
Avant de nouveau, la tâche de détecter des objets. Priorité - vitesse avec une précision acceptable. Vous prenez l'architecture de YOLOv3 et la formez. La précision (mAp75) est supérieure à 0,95. Mais la vitesse de course est encore faible. L'enfer
Aujourd'hui, nous contournerons la quantification. Et sous la coupe, pensez à l' élagage du modèle - couper les parties de réseau redondantes pour accélérer l'inférence sans perdre en précision. Visuellement - où, combien et comment couper. Voyons comment le faire manuellement et où vous pouvez automatiser. À la fin se trouve un référentiel sur les keras.
Présentation
Au dernier lieu de travail, Perm Macroscop, j'ai eu une habitude - toujours de surveiller le temps d'exécution des algorithmes. Et la durée d'exécution du réseau doit toujours être vérifiée via le filtre d'adéquation. Habituellement, l'état de l'art dans la prod ne passe pas ce filtre, ce qui m'a conduit à l'élagage.
L'élagage est un thème ancien qui a été abordé dans les conférences de Stanford en 2017. L'idée principale est de réduire la taille du réseau formé sans perdre en précision en supprimant divers nœuds. Ça a l'air cool, mais j'entends rarement parler de son utilisation. Probablement, il n'y a pas assez d'implémentations, il n'y a pas d'articles en russe, ou tout le monde considère que l'élagage du savoir-faire est silencieux.
Mais va démonter
Un regard sur la biologie
J'aime quand dans le Deep Learning les idées viennent de la biologie. On peut leur faire confiance, comme l'évolution (saviez-vous que ReLU est très similaire à la fonction d'activation des neurones dans le cerveau ?)
Le processus d'élagage du modèle est également proche de la biologie. La réponse du réseau ici peut être comparée à la plasticité du cerveau. Quelques exemples intéressants se trouvent dans le livre de Norman Dodge :
- Le cerveau d'une femme qui n'avait qu'une moitié de naissance s'est reprogrammée pour remplir les fonctions de la moitié manquante
- Le gars s'est tiré une balle dans la partie du cerveau responsable de la vision. Au fil du temps, d'autres parties du cerveau ont repris ces fonctions. (ne réessayez pas)
Ainsi, à partir de votre modèle, vous pouvez supprimer certains des paquets faibles. Dans les cas extrêmes, les faisceaux restants aideront à remplacer ceux coupés.
Aimez-vous le transfert d'apprentissage ou apprenez à partir de zéro?
Option numéro un. Vous utilisez Transfer Learning sur Yolov3. Retina, Mask-RCNN ou U-Net. Mais le plus souvent, nous n'avons pas besoin de reconnaître 80 classes d'objets, comme dans COCO. Dans ma pratique, tout est limité à 1-2 classes. On peut supposer que l'architecture pour 80 classes est redondante ici. Cela laisse penser que l'architecture doit être réduite. De plus, je voudrais le faire sans perdre les poids pré-formés existants.
Option numéro deux. Peut-être que vous avez beaucoup de données et de ressources informatiques, ou que vous avez juste besoin d'une architecture super-personnalisée. Peu importe. Mais vous apprenez le réseau à partir de zéro. L'ordre habituel consiste à examiner la structure des données, à sélectionner une architecture dont la puissance est RÉDUITE et à empêcher les abandons de se recycler. J'ai vu des décrocheurs 0,6, Carl.
Dans les deux cas, le réseau peut être réduit. Promu. Voyons maintenant quel genre de circoncision élagage
Algorithme général
Nous avons décidé de supprimer la convolution. Cela semble très simple:
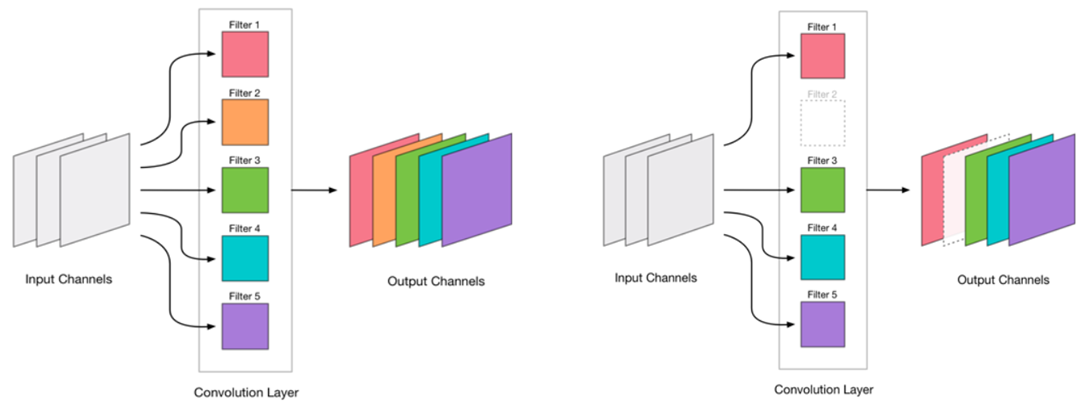
La suppression de toute convolution est une contrainte pour le réseau, ce qui entraîne généralement une augmentation des erreurs. D'une part, cette croissance d'erreur est un indicateur de la façon dont nous supprimons correctement les convolutions (par exemple, une croissance importante indique que nous faisons quelque chose de mal). Mais une petite croissance est tout à fait acceptable et est souvent éliminée par un entraînement ultérieur facile et ultérieur avec un petit LR. Nous ajoutons une étape de recyclage:
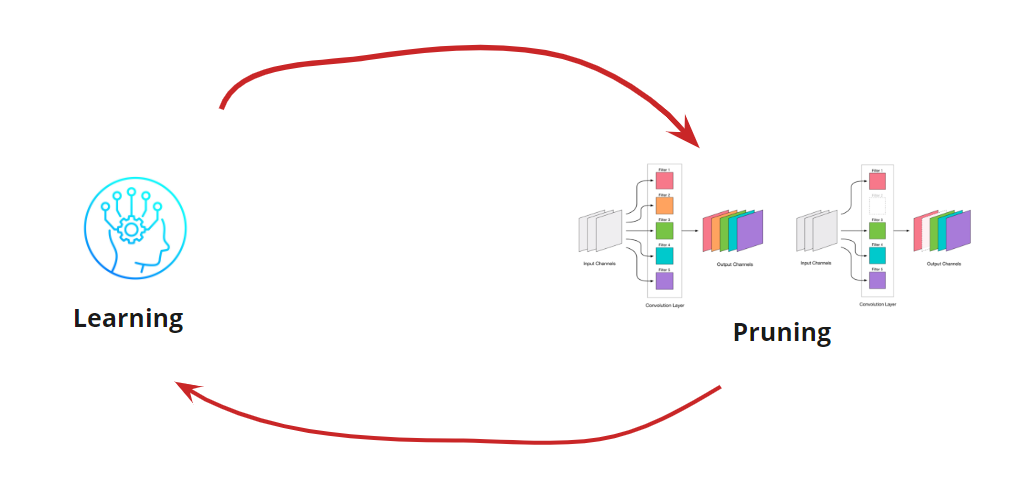
Maintenant, nous devons comprendre quand nous voulons arrêter notre cycle d'apprentissage <-> Élagage. Il peut y avoir des options exotiques lorsque nous devons réduire le réseau à une certaine taille et vitesse d'exécution (par exemple, pour les appareils mobiles). Cependant, l'option la plus courante consiste à poursuivre le cycle jusqu'à ce que l'erreur devienne supérieure à celle autorisée. Ajouter une condition:
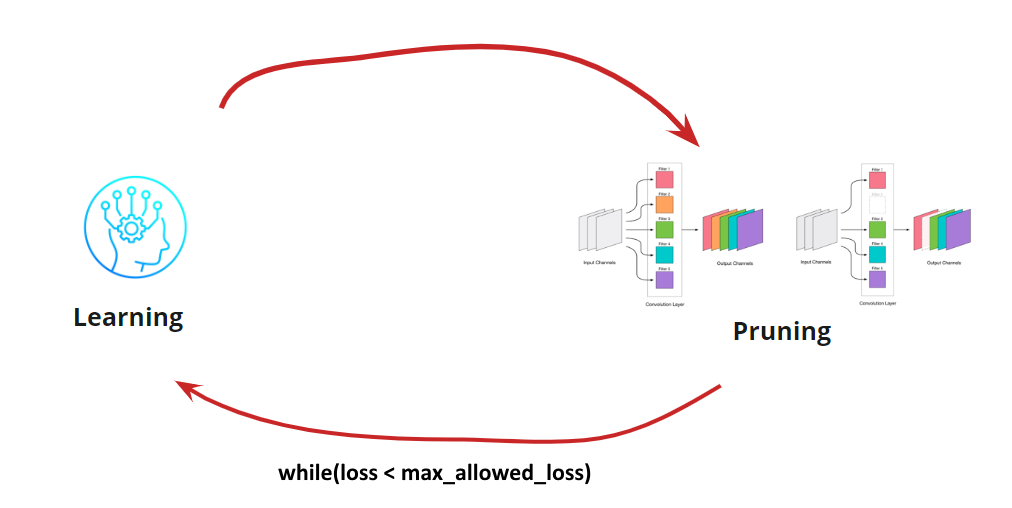
Ainsi, l'algorithme devient clair. Reste à savoir comment déterminer les circonvolutions supprimées.
Rechercher la convolution à supprimer
Nous devons supprimer certaines circonvolutions. Arracher et «tirer» sur n'importe quelle est une mauvaise idée, même si cela fonctionnera. Mais si vous avez une tête, vous pouvez penser et essayer de sélectionner des convolutions «faibles» pour l'enlèvement. Il existe plusieurs options:
- La plus petite mesure L1 ou élagage à faible amplitude . L'idée que les convolutions de petits poids contribuent peu à la décision finale
- La plus petite mesure L1 tenant compte de la moyenne et de l'écart-type. Nous complétons l'appréciation de la nature de la distribution.
- Masquer les circonvolutions et éliminer le moins possible la précision résultante . Une définition plus précise des convolutions insignifiantes, mais très chronophage et gourmande en ressources.
- Autre
Chacune des options a droit à la vie et possède ses propres fonctionnalités de mise en œuvre. Ici, nous considérons la variante avec la plus petite mesure L1
Processus manuel pour YOLOv3
L'architecture d'origine contient des blocs résiduels. Mais peu importe à quel point ils sont cool pour les réseaux profonds, ils nous gêneront quelque peu. La difficulté est que vous ne pouvez pas supprimer les rapprochements avec différents indices dans ces couches:

Par conséquent, nous sélectionnons les couches dont nous pouvons supprimer librement les rapprochements:
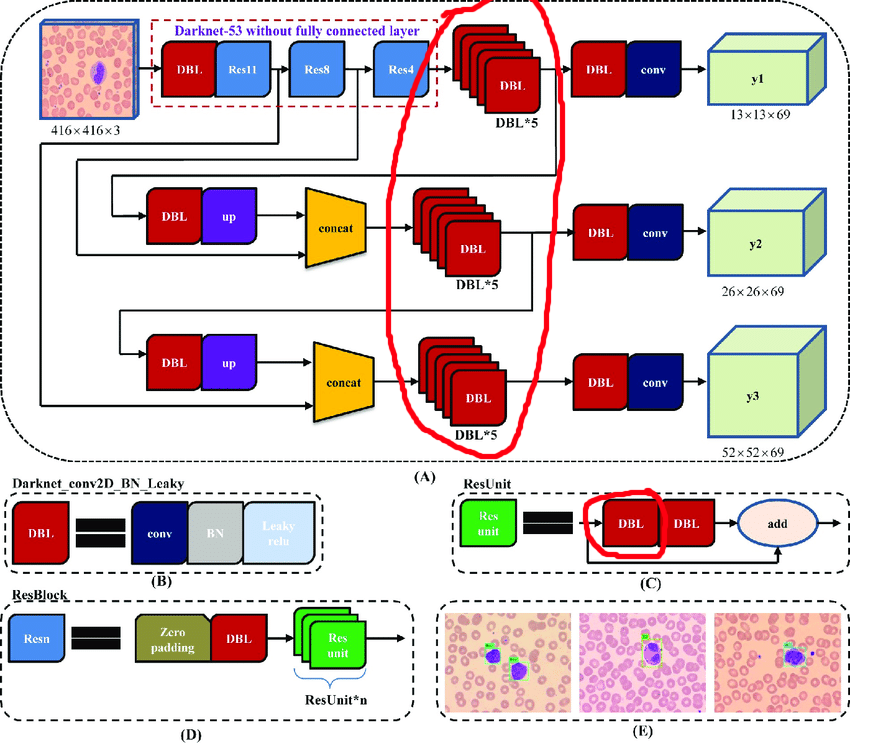
Construisons maintenant un cycle de travail:
- Décharger l'activation
- On se demande combien couper
- Découper
- Apprenez 10 époques avec LR = 1e-4
- Test
Le déchargement des convolutions est utile pour évaluer quelle partie nous pouvons retirer à une certaine étape. Exemples de déchargement:

Nous voyons que presque partout 5% des circonvolutions ont une norme L1 très basse et nous pouvons les supprimer. À chaque étape, ce déchargement a été répété et une évaluation a été faite des couches et de la quantité pouvant être coupée.
L'ensemble du processus s'est déroulé en 4 étapes (ici et partout les chiffres du RTX 2060 Super):
À l'étape 2, un effet positif a été ajouté: le patch de taille 4 est entré en mémoire, ce qui a considérablement accéléré le processus de recyclage.
À l'étape 4, le processus a été arrêté, car même une formation continue prolongée n'a pas élevé le mAp75 à ses anciennes valeurs.
En conséquence, nous avons réussi à accélérer l'inférence de 15% , à réduire la taille de 35% et à ne pas perdre en précision.
Automatisation pour des architectures plus simples
Pour les architectures de réseau plus simples (sans ajout conditionnel, concaténation et blocs résiduels), il est tout à fait possible de se concentrer sur le traitement de toutes les couches convolutives et d'automatiser le processus de découpe des convolutions.
J'ai implémenté cette option ici .
C'est simple: vous n'avez qu'une fonction de perte, un optimiseur et des générateurs batch:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
Si nécessaire, vous pouvez modifier les paramètres de configuration:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
De plus, une restriction basée sur l'écart-type est mise en œuvre. L'objectif est de limiter une partie de celles supprimées, à l'exclusion des convolutions avec des mesures L1 déjà "suffisantes":
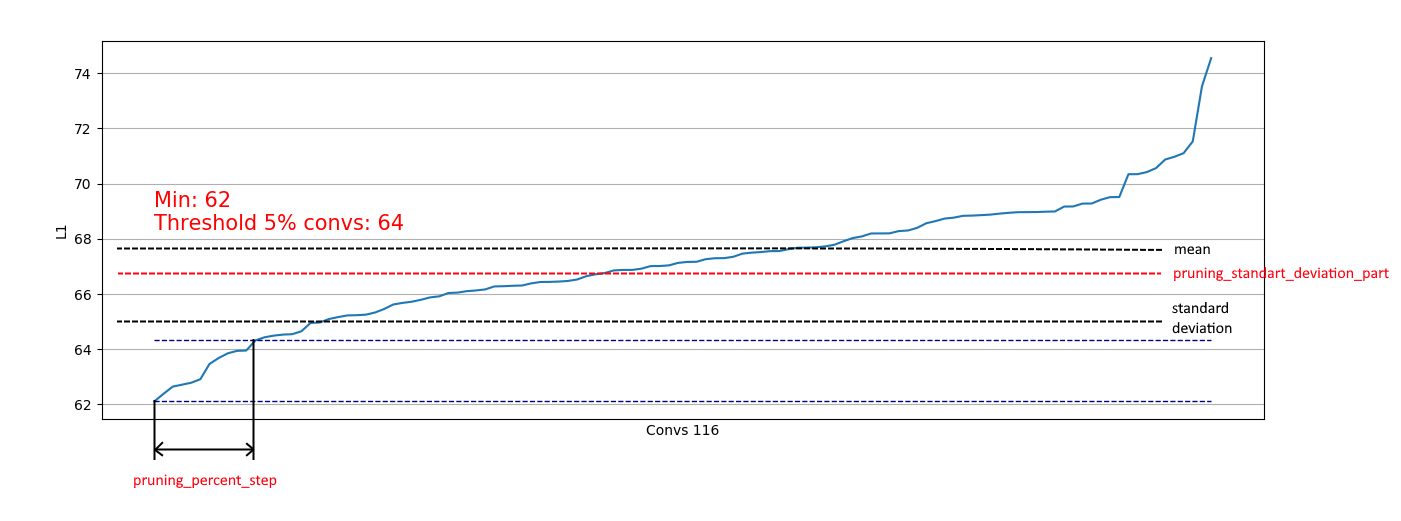
Ainsi, nous ne pouvons supprimer que des convolutions faibles de distributions similaires à la droite et ne pas affecter la suppression de distributions comme la gauche:

Lorsque la distribution s'approche de la normale, le coefficient pruning_standart_deviation_part peut être sélectionné parmi:

Je recommande une hypothèse de 2 sigma. Ou vous ne pouvez pas vous concentrer sur cette fonctionnalité, laissant la valeur <1.0.
La sortie est un graphique de la taille du réseau, de la perte et de la durée d'exécution du réseau pour l'ensemble du test, normalisé à 1,0. Par exemple, ici, la taille du réseau a été réduite de près de 2 fois sans perte de qualité (un petit réseau de convolution pour des poids de 100k):
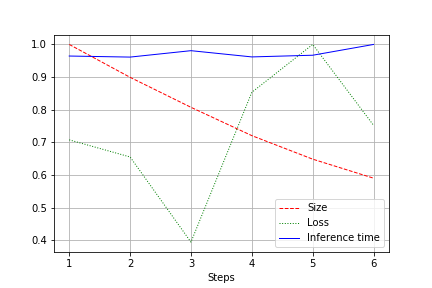
La vitesse de course est sujette à des fluctuations normales et n'a pas beaucoup changé. Il y a une explication à cela:
- Le nombre de circonvolutions passe de pratique (32, 64, 128) à pas le plus pratique pour les cartes vidéo - 27, 51, etc. Ici, je peux me tromper, mais cela affecte très probablement.
- L'architecture n'est pas large, mais cohérente. En réduisant la largeur, on ne touche pas la profondeur. Ainsi, nous réduisons la charge, mais ne modifions pas la vitesse.
Par conséquent, l'amélioration s'est traduite par une diminution de la charge de CUDA pendant l'analyse de 20 à 30%, mais pas par une diminution de la durée d'exécution.
Résumé
Réfléchissez. Nous avons envisagé 2 options d'élagage - pour YOLOv3 (lorsque vous devez travailler avec vos mains) et pour les réseaux avec des architectures plus faciles. On peut voir que dans les deux cas, il est possible d'obtenir une réduction de la taille et de l'accélération du réseau sans perte de précision. Résultats:
- Réduction des effectifs
- Accélération de la course
- Réduction de charge CUDA
- En conséquence, respect de l'environnement (Nous optimisons l'utilisation future des ressources informatiques. Quelque part Greta Tunberg se réjouit seule)
Appendice
- Après l'étape d'élagage, vous pouvez également tordre la quantification (par exemple, avec TensorRT)
- Tensorflow fournit des fonctionnalités pour low_magnitude_pruning . Ça marche.
- Je souhaite développer le référentiel et je serai heureux de vous aider