Nous terminons une série d'articles pratiques sur la façon d'utiliser les données des tests génétiques. Aujourd'hui, nous publions les bonnes réponses et les gagnants qui ont résolu les trois problèmes plus rapidement que les autres.

Tous les articles de notre série:
Qu'est-ce que le génome complet et pourquoi est-il nécessaireNuméro de tâche 1. Découvrez le sexe et le degré de relation.Numéro de tâche 2. Détermination de la structure de la populationNuméro de tâche 3. Conversion de données et téléchargement vers des services tiersPour terminer les tâches de test, nous avons utilisé 12 échantillons des données ouvertes du projet 1000 Genomes. Nous avons renommé les échantillons afin que les participants ne puissent pas utiliser les données disponibles pour les réponses.

Table de correspondance des identifiants originaux et utilisés dans les tâches.
Tâche numéro 1. Découvrir le sexe et le degré de relation
Le pedigree des échantillons utilisés est montré dans la figure 1. Les décisions ont été considérées comme correctes, dans lesquelles 3 familles et 3 échantillons génétiquement indépendants ont été identifiés - 0030, 0090 et 0066. Leur relation avec la famille ne peut être établie par cette analyse s'il n'y a pas d'échantillons d'enfants. Les 12 échantillons doivent être présents dans la solution. La conception du pedigree a également été prise en compte (figure 2). Nous avons écrit sur les règles de conception dans la première tâche.
 Figure 1 Relations familiales des échantillons de l'ensemble de données de test selon les données de 1000 génomes. Le fichier généalogique est disponible ici .
Figure 1 Relations familiales des échantillons de l'ensemble de données de test selon les données de 1000 génomes. Le fichier généalogique est disponible ici . Figure 2 À droite, la représentation incorrecte d'une famille avec un enfant: deux mariages sont représentés, il n'y a pas de lien familial.
Figure 2 À droite, la représentation incorrecte d'une famille avec un enfant: deux mariages sont représentés, il n'y a pas de lien familial.Numéro de tâche 2. Détermination de la structure de la population
Dans l'ensemble de données pour la tâche, nous avons utilisé des échantillons de deux superpopulations. La visualisation de l'emplacement de 12 échantillons le long des trois principaux composants est représentée sur les figures 3 et 4. Dans les diagrammes de dispersion, la formation de quatre grappes peut être observée. Cependant, ils ne correspondent pas entièrement aux données initiales sur la population: figure 5, deux populations. Nous avons expliqué les raisons d'une séparation aussi prononcée et contradictoire des échantillons dans l'
article . De plus, tous les échantillons montrant un clivage de grappe inattendu appartiennent à la superpopulation AMR - Ad Mixed American. La mixité et l'hétérogénéité sont inhérentes aux populations mixtes et peuvent se manifester dans le regroupement observé.
 Figure 3 Diagrammes de dispersion de l'emplacement des échantillons de l'ensemble de données de test par paires des trois premiers composants principaux.
Figure 3 Diagrammes de dispersion de l'emplacement des échantillons de l'ensemble de données de test par paires des trois premiers composants principaux.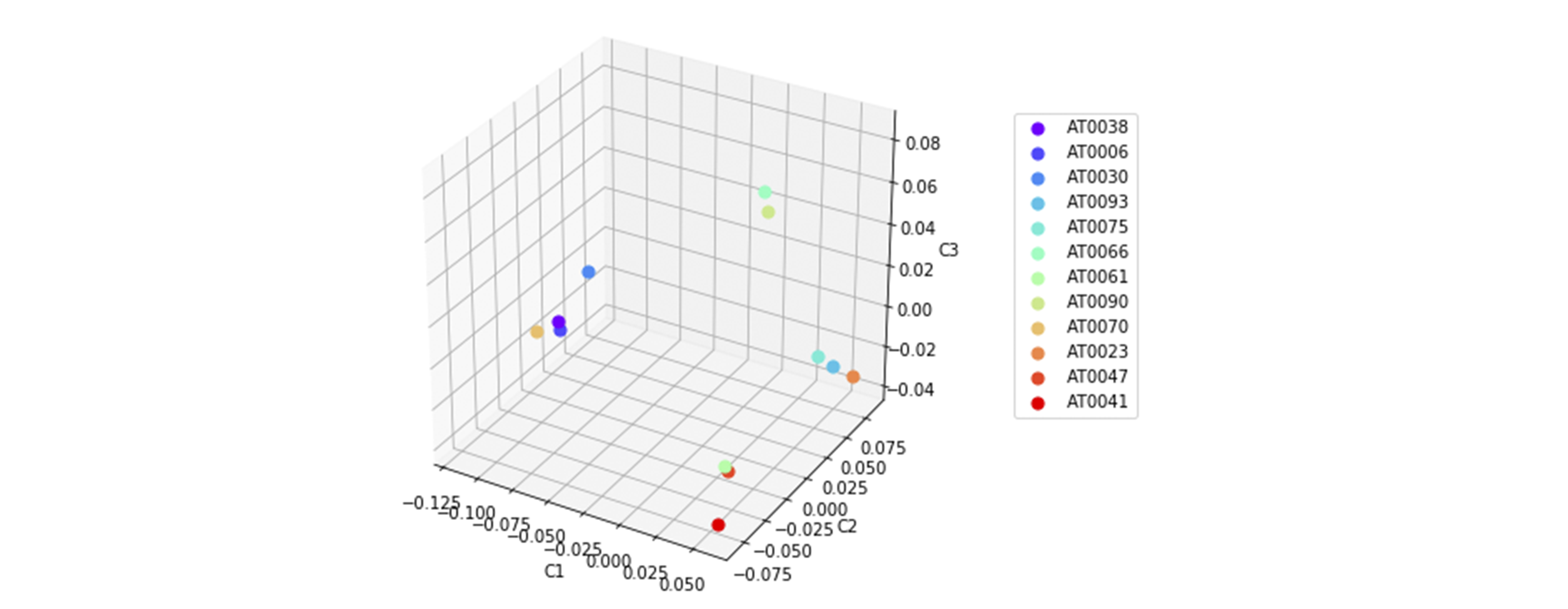 Figure 4 Diagramme de dispersion des échantillons de l'ensemble de données de test pour les trois principaux composants.
Figure 4 Diagramme de dispersion des échantillons de l'ensemble de données de test pour les trois principaux composants. Figure 5 La population et le pedigree des échantillons utilisés dans le jeu de données de test selon les «1000 génomes». Le fichier généalogique est disponible ici .
Figure 5 La population et le pedigree des échantillons utilisés dans le jeu de données de test selon les «1000 génomes». Le fichier généalogique est disponible ici .
La figure 6 montre l'arborescence de clustering construite à partir du fichier
cluster3 . L'arbre pouvait être construit manuellement ou en utilisant n'importe quel type d'automatisation, mais il devait correspondre au clustering réalisé avec Plink. Les arbres qui ne sont pas conformes à la structure et pour lesquels les participants ont utilisé d'autres paquets PCA n'ont pas été acceptés. Ils ne reflétaient pas la solution trouvée par Plink; par conséquent, ils n'étaient pas adaptés pour confirmer les clusters Plink obtenus.
 Figure 6 Arbre de regroupement binaire pour un ensemble de données de test de 12 échantillons.
Figure 6 Arbre de regroupement binaire pour un ensemble de données de test de 12 échantillons.Numéro de tâche 3. Conversion de données et téléchargement vers des services tiers
Dans cette tâche, nous avons demandé aux participants de préparer les données des tests génétiques à charger dans le système d'interprétation Promethease et d'analyser les résultats. Pour vérifier les réponses, il était nécessaire de collecter un tableau avec les identifiants des échantillons de l'ensemble de données de test, leur groupe sanguin et le facteur Rh.

Un tableau avec les identifiants des échantillons de l'ensemble de données de test et le groupe sanguin détecté et le facteur Rh du système d'interprétation Promethease.
Les gagnants
Nous avons écrit que nous offrirons des cadeaux à ceux qui résolvent les problèmes plus rapidement que les autres. Par conséquent, nous avons pris en compte non seulement l'exactitude des réponses, mais aussi le temps écoulé entre le moment où la tâche a été publiée et la réception de la réponse. Le temps pour les trois tâches a été résumé et nous avons donc sélectionné les trois gagnants les plus rapides.

Un tableau avec les résultats de tous les participants.
Membre avec le domaine de messagerie ab12ab, nous ne pouvons pas vous contacter. Veuillez écrire à l'auteur de l'article dans des messages privés jusqu'à lundi. Sinon, nous remettrons le prix au prochain participant sur la liste.Les gagnants ont déjà reçu des lettres de gains. Pour le reste, nous avons également un petit cadeau. Jusqu'à la nouvelle année,
le site Web d'Atlas propose des réductions allant jusqu'à 50%.