Salut Habr! Les ensembles de données pour le Big Data et l'apprentissage automatique connaissent une croissance exponentielle et doivent être traités. Notre article sur une autre technologie innovante en calcul haute performance (HPC), présentée sur le stand de Kingston au
Supercomputing 2019 . Il s'agit de l'utilisation de systèmes de stockage haut de gamme (SHD) dans des serveurs dotés de processeurs graphiques (GPU) et de la technologie de bus de stockage GPUDirect. Grâce à l'échange de données direct entre le stockage et les GPU, en contournant le CPU, le chargement des données dans les accélérateurs de GPU est accéléré d'un ordre de grandeur, donc les applications Big Data fonctionnent aux performances maximales fournies par le GPU. À leur tour, les développeurs de systèmes HPC sont intéressés par les réalisations dans le domaine du stockage avec la vitesse d'entrée / sortie la plus élevée - comme celles publiées par Kingston.

Performances du GPU avant le chargement des données
Depuis la création de CUDA, une architecture informatique parallèle matérielle et logicielle basée sur GPU pour le développement d'applications à usage général, en 2007, les capacités matérielles des GPU elles-mêmes se sont considérablement accrues. Aujourd'hui, les GPU sont de plus en plus utilisés dans le domaine des applications HPC telles que le Big Data, le machine learning et le deep learning.
Notez que malgré la similitude des termes, les deux derniers sont des tâches algorithmiquement différentes. ML enseigne un ordinateur basé sur des données structurées, et DL enseigne un ordinateur basé sur la réponse d'un réseau neuronal. Un exemple qui aide à comprendre les différences est assez simple. Supposons qu'un ordinateur doit distinguer les photos de chats et de chiens chargées du stockage. Pour ML, vous devez soumettre un ensemble d'images avec de nombreuses balises, chacune définissant une caractéristique particulière de l'animal. Pour DL, il suffit de télécharger un nombre d'images beaucoup plus important, mais avec une seule étiquette "c'est un chat" ou "c'est un chien". DL est très similaire à la façon dont les jeunes enfants sont enseignés - on leur montre simplement des images de chiens et de chats dans les livres et dans la vie (le plus souvent, sans même expliquer la différence détaillée), et le cerveau de l'enfant lui-même commence à déterminer le type d'animal après un certain nombre critique d'images à comparer ( selon les estimations, on parle de cent ou deux impressions pour tout le temps de la petite enfance). Les algorithmes DL ne sont pas encore aussi parfaits: pour réussir à travailler sur la définition d'images d'un réseau neuronal, il est nécessaire de soumettre et de traiter des millions d'images dans le GPU.
Résultat de la préface: sur la base du GPU, vous pouvez créer des applications HPC dans le domaine des Big Data, ML et DL, mais il y a un problème - les ensembles de données sont si importants que le temps nécessaire pour charger les données du système de stockage vers le GPU commence à réduire les performances globales de l'application. En d'autres termes, les GPU rapides restent sous-chargés en raison de la lenteur d'entrée / sortie des données d'autres sous-systèmes. La différence de vitesse d'entrée / sortie du GPU et du bus vers le CPU / SHD peut être d'un ordre de grandeur.
Comment fonctionne la technologie de stockage GPUDirect?
Le processus d'entrée / sortie est contrôlé par le CPU, ainsi que le processus de chargement des données du stockage dans les GPU pour un traitement ultérieur. Cela a déclenché une demande de technologie qui fournirait un accès direct entre les disques GPU et NVMe pour une interaction rapide entre eux. La première de ces technologies a été proposée par NVIDIA et l'a appelée GPUDirect Storage. En fait, il s'agit d'une variante de la technologie GPUDirect RDMA (Remote Direct Memory Address) qu'ils ont précédemment développée.
 Jensen Huang, PDG de NVIDIA, présente GPUDirect Storage comme une variante de GPUDirect RDMA au SC-19. Source: NVIDIA
Jensen Huang, PDG de NVIDIA, présente GPUDirect Storage comme une variante de GPUDirect RDMA au SC-19. Source: NVIDIALa différence entre GPUDirect RDMA et GPUDirect Storage réside dans les périphériques entre lesquels l'adressage est effectué. La technologie GPUDirect RDMA est réaffectée pour déplacer les données directement entre la carte d'entrée d'interface réseau (NIC) et la mémoire GPU, et le stockage GPUDirect fournit un chemin de transfert de données direct entre le stockage local ou distant, tel que NVMe ou NVMe via Fabric (NVMe-oF) et la mémoire GPU.
Les deux options, GPUDirect RDMA et GPUDirect Storage, évitent les mouvements de données inutiles à travers un tampon dans la mémoire du processeur et permettent au mécanisme DMA (Direct Memory Access) de transférer des données depuis une carte réseau ou un stockage directement vers ou depuis la mémoire GPU - le tout sans charge sur la centrale processeur Pour GPUDirect Storage, l'emplacement de stockage n'a pas d'importance: il peut s'agir d'un disque NVME à l'intérieur d'une unité GPU, à l'intérieur d'un rack ou connecté via un réseau en tant que NVMe-oF.
 Schéma d'opération de stockage GPUDirect. Source: NVIDIA
Schéma d'opération de stockage GPUDirect. Source: NVIDIAStockage haut de gamme NVMe requis sur le marché des applications HPC
Comprenant qu'avec l'avènement de GPUDirect Storage, l'intérêt des grands clients sera tourné vers l'offre de systèmes de stockage avec une vitesse d'entrée / sortie correspondant à la bande passante du GPU, Kingston a montré un système de démonstration composé de systèmes de stockage basés sur des disques NVMe et d'une unité avec un GPU au SC-19 qui a analysé des milliers d'images satellites par seconde. Nous avons déjà écrit sur un tel stockage sur la base de 10 disques DC1000M U.2 NVMe
dans un rapport de l'exposition des supercalculateurs .
 Le stockage basé sur 10 disques DC1000M U.2 NVMe complète adéquatement le serveur avec des accélérateurs graphiques. Source: Kingston
Le stockage basé sur 10 disques DC1000M U.2 NVMe complète adéquatement le serveur avec des accélérateurs graphiques. Source: KingstonUn tel stockage est effectué sous la forme d'une unité de rack 1U ou plus et peut être mis à l'échelle en fonction du nombre de disques NVMe DC1000M U.2, chacun ayant une capacité de 3,84 à 7,68 To. Le DC1000M est le premier modèle SSD NVMe au format U.2 de la gamme de disques Kingston pour centres de données. Il a une cote d'endurance (DWPD, Drive écrit par jour), ce qui vous permet d'écraser les données à pleine capacité une fois par jour pour une durée de vie du lecteur garantie.
Dans le test fio v3.13 sur le système d'exploitation Ubuntu 18.04.3 LTS, noyau Linux 5.0.0-31-générique, le modèle de stockage d'exposition a montré une vitesse de lecture soutenue de 5,8 millions d'IOPS avec une bande passante soutenue de 23,8 Gb / s.
Ariel Perez, directeur commercial des SSD de Kingston, a décrit les nouveaux systèmes de stockage comme suit: «Nous sommes prêts à fournir à la prochaine génération de serveurs des SSD U.2 NVMe pour résoudre de nombreux goulots d'étranglement de transfert de données qui étaient traditionnellement associés au stockage. La combinaison de disques SSD NVMe et de notre DRAM Server Premium Premium fait de Kingston l'un des fournisseurs de processeurs de données de bout en bout les plus complets du secteur. »
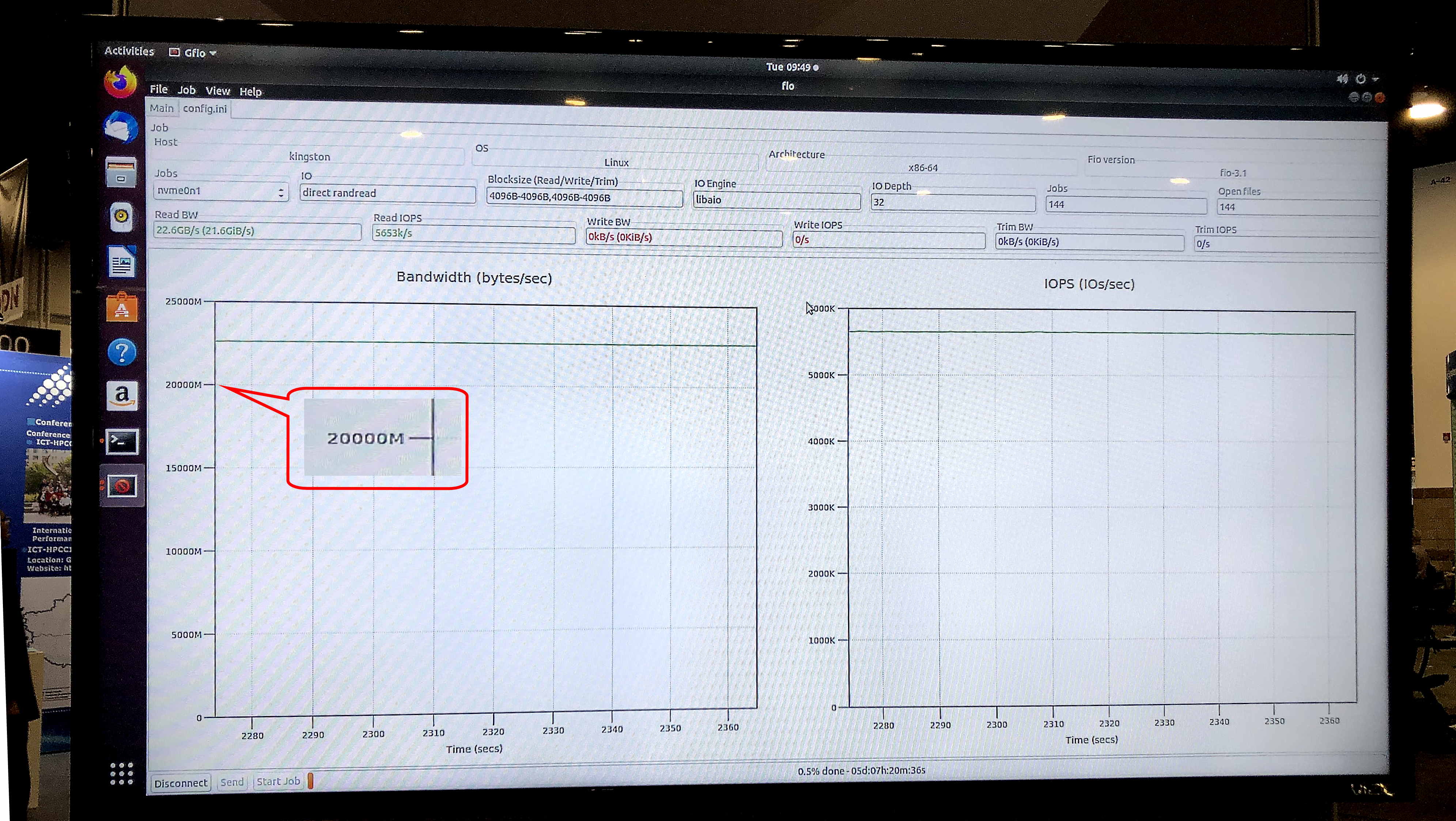 Le test gfio v3.13 a montré une bande passante de 23,8 Gb / s pour le stockage de démonstration sur les disques NVMe DC1000M U.2. Source: Kingston
Le test gfio v3.13 a montré une bande passante de 23,8 Gb / s pour le stockage de démonstration sur les disques NVMe DC1000M U.2. Source: KingstonÀ quoi ressemblera un système typique pour les applications HPC qui utilisent la technologie de stockage GPUDirect ou similaire? Il s'agit d'une architecture avec séparation physique des blocs fonctionnels au sein d'un rack: une ou deux unités pour la RAM, quelques autres pour les nœuds de calcul GPU et CPU, et une ou plusieurs unités pour le stockage.
Avec l'annonce de GPUDirect Storage et l'émergence possible de technologies similaires chez d'autres fournisseurs de GPU, Kingston élargit sa demande de systèmes de stockage conçus pour une utilisation dans le calcul haute performance. Le marqueur sera la vitesse de lecture des données du système de stockage, comparable à la bande passante des cartes réseau 40 ou 100 Gbit à l'entrée d'une unité informatique avec un GPU. Ainsi, les systèmes de stockage ultra-rapides, y compris les NVMe externes via Fabric, de l'exotic deviendront courants pour les applications HPC. En plus des calculs scientifiques et financiers, ils trouveront une application dans de nombreux autres domaines pratiques, tels que les systèmes de sécurité au niveau de la mégalopole Safe City ou les centres de surveillance sur les véhicules où la reconnaissance et l'identification de la vitesse de millions d'images HD par seconde sont nécessaires », la niche de marché du top SHD
Des informations supplémentaires sur les produits Kingston sont disponibles sur
le site officiel de l'entreprise .