Les réseaux de neurones sont passés d'un état de curiosité académique à une industrie massive

Au cours de la dernière décennie, les ordinateurs ont considérablement amélioré leur capacité à comprendre le monde qui les entoure. Le logiciel pour l'équipement photo reconnaît automatiquement les visages des personnes. Les smartphones convertissent la parole en texte. Les robots motorisés reconnaissent les objets sur la route et évitent les collisions avec eux.
Au cœur de toutes ces percées se trouve la technologie de l'intelligence artificielle (IA) appelée deep learning (GO). GO est basé sur des réseaux de neurones (NS), des structures de données inspirées de réseaux composés de neurones biologiques. Les NS sont organisés en couches et les entrées d'une couche sont connectées aux sorties de la voisine.
Les informaticiens expérimentent la NS depuis les années 50. Cependant, le fondement de la vaste industrie GO actuelle a été posé par deux percées majeures - l'une survenue en 1986, la seconde en 2012. La percée de 2012 - la révolution de GO - a été associée à la découverte que l'utilisation de NS avec un grand nombre de couches nous permettra d'améliorer considérablement leur efficacité. La découverte a été facilitée par les volumes croissants de données et de puissance de calcul.
Dans cet article, nous vous présenterons le monde de l'Assemblée nationale. Nous expliquerons ce qu'est la NS, comment elle fonctionne et d'où elle vient. Et nous étudierons pourquoi - malgré de nombreuses décennies de recherches antérieures - les SN ne sont devenues vraiment utiles qu'en 2012.
Les réseaux de neurones sont apparus dans les années 1950
 Frank Rosenblatt travaille sur son perceptron - un des premiers modèles NS
Frank Rosenblatt travaille sur son perceptron - un des premiers modèles NSL'idée de l'Assemblée nationale est assez ancienne - du moins selon les normes de l'informatique. En 1957,
Frank Rosenblatt de l'Université Cornell a publié un
rapport décrivant un des premiers concepts NS appelé le perceptron. En 1958, avec le soutien de l'US Navy, il crée un système primitif capable d'analyser 20x20 pixels et de reconnaître des formes géométriques simples.
L'objectif principal de Rosenblatt n'était pas de créer un système de classification d'images pratique. Il a essayé de comprendre le fonctionnement du cerveau humain, créant des systèmes informatiques organisés à son image. Cependant, ce concept a suscité un enthousiasme excessif de la part de tiers.
"Aujourd'hui, l'US Navy a révélé au monde l'embryon d'un ordinateur électronique qui devrait pouvoir marcher, parler, voir, écrire, se reproduire et être conscient de son existence", écrit le New York Times.
En fait, chaque neurone de la NS n'est qu'une fonction mathématique. Chaque neurone calcule la somme pondérée des données d'entrée - plus le poids d'entrée est élevé, plus ces données d'entrée affectent fortement la sortie du neurone. Ensuite, la somme pondérée est appliquée à la fonction «d'activation» non linéaire - à cette étape, les NS peuvent simuler des phénomènes non linéaires complexes.
Les capacités des premiers perceptrons que Rosenblatt a expérimentés - et NS en général - découlent de leur capacité à "apprendre" avec des exemples. Les NS sont formés en ajustant les poids d'entrée des neurones sur la base des résultats du réseau avec les données d'entrée sélectionnées par exemple. Si le réseau classe correctement l'image, les pondérations contribuant à la réponse correcte augmentent, tandis que d'autres diminuent. Si le réseau est incorrect, les poids s'ajustent dans l'autre sens.
Une telle procédure a permis aux premiers SN «d'apprendre» d'une manière qui rappelle le comportement du système nerveux humain. Le battage médiatique autour de cette approche ne s'est pas arrêté dans les années 1960. Cependant, le
livre influent de 1969 des auteurs des informaticiens Marvin Minsky et Seymour Papert a montré que ces premières NS avaient des limites importantes.
Les premiers NS de Rosenblatt n'avaient qu'une ou deux couches entraînées. Minsky et Papert ont montré que de telles NS sont mathématiquement incapables de modéliser des phénomènes complexes du monde réel.
En principe, les SN plus profonds étaient plus capables. Cependant, une telle NS surchargerait ces misérables ressources informatiques que les ordinateurs possédaient à l'époque. Les algorithmes de
recherche ascendants les plus simples utilisés dans les premiers NS n'ont pas évolué pour les NS plus profonds.
En conséquence, l'Assemblée nationale a perdu tout soutien dans les années 1970 et au début des années 1980 - elle faisait partie de l'ère de «l'hiver de l'IA».
Algorithme révolutionnaire
 Mon propre réseau de neurones basé sur des «équipements souples» estime que la probabilité d'avoir un hot dog sur cette photo est de 1. Nous deviendrons riches!
Mon propre réseau de neurones basé sur des «équipements souples» estime que la probabilité d'avoir un hot dog sur cette photo est de 1. Nous deviendrons riches!La chance s'est de nouveau tournée vers la NS grâce au célèbre
travail de 1986, qui a introduit le concept de la propagation arrière - une méthode pratique d'enseignement de la NS.
Supposons que vous travailliez en tant que programmeur dans une société de logiciels imaginaires et que l'on vous ait demandé de créer une application qui détermine s'il y a un hot dog dans l'image. Vous commencez à travailler avec un NS initialisé au hasard, qui prend une image d'entrée et sort une valeur de 0 à 1 - où 1 signifie «hot dog» et 0 signifie «pas hot dog».
Pour former le réseau, vous collectez des milliers d'images, sous chacune desquelles se trouve une étiquette indiquant s'il y a un hot dog sur cette image. Vous lui donnez la première image - et il y a un hot-dog dessus - dans le réseau neuronal. Il donne une valeur de sortie de 0,07, ce qui signifie «pas de hot-dog». Ce n'est pas la bonne réponse; le réseau aurait dû renvoyer une réponse proche de 1.
Le but de l'algorithme de rétropropagation est d'ajuster les poids d'entrée afin que le réseau produise une valeur plus élevée s'il reçoit à nouveau cette image - et, de préférence, d'autres images où il y a des hot dogs. Pour cela, l'algorithme de rétropropagation commence par examiner les neurones d'entrée de la couche de sortie. Chaque valeur a une variable de poids. L'algorithme de rétropropagation ajuste chaque poids dans une direction telle que le NS donne une valeur plus élevée. Plus la valeur d'entrée est élevée, plus son poids augmente.
Jusqu'à présent, je décris la montée la plus simple au sommet familière aux chercheurs dans les années 1960. La percée de rétropropagation a été l'étape suivante: l'algorithme utilise des dérivées partielles pour répartir le «défaut» pour la sortie incorrecte entre les entrées des neurones. L'algorithme calcule comment un petit changement dans chaque valeur d'entrée affectera la sortie finale d'un neurone, et si ce changement rapprochera le résultat de la bonne réponse, ou vice versa.
Le résultat est un ensemble de valeurs d'erreur pour chaque neurone de la couche précédente - en fait, un signal qui évalue si la valeur de chaque neurone est trop grande ou trop petite. Ensuite, l'algorithme répète le processus de réglage pour les nouveaux neurones de la deuxième couche [de la fin]. Il modifie légèrement les poids d'entrée de chaque neurone pour rapprocher le réseau de la bonne réponse.
Ensuite, l'algorithme utilise à nouveau des dérivées partielles pour calculer comment la valeur de chaque entrée de la couche précédente a affecté les erreurs de sortie de cette couche - et propage ces erreurs à la couche précédente, où le processus se répète.
Il s'agit simplement d'un modèle de rétropropagation simplifié. Si vous avez besoin de détails mathématiques détaillés, je recommande le livre de Michael Nielsen sur ce sujet [
et nous avons sa traduction / env. trad.]. Pour nos besoins, il suffit que la distribution inverse change radicalement la gamme des NS formés. Les gens n'étaient plus limités à de simples réseaux à une ou deux couches. Ils pourraient créer des réseaux à cinq, dix ou cinquante couches, et ces réseaux pourraient avoir une structure interne arbitrairement complexe.
L'invention de la rétropropagation a lancé le deuxième boom de l'Assemblée nationale, qui a commencé à produire des résultats pratiques. En 1998, un groupe de chercheurs d'AT & T a montré comment les réseaux de neurones peuvent être utilisés pour reconnaître des nombres manuscrits, ce qui a permis d'automatiser le traitement des chèques.
"Le principal message de ce travail est que nous pouvons créer des systèmes améliorés pour reconnaître les modèles, en s'appuyant davantage sur l'apprentissage automatique et moins sur l'heuristique développée manuellement", ont écrit les auteurs.
Et pourtant, dans cette phase, les NS n'étaient qu'une des nombreuses technologies à la disposition des chercheurs en apprentissage automatique. Lorsque j'ai étudié dans un cours d'IA à l'institut en 2008, les réseaux de neurones n'étaient qu'un des neuf algorithmes MO, parmi lesquels nous pouvions choisir l'option appropriée pour la tâche. Cependant, GO s'apprêtait déjà à occulter le reste de la technologie.
Le Big Data démontre la puissance du deep learning
 Détente détectée. Chance de la plage 1.0. Nous commençons la procédure d'utilisation de Mai Tai.
Détente détectée. Chance de la plage 1.0. Nous commençons la procédure d'utilisation de Mai Tai.La rétropropagation a facilité le processus de calcul de la NS, mais les réseaux plus profonds avaient encore besoin de plus de ressources informatiques que les petits. Les résultats d'études menées dans les années 1990 et 2000 ont souvent montré qu'il était possible de bénéficier de moins en moins de complications supplémentaires de la NS.
Puis la pensée des gens a été changée par le célèbre travail de 2012, qui décrivait la NS sous le nom d'AlexNet, du nom du chercheur principal Alex Krizhevsky. Tout comme les réseaux plus profonds pourraient fournir une efficacité révolutionnaire, mais uniquement en combinaison avec une abondance de puissance informatique et une énorme quantité de données.
AlexNet a développé un trio d'informaticiens de l'Université de Toronto pour participer au concours scientifique ImageNet. Les organisateurs du concours ont collecté un million d'images sur Internet, chacune étant étiquetée et affectée à l'une des milliers de catégories d'objets, par exemple «cerise», «porte-conteneurs» ou «léopard». Les chercheurs en IA ont été invités à former leurs programmes MO sur des parties de ces images, puis à essayer de mettre les étiquettes correctes pour d'autres images que le logiciel n'avait pas rencontrées auparavant. Le logiciel devait sélectionner cinq étiquettes possibles pour chaque image, et la tentative était considérée comme réussie si l'une d'elles coïncidait avec la vraie.
C'était une tâche difficile et jusqu'en 2012, les résultats n'étaient pas très bons. Pour le vainqueur 2011, le taux d'erreur était de 25%.
En 2012, l'équipe AlexNet a surpassé tous les concurrents en donnant des réponses avec 15% d'erreurs. Pour le concurrent le plus proche, ce chiffre était de 26%.
Des chercheurs de Toronto ont combiné plusieurs techniques pour obtenir des résultats révolutionnaires. L'un d'eux était l'utilisation de
névroses convolutives (SNS). En fait, le SNA, pour ainsi dire, entraîne de petits réseaux de neurones - dont les données d'entrée sont des carrés avec un côté de 7 à 11 pixels - puis les «superpose» sur une image plus grande.
"C'est comme si vous preniez un petit gabarit ou un pochoir et tentiez de le comparer avec chaque point de l'image", nous a dit l'an dernier le chercheur en IA Jie Tan. - Vous avez un pochoir de chien, et vous le fixez à l'image, et voyez s'il y a un chien là-bas? Sinon, déplacez le pochoir. Et donc pour l'image entière. Et peu importe où le chien apparaît sur la photo. Le pochoir coïncidera avec lui. Chaque sous-section du réseau ne doit pas devenir un classificateur de chien distinct. »
Un autre facteur clé de succès pour AlexNet a été l'utilisation de cartes graphiques pour accélérer le processus d'apprentissage. Les cartes graphiques ont une puissance de traitement parallèle, bien adaptée aux calculs répétitifs nécessaires pour former un réseau neuronal. En transférant la charge de calcul à une paire de GPU - le Nvidia GTX 580, avec 3 Go de mémoire chacun -, les chercheurs ont pu développer et former un réseau extrêmement vaste et complexe. AlexNet avait huit couches entraînables, 650 000 neurones et 60 millions de paramètres.
Enfin, le succès d'AlexNet a également été assuré par la grande taille de la base de données d'images de formation d'ImageNet: un million de pièces. De nombreuses images sont nécessaires pour affiner 60 millions de paramètres. Pour remporter une victoire décisive, AlexNet a été aidé par la combinaison d'un réseau complexe et d'un grand ensemble de données.
Je me demande pourquoi une telle percée ne s'est pas produite plus tôt:
- La paire de GPU grand public utilisée par les chercheurs d'AlexNet était loin d'être le dispositif informatique le plus puissant de 2012. Cinq et même dix ans auparavant, il y avait des ordinateurs plus puissants. De plus, la technologie d'accélération de l'apprentissage des NS à l'aide de cartes graphiques est connue depuis au moins 2004.
- La base d'un million d'images était inhabituellement importante pour l'enseignement des algorithmes MO en 2012, cependant, la collecte de telles données n'était pas une nouvelle technologie pour cette année. Une équipe de recherche bien financée pourrait facilement constituer une base de données de cette taille cinq ou dix ans plus tôt.
- Les principaux algorithmes utilisés dans AlexNet n'étaient pas nouveaux. L'algorithme de rétropropagation en 2012 existait déjà depuis environ un quart de siècle. Des idées clés liées aux réseaux de neurones convolutifs ont été développées dans les années 1980 et 1990.
Ainsi, chacun des éléments de réussite d'AlexNet existait séparément bien avant la percée. De toute évidence, personne n'a pensé à les combiner - en grande partie parce que personne ne savait à quel point cette combinaison serait puissante.
L'augmentation de la profondeur des SN n'a pratiquement pas amélioré l'efficacité de leur travail s'ils n'utilisaient pas des ensembles de données de formation suffisamment volumineux. Et l'extension de l'ensemble de données n'a pas amélioré les performances des petits réseaux. Pour voir l'augmentation de l'efficacité, nous avions besoin à la fois de réseaux plus profonds et de plus grands ensembles de données - ainsi que d'une puissance de calcul importante qui nous a permis de mener le processus de formation dans un délai raisonnable. L'équipe AlexNet a été la première à réunir les trois éléments en un seul programme.
Le boom du deep learning

La démonstration de toute la puissance de la NS profonde, fournie par une quantité suffisante de données de formation, a été remarquée par de nombreuses personnes - à la fois parmi les scientifiques, les chercheurs et les représentants de l'industrie.
Le premier concours ImageNet à changer. Jusqu'en 2012, la plupart des candidats utilisaient des technologies autres que le deep learning. Lors du concours de 2013, comme l'ont écrit les sponsors, «la majorité» des candidats ont utilisé GO.
Le pourcentage d'erreurs parmi les gagnants a progressivement diminué - passant d'un impressionnant 16% chez AlexNet en 2012 à 2,3% en 2017:
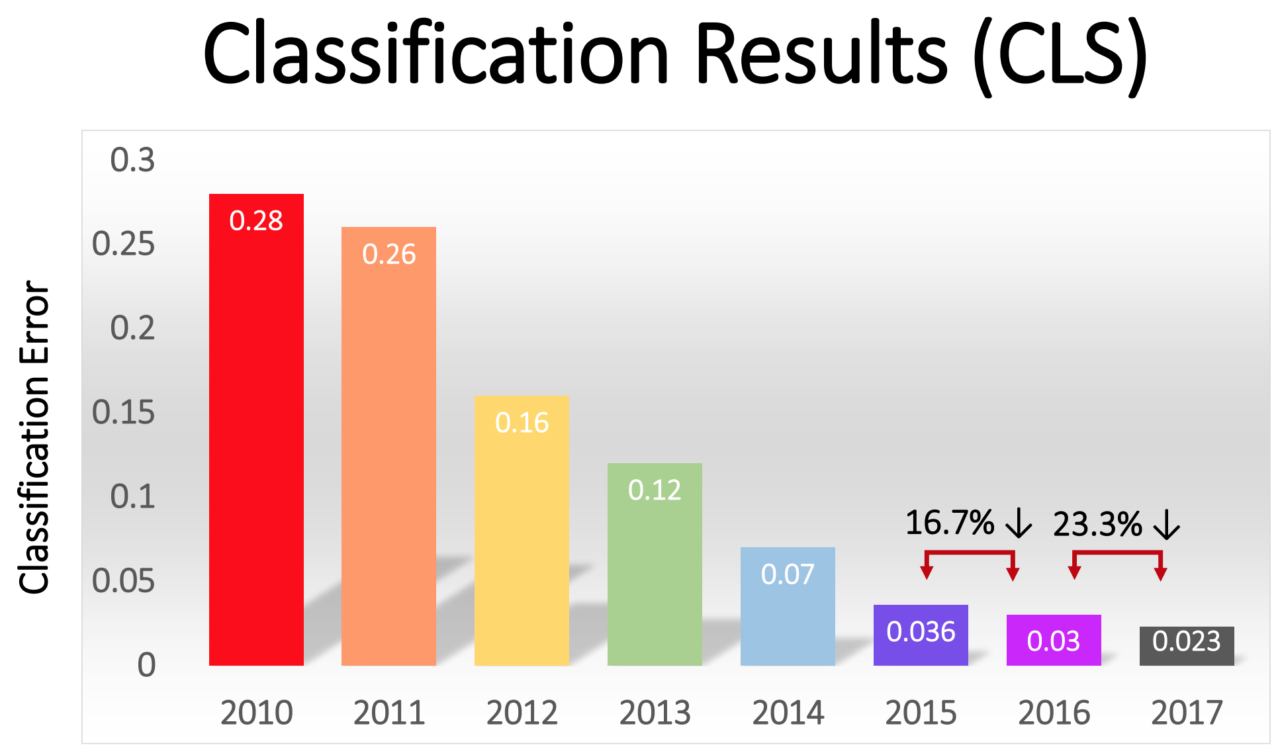
La révolution GO s'est rapidement propagée dans toute l'industrie. En 2013, Google a acquis une startup formée des auteurs d'AlexNet et a utilisé sa technologie comme base pour la fonction de recherche d'images dans Google Photos. En 2014, Facebook vantait son propre logiciel qui reconnaît les images à l'aide de GO. Apple utilise GO pour la reconnaissance faciale dans iOS depuis au moins 2016.
GO sous-tend également l'amélioration récente de la technologie de reconnaissance vocale. Siri d'Apple, Alexa d'Amazon, Cortana de Microsoft et l'assistant de Google utilisent GO - soit pour comprendre les mots d'une personne, soit pour générer une voix plus naturelle, ou les deux.
Ces dernières années, une tendance autosuffisante est apparue dans l'industrie, dans laquelle l'augmentation de la puissance de calcul, du volume de données et de la profondeur du réseau se soutiennent mutuellement. L'équipe AlexNet a utilisé le GPU car elle offrait l'informatique parallèle à un prix raisonnable. Mais au cours des dernières années, de plus en plus d'entreprises ont commencé à développer leurs propres puces, spécialement conçues pour être utilisées dans le domaine des MO.
Google a annoncé la sortie de la puce Tensor Processing Unit spécialement conçue pour la NS en 2016. La même année, Nvidia a annoncé la sortie d'un nouveau GPU appelé Tesla P100, optimisé pour la NS. Intel a répondu à l'appel avec sa puce AI en 2017. En 2018, Amazon a annoncé la sortie de sa propre puce AI, qui peut être utilisée dans le cadre des services cloud de l'entreprise. Même Microsoft travaillerait sur sa puce AI.
Les fabricants de smartphones travaillent également sur des puces qui permettront aux appareils mobiles de faire plus d'informatique en utilisant NS localement, sans avoir à télécharger de données sur les serveurs. Une telle informatique sur les appareils réduit la latence et améliore la confidentialité.
Même Tesla est entré dans ce jeu avec des jetons spéciaux. Cette année, Tesla a présenté un nouvel ordinateur puissant, optimisé pour le calcul de NS. Tesla l'a nommé Full Self-Driving Computer et l'a présenté comme un moment clé dans la stratégie de l'entreprise pour transformer la flotte Tesla en véhicules robotisés.
La disponibilité de capacités informatiques optimisées pour l'IA a généré une demande de données nécessaires pour former des SN de plus en plus complexes. Cette dynamique est plus évidente dans le secteur de la robotique, où les entreprises collectent des données sur des millions de kilomètres de routes réelles. Tesla peut collecter ces données automatiquement à partir des voitures des utilisateurs, et ses concurrents Waymo et Cruise ont payé les conducteurs qui conduisaient leur voiture sur la voie publique.

La demande de données donne un avantage aux grandes entreprises en ligne qui ont déjà accès à de grands volumes de données utilisateur.
Le deep learning a conquis tant de domaines différents en raison de son extrême flexibilité. Des décennies d'essais et d'erreurs ont permis aux chercheurs de développer les blocs de construction de base pour les tâches les plus courantes dans le domaine de la MO - comme les réseaux de convolution pour une reconnaissance d'image efficace. Cependant, si vous avez un réseau de haut niveau adapté au programme et suffisamment de données, le processus de formation sera simple. Les NS profonds sont capables de reconnaître une gamme exceptionnellement large de modèles complexes sans conseils particuliers de développeurs humains.
Il y a bien sûr des limites. Par exemple, certaines personnes se sont lancées dans l'idée de former des robots à l'aide de GO seul - c'est-à-dire nourrir des images reçues d'une caméra, d'un réseau de neurones et recevoir des instructions de celui-ci pour tourner le volant et appuyer sur les pédales. Je suis sceptique quant à cette approche.
L'Assemblée nationale n'a pas encore démontré sa capacité à mener un raisonnement logique complexe, qui est nécessaire pour comprendre certaines conditions qui se présentent sur la route. De plus, les NS sont des «boîtes noires» dont le flux de travail est pratiquement invisible. Il serait difficile d'évaluer et de confirmer la sécurité d'un tel système.Cependant, GO a permis de faire de très grands sauts dans une gamme d'applications étonnamment large. Dans les années à venir, on peut s'attendre aux prochains progrès dans ce domaine.