Aujourd'hui, il existe des solutions prêtes à l'emploi (propriétaires) pour la surveillance des flux IP (TS), par exemple, VB et iQ , elles ont un ensemble de fonctions assez riche et généralement de telles solutions sont disponibles pour les grands opérateurs traitant des services de télévision. Cet article décrit une solution basée sur le projet open source TSDuck , conçue pour un contrôle minimal des flux IP (TS) par le compteur CC (compteur de continuité) et le débit binaire. Une application possible consiste à contrôler la perte de paquets ou de l'ensemble du flux via un canal L2 loué (qui ne peut pas être surveillé normalement, par exemple, en lisant les compteurs de pertes dans les files d'attente).
Très bref sur TSDuck
TSDuck est un logiciel open source (licence BSD à 2 clauses) (un ensemble d'utilitaires de console et une bibliothèque pour développer ses utilitaires ou plug-ins) pour manipuler les flux TS. En entrée, il peut fonctionner avec IP (multicast / unicast), http, hls, tuners dvb, dektec dvb-asi demodulator, il y a un générateur de flux TS interne et la lecture à partir de fichiers. La sortie peut être un fichier, IP (multicast / unicast), hls, dektec dvb-asi et modulateurs HiDes, des joueurs (mplayer, vlc, xine) et drop. Entre l'entrée et la sortie, vous pouvez activer divers processeurs de trafic, par exemple le remappage PID, l'embrouillage / désembrouillage, l'analyse des compteurs CC, le calcul du débit binaire et d'autres opérations typiques pour les flux TS.
Dans cet article, les flux IP (multidiffusion) seront utilisés en entrée, les processeurs bitrate_monitor sont utilisés (du nom, il est clair ce que c'est) et la continuité (analyse des compteurs CC). Sans aucun problème, vous pouvez remplacer la multidiffusion IP par un autre type d'entrée pris en charge par TSDuck.
Il existe des versions / packages officiels de TSDuck pour la plupart des systèmes d'exploitation actuels. Pour Debian, ce n'est pas le cas, mais il a été possible d'assembler sans problème sous Debian 8 et Debian 10.
Ensuite, TSDuck version 3.19-1520 est utilisé, Linux est utilisé comme système d'exploitation (Debian 10 a été utilisé pour préparer la solution, CentOS 7 a été utilisé pour une utilisation réelle)
Préparation de TSDuck et OS
Avant de surveiller les flux réels, vous devez vous assurer que TSDuck fonctionne correctement et qu'il n'y a pas de pertes au niveau de la carte réseau ou du système d'exploitation (socket). Ceci est nécessaire pour ne pas deviner plus tard où les chutes se sont produites - sur le réseau ou "à l'intérieur du serveur". Vous pouvez vérifier les suppressions au niveau de la carte réseau avec la commande ethtool -S ethX, le réglage se fait avec le même ethtool (généralement, vous devez augmenter le tampon RX (-G) et parfois désactiver certains déchargements (-K)). En tant que recommandation générale, vous pouvez recommander d'utiliser un port distinct pour recevoir le trafic analysé, si possible, cela minimise les faux positifs associés au fait que la baisse s'est produite de manière cohérente sur le port de l'analyseur en raison de la présence d'autres trafics. Si cela n'est pas possible (un mini-ordinateur / NUC avec un seul port est utilisé), il est hautement souhaitable de hiérarchiser le trafic analysé par rapport au reste sur le périphérique auquel l'analyseur est connecté. En ce qui concerne les environnements virtuels, ici, vous devez être prudent et pouvoir trouver des suppressions de packages à partir du port physique et se terminant par l'application à l'intérieur de la machine virtuelle.
Génération et réception d'un flux à l'intérieur de l'hôte
Dans une première étape de préparation de TSDuck, nous générerons et recevrons du trafic au sein du même hôte à l'aide de netns.
Environnement de cuisson:
ip netns add P
L'environnement est prêt. Nous démarrons l'analyseur de trafic:
ip netns exec P tsp --realtime -t \ -I ip 239.0.0.1:1234 \ -P continuity \ -P bitrate_monitor -p 1 -t 1 \ -O drop
où "-p 1 -t 1" signifie que vous devez calculer le débit binaire chaque seconde et afficher des informations sur le débit binaire chaque seconde
Nous démarrons le générateur de trafic avec une vitesse de 10 Mbps:
tsp -I craft \ -P regulate -b 10000000 \ -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
où "-p 7 -e" signifie que vous devez emballer 7 paquets TS dans 1 paquet IP et le faire dur (-e), c'est-à-dire attendez toujours 7 paquets TS du dernier processeur avant d'envoyer un paquet IP.
L'analyseur commence à afficher les messages attendus:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s * 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s * 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/s
Maintenant, ajoutez quelques gouttes:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROP
et des messages comme ceux-ci apparaissent:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets * 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets
ce qui est attendu. Désactivez la perte de paquets (ip netns exec P iptables -F) et essayez d'augmenter le débit binaire du générateur à 100 Mbps. L'analyseur signale un tas d'erreurs CC et environ 75 Mbit / s au lieu de 100. Nous essayons de savoir qui est à blâmer - le générateur n'a pas le temps ou le problème n'est pas dedans, pour cela nous commençons à générer un nombre fixe de paquets (700 000 paquets TS = 100 000 paquets IP):
# ifconfig veth0 | grep TX TX packets 151825460 bytes 205725459268 (191.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234 * count: PID 0 (0x0000): 700,000 packets # ifconfig veth0 | grep TX TX packets 151925460 bytes 205861259268 (191.7 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Comme vous pouvez le voir, exactement 100 000 paquets IP ont été générés (151925460-151825460). Nous comprenons donc ce qui se passe avec l'analyseur, pour cela nous vérifions avec le compteur RX sur veth1, il est strictement égal au compteur TX sur veth0, puis nous regardons ce qui se passe au niveau du socket:
# ip netns exec P cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355
Ici, vous pouvez voir le nombre de gouttes = 24355. Dans les paquets TS, c'est 170485 ou 24,36% de 700000, nous voyons donc que les 25% du débit binaire perdu sont des gouttes dans le socket udp. Des baisses dans un socket UDP se produisent généralement en raison d'un manque de tampon, regardez quelle est la taille du tampon de socket par défaut et la taille maximale du tampon de socket:
# sysctl net.core.rmem_default net.core.rmem_default = 212992 # sysctl net.core.rmem_max net.core.rmem_max = 212992
Ainsi, si les applications ne demandent pas explicitement la taille du tampon, les sockets sont créées avec un tampon de 208 Ko, mais si elles en demandent plus, elles ne recevront toujours pas ce qui est demandé. Étant donné que dans tsp, vous pouvez définir la taille du tampon (--buffer-size) pour l'entrée IP, nous ne toucherons pas la taille du socket par défaut, nous définissons simplement la taille maximale du tampon du socket et spécifions explicitement la taille du tampon via les arguments tsp:
sysctl net.core.rmem_max=8388608 ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O drop
Avec cet ajustement du tampon de socket, le débit binaire maintenant signalé est d'environ 100 Mbit / s, il n'y a pas d'erreur CC.
Par consommation CPU par l'application tsp elle-même. Par rapport à un cœur du processeur i5-4260U à 1,40 GHz, l'analyse d'un flux à 10 Mbit / s nécessite un processeur de 3 à 4%, 100 Mbit / s - 25%, 200 Mbit / s - 46%. Lors de la définition du% de perte de paquets, la charge sur le CPU n'augmente pratiquement pas (mais peut diminuer).
Sur un matériel plus productif, il a été possible de générer et d'analyser sans problème des flux de plus de 1 Gb / s.
Test sur de vraies cartes réseau
Après avoir testé sur une paire de veth, vous devez prendre deux hôtes ou deux ports d'un hôte, connecter les ports l'un à l'autre, exécuter le générateur sur un et l'analyseur sur le second. Il n'y a pas eu de surprise, mais en réalité tout dépend du fer, plus il sera faible, plus il sera intéressant.
Utilisation des données reçues par le système de surveillance (Zabbix)
Tsp n'a pas d'API lisible par machine comme SNMP ou similaire. Les messages CC doivent être agrégés d'au moins 1 seconde (avec un pourcentage élevé de perte de paquets, il peut y avoir des centaines / milliers / dizaines de milliers par seconde, selon le débit binaire).
Ainsi, afin d'enregistrer des informations et de dessiner des graphiques d'erreurs CC et de débit binaire et de faire une sorte d'accident, les options suivantes peuvent être plus avancées:
- Analyser et agréger (selon CC) la sortie de tsp, c'est-à-dire convertissez-le à la forme souhaitée.
- Ajoutez des plugins tsp et / ou processeur bitrate_monitor et la continuité elle-même afin que le résultat soit affiché sous une forme lisible par machine adaptée à un système de surveillance.
- Écrivez votre application au-dessus de la bibliothèque tsduck.
De toute évidence, du point de vue des coûts de main-d'œuvre, l'option 1 est la plus simple, d'autant plus que tsduck lui-même est écrit dans un langage de bas niveau (selon les normes modernes) (C ++)
Un simple prototype de l'analyseur + agrégateur sur bash a montré que sur un flux de 10 Mbit / s et une perte de paquets de 50% (le pire des cas), le processus bash consommait 3-4 fois plus de CPU que le processus tsp lui-même. Ce scénario est inacceptable. En fait, un morceau de ce prototype ci-dessous
Outre le fait qu'il fonctionne de manière inacceptable lentement, il n'y a pas de threads normaux dans bash, les tâches bash sont des processus indépendants, et j'ai dû enregistrer la valeur des paquets manquants sur l'effet secondaire une fois par seconde (lorsque je reçois des messages de débit binaire qui arrivent toutes les secondes). En conséquence, bash a été laissé seul et il a été décidé d'écrire un wrapper (analyseur + agrégateur) dans golang. La consommation CPU d'un code golang similaire est 4 à 5 fois inférieure à celle du processus tsp lui-même. Accélérer le wrapper en remplaçant bash par golang s'est avéré être environ 16 fois et dans l'ensemble le résultat est acceptable (surcharge de 25% sur le CPU dans le pire des cas). Le fichier source sur golang est ici .
Lancement de Wrapper
Pour exécuter l'encapsuleur, le modèle de service le plus simple pour systemd a été créé ( ici ). On suppose que le wrapper lui-même est compilé dans un fichier binaire (allez construire tsduck-stat.go), situé dans / opt / tsduck-stat /. On suppose que golang est utilisé avec le support de l'horloge monotone (> = 1,9).
Pour créer une instance du service, vous devez exécuter la commande systemctl enable tsduck-stat@239.0.0.1: 1234, puis commencer à utiliser systemctl start tsduck-stat@239.0.0.1: 1234.
Découverte de Zabbix
Afin que zabbix puisse découvrir les services en cours d'exécution, un générateur de liste de groupes (discovery.sh) a été créé, au format nécessaire à la découverte de Zabbix, il est supposé qu'il se trouve là - dans / opt / tsduck-stat. Pour démarrer la découverte via zabbix-agent, vous devez ajouter le fichier .conf au répertoire contenant les configurations de zabbix-agent pour ajouter le paramètre utilisateur.
Modèle Zabbix
Le modèle créé (tsduck_stat_template.xml) contient la règle de découverte automatique, les prototypes d'éléments de données, les graphiques et les déclencheurs.
Une courte liste de contrôle (et si quelqu'un décide de l'utiliser)
- Assurez-vous que tsp ne laisse pas tomber les paquets dans des conditions "idéales" (le générateur et l'analyseur sont connectés directement), s'il y a des chutes, voir la section 2 ou le texte de l'article à ce sujet.
- Effectuez le réglage du tampon de socket maximum (net.core.rmem_max = 8388608).
- Compilez tsduck-stat.go (allez construire tsduck-stat.go).
- Placez le modèle de service dans / lib / systemd / system.
- Démarrez les services en utilisant systemctl, vérifiez que les compteurs ont commencé à apparaître (grep "" / dev / shm / tsduck-stat / *). Nombre de services par le nombre de flux de multidiffusion. Ici, vous devrez peut-être créer un itinéraire vers le groupe de multidiffusion, peut-être désactiver rp_filter ou créer un itinéraire vers l'IP source.
- Exécutez discovery.sh, assurez-vous qu'il génère json.
- Attachez la configuration de l'agent zabbix, redémarrez l'agent zabbix.
- Téléchargez le modèle sur zabbix, appliquez-le à l'hôte sur lequel zabbix-agent est surveillé et installé, attendez environ 5 minutes, vérifiez que de nouveaux éléments de données, graphiques et déclencheurs sont apparus.
Résultat
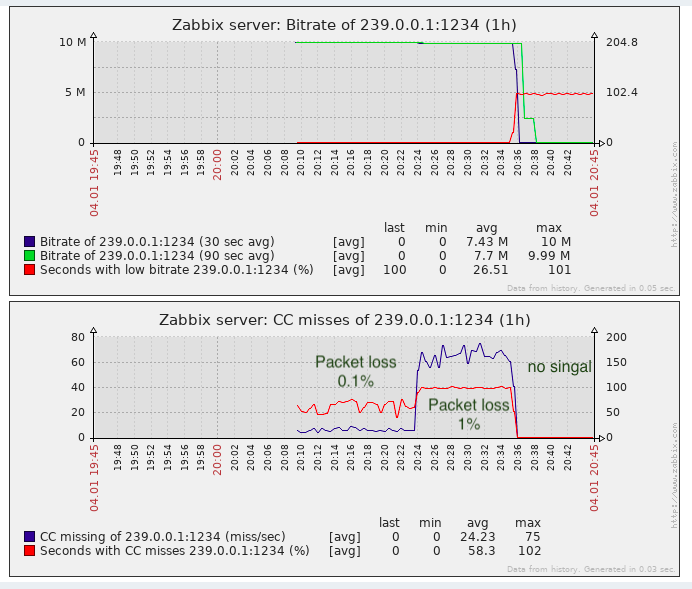
Pour détecter la perte de paquets, la tâche est presque suffisante, au moins elle est meilleure que le manque de surveillance.
En fait, des «pertes» CC peuvent survenir lors du collage de clips vidéo (pour autant que je sache, les insertions sont effectuées dans les télécentres locaux de la Fédération de Russie, c'est-à-dire sans compter le compteur CC), cela doit être rappelé. Dans les solutions propriétaires, ce problème est partiellement contourné par la détection des étiquettes de balise SCTE-35 (si elles sont ajoutées par le générateur de flux).
UPD: ajout de la prise en charge des balises SCTE-35 au modèle wrapper et zabbix
Du point de vue de la surveillance de la qualité du transport, il n'y a pas assez de gigue de surveillance (IAT), car L'équipement de télévision (qu'il s'agisse de modulateurs ou d'appareils terminaux) a des exigences pour ce paramètre et il n'est pas toujours possible de gonfler jitbuffer à l'infini. Et la gigue peut flotter lorsque de l'équipement avec de grands tampons est utilisé en transit et que la QoS n'est pas configurée ou n'est pas bien configurée pour transmettre un tel trafic en temps réel.