Habituellement à la veille du nouvel an, nous mettons à jour notre ensemble de données sur la sémantique ouverte. Beaucoup de travail a été accompli cette année, mais il n'est pas parvenu à sa conclusion logique et nous le poursuivrons l'année prochaine. Nous voulons maintenant parler d'un ensemble de données ouvertes tout aussi important qui a suscité un vif intérêt lors de plusieurs conférences linguistiques cette année, tant de la part des chercheurs que des représentants de l'industrie. Ce post se concentrera sur le dictionnaire tonal ouvert de la langue russe.

Pourquoi?
La tonalité, ou en termes simples bon / mauvais, est une caractéristique naturelle des mots. Naturel pour les humains et leurs perceptions, mais pas pour la compréhension informatique. Le langage est agencé de manière à contenir une symétrie par rapport à la polarité des mots et il n'est pas possible de séparer les bons mots des mauvais sans recourir à un marquage externe. En fait, initialement, la tâche de créer un dictionnaire tonal est née de la nécessité de regrouper les listes de mots reçues automatiquement par l'algorithme en fonction de leur polarité.
Bien sûr, la tonalité n'est qu'un aspect du sens d'un mot, et une véritable compréhension du sentiment nécessite une analyse sémantique complète, une compréhension des rôles dans une situation particulière et une connaissance de la position occupée par l'observateur. Ainsi, par exemple, la «réduction du prix des actions» pour différentes parties peut avoir une tonalité différente, mais «les coûts ont augmenté» et «les bénéfices ont augmenté» ont une polarité différente, bien que dans les deux expressions, le verbe croît, ce qui a une note plutôt positive (selon notre ensemble de données).
Il existe un éventail assez large de raisons pour lesquelles nous attribuons un mot particulier à une clé spécifique. Parfois, ce sont nos sensations immédiates - joie et désir; parfois, ce sont les qualités d'une personne - le professionnalisme et la négligence: et parfois des concepts tels que l'éducation ou l'entrepreneuriat associés à des institutions sociales complexes et offrant des avantages à long terme. Et l'évaluation de ces mots est fortement liée à la culture et au contrat social. Et, par conséquent, il peut ne pas avoir une évaluation universellement reconnue et universelle.
Néanmoins, la langue et la communication ne pourraient exister si les systèmes de coordonnées de différentes personnes au sein d'une même culture n'avaient rien de commun les uns avec les autres. Et donc, pour des groupes de mots assez importants, leur composante estimée est plus ou moins cohérente.
Comment?
Il existe deux façons principales de collecter une grande quantité de données linguistiques - attirer des experts et interroger des personnes (ou une version plus moderne de ces dernières - le crowdsourcing). Nous ne répéterons pas les différences évidentes entre ces approches, mais prêterons plutôt attention à celles d'entre elles qui ont un impact direct sur les propriétés de l'ensemble de données résultant.
Le marquage expert implique une orientation claire vers une utilisation future, et stipule donc une méthode de prise de décision dans une situation d'ambiguïté dictée par cette application. Pour un jeu de données final, cela signifie:
- fixation du sujet;
- définition claire de la position de l'observateur.
Ainsi, si un expert compile un dictionnaire tonal pour analyser les informations destinées à un public de masse, il prend alors la position d'un lecteur généralisé et assume les accords tacites entre les médias et les lecteurs. Disons que la «réduction des coûts» dans de telles installations aura une évaluation positive et la «croissance tarifaire» - négative (selon l'ensemble de données RusentiLex-2017).
Le crowdsourcing est privé de la possibilité de mettre en place un tel cadre et n'est guère l'outil optimal pour résoudre des problèmes appliqués hautement spécialisés. Mais cela nous permet de saisir un autre aspect important de l'évaluation de la tonalité - la cohérence entre les répondants. Certains mots seront évalués sans ambiguïté comme positifs ou négatifs; certains répartiront l'évaluation entre les options neutre et polaire; et un petit groupe de mots montrera une incohérence prononcée des notes.
Répartition de la cohérence des notesÀ gauche sur le graphique, la cohérence maximale des estimations, à droite, l'incohérence maximale.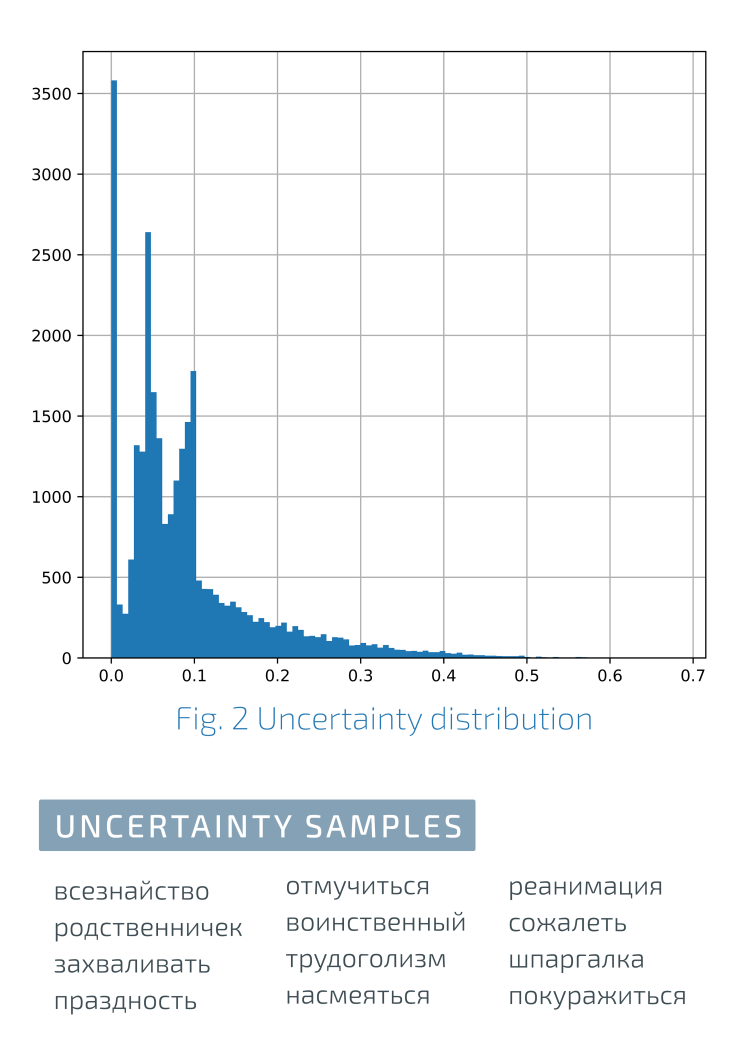
De plus, contrairement à l'évaluation d'experts, le crowdsourcing vous permet d'obtenir une valeur continue de polarité, délimitant des mots strictement positifs (négatifs), plutôt positifs (négatifs) et neutres. La répartition entre ces groupes dépend bien entendu des valeurs de seuil sélectionnées. Cependant, l'échantillonnage est complètement facultatif - il est possible pour un certain nombre d'applications qu'une valeur continue soit plus pratique.
Structure du jeu de données
La structure de l'ensemble de données est assez simple: il s'agit d'un dictionnaire tonal qui associe les mots à leur évaluation dans une plage de -1 (note négative marginale) à +1 (note positive marginale). Pour plus de commodité, une étiquette lisible par l'homme à partir de l'ensemble de «positif», «neutre», «négatif» calculé en utilisant des valeurs de seuil est indiquée.
Exemples de mots positifs, neutres et négatifs de l'ensemble de données- positif: fiable, réconcilier, gentillesse, pardon, consciencieux, inspirer, photogénique, profit, bon élevage, retrouvailles, inspirer, confiance, enthousiasme, enfants, transformer, bien-être, pendaison de crémaillère, confort, sensible, bourse, bénévole;
- neutre: abréviation, compter, bâton, tunique, polyèdre, toucher, meubles, résident, cliquer, fondre, utilisation, enjamber, route, ingrédient, dégonfler, souligner, emblème, descendre, armé, sept, dessiner;
- négatifs: élucidateur, snicker, blab, otage, plouc, arrogant, faux, pollution, envieux, étrangler, geler, gaspiller, frauduleux, dégrader, accro, mordre, attraper un rhume, trouver la faute, avoir peur, voleur, ignorant;
De plus, dans cette version de l'ensemble de données (il existe toujours une première version précédente), des données brutes sont fournies - le pourcentage de votes exprimés pour chacune des options. Cela vous permet d'appliquer des modèles personnalisés pour calculer la polarité totale et le niveau de cohérence du balisage.
Remarque La version présentée de l'ensemble de données couvre les mots d'OT les plus reconnaissables (vocabulaire actif); les phrases n'étaient pas étiquetées. En comparant avec d'autres dictionnaires de tonalité, nous avons trouvé un certain nombre de mots qui sont disponibles dans le vocabulaire actif, mais non représentés dans notre ensemble de données. Nous procéderons à un balisage supplémentaire et prévoyons d'inclure les unités linguistiques manquantes au cours de la prochaine année.
Plans supplémentaires
Marquer le sentiment est l'une des tâches spéciales dans le cadre de l'étude du système sémantique du langage. Comme nous l'avons noté ci-dessus, l'utilité de l'ensemble de données présenté dépend directement de la capacité à associer les valeurs de polarité qui y sont présentées à d'autres informations sémantiques. Avec des classes de mots, par exemple. Nous avons commencé ce travail et prévoyons de le développer à l'avenir.
Un autre domaine de recherche important est le désir de comprendre la raison de la coloration de certains mots, d'élever des mots liés aux sentiments, aux émotions et à l'évaluation directe et ces mots où le concept ou la situation qu'ils décrivent promettent un profit ou une perte retardé. Par conséquent, ces mots sont plus sensibles aux influences culturelles et sociales.
Il est également prévu d'étendre le balisage avec des phrases, y compris des expressions stables et des unités phraséologiques. Mais ici, nous parlons déjà de volumes de vocabulaire complètement différents, donc la tâche générale est de comprendre comment le sentiment fonctionne à un niveau plus général (plus sous le spoiler).
Sentiment et sémantiqueEn y regardant de plus près, il devient clair que le langage fonctionne avec un ensemble compact de concepts relatifs au nombre de mots et à leurs combinaisons, chacun pouvant être exprimé de plusieurs manières. Cette observation a été reflétée en détail dans les travaux des linguistes russes et dans le modèle Sense-Text qu'ils ont créé.
Par exemple, «réduction de prix», «chute de prix», «prix effondrés», «prix réduits» - ce sont des façons différentes de décrire un processus similaire, mais exprimées par divers moyens linguistiques. Dans le même temps, dans des contextes similaires, on peut rencontrer d'autres concepts qui ont une expression quantitative - «une baisse du niveau de confiance», «une augmentation du niveau de revenu», etc. Dans chaque cas, il suffit de comprendre la correspondance au-dessus / en dessous - bonne / mauvaise (niveau de connaissance et du monde) et par quels moyens lexicaux s'exprime un mouvement dans une direction donnée (niveau de langage).
Rétroaction et distribution
Nous apprécions tout commentaire dans les commentaires - de la critique du travail et de nos approches de liens vers des études intéressantes et des articles connexes.
Si vous avez des connaissances ou des collègues qui pourraient être intéressés par l'ensemble de données publié, envoyez-leur un lien vers l'article ou le référentiel pour aider à diffuser les données ouvertes.
Lien vers l'ensemble de données et la licence
Jeu de données: dictionnaire tonal ouvert de la langue russeL'
ensemble de données comprend 28197 mots .
L'ensemble de données est autorisé sous
CC BY-NC-SA 4.0 .
Liens vers des projets connexes