Remarque perev. : Cet article à succès moyen est un aperçu des changements clés (2010-2019) dans le monde des langages de programmation et de l'écosystème technologique connexe (une attention particulière est accordée à Docker et Kubernetes). Son auteur original est Cindy Sridharan, spécialisée dans les outils pour les développeurs et les systèmes distribués - en particulier, elle a écrit le livre «Distributed Systems Observability» - et est très populaire dans l'espace Internet parmi les professionnels de l'informatique qui sont particulièrement intéressés par le sujet du cloud native.
2019 a pris fin, je voudrais donc partager mes réflexions sur certaines des réalisations et innovations technologiques les plus importantes de la dernière décennie. De plus, j'essaierai de regarder un peu vers l'avenir et de décrire les principaux problèmes et opportunités de la prochaine décennie.
Je veux immédiatement faire une réserve que dans cet article, je ne couvre pas les changements dans des domaines tels que
la science des données , l'intelligence artificielle, l'ingénierie frontale, etc., car je n'ai pas suffisamment d'expérience en la matière.
Taper contre-attaque
L'une des tendances les plus positives des années 2010 a été la renaissance des langues à typification statique. Cependant, ces langages n'ont disparu nulle part (C ++ et Java sont aujourd'hui en demande; ils dominaient il y a dix ans), cependant, les langages à typage dynamique (dynamique) ont connu une augmentation significative de leur popularité après l'émergence du mouvement Ruby on Rails en 2005. Cette croissance a culminé en 2009 avec l'ouverture du code source de Node.js, faisant de Javascript sur le serveur une réalité.
Au fil du temps, les langages dynamiques ont perdu une partie de leur attrait dans le développement de logiciels de serveur. Le langage Go, popularisé pendant la révolution des conteneurs, semblait mieux adapté pour créer des serveurs performants et économes en ressources avec un traitement parallèle des informations (ce avec quoi le créateur de Node.js
est d'
accord ).
Rust, introduit en 2010, comprenait des avancées dans la
théorie des types dans le but de devenir un langage sûr et typé. Au cours de la première moitié de la décennie, l'attitude envers Rust dans l'industrie était plutôt cool, mais dans la seconde moitié, sa popularité a considérablement augmenté. Des exemples notables de l'utilisation de Rust incluent son utilisation pour
Magic Pocket dans Dropbox ,
AWS Firecracker (nous en avons parlé dans cet article - environ Transl.) , Le premier compilateur WebAssembly de Fastly de Fastly (qui fait maintenant partie de la Bytecode Alliance), etc. Dans une situation où Microsoft envisage de réécrire certaines parties de Windows vers Rust, il est sûr de dire que dans les années 2020, ce langage a un brillant avenir.
Même les langages dynamiques ont gagné de nouvelles fonctionnalités comme
les types optionnels . Ils ont d'abord été implémentés en TypeScript, un langage qui vous permet de créer du code typé et de le compiler en JavaScript. PHP, Ruby et Python ont acquis leurs propres systèmes de typage optionnels (
mypy ,
Hack ), qui sont utilisés avec succès en
production .
Retour SQL à NoSQL
NoSQL est une autre technologie qui était beaucoup plus populaire au début de la décennie qu'à la fin. Je pense qu'il y a deux raisons à cela.
Premièrement, le modèle NoSQL avec le manque de schéma, de transactions et de garanties de cohérence plus faibles s'est avéré plus difficile à mettre en œuvre que le modèle SQL. Dans un
article de blog intitulé «
Pourquoi choisir une cohérence forte, dans la mesure du possible», Google écrit:
L'une des choses que nous avons apprises chez Google est que le code d'application est plus simple et que le temps de développement est plus court si les ingénieurs peuvent s'appuyer sur le stockage existant pour gérer les transactions complexes et maintenir l'ordre des données. Citant la documentation originale de Spanner, «nous pensons qu'il est préférable que les programmeurs traitent les problèmes de performances des applications en raison de l'abus de transactions lorsque des goulots d'étranglement se produisent plutôt que de garder à l'esprit en permanence l'absence de transactions.»
La deuxième raison est liée à la croissance des bases de données SQL distribuées «évolutives» (telles que
Cloud Spanner et
AWS Aurora ) dans l'espace cloud public, ainsi qu'aux alternatives Open Source comme CockroachDB
(nous avons également écrit à ce sujet - environ Transl.) , Que beaucoup résolvent des problèmes techniques, à cause desquels les bases SQL traditionnelles «ne se sont pas mises à l'échelle». Même MongoDB, qui était autrefois l'incarnation du mouvement NoSQL,
propose désormais
des transactions distribuées.
Pour les situations nécessitant des opérations de lecture et d'écriture atomiques sur plusieurs documents (dans une ou plusieurs collections), MongoDB prend en charge les transactions avec plusieurs documents. Dans le cas de transactions distribuées, les transactions peuvent être utilisées pour de nombreuses opérations, collections, bases de données, documents et fragments.
Streaming total
Apache Kafka, sans aucun doute, est devenue l'une des inventions les plus importantes de la dernière décennie. Son code source a été ouvert en janvier 2011 et, au fil des ans, Kafka a révolutionné le fonctionnement de l'entreprise de données. Kafka a été utilisé dans toutes les entreprises dans lesquelles j'ai eu la chance de travailler, allant des startups aux grandes entreprises. Les garanties et les cas d'utilisation qui leur sont fournis (pub-sub, flux, architectures événementielles) sont utilisés dans diverses tâches: de l'organisation du stockage de données à la surveillance et à l'analyse en streaming, qui sont demandés dans de nombreux domaines, tels que la finance, les soins de santé, le secteur public, le commerce de détail et etc.
Intégration continue (et dans une moindre mesure déploiement continu)
L'intégration continue n'est pas apparue au cours des 10 dernières années, mais c'est au cours de la dernière décennie qu'elle s'est
propagée à un point tel qu'elle est devenue partie intégrante du flux de travail standard (exécution de tests sur toutes les demandes d'extraction). Devenir un GitHub en tant que plate-forme pour développer et stocker du code et, plus important encore, développer un flux de travail basé sur le
flux GitHub signifie que la réalisation de tests avant d'accepter une demande d'extraction dans le maître est le
seul flux de travail de développement familier aux ingénieurs qui ont commencé leur carrière dans dix dernières années.
Le déploiement continu (déploiement continu; déployer chaque commit tel quel et lorsqu'il entre dans le maître) n'est pas aussi répandu que l'intégration continue. Cependant, avec de nombreuses API cloud différentes pour le déploiement, la popularité croissante de plates-formes comme Kubernetes (fournissant une API standardisée pour les déploiements) et l'émergence d'outils multiplateformes et multi-cloud comme Spinnaker (construits au-dessus de ces API standardisées), les processus de déploiement sont devenus plus automatisés, rationalisés et rationalisés. généralement plus sûr.
Conteneurs
Les conteneurs, peut-être, peuvent être appelés la technologie la plus hype, discutée, annoncée et mal comprise des années 2010. D'un autre côté, il s'agit de l'une des innovations les plus importantes de la décennie précédente. Une partie de la raison de toute cette cacophonie réside dans les signaux mixtes que nous avons reçus presque partout. Maintenant que le battage médiatique s'est un peu calmé, certains moments ont pris des nuances plus distinctes.
Les conteneurs sont devenus populaires non pas parce qu'ils sont le meilleur moyen d'exécuter une application qui répond aux besoins de la communauté mondiale des développeurs. Les conteneurs sont devenus populaires car ils s'intègrent avec succès dans une demande marketing pour un outil qui résout un problème complètement différent. Docker s'est avéré être un outil de développement
fantastique pour résoudre le problème urgent de compatibilité («fonctionne sur ma machine»).
Plus précisément, l'
image Docker a fait une révolution, car elle a résolu le problème de la parité entre les environnements et assuré une véritable portabilité non seulement du fichier d'application, mais aussi de tous ses logiciels et de ses dépendances opérationnelles. Le fait que cet outil ait en quelque sorte stimulé la popularité des «conteneurs», qui constituent en fait un détail de mise en œuvre de très bas niveau, reste pour moi peut-être le principal mystère de la dernière décennie.
Sans serveur
Je parie que l'apparition de l'informatique «sans serveur» est encore plus importante que les conteneurs, car elle vous permet vraiment de réaliser le rêve de l'informatique à la
demande . Au cours des cinq dernières années, j'ai observé l'expansion progressive de la portée de l'approche sans serveur (ajout de la prise en charge de nouveaux langages et de nouvelles exécutions). L'émergence de produits tels que Azure Durable Functions semble être une étape sûre vers la mise en œuvre de fonctions avec état (résolvant simultanément
certains problèmes liés aux restrictions FaaS). J'observerai avec intérêt l'évolution de ce nouveau paradigme dans les années à venir.
Automatisation
C'est peut-être la communauté des ingénieurs d'exploitation qui a le plus profité de cette tendance, car c'est lui qui a permis la mise en œuvre de concepts comme «l'infrastructure en tant que code» (IaC). De plus, la passion pour l'automatisation a coïncidé avec la croissance de la «culture SRE», dont l'objectif est une approche plus orientée programme de l'exploitation.
API universelle
Une autre caractéristique curieuse de la dernière décennie a été la fication API de diverses tâches de développement. De bonnes API flexibles permettent aux développeurs de créer des flux de travail et des outils innovants qui, à leur tour, aident à la maintenance et augmentent la convivialité.
De plus, la fiction API est la première étape vers la fiction SaaS de certaines fonctionnalités ou outils. Cette tendance a également coïncidé avec la popularité croissante des microservices: le SaaS n'était qu'un autre service avec lequel vous pouvez travailler en utilisant l'API. Actuellement, il existe de nombreux outils SaaS et FOSS dans des domaines tels que la surveillance, les paiements, l'équilibrage de charge, l'intégration continue, les alertes, la
signalisation des fonctionnalités , le CDN, l'ingénierie du trafic (par exemple DNS), etc., qui a prospéré au cours de la dernière décennie.
Observabilité
Il convient de noter qu'aujourd'hui, nous avons
des outils
beaucoup plus avancés disponibles pour surveiller et diagnostiquer le comportement des applications que jamais auparavant. Le système de surveillance Prometheus, qui a reçu le statut d'Open Source en 2015, peut être appelé peut-être le
meilleur système de surveillance de ceux avec lesquels j'ai travaillé. Ce n'est pas parfait, mais un nombre important de choses sont implémentées de manière complètement correcte (par exemple, la prise en charge des
dimensions dans le cas des métriques).
Le traçage distribué était une autre technologie qui est entrée dans le courant dominant dans les années 2010 grâce à des initiatives telles que OpenTracing (et son successeur, OpenTelemetry). Bien que le traçage soit encore assez difficile à utiliser, certains des derniers développements nous permettent d'espérer que dans les années 2020, nous révélerons son véritable potentiel.
(Remarque perev.: Lisez également dans notre blog la traduction de l'article "Traçage distribué: nous avons tout mal fait " du même auteur.)Tourné vers l'avenir
Hélas, de nombreux points douloureux attendent d'être résolus au cours de la prochaine décennie. Voici mes réflexions à leur sujet et quelques idées potentielles sur la façon de s'en débarrasser.
Résoudre le problème de la loi de Moore
La fin de la loi de mise à l'échelle de Dennard et son retard par rapport à la loi de Moore nécessitent de nouvelles innovations. John Hennessy, dans
sa conférence, explique pourquoi
les architectures
spécifiques à un domaine comme les TPU peuvent devenir l'une des solutions au problème du retard par rapport à la loi de Moore. Les boîtes à outils comme les
MLIR de Google semblent déjà constituer un bon pas en avant dans cette direction:
Les compilateurs doivent prendre en charge de nouvelles applications, porter facilement sur un nouveau matériel, lier de nombreux niveaux d'abstraction, des langages dynamiques contrôlés aux accélérateurs vectoriels et aux périphériques de stockage contrôlés par programme, tout en fournissant en même temps des commutateurs de haut niveau pour l'auto-réglage, fournissant une fonctionnalité juste-in temps, diagnostiquer et distribuer des informations de débogage sur le fonctionnement et les performances des systèmes à travers la pile, et dans la plupart des cas fournir zvoditelnost suffisamment proche de l'assembleur écrit à la main. Nous avons l'intention de partager notre vision, nos progrès et nos plans concernant le développement et la mise à disposition du public d'une telle infrastructure de compilation.
CI / CD
Bien que la popularité croissante de CI soit devenue l'une des principales tendances des années 2010, Jenkins est toujours l'étalon-or CI.
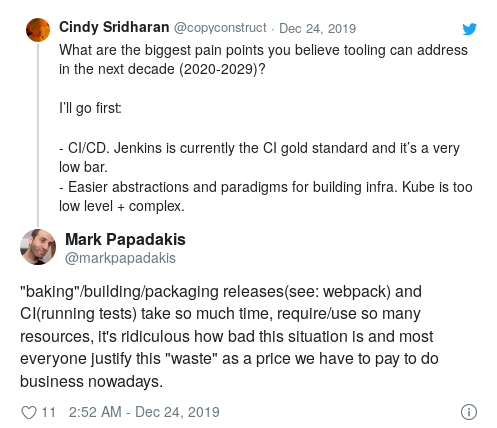
Cet espace a un besoin urgent d'innovation dans les domaines suivants:
- interface utilisateur (DSL pour coder les spécifications des tests);
- les détails de mise en œuvre qui le rendront vraiment évolutif et rapide;
- intégration avec différents environnements (staging, prod, etc.) pour la mise en œuvre de formes de tests plus avancées;
- validation et déploiement continus.
Outils pour les développeurs
En tant qu'industrie, nous avons commencé à créer des logiciels de plus en plus complexes et impressionnants. Cependant, en ce qui concerne nos propres outils, nous pouvons dire que la situation pourrait être bien meilleure.
L'édition conjointe et à distance (via ssh) a gagné en popularité, mais n'est pas encore devenue la nouvelle méthode de développement standard. Si vous, comme moi, rejetez l'idée même de la
nécessité d'une connexion Internet permanente juste pour pouvoir faire de la programmation, alors travailler avec ssh sur une machine distante est peu susceptible de vous convenir.
Les environnements de développement local, en particulier pour les ingénieurs travaillant sur de grandes architectures orientées services, restent un problème. Certains projets tentent de le résoudre, et je serais intéressé de savoir à quoi ressemblera l'UX la plus ergonomique pour ce cas d'utilisation.
Il serait également intéressant de développer le concept d '«environnements portables» dans d'autres domaines de développement, tels que les erreurs de reproduction (ou
tests feuilletés ) rencontrées dans certaines conditions ou avec certains paramètres.
J'aimerais également voir plus d'innovations dans des domaines tels que la recherche de code sémantique et contextuelle, les outils qui vous permettent de corréler les incidents de production avec des parties spécifiques de la base de code, etc.
Calculs (futur PaaS)
Au milieu du battage médiatique général autour des conteneurs et des serveurs sans serveur dans les années 2010, la gamme de solutions dans le cloud public s'est considérablement développée au cours des dernières années.

À cet égard, plusieurs questions intéressantes se posent. Tout d'abord, la liste des options disponibles dans le cloud public ne cesse de s'allonger. Les fournisseurs de services cloud ont du personnel et des ressources pour suivre facilement les dernières avancées dans le monde Open Source et publier des produits comme des pods sans serveur (je soupçonne simplement en rendant leurs propres exécutions FaaS compatibles avec OCI) ou autres trucs fantaisie similaires.
Ceux qui utilisent ces solutions cloud ne peuvent qu'être enviés. En théorie, les offres cloud de Kubernetes (GKE, EKS, EKS on Fargate, etc.) fournissent des API de fournisseur indépendantes du cloud pour exécuter des charges de travail. Si vous utilisez des produits similaires (ECS, Fargate, Google Cloud Run, etc.), vous êtes susceptible de maximiser l'utilisation des fonctions les plus intéressantes proposées par le fournisseur de services. De plus, avec l'avènement de nouveaux produits ou paradigmes informatiques, la migration risque d'être simple et sans souci.
Compte tenu de la rapidité avec laquelle la gamme de ces solutions se développe (je suis très surpris si quelques nouvelles options n'apparaissent pas dans un avenir proche), de petites équipes de «plate-forme» (équipes liées à l'infrastructure et chargées de créer des plates-formes sur site pour le lancement des charges de travail dans les entreprises), il sera extrêmement difficile de rivaliser en termes de fonctionnalité, de facilité d'utilisation et de fiabilité globale. Les années 2010 ont été marquées par Kubernetes comme un outil de création de PaaS (plateforme en tant que service), il semble donc complètement inutile de créer une plateforme interne basée sur Kubernetes qui offre le même choix, la simplicité et la liberté disponibles dans un espace de cloud public. Le concept de PaaS basé sur des conteneurs en tant que stratégie Kubernetes équivaut à abandonner intentionnellement les fonctionnalités cloud les plus innovantes.
Si vous regardez les capacités informatiques disponibles
aujourd'hui , il devient évident que créer votre propre PaaS uniquement sur la base de Kubernetes revient à vous pousser dans un coin (approche pas trop prévoyante, non?). Même si quelqu'un décide de créer un PaaS conteneurisé basé sur Kubernetes aujourd'hui, dans quelques années, il sera obsolète par rapport aux capacités du cloud. Bien que Kubernetes ait commencé son existence en tant que projet open source, son ancêtre et inspirateur idéologique est l'outil Google interne correspondant. Cependant, il a été initialement développé au début / milieu des années 2000, lorsque le paysage informatique était complètement différent.
De plus, dans un sens très large, les entreprises ne doivent pas devenir des experts dans le travail avec le cluster Kubernetes, ni créer et maintenir leurs propres centres de données. Fournir une base informatique fiable est l'objectif principal des
fournisseurs de services cloud .
Enfin, j'ai l'impression que nous avons un peu régressé en tant qu'industrie en termes d'
expérience d'interaction (
UX ). Heroku a été lancé en 2007 et reste toujours l'une des plateformes les
plus faciles à utiliser . Sans aucun doute, Kubernetes a beaucoup plus de puissance, d'extensibilité et de programmabilité, mais je regrette à quel point il est facile de démarrer et de déployer sur Heroku. Pour utiliser cette plateforme, il suffit de connaître Git.
Tout cela m'amène à la conclusion suivante: pour le travail, nous avons besoin de meilleures abstractions de niveau supérieur (cela est particulièrement vrai pour les
abstractions du plus haut niveau ).
La bonne API au plus haut niveau
Docker est un excellent exemple de la nécessité d'une meilleure séparation des tâches ainsi que la
mise en œuvre correcte de l'API de plus haut niveau .
Le problème avec Docker est que (au moins) le projet a été fixé des objectifs trop globaux: tout pour résoudre le problème de compatibilité ("fonctionne sur ma machine") en utilisant la technologie des conteneurs. Docker était à la fois un format d'image et un runtime avec son propre réseau virtuel, un outil CLI, un démon racine et bien plus encore. Dans tous les cas, la messagerie était
plus déroutante, sans parler des «machines virtuelles légères», des groupes de contrôle, des espaces de noms, de nombreux problèmes de sécurité et fonctionnalités mélangés à l'appel marketing «créer, livrer, exécuter n'importe quelle application n'importe où».

Comme pour toutes les bonnes abstractions, il faut du temps (ainsi que de l'expérience et de la douleur) pour décomposer les différents problèmes en couches logiques qui peuvent être combinées les unes avec les autres. Hélas, avant que Docker ne parvienne à atteindre une telle maturité, Kubernetes est entré dans le combat. Il a tellement monopolisé le cycle de battage que maintenant tout le monde a essayé de suivre les changements dans l'écosystème Kubernetes, et l'écosystème de conteneurs a acquis un statut secondaire.
Kubernetes partage à bien des égards les mêmes problèmes que Docker. Malgré tous les discours sur l'abstraction cool et composable, la
séparation des différentes tâches en couches n'est pas trop encapsulée. Fondamentalement, c'est un orchestre de conteneurs qui lance des conteneurs dans un cluster de différentes machines. Il s'agit d'une tâche de niveau assez bas, applicable uniquement aux ingénieurs exploitant le cluster. Kubernetes, d'autre part, est également une
abstraction du plus haut niveau , un outil CLI avec lequel les utilisateurs interagissent via YAML.
Docker était (et reste) un outil de développement
sympa , malgré toutes ses lacunes. Dans une tentative de suivre immédiatement tous les «lièvres», ses développeurs ont réussi à implémenter correctement l'
abstraction du plus haut niveau .
Par abstraction du plus haut niveau, j'entends un sous - ensemble des fonctionnalités auxquelles le public cible était vraiment intéressé (dans ce cas, les développeurs qui ont passé la majeure partie de leur temps dans leurs environnements de développement local) et qui fonctionnaient parfaitement "out of the box" .
Dockerfile et l'utilitaire CLI
docker devraient être un exemple de construction d'une bonne «interface utilisateur de haut niveau». Un développeur ordinaire peut commencer à travailler avec Docker sans rien savoir des subtilités de l'
implémentation, qui contribuent à l'expérience opérationnelle , comme les espaces de noms, les groupes de contrôle, les limitations de mémoire et de CPU, etc. En fin de compte, l'écriture d'un Dockerfile n'est pas très différente de l'écriture d'un script shell.
Kubernetes est conçu pour différents groupes cibles:
- Administrateurs de cluster
- les ingénieurs logiciels impliqués dans les problèmes d'infrastructure, étendant les capacités de Kubernetes et créant des plateformes basées sur celui-ci;
- les utilisateurs finaux interagissant avec Kubernetes via
kubectl .
L'approche «une API pour tous» de Kubernetes est une «montagne de complexité» sous-encapsulée sans indication de la manière de la faire évoluer. Tout cela conduit à un parcours d'apprentissage déraisonnablement long. Selon Adam Jacob, «Docker a apporté aux utilisateurs une expérience transformatrice qui n'a pas encore été dépassée. Demandez à tous ceux qui utilisent des K8 s'ils souhaitent que cela fonctionne comme leur premier
docker run . La réponse sera «oui»:

Je dirais que l'essentiel des technologies d'infrastructure aujourd'hui est trop bas (et donc considéré comme "trop complexe"). Kubernetes est implémenté à un niveau assez bas. Le traçage distribué dans sa
forme actuelle (de nombreuses étendues cousues ensemble pour former une vue de trace) est également implémenté à un niveau trop bas. Les outils destinés aux développeurs qui mettent en œuvre des «abstractions du plus haut niveau» sont généralement les plus efficaces. Cette conclusion est vraie dans un nombre incroyable de cas (si la technologie est trop complexe ou difficile à utiliser, alors "l'API / UI de plus haut niveau" pour cette technologie doit encore être ouverte).
À l'heure actuelle, l'écosystème natif du cloud est gêné par sa concentration sur les faibles niveaux. En tant qu'industrie, nous devons innover, expérimenter et enseigner à quoi ressemble le bon niveau d'abstraction maximale et la plus élevée.
Commerce de détail
Dans les années 2010, l'expérience de vente au détail numérique a à peine changé. D'une part, la facilité des achats en ligne aurait dû toucher les magasins de détail classiques et, d'autre part, les achats en ligne ont fondamentalement à peine changé en une décennie.
Bien que je n'aie aucune pensée concrète concernant le développement de cette industrie au cours de la prochaine décennie, je serai très déçu si, en 2030, nous effectuons des achats de la même manière qu'en 2020.
Journalisme
Je suis de plus en plus déçu par l'état du journalisme mondial. Il devient de plus en plus difficile de trouver des sources d'information impartiales qui diffusent de manière objective et méticuleuse. Très souvent, la frontière entre l'actualité elle-même et l'opinion à son sujet est effacée. En règle générale, les informations sont biaisées. Cela est particulièrement vrai dans le cas de certains pays où, historiquement, il n'y avait pas de séparation entre l'actualité et l'opinion à ce sujet. Dans un récent article publié après les dernières élections générales au Royaume-Uni, Alan Rusbridger, ancien rédacteur en chef de The Guardian,
écrit :
L'idée principale est que pendant de nombreuses années, j'ai regardé les journaux américains et j'ai regretté les collègues là-bas, qui étaient exclusivement responsables de l'actualité, et ont commenté des personnes complètement différentes. Cependant, avec le temps, la pitié s'est transformée en envie. Maintenant, je pense que tous les journaux nationaux britanniques devraient séparer la responsabilité des informations de la responsabilité des commentaires. Hélas, le lecteur moyen - en particulier le lecteur en ligne - est trop difficile à faire la différence.
Compte tenu de la réputation plutôt douteuse de la Silicon Valley en matière d'éthique, je ne ferais en aucun cas confiance à la technologie pour «révolutionner» le journalisme. En même temps, je (et beaucoup de mes amis) serais heureux si une ressource impartiale, désintéressée et digne de confiance apparaissait. Bien que je ne puisse pas imaginer à quoi pourrait ressembler une telle plateforme, je suis sûr qu'à une époque où la vérité devient de plus en plus difficile à discerner, le besoin d'un journalisme honnête est plus important que jamais.
Réseaux sociaux
Les réseaux sociaux et les plateformes d'actualités collectives sont la principale source d'informations pour de nombreuses personnes dans différentes parties du monde, et le manque d'exactitude et la réticence de certaines plateformes à effectuer au moins une vérification de base des faits de base entraînent des conséquences aussi graves que le génocide, l'ingérence dans les élections, etc.
Les réseaux sociaux sont également l'outil médiatique le plus puissant qui ait jamais existé. Ils ont radicalement changé la pratique politique. Ils ont changé les annonces. Ils ont changé la culture pop (par exemple, ce sont les réseaux sociaux qui contribuent le plus au développement de la culture dite d'annulation). Les critiques soutiennent que les médias sociaux se sont révélés être un terrain fertile pour des changements rapides et «capricieux» des valeurs morales, mais ils ont également fourni aux représentants des groupes marginalisés la possibilité de s'unir (ils n'avaient jamais eu une telle opportunité auparavant). Essentiellement, les réseaux sociaux ont changé la façon dont les gens communiquent et comment ils s'expriment au 21e siècle.
Cependant, je suis également convaincu que les réseaux sociaux contribuent à la manifestation des pires impulsions humaines. L'attention et la réflexion sont souvent négligées pour des raisons de popularité, et il devient presque impossible d'exprimer un désaccord motivé avec certaines opinions et positions. La polarisation devient souvent incontrôlable, par conséquent, le public n'entend simplement pas d'opinions séparées, tandis que les absolutistes contrôlent les questions d'étiquette en ligne et d'acceptabilité.
Je me demande, est-il possible de créer une «meilleure» plateforme qui peut aider à améliorer la qualité des discussions? Après tout, c'est précisément ce qui motive «l'engagement» qui apporte souvent le principal profit à ces plateformes. Comme l'
écrit Kara Swisher dans le New York Times:
L'engagement numérique peut être développé sans provoquer de haine et d'intolérance. La plupart des réseaux sociaux semblent si toxiques parce qu'ils ont été créés pour la vitesse, la viralité et l'attention, pas pour le contenu et la précision.
Il serait vraiment regrettable que, dans quelques décennies, le seul héritage des réseaux sociaux soit l'érosion des nuances et l'adéquation du discours public.
PS du traducteur
Lisez aussi dans notre blog: