La complexité de l'interprétation des données sismiques est due au fait que pour chaque tâche, il est nécessaire de rechercher une approche individuelle, car chaque ensemble de ces données est unique. Le traitement manuel nécessite des coûts de main-d'œuvre importants et le résultat contient souvent des erreurs liées au facteur humain. L'utilisation de réseaux de neurones pour l'interprétation peut réduire considérablement le travail manuel, mais l'unicité des données impose des restrictions à l'automatisation de ce travail.
Cet article décrit une expérience pour analyser l'applicabilité des réseaux de neurones pour automatiser l'allocation des couches géologiques dans les images 2D en utilisant des données entièrement étiquetées de la mer du Nord comme exemple.
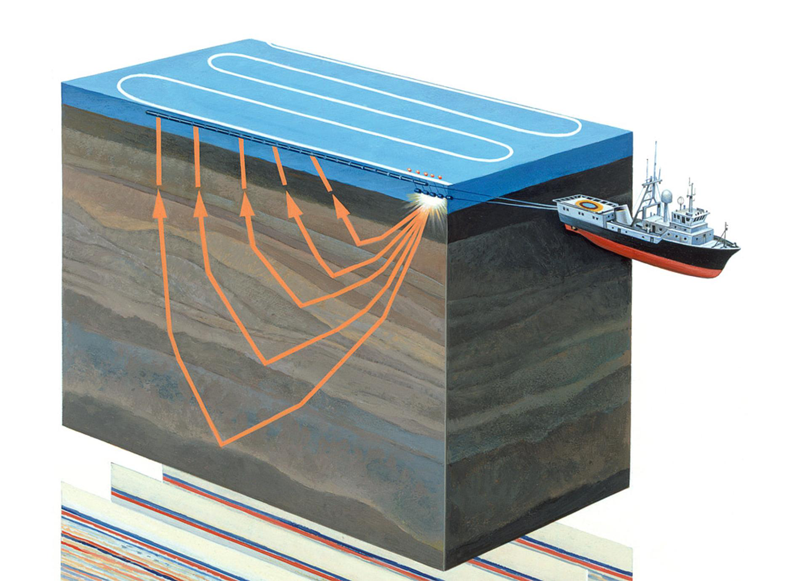
Figure 1. Levés sismiques aquatiques (
source )
Un peu sur le sujet
L'exploration sismique est une méthode géophysique pour étudier des objets géologiques à l'aide de vibrations élastiques - ondes sismiques. Cette méthode est basée sur le fait que la vitesse de propagation des ondes sismiques dépend des propriétés de l'environnement géologique dans lequel elles se propagent (composition de la roche, porosité, fracture, saturation en humidité, etc.) En traversant des couches géologiques aux propriétés différentes, les ondes sismiques sont réfléchies par différents objets et retournés au récepteur (voir figure 1). Leur nature est enregistrée et, après traitement, vous permet de former une image bidimensionnelle - une section sismique ou un tableau de données tridimensionnel - un cube sismique.
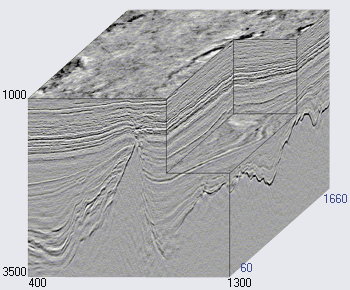
Figure 2. Un exemple de cube sismique (
source )
L'axe horizontal du cube sismique est situé le long de la surface de la terre et la verticale représente la profondeur ou le temps (voir la figure 2). Dans certains cas, le cube est divisé en sections verticales le long de l'axe des géophones (les soi-disant inlines, inlines) ou à travers (crosslines, crosslines, xlines). Chaque cube vertical (et tranche) est une trace sismique distincte.
Ainsi, les alignements et les croisements sont constitués des mêmes traînées sismiques, mais dans un ordre différent. Les sentiers sismiques adjacents sont très similaires les uns aux autres. Un changement plus spectaculaire se produit aux points de faille, mais il y aura toujours des similitudes. Cela signifie que les tranches voisines sont très similaires les unes aux autres.
Toutes ces connaissances nous seront utiles lors de la planification d'expériences.
La tâche d'interprétation et le rôle des réseaux de neurones dans sa solution
Les données obtenues sont traitées manuellement par des interprètes qui identifient directement sur le cube ou à chaque tranche ses couches géologiques individuelles de roches et leurs limites (horizons, horizons), les dépôts de sel, les failles et autres caractéristiques de la structure géologique de la zone d'étude. L'interprète, travaillant avec un cube ou une tranche, commence son travail par une sélection manuelle minutieuse des couches géologiques et des horizons. Chaque horizon doit être piqué manuellement (de la collection «picking» en anglais) en pointant le curseur et en cliquant avec la souris.
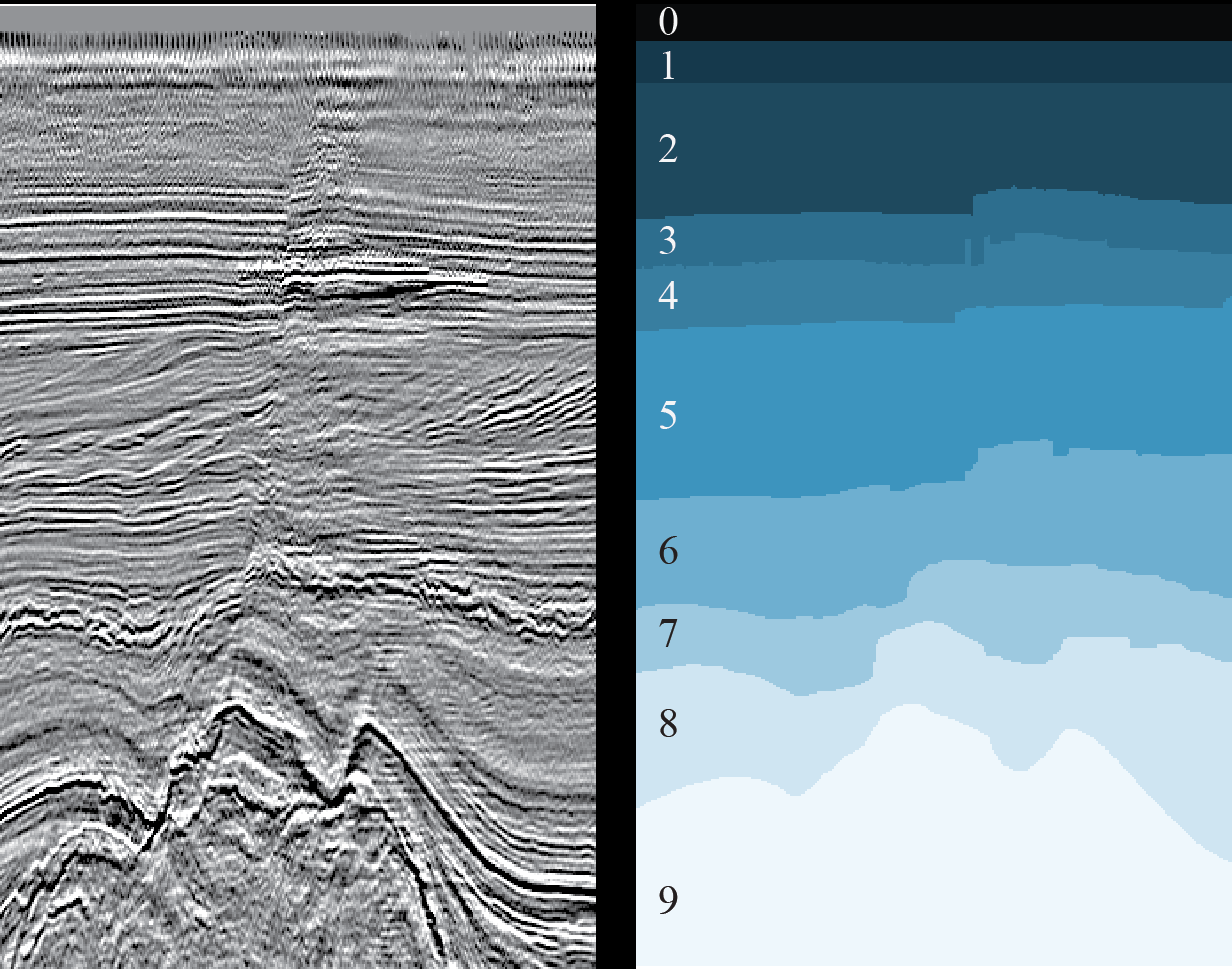
Figure 3. Exemple de coupe 2D (à gauche) et résultat du marquage des couches géologiques correspondantes (à droite) (
source )
Le principal problème est lié au volume croissant de données sismiques obtenues chaque année dans des conditions géologiques de plus en plus complexes (par exemple, des sections sous-marines à grande profondeur de mer) et à l'ambiguïté de l'interprétation de ces données. De plus, dans des conditions de délais serrés et / ou de gros volumes, l'interprète fait inévitablement des erreurs, par exemple, passe à côté de diverses caractéristiques de la section géologique.
Ce problème peut être partiellement résolu à l'aide de réseaux de neurones, réduisant considérablement le travail manuel, accélérant ainsi le processus d'interprétation et réduisant le nombre d'erreurs. Pour le fonctionnement du réseau de neurones, un certain nombre de sections prêtes à l'emploi et étiquetées (sections du cube) sont nécessaires, et par conséquent un marquage complet de toutes les sections (ou du cube entier) sera obtenu, ce qui, idéalement, ne nécessitera qu'un raffinement mineur par une personne pour ajuster certaines sections des horizons ou repérer de petites zones qui le réseau n'a pas pu reconnaître correctement.
Il existe de nombreuses solutions aux problèmes d'interprétation à l'aide de réseaux de neurones, en voici quelques exemples:
un ,
deux ,
trois . La difficulté réside dans le fait que chaque ensemble de données est unique - en raison des particularités des roches géologiques de la région étudiée, en raison de divers moyens techniques et méthodes d'exploration sismique, en raison des diverses méthodes utilisées pour transformer les données brutes en données prêtes à l'emploi. Même à cause des bruits extérieurs (par exemple, un chien qui aboie et d'autres sons forts), qu'il n'est pas toujours possible de supprimer complètement. Par conséquent, chaque tâche doit être résolue individuellement.
Mais, malgré cela, de nombreux travaux permettent de chercher à tâtons des approches générales distinctes pour résoudre divers problèmes d'interprétation.
Nous à
MaritimeAI (un projet développé à partir de la
communauté Machine Learning for Social Goods
ODS ,
un article sur nous ) pour chaque zone de notre domaine d'intérêt (recherche en mer) étudions des travaux déjà publiés et menons nos propres expériences, nous permettant de clarifier les limites et les caractéristiques de l'application de certains solutions, et parfois trouver vos propres approches.
Les résultats d'une expérience que nous décrivons dans cet article.
Objectifs de recherche commerciale
Il suffit qu'un spécialiste de la science des données jette un coup d'œil à la figure 3 pour soupirer de soulagement - une tâche courante de la segmentation d'image sémantique, pour laquelle de nombreuses architectures de réseaux de neurones et méthodes d'enseignement ont été inventées. Il vous suffit de choisir les bons et de former le réseau.
Mais pas si simple.
Pour obtenir un bon résultat à l'aide d'un réseau de neurones, vous avez besoin autant que possible de données déjà balisées sur lesquelles il va apprendre. Mais notre tâche est précisément de réduire la quantité de travail manuel. Et il est rarement possible d'utiliser des données balisées d'autres régions en raison de leurs fortes différences dans la structure géologique.
Nous traduisons ce qui précède dans la langue des affaires.
Pour que l'utilisation des réseaux de neurones soit économiquement justifiée, il est nécessaire de minimiser la quantité d'interprétation manuelle primaire et les raffinements des résultats obtenus. Mais la réduction des données pour la formation du réseau affectera négativement la qualité de son résultat. Un réseau de neurones peut-il donc accélérer et faciliter le travail des interprètes et améliorer la qualité des images étiquetées? Ou simplement compliquer le processus habituel?
Le but de cette étude est de tenter de déterminer le volume minimum suffisant de données de cube sismique balisé pour un réseau de neurones et d'évaluer les résultats obtenus. Nous avons essayé de trouver des réponses aux questions suivantes, qui devraient aider les "propriétaires" des résultats de l'enquête sismique à décider de l'interprétation manuelle ou partiellement automatisée:
- De combien de données les experts ont-ils besoin pour créer un réseau de neurones? Et quelles données choisir pour cela?
- Que se passe-t-il à une telle sortie? Un raffinement manuel des prédictions du réseau neuronal sera-t-il nécessaire? Si oui, dans quelle mesure est-il complexe et volumineux?
Description générale de l'expérience et des données utilisées
Pour l'expérience, nous avons sélectionné l'un des problèmes d'interprétation, à savoir la tâche d'isoler les couches géologiques sur les coupes 2D d'un cube sismique (voir figure 3). Nous avons déjà essayé de résoudre ce problème (voir
ici ) et, selon les auteurs, nous avons obtenu un bon résultat pour 1% des tranches sélectionnées au hasard. Compte tenu du volume du cube, ce sont 16 images. Cependant, l'article ne fournit pas de paramètres de comparaison et il n'y a pas de description de la méthodologie de formation (fonction de perte, optimiseur, schéma de changement de la vitesse d'apprentissage, etc.), ce qui rend l'expérience irreproductible.
De plus, les résultats qui y sont présentés, à notre avis, sont insuffisants pour obtenir des réponses complètes aux questions posées. Cette valeur est-elle optimale à 1%? Ou peut-être que pour un autre échantillon de tranches, ce sera différent? Puis-je sélectionner moins de données? Vaut-il la peine d'en prendre plus? Comment le résultat va-t-il changer? Etc.
Pour l'expérience, nous avons pris le même ensemble de données entièrement étiquetées du secteur néerlandais de la mer du Nord. Les données sismiques source sont disponibles sur le site Web Open Seismic Repository:
Project Netherlands Offshore F3 Block . Une brève description peut être trouvée dans
Silva et al. "Netherlands Dataset: A New Public Dataset for Machine Learning in Seismic Interpretation .
"Puisque dans notre cas, nous parlons de tranches 2D, nous n'avons pas utilisé le cube 3D d'origine, mais le «découpage» déjà fait, disponible ici:
Netherlands F3 Interpretation Dataset .
Au cours de l'expérience, nous avons résolu les tâches suivantes:
- Nous avons examiné les données source et sélectionné les tranches, dont la qualité est la plus proche du marquage manuel.
- Nous avons enregistré l'architecture du réseau neuronal, la méthodologie et les paramètres de la formation, et le principe de sélection des tranches pour la formation et la validation.
- Nous avons formé 20 réseaux neuronaux identiques sur différents volumes de données du même type de tranches pour comparer les résultats.
- Nous avons formé 20 autres réseaux de neurones sur une quantité différente de données de différents types de tranches pour comparer les résultats.
- Estimation du degré de raffinement manuel nécessaire des résultats prévus.
Les résultats de l'expérience sous forme de métriques estimées et prédits par les réseaux de masques de tranche sont présentés ci-dessous.
Tâche 1. Sélection des données
Ainsi, comme données initiales, nous avons utilisé des lignes et des lignes transversales prêtes à l'emploi du cube sismique du secteur néerlandais de la mer du Nord. Une analyse détaillée a montré que tout ne se passe pas bien - il existe de nombreuses images et masques avec des artefacts et même des déformations graves (voir les figures 4 et 5).

Figure 4. Exemple de masque avec des artefacts
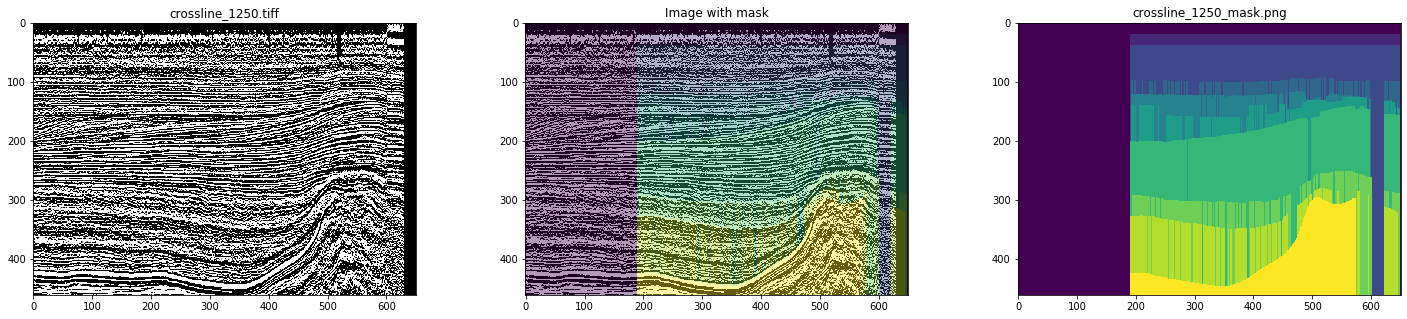
Figure 5. Un exemple de masque déformé
Avec un marquage manuel, rien de tel ne sera observé. Par conséquent, en simulant le travail de l'interprète, pour la formation du réseau, nous n'avons choisi que des masques propres, après avoir regardé toutes les tranches. En conséquence, 700 crosslines et 400 inlines ont été sélectionnées.
Tâche 2. Fixer les paramètres de l'expérience
Cette section est tout d'abord intéressante pour les spécialistes de la science des données, par conséquent, une terminologie appropriée sera utilisée.
Puisque les alignements et les croisements sont constitués des mêmes traces sismiques, deux hypothèses mutuellement exclusives peuvent être avancées:
- La formation ne peut être effectuée que sur un type de tranches (par exemple, en ligne), en utilisant des images d'un autre type comme sélection retardée. Cela donnera une évaluation plus adéquate du résultat, car les tranches restantes du même type que celles utilisées lors de la formation seront toujours similaires à celles de la formation.
- Pour l'entraînement, il est préférable d'utiliser un mélange de tranches de différents types, car il s'agit d'une augmentation prête à l'emploi.
Vérifiez-le.
De plus, la similitude des tranches voisines du même type et le désir d'obtenir un résultat reproductible nous ont conduit à une stratégie de sélection des tranches pour la formation et la validation, non pas par un principe arbitraire, mais uniformément dans tout le cube, c'est-à-dire de sorte que les tranches soient aussi éloignées que possible et couvrent donc la plus grande variété de données.
Pour la validation, 2 tranches ont été utilisées, également réparties également entre les images adjacentes de l'échantillon d'apprentissage. Par exemple, dans le cas d'un échantillon d'apprentissage de 3 inlines, l'échantillon de validation était composé de 4 inlines, pour 3 inlines et 3 crosslines, de 8 tranches, respectivement.
En conséquence, nous avons mené 2 séries de formations:
- Formation sur des échantillons de lignes de 3 à 20 tranches uniformément réparties sur le cube avec vérification du résultat des prédictions du réseau sur les lignes restantes et sur toutes les lignes croisées. De plus, une formation a été dispensée sur 80 et 160 sections.
- Formation à des échantillons combinés à partir de lignes en ligne et de lignes transversales de 3 à 10 sections de chaque type uniformément réparties sur un cube avec vérification du résultat des prévisions du réseau dans les images restantes. De plus, une formation a été dispensée sur 40 + 40 et 80 + 80 sections.
Avec cette approche, il est nécessaire de tenir compte du fait que les tailles des échantillons de formation et de validation varient considérablement, ce qui complique la comparaison, mais le volume des images restantes n'est pas tellement réduit qu'il peut être utilisé pour évaluer correctement les changements dans le résultat.
Pour réduire le recyclage de l'échantillon d'apprentissage, l'augmentation a été utilisée avec une taille de recadrage arbitraire 448x64 et une image miroir le long de l'axe vertical avec une probabilité de 0,5.
Comme nous ne nous intéressons à la dépendance de la qualité du résultat que sur le nombre de tranches dans l'échantillon d'apprentissage, le prétraitement des images peut être négligé. Nous avons utilisé une seule couche d'images PNG sans aucun changement.
Pour la même raison, dans le cadre de cette expérience, il n'est pas nécessaire de rechercher la meilleure architecture réseau - l'essentiel est qu'elle soit la même à chaque étape. Nous avons choisi une UNet simple mais bien établie pour ces tâches:

Figure 6. Architecture du réseau
La fonction de perte consistait en une combinaison du coefficient de Jacquard et de l'entropie croisée binaire:
def jaccard_loss(y_true, y_pred): smoothing = 1. intersection = tf.reduce_sum(y_true * y_pred, axis = (1, 2)) union = tf.reduce_sum(y_true + y_pred, axis = (1, 2)) jaccard = (intersection + smoothing) / (union - intersection + smoothing) return 1. - tf.reduce_mean(jaccard) def loss(y_true, y_pred): return 0.75 * jaccard_loss(y_true, y_pred) + 0.25 * keras.losses.binary_crossentropy(y_true, y_pred)
Autres options d'apprentissage:
keras.optimizers.SGD(lr = 0.01, momentum = 0.9, nesterov = True) keras.callbacks.EarlyStopping(monitor = 'val_loss', patience = 10), keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', patience = 5)
Pour réduire l'influence du caractère aléatoire du choix des poids initiaux sur les résultats, le réseau a été formé sur 3 inlines pour 1 ère. Toutes les autres formations ont commencé avec ces poids reçus.
Chaque réseau a été formé sur la GeForce GTX 1060 6 Go pour 30 à 60 époques. La formation de chaque époque a pris 10 à 30 secondes selon la taille de l'échantillon.
Tâche 3. Formation sur un type de tranches (en ligne)
La première série comprenait 18 formations réseau indépendantes sur 3 à 20 lignes. Et, bien que nous ne soyons intéressés que par l'estimation du coefficient de Jacquard sur des tranches non utilisées en formation et validation, il est intéressant de considérer tous les graphiques.
Rappelons que les résultats d'interprétation pour chaque tranche sont de 10 classes (couches géologiques), qui sur les figures sont en outre marquées par des nombres de 0 à 9.

Figure 7. Coefficient Jacquard pour l'ensemble d'entraînement

Figure 8. Coefficient Jacquard pour l'échantillon de validation
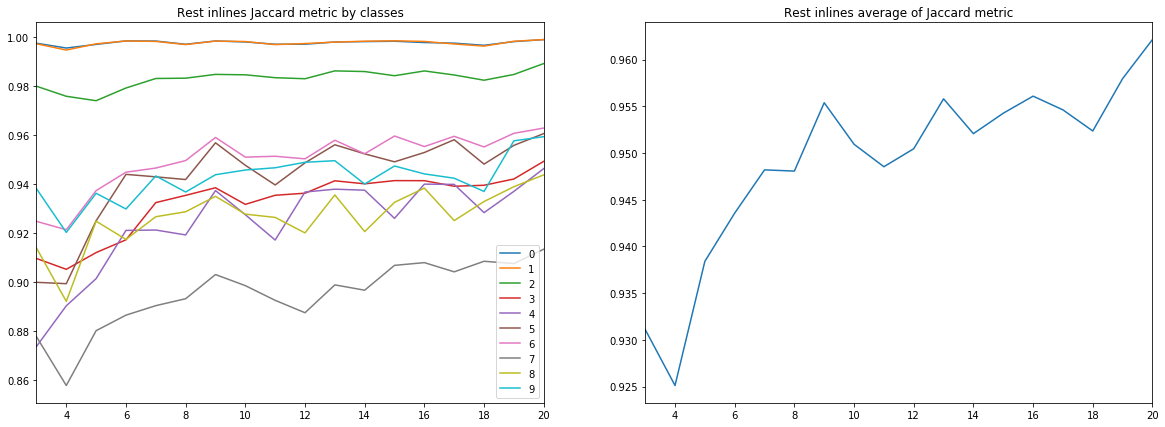
Figure 9. Coefficient Jacquard pour les autres lignes
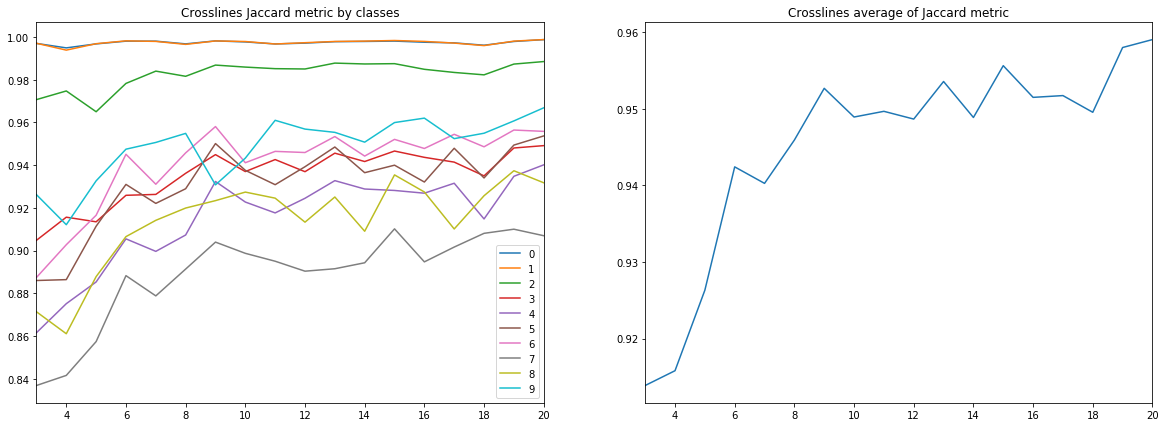
Figure 10. Coefficient Jacquard pour les lignes croisées
Un certain nombre de conclusions peuvent être tirées des diagrammes ci-dessus.
Premièrement, la qualité de la prévision, mesurée par le coefficient Jacquard, déjà à 9 inlines atteint une valeur très élevée, après quoi elle continue de croître, mais pas de manière aussi intensive. C'est-à-dire l'hypothèse de la suffisance d'un petit nombre d'images marquées pour la formation d'un réseau neuronal est confirmée.
Deuxièmement, un résultat très élevé a été obtenu pour les lignes croisées, malgré le fait que seules les lignes en ligne ont été utilisées pour la formation et la validation - l'hypothèse de la suffisance d'un seul type de tranches est également confirmée. Cependant, pour la conclusion finale, vous devez comparer les résultats avec une formation sur un mélange de lignes et de lignes croisées.
Troisièmement, les métriques pour différentes couches, c'est-à-dire La qualité de leur reconnaissance est très différente. Cela conduit à l'idée de choisir une stratégie d'apprentissage différente, par exemple, en utilisant des poids ou des réseaux supplémentaires pour les classes faibles, ou un système à part entière «un contre tous».
Enfin, il convient de noter que le coefficient Jacquard ne peut pas donner une description complète de la qualité du résultat. Afin d'évaluer les prédictions de réseau dans ce cas, il est préférable de regarder les masques eux-mêmes pour évaluer leur aptitude à la révision par l'interpréteur.
Les figures suivantes montrent le balisage par un réseau formé sur 10 inlines. La deuxième colonne, marquée «masque GT» (masque de vérité au sol), représente l'interprétation cible, la troisième est la prédiction du réseau neuronal.


Figure 11. Exemples de prévisions de réseau pour les inlines
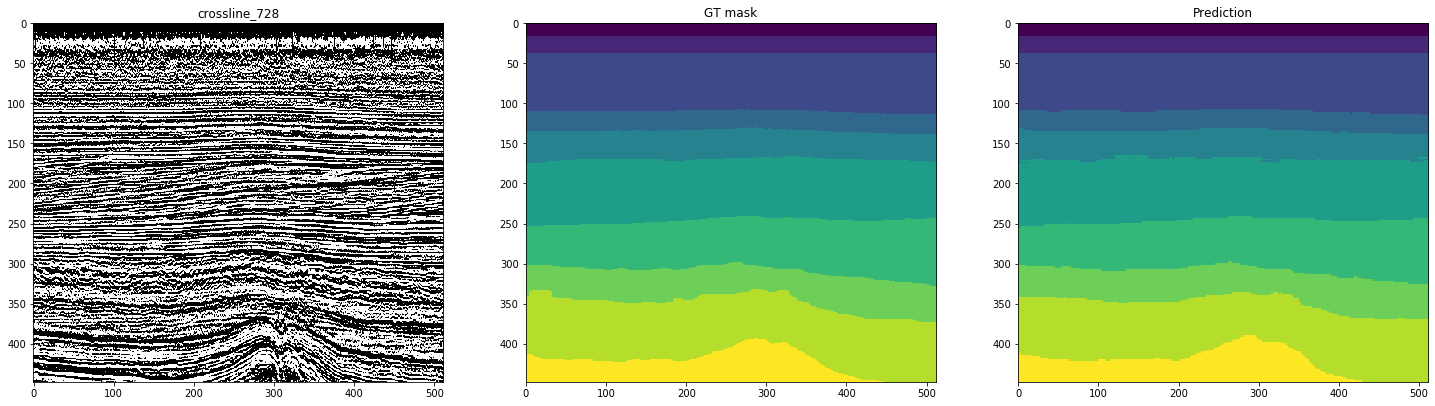

Figure 12. Exemples de prévisions de réseau pour les lignes croisées
On peut voir sur les figures que, avec des masques assez propres, le réseau est difficile à reconnaître des cas complexes, même sur les lignes elles-mêmes. Ainsi, malgré la métrique suffisamment élevée pour 10 tranches, une partie des résultats nécessitera un raffinement important.
La taille des échantillons que nous considérons fluctue autour de 1% du volume total de données - et cela permet déjà de bien délimiter une partie des tranches restantes. Dois-je augmenter le nombre de sections initialement marquées? Cela donnera-t-il une augmentation comparable de la qualité?
Considérons la dynamique des changements dans les résultats de prévision par des réseaux formés sur 5, 10, 15, 20, 80 (5% du volume total du cube) et 160 (10%) en ligne en utilisant les mêmes sections comme exemple.
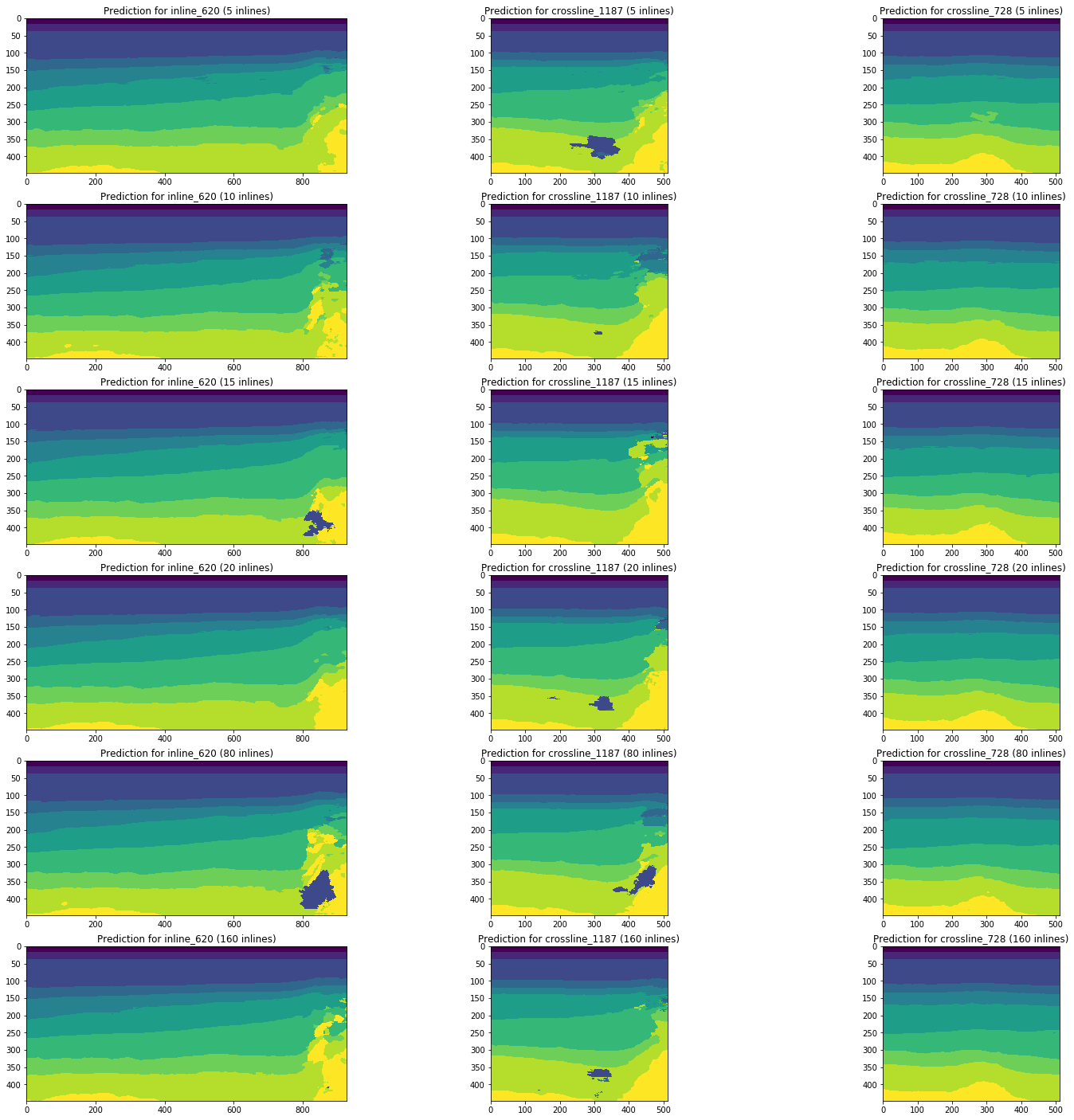
Figure 13. Exemples de prévisions de réseaux formés sur différents volumes de l'échantillon de formation
La figure 13 montre qu'une augmentation du volume de l'échantillon d'apprentissage de 5 ou même 10 fois ne conduit pas à une amélioration significative. Les tranches déjà bien reconnues dans 10 images d'entraînement ne s'aggravent pas.
Ainsi, même un simple réseau sans réglage et prétraitement d'images est capable d'interpréter une partie des tranches avec une qualité suffisamment élevée avec un petit nombre d'images marquées manuellement. Nous examinerons la question de la part de ces interprétations et de la complexité de la finalisation de tranches mal reconnues.
Une sélection rigoureuse de l'architecture, des paramètres réseau et de la formation, le prétraitement des images peuvent améliorer ces résultats sur le même volume de données balisées. Mais cela dépasse déjà le cadre de l'expérience actuelle.
Tâche 4. Formation sur différents types de tranches (en ligne et en croix)
Comparons maintenant les résultats de cette série avec les prévisions obtenues par la formation sur un mélange de lignes et de lignes croisées.
Les diagrammes ci-dessous montrent des estimations du coefficient de Jacquard pour différents échantillons, y compris, en comparaison avec les résultats de la série précédente. Pour comparaison (voir les bons diagrammes sur les figures), seuls des échantillons du même volume ont été prélevés, c'est-à-dire 10 inlines vs 5 inlines + 5 crosslines, etc.

Figure 14. Coefficient Jacquard pour l'ensemble d'entraînement

Figure 15. Coefficient Jacquard pour l'échantillon de validation

Figure 16. Coefficient Jacquard pour les autres lignes

Figure 17. Coefficient Jacquard pour les lignes transversales restantes
Les diagrammes illustrent clairement que l'ajout de tranches d'un type différent n'améliore pas les résultats. Même dans le contexte des classes (voir figure 18), l'influence des croisements n'est observée pour aucune des tailles d'échantillon considérées.

Figure 18. Coefficient de jacquard pour différentes classes (le long de l'axe X) et différentes tailles et composition de l'échantillon d'apprentissage
Pour compléter le tableau, nous comparons les résultats des prévisions du réseau sur les mêmes tranches:
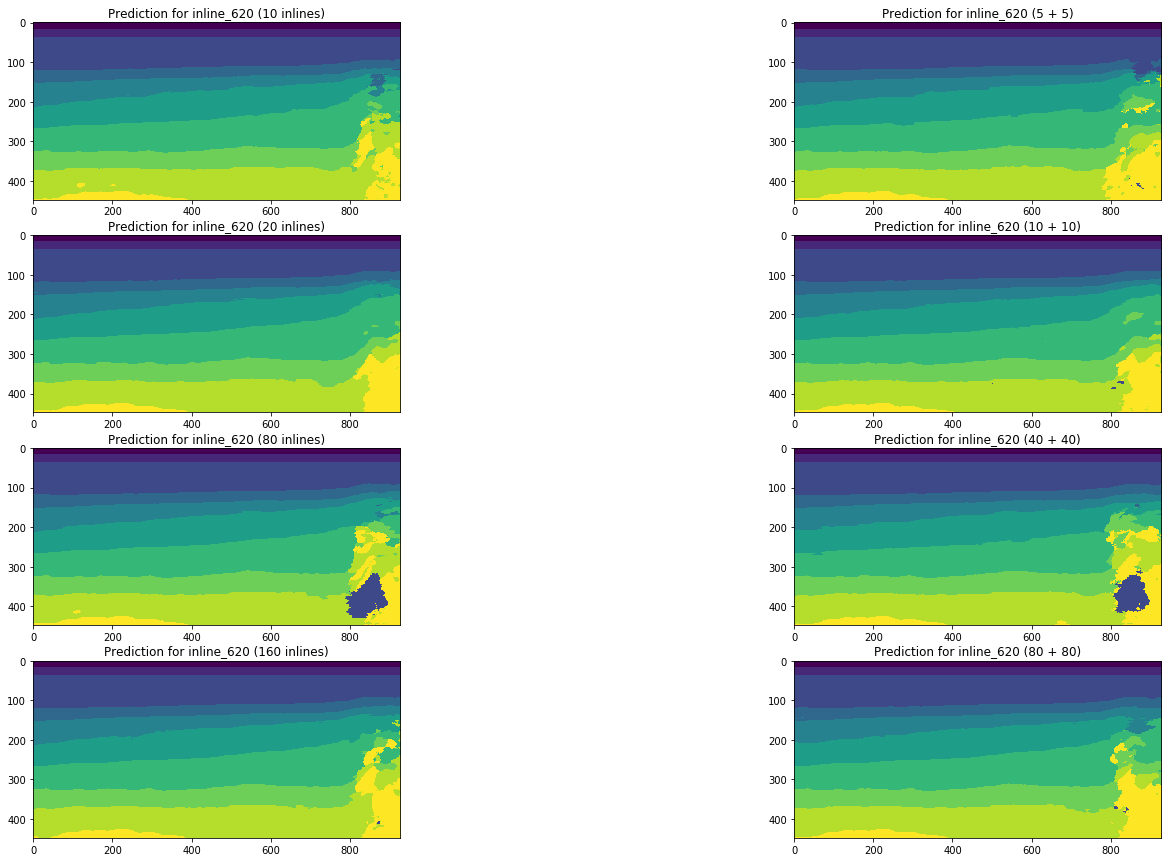
Figure 19. Comparaison des prévisions de réseau pour en ligne
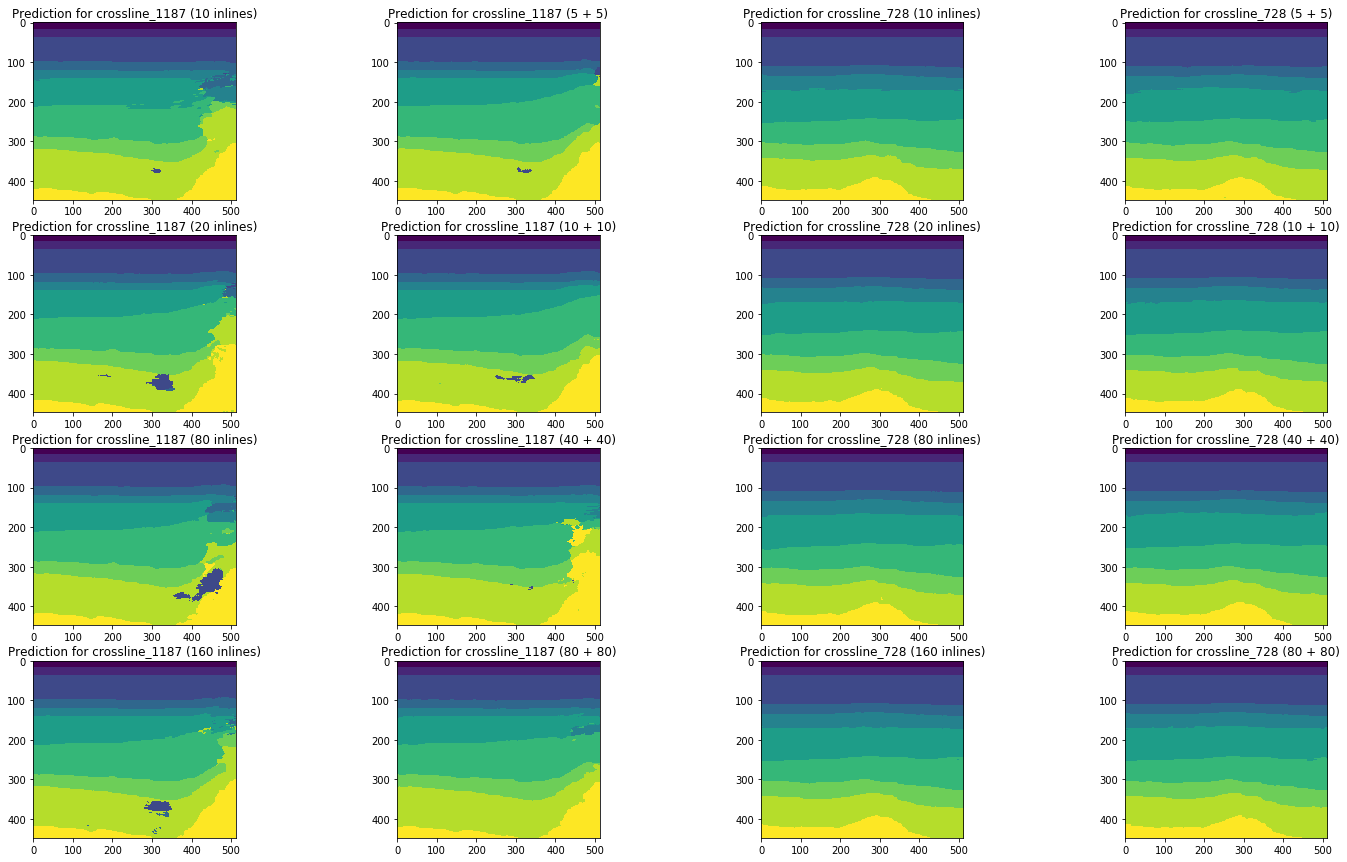
Figure 20. Comparaison des prévisions de réseau pour les lignes croisées
Une comparaison visuelle confirme l'hypothèse selon laquelle l'ajout de différents types de tranches à la formation ne change pas fondamentalement la situation. Certaines améliorations ne peuvent être observées que pour la ligne transversale gauche, mais sont-elles globales? Nous essaierons de répondre davantage à cette question.
Tâche 5. Évaluation du volume de raffinement manuel
Pour une conclusion finale sur les résultats, il est nécessaire d'estimer le degré de raffinement manuel des prévisions de réseau obtenues. Pour ce faire, nous avons déterminé le nombre de composants connectés (c'est-à-dire des taches solides de la même couleur) sur chaque prévision obtenue. Si cette valeur est 10, alors les couches sont sélectionnées correctement et nous parlons d'un maximum de correction d'horizon mineure. S'il n'y en a pas beaucoup plus, il vous suffit de «nettoyer» les petites zones de l'image. S'il y en a beaucoup plus, tout est mauvais et peut même nécessiter une réorganisation complète.
Pour les tests, nous avons sélectionné 110 lignes et 360 lignes croisées qui n'ont été utilisées dans la formation d'aucun des réseaux considérés.
Tableau 1. Statistiques moyennes sur les deux types de tranches
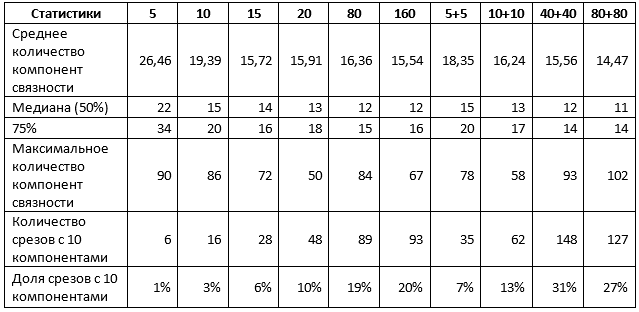
Le tableau 1 confirme certains des résultats précédents. En particulier, lors de l'utilisation de tranches de 1% pour la formation, il n'y a pas de différence, utilisez un type de tranches ou les deux, et le résultat peut être caractérisé comme suit:
- environ 10% des prévisions sont proches de l'idéal, c'est-à-dire ne nécessitent pas plus que des ajustements à des sections individuelles des horizons;
- 50% des prévisions ne contiennent pas plus de 15 spots, soit pas plus de 5 supplémentaires;
- 75% des prévisions ne contiennent pas plus de 20 spots, soit pas plus de 10 supplémentaires;
- les 25% restants des prévisions nécessitent un raffinement plus substantiel, y compris, éventuellement, une refonte complète des tranches individuelles.
Une augmentation de la taille de l'échantillon allant jusqu'à 5% modifie la situation. En particulier, les réseaux formés sur un mélange de sections affichent des indicateurs significativement plus élevés, bien que la valeur maximale des composants augmente également, ce qui indique l'apparition d'interprétations distinctes de très mauvaise qualité. Cependant, si vous augmentez l'échantillon de 5 fois et utilisez un mélange de tranches:
- environ 30% des prévisions sont proches de l'idéal, c'est-à-dire ne nécessitent pas plus que des ajustements à des sections individuelles des horizons;
- 50% des prévisions ne contiennent pas plus de 12 spots, soit pas plus de 2 supplémentaires;
- 75% des prévisions ne contiennent pas plus de 14 spots, soit pas plus de 4 supplémentaires;
- les 25% restants des prévisions nécessitent un raffinement plus substantiel, y compris, éventuellement, une refonte complète des tranches individuelles.
Une nouvelle augmentation de la taille de l'échantillon n'améliore pas les résultats.
En général, pour le cube de données que nous avons examiné, nous pouvons tirer des conclusions sur la suffisance de 1 à 5% du volume total de données pour obtenir un bon résultat à partir d'un réseau de neurones.
Selon ces données, en conjonction avec les métriques et illustrations ci-dessus, il est déjà possible de tirer des conclusions sur la pertinence d'utiliser des réseaux de neurones pour aider les interprètes et sur les résultats que les spécialistes traiteront.
Conclusions
Ainsi, maintenant nous pouvons répondre aux questions posées au début de l'article, en utilisant les résultats obtenus sur l'exemple d'un cube sismique de la mer du Nord:
De combien de données les experts ont-ils besoin pour créer un réseau de neurones? Et quelles données dois-je choisir?Pour avoir une bonne prévision du réseau, il suffit vraiment de pré-marquer 1 à 5% du nombre total de tranches. Une nouvelle augmentation de volume n'entraîne pas une amélioration du résultat, comparable à l'augmentation du nombre de données précédemment marquées. Pour obtenir un meilleur balisage sur un si petit volume à l'aide d'un réseau de neurones, vous devez essayer d'autres approches, par exemple, affiner l'architecture et les stratégies d'apprentissage, le prétraitement des images, etc.
Pour le marquage préliminaire, il vaut la peine de choisir des tranches des deux types - en ligne et en croix.
Que se passe-t-il à une telle sortie? Un raffinement manuel des prédictions du réseau neuronal sera-t-il nécessaire? Si oui, dans quelle mesure est-il complexe et volumineux?
En conséquence, une partie importante des images marquées par un tel réseau neuronal ne nécessitera pas le raffinement le plus significatif, consistant en la correction de zones individuelles mal reconnues. Parmi eux, de telles interprétations ne nécessiteront aucune correction. Et uniquement pour des images uniques, vous devrez peut-être une nouvelle mise en page manuelle.
Bien sûr, lors de l'optimisation de l'algorithme d'apprentissage et des paramètres réseau, ses capacités de prédiction peuvent être améliorées. Dans notre expérience, la solution de ces problèmes n'a pas été incluse.
De plus, les résultats d'une étude sur un cube sismique ne devraient pas être généralisés sans réfléchir - précisément en raison de l'unicité de chaque ensemble de données. Mais ces résultats sont la confirmation d'une expérience menée par d'autres auteurs, et la base de comparaison avec nos études ultérieures, dont nous parlerons également sous peu.
Remerciements
Et à la fin, je voudrais remercier mes collègues de
MaritimeAI (en particulier Andrey Kokhan) et
ODS pour leurs précieux commentaires et leur aide!
Liste des sources utilisées:
- Bas Peters, Eldad Haber, Justin Granek. Réseaux de neurones pour les géophysiciens et leur application à l'interprétation des données sismiques
- Hao Wu, Bo Zhang. Un réseau neuronal codeur-décodeur convolutionnel profond pour aider le suivi de l'horizon sismique
- Thilo Wrona, Indranil Pan, Robert L. Gawthorpe et Haakon Fossen. Analyse des faciès sismiques à l'aide de l'apprentissage automatique
- Reinaldo Mozart Silva, Lais Baroni, Rodrigo S. Ferreira, Daniel Civitarese, Daniela Szwarcman, Emilio Vital Brésil. Pays-Bas: un nouveau jeu de données public pour l'apprentissage automatique en interprétation sismique