM pense que les puces analogiques accélèrent l'apprentissage automatique
Source: IBM pense que les puces analogiques accélèrent l'apprentissage automatiqueLa clé du succès ici sera une réduction de la précision, et là encore IBM est au premier plan:
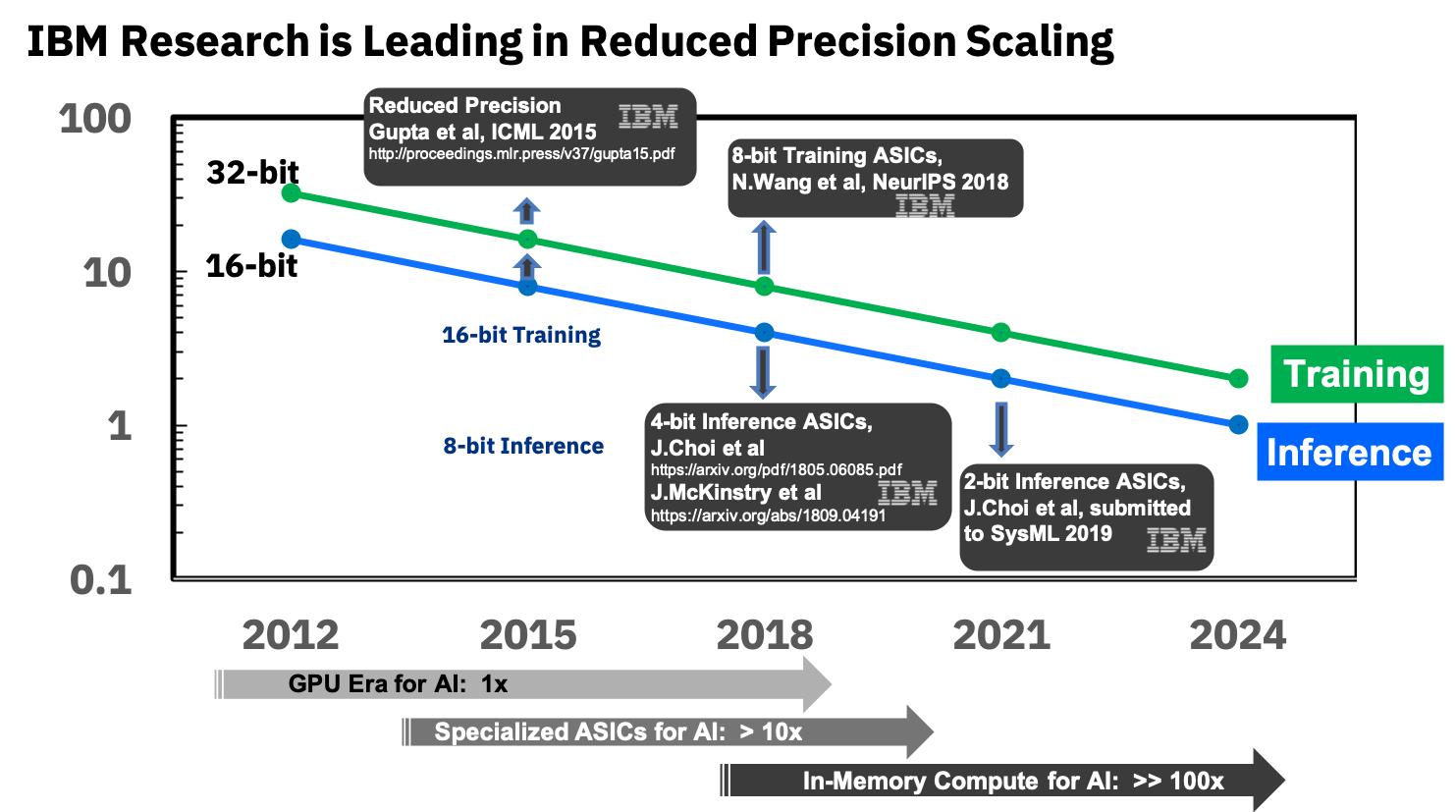 Source: IBM Research Blog: précision 8 bits pour la formation de systèmes d'apprentissage en profondeur
Source: IBM Research Blog: précision 8 bits pour la formation de systèmes d'apprentissage en profondeurIls sont déjà engagés dans des ASIC spécialisés pour les réseaux de neurones, qui présentent une supériorité de plus de 10 fois sur le GPU, et prévoient d'atteindre une supériorité de 100 fois dans les années à venir. Cela semble extrêmement encourageant, nous l'attendons vraiment avec impatience, car, je le répète, ce sera une percée pour les appareils mobiles.
En attendant, la situation n'est pas si magique, bien qu'il y ait de sérieux succès. Voici un test intéressant des accélérateurs matériels mobiles actuels des réseaux de neurones (l'image est cliquable, et cela réchauffe encore l'âme de l'auteur, également en images par seconde):
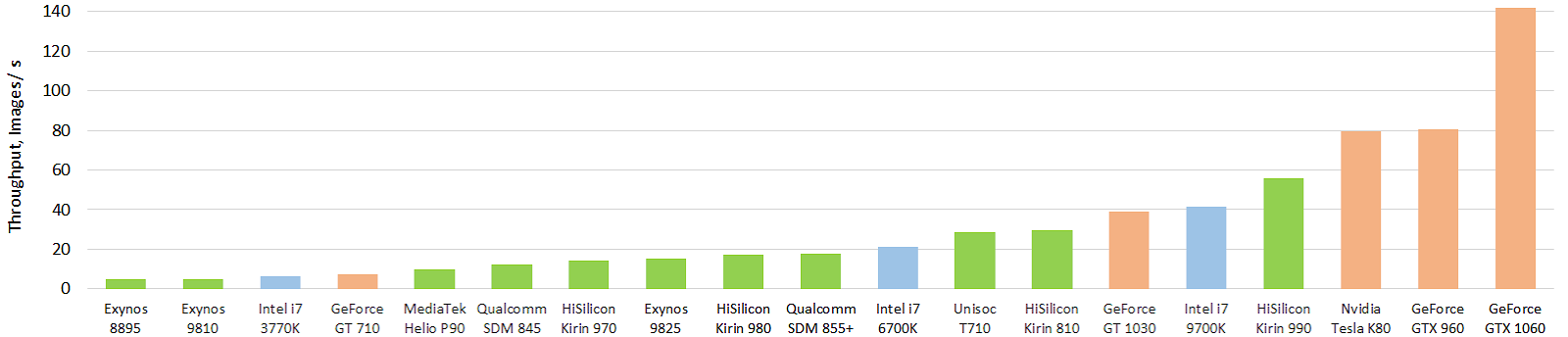 Source: Evolution des performances des accélérateurs d'intelligence artificielle mobiles: débit d'image pour le modèle float Inception-V3 (modèle FP16 utilisant TensorFlow Lite et NNAPI)
Source: Evolution des performances des accélérateurs d'intelligence artificielle mobiles: débit d'image pour le modèle float Inception-V3 (modèle FP16 utilisant TensorFlow Lite et NNAPI)Le vert indique les puces mobiles, le bleu indique le CPU, l'orange indique le GPU. On voit clairement que les puces mobiles actuelles, et tout d'abord, la puce haut de gamme de Huawei, dépassent déjà les processeurs des dizaines de fois plus grandes (et la consommation d'énergie). Et c'est fort! Avec le GPU, jusqu'à présent, tout n'est pas si magique, mais il y aura autre chose. Vous pouvez regarder les résultats plus en détail sur un site Web séparé
http://ai-benchmark.com/ , faites attention à la section des tests là-bas, ils ont choisi un bon ensemble d'algorithmes pour la comparaison.
Total: Les progrès des accélérateurs analogiques sont aujourd'hui assez difficiles à évaluer. Il y a une course. Mais les produits ne sont pas encore sortis, il y a donc relativement peu de publications. Vous pouvez surveiller les brevets apparaissant avec un retard (par exemple, un flux dense d'IBM ) ou rechercher des brevets rares d' autres fabricants. Il semble que ce sera une révolution très sérieuse, principalement dans les smartphones et les TPU de serveurs.Au lieu d'une conclusion
ML / DL est aujourd'hui appelé une nouvelle technologie de programmation, lorsque nous n'écrivons pas de programme, mais insérons un bloc et le formons. C'est-à-dire Comme au début, il y avait un assembleur, puis C, puis C ++, et maintenant, après 30 longues années d'attente, la prochaine étape est ML / DL:
Cela a du sens. Récemment, dans les entreprises avancées, les lieux de décision dans les programmes sont remplacés par des réseaux de neurones. C'est-à-dire
si hier il y avait des décisions «sur les FI» ou sur des heuristiques qui étaient bonnes pour le cœur du programmeur ou même les équations de Lagrange (wow!) et d'autres réalisations plus complexes de décennies de développement de la théorie du contrôle ont été utilisées, aujourd'hui, ils ont mis un réseau neuronal simple avec 3-5 couches avec plusieurs entrées et des dizaines de cotes. Elle apprend instantanément, travaille beaucoup plus efficacement et le développement de code devient plus rapide. Si auparavant, il fallait s'asseoir, chaman , allumer le cerveau , maintenant je l'ai collé, alimenté des données, et cela a fonctionné, et vous êtes occupé avec des choses de niveau supérieur. Juste une sorte de vacances!Naturellement, le débogage est désormais différent. Si avant, quand quelque chose ne fonctionnait pas, il y avait une demande: "Envoyez un exemple sur lequel ça ne marche pas!" Et puis un barbu sérieux et expérimenté- Le smartphone prend des photos du texte et le reconnaît - ce sont des réseaux de neurones,
- Un smartphone traduit bien à la volée d'une langue à l'autre et parle une traduction - réseaux de neurones et encore une fois réseaux de neurones,
- Le navigateur et le haut-parleur intelligent reconnaissent assez bien la parole - encore une fois les réseaux de neurones,
- Le téléviseur affiche une image de contraste lumineux de 8K à partir de la vidéo d'entrée 2K - également un réseau neuronal,
- Les robots en production sont devenus plus précis, ils ont commencé à mieux voir et reconnaître les situations anormales - encore une fois les réseaux de neurones,
- 10 ,
- — ,
- — - — ,
- — ! )

Seulement 4 ans se sont écoulés depuis que les gens ont appris à former des réseaux neuronaux très profonds à bien des égards grâce à BatchNorm (2015) et à sauter les connexions (2015), et 3 ans se sont écoulés depuis leur «décollage», et nous lisons vraiment les résultats de leur travail n'a pas vu. Et maintenant, ils atteindront les produits. Quelque chose nous dit que dans les années à venir, beaucoup de choses intéressantes nous attendent. Surtout quand les accélérateurs "décollent" ...

Il était une fois, si quelqu'un se souvient, Prométhée a volé le feu d'Olympe et l'a remis aux gens. Angry Zeus avec d'autres dieux a créé la première beauté d'une femme-homme nommée Pandora, qui était dotée de nombreuses qualités féminines merveilleuses
(j'ai soudainement réalisé que le récit politiquement correct de certains des mythes de la Grèce antique est extrêmement difficile) . Pandora a été envoyée aux gens, mais Prométhée, qui soupçonnait que quelque chose n'allait pas, a résisté à son sort, et son frère Épiméthée ne l'a pas fait. En cadeau pour le mariage, Zeus a envoyé un beau cercueil avec Mercure et Mercure, une âme gentille, a rempli la commande - il a donné le cercueil à Epiméthée, mais l'a averti de ne pas l'ouvrir de toute façon. La curieuse Pandore a volé le cercueil de son mari, l'a ouvert, mais il n'y avait que des péchés, des maladies, des guerres et d'autres problèmes de l'humanité. Elle a essayé de fermer le cercueil, mais il était trop tard:
 Source: Artiste Frederick Stuart Church, Boîte ouverte de Pandore
Source: Artiste Frederick Stuart Church, Boîte ouverte de PandoreDepuis lors, la phrase «ouvrir la boîte de Pandore» a disparu, c'est-à-dire effectuer
par curiosité une action irréversible, dont les conséquences peuvent ne pas être aussi belles que les décorations du cercueil à l'extérieur.
Vous savez, plus je plonge profondément dans les réseaux de neurones, plus distinct est le sentiment qu'il s'agit d'une autre boîte de Pandore. Cependant, l'humanité a la plus riche expérience dans l'ouverture de telles boîtes! De la récente récente - c'est l'énergie nucléaire et Internet. Donc, je pense que nous pouvons faire face ensemble. Pas étonnant qu'un groupe d'hommes
barbus durs parmi les ouvreurs. Eh bien, un cercueil est beau, d'accord! Et ce n'est pas vrai qu'il n'y a que des problèmes, un tas de bonnes choses ont déjà été obtenues. Par conséquent, ils se sont réunis et ... nous ouvrons plus loin!
Total:
- L'article n'inclut pas de nombreux sujets intéressants, par exemple, les algorithmes ML classiques, l'apprentissage par transfert, l'apprentissage par renforcement, la popularité des ensembles de données, etc. (Messieurs, vous pouvez continuer le sujet!)
- À la question sur le cercueil: je pense personnellement que les programmeurs de Google qui ont permis à Google d'abandonner le contrat de 10 milliards de dollars avec le Pentagone sont grands et beaux. Ils respectent et respectent. Cependant, notez que quelqu'un a remporté cet appel d'offres majeur.
Lisez aussi:
- Accélération matérielle des réseaux de neurones profonds: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP et autres lettres - le texte de l'auteur sur l'état actuel et les perspectives de l'accélération matérielle des réseaux de neurones par rapport aux approches actuelles.
- Deep Fake Science, la crise de la reproductibilité et d'où viennent les référentiels vides - sur les problèmes scientifiques générés par le ML / DL.
- Comparaison des codecs magiques de rue. Nous révélons des secrets - un exemple de faux basé sur des réseaux de neurones.
Autant de nouvelles découvertes intéressantes dans les années 2020 en général et dans la nouvelle année en particulier!
Remerciements
Je remercie chaleureusement:
- Laboratoire d'infographie et multimédia VMK Université d'État de Moscou M.V. Lomonosov pour sa contribution au développement de l'apprentissage profond en Russie et pas seulement
- personnellement Konstantin Kozhemyakov et Dmitry Konovalchuk, qui ont fait beaucoup pour rendre cet article meilleur et plus visuel,
- et enfin, un grand merci à Kirill Malyshev, Yegor Sklyarov, Nikolai Oplachko, Andrey Moskalenko, Ivan Molodetsky, Evgeny Lyapustin, Roman Kazantsev, Alexander Yakovenko et Dmitry Klepikov pour de nombreux commentaires et corrections utiles qui ont rendu ce texte bien meilleur!