En informatique, un projet sain est un système ou un service qui, d'une part, est de haute qualité, c'est-à-dire qu'il répond aux exigences et aux utilisateurs qui l'aiment. D'un autre côté, cela fait du profit, car l'entreprise veut toujours vraiment faire de l'argent. Sans un ensemble de qualité et d'affaires, rien de bon n'en sortira.

Sous la coupe, Ruslan Ostropolsky vous dira tout sur les métriques qui sont des indicateurs de la santé des systèmes informatiques. Il analysera ce que sont les métriques, comment elles changent à mesure que le projet se développe, lesquelles sont les mieux utilisées dans quel projet. Explique comment la qualité et les affaires s'entraident en termes de mesures et pourquoi cette collaboration est nécessaire.
À propos du conférencier et de l'entreprise: Ruslan Ostropolsky en informatique depuis 2010, le principal domaine d'intérêt est l'assurance qualité. Depuis 5 ans, il travaille chez DocDoc, une entreprise qui développe des services Internet médicaux. Le produit principal est un rendez-vous en ligne avec un médecin, plus de 2 millions de patients se sont inscrits pour un médecin via DocDoc, il existe également une ligne de diagnostic, de télémédecine et d'assurance VHI.
Quand qualité et business ne sont pas amis
Sans assurance qualité, il sera difficile pour une entreprise de gagner de l'argent à long terme. Besoin d'un tas de qualité et d'affaires. Si ce n'est pas le cas, les situations suivantes sont possibles.
Premièrement, il y a la
qualité pour la qualité : lorsque tous les types de tests connus sont utilisés dans une petite startup. Vous pouvez immédiatement penser à l'automatisation et aux tests sous charges, mais si vous en faites trop, le produit risque de ne pas atteindre la production. Par conséquent, vous avez besoin de:
- Comprendre l'entreprise - ce qui est pertinent en ce moment: gagner de l'argent, entrer sur le marché ou évoluer rapidement. La tâche de l'entreprise est de transférer ces objectifs au service technique.
- La qualité au bon endroit et en bonne quantité. Parfois, vous pouvez publier des versions contenant des bogues, mais en comprendre les risques et, en conséquence, en tenir compte.
Deuxièmement, il y a un autre cas - une
entreprise sans qualité . Une entreprise informatique peut même avoir un département de test, mais si l'assurance qualité est légère ou existe sous la forme de tests de singe, ce qui efface simplement la régression et s'arrête là, cela ne s'améliorera pas beaucoup.
NB: le contrôle qualité n'est pas vraiment un test, mais une approche générale au niveau de l'entreprise pour la fabrication de bons produits.
Comment savoir si vous développez ou non de la qualité?
Une évaluation objective nécessite des mesures qui montrent:
- Le fait des problèmes. Que vous avez essentiellement des problèmes, et s'il n'y a pas de problèmes, vous devez les rechercher plus attentivement. Très probablement, ils sont quelque part, mais vous ne les voyez toujours pas.
- Le fait des résultats. Les projets sont créés pour gagner de l'argent, entrer sur le marché, augmenter la conversion. Ces résultats doivent être suivis.
- État actuel. Où êtes-vous sur le chemin de vos objectifs, combien de bugs avez-vous actuellement, parvenez-vous à sprinter, à quelle vitesse vous déplacez-vous.
Comment choisir les métriques
Vous pouvez choisir des métriques selon trois principes.
Où ça fait mal. Si un incident se produit, il doit être démonté, pondéré avec des mesures et examiner la douleur: comment se déroule le traitement, quelle dynamique, si les bugs sont corrigés.
Avec une
approche ciblée, nous nous concentrons évidemment sur des objectifs, par exemple, l'accélération et l'automatisation. Auparavant, nos tests automatisés prenaient deux heures. Nous avons fixé un objectif en 10 minutes et examiné les mesures pour voir si nous approchions de cette valeur.
Mais il est impossible d'obtenir un projet sain si les mesures n'ont aucun lien avec l'entreprise, elles sont uniquement techniques et l'entreprise n'obtient pas de résultats. À l'inverse, s'il n'y a pas de bugs et que l'entreprise perd de l'argent, alors quelque chose d'étrange se produit.
Il est important de se rappeler qu'il existe différentes entreprises et différentes étapes d'un projet. Une startup, une entreprise en croissance ou un projet d'expansion a besoin de différentes mesures. C'est comme avec une maladie - si vous toussez, vous pouvez mesurer la température, boire de l'acide ascorbique et tout passera. Si vous avez des soupçons de pneumonie, vous devez prendre des photos, passer un examen et être traité différemment.
Mesures à différentes étapes du projet
Je vais vous dire quelles mesures nous avons mesurées lorsque nous étions une startup, puis nous avons commencé à croître et à nous développer.
Démarrage
À ce stade, le produit n'est qu'à ses balbutiements, vous testez une hypothèse, en recherchant si les gens en ont besoin.
Au stade du démarrage d'une entreprise, il est important que les idées soient livrées à l'utilisateur le plus rapidement possible et qu'elles puissent être vérifiées. C'est-à-dire que vous devez mesurer le
temps de mise sur le marché - la vitesse de livraison des idées aux utilisateurs (à savoir à la production et pas seulement à la publication) et le
nombre de clients .
Dans la partie QA, nous n'avions que 3 à 5 mesures:
- nombre de bugs de la bataille;
- le nombre de bogues qui atteignent la version;
- criticité des bogues.
La réponse à la question de savoir comment collecter des métriques est simple: il y a des mains et il y a Excel. Environ une fois par mois, mettez vos mains dans le tableau de données, cela devrait suffire.
Grandissent
À l'étape suivante, nous avons déjà appris à nous tenir debout, nous marchons un peu.
Les besoins des entreprises évoluent, il devient important de mesurer:
- Trafic Lorsqu'il est devenu clair que les utilisateurs ont besoin du produit, autant de trafic que possible est généré, par exemple, des programmes d'affiliation apparaissent.
- Mise à l'échelle - autant que possible pour croître à la fois du côté du produit et du côté du développement.
L'assurance qualité augmente déjà: 10 à 15 mesures. Si dans une startup nous avons créé un produit selon nos sentiments, par exemple, le fondateur a dit: «Je veux un bouton bleu», et tout le monde l'a fait, maintenant il y a la première statistique. Vous pouvez ignorer les fonctionnalités lors des
tests A / B et n'oubliez pas de mesurer les résultats.
L'automatisation apparaît. Les tests sur les singes ne suffisent plus et il est logique d'investir dans une extension. À ce stade, des tests automatiques apparaissent, ce qui devrait permettre d'accélérer les tests de régression. En conséquence, la
vitesse des tests de publication est mesurée
: le degré d'automatisation justifié. C'est triste quand l'automatisation a pris six mois, et pour une raison quelconque, les versions n'ont pas accéléré.
Le
volume de versions est également mesuré afin de voir si, par exemple, au lieu de 5 développeurs, il est devenu 15, mais pour une raison quelconque, le volume de versions n'a pas augmenté.
Pour collecter des métriques au stade de la croissance, en plus des mains et d'Excel, des systèmes spécialisés apparaissent. Les systèmes sont des outils qui aident à créer un produit. Si auparavant les mêmes cas de test ont été écrits dans Google docs, ils apparaissent ici:
- gestionnaire de système, par exemple, TestRail;
- Google Analytics pour la collecte de données utilisateur;
- Portail de rapports, Allure pour l'automatisation.
Le système construit en lui-même des métriques et des rapports supplémentaires.
Graisse
Nous grandissons encore, «nous envahissons de graisse» - nous n'entrons pas dans les bureaux dans lesquels nous étions assis et nous commençons à nous déplacer périodiquement.
Qu'est-ce qui est important pour les entreprises?- LTV. Besoin de garder les clients. Si auparavant le client enregistrait une fois et partait, maintenant, évidemment, il faut le garder, pour construire un service utilisateur.
- Marque / réputation. Si les personnes qui ont contacté DocDoc auparavant pouvaient penser qu'il s'agit d'une clinique, elles savent maintenant qu'elles sont au service qui les aide.
- SLA Alors que les gens commencent à utiliser le service en permanence, la disponibilité du service devient critique, car tout temps d'arrêt affecte directement l'argent.
- Données. Les premières données apparaissent, à la fois produit et technique et utilisateur, qui doivent pouvoir être traitées et stockées. Il y a une question de sécurité.
- Conversion Au stade de la mise à l'échelle, un produit fondamentalement nouveau n'est pas créé, mais le produit créé s'améliore.
L'assurance qualité comprend déjà environ 30 à 50 mesures. Nous mesurons:
- Charge: backend, serveur et front, et dans différentes tranches.
- La sécurité
- Taux de libération.
- Vitesse d'automatisation.
- Stabilité de l'automatisation: la vitesse et la stabilité de l'automatisation affectent directement la vitesse des versions, car la régression manuelle n'est pas la place à ce stade du développement du projet.
- Couverture d'automatisation.
Nous collectons des données comme auparavant, mais il y a plus de systèmes utilisés.
Des difficultés
Tout ne se passe pas bien et nous ne faisons pas exception. Je vais vous dire quelles difficultés nous avons rencontrées lorsque le projet a suffisamment progressé.
Il y a beaucoup de systèmes , il faut en quelque sorte les gérer. Regarder chaque système prend au moins beaucoup de temps.
Le nombre de directions , à la fois épicerie et technique,
a augmenté . De plus, chaque direction évolue différemment, certaines d'entre elles sont lancées en tant que startup, et il sera erroné de mettre des mesures et une assurance qualité sur toutes.
Les processus sont devenus plus compliqués : si auparavant 5 personnes travaillaient sur le projet, il était facile de se mettre d'accord et d'agir en conséquence, maintenant nous devons surveiller les processus. Par exemple, de nouvelles personnes doivent être introduites progressivement, sinon il leur sera difficile de comprendre le nombre cumulé de systèmes.
Les données et les rapports sont uniques au sein du service. Cela découle du fait qu'il existe de nombreux systèmes et que vous devez tous les surveiller. Chaque service génère ses propres rapports et vous devez tous les suivre. De plus, il devient de plus en plus difficile de les configurer vous-même: vous devez soit contacter le support technique pour un nouveau rapport, soit essayer de le configurer vous-même à l'aide de scripts.
Et s'il y a beaucoup de données,
Excel n'aide pas . Surtout si des dizaines de personnes commencent à travailler sur un fichier dans lequel tout est mis en place sur des formules - quelqu'un a changé quelque chose, tout est tombé en panne - ils l'ont vu en une semaine.
C'est peut-être ainsi que les analystes apparaissent dans les entreprises - des personnes spéciales qui collectent et tiennent à jour des statistiques et des données, car cela prend trop de temps pour être combiné.
Et bien sûr, il devient beaucoup
plus difficile d'analyser les informations en raison du fait qu'il existe à nouveau de nombreux systèmes, des données différentes que vous souhaitez relier les uns aux autres.
Traitez la tristesse
Vous pouvez aller à la mer, vous détendre, revenir et regarder l'expérience d'autres entreprises.
La solution logique est de tout rassembler en termes de données et de les convertir en métriques.
Nous avons formulé les critères suivants:
- Collectez automatiquement afin que personne ne charge quoi que ce soit n'importe où.
- Mettre en œuvre diverses représentations de données.
- Il devrait y avoir un tas de systèmes: si la moitié des données proviennent de Jira, la moitié de TestRail, elles doivent tomber dans une tirelire, d'où un rapport unique sera obtenu.
- Tout doit être gérable et facile à entretenir. Cela signifie que les gens eux-mêmes peuvent créer les rapports nécessaires sur la base du système et le soutenir eux-mêmes.
Tableaux de bord
Nous avons beaucoup de tableaux de bord, seuls les techniciens actifs sont maintenant environ 30, et environ 100 au total.
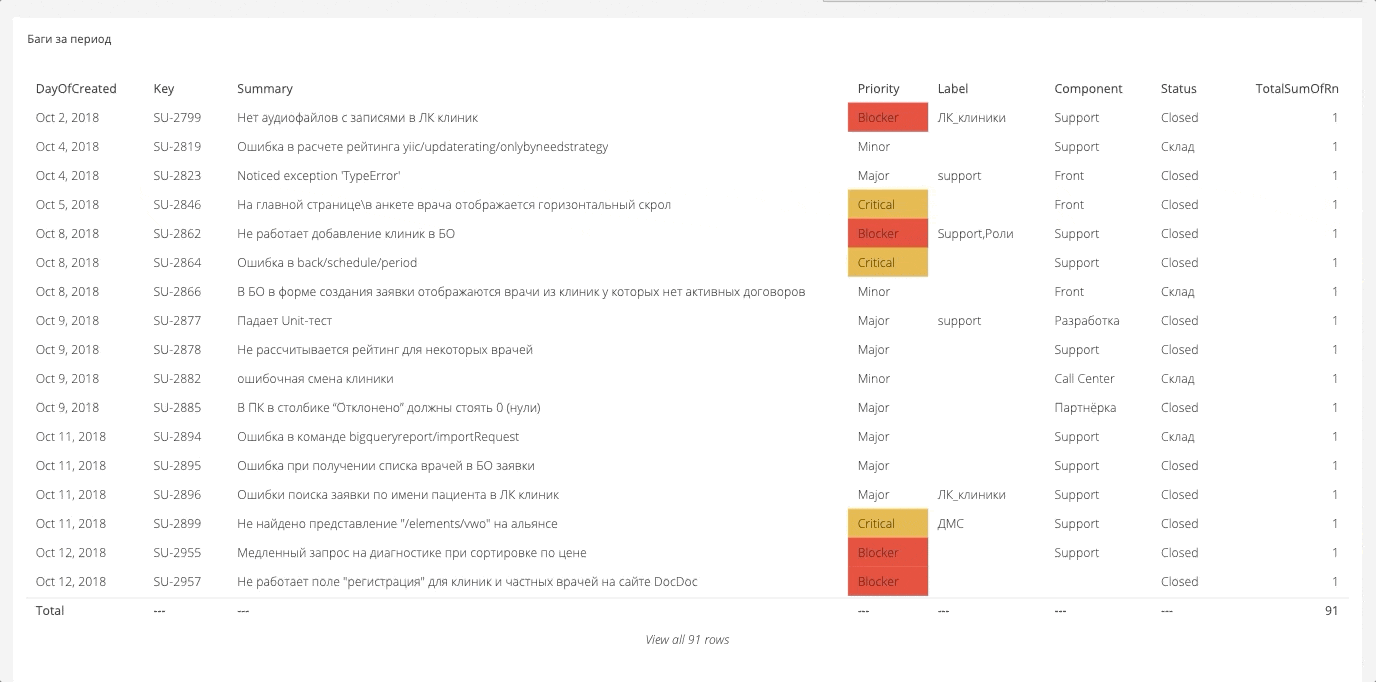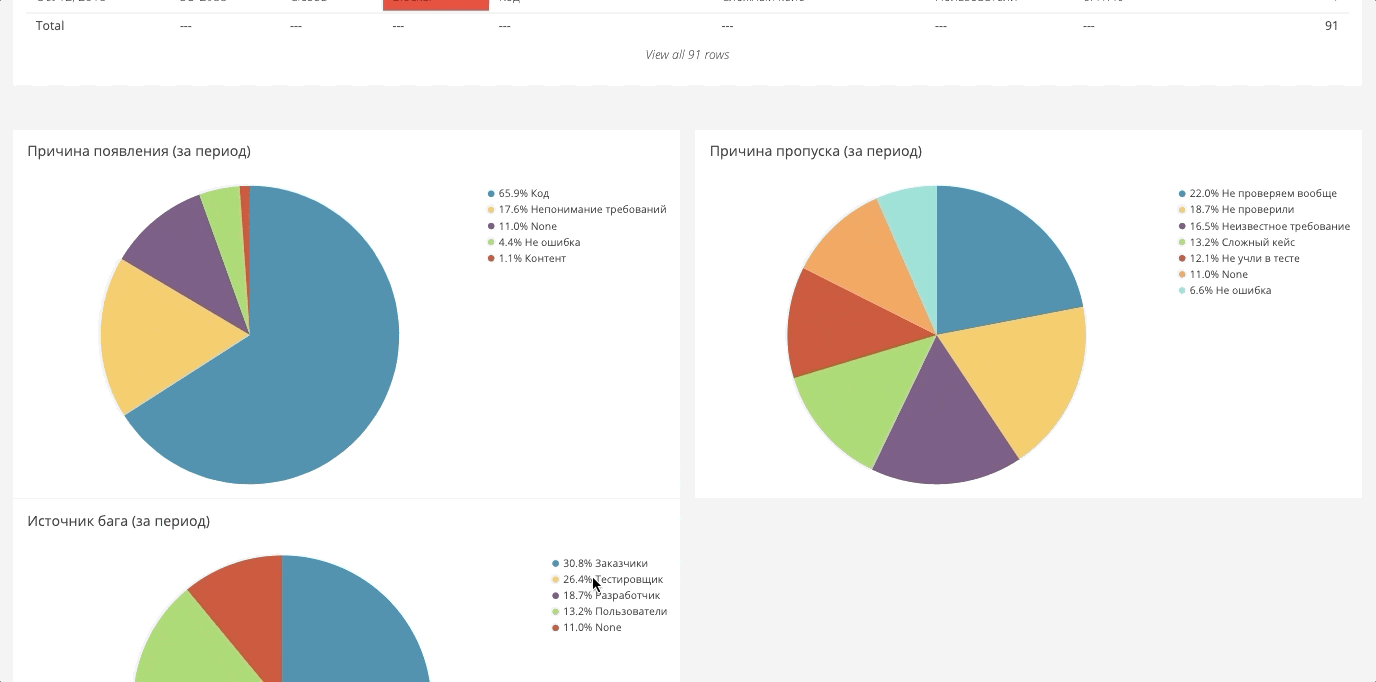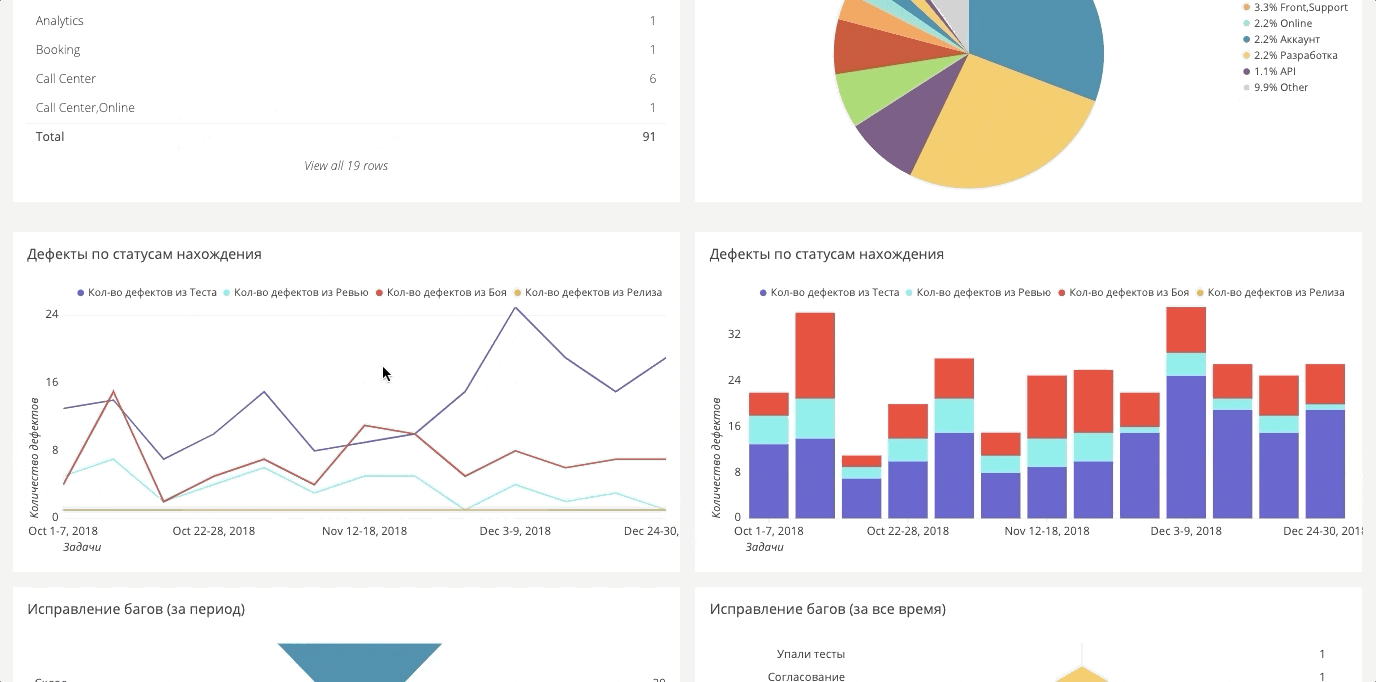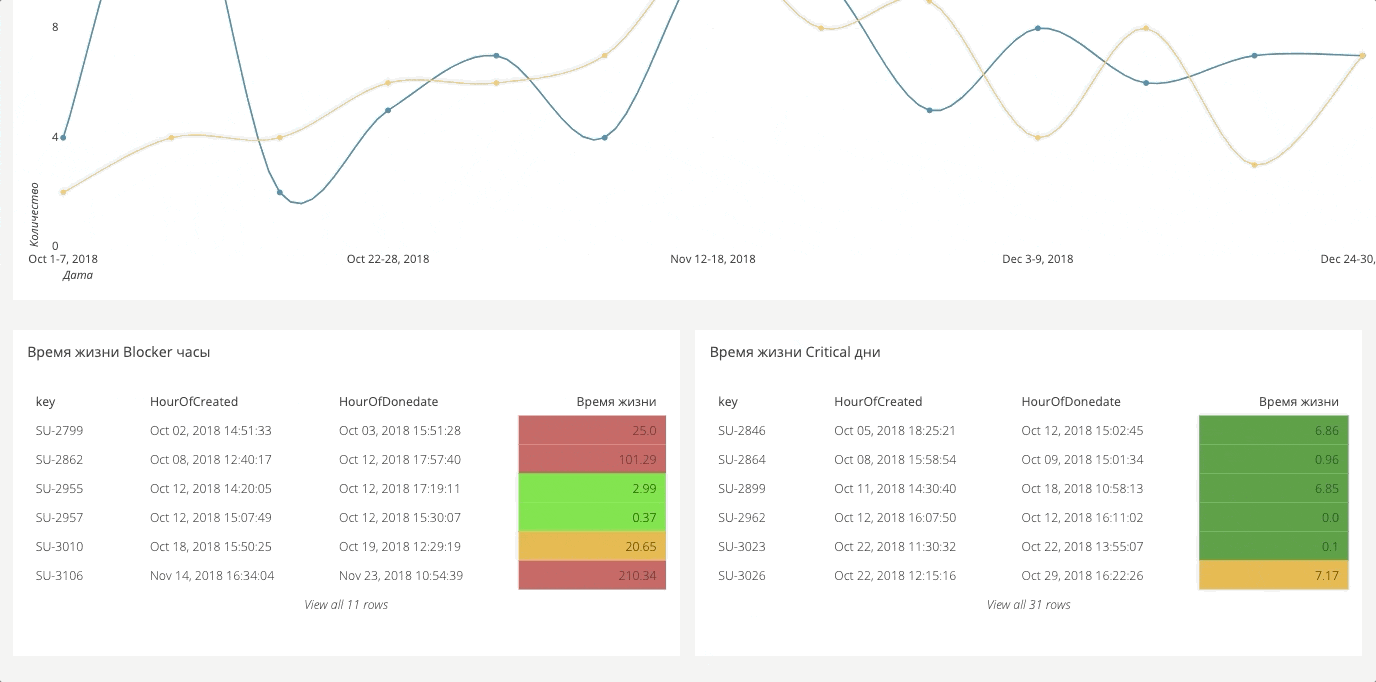
Les données du tableau de bord sont collectées généralement de partout. Il s'avère qu'un grand canevas à partir duquel vous pouvez générer les rapports nécessaires. Voici quelques exemples.
Répartition des bogues de criticité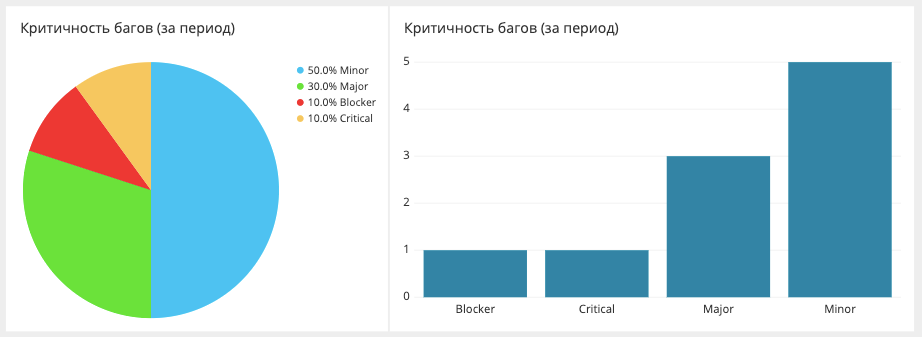
Ici, nous mesurons et affichons le nombre de bogues pour une certaine période et leur importance. Les données sont extraites de Jira. Jira elle-même, probablement, peut construire un tel rapport, mais pas sous une forme très pratique.
Répartition des bogues par champs propresDans Jira, vous pouvez emballer tous les champs personnalisés, et ces champs peuvent être des analyses, qui sont également chargées dans le système général. Par exemple, voici les bogues des composants.
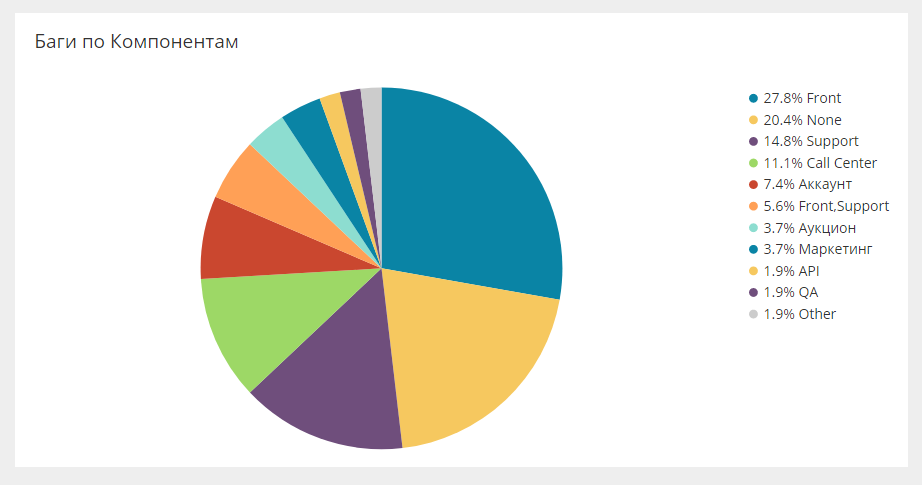
Il en va de même pour les équipes, les personnes, les directions. Cela vous permet de regarder une variété de tranches.
Le ratio de bogues nouveaux et fermésSi nous créons 20 bugs et n'en fermons que 5, alors à un moment donné, nous nous y vautrerons. Par conséquent, vous devez suivre les chiffres et vous efforcer que le rapport soit égal à 1.
 Tendance des bugs pour la période
Tendance des bugs pour la périodeLe système pratique que nous avons introduit est que nous avons téléchargé toutes les données historiques et que nous pouvons voir la dynamique.

À Jira, c'est un peu compliqué. Tout fonctionne automatiquement pour nous, et vous pouvez choisir n'importe quelle période et voir si vous avez réussi à améliorer quelque chose, et si les processus et les idées introduits ont fonctionné.
Étapes de la recherche de boguesSi auparavant nous ne mesurions que les bogues dans la bataille, nous nous efforçons maintenant de nous assurer qu'il n'y a pas de bogues dans la bataille et nous construisons des tranches à différents stades: bataille, publication, test, automatisation, révision, exigences.
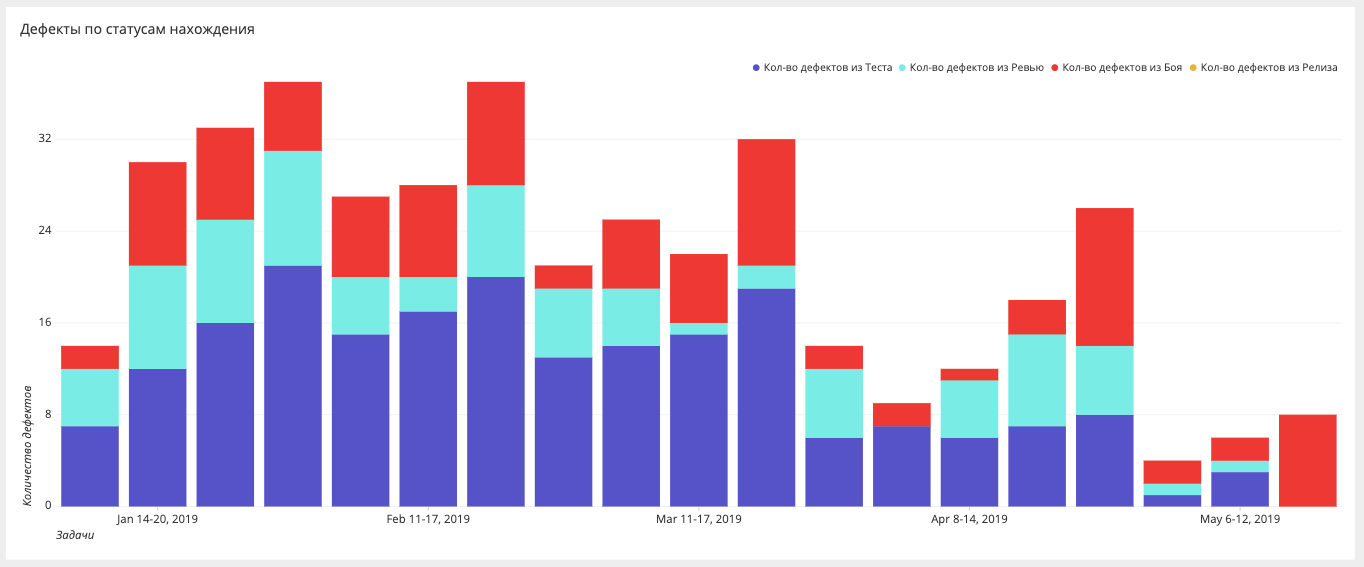 Tableau de bord d'automatisation
Tableau de bord d'automatisationPour les tests automatiques, il existe également un tableau de bord. Il est très grand, donc ci-dessous se trouvent deux fragments séparés.

Il affiche le nombre de bogues manqués. Si vous avez une couverture de 90%, mais que la moitié des bogues sont simplement commentés ou ignorés, cela est très critique, car en réalité, seulement 50% des fonctionnalités fonctionnent correctement.
Même chose avec les échecs: combien de tests plantent. Nous distinguons généralement différentes causes de plantage: plantage du système, plantage de bogue, les fonctionnalités ont changé. Séparément, nous partageons des plantages qui dépendaient du système et de l'environnement, et qui étaient purement basés sur des tests. Le premier est le travail de l'équipe d'exploitation, le second est l'automatisation.
Nous examinons également la couverture de l'automatisation. Nous prenons toutes les suites de TestRial, et nous pouvons également plonger dans les blocs de fonctionnalités et déterminer, par exemple, que la recherche est couverte à 30%.

De plus, les données sur la réduction de statut sont reflétées ici:
- Nouvelle - nouvelle fonctionnalité.
- Besoin de correction - vous devez mettre à jour le boîtier.
- Pas besoin - je ne veux pas couvrir l'automatisation.
- Terminé - Couvert.
La criticité a également sa propre coupe.
Performances du tableau de bordNous construisons ce tableau de bord dans Grafana, et nous chargeons les métriques séparément par API, frontend, backend et côté serveur. Il y a un bloc qui montre la tranche actuelle de la dernière version. En conséquence, vous pouvez entrer dans chacune des métriques et voir la dynamique.

Tout se chevauche avec différentes fonctionnalités, différentes pages du site.
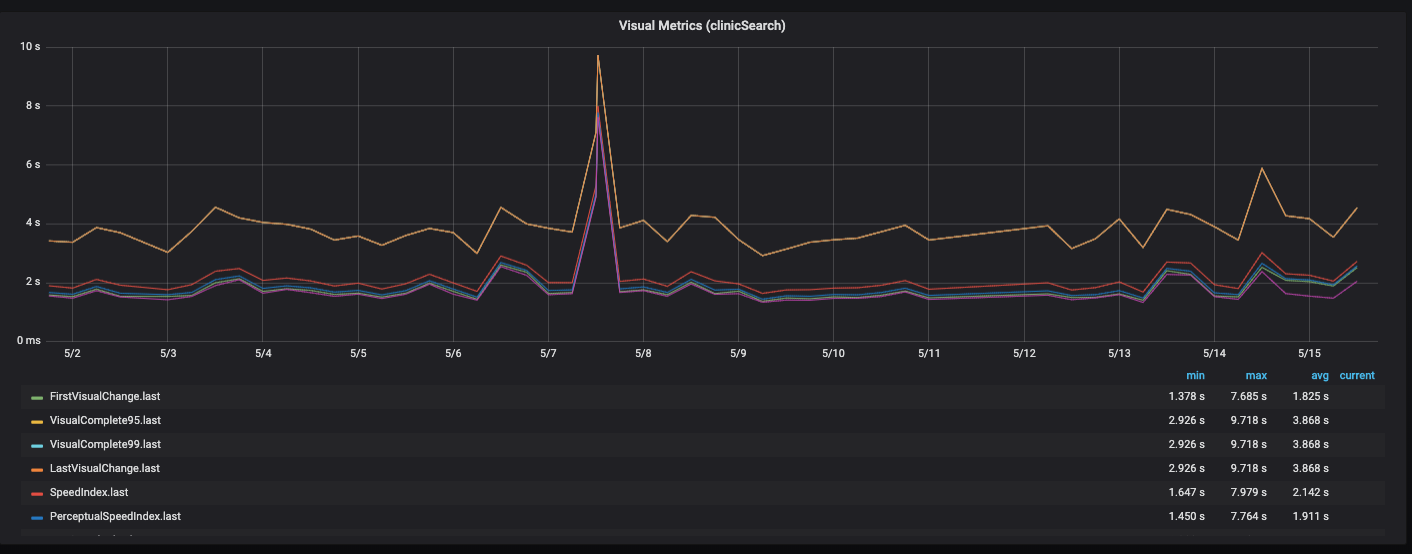
Envolez-vous
Il semble que maintenant tout va bien: il se rassemble et en un seul endroit, un tas de métriques. Vous pouvez continuer en toute sécurité.
Mais il y a de nouveaux problèmes en cours de route. Il y a trop de graphiques, et donc ils sont moins souvent regardés. Lorsqu'il y a 5 horaires, ils sont faciles à vérifier tous les jours. Avec une augmentation de leur nombre, un régime d'une fois par semaine est obtenu - également bon. Et puis soudain, il y a 3 jours, il y a eu un fakap, que personne n'a remarqué. Par conséquent, la réaction devient longue et les métriques et tableaux de bord parviennent à devenir obsolètes. Il y a plusieurs raisons à cela, qui doivent également pouvoir se battre.
Nous devons faire
des graphiques agrégés : sur 10, nous en faisons un qui montrera l'état de ces 10. De plus, nous remontons les principaux indicateurs. Vous ouvrez le tableau de bord et voyez immédiatement les valeurs souhaitées, puis tout le reste, qui révèle les métriques plus en détail.
Nous partageons: les mesures commerciales, les mesures de processus, les mesures d'AQ (Web / Mobile, Manuel / Automatisation, Performance).
Voici à quoi ressemble le graphique agrégé (NPS, CSAT).
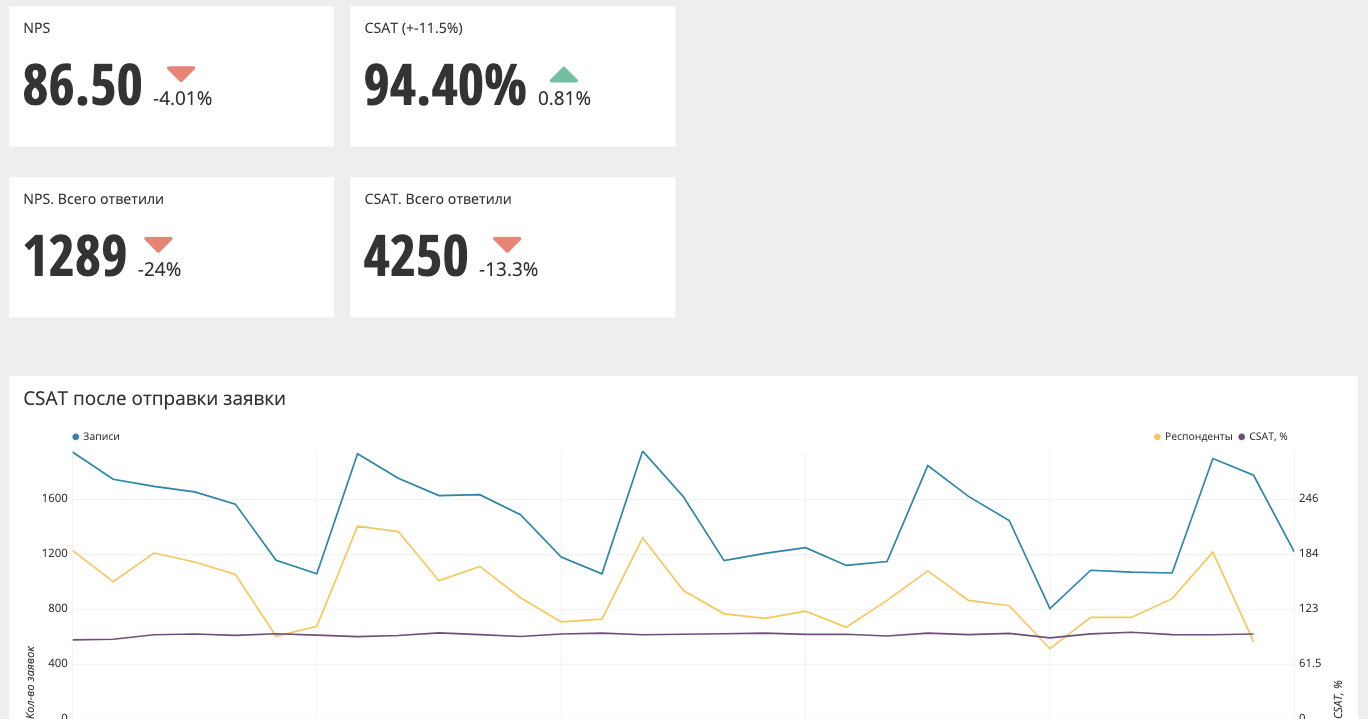
En haut se trouvent les valeurs et le delta par rapport à la période précédente. Dans ce cas, si la flèche est rouge, alors vous devez faire quelque chose, regardez au moins les graphiques plus en détail. Si la flèche est verte, alors tout va bien et vous ne pouvez pas réagir.
De plus, les graphiques ont la
possibilité de tomber à un niveau inférieur , sans aller nulle part.

Les bugs sont liés aux personnes qui les ont autorisés (testeurs ou développeurs). Si vous cliquez séparément sur un testeur, une table distincte s’ouvrira dessus - une tranche pour les tâches.
L'étape suivante consiste à résoudre le problème que les graphiques sont rarement contrôlés. À savoir, nous allons étendre le schéma de travail avec les données et les métriques: ajouter des notifications aux métriques nécessaires.
Alertes
Nous utilisons beaucoup d'alertes. Je vais donner des exemples de catégories et de situations spécifiques:
- Performances
- Tests automatiques. Par exemple, si le pourcentage de bogues manqués est trop élevé ou si trop de nouvelles fonctionnalités ne sont pas couvertes par les tests.
- Bogues entrants. Dans notre entreprise, tout le monde peut avoir un bug dans le système de ticket. Auparavant, cela était accompagné d'un message en PM, et maintenant il y a un canal pour les notifications de nouveaux bugs, de plus, les bugs sont automatiquement assignés à l'exécuteur tour à tour. La personne désignée doit analyser le bug, sinon le bot le lui rappellera toutes les 15 minutes.
- Vitesse de test / test en attente. S'il est clair qu'une personne s'est enterrée dans une tâche - cela n'a pas d'importance, il l'a encodée, a fait un examen, l'a testée - une alerte devrait apparaître: "Vous effectuez déjà trois tâches, peut-être avez-vous enterré, demandez de l'aide."
- Défauts sur la tâche / l'équipe.
- Examen des cas de test. Il s'agit simplement d'une automatisation du processus, afin de ne pas le faire à la main.
Exemples d'alerte
Pour les tâches qui brûlent, le bot écrit le numéro de tâche, l'état, la priorité, la durée de la tâche et la personne qui la teste.

Une notification, rédigée sous forme de résumé, parvient à une personne qui examine ses problèmes. Voici un exemple d'alertes pour le scénario de test envoyé par TestRial.

Il indique quels cas sont attribués à qui, avec quel statut et qui doit être surveillé.
Un autre exemple est le robot Yabeda, qui surveille les processus.

Cela était nécessaire pour configurer le processus de liaison du bogue et de la tâche. Le développeur, en analysant le bogue, doit trouver la tâche dans laquelle nous avons manqué ce bogue, pour une analyse plus approfondie, pour savoir pourquoi nous avons manqué le bogue. C'est une sorte d'analyse de l'incident, mais avec du retard.
De combien d'alertes avez-vous besoin et à quelle fréquence?
S'il y aura beaucoup d'alertes, alors il y aura beaucoup de stress de leur part. Par conséquent, nous avons mis en place des règles de gestion des alertes pour nous-mêmes.
— . 500 , .
— . , , , - .
— . , : , , , . , , , .
: , . , , - , . ,
:
- — , .
- — , , . , , . .
- — , , , , .
,
:- — , , .
- / . , , .
- . , .
- . , . , . , , .
. , . . , , , , . , , : , .
, :
, , . . -, , , , , 15 , . -, , . . -, . , , , , , .
Online
. , . , . , .

QA
, QA .
: , , .
: , , .
:

— , X ( ), () (). , - , ( ) : , . , . , , . , , .
: — , , ( , , ).
: « ». , , , , . - . .
, , . , , . .
-
: , , . , .
: , , , .
, 10 , 500, . , .
. , , .

,
, , . , , . «5 », .
, , , .
Résumé
— , . , . , . , , , — , .
:. , , , . .
— . , . , , - .
. , .
:- ~ 50 QA 100 .
- ~ 30 .
- — , .
- .
- .
- QA must have.
Notre conférence, qui combine tous les aspects du développement de produits de haute qualité, renaîtra l'année prochaine, quittera RIT ++ et deviendra un événement indépendant à grande échelle TechLead Conf. Nous annoncerons bientôt la date et le lieu sur le canal des télégrammes , mais si vous avez vu de votre propre expérience que le processus de développement n'est pas un ensemble de briques non connectées et que vous souhaitez partager des solutions pour les processus d'ingénierie de construction, demandez un rapport sans attendre d'annonces.