Le 14 mars 2017, Arthur Khachuyan, PDG de Social Data Hub, a pris la parole dans la salle de conférence BBDO. Arthur a parlé de la surveillance intelligente, de la création de modèles comportementaux, de la reconnaissance du contenu photo et vidéo, ainsi que d'autres outils et études du Social Data Hub, qui vous permettent de cibler votre public à l'aide des réseaux sociaux et des technologies Big Data.
 Arthur Khachuyan (ci-après - AH):
Arthur Khachuyan (ci-après - AH): - Bonjour! Bonjour à tous! Je m'appelle Arthur Khachuyan, je dirige la société Social Data Hub, et nous sommes engagés dans diverses analyses intellectuelles intéressantes des sources de données ouvertes, des champs d'information et faisons toutes sortes d'études intéressantes, etc.
Et aujourd'hui, des collègues du groupe BBDO ont demandé à parler des technologies modernes pour l'analyse des mégadonnées, des mégadonnées et pas tant de données pour la publicité: comment elles sont utilisées, montrent quelques exemples intéressants. J'espère que vous poserez des questions en cours de route, car je peux commencer à ennuyer et à ne pas révéler l'essence et ainsi de suite, alors ne soyez pas timide.
En fait, les principales directions, quelque part où des solutions «à gros chiffres» ont été utilisées, elles sont toutes claires - il s'agit du ciblage, de l'analyse du public, d'une sorte d'analyse et de recherche marketing. Mais il est toujours intéressant de savoir quelles données supplémentaires peuvent être trouvées, quelles significations supplémentaires peuvent être trouvées après l'application de l'analyse.
Pourquoi avons-nous besoin de technologie pour la publicité?
Par où commencer? La plus compréhensible est la publicité sur les réseaux sociaux. Aujourd'hui, je l'ai filmé le matin: pour une raison quelconque, Vkontakte pense que je devrais voir cette publicité particulière ... Pour le meilleur ou pour le pire, c'est la deuxième question. Nous voyons que je tombe dans la catégorie des recrues à coup sûr:

La toute première chose intéressante qui peut être considérée comme une solution technologique ... La première chose que je voulais résoudre avant de commencer était de définir les termes: qu'est-ce que l'open data et qu'est-ce que le big data? Parce que tout le monde a sa propre compréhension à ce sujet, et je ne veux imposer mes conditions à personne, mais ... Juste pour qu'il n'y ait pas de divergences.
Personnellement, je pense que les données ouvertes sont toutes les données auxquelles je peux accéder sans aucun identifiant ou mot de passe. Ceci est un profil ouvert sur les réseaux sociaux, ce sont les résultats de la recherche, ce sont des registres ouverts, etc. quelque part pétaoctet de données. Le reste de ma terminologie n'est pas le big data, mais quelque chose autour.
Profils de profilage et de notation très précis
Allons dans l'ordre. La première et la plus intéressante chose à laquelle vous pouvez penser à partir d'une analyse de sources de données ouvertes est le profilage et la notation de haute précision des profils. Qu'est ce que c'est C'est une histoire où vous pouvez prédire non seulement qui vous êtes, mais pas seulement vos intérêts dans votre compte de réseau social.
Mais maintenant, en combinant différentes sources, vous pouvez comprendre le niveau moyen de votre salaire, combien coûte votre appartement, où est-il situé. Et toutes ces données peuvent être utilisées littéralement à partir de moyens improvisés. Par exemple, si vous prenez votre compte sur un réseau social, voyez, disons, où vous vivez, où vous travaillez; comprendre dans quelle section de l'entreprise se trouve l'entreprise dans laquelle vous travaillez; Prenez le déchargement de postes similaires de HH et SuperJob si vous êtes un analyste, un gestionnaire, etc. voir où vous vivez (base, disons CIAN), comprendre combien cela coûte de louer une maison à cet endroit, combien cela coûte d'acheter une maison à cet endroit, de prédire combien vous gagnez. Plus loin sur vos réseaux sociaux, vous pouvez comprendre combien vous voyagez, où vous êtes, combien vous êtes fidèle à l'employeur.
En conséquence, à partir d'un si grand nombre de mesures, nous pouvons tout faire. Nous pouvons vous présenter un produit qui vous intéresse. Imaginez une boutique en ligne? Vous y allez - cette boutique en ligne attrape votre compte sur le réseau social et vous dit: "Masha, tu viens de rompre avec un mec, ici tu as certains, certains produits." Ce n'est pas un avenir proche ...
Comment déterminer la géolocalisation d'une personne
Réponses aux questions du public:- Habituellement, 80% de tous les enregistrements sont considérés comme le lieu de résidence exact. Mais pour les personnes qui ne s'enregistrent nulle part, il y a plusieurs options: soit un enregistrement, soit une géo-position, ou une analyse des publications et des publications pour toute la période où quelque chose a été écrit par une personne ... Et quelque part, laissez quelque chose arriver comme "Je veux acheter une poussette près de l'Académie" ou "J'ai récemment vu ici de vilains graffitis sur le mur". Autrement dit, près de 80% des personnes peuvent déterminer leur géolocalisation, leur lieu de travail et leur lieu de résidence en fonction de données ou de métadonnées qui peuvent être collectées sur les réseaux sociaux.
Ceci, encore une fois, est une analyse des postes. Dans le sens le plus simple, il s'agit d'une analyse des enregistrements et des géolocalisations dans les réseaux sociaux qui ne suppriment pas les métadonnées jpeg (vous pouvez analyser quelque chose dessus). Mais pour les personnes restantes, il s'agit généralement d'émissions textuelles: soit une personne «fait briller» son emplacement lorsqu'il écrit quelque chose, soit elle «fait briller» son téléphone, sur lequel vous pouvez trouver certaines de ses annonces sur Avito ou son compte sur "Auto.ru". Selon ces données, vous pouvez combiner (par exemple, "Je vends une voiture près de Mayakovskaya") et supposer à peu près cela. - Habituellement, les gens le publient sur les réseaux sociaux. Nous travaillons uniquement avec des sources ouvertes et ici, nous parlons exclusivement de sources ouvertes. Habituellement, les publicités sont publiées, c'est-à-dire 60% du temps, l'histoire la plus fréquente est lorsque les gens «font briller» leur numéro de téléphone portable actuel - ce sont des publicités pour vendre quelque chose. Soit dans certains groupes une personne écrit («Je vends ceci ou cela là-bas), soit elle va quelque part.
Oui! Ils font généralement des commentaires tels que: «Répondez-moi ou lancez un SMS, appelez-moi au numéro. Cela arrive très souvent avec des gens qui vendent quelque chose, achètent sur les réseaux sociaux, communiquent avec quelqu'un ... Par conséquent, par ce numéro, vous pouvez ensuite lui lier son profil à l'Institut Cyan, s'il a publié quelque chose, ou , encore une fois, sur Avito. Ce sont simplement les sources les plus populaires et les plus populaires, elles continueront de l'être - il s'agit d'Avito, de CIAN, etc. - Cela fait référence à une boutique en ligne. La prochaine étape sera la reconnaissance des visages et la technologie de correspondance des profils (nous en parlerons). Théoriquement, cela peut également être appliqué à un magasin hors ligne. Et en général, mon grand rêve est que lorsque des bannières de rue apparaissent, lorsque vous passez devant la caméra, cela «raye» votre visage. Mais cette affaire sera interdite par la loi, car il s'agit d'une violation de la vie privée. J'espère que ce sera tôt ou tard.
- J'ai de l'expérience personnelle. Très souvent, lorsqu'une personne vous écrit quelque chose, vous opérez sur des faits de sa vie que vous ne devriez pas savoir ... Les gens dans la plupart des cas ont peur. Mais! Sur la base de statistiques récentes, le nombre de comptes fermés sur les réseaux sociaux a diminué de 14%. Le nombre de faux augmente, le nombre de comptes ouverts augmente - les gens s'orientent de plus en plus vers l'ouverture. Je pense qu'après 3-4 ans, ils cesseront de réagir si brusquement au fait que quelqu'un connaît des informations à leur sujet qu'il ne devrait potentiellement pas connaître. Mais en fait, c'est très facile à obtenir en regardant son mur.
Que peut-on tirer des sources ouvertes?
Une liste approximative de choses qui peuvent être comprises avec une fiabilité assez élevée à partir de sources ouvertes - ça l'est. En fait, il existe encore plus de toutes sortes de métriques différentes; cela dépend du client de ces recherches. Il existe une agence RH qui souhaite savoir si vous jurez sur les réseaux sociaux ou quelque part dans l'espace public. Quelqu'un veut savoir si vous aimez les likes sous les publications de Navalny ou, inversement, sous les publications de United Russia, ou une sorte de contenu pornographique - de telles choses se produisent assez souvent.
Les principales sont les valeurs familiales, le coût approximatif d'un appartement, d'une maison, de la recherche d'une voiture, etc. Pour cette raison, les gens peuvent être divisés en groupes sociaux. Ce sont les utilisateurs du «Tinder» de Moscou, qui ils sont (selon leurs photos trouvées sur leurs comptes Facebook); en fonction de leurs intérêts, ils sont répartis en différents groupes sociaux:

Si nous nous rapprochons de la publicité, nous avons progressivement quitté le ciblage standard de la publicité lorsque vous choisissez dans le Vkontakte conditionnel qui vous intéresse les hommes de 18 ans, abonnés à certains groupes. J'ai une telle image plus loin, maintenant je vais vous montrer:

L'essentiel est que la plupart des services actuels qui analysent, en principe, les personnes qui analysent les réseaux sociaux, sont intéressés par l'analyse des intérêts ... La première chose qui vient à l'esprit des gens est d'analyser les groupes supérieurs de leurs abonnés. Peut-être que cela fonctionne avec quelqu'un, mais personnellement, je pense que c'est fondamentalement faux. Pourquoi?
Vos goûts collectent et analysent
Maintenant, prenez vos téléphones, regardez vos meilleurs groupes - il y aura certainement plus de 50% des groupes que vous avez déjà oubliés, c'est une sorte de contenu qui n'est en fait pas pertinent pour vous. Vous ne le consommez pas du tout, mais néanmoins le système vous étirera selon eux: que vous êtes abonné à des recettes, à certains groupes populaires. Autrement dit, vous violez le système qui analyse votre profil et vos intérêts ne seront pas justifiés.
Passons à autre chose ... Qu'y a-t-il? Nous supposons que le reste des gens font. Le plus, à notre avis, est une manière adéquate d'évaluer les intérêts des utilisateurs. Par exemple, à Vkontakte, il n'y a pas de flux similaire et les gens pensent que personne ne sait ce qu'ils aiment. Oui, une partie des likes a été introduite sur Instagram, nous voyons quelque chose sur Facebook, mais la plupart du contenu de certains groupes ne diffuse pas cela avec un flux commun, et les gens vivent et pensent que personne ne saura ce qu'ils aiment.
Et, après avoir collecté certains contenus de certains contenus qui nous intéressent, collecter ces messages, collecter ces goûts, puis vérifier cette personne dans cette base de données, nous pouvons déterminer avec une grande précision qui il est, quel sort il a, ce qui l'intéresse. Identifiez-vous précisément dans un groupe social particulier et interagissez avec lui.
L'achat d'une voiture change le comportement
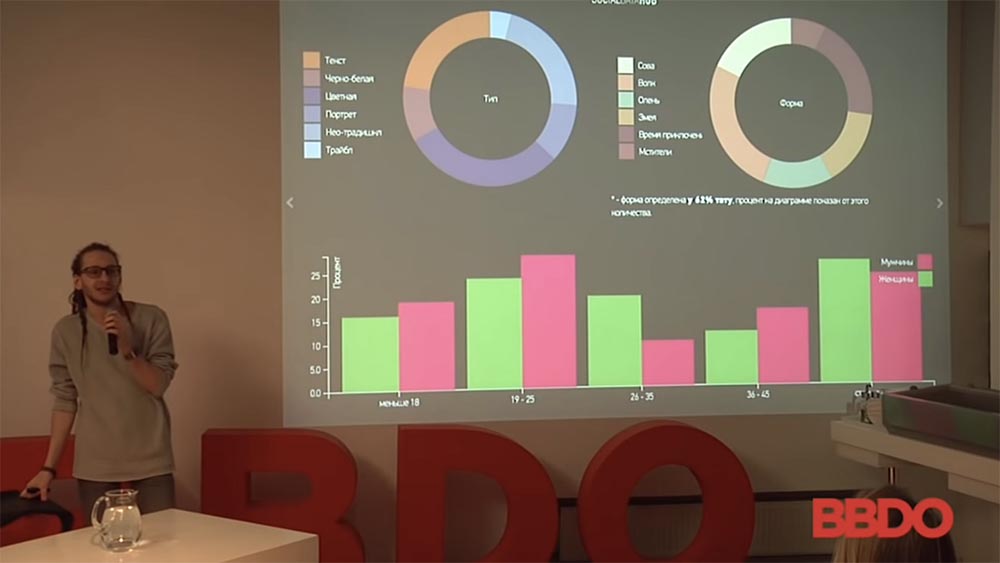
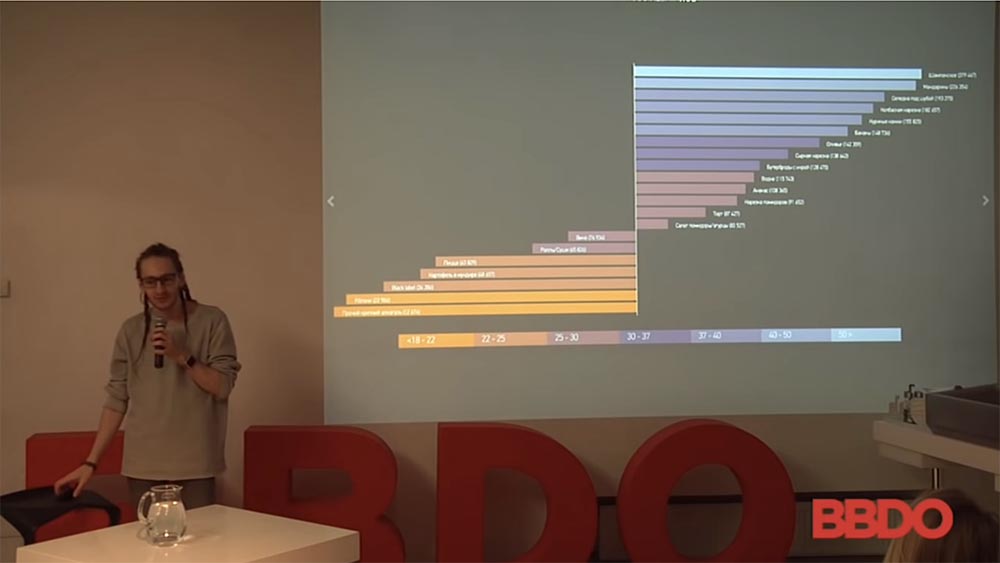
J'ai un tel exemple. Je ferai immédiatement une réservation pour avoir des exemples de quasi-publicité et de quasi-marketing, car, comme vous le savez, la plupart des cas sont protégés par la NDA, etc. Mais il y aura encore beaucoup de choses intéressantes. Alors, l'histoire avec ces gens: ce sont des hommes qui ont acheté une voiture entre 2010 et 2015. La façon dont leur comportement social sur le réseau a changé est codée par couleur. Le pourcentage de filles dans les abonnés a changé, souscrit au public "patsansky", trouvé un partenaire sexuel permanent ...

Tout cela est ventilé par marque de voiture et par nombre de personnes. De là, vous pouvez tirer de nombreuses conclusions intéressantes sur le comportement des gens, comment tout cela fonctionne. Je peux dire que la «Porsche Cayenne» et la «Priora» plantée en termes de nombre de publics attirés sont presque les mêmes. La qualité de ce public, son comportement est différent, mais le montant est à peu près le même. La conclusion d'ici peut être tirée, plus près de votre marché, peu importe. Vous vendez Audi, vous faites le slogan "Achetez Audi," éloignez-vous de vos parents! "Et ainsi de suite.
C'est oui, un exemple ridicule du fait que le comportement des gens basé sur l'analyse des goûts, sur la base du groupe auquel ils vont, du contenu qu'ils analysent, rend presque 100% probable qui vous êtes. Parce que si vous n'avez pas accès au trafic réseau, ne lisez pas les messages privés, les likes vous diront toujours qui est cette personne - une femme enceinte, une mère, des militaires, un policier. Et pour vous, comme pour une personne qui peut faire de la publicité, c'est un gros coup sur la cible.
Réponses aux questions du public:- Chaque colonne est le nombre de personnes dans une voiture donnée; comment le modèle de leur comportement a changé. Regardez: les gens qui ont acheté Porsche Cayenne - environ 550 personnes (jaune), le pourcentage de filles dans les abonnés a augmenté.
- L'échantillon comprend des utilisateurs des réseaux sociaux VKontakte, Facebook et Instagram de 2010 à 2015. Seule précision: voici des machines sélectionnées qui peuvent être déterminées avec plus de 80% de précision dans les photographies à l'aide de certains outils.
- Pendant un certain temps, sa voiture (enfin, ce n'est pas le sien, on la laisse pour les réseaux sociaux) ... Pendant un certain temps, une personne prenait constamment des photos avec une voiture, était avec lui, les publications étaient différentes, les photographies étaient sous des angles différents et ainsi de suite . Il y aura une image plus loin, avec laquelle les gens sont photographiés avec quelles machines et ... Oui, c'est la deuxième question - la confiance dans les données des réseaux sociaux.
- Depuis que nous l'avons soulevé - malheureusement, les données sur les réseaux sociaux ne sont pas toujours correctes. Les gens ne sont pas toujours enclins à publier leurs informations. Personnellement, j'ai mené une telle étude: j'ai comparé le nombre de diplômés des universités de Moscou avec le nombre de personnes inscrites sur les réseaux sociaux. En moyenne, 60% de plus de personnes sont inscrites dans les réseaux sociaux - les diplômés MSU d'une certaine année dans certaines spécialités qu'ils n'existent en principe. Alors oui - ici, bien sûr, il y a un pourcentage d'erreurs, et personne ne le cache. Ici, les voitures qui peuvent être déterminées avec une probabilité de plus de 80% sont simplement prises comme base.
Liste des sources pour la formation de modèles
Voici un exemple de liste de sources utilisables, qui permet de déterminer avec une grande certitude le profil social d'une personne, qui elle est.

À partir des réseaux sociaux, nous prenons un profil, de CIAN - le coût d'un appartement est d'environ "Head Hunter", "Super Job" - c'est le salaire moyen pour cette personne. J'espère qu'il n'y a pas de représentants de Head Hunter ici, car ils pensent qu'il n'est pas très bon de leur prendre ces données. Néanmoins, il s'agit du salaire moyen de certaines régions pour certains types d'activités professionnelles.
Avito, Avto.ru: très souvent les gens, quand ils ont allumé leur téléphone, ils ont toujours (dans un grand nombre de cas) au moins quelque chose sur Avito, ou Avto.ru, ou même plusieurs sites à partir desquels vous pouvez comprendre qui ils sont. Si vous avez vendu une poussette ou une voiture sur ce téléphone ... Rosstat et l'USRLE sont encore plus de registres avec lesquels vous pouvez classer l'entreprise employeur selon une formule, selon un modèle que toute personne peut demander (vous pouvez déterminer grossièrement l'argent de cette personne etc.).
«Tinder» aide à collecter des données sur la situation des personnes
De plus, il y a quelque chose d'intéressant (en option, très drôle dans l'étude) - cela, encore une fois, collecte des données du Moscou Tinder en utilisant des bots pour ce Tinder. La distance aux personnes a été déterminée, puis leur emplacement approximatif a été déterminé.

L'objectif de cette étude était de déterminer le nombre de comptes Tinder sur le territoire des institutions étatiques - à la Douma, au parquet, etc. Mais vous, en tant qu'annonceur, pouvez imaginer n'importe quoi: cela peut être, par exemple, Starbucks ou quelqu'un d'autre ... Autrement dit, le nombre de personnes du même Tinder qui boivent du café chez vous, commandent quelque chose, sont en magasins. Concernant cette géolocalisation: cela peut se faire avec n'importe quel service.
La réponse à une question du public:- Tinder? Tu ne sais pas? "Tinder" est une telle application de rencontres où vous visualisez des photos (gauche-droite), et cette application vous montre la distance d'une personne. Si vous obtenez la distance à cette personne à partir de trois points différents, vous pouvez approximativement (+ 5-7 mètres) déterminer l'emplacement. Dans ce cas, pour déterminer le territoire du parquet ou de la Douma, ce n'est pas si difficile. Mais, encore une fois, cela pourrait être votre magasin, ce pourrait être n'importe quoi.
Par exemple, nous avions un tel cas (pas de recherche) depuis longtemps, lorsque nous recevions des données sur la densité du flux, des données sur la densité de mouvement des points cellulaires d'un des opérateurs cellulaires, et toutes ces informations étaient superposées aux coordonnées des panneaux d'affichage situés sur les autoroutes . Et la tâche de l'opérateur mobile est de déterminer à quel point un certain nombre de personnes traversent et peuvent potentiellement voir cette publicité sur le panneau d'affichage.
S'il y a des spécialistes de la publicité sur panneau d'affichage, vous pouvez dire: il est impossible de comprendre de manière très fiable - quelqu'un voyage, quelqu'un n'a pas regardé, quelqu'un a regardé ... Néanmoins, ceci est un exemple de la façon dont 20 milliards de ces polygones à Moscou où il y a des densités de ces gens toutes les heures sur certains itinéraires ... Vous pouvez voir à tout moment ce que ces gens ont traversé et estimer grossièrement le flux de passagers.
La réponse à une question du public:- Personne ne donne de telles données. Nous avons mené une telle étude pour l'un des opérateurs, c'est une histoire exclusivement interne, donc, malheureusement, elle n'est pas présentée sous forme d'images. Mais souvent, les grandes agences de publicité n'ont aucun problème à contacter l'opérateur. Au moins à Moscou, il existe de nombreux précédents lorsque, par exemple, les compagnies d'assurance se tournent vers des sociétés telles que GetTaxi, qui fournissent des données anonymisées sur l'âge du conducteur, la façon dont il conduit (bon - mauvais, imprudent - non), pour cela. pour prévoir les politiques et ainsi de suite. Tout le monde se débat avec cela, mais à un certain niveau interne pour fournir des données anonymes - je pense que personne n'a un tel problème.
Reconnaissance d'images et d'images
Continuons. Mon préféré est la reconnaissance d'image. Il y aura un petit article sur la recherche de personnes par visages, mais nous ne prenons généralement pas cette partie. , – , .

:

. , , , . , ( ).
. , , , – - BMW X6, , , , . , .

: , ; – . : , - - ( ).

( ): . , , -, : . , - ( «») , , - . .
. , , . , .
:- – . . , , … , . Au revoir. , , - … . , . , . , - .
, , , ( ), – , .
, . , . – :
. , , . , , , : , . , , , . , - - .
. , , . , . , . .
:

, - , , . , , -, , , , , .
: , , , , ( ) , ; , , , . , . , , , .


: . , , , – , , .

– . , , , . , . , , . . , , - , - .
. - , . – , – , .

, , , , , … , , , … , :

. . , / – , Transparency International, « », . – , , « ».
, ( ), . , , . , , - . ( , ), - , , , - - – .
. : BBDO Group, . , , , …

, . , - , – , .
– , . – ; , , - . – (, ); , , , , . – , .
,
– , : , - , -, . , , , , , (, ).
– , , -, , - , , - «. » , . , , , .
, , – , . , , , ( , ). , – . , «».
– , , ; - . , «» , . , – . :

– ( ). , . – , – , . . , , , , . , . -, «» , - .
.
( , ) . , . , , . :

: « » , . , , . , «», , : , , « – », , , , . , , , - , . !
, . ! , , -. , ; ( ) , . ! …
, , , . . , . , , - , - , .
, , . .

. . … , , , , – «, 37% , – , – « ! !» : , .
, … , , , - , - - . - . - .
( , 10 ), , , , , . « », « » .
«», -
: , «» .

: , , , 2%, – « ». , – , - . , – , . , , , - .
. , ?

- , , , , . , -, , – . . , , … – ! , . , , .
:Big Data
En fait, j'ai de nombreux exemples politiques intéressants sur Trump et sur tout le monde, mais j'ai décidé de ne pas les amener ici. Mais il y a un exemple politique.
Il s'agit d'une élection à la Douma d'État. Quand étiez-vous? L'année dernière? Il y a presque un an et demi.

Voici des gens qui ont réussi à déterminer leur emplacement exact, jusqu'à un certain point géographique, afin de comprendre dans quel PEC sélectif ils se trouvent. Et puis seuls ceux qui ont exprimé leur opinion définitive ont été retirés de ces personnes, pour lesquelles ils iraient voter.
Du point de vue des technologies politiques, ce n'est pas très correct, car le tout doit être normalisé à la densité de population, etc. Néanmoins, les bleus vont voter ici, vous savez pour qui, les rouges sont pour les camarades de l'opposition qui, soit dit en passant, n'étaient pas si nombreux.
Je pense personnellement que le Big Data n'atteindra pas les technologies politiques très prochainement, mais, en option, le candidat est aussi une marque. Et c'est aussi, dans une certaine mesure, une analyse des faits et des opinions sur votre marque, et une chose assez intéressante, car vous pouvez comprendre en temps réel qui fait quoi. Je connais maintenant plusieurs cas de la BBC quand ils ont surveillé les réseaux sociaux en temps réel dans une sorte de diffusion: la réponse est telle ou telle, les gens écrivent à ce sujet, posent telle ou telle question - et c'est cool! Je pense qu'il sera appliqué très prochainement, car il est intéressant pour tout le monde.
Modélisation des positions de marque

Ensuite, je modélise les positions des marques. Une petite et courte explication sur la manière dont vous pouvez classer les marques en utilisant diverses mesures (pas comme les abonnés sur les réseaux sociaux, mais en utilisant des mesures complexes, l'intérêt pour le contenu, le temps passé à obtenir des mesures).

J'ai un exemple pour une «ferme» pour un certain. Ici, les petits cercles ronds sont internes, lumineux - c'est la quantité de contenu texte que la marque crée, les grands cercles ronds - c'est la quantité de contenu photo et vidéo que la marque crée.
La proximité du centre montre à quel point ce contenu est intéressant pour le public. Il y a un grand modèle, il y a beaucoup de toutes sortes de paramètres: likes, reposts, temps de réponse, qui y ont partagé en moyenne ... Ici vous pouvez voir: il y a un merveilleux "Kagocel" qui dépense beaucoup d'argent pour créer votre propre contenu, et de ce fait ils sont assez proches au centre. Et il y a des camarades qui créent aussi leur contenu, mais ce n'est pas intéressant pour le public. Ce n'est pas un exemple très adéquat, car tous ces comptes sont presque morts.
Yegor Creed aime plus que Basta

Malheureusement, le reste ... de quoi montrer ... Ici, il y a encore des rappeurs russes, en option, de vraies compagnies.
Quel est le plus? Le fait qu'une entreprise puisse mettre presque tout dans un tel modèle, à partir du salaire moyen des abonnés de votre marque; n'importe quel modèle qu'ils aiment. Parce que chaque agence de publicité considère ses propres métriques différemment, les marques considèrent leurs propres métriques différemment.
Il y en a aussi un ici - Basta, qui génère une grande quantité de contenu, mais est situé à la périphérie, car ce contenu, apparemment, n'est pas très intéressant pour le public. Encore une fois, je ne prétends pas juger. Néanmoins, il y a Yegor Creed, qui, selon les réseaux sociaux, est presque le meilleur interprète de notre temps, et en même temps ne publie que ses photos personnelles. Néanmoins, il compte un grand nombre d'abonnés: il y en a environ un million. Je ne me souviens pas du montant exact; Je me souviens que le pourcentage d'implication de ces personnes est bien supérieur à 85%, c'est-à-dire que pour un million d'abonnés, il reçoit 850 000 réponses de ces personnes réelles - c'est une vraie folie. C'est vrai.
 Réponses aux questions du public:
Réponses aux questions du public:Combien de temps a-t-il fallu pour compiler un modèle d'analyse de rappeur?
- Chacun a son propre public cible, ses intérêts, ces gens sont comptés ... Tout cela est normalisé à une distance du centre, leur position radiale n'est pas importante (c'est juste barbouillé ici pour la beauté, afin qu'ils ne se rencontrent pas). Seule la proximité approximative du centre est importante. C'est le modèle que nous utilisons. Par exemple, j'aime plus le cercle, quelqu'un le fait en pensant à un demi-cercle.
- Ce modèle a été compilé rapidement, en deux heures, en trois (oui, une personne). Ici, exclusivement des métriques ont été insérées: ce que nous multiplions, ajoutons, puis normalisons en quelque sorte. Dépend du modèle. Il y a des gens qui s'intéressent au salaire moyen (ce n'est pas une blague) de leurs abonnés. Et pour cela, vous devez trouver leurs contacts, "Avito", tout cela pour calculer, multiplier. Cela arrive, cela prend beaucoup de temps, mais plus précisément (pointe vers la diapositive précédente) - voici des paramètres très simples: abonnés, reposts, etc. Cela a pris environ deux à trois heures. En conséquence, cette chose est ensuite mise à jour en temps réel, elle peut être utilisée.
Maintenant, la partie amusante. J'ai tout avec des exemples, car ce n'est pas intéressant de parler seul longtemps. Et j'espère que vous allez maintenant poser des questions, et nous irons plus loin, de sujet en sujet, parce que j'ai des exemples de la façon dont les technologies peuvent être utilisées et ainsi de suite ...
Réponses aux questions du public:- J'avais un seul et unique cas personnel avec un, pour ainsi dire, okolokazino, lorsque la caméra a été placée là-bas, les visages ont été reconnus, etc. Le pourcentage de personnes reconnues est certainement assez important - ce que nous avons, ce que nos concurrents ont. Mais en fait, c'est assez intéressant. Je vois cela comme une chose intéressante: vous pouvez comprendre qui sont ces gens et prédire assez bien pourquoi ils sont venus ici, ce qui a changé dans leur vie, qu'ils ont décidé de venir au casino. Mais à propos de types d’entreprises spécifiques ... Si vous mettez une telle chose dans une pharmacie, cela n’a aucun sens - vous ne pouvez pas prédire pourquoi une personne est venue dans une pharmacie.
La tâche globale ici était de construire un modèle afin de comprendre quand une personne pourrait potentiellement intéresser votre marque, de lui donner une publicité non pas après avoir acheté quelque chose (comme c'est le cas actuellement), mais de lui donner une publicité "dans les prévisions" de quand tout se passe. Avec un tel "okolokazino", c'était intéressant; là, un pourcentage assez intéressant de ces personnes s'est avéré - pourquoi: quelqu'un a soudainement obtenu une augmentation, quelqu'un d'autre quelque chose - de telles perspectives intéressantes. Mais avec certains magasins, avec la vente au détail, avec un magasin de pilules, il me semble que ce ne sera pas très juste.
Le Big Data est-il utilisé hors ligne?
- C'était hors ligne. Vous avez juste besoin de comprendre exactement, approximativement - ce modèle convergera, ne convergera pas. Encore une fois, avec l'eau gazeuse ... Je m'intéresse en fait à tout, mais personnellement, je ne comprends pas à quel point le profil de ces personnes, leur comportement, dépendent du moment où ils veulent acheter de l'eau en bouteille. Bien que cela puisse être vrai, je ne sais pas.
Combien de comptes ouverts sur les réseaux sociaux?
- Nous avons spécifiquement 11 réseaux sociaux - c'est Vkontakte, Facebook, Twitter, Odnoklassniki, Instagram et quelques petites choses là-bas (je peux voir la liste, comme Mail.ru et ainsi de suite). «Vkontakte», nous avons certainement une copie de tous ces camarades. Nous avons des Vkontakte - c'est 430 millions de tous ceux qui ont jamais existé (dont environ 200 millions sont constamment actifs); il y a des groupes, il y a des liens entre ces gens, et il y a du contenu qui nous intéresse (texte), et une partie des médias, mais très petit ... Grosso modo, on regarde cette photo: s'il y a des visages, on les sauve, si le memesic on l'utilise Nous n'économisons pas, car même avec nous, il n'y aurait pas assez de quoi que ce soit pour préserver le contenu multimédia.
Il existe un Facebook en langue russe. Quelque part maintenant, 60 à 80% sont Odnoklassniki, dans quelques mois, nous les aurons probablement tous à la fin. "Instagram" russe. Pour tous ces réseaux sociaux, il y a des groupes, des gens, des liens entre eux et le texte. - Environ 400 millions de personnes. Il y a une subtilité: il y a des gens qui n'ont pas de ville (ils sont potentiellement russes / non russes); d'entre eux en moyenne sur les réseaux sociaux, ici - sur Vkontakte - 14% des comptes fermés, je ne connais pas le nombre exact sur Facebook.
- Sur Instagram, nous n'enregistrons pas non plus de médias - uniquement s'il y a des visages. Nous n'enregistrons pas ce (autre) contenu multimédia. Habituellement intéressant: juste du texte, la communication entre les gens; c'est tout. La recherche Instagram la plus fréquente est la recherche habituelle par public: qui sont ces personnes, comme la chose la plus importante ici est la connexion de ces personnes avec d'autres réseaux sociaux. Retrouvez le profil de cette personne sur Vkontakte et Facebook afin de calculer son âge et ainsi de suite.
- Jusqu'à présent, il n'est pas nécessaire de prendre tout le monde - simplement parce qu'il n'y a pas de clients. En ce qui concerne la langue: nous avons le russe, l'anglais, l'espagnol, mais il est encore utilisé jusqu'à présent exclusivement pour les marques de Russie; ou des entreprises qui les dirigent depuis la Russie.
- Chaque jour, nous interviewons des personnes dans de très nombreux flux: nous collectons des données en collectant le web, et nous mettons à jour ces indicateurs à l'aide d'Api. En 2-3 jours, vous pouvez parcourir l'ensemble du Vkontakte, après les avoir scannés; quelque part dans une semaine, vous pouvez parcourir l'ensemble de Facebook, en réalisant qui a mis à jour, ce qui ne l'est pas. Et puis ces personnes devraient être rassemblées séparément: ce qui a exactement changé, pour écrire toute cette histoire. À ma mémoire, il est très rare qu'une tâche commerciale réelle utilise l'ancien profil de quelqu'un sur les réseaux sociaux. C'était le moment où un politicien s'est approché, et sa tâche était de comprendre quel genre de personnes sont venues au siège, qui étaient ces personnes il y a 6-8 mois (n'ont-ils pas supprimé leur profil, mais en fait pour un autre candidat, les bulletins de vote sont venus gâcher).
Et quelques fois - des histoires personnelles lorsque les photos de quelqu'un ont été publiées publiquement. Il a fallu trouver des connexions, etc. Malheureusement, c'est très pathétique, mais nous ne pouvons pas témoigner devant les tribunaux, car notre base est juridiquement illiquide. - Le référentiel MongoDB est mon préféré.
Les réseaux sociaux ont du mal avec la collecte de données
- Habituellement, nous, les annonceurs, déchargeons uniquement la liste de ces comptes, puis ils utilisent la norme ... C'est-à-dire que sur les réseaux sociaux, à Vkontakte, vous pouvez spécifier une liste de ces personnes.
Mais pour Facebook, les cookies achetés sont utilisés. Nous ne travaillons pas nous-mêmes avec les cookies, mais il y a eu plusieurs histoires lorsque l'annonceur lui-même a donné des gens, nous avons interagi avec eux - ils ont ces réseaux, avec des publicités teaser, non teaser, ces cookies. Vous pouvez lier - pas question! Mais je n'aime pas vraiment ces choses, car je pense que ce n'est pas très fiable. C'est pur à mon avis, c'est comme TNS, qui "diffuse" les téléviseurs - il n'est pas clair si vous regardez ce téléviseur, ne regardez pas, vous lavez la vaisselle pendant que votre téléviseur fonctionne ... Et la même chose ici: je google très souvent quelque chose Internet, mais cela ne signifie pas que je veux l'acheter. - Si vous utilisez un réseau standard d'une sorte de publicité contextuelle: j'ai eu plusieurs histoires lorsque nous leur avons déchargé ces personnes, j'ai essayé d'utiliser leurs interfaces pour les lier avec des «cookies» sur leurs sites. Mais je n'aime pas vraiment de telles choses.
Formule de paie des utilisateurs Internet
- La formule générale du salaire moyen: c'est la région où vit la personne, c'est la catégorie d'entreprise dans laquelle elle travaille (c'est-à-dire l'entreprise qui est son employeur), puis son poste dans cette entreprise est pris, le salaire moyen dans ce poste est prétendu ... Salaire moyen extrait de Head Hunter et Super Job (et il existe plusieurs autres sources) pour un poste vacant donné dans une région donnée et pour un contexte commercial donné.
Avec Avito et Auto.ru, des paramètres supplémentaires sont généralement pris si une personne allume le téléphone. Avec Avito, vous pouvez voir ce que vend une personne - cher, peu coûteux, utilisé, non utilisé. Avec "Auto.ru", vous pouvez voir s'il a une voiture - il possède, ne possède pas. C'est quelque part moins de 20% des personnes qui ont accidentellement laissé tomber leur téléphone quelque part, et leur compte peut être lié à ces données.
Quelle est la taille de l'entreprise de collecte de données?
- Le volume de photos stockées en pétaoctets est de 6,4. Je ne peux pas dire avec certitude le taux de croissance en ce moment, car en 2016, nous avons commencé à enregistrer des périscopes et à commencer à enregistrer des vidéos un peu.
Je ne peux pas dire exactement quand il était nul. Nous sommes passés de société en société - toutes ces histoires sont longues. Mais je peux dire que VK, Facebook, Instagram et Twitter - toutes ces affaires (personnes, groupes et liens entre eux) avec du texte et du contenu - ce ne sont en fait pas tellement de données, ce n'est même pas un pétaoctet ramassé. Je pense que c'est un gigaoctet de 700, probablement 800.
Aider les clients à identifier le créneau actuel, où «creuser»?
- Lorsqu'un client arrive, nous lui disons de telles choses, mais nous, comme Google Trends, ne faisons pas ces choses.
- Nous avons eu plusieurs histoires quasi sociologiques, avec une histoire élective et pré-électorale - nous avons analysé tout cela. Avec les marques et l'évaluation des opinions sur les marques, tout est presque toujours d'accord. Voici les histoires des élections électives - non (avec une évaluation du candidat qui devrait gagner). Eh bien, qui a tort ici - nous, ou ceux qui croient en VTsIOM - je ne sais pas.
- Habituellement, nous prenons ces résultats de contrôle de la marque elle-même, ils les prennent des camarades qui commandent la recherche - téléphone là-bas, marketing, etc. De plus, tout cela peut être vérifié avec des choses de base: quelqu'un y a répondu à la newsletter, quelqu'un interroge ... S'il s'agit d'une grande marque (Coca-Cola, par exemple), ils doivent avoir un million ou deux avis clients internes - ce ne sont pas seulement des commentaires sur les réseaux sociaux et des opinions; certains systèmes internes, revues, etc.
La loi ne «sait» pas ce que sont les données personnelles!
- Nous analysons exclusivement des sources de données ouvertes; nous ne montons jamais dans un chernukha sale. Notre modèle est basé sur le fait que nous stockons toutes les données ouvertes dans certains centres de données publics, les louons ailleurs et les analysons à la maison, sur le territoire des bureaux, sur nos serveurs, et cela ne va pas au-delà du territoire.
Mais notre législation sur les données ouvertes est très vague.
Nous n'avons pas une compréhension claire de ce que sont les données ouvertes, quelles sont les données personnelles - il y a cette 152e loi fédérale, mais de toute façon ... Ils pensent comment? Maintenant, si j'ai votre nom et votre numéro de téléphone dans une base de données, j'ai votre numéro de téléphone et votre e-mail dans une autre base de données, et dans la troisième, disons, votre e-mail et votre voiture; tout cela est comme des données non personnelles. Si vous mettez tout cela ensemble, il semble que la loi devienne des données personnelles.
Nous contournons cela de deux manières. Tout d'abord, nous mettons le serveur avec le logiciel au client, puis ces données ne vont pas au-delà de son territoire, puis le client est responsable de la diffusion de ces données personnelles, pas des données personnelles, etc. Ou la deuxième option: si c'est une sorte d'histoire où vous devez poursuivre le réseau social ou autre chose ...
Nous avons eu une telle étude lorsque nous avons collecté (c'était les primaires de "Russie unie") pour les comptes LifeNews de ces camarades et regardé quel genre de porno ils aiment. La chose drôle était, mais néanmoins. Nous vendons cela comme notre propre opinion personnelle, sans divulguer légalement dans les documents que nous avons analysés - le registre, le salaire, les réseaux sociaux; nous vendons des avis d'experts, et là déjà en marge nous expliquons à la personne ce que nous avons analysé et comment.
Il y avait plusieurs histoires, mais elles étaient associées à certains projets commerciaux publics. Par exemple, nous avons un projet gratuit à but non lucratif pour ceux qui font du longboard (ces planches sont longues): la tâche était de collecter les publications des gens - quand quelqu'un publie: «Je suis allé au parc de Gorky pour faire du vélo.» Et puis il devrait monter sur la carte, et les gens autour de lui peuvent voir que quelqu'un est à côté de lui. VK a passé beaucoup de temps à se battre avec nous à ce sujet, car ils n'aimaient pas que nous publions ces informations sans la permission des gens. Mais alors l'affaire n'a pas été portée devant les tribunaux, car nous, au sein de plusieurs grandes communautés, avons ajouté aux règles que les données peuvent être utilisées par des agences tierces, des agences, des analyses, etc. Bien sûr, ce n'était pas particulièrement éthique, mais néanmoins. - Nous avons soudainement compris et commencé à vendre notre avis d'expert à tout le monde.
Travaillez-vous avec des établissements d'enseignement?
- Nous coopérons avec l'éducation, oui. Nous avons toute une série: nous avons un programme de master à l'école supérieure, nous coopérons avec d'autres universités. Les universités que nous aimons vraiment!
- Il y a mes contacts - vous pouvez écrire. Et une référence à la présentation, si quelqu'un est intéressé - il y a tous ces exemples, vous pouvez vous déplacer.
- Si un téléphone est connu, le courrier est presque une option absolue, personne ne le supprimera. S'il n'y a pas de téléphone, c'est généralement une image, il n'y a pas d'image - c'est l'année, le lieu de résidence, le travail. C'est-à-dire, par année, lieu de résidence et de travail, presque tous peuvent toujours être identifiés très subtilement. Mais là encore, c'est une question sur la tâche.
Nous avons, par exemple, un client qui vend la télévision sur Internet. Quelqu'un leur a acheté un abonnement à ces jeux de trônes, et la tâche consiste à trouver ces personnes à partir de leur CRM sur les réseaux sociaux, puis à trouver des personnes potentielles dans leur zone d'influence. Je dis juste qu'ils ont, disons, un nom, un prénom et un e-mail ... Et puis c'est très difficile donc de faire quelque chose. Vous pouvez trouver des personnes dans la plupart des cas par e-mail. - En termes d'amis, nous «jumelons» généralement les gens avec les réseaux sociaux, mais ce n'est pas toujours vrai. Non pas que ce ne soit pas toujours juste - cela ne fonctionne pas toujours. Tout d'abord, cela demande beaucoup de travail, car cette opération (pour le jumelage de personnes) devra être effectuée en premier pour chacun des amis - pour savoir s'ils sont passés des réseaux sociaux ou non. Et puis - car personne n'est un fait inconnu que "Vkontakte" nous n'avons que des amis, sur "Facebook" nous avons d'autres amis. Pas pour tout le monde, mais pour moi, par exemple, comme ça; .
?
- . , , . NDA. , , , , – , , . , – , – .
?
- , , , – , , – . , , , – Social Data Hub, . . , , , , . , …
- ( ?) , , .
( ): , , . - «» – 14%, «» ( ). , – .
, !
- , – . , «». , , … , ! - – , . – , . , , …
- : «, - ! !» , . - , – , , … , , 5 , - . , HR-, , : « – »!
. ?
- -10 . : … – , HR- , . , , - …
- ( ) 25 , .
- , , , 50 %. , - . , 40 , 50-60 % . . , - , , - , , … , – , . .
Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis
des VPS basés sur le cloud pour les développeurs à partir de 4,99 $ , un
analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur les VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?