Parfois, il peut être nécessaire de profiler les performances du programme ou la consommation de mémoire dans un programme C ++. Malheureusement, ce n'est souvent pas aussi simple qu'il y paraît.
Nous examinerons ici les caractéristiques des programmes de profilage à l'aide des
outils valgrind et
google perftools . Le matériel s'est avéré peu structuré, il s'agit plutôt d'une tentative de constitution d'une base de connaissances «à des fins personnelles» afin qu'à l'avenir vous n'ayez pas à vous souvenir frénétiquement «pourquoi cela ne fonctionne pas» ou «comment le faire». Très probablement, tous les cas non évidents ne seront pas affectés ici, si vous avez quelque chose à ajouter, veuillez écrire dans les commentaires.
Tous les exemples s'exécuteront sur le système Linux.
Profilage d'exécution
La préparation
Pour analyser les caractéristiques du profilage, je vais exécuter de petits programmes, généralement constitués d'un fichier main.cpp et d'un fichier func.cpp avec l'inclusion.
Je vais les compiler avec le
compilateur g ++ 8.3.0 .
Étant donné que le profilage de programmes non optimisés est une tâche plutôt étrange, nous compilerons avec l'option
-Ofast , et afin d'obtenir des caractères de débogage dans la sortie, nous n'oublierons pas d'ajouter l'option
-g . Cependant, parfois au lieu des noms de fonction normaux, vous ne pouvez voir que les adresses d'appel inaudibles. Cela signifie qu'il y a eu une "randomisation de l'allocation de l'espace d'adressage". Cela peut être déterminé en appelant la commande
nm sur le binaire. Si la plupart des adresses ressemblent à quelque chose comme ceci 00000000000030e0 (un grand nombre de zéros au début), c'est très probablement le cas. Dans un programme normal, les adresses ressemblent à 0000000000402fa0. Par conséquent, vous devez ajouter l'option
-no-pie . Par conséquent, l'ensemble complet des options ressemblera à ceci:
-Ofast -g -no-piePour afficher les résultats, nous utiliserons le programme
KCachegrind , qui peut fonctionner avec le
format de rapport
callgrindCallgrind
Le premier utilitaire que nous examinerons aujourd'hui est le
callgrind . Cet utilitaire fait partie de l'outil valgrind. Il émule chaque instruction exécutable du programme et, sur la base de mesures internes sur le «coût» de chaque instruction, émet la conclusion dont nous avons besoin. En raison de cette approche, il arrive parfois que callgrind ne puisse pas reconnaître l'instruction suivante et tombe avec une erreur
Instruction non reconnue à l'adresseLe seul moyen de sortir de cette situation est de reconsidérer toutes les options de compilation et d'essayer de trouver l'interférence
Créons un programme pour tester cet outil, composé d'une bibliothèque partagée et d'une bibliothèque statique (nous abandonnerons les bibliothèques dans d'autres tests plus tard). Chaque bibliothèque, ainsi que le programme lui-même, fournira une fonction de calcul simple, par exemple, le calcul de la séquence de Fibonacci.
Nous compilons le programme et exécutons valgrind comme suit:
valgrind --tool=callgrind ./test_profiler 100000000
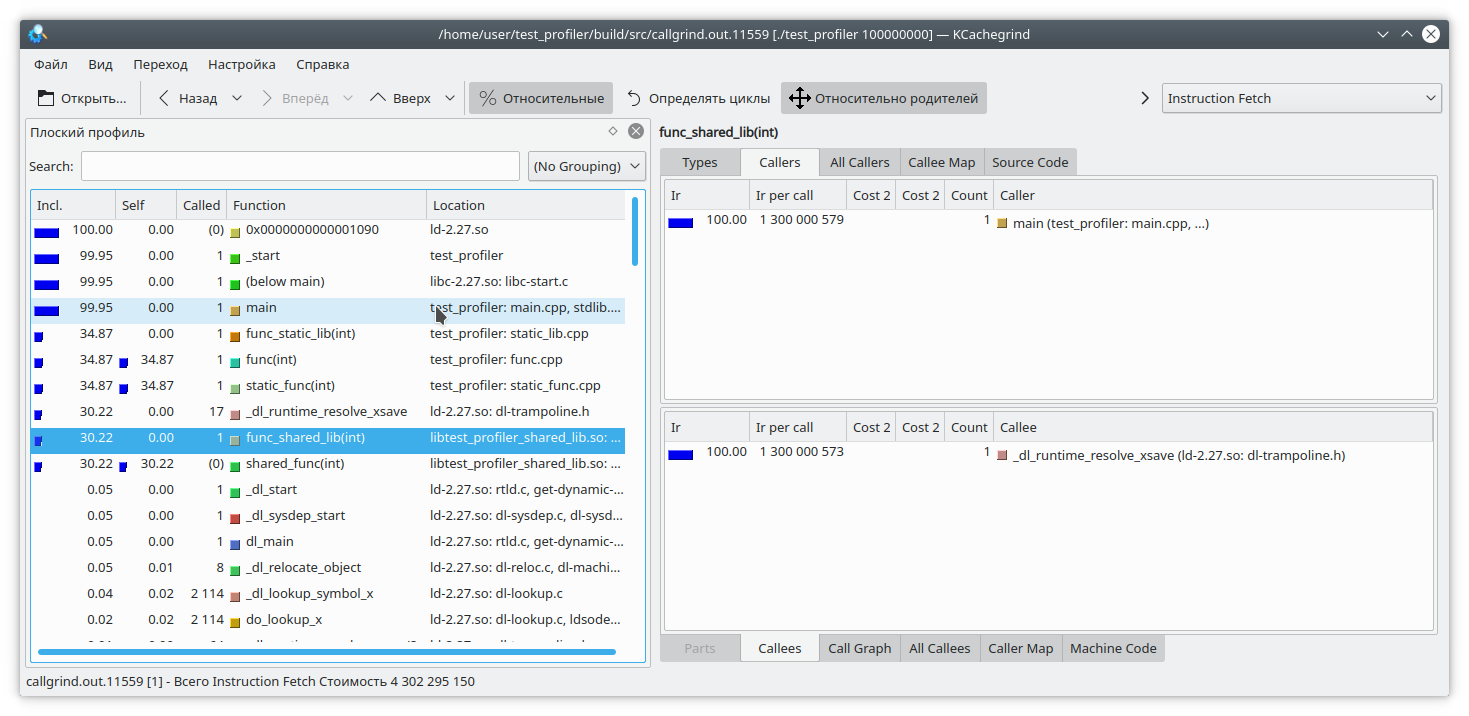
Nous voyons que pour une bibliothèque statique et une fonction régulière, le résultat est similaire à celui attendu. Mais dans la bibliothèque dynamique, callgrind n'a pas pu résoudre complètement la fonction.
Pour résoudre ce problème, lors du démarrage du programme, vous devez définir la variable
LD_BIND_NOW sur 1, comme ceci:
LD_BIND_NOW=1 valgrind --tool=callgrind ./test_profiler 100000000
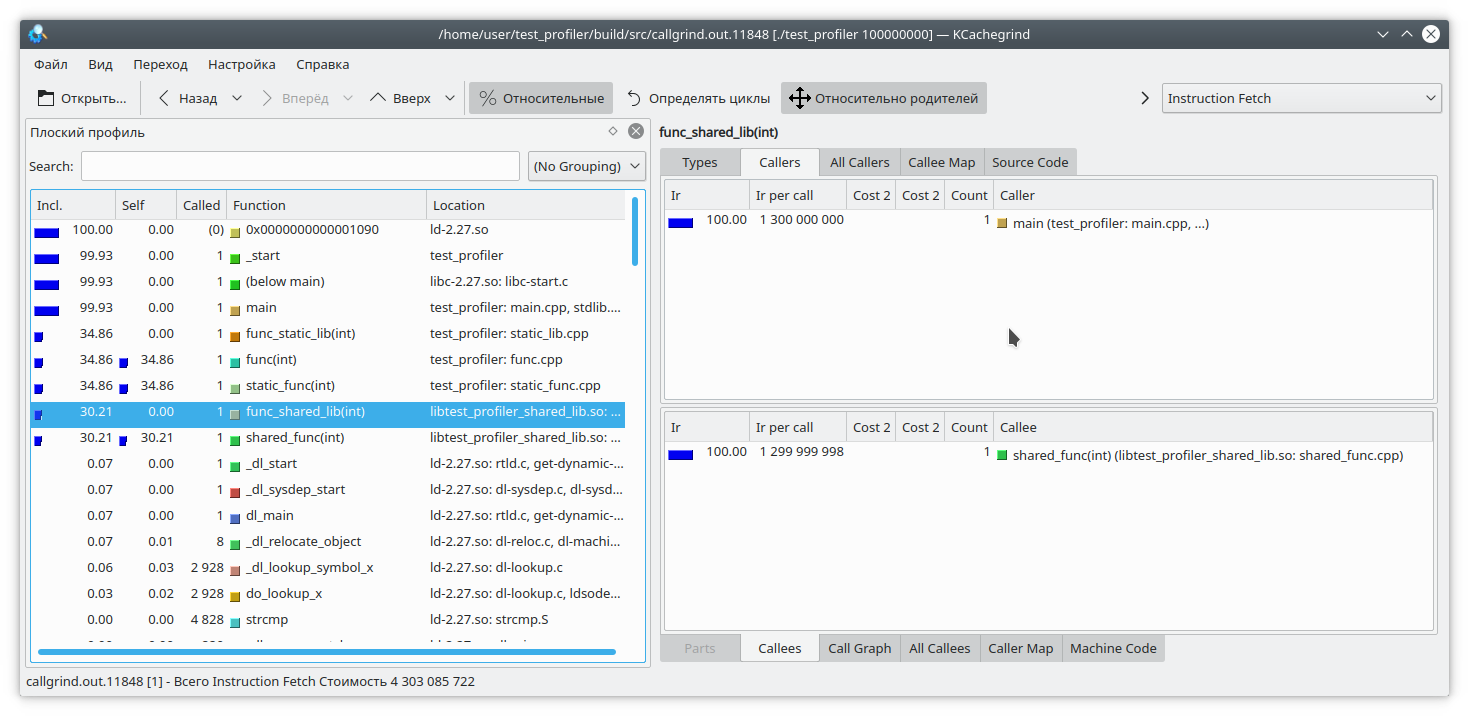
Et maintenant, comme vous pouvez le voir, tout va bien
Le prochain problème de callgrind résultant du profilage en émulant des instructions est que l'exécution du programme ralentit beaucoup. Cela peut entraîner une estimation relative incorrecte du temps d'exécution de différentes parties du code.
Regardons ce code:
int func(int arg) { int fst = 1; int snd = 1; std::ofstream file("tmp.txt"); for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; std::string r = std::to_string(res); file << res; file.flush(); fst = snd; snd = res + r.size(); } return fst; }
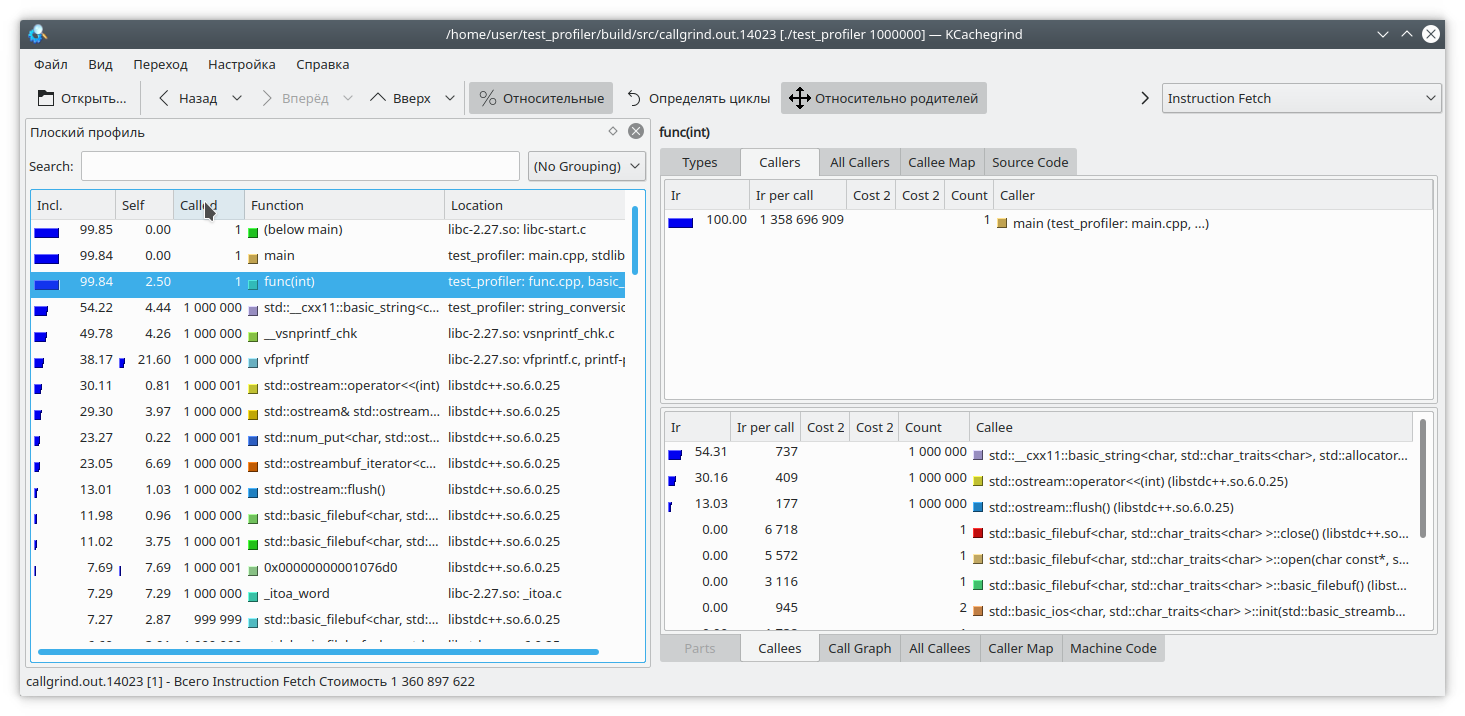
Ici, j'ai ajouté une petite quantité de données à un fichier pour chaque itération de la boucle. Comme l'écriture dans un fichier est une opération assez longue, en contrepoids, j'ai ajouté une génération de ligne à partir d'un nombre à chaque itération de la boucle. Évidemment, dans ce cas, l'opération d'écriture dans le fichier prend plus de temps que le reste de la logique de la fonction. Mais callgrind pense différemment:
Il convient également de considérer que le callgrind ne peut mesurer le coût d'une fonction que lorsqu'elle fonctionne. La fonction ne fonctionne pas - par conséquent, le coût n'augmente pas. Cela complique le débogage de programmes qui, de temps en temps, entrent dans la serrure ou fonctionnent avec un système de fichiers / réseau bloquant. Vérifions:
#include "func.h" #include <mutex> static std::mutex mutex; int funcImpl(int arg) { std::lock_guard<std::mutex> lock(mutex); int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; } return fst; } int func2(int arg){ return funcImpl(arg); } int func(int arg) { return funcImpl(arg); } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); auto future = std::async(std::launch::async, &func2, arg); std::cout << "result: " << func(arg) << std::endl; std::cout << "second result " << future.get() << std::endl; return 0; }
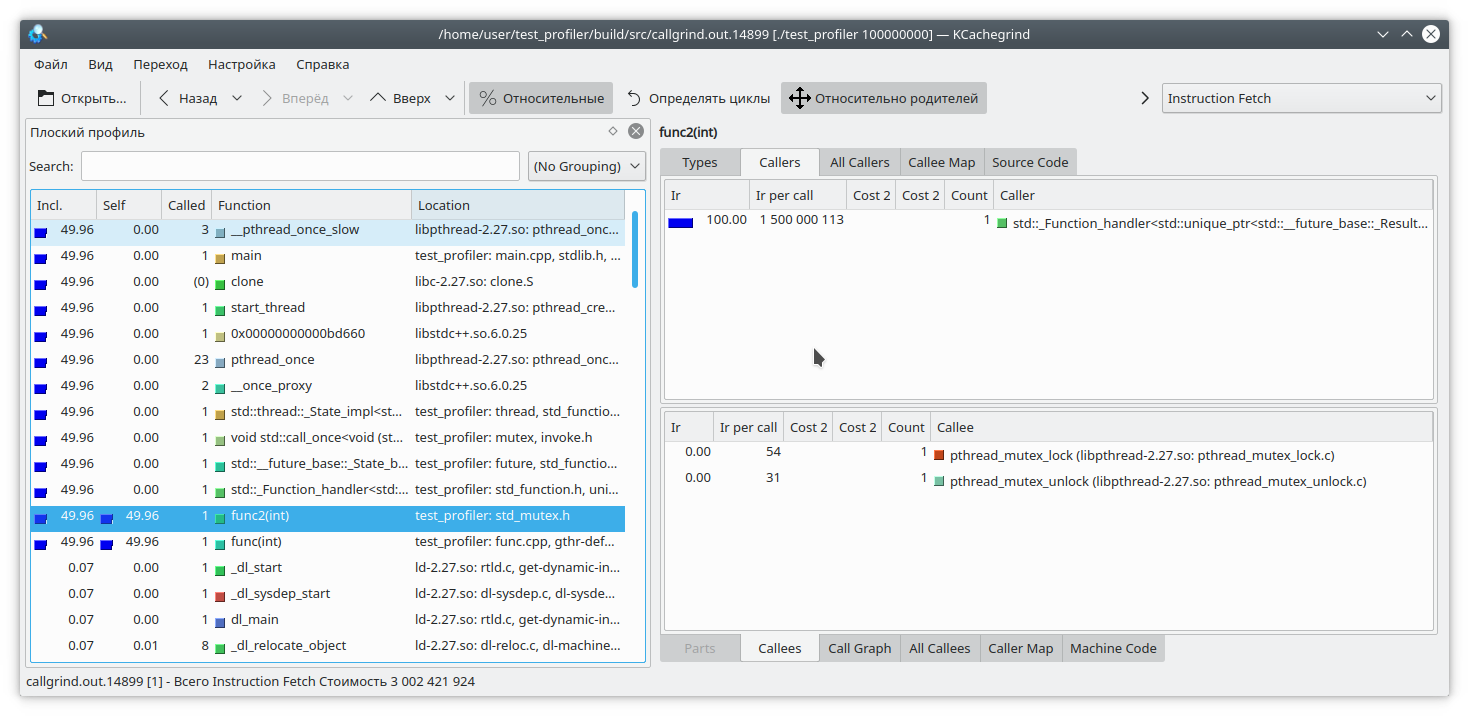
Ici, nous avons inclus l'exécution entière de la fonction dans le verrou du mutex, et appelé cette fonction à partir de deux threads différents. Le résultat du callgrind est assez prévisible - il ne voit pas de problème dans la capture mutex:
Nous avons donc examiné certains des problèmes liés à l'utilisation du profileur de callgrind. Passons au sujet de test suivant - le profileur google perftools
google perftools
Contrairement à Callgrind, Google Profiler fonctionne sur un principe différent.
Au lieu d'analyser chaque instruction du programme exécutable, il interrompt le programme à intervalles réguliers et essaie de déterminer dans quelle fonction il se trouve actuellement. Par conséquent, cela n'affecte presque pas les performances de l'application en cours d'exécution. Mais cette approche a aussi ses faiblesses.
Commençons par profiler le premier programme avec deux bibliothèques.
En règle générale, pour démarrer le profilage avec cet utilitaire, vous devez précharger la bibliothèque libprofiler.so, définir la fréquence d'échantillonnage et spécifier le fichier pour enregistrer le vidage. Malheureusement, le profileur exige que le programme se termine «tout seul». L'arrêt forcé du programme empêchera simplement le rapport de faire l'objet d'un dumping. Cela n'est pas pratique lors du profilage de programmes à longue durée de vie qui ne s'arrêtent pas, tels que les démons. Pour contourner cet obstacle, j'ai créé ce script:
gprof.sh rnd=$RANDOM if [ $# -eq 0 ] then echo "./gprof.sh command args" echo "Run with variable N_STOP=true if hand stop required" exit fi libprofiler=$( dirname "${BASH_SOURCE[0]}" ) arg=$1 nostop=$N_STOP profileName=callgrind.out.$rnd.g gperftoolProfile=./gperftool."$rnd".txt touch $profileName echo "Profile name $profileName" if [[ $nostop = "true" ]] then echo "without stop" trap 'echo trap && kill -12 $PID && sleep 1 && kill -TERM $PID' TERM INT else trap 'echo trap && kill -TERM $PID' TERM INT fi if [[ $nostop = "true" ]] then CPUPROFILESIGNAL=12 CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & else CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & fi PID=$! if [[ $nostop = "true" ]] then sleep 1 kill -12 $PID fi wait $PID trap - TERM INT wait $PID EXIT_STATUS=$? echo $PWD ${libprofiler}/pprof --callgrind $arg $gperftoolProfile* > $profileName echo "Profile name $profileName" rm -f $gperftoolProfile*
Cet utilitaire doit être exécuté, en passant comme paramètres le nom du fichier exécutable et une liste de ses paramètres. En outre, il est supposé qu'à côté du script se trouvent les fichiers nécessaires libprofiler.so et pprof. Si le programme dure longtemps et s'arrête en interrompant l'exécution, vous devez définir la variable N_STOP sur true, par exemple, comme ceci:
N_STOP=true ./gprof.sh ./test_profiler 10000000000
À la fin du travail, le script générera un rapport dans mon format de callgrind préféré.
Alors, exécutons notre programme sous ce profileur.
./gprof.sh ./test_profiler 1000000000

En principe, tout est assez clair.
Comme je l'ai dit, le profileur Google fonctionne en arrêtant l'exécution du programme et en calculant la fonction actuelle. Comment fait-il ça? Il le fait en faisant tourner la pile. Mais que se passe-t-il si, au moment de la promotion de la pile, le programme lui-même déroulait la pile? Eh bien, évidemment, rien de bon ne se passera. Voyons ça. Écrivons une telle fonction:
int runExcept(int res) { if (res % 13 == 0) { throw std::string("Exception"); } return res; } int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; try { res = runExcept(res); } catch (const std::string &e) { res = res - 1; } fst = snd; snd = res; } return fst; }
Et exécutez le profilage. Le programme se fige assez rapidement.
Il existe un autre problème lié à la particularité de l'opération du profileur. Supposons que nous ayons réussi à dérouler la pile, et maintenant nous devons faire correspondre les adresses avec les fonctions spécifiques du programme. Cela peut être très simple, car en C ++ un assez grand nombre de fonctions sont en ligne. Regardons un exemple comme celui-ci:
#include "func.h" static int func1(int arg) { std::cout << 1 << std::endl; return func(arg); } static int func2(int arg) { std::cout << 2 << std::endl; return func(arg); } static int func3(int arg) { std::cout << 3 << std::endl; if (arg % 2 == 0) { return func2(arg); } else { return func1(arg); } } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); int arg2 = func3(arg); int arg3 = func(arg); std::cout << "result: " << arg2 + arg3; return 0; }
Évidemment, si vous exécutez le programme par exemple comme ceci:
./gprof.sh ./test_profiler 1000000000
alors la fonction func1 ne sera jamais appelée. Mais le profileur pense différemment:
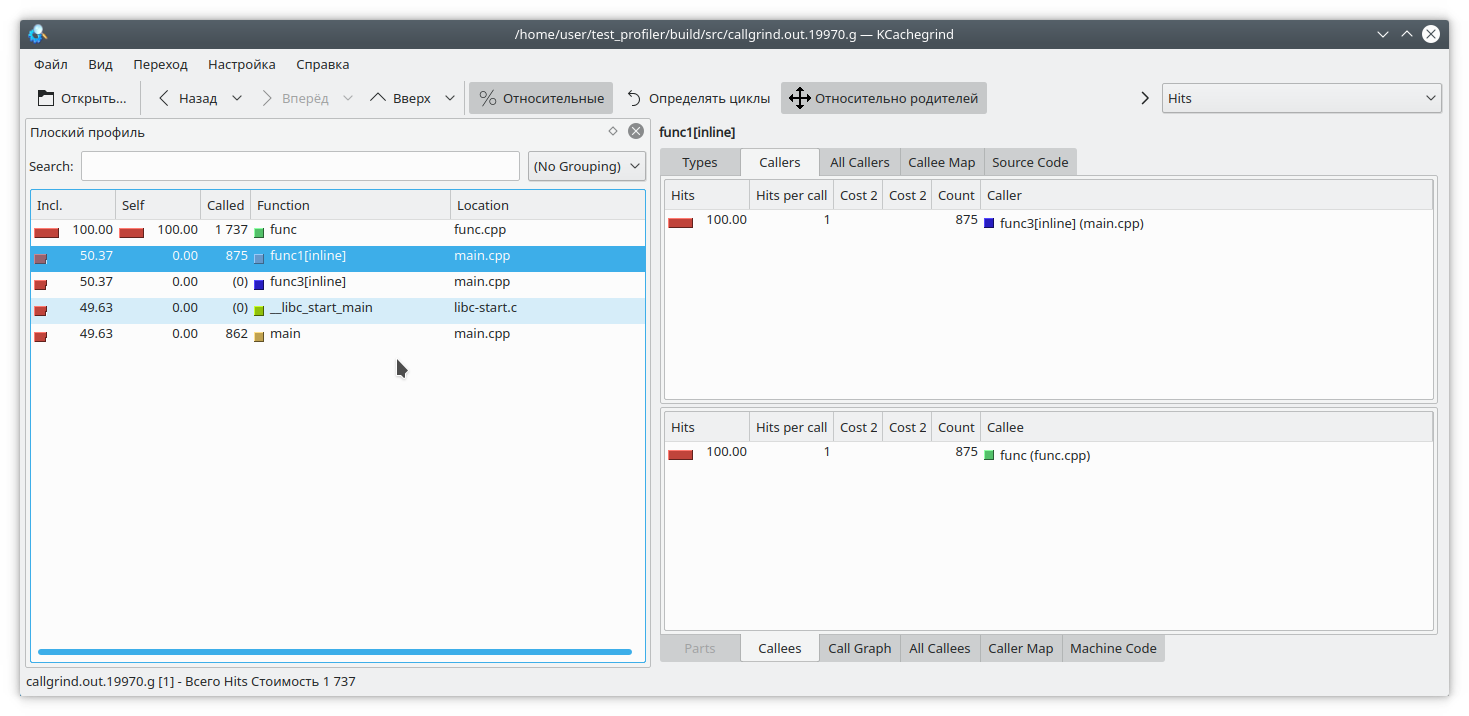
(Soit dit en passant, valgrind a décidé ici de garder le silence modestement et de ne pas spécifier de quelle fonction spécifique l'appel provenait).
Profilage de la mémoire
Il y a souvent des situations où la mémoire de l'application quelque part "coule". Si cela est dû à un manque de nettoyage des ressources, Memcheck devrait aider à identifier le problème. Mais dans le C ++ moderne, il n'est pas si difficile de se passer de la gestion manuelle des ressources. unique_ptr, shared_ptr, vector, map rendent la manipulation aux points nus inutile.
Néanmoins, dans de telles applications, la mémoire fuit. Comment ça se passe? Tout simplement, en règle générale, c'est quelque chose comme «mettre la valeur dans une carte longue durée, mais j'ai oublié de la supprimer». Essayons de suivre cette situation.
Pour ce faire, nous réécrivons notre fonction de test de cette façon
#include "func.h" #include <deque> #include <string> #include <map> static std::deque<std::string> deque; static std::map<int, std::string> map; int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; deque.emplace_back(std::to_string(res) + " integer"); map[i] = "integer " + std::to_string(res); deque.pop_front(); if (res % 200 != 0) { map.erase(i - 1); } } return fst; }
Ici, à chaque itération, nous ajoutons quelques éléments à la carte, et tout à fait par accident (vrai, vrai) nous oublions parfois de les supprimer de là. De plus, pour éviter nos yeux, nous torturons un peu std :: deque.
Nous allons
attraper les fuites de mémoire avec deux outils -
Valgrind massif et
google heapdump .
Massif
Exécutez le programme avec cette commande
valgrind --tool=massif ./test_profiler 1000000
Et nous voyons quelque chose comme
Massif time=1277949333 mem_heap_B=313518 mem_heap_extra_B=58266 mem_stacks_B=0 heap_tree=detailed n4: 313518 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 195696 0x109A69: func(int) (new_allocator.h:111) n0: 195696 0x10947A: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 42966 0x10A7EC: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (new_allocator.h:111) n1: 42966 0x10AAD9: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 42966 0x1099D4: func(int) (basic_string.h:1932) n0: 42966 0x10947A: main (main.cpp:18) n0: 0 in 2 places, all below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
On peut voir que le massif a pu détecter une fuite dans la fonction, mais on ne sait pas encore où. Reconstruisons le programme avec l'indicateur
-fno-inline et réexécutons l'analyse
massif time=3160199549 mem_heap_B=345142 mem_heap_extra_B=65986 mem_stacks_B=0 heap_tree=detailed n4: 345142 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 221616 0x10CDBC: std::_Rb_tree_node<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >* std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_create_node<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .isra.81] (stl_tree.h:653) n1: 221616 0x10CE0C: std::_Rb_tree_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_emplace_hint_unique<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::_Rb_tree_const_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .constprop.87] (stl_tree.h:2414) n1: 221616 0x10CF2B: std::map<int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::operator[](int const&) (stl_map.h:499) n1: 221616 0x10A7F5: func(int) (func.cpp:20) n0: 221616 0x109F8E: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 48670 0x10B866: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:317) n1: 48639 0x10BB2C: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 48639 0x10A643: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > std::operator+<char, std::char_traits<char>, std::allocator<char> >(char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&&) [clone .constprop.86] (basic_string.h:6018) n1: 48639 0x10A7E5: func(int) (func.cpp:20) n0: 48639 0x109F8E: main (main.cpp:18) n0: 31 in 1 place, below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
Maintenant, il est clair où se trouve la fuite lors de l'ajout de l'élément de carte. Massif peut détecter des objets éphémères, donc les manipulations avec std :: deque sont invisibles dans ce vidage.
Heapdump
Pour que Google heapdump fonctionne, vous devez lier ou précharger la bibliothèque
tcmalloc . Cette bibliothèque remplace les fonctions standard d'allocation de mémoire malloc, free, ... Elle peut également collecter des informations sur l'utilisation de ces fonctions, que nous utiliserons lors de l'analyse du programme.
Étant donné que cette méthode fonctionne très lentement (même par rapport au massif), je vous recommande de désactiver immédiatement la compilation des fonctions avec l'option
-fno-inline lors de la compilation. Donc, nous reconstruisons notre application et exécutons avec l'équipe
HEAPPROFILESIGNAL=23 HEAPPROFILE=./heap ./test_profiler 100000000
Ici, on suppose que la bibliothèque tcmalloc est liée à notre application.
Maintenant, nous attendons le temps nécessaire à la formation d'une fuite notable et envoyons à notre processus un signal 23
kill -23 <pid>
En conséquence, un fichier appelé heap.0001.heap apparaît, que nous convertissons au format callgrind avec la commande
pprof ./test_profiler "./heap.0001.heap" --inuse_space --callgrind > callgrind.out.4
Faites également attention aux options de pprof. Vous pouvez choisir parmi les options
inuse_space ,
inuse_objects ,
alloc_space ,
alloc_objects , qui montrent respectivement l'espace ou les objets utilisés ou l'espace et les objets alloués pour toute la durée du programme. Nous sommes intéressés par l'option inuse_space, qui montre l'espace mémoire actuellement utilisé.
Ouvrez notre kCacheGrind préféré et voyez
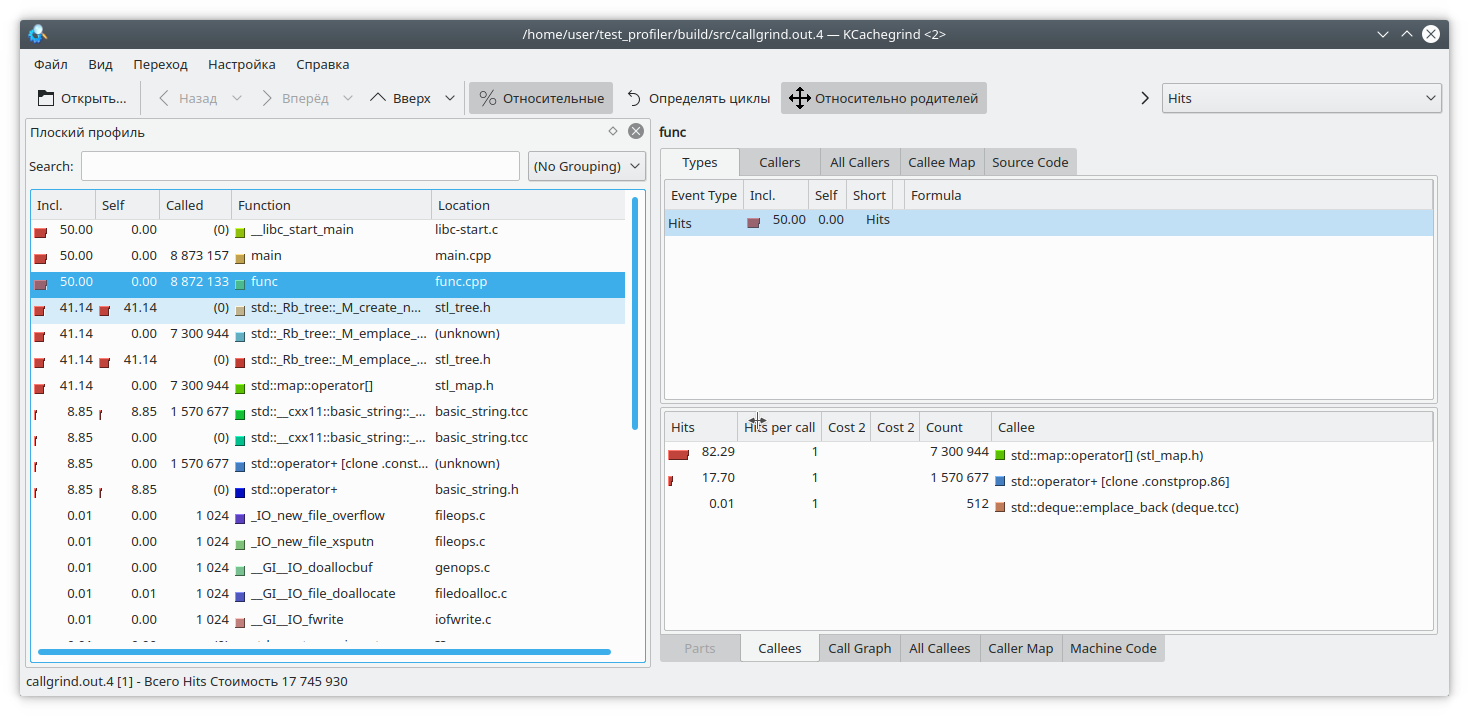
std :: map a consommé trop de mémoire. Probablement une fuite dedans.
Conclusions
Le profilage en C ++ est une tâche très difficile. Ici, nous devons traiter des fonctions intégrées, des instructions non prises en charge, des résultats incorrects, etc. Il n'est pas toujours possible de faire confiance aux résultats du profileur.
En plus des fonctions proposées ci-dessus, il existe d'autres outils conçus pour le profilage - perf, intel VTune et autres. Mais ils montrent également certaines de ces lacunes. Par conséquent, n'oubliez pas la méthode de profilage «grand-père» en mesurant le temps d'exécution des fonctions et en l'affichant dans le journal.
De plus, si vous avez des techniques intéressantes pour profiler votre code, veuillez les poster dans les commentaires