L'article se compose de deux parties:
- Une brève description de certaines architectures de réseau pour détecter des objets dans une image et une segmentation d'image avec les liens les plus compréhensibles pour les ressources pour moi. J'ai essayé de choisir des explications vidéo et de préférence en russe.
- La deuxième partie est une tentative de comprendre la direction du développement des architectures de réseaux de neurones. Et des technologies basées sur eux.

Figure 1 - Comprendre l'architecture des réseaux de neurones n'est pas facile
Tout a commencé avec le fait qu'il a fait deux applications de démonstration pour classer et détecter des objets sur un téléphone Android:
- Démo back-end , lorsque les données sont traitées sur le serveur et transférées sur le téléphone. Classification d'image de trois types d'ours: brun, noir et nounours.
- Démonstration frontale lorsque les données sont traitées sur le téléphone lui-même. Détection d'objets de trois types: noisettes, figues et dattes.
Il existe une différence entre les tâches de classification des images, de détection d'objets dans une image et de segmentation d'images . Par conséquent, il était nécessaire de savoir quelles architectures de réseaux de neurones détectent les objets dans les images et lesquelles peuvent se segmenter. J'ai trouvé les exemples d'architectures suivants avec les liens les plus compréhensibles vers les ressources pour moi:
- Une série d'architectures basées sur R-CNN ( R egions avec C onvolution N etural N etworks): R-CNN, Fast R-CNN, Faster R-CNN , Mask R-CNN . Pour détecter un objet dans une image à l'aide du mécanisme de réseau de propositions de région (RPN), des boîtes englobantes sont allouées. Initialement, le mécanisme de recherche sélective plus lent a été utilisé à la place du RPN. Ensuite, les régions limitées sélectionnées sont alimentées à l'entrée d'un réseau neuronal normal pour la classification. Dans l'architecture de R-CNN, il existe des cycles d'énumération «pour» explicites sur des régions limitées, pour un total de jusqu'à 2000 passages à travers le réseau interne AlexNet. En raison de boucles "for" explicites, la vitesse de traitement de l'image est ralentie. Le nombre de cycles explicites, parcourt le réseau neuronal interne, diminue avec chaque nouvelle version de l'architecture, et des dizaines d'autres changements sont effectués pour augmenter la vitesse et remplacer la tâche de détection des objets par la segmentation des objets dans le masque R-CNN.
- YOLO ( Y ou O nly L ook O nce) est le premier réseau neuronal à reconnaître des objets en temps réel sur des appareils mobiles. Particularité: distinguer les objets en un seul passage (il suffit de regarder une fois). Autrement dit, il n'y a pas de boucles "for" explicites dans l'architecture YOLO, c'est pourquoi le réseau est rapide. Par exemple, ceci est une analogie: dans NumPy, il n'y a pas de boucles explicites "pour" dans les opérations avec des matrices, qui sont implémentées dans NumPy à des niveaux d'architecture inférieurs via le langage de programmation C. YOLO utilise une grille de fenêtres prédéfinies. Pour éviter que le même objet ne soit détecté plusieurs fois, le coefficient de recouvrement de fenêtre (IoU, Intersection o ver Union) est utilisé. Cette architecture fonctionne dans une large gamme et a une grande robustesse : le modèle peut être formé en photographie, mais en même temps fonctionne bien dans les peintures peintes.
- SSD ( S ingle S hot MultiBox D etector) - les «hacks» les plus réussis de l'architecture YOLO (par exemple, la suppression non maximale) sont utilisés et de nouveaux sont ajoutés pour rendre le réseau neuronal plus rapide et plus précis. Particularité: distinguer les objets en une seule fois en utilisant une grille de fenêtres donnée (case par défaut) sur la pyramide d'images. La pyramide d'images est codée en tenseurs de convolution lors d'opérations de convolution et de mise en commun successives (avec l'opération de mise en commun maximale, la dimension spatiale diminue). De cette façon, les grands et les petits objets sont déterminés en une seule exécution de réseau.
- MobileSSD ( Mobile NetV2 + SSD ) est une combinaison de deux architectures de réseaux de neurones. Le premier réseau MobileNetV2 est rapide et augmente la précision de reconnaissance. MobileNetV2 est utilisé à la place de VGG-16, qui était à l'origine utilisé dans l' article d'origine . Le deuxième réseau SSD détermine l'emplacement des objets dans l'image.
- SqueezeNet est un réseau neuronal très petit mais précis. En soi, il ne résout pas le problème de la détection d'objets. Cependant, il peut être utilisé avec une combinaison de différentes architectures. Et être utilisé sur des appareils mobiles. Une caractéristique distinctive est que les données sont d'abord compressées en quatre filtres convolutionnels 1 × 1, puis étendues en quatre filtres convolutionnels 1 × 1 et quatre 3 × 3. Une telle itération de compression-expansion de données est appelée «module d'incendie».
- DeepLab (Segmentation d'image sémantique avec des réseaux convolutionnels profonds) - segmentation des objets dans l'image. Une caractéristique distinctive de l'architecture est une convolution diluée, qui préserve la résolution spatiale. Ceci est suivi par l'étape de post-traitement des résultats à l'aide d'un modèle graphique probabiliste (champ aléatoire conditionnel), qui vous permet de supprimer le petit bruit dans la segmentation et d'améliorer la qualité de l'image segmentée. Derrière le nom formidable de «modèle probabiliste graphique» se trouve le filtre gaussien habituel, qui est approximativement de cinq points.
- J'ai essayé de comprendre le dispositif AffinerDet (Réseau neuronal de raffinement à un coup pour la détection d'objets), mais j'ai un peu compris.
- J'ai également regardé comment fonctionne la technologie de l'attention: vidéo1 , vidéo2 , vidéo3 . Une caractéristique distinctive de l'architecture «d'attention» est l'attribution automatique de régions d'attention accrue à l'image (RoI, Régions de l'intérêt) à l'aide d'un réseau de neurones appelé Attention Unit. Les régions d'attention accrue sont similaires aux régions limitées (encadrés), mais contrairement à elles, elles ne sont pas fixées sur l'image et peuvent avoir des bordures floues. Ensuite, parmi les régions d'attention accrue, on distingue des caractéristiques (caractéristiques) qui sont «alimentées» à des réseaux de neurones récurrents avec des architectures LSDM, GRU ou Vanilla RNN . Les réseaux de neurones récursifs sont capables d'analyser la relation des signes dans une séquence. Les réseaux neuronaux récursifs étaient à l'origine utilisés pour traduire du texte dans d'autres langues, et maintenant pour traduire des images en texte et du texte en images .
En étudiant ces architectures, j'ai réalisé que je ne comprenais rien . Et le fait n'est pas que mon réseau de neurones a des problèmes avec le mécanisme d'attention. La création de toutes ces architectures ressemble à une sorte de hackathon énorme où les auteurs s'affrontent dans les hacks. Hack est une solution rapide à une tâche logicielle difficile. Autrement dit, il n'y a pas de connexion logique visible et compréhensible entre toutes ces architectures. Tout ce qui les unit est un ensemble de hacks les plus réussis qu'ils s'empruntent, plus une opération de convolution commune avec rétroaction (propagation inverse de l'erreur, rétropropagation). Pas de pensée systémique ! On ne sait pas quoi changer et comment optimiser les réalisations existantes.
En raison de l'absence de connexion logique entre les hacks, ils sont extrêmement difficiles à mémoriser et à mettre en pratique. Il s'agit de connaissances fragmentées. Dans le meilleur des cas, plusieurs moments intéressants et inattendus sont rappelés, mais la plupart de ce qui est compris et incompréhensible disparaît de la mémoire en quelques jours. Ce sera bien si dans une semaine je me souviens au moins du nom de l'architecture. Mais il a fallu plusieurs heures, voire plusieurs jours de temps de travail pour lire des articles et regarder des vidéos de critiques!
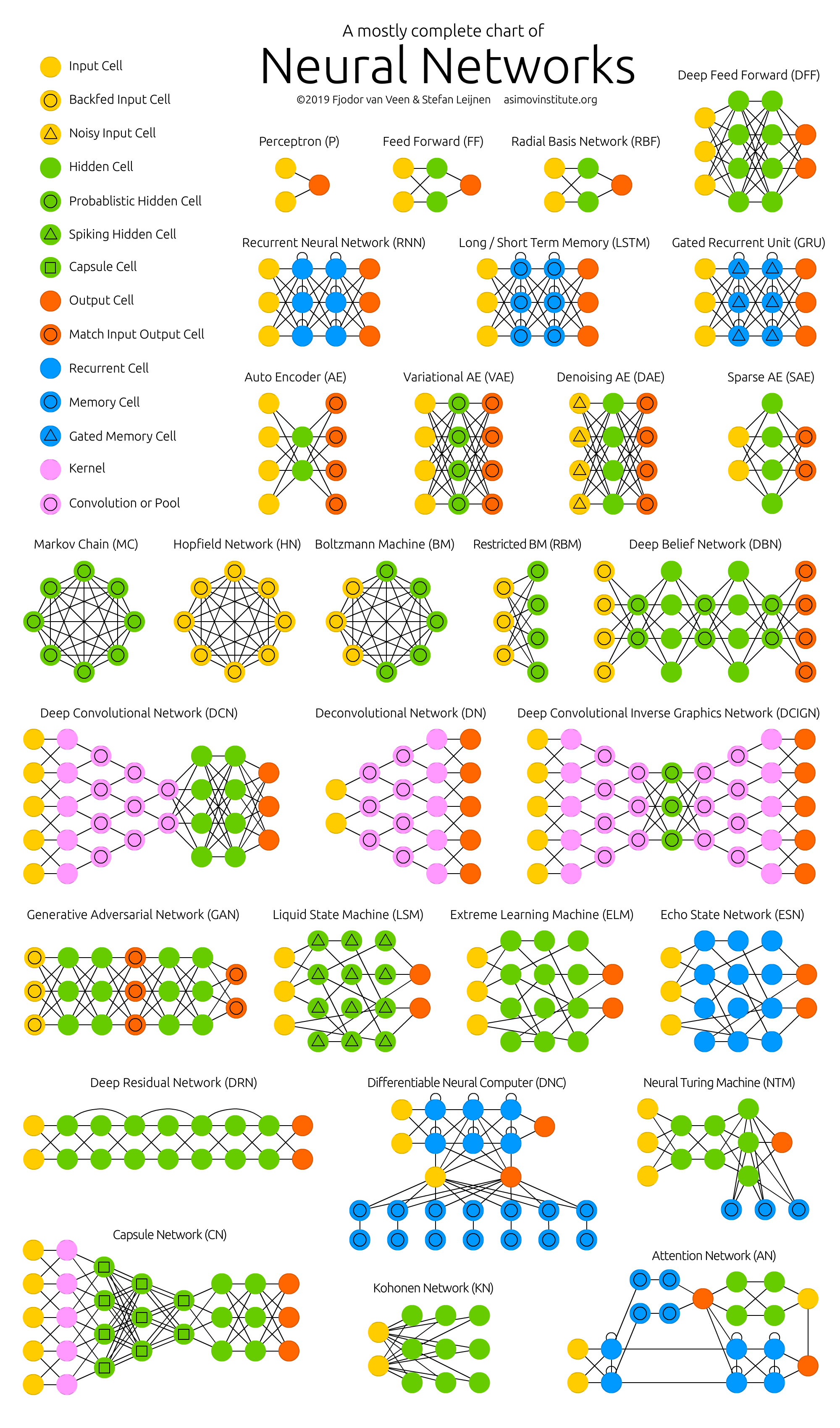
Figure 2 - Zoo de réseaux de neurones
La plupart des auteurs d'articles scientifiques, à mon avis, font tout leur possible pour que même cette connaissance fragmentée ne soit pas comprise par le lecteur. Mais les participes dans des phrases de dix lignes avec des formules prises "du plafond" sont un sujet pour un article séparé (problème de publication ou de disparition ).
Pour cette raison, il est devenu nécessaire de systématiser les informations sur les réseaux de neurones et, ainsi, d'augmenter la qualité de la compréhension et de la mémorisation. Par conséquent, le sujet principal de l'analyse des technologies et architectures individuelles des réseaux de neurones artificiels était la tâche suivante: découvrir où tout cela se déplace , et non le dispositif d'un réseau de neurones particulier séparément.
Où va tout cela. Les principaux résultats:
- Le nombre de startups dans le domaine de l'apprentissage automatique a fortement diminué au cours des deux dernières années. Raison possible: "les réseaux de neurones ont cessé d'être quelque chose de nouveau".
- Tout le monde pourra créer un réseau de neurones fonctionnel pour résoudre un problème simple. Pour ce faire, prenez le modèle fini du «zoo modèle» et entraînez la dernière couche du réseau de neurones ( transfert d'apprentissage ) sur les données finales de Google Dataset Search ou de 25 000 jeux de données Kaggle dans le nuage Jupyter Notebook gratuit.
- De grands fabricants de réseaux de neurones ont commencé à créer des «zoos modèles» (zoo modèle). En les utilisant, vous pouvez rapidement créer une application commerciale: TF Hub pour TensorFlow, MMDetection pour PyTorch, Detectron pour Caffe2, chainer-modelzoo pour Chainer et autres .
- Réseaux de neurones en temps réel sur appareils mobiles. 10 à 50 images par seconde.
- L'utilisation des réseaux de neurones dans les téléphones (TF Lite), dans les navigateurs (TF.js) et dans les articles ménagers (IoT, Internet et T hings). Surtout dans les téléphones qui prennent déjà en charge les réseaux de neurones au niveau matériel (neuroaccélérateurs).
- «Chaque appareil, chaque vêtement et peut-être même un aliment auront une adresse IP-v6 et communiqueront entre eux» - Sebastian Trun .
- L'augmentation des publications d'apprentissage automatique a commencé à dépasser la loi de Moore (doublant tous les deux ans) depuis 2015. De toute évidence, des réseaux neuronaux d'analyse d'articles sont nécessaires.
- Les technologies suivantes gagnent en popularité:
- PyTorch - La popularité augmente rapidement et semble dépasser TensorFlow.
- Sélection automatique des hyperparamètres AutoML - la popularité croît en douceur.
- Diminution progressive de la précision et augmentation de la vitesse de calcul: logique floue , algorithmes de boosting , calculs imprécis (approximatifs), quantification (lorsque les poids d'un réseau neuronal sont convertis en nombres entiers et quantifiés), neuroaccélérateurs.
- Traduction d' image en texte et texte en image .
- Création d' objets tridimensionnels sur vidéo , désormais en temps réel.
- L'essentiel dans DL est beaucoup de données, mais la collecte et le marquage ne sont pas faciles. Par conséquent, une annotation automatisée pour les réseaux de neurones utilisant des réseaux de neurones se développe.
- Avec les réseaux de neurones, l'informatique est soudainement devenue une science expérimentale et une crise de reproductibilité est apparue.
- L'argent informatique et la popularité des réseaux de neurones sont apparus simultanément lorsque l'informatique est devenue une valeur marchande. L'économie de l'or et des devises est en train de devenir une monnaie d'or . Voir mon article sur l' économie et la raison de l'émergence de l'IT-money.
Progressivement, une nouvelle méthodologie de programmation ML / DL (Machine Learning & Deep Learning) apparaît, basée sur la présentation du programme comme une collection de modèles de réseaux neuronaux formés.
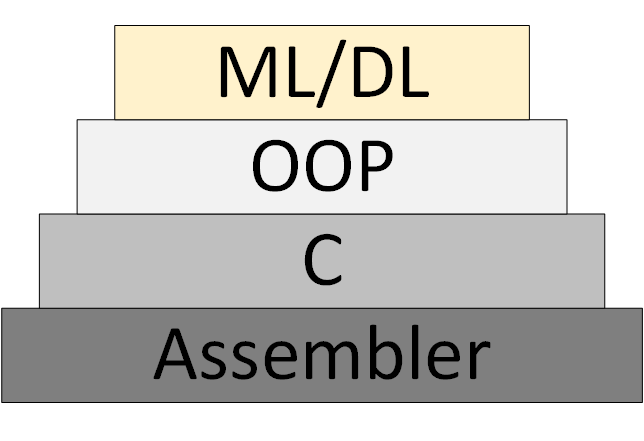
Figure 3 - ML / DL comme nouvelle méthodologie de programmation
Cependant, la «théorie des réseaux de neurones» n'est pas apparue, dans le cadre de laquelle on peut penser et travailler systématiquement. Ce que l'on appelle maintenant la «théorie» est en fait des algorithmes expérimentaux et heuristiques.
Liens vers mes ressources et pas seulement:
- Bulletin de la science des données. Surtout le traitement d'image. Qui veut recevoir, qu'il envoie un e-mail (foobar167 <gaff-gaf> gmail <dot> com). J'envoie des liens vers des articles et des vidéos à mesure que le matériel s'accumule.
- Une liste générale des cours et articles que j'ai suivis et que j'aimerais suivre.
- Cours et vidéos pour débutants , à partir desquels il vaut la peine de commencer à étudier les réseaux de neurones. Plus la brochure "Introduction à l'apprentissage automatique et aux réseaux de neurones artificiels" .
- Des outils utiles où chacun trouvera quelque chose d'intéressant.
- Les canaux vidéo pour l'analyse d'articles scientifiques sur la science des données se sont avérés extrêmement utiles. Trouvez-les, abonnez-vous et envoyez des liens à vos collègues et à moi aussi. Exemples:
Merci de votre attention!