Contexte
Une fois, une conversation a commencé avec un collègue sur l'amélioration des outils de travail avec les indicateurs de bits dans les énumérations C ++. À ce moment-là, nous avions déjà la fonction IsEnumFlagSet, qui prend la variable testée comme premier argument et le deuxième ensemble d'indicateurs à vérifier. Pourquoi est-il meilleur que le bon vieux bit à bit Et?
if (IsEnumFlagSet(state, flag)) { }
À mon avis - lisibilité. Je travaille rarement avec les indicateurs de bits et les opérations de bits en général, donc lorsque vous consultez le code de quelqu'un d'autre, il est beaucoup plus facile de percevoir les noms de fonctions habituels que les cryptiques & et | qui appellent immédiatement le window.alert () interne avec le titre "Attention! Il peut y avoir une sorte de magie qui se produit. "
Un peu de tristesseMalheureusement, C ++ ne prend toujours pas en charge les méthodes d'extension (bien qu'il y ait déjà eu une
proposition similaire ) - sinon, par exemple, la méthode a la std :: bitset serait une option idéale:
if (state.Test(particularFlags)) {}
La lisibilité en particulier s'aggrave lors des opérations de définition ou de suppression des indicateurs. Comparez:
state |= flag;
Au cours de la discussion, l'idée a également été exprimée de créer la fonction
SetEnumFlag(state, flag, isSet) : selon le troisième argument, l'
state SetEnumFlag(state, flag, isSet) les
SetEnumFlag(state, flag, isSet) .
Comme il a été supposé que cet argument est passé au
RaiseEnumFlag/ClearEnumFlag de l'
RaiseEnumFlag/ClearEnumFlag , vous ne pouvez évidemment pas vous passer de surcharge par rapport à la paire
RaiseEnumFlag/ClearEnumFlag . Mais pour des raisons académiques, je voulais le minimiser en descendant dans la
mine au diable des micro-optimisations.
Implémentation
1. Implémentation naïve
Tout d'abord, nous introduisons notre énumération (nous n'utiliserons pas la classe enum pour simplifier):
#include <limits> #include <random> enum Flags : uint32_t { One = 1u << 1, Two = 1u << 2, Three = 1u << 3, OneOrThree = One | Three, Max = 1u << 31, All = std::numeric_limits<uint32_t>::max() };
Et l'implémentation elle-même:
void SetFlagBranched(Flags& x, Flags y, bool cond) { if (cond) { x = Flags(x | y); } else { x = Flags(x & (~y)); } }
2. Microoptimisation
L'implémentation naïve a une ramification évidente, que j'aimerais beaucoup transférer à l'arithmétique, ce que nous essayons de faire maintenant.
Tout d'abord, nous devons sélectionner une expression qui nous permet de passer d'un résultat à un autre en fonction du paramètre. Par exemple
(x | y) & ¬p
- Lorsque
p = 0 levons les drapeaux:
(x | y) & ¬0 ≡ (x | y) & 1 ≡ x | y
- Lorsque
p = y drapeaux sont supprimés:
(x | y) & ¬y ≡ (x & ¬y) | (y & ¬y) ≡ (x & ¬y) | 0 ≡ x & ¬y
Maintenant, nous devons en quelque sorte «empaqueter» en arithmétique le changement de la valeur du paramètre en fonction de la variable
cond (rappelez-vous - la ramification est interdite).
Soit
p = y départ, et si
cond vrai, alors essayez de réinitialiser
p , sinon, laissez tout tel quel.
Nous ne pourrons pas travailler directement avec la variable
cond : lors de la conversion au type arithmétique, si vrai, nous n'obtenons qu'une seule unité dans l'ordre inférieur, et idéalement nous devons obtenir des unités dans tous les bits (UPD:
vous pouvez toujours ). En conséquence, rien de mieux n'est venu à l'esprit que d'utiliser des décalages au niveau du bit.
Nous définissons la quantité de décalage: nous ne pouvons pas immédiatement décaler tous nos bits de sorte que le paramètre
p réinitialisé en une seule opération, car la norme exige que la quantité de décalage soit inférieure à la taille du type.
Pas à juste titrePar exemple, la commande shift arithmetic left (SAL) dans la documentation asm indique «La plage de comptage est limitée à 0 à 31 (ou 63 si le mode 64 bits et REX.W est utilisé)»
Par conséquent, nous calculons la taille de décalage maximale, écrivons l'expression préliminaire
constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) * 8 - 1; (x | y) & ~ ( y >> shiftSize * cond);
Et traiter séparément le bit de
y >> shiftSize * cond faible du résultat de l'expression
y >> shiftSize * cond :
(x | y) & ~ (( y >> shiftSize * cond) & ~cond);
La ramification a été
shiftSize * cond dans
shiftSize * cond - selon false ou true in cond, la valeur de décalage sera soit 0 ou 31, respectivement, et notre paramètre sera soit égal à
y soit à 0.
Que se passe-t-il lorsque
shiftSize = 31 :
- Avec
cond = true nous décalons les y bits de 31 vers la droite, à la suite de quoi le bit le plus significatif de y devient le moins significatif, et tous les autres sont remis à zéro. En ~cond contraire, le bit le moins significatif est 0, et tous les autres sont un. La multiplication au niveau du bit de ces valeurs donnera un 0 propre. - Lorsque
cond = false aucun décalage ne se produit, ~cond dans tous les chiffres a 1, et une multiplication au niveau du bit de ces valeurs donnera y .
Je voudrais noter le compromis de cette approche, qui n'est pas immédiatement évident: sans utiliser de branches, nous calculons
x | y x | y (c'est-à-dire, l'une des branches de la version naïve) dans
tous les cas, puis, en raison des opérations arithmétiques "supplémentaires", nous le transformons en le résultat souhaité. Et tout cela a du sens si la surcharge d'arithmétique supplémentaire est inférieure à la ramification.
Ainsi, la décision finale était la suivante:
void SetFlagsBranchless(Flags& x, Flags y, bool cond) { constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) * 8 - 1; x = Flags((x | y) & ~(( y >> shiftSize * cond) & ~cond)); }
(La taille de décalage est plus correcte pour lire à travers
std::numeric_limits::digits ,
voir commentaire )
3. Comparaison
Ayant implémenté la solution sans branchement, je suis allé sur
quick-bench.com pour m'assurer de son avantage. Pour le développement, nous utilisons principalement clang, j'ai donc décidé de lancer les benchmarks dessus (clang-9.0). Mais alors une surprise m'attendait ...
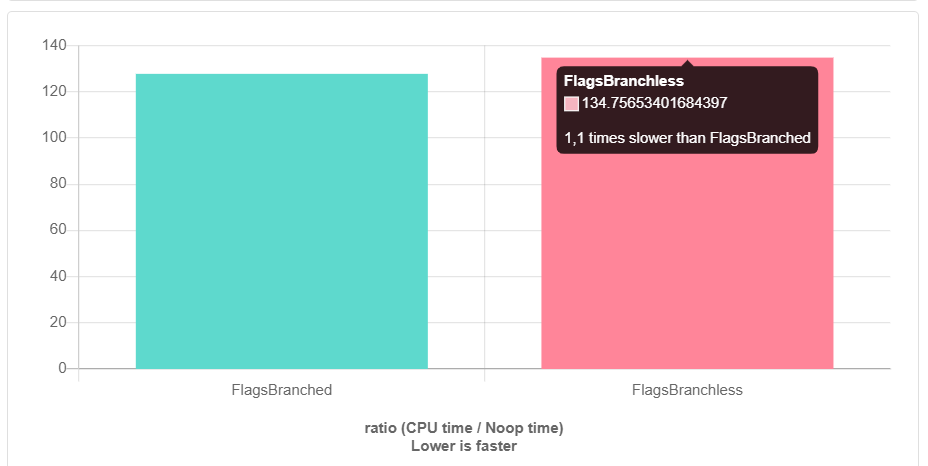
Et c'est avec -O3. Sans optimisations, c'est pire. Comment est-ce arrivé? Qui est à blâmer et que faire?
Nous commandons "mettre de côté la panique!" Et allez comprendre
godbolt.org (quick-bench fournit également une liste asm, mais godbolt semble plus pratique à cet égard).
Ensuite, nous ne parlerons que du niveau d'optimisation -O3. Alors, quel code a généré clang pour notre implémentation naïve?
SetFlagBranched(Flags&, Flags, bool): # @SetFlagBranched(Flags&, Flags, bool) mov eax, dword ptr [rdi] mov ecx, esi not ecx and ecx, eax or eax, esi test edx, edx cmove eax, ecx mov dword ptr [rdi], eax ret
Pas mal, non? Clang sait également comment effectuer un compromis et comprend qu'il sera plus rapide d'utiliser des commandes de saut conditionnel pour calculer les
deux branches et d'utiliser la commande de déplacement conditionnel, qui
n'implique pas de prédicteur de branche dans le travail.
Code d'implémentation sans branche:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool) mov eax, dword ptr [rdi] or eax, esi test edx, edx mov ecx, 31 cmove ecx, edx shr esi, cl not esi or esi, edx and esi, eax mov dword ptr [rdi], esi ret
Presque «sans branche» - J'ai pour ainsi dire ordonné la multiplication habituelle ici, et vous, mon ami, avez apporté une décision conditionnelle. Peut-être que le compilateur a raison, et test + cmove dans ce cas sera plus rapide qu'imul, mais je ne suis pas si bon en assembleur (personnes bien informées, dites-moi, s'il vous plaît, dans les commentaires).
Une autre chose est intéressante - en fait, pour les deux implémentations après optimisations, le compilateur n'a pas généré exactement ce que nous avons demandé, et en conséquence, nous avons obtenu quelque chose entre les deux: cmove est utilisé dans les deux variantes, nous avons juste beaucoup d'arithmétique supplémentaire dans l'implémentation sans branche, ce qui dépasse la référence.
Clang de la huitième version et des versions antérieures utilise généralement de véritables transitions conditionnelles, «grâce auxquelles» la version «sans branche» devient presque une fois et demie plus lente:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool) mov eax, dword ptr [rdi] or eax, esi mov cl, 31 test edx, edx jne .LBB0_2 xor ecx, ecx .LBB0_2: shr esi, cl not esi or esi, edx and eax, esi mov dword ptr [rdi], eax ret
Quelle conclusion peut-on tirer? En plus de l'évident "ne faites pas de microoptimisation inutilement", à moins que vous ne puissiez vous conseiller de toujours vérifier le résultat du travail dans le code machine - il peut s'avérer que le compilateur a déjà suffisamment optimisé la version initiale, et vos optimisations "ingénieuses" ne la comprendront pas, et malgré cela vous méditerez conditionnelle transitions au lieu de multiplications.
À ce stade, il serait possible de terminer, sinon pour un «mais». Le code gcc pour l'implémentation naïve est identique au code clang, mais la version sans branche est ..:
SetFlag(Flags&, Flags, bool): movzx edx, dl mov eax, esi or eax, DWORD PTR [rdi] mov ecx, edx sal ecx, 5 sub ecx, edx shr esi, cl not esi or esi, edx and esi, eax mov DWORD PTR [rdi], esi ret
Mon respect aux développeurs pour une manière si élégante d'optimiser notre expression sans utiliser ni
imul ni
cmove . Ce qui se passe ici: la variable bool cond est décalée au niveau du bit vers la gauche de 5 caractères (car le type de notre énumération est uint32_t, sa taille est de 32 bits, soit 100000
2 ), puis elle est soustraite du résultat. Ainsi, on obtient 11111
2 = 31
10 dans le cas de cond = true, et 0 sinon. Inutile de dire qu'une telle option est plus rapide que la naïve, même en tenant compte de son optimisation conditionnelle de déplacement?

Eh bien, le résultat était très étrange - selon le compilateur, l'option sans branches peut être plus rapide ou plus lente que l'implémentation avec des branches. Essayons d'aider clang et transformer notre expression en utilisant la méthode gcc (en même temps simplifier la partie
~((y >> shiftSize * cond) & ~cond) selon de Morgan - ceci est fait à la fois par clang et gcc):
void SetFlagVerbose(Flags& x, Flags y, bool b) { constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) + 1; x = Flags( (x | y) & ( ~(y >> ((b << shiftSize) - b)) | b) ); }
Un tel indice n'a d'effet que sur la version tronc de clang, où il génère vraiment du code similaire à gcc (bien que dans le "branchless" d'origine, c'est le même test + cmove)
Et MSVC? Dans les deux versions, sans branchement, un imul honnête est utilisé (je ne sais pas combien plus rapide / plus lent que l'option clang / gcc - quick-bench ne prend pas en charge ce compilateur), et dans la version naïve, un saut conditionnel est apparu. Triste mais vrai.
Résumé
On peut peut-être conclure que les intentions du programmeur dans le code de haut niveau sont loin d'être toujours reflétées dans le code machine - et cela rend les microoptimisations inutiles sans repères et listes d'affichage. De plus, le résultat des microoptimisations peut être meilleur ou pire que la version habituelle - tout dépend du compilateur, ce qui peut être un problème sérieux si le projet est multi-plateforme.