Présentation
Tous ceux qui connaissent le C ++ moderne ont entendu qu'à partir de C ++ 11, le spécificateur constexpr a été introduit dans la norme, avec lequel vous pouvez effectuer des calculs de compilation limités.
Si constexpr et
constexpr lambdas ont été ajoutés aux normes suivantes, ce qui supprime dans une certaine mesure les restrictions et aide à écrire du code avec les calculs de temps de compilation. Aujourd'hui, nous allons parler de la génération de code aléatoire au moment de la compilation.
Nous sélectionnons la base pour recevoir des valeurs de compilation «aléatoires»
Afin de sélectionner un chemin spécifique pour le code au moment de la compilation, vous avez besoin d'un PRNG constexpr avec une bonne sortie, pour cela j'ai choisi le générateur
xorshift , par la façon dont
xorshift passe les
tests empiriques
BigCrush (TestU01) .
xorshift256 ++#include <stdint.h> /* This is xoshiro256++ 1.0, one of our all-purpose, rock-solid generators. It has excellent (sub-ns) speed, a state (256 bits) that is large enough for any parallel application, and it passes all tests we are aware of. For generating just floating-point numbers, xoshiro256+ is even faster. The state must be seeded so that it is not everywhere zero. If you have a 64-bit seed, we suggest to seed a splitmix64 generator and use its output to fill s. */ static inline uint64_t rotl(const uint64_t x, int k) { return (x << k) | (x >> (64 - k)); } static uint64_t s[4]; uint64_t next(void) { const uint64_t result = rotl(s[0] + s[3], 23) + s[0]; const uint64_t t = s[1] << 17; s[2] ^= s[0]; s[3] ^= s[1]; s[1] ^= s[2]; s[0] ^= s[3]; s[2] ^= t; s[3] = rotl(s[3], 45); return result; } /* This is the jump function for the generator. It is equivalent to 2^128 calls to next(); it can be used to generate 2^128 non-overlapping subsequences for parallel computations. */ void jump(void) { static const uint64_t JUMP[] = { 0x180ec6d33cfd0aba, 0xd5a61266f0c9392c, 0xa9582618e03fc9aa, 0x39abdc4529b1661c }; uint64_t s0 = 0; uint64_t s1 = 0; uint64_t s2 = 0; uint64_t s3 = 0; for(int i = 0; i < sizeof JUMP / sizeof *JUMP; i++) for(int b = 0; b < 64; b++) { if (JUMP[i] & UINT64_C(1) << b) { s0 ^= s[0]; s1 ^= s[1]; s2 ^= s[2]; s3 ^= s[3]; } next(); } s[0] = s0; s[1] = s1; s[2] = s2; s[3] = s3; } /* This is the long-jump function for the generator. It is equivalent to 2^192 calls to next(); it can be used to generate 2^64 starting points, from each of which jump() will generate 2^64 non-overlapping subsequences for parallel distributed computations. */ void long_jump(void) { static const uint64_t LONG_JUMP[] = { 0x76e15d3efefdcbbf, 0xc5004e441c522fb3, 0x77710069854ee241, 0x39109bb02acbe635 }; uint64_t s0 = 0; uint64_t s1 = 0; uint64_t s2 = 0; uint64_t s3 = 0; for(int i = 0; i < sizeof LONG_JUMP / sizeof *LONG_JUMP; i++) for(int b = 0; b < 64; b++) { if (LONG_JUMP[i] & UINT64_C(1) << b) { s0 ^= s[0]; s1 ^= s[1]; s2 ^= s[2]; s3 ^= s[3]; } next(); } s[0] = s0; s[1] = s1; s[2] = s2; s[3] = s3; }
A partir de là, nous n'avons besoin que des fonctions rotl et next, pour ne pas faire trop de calculs. J'adresse mes sincères salutations aux développeurs du compilateur MSVC, au vu des bogues du compilateur qui ont été découverts lors du processus d'écriture, cela sera discuté ci-dessous.
Comme vous pouvez le voir dans le code ci-dessus, nous avons besoin de quatre variables statiques 64 bits pour stocker l'état, afin que ce code fonctionne au moment de la compilation, nous devons nous en débarrasser en passant un état aléatoire en tant que paramètres. Vous pouvez organiser cela à l'aide de hachage constexpr fnv1 et de la macro __COUNTER__, réécrire le code conformément à cela et obtenir ce qui suit:
temps de compilation «aléatoire» #include <cstdint> #define STRING(s) #s // an enumeration can also be used here template <typename T, T value> constexpr T ensure_constexpr() { return value; } #define CONSTEXPR(x) ensure_constexpr<decltype(x), x>() constexpr uint64_t fnv1impl(uint64_t h, const char* s) { return (*s == 0) ? h : fnv1impl((h * 1099511628211ull) ^ static_cast<uint64_t>(*s), s + 1); } constexpr uint64_t fnv1(const char* s) { return fnv1impl(14695981039346656037ull, s); } template <uint64_t n> constexpr uint64_t get_seed(const uint64_t x, const uint64_t y = CONSTEXPR(fnv1(STRING(n)))) { return x ^ y * n; } #define SEED CONSTEXPR(get_seed<__COUNTER__ + 1>(fnv1(__TIME__))) //! Rotate left by constexpr uint64_t rotl(uint64_t x, int k) { return (x << k) | (x >> (64 - k)); } //! XorShift 256 compile time random implementation template <uint64_t a, uint64_t b, uint64_t c, uint64_t d> constexpr uint64_t xorshift256_next() { uint64_t s[4] = {a, b, c, d}; const uint64_t t = s[1] << 17; s[2] ^= s[0]; s[3] ^= s[1]; s[1] ^= s[2]; s[0] ^= s[3]; s[2] ^= t; s[3] = rotl(s[3], 45); return rotl(s[0] + s[3], 23) + s[0]; } #define RND \ xorshift256_next< \ CONSTEXPR(SEED + __COUNTER__), CONSTEXPR(SEED + __COUNTER__), \ CONSTEXPR(SEED + __COUNTER__), CONSTEXPR(SEED + __COUNTER__)>()
Sous le capot
Maintenant, nous devons nous assurer que les compilateurs «réduisent» vraiment le code au moment de la compilation.
Nous compilons le code ci-dessous en utilisant GCC 9.2.1 dans le débogage g ++ _.cpp -S -masm = intel
#include "compile_random.h" #include <iostream> int main() { std::cout << RND << std::endl; std::cout << RND << std::endl; }
Je veux voir des histoires d'horreur.file "_.cpp"
.intel_syntax noprefix
.text
.section .text._Z4rotlmi,"axG",@progbits,_Z4rotlmi,comdat
.weak _Z4rotlmi
.type _Z4rotlmi, @function
_Z4rotlmi:
.LFB4:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
mov QWORD PTR [rbp-8], rdi
mov DWORD PTR [rbp-12], esi
mov eax, DWORD PTR [rbp-12]
mov rdx, QWORD PTR [rbp-8]
mov ecx, eax
rol rdx, cl
mov rax, rdx
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE4:
.size _Z4rotlmi, .-_Z4rotlmi
.section .rodata
.type _ZStL19piecewise_construct, @object
.size _ZStL19piecewise_construct, 1
_ZStL19piecewise_construct:
.zero 1
.local _ZStL8__ioinit
.comm _ZStL8__ioinit,1,1
.text
.globl main
.type main, @function
main:
.LFB1528:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
call _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
mov rsi, rax
mov edi, OFFSET FLAT:_ZSt4cout
call _ZNSolsEm
mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov rdi, rax
call _ZNSolsEPFRSoS_E
call _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
mov rsi, rax
mov edi, OFFSET FLAT:_ZSt4cout
call _ZNSolsEm
mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov rdi, rax
call _ZNSolsEPFRSoS_E
mov eax, 0
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1528:
.size main, .-main
.section .text._Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv,"axG",@progbits,_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv,comdat
.weak _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
.type _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv, @function
_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv:
.LFB1790:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 48
movabs rax, 5485350875583313748
mov QWORD PTR [rbp-48], rax
movabs rax, -1344488152466593804
mov QWORD PTR [rbp-40], rax
movabs rax, -8102276183547423076
mov QWORD PTR [rbp-32], rax
movabs rax, 2938160962983216444
mov QWORD PTR [rbp-24], rax
mov rax, QWORD PTR [rbp-40]
sal rax, 17
mov QWORD PTR [rbp-8], rax
mov rdx, QWORD PTR [rbp-32]
mov rax, QWORD PTR [rbp-48]
xor rax, rdx
mov QWORD PTR [rbp-32], rax
mov rdx, QWORD PTR [rbp-24]
mov rax, QWORD PTR [rbp-40]
xor rax, rdx
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-40]
mov rax, QWORD PTR [rbp-32]
xor rax, rdx
mov QWORD PTR [rbp-40], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
xor rax, rdx
mov QWORD PTR [rbp-48], rax
mov rax, QWORD PTR [rbp-32]
xor rax, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-32], rax
mov rax, QWORD PTR [rbp-24]
mov esi, 45
mov rdi, rax
call _Z4rotlmi
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov esi, 23
mov rdi, rax
call _Z4rotlmi
mov rdx, QWORD PTR [rbp-48]
add rax, rdx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1790:
.size _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv, .-_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
.section .text._Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv,"axG",@progbits,_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv,comdat
.weak _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
.type _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv, @function
_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv:
.LFB1794:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 48
movabs rax, -3891678030706526748
mov QWORD PTR [rbp-48], rax
movabs rax, 7653162274090525828
mov QWORD PTR [rbp-40], rax
movabs rax, 823244081203417900
mov QWORD PTR [rbp-32], rax
movabs rax, -6510995906087812148
mov QWORD PTR [rbp-24], rax
mov rax, QWORD PTR [rbp-40]
sal rax, 17
mov QWORD PTR [rbp-8], rax
mov rdx, QWORD PTR [rbp-32]
mov rax, QWORD PTR [rbp-48]
xor rax, rdx
mov QWORD PTR [rbp-32], rax
mov rdx, QWORD PTR [rbp-24]
mov rax, QWORD PTR [rbp-40]
xor rax, rdx
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-40]
mov rax, QWORD PTR [rbp-32]
xor rax, rdx
mov QWORD PTR [rbp-40], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
xor rax, rdx
mov QWORD PTR [rbp-48], rax
mov rax, QWORD PTR [rbp-32]
xor rax, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-32], rax
mov rax, QWORD PTR [rbp-24]
mov esi, 45
mov rdi, rax
call _Z4rotlmi
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov esi, 23
mov rdi, rax
call _Z4rotlmi
mov rdx, QWORD PTR [rbp-48]
add rax, rdx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1794:
.size _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv, .-_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
.text
.type _Z41__static_initialization_and_destruction_0ii, @function
_Z41__static_initialization_and_destruction_0ii:
.LFB2042:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 16
mov DWORD PTR [rbp-4], edi
mov DWORD PTR [rbp-8], esi
cmp DWORD PTR [rbp-4], 1
jne .L11
cmp DWORD PTR [rbp-8], 65535
jne .L11
mov edi, OFFSET FLAT:_ZStL8__ioinit
call _ZNSt8ios_base4InitC1Ev
mov edx, OFFSET FLAT:__dso_handle
mov esi, OFFSET FLAT:_ZStL8__ioinit
mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev
call __cxa_atexit
.L11:
nop
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2042:
.size _Z41__static_initialization_and_destruction_0ii, .-_Z41__static_initialization_and_destruction_0ii
.type _GLOBAL__sub_I_main, @function
_GLOBAL__sub_I_main:
.LFB2043:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
mov esi, 65535
mov edi, 1
call _Z41__static_initialization_and_destruction_0ii
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2043:
.size _GLOBAL__sub_I_main, .-_GLOBAL__sub_I_main
.section .init_array,"aw"
.align 8
.quad _GLOBAL__sub_I_main
.hidden __dso_handle
.ident "GCC: (GNU) 9.2.1 20190827 (Red Hat 9.2.1-1)"
.section .note.GNU-stack,"",@progbits
Comme vous pouvez le voir dans le code assembleur ci-dessus, les fonctions rotl et xorshift256_next sont présentes dans le code, mais en fait c'est le comportement attendu, car les optimisations ont été désactivées.
Vérifiez avec les optimisations activées g ++ _.cpp -S -masm = intel -O2
Je n'ai plus peur, j'ai tout vu.file "_.cpp"
.intel_syntax noprefix
.text
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB1550:
.cfi_startproc
sub rsp, 8
.cfi_def_cfa_offset 16
mov edi, OFFSET FLAT:_ZSt4cout
movabs rsi, 6340608927850167019
call _ZNSo9_M_insertImEERSoT_
mov rdi, rax
call _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov edi, OFFSET FLAT:_ZSt4cout
movabs rsi, -1433878323375531419
call _ZNSo9_M_insertImEERSoT_
mov rdi, rax
call _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
xor eax, eax
add rsp, 8
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE1550:
.size main, .-main
.p2align 4
.type _GLOBAL__sub_I_main, @function
_GLOBAL__sub_I_main:
.LFB2064:
.cfi_startproc
sub rsp, 8
.cfi_def_cfa_offset 16
mov edi, OFFSET FLAT:_ZStL8__ioinit
call _ZNSt8ios_base4InitC1Ev
mov edx, OFFSET FLAT:__dso_handle
mov esi, OFFSET FLAT:_ZStL8__ioinit
mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev
add rsp, 8
.cfi_def_cfa_offset 8
jmp __cxa_atexit
.cfi_endproc
.LFE2064:
.size _GLOBAL__sub_I_main, .-_GLOBAL__sub_I_main
.section .init_array,"aw"
.align 8
.quad _GLOBAL__sub_I_main
.local _ZStL8__ioinit
.comm _ZStL8__ioinit,1,1
.hidden __dso_handle
.ident "GCC: (GNU) 9.2.1 20190827 (Red Hat 9.2.1-1)"
.section .note.GNU-stack,"",@progbits
Hourra! nous obtenons ce que nous attendions, le compilateur a déployé 2 appels de la macro RND à 2 instructions mov. Le comportement des compilateurs clang et MSVC en MODE DE LIBÉRATION est similaire. Vous pouvez procéder à la compilation de la génération du code temporel.
Pour une meilleure compréhension, vous devez vous familiariser avec les éléments logiques universels.
NOR (flèche fléchée)
NAND (Schaeffer Bar) avec lequel vous pouvez construire absolument toute la logique. Je ne joindrai pas tout le code pour implémenter le & | ^ ++ -, nous analyserons un seul exemple basé sur un échantillonnage aléatoire de la fonction de modèle NAND, dans d'autres instructions émulées, le principe de sélection est le même.
Imaginons que nous ayons 5 implémentations NAND de modèle que nous voulons randomiser.
Pour ce faire, nous avons juste besoin de faire ce qui suit:
template <typename T, const uint64_t n> FORCEINLINE volatile T NandR(volatile T a, volatile T b) { switch (n % 5) { case 0: return Nand_1<T>(a, b); case 1: return Nand_2<T>(a, b); case 2: return Nand_3<T>(a, b); case 3: return Nand_4<T>(a, b); case 4: return Nand_5<T>(a, b); default: return Nand_1<T>(a, b); } }
Il peut être appelé en code comme ceci:
NandR<uint64_t, RND>(a,b)
Le compilateur ne laissera qu'un seul appel de fonction, qui sera sélectionné en fonction du résultat de la macro RND, puisque le nombre est connu au moment de la compilation. RND est une macro utilisant xorshift + fnv1 + __COUNTER__ qui a été discutée ci-dessus. Aussi pour plus de commodité, une classe de modèle primitif CNNInt <> a été écrite qui contient des surcharges d'opérateurs nécessaires afin d'améliorer la lisibilité du code.
Considérez le code assembleur généré et DIFF de deux compilations différentes pour la fonction suivante:
uint64_t diff_me(uint64_t x) { using u64 = uint64_t; CNNInt<u64> r(std::chrono::system_clock::now().time_since_epoch().count()); CNNInt<u64> test(x); test++; test--; test|=r; test^=r; test&=r; test^=r; test = ~test; return test.value(); }
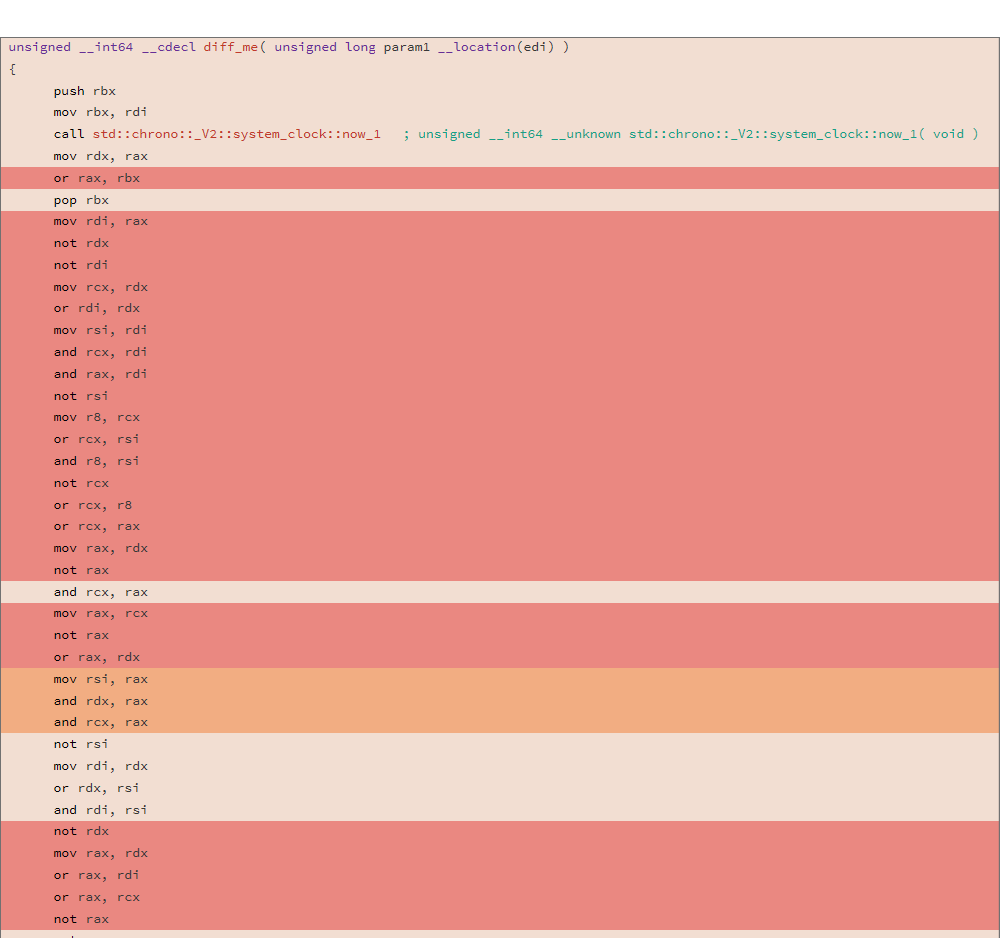
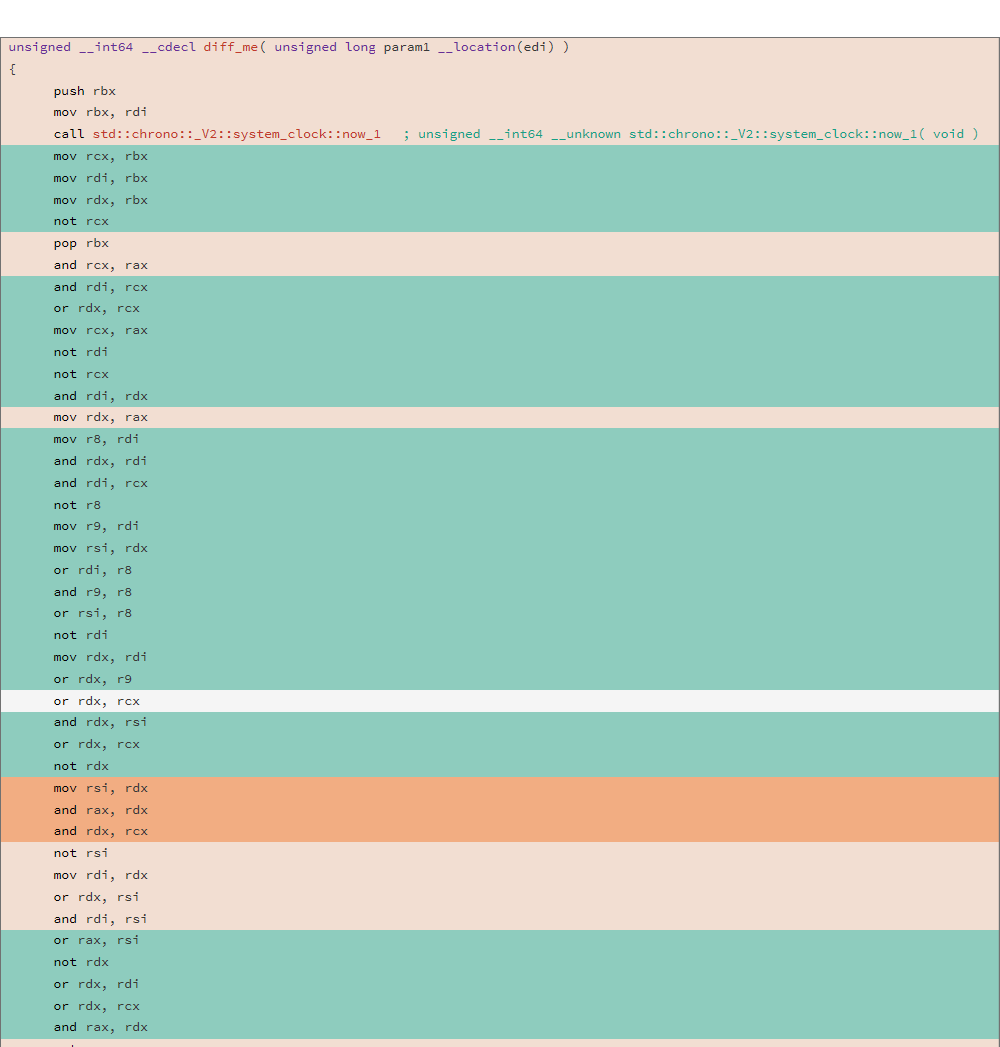
L'analyse a été réalisée à l'aide de l'utilitaire de mise en route, le DIFF de deux binaires a montré le résultat suivant:
81.13% diff_me - diff_me
Regardons la fonction diff_me sous les décompilateurs:
1.
Ghidra ulong diff_me(ulong param_1) { ulong uVar1; ulong uVar2; ulong uVar3; ulong uVar4; uVar1 = now(); uVar2 = ~uVar1; uVar3 = ~(param_1 & ~param_1 & uVar1) & (param_1 | ~param_1 & uVar1); uVar4 = ~uVar3; uVar3 = (~(uVar3 & uVar2 | uVar4) | uVar3 & uVar2 & uVar4 | uVar2) & (uVar1 & uVar3 | uVar4) | uVar2; uVar4 = ~uVar3 & uVar2; return (uVar1 & ~uVar3 | uVar3) & (~(uVar4 | uVar3) | uVar4 & uVar3 | uVar2); }
Il existe une autre fonction execute_code dans le projet à titre d'exemple, Ghidra n'a pas pu la décompiler.
2.
Trémie int _Z7diff_mem(long arg0) { rax = std::chrono::_V2::system_clock::now(); rax = (rax & !((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) | !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax)) & (!(!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) & !rax | !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax)) | !((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) & !rax & !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) | !rax); return rax; }
3.
RetDec
Bonus
1.
Le référentiel du projet .
2. Revenons au compilateur MSVC (version de la chaîne d'outils 16.4.2), la compilation de l'exemple du projet consomme une énorme quantité de mémoire et prend beaucoup de temps, j'ai
signalé le bogue à l'équipe du compilateur MSVC , je serai heureux si vous votez pour corriger ce bogue.
Consommation de mémoire lors de la compilation d'un projet de test:

Il est à noter que l'assemblage du projet de test à l'aide de Clang 9.0 et GCC 9.2.1 se produit presque instantanément et ne consomme pas une telle quantité de mémoire :)