Bonjour à tous. Vous trouverez ci-dessous une transcription du rapport avec Big Monitoring Meetup 4 .
Prometheus est un système de surveillance de divers systèmes et services, avec lequel les administrateurs système peuvent collecter des informations sur les paramètres actuels des systèmes et configurer des alertes pour recevoir des notifications de déviations dans le fonctionnement des systèmes.
Le rapport comparera Thanos et VictoriaMetrics , des projets de stockage à long terme des métriques Prometheus.


Je vais d'abord parler de Prométhée. Il s'agit d'un système de surveillance qui collecte des métriques à partir de cibles données et les enregistre dans le stockage local. Prometheus peut écrire des métriques dans un référentiel distant, générer des alertes et des règles d'enregistrement.

Limitations de Prométhée:
- Il n'a pas de vue de requête globale. C'est quand vous avez plusieurs instances indépendantes de prometheus. Ils collectent des métriques. Et vous voulez faire une demande en plus de toutes ces métriques collectées à partir de différentes instances de prometheus. Prométhée ne le permet pas.
- Avec prometheus, les performances sont limitées à un seul serveur. Prometheus ne peut pas évoluer automatiquement sur plusieurs serveurs. Vous pouvez uniquement diviser manuellement vos cibles entre plusieurs Prometheus.
- Le volume de métriques dans Prometheus est limité à un seul serveur pour la même raison qu'il ne peut pas automatiquement évoluer vers plusieurs serveurs.
- Dans Prometheus, il n'est pas si facile d'organiser la sécurité des données.

Résoudre ces problèmes / défis?
Les solutions sont:
Toutes ces solutions de stockage à distance collectées par Prometheus. Ils résolvent le problème de stockage à distance de la diapositive précédente de différentes manières. Dans cette présentation, je ne parlerai que des deux premières solutions: Thanos et VictoriaMetrics .
Pour la première fois, des informations sur Thanos sont apparues sur ce lien . Il décrit l'architecture de Thanos et son fonctionnement.

Thanos prend les données que Prometheus a enregistrées sur le disque local et les copie sur S3, sur GCS ou sur un autre stockage d'objets.

De cette façon, Thanos fournit une vue de requête globale. Vous pouvez demander des données stockées dans le stockage d'objets à partir de plusieurs instances de Prometheus.

Thanos prend en charge PromQL et l' API d'interrogation Prometheus .

Thanos utilise le code Prometheus pour stocker des données.

Thanos est développé par les mêmes développeurs que Prometheus.
À propos de VictoriaMetrics . Voici le lien où nous avons parlé pour la première fois de VictoriaMetrics .

VictoriaMetrics reçoit des données de plusieurs prometheus via le protocole API d'écriture à distance pris en charge par Prometheus.
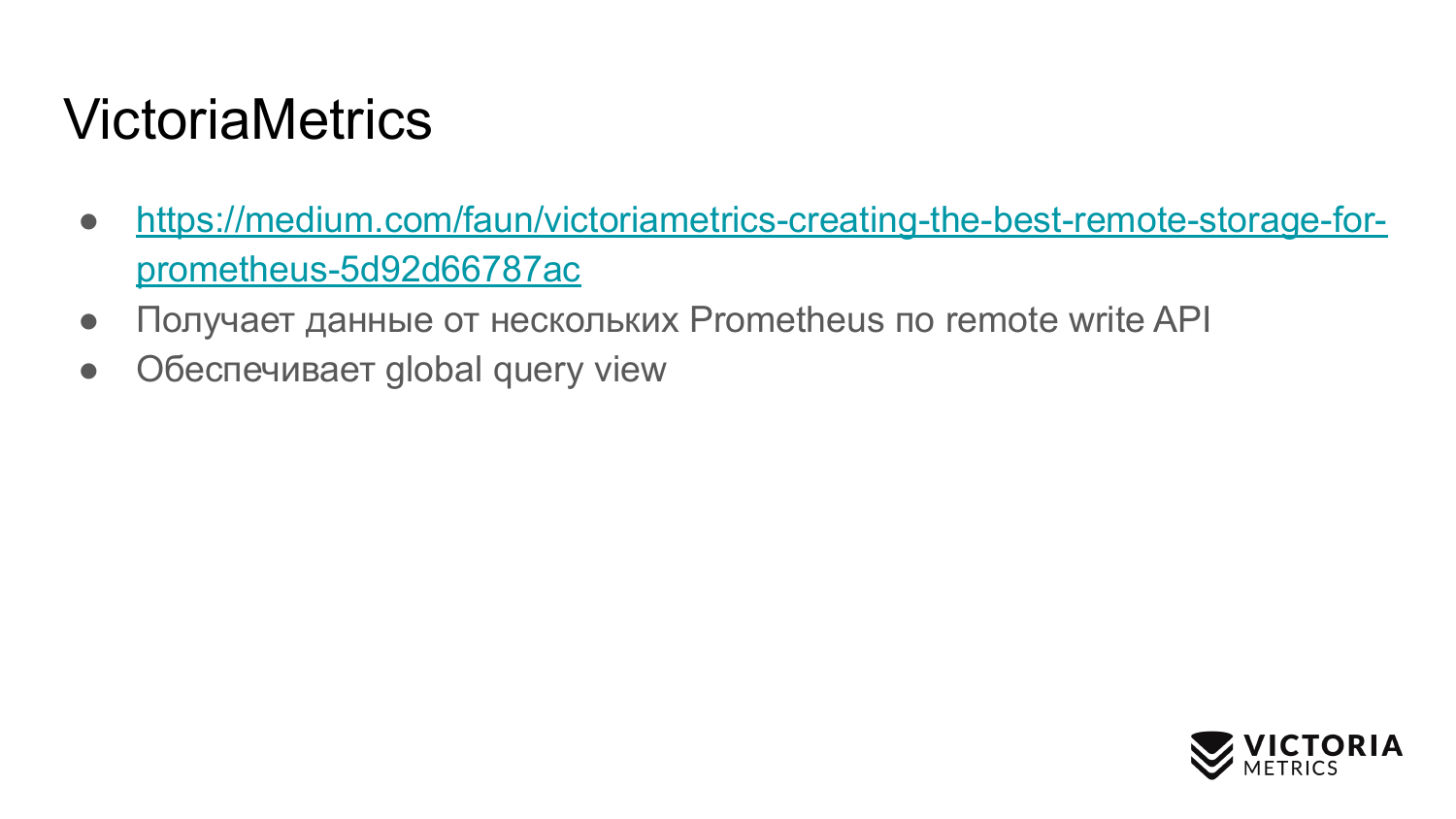
VictoriaMetrics fournit une vue de requête globale, car plusieurs instances de Prometheus peuvent écrire des données sur un VictoriaMetrics. En conséquence, vous pouvez demander toutes ces données.

VictoriaMetrics prend également en charge, comme Thanos, PromQL et l'API d'interrogation Prometheus.

Contrairement à Thanos, le code source de VictoriaMetrics est écrit à partir de zéro et optimisé pour la vitesse et les ressources.

Contrairement à Thanos, VictoriaMetrics évolue verticalement et horizontalement. Il existe une version à nœud unique qui évolue verticalement. Vous pouvez commencer avec un processeur et 1 Go de mémoire et passer progressivement à des centaines de processeurs et 1 To de mémoire. VictoriaMetrics peut utiliser toutes ces ressources. Ses performances augmenteront d'environ 100 fois par rapport à un système monocœur.

L'histoire de Thanos a commencé en novembre 2017, lorsque le premier engagement public est apparu. Avant cela, Thanos a été développé en interne par improbable.io .

En juin 2019, il y a eu une version historique 0.5.0, dans laquelle le protocole Gossip a été supprimé . Il a été retiré de Thanos parce qu'il n'a pas fait de son mieux. Souvent, le cluster Thanos ne fonctionnait pas correctement, les nœuds y étant mal connectés en raison du protocole Gossip. Par conséquent, ils ont décidé de le retirer de là. Je pense que c'est la bonne décision.

Toujours en juin 2019, ils ont envoyé la demande numéro 256 à la Cloud Native Computing Foundation .

Et après quelques mois, Thanos a rejoint la Cloud Native Computing Foundation , qui comprend Prometheus, Kubernetes et d'autres projets populaires.

En janvier 2018, le développement de VictoriaMetrics a commencé.

En septembre 2018, j'ai mentionné publiquement VictoriaMetrics pour la première fois.

En décembre 2018, la version à nœud unique a été publiée.

En mai 2019 , les sources de la version à nœud unique et de la version en cluster ont été publiées .

En juin 2019, comme Thanos, nous avons déposé une demande auprès de la fondation CNCF au numéro 255 . Nous avons postulé un jour avant la candidature de Thanos.

Mais, malheureusement, nous n'y sommes toujours pas acceptés. Besoin d'aide de la communauté.

Considérez les diapositives les plus importantes montrant l'architecture de Thanos et VictoriaMetrics.

Commençons par Thanos. Les composants jaunes sont des composants Prometheus. Tout le reste, ce sont les composants de Thanos. Commençons par le composant le plus important. Thanos Sidecar est un composant installé à côté de chaque Prométhée. Il s'engage à charger les données Prometheus du stockage local dans S3 ou dans un autre stockage d'objets.
Il existe également un composant tel que Thanos Store Gateway, qui peut lire ces données à partir du stockage d'objets sur les demandes entrantes de Thanos Query. Thanos Query implémente PromQL et l'API Prometheus. Autrement dit, de l'extérieur, il ressemble à un Prométhée. Il accepte les requêtes PromQL, les envoie à Thanos Store Gateway, Thanos Store Gateway récupère les données nécessaires du stockage d'objets, les renvoie.
Mais nous avons stocké des données dans Object Storage sans les deux dernières heures en raison de la particularité de l'implémentation de Thanos Sidecar, qui ne peut pas télécharger les deux dernières heures vers Object Storage S3, car pendant ces deux heures, Prometheus n'a pas encore créé de fichiers dans le stockage local.
Comment ont-ils décidé de contourner cela? Thanos Query, en plus des demandes de Thanos Store Gateway, envoie des demandes parallèles à chaque Thanos Sidecar situé à côté de Prometheus.
Et Thanos Sidecar, à son tour, procède à des requêtes supplémentaires dans Prometheus et obtient des données pour les deux dernières heures.
En plus de ces composants, il existe également un composant optionnel sans lequel Thanos ne se sentira pas bien. Il s'agit de Thanos Compact, qui fusionne de petits fichiers sur le stockage d'objets dans des fichiers plus gros qui ont été téléchargés ici par Thanos Sidecar. Thanos Sidecar y télécharge des fichiers de données en deux heures. Ces fichiers, si vous ne les fusionnez pas en fichiers plus volumineux, leur nombre peut augmenter de manière très significative. Plus ces fichiers sont nombreux, plus il faut de mémoire pour Thanos Store Gateway, plus il faut de ressources pour transférer des données sur le réseau, des métadonnées. Thanos Store Gateway devient inefficace. Par conséquent, vous devez absolument exécuter Thanos Compact, qui fusionne les petits fichiers en plus gros afin qu'il y ait moins de tels fichiers et pour réduire la surcharge sur Thanos Store Gateway.
Il existe également un composant tel que la règle de Thanos. Il suit les règles d'alerte Prometheus et peut calculer les règles d'enregistrement Prometheus afin de réécrire les données dans Object Storage. Mais ce composant n'est pas recommandé, car il est enclin à renvoyer des données incomplètes .
Il s'agit d'un schéma simple pour Thanos.
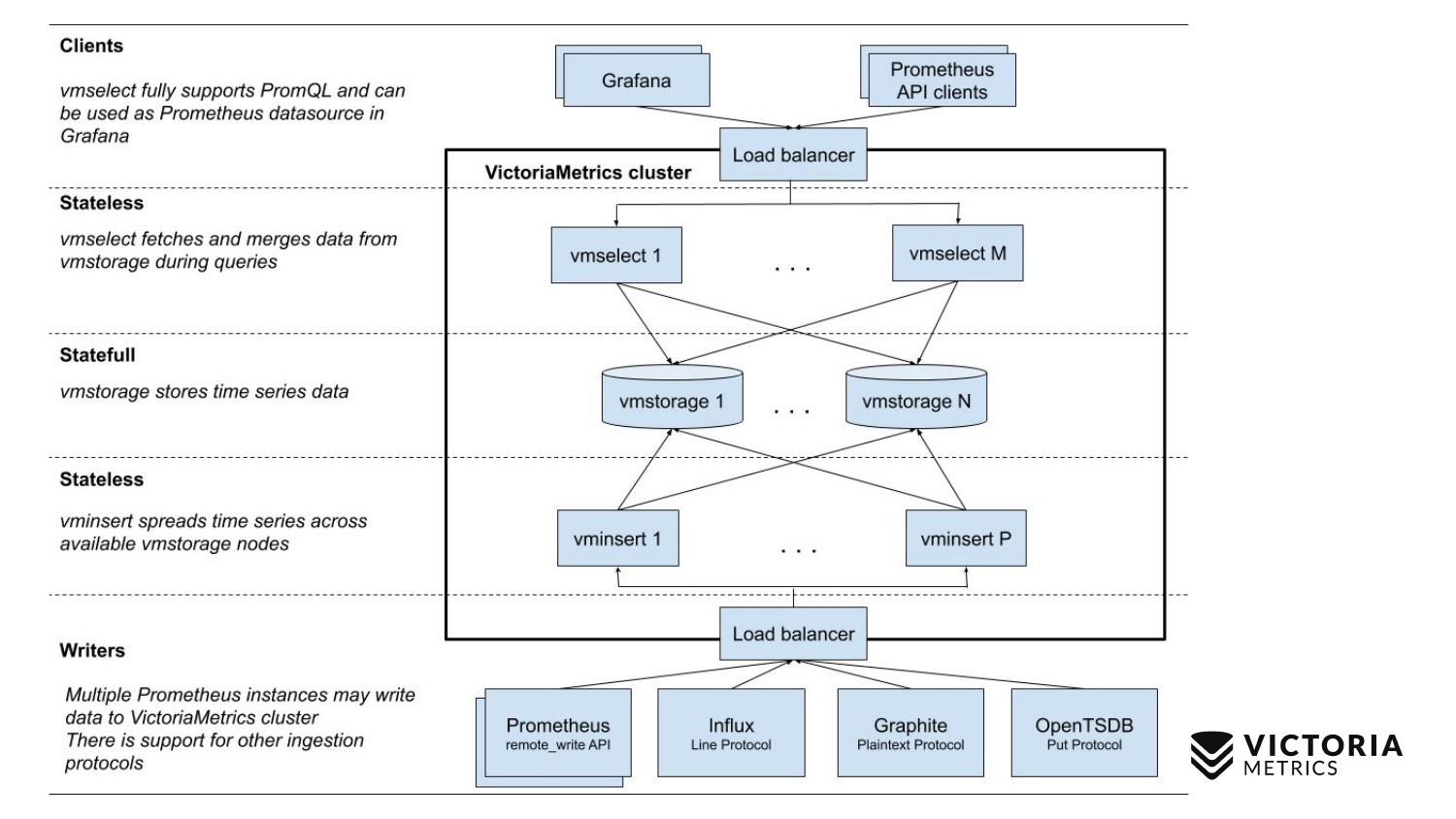
Comparez maintenant avec le schéma VictoriaMetrics.
VictoriaMetrics a 2 versions: version à nœud unique et en cluster. Un nœud unique s'exécute sur un seul ordinateur. Un seul nœud n'a pas ces composants, juste un binaire. Ce binaire sur la diapositive ressemble à ce carré. Tout ce qui se trouve à l'intérieur du carré est le contenu du fichier binaire pour la version à nœud unique. Vous n'avez pas besoin de le connaître. Commencez simplement le binaire - et tout fonctionne pour nous.
La version cluster est plus compliquée. À l'intérieur, il y a trois composants différents: vmselect, vminsert et vmstorage. D'après leur nom, il devrait être clair ce que chacun d'eux fait. Le composant Insert accepte des données dans différents formats: à partir de l'API d'écriture à distance Prometheus, du protocole de ligne Influx, du protocole Graphite et du protocole OpenTSDB. Le composant Insérer les accepte, les analyse et les distribue entre les composants de stockage existants, où les données sont déjà stockées. Le composant Select, à son tour, accepte les requêtes PromQL. Il implémente PromQL ainsi que l'API d'interrogation Prometheus et peut être utilisé en remplacement de Prometheus dans Grafana ou d'autres clients API Prometheus. Select accepte une demande promql, l'analyse, lit les données nécessaires pour exécuter cette demande à partir du nœud de stockage, traite ces données et renvoie une réponse.

Comparez la difficulté d'installation de Thanos et de VictoriaMetrics.

Commençons par Thanos. Avant de commencer à travailler avec Thanos, vous devez créer un compartiment dans le stockage d'objets, tel que S3 ou GCS, afin que Thanos Sidecar puisse y écrire des données.

Ensuite, pour chaque Prometheus, vous devez installer Thanos Sidecar. Avant cela, vous devez vous rappeler de désactiver le compactage des données dans Prometheus. Le compactage des données comprime périodiquement les données dans le stockage local Prometheus afin de réduire la consommation de ressources.
Lorsque vous installez Thanos Sidecar sur votre Prometheus, vous devez désactiver ce compactage des données, car Thanos Sidecar ne peut pas fonctionner normalement lorsque le compactage des données est activé. Cela signifie que votre Prometheus commence à enregistrer les données en blocs de deux heures et cesse de fusionner ces blocs en blocs plus grands. Par conséquent, si vous effectuez des requêtes plus longues que les deux dernières heures, elles ne fonctionneront pas aussi efficacement qu'elles le pourraient si le compactage des données était activé.

Par conséquent, Thanos recommande de réduire le temps de rétention des données dans le stockage local à 6-8 heures afin de réduire cette surcharge d'un grand nombre de petits blocs.
Après avoir installé Thanos Sidecar, vous devez installer deux composants pour chaque compartiment de stockage d'objets. Ce sont Thanos Compactor et Thanos Store Gateway.

Après cela, vous devez installer Thanos Query et le configurer pour qu'il sache comment se connecter à tous les Thanos Store Gateway que vous avez, et sait également comment se connecter à tous les Thanos Sidecar.
Il peut y avoir un petit problème.

Vous devez configurer une connexion fiable et sécurisée entre Thanos Query et ces composants. Et si vos Prometheus sont situés dans différents centres de données ou dans différents VPC, les connexions externes à ces derniers sont interdites. Mais pour que Thanos Query fonctionne, vous devez en quelque sorte configurer la connexion là-bas, et vous devez trouver un moyen.
Si vous disposez d'un grand nombre de ces centres de données, la fiabilité de l'ensemble du système diminue en conséquence. Étant donné que Thanos Query doit rester connecté en permanence à tous les Sidos Sidos situés dans différents centres de données. Avec chaque demande entrante, il transmettra les demandes à tous les Sidos Sidos. Si la connexion est interrompue, vous recevrez soit un ensemble de données incomplet, soit vous obtiendrez la réponse «le cluster ne fonctionne pas».

Dans VictoriaMetrics, les choses sont un peu plus faciles. Pour la version à nœud unique, il suffit d'exécuter un seul binaire et tout fonctionne.

Dans une version en cluster, il suffit d'exécuter les trois types de composants ci-dessus dans la quantité dont vous avez besoin, ou d'utiliser le graphique de barre pour automatiser le lancement de composants dans Kubernetes. Nous prévoyons toujours de faire un opérateur Kubernetes. Le graphique du casque ne couvre pas certains cas et vous permet de tirer sur votre jambe. Par exemple, il vous permet de réduire le nombre de nœuds de stockage, ce qui entraînera une perte de données.

Après avoir exécuté une version binaire ou de cluster, il vous suffit d'ajouter le paramètre d'URL d'écriture à distance à la configuration Prometheus afin qu'il commence à écrire des données en parallèle au stockage local et au stockage distant. Comme vous l'avez remarqué, cette configuration devrait fonctionner de manière beaucoup plus fiable par rapport à la configuration de Thanos. Nous n'avons pas besoin de garder VictoriaMetrics connecté à tous les Prometheus, car les Prometheus eux-mêmes se connectent à VictoriaMetrics et transmettent les données.

Considérez les escortes Thanos et VictoriaMetrics.

Thanos doit garder un œil sur Sidecar afin qu'il n'arrête pas de charger des données dans Object Storage. Ils peuvent arrêter ce chargement de données en raison d'erreurs de chargement, par exemple, votre connexion réseau avec Object Storage est temporairement déconnectée ou Object Storage est temporairement indisponible. Thanos Sidecar le remarquera en ce moment, signalera une erreur, pourrait tomber et cesser de fonctionner. Si vous ne le surveillez pas, vos données ne seront plus transférées vers Object Storage. Si le temps de rétention passe (6-8 heures recommandées), vous perdrez des données qui ne sont pas tombées dans Object Storage.

Les compacteurs Thanos peuvent cesser de fonctionner en raison de la course avec Sidecar . Les compacteurs prennent les données d'Object Storage et les fusionnent en de plus gros morceaux de données. Comme les compacteurs ne sont pas synchronisés avec le Sidecar, cela peut arriver: Sidecar n'a pas encore fini d'écrire le bloc, Compactor décide que ce bloc est complètement enregistré. Le compacteur commence à le lire. Il ne lit pas le bloc dans son intégralité et cesse de fonctionner. Voir les détails ici .

Store Gateway peut fournir des données incohérentes en raison de la course entre Compactor et Sidecar. C'est la même chose, car le Store Gateway n'est en aucun cas synchronisé avec Compactor et Sidecar. Par conséquent, une condition de concurrence critique peut se produire lorsque la passerelle de stockage ne voit pas une partie des données ou voit des données en excès.

Le composant Query dans Thanos utilise par défaut des résultats partiels si certains Sidecar ou Store Gateway ne sont pas actuellement disponibles. Vous recevrez une partie des données et vous ne saurez même pas que toutes les données n'ont pas été reçues. Que cela fonctionne comme ça par défaut. Dans une situation similaire, VictoriaMetrics renvoie les données marquées comme partielles.

Contrairement à Thanos, VictoriaMetrics perd rarement des données. Même si la connexion de Prometheus à VictoriaMetrics est interrompue, ce n'est pas un problème, car Prometheus continue d'enregistrer les nouvelles données entrantes dans Write Ahead Log, qui a une taille de 2 heures. Si vous vous reconnectez à VictoriaMetrics dans les deux heures, les données ne seront pas perdues. Prometheus peut ajouter des données après une reconnexion à VictoriaMetrics .

Contrairement à Thanos, qui n'écrit les données dans le stockage d'objets qu'après deux heures, Prometheus réplique automatiquement les données via le protocole d'écriture à distance vers le stockage à distance, comme VictoriaMetrics. Vous n'avez pas peur de perdre le stockage local dans Prometheus. S'il a soudainement perdu le stockage local, dans le pire des cas, vous perdrez les dernières secondes de données qui n'ont pas eu le temps d'écrire sur le stockage distant.

Kubernetes gère automatiquement le cluster, contrairement à Thanos. Tous les composants Thanos sont difficiles à mettre dans un seul cluster Kubernetes, contrairement aux composants du cluster VictoriaMetrics.

VictoriaMetrics propose une mise à niveau très simple vers la nouvelle version. Arrêtez simplement VictoriaMetrics, mettez à jour les fichiers binaires et exécutez. Lors de l'arrêt via un signal SIGINT, tous les binaires VictoriaMetrics effectuent un arrêt gracieux. Ils enregistrent correctement les données nécessaires, ferment correctement les connexions entrantes afin de ne rien perdre. Par conséquent, vous ne perdrez rien lors de la mise à niveau.

VictoriaMetrics propose un moyen très simple de développer un cluster. Ajoutez simplement les composants nécessaires et continuez à travailler.

À propos des pièges de Thanos et Victoria Metrics.

Thanos a les pièges suivants. Prometheus doit stocker les données des deux dernières heures. S'ils sont perdus, vous les perdrez complètement, car ils n'ont pas encore réussi à s'enregistrer dans Object Storage, comme S3.

Le composant Store Gateway et le composant compacteur peuvent nécessiter beaucoup de mémoire pour fonctionner avec un stockage d'objets volumineux si de nombreux petits fichiers y sont stockés. Plus le nombre et le volume de fichiers sont importants, plus la passerelle de stockage et la mémoire du compacteur sont nécessaires pour stocker des méta-informations. Thanos a beaucoup de problèmes avec la perte de la passerelle de stockage et du compacteur avec des données enregistrées moyennes .

Thanos est vanté qu'il peut évoluer indéfiniment en fonction de la quantité de votre Prométhée. Ce n'est en fait pas vrai. Étant donné que toutes les demandes passent par le composant Query, qui doit interroger simultanément tous les composants Store Gateway et tous les composants Sidecar, extraire les données à partir de là, puis les prétraiter. De toute évidence, la vitesse de requête est limitée par le maillon faible le plus lent, la passerelle de magasin la plus lente ou le Sidecar le plus lent.
Ces composants peuvent être inégalement chargés. Par exemple, vous avez un Prométhée qui collecte des millions de métriques par seconde. Et il y a Prometheus, qui collecte des milliers de métriques par seconde. Prometheus, qui collecte des millions de métriques par seconde, charge bien plus le serveur sur lequel il s'exécute. En conséquence, Sidecar y est plus lent. En général, tout y fonctionne lentement. Et le composant Query extraira les données très lentement à partir de là. En conséquence, les performances de l'ensemble de votre cluster seront limitées par ce lent Sidecar.

Par défaut, Thanos renvoie des données partielles si certains Sidecar et Store Gateway ne sont pas disponibles. Par exemple, si Sidecar est dispersé dans le monde entier dans différents centres de données, la probabilité de déconnexion et d'indisponibilité des composants augmente considérablement. En conséquence, dans la plupart des cas, vous recevrez des données partielles sans même le savoir.

VictoriaMetrics a également des pièges. Le premier écueil est une option qui limite la quantité de RAM utilisée pour le cache VictoriaMetrics. Par défaut, il est égal à 60% de la RAM sur la machine sur laquelle VictoriaMetrics s'exécute, ou 60% de la RAM du pod VictoriaMetrics dans Kubernetes.
Si vous modifiez incorrectement cette valeur, vous pouvez ruiner les performances de VictoriaMetrics. Par exemple, si vous définissez une valeur trop faible, les données risquent de ne plus tenir dans le cache VictoriaMetrics. Pour cette raison, elle devra faire un travail supplémentaire et charger le processeur avec le disque. Si vous rendez cette option trop grande, cela augmente, d'une part, la probabilité que VictoriaMetrics se bloque avec une erreur de mémoire insuffisante, et, d'autre part, cela entraînera très peu de mémoire opérationnelle dans le système d'exploitation. mémoire pour le cache de fichiers. Et VictoriaMetrics s'appuie sur un cache de fichiers pour les performances. Si cela ne suffit pas, la charge sur le disque peut augmenter considérablement. Par conséquent, un conseil: ne modifiez pas le paramètre à moins que cela ne soit absolument nécessaire.
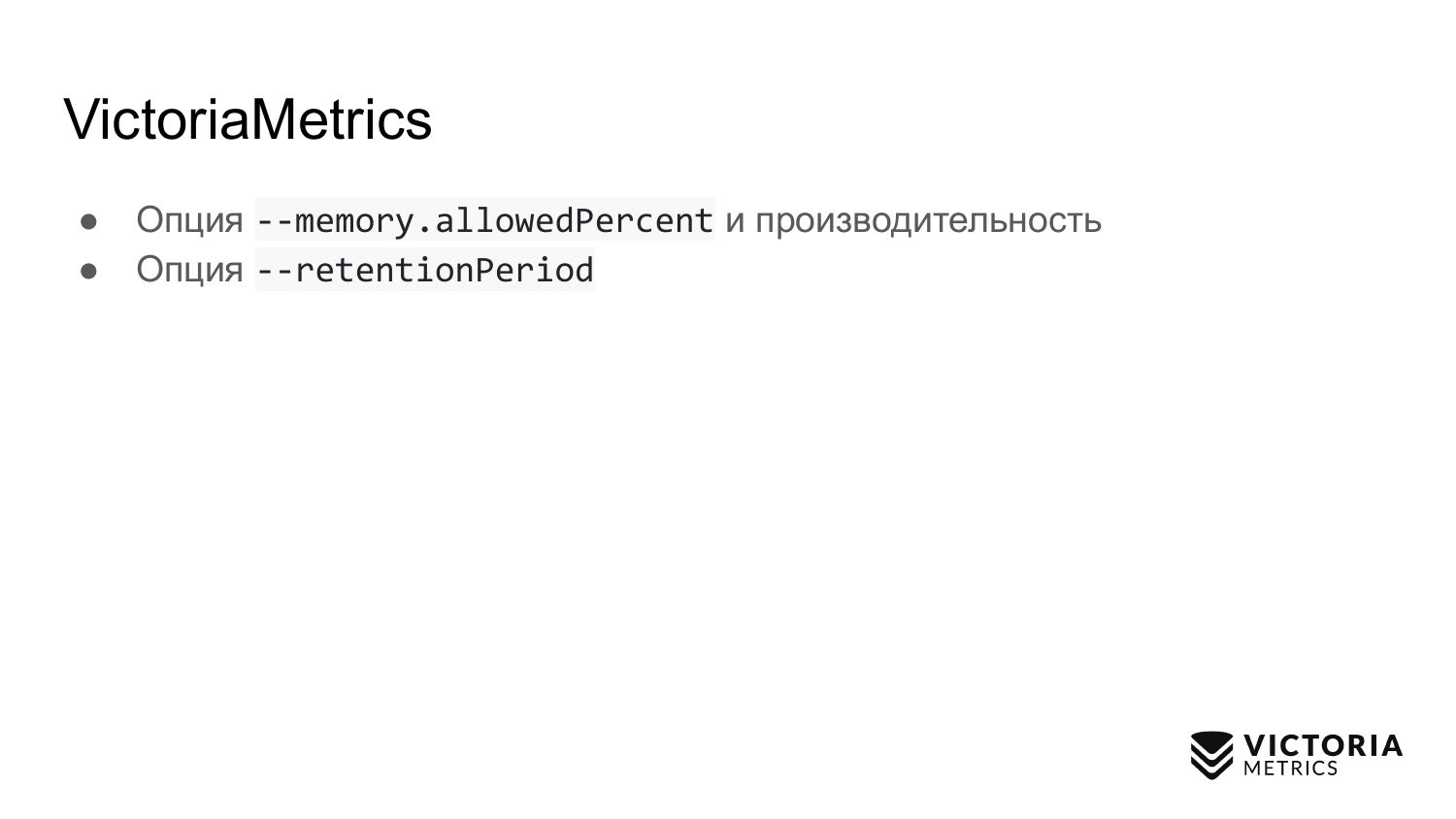
La deuxième option. Il s'agit de retentionPeriod - la période définie sur 1 mois par défaut. C'est le moment où VictoriaMetrics stocke les données. Après cette période, VictoriaMetrics supprime les données.
Beaucoup exécutent VictoriaMetrics sans ce paramètre, ils enregistrent des données pendant un mois. Et puis ils demandent: pourquoi les données ont-elles disparu pour le mois précédent? Parce que retentionPeriod est de 1 mois par défaut. Par conséquent, vous devez connaître et définir la période de rétention correcte.

Passons en revue les opportunités uniques.

Thanos a une fonctionnalité telle que le sous-échantillonnage: intervalles de 5 minutes et heures, qui souvent ne fonctionnent pas correctement . Si vous le recherchez sur Google et examinez leur problème sur github, il y a beaucoup de problèmes liés à ce sous-échantillonnage, qui parfois ne fonctionnent pas correctement ou ne fonctionnent pas comme les utilisateurs s'y attendent.

Thanos propose la déduplication des données pour les paires Prometheus HA. Lorsque deux Prometheus'a collectent les mêmes métriques de la même cible'et Thanos les place dans le stockage d'objets. Thanos , VictoriaMetrics.

Thanos alert , Thanos. production .

Thanos , Thanos Prometheus — . Thanos Prometheus . Thanos Prometheus .

VictoriaMetrics — MetricsQL. VictoriaMetrics PromQL, big monitoring metup.

VictoriaMetrics . VictoriaMetrics Prometheus, Influx, OpenTSDB Graphite.

VictoriaMetrics Thanos Prometheus.
, 2-5 Prometheus Thanos.

VictoriaMetrics — .

.

Thanos , object storage, .
object storage, ($10 ). object storage, , AWS — . , $10 $230 1. , Thanos .

Thanos Compact, Store Gateway, Query , , .

VictoriaMetrics . GCE HDD , $40 1. VictoriaMetrics HDD , SSD, . VictoriaMetrics HDD.

VictoriaMetrics a besoin de serveurs pour les composants: Single-nod ou pour les composants de cluster, qui, contrairement aux composants de Thanos, nécessitent beaucoup moins de CPU, de RAM - ce sera moins cher en conséquence.

Exemples de mise en œuvre.

L'exemple d'implémentation de Thanos est Gitlab. Gitlab est entièrement propulsé par Thanos. Mais il n'y a pas si lisse. Si vous regardez leurs problèmes , vous pouvez voir qu'ils ont constamment des problèmes de fonctionnement avec Thanos : il n'y a pas assez de mémoire pour les composants Store Gateway ou Query. Ils doivent constamment augmenter la quantité de mémoire.
De ce fait, les coûts de résolution de ces problèmes augmentent.
La deuxième implémentation, qui peut être plus réussie, est la société Improbable, qui a commencé le développement de Thanos. Ils ont publié la source de Thanos. Improbable est une entreprise qui développe des moteurs de jeux.

Exemples de mise en œuvre publique de VictoriaMetrics:
- Constructeur de site wix.com
- Adidas présente VictoriaMetrics et a même fait une présentation lors du dernier PromCon 2019
- TrafficStars - réseau publicitaire
- Seznam.cz est un moteur de recherche tchèque populaire.
Et puis je suis allé au nom de la société, que je ne peux pas nommer maintenant. Ils n'étaient pas d'accord.
- Un développeur de jeux majeur. Plus grand qu'eux Improbable.
- Un développeur de logiciels graphiques majeur.
- Grande banque russe.
- Fabricant européen d'éoliennes qui a testé avec succès VictoriaMetrics. Ce fabricant met en œuvre VictoriaMetrics pour surveiller les données des éoliennes à une vitesse de 50 échantillons par seconde par capteur. Chaque éolienne possède plusieurs centaines de capteurs. Ils ont plusieurs centaines d'éoliennes.
- Les compagnies aériennes russes qui souhaitent introduire VictoriaMetrics, mais ne le peuvent toujours pas. Nous sommes au stade du contrat avec eux.
 Conclusions
Conclusions
VictoriaMetrics et Thanos résolvent des problèmes similaires, mais de différentes manières:
- Vue de requête globale
- mise à l'échelle horizontale
- rétention arbitraire

Je vous remercie
Nous vous attendons sur notre chaîne télégramme .
