Dans cet article, je vous présente mes réflexions sur l'histoire et les perspectives de développement de l'Internet, des réseaux centralisés et décentralisés et, par conséquent, de l'architecture possible du réseau décentralisé de prochaine génération.
Quelque chose ne va pas avec Internet
J'ai découvert Internet pour la première fois en 2000. Bien sûr, ce n'est pas le tout début - le Réseau existait déjà avant cela, mais ce temps peut être appelé le premier âge d'or d'Internet. Le World Wide Web est une brillante invention de Tim Berners-Lee, web1.0 dans sa forme canonique classique. De nombreux sites et pages qui se lient les uns aux autres avec des hyperliens. À première vue - une architecture simple, comme toute brillante:
décentralisée et gratuite . Je veux - je voyage sur les sites d'autres personnes, en suivant des hyperliens; Je veux - je crée mon propre site Web sur lequel je publie ce qui m'intéresse - par exemple, mes articles, photos, programmes, hyperliens vers des sites qui m'intéressent. Et d'autres m'envoient des liens.
Il semblerait - une image idyllique? Mais vous savez déjà comment tout cela s'est terminé.
Il y avait trop de pages et la recherche d'informations est devenue une chose très simple. Les hyperliens enregistrés par les auteurs n'ont tout simplement pas pu structurer cette énorme quantité d'informations. Il y a d'abord eu des répertoires remplis manuellement, puis des moteurs de recherche géants qui ont commencé à utiliser des algorithmes de classement heuristique ingénieux. Des sites ont été créés et abandonnés, les informations ont été dupliquées et déformées. Internet se commercialisait rapidement et s'éloignait davantage du réseau universitaire idéal. Le langage de balisage s'est rapidement transformé en langage de formatage. Il y avait la publicité, les bannières ennuyeuses et la technologie de promotion et de tromperie des moteurs de recherche - SEO. Le réseau s'est rapidement engorgé de déchets d'informations. Les hyperliens ont cessé d'être un outil de communication logique et sont devenus un outil de promotion. Les sites étaient choyés, fermés sur eux-mêmes, transformés de "pages" ouvertes en "applications" hermétiques, devenues le seul moyen de générer des revenus.
Même alors, j'avais une certaine pensée que "quelque chose ne va pas ici." Un tas de sites différents, allant de pages d'accueil primitives avec une apparence vyrviglazny, et se terminant par des "mégaportaux", surchargés de bannières vacillantes. Même si les sites sur le même sujet - ils sont complètement indépendants, chacun a sa propre conception, sa propre structure, des bannières ennuyeuses, une recherche qui fonctionne mal, des problèmes de téléchargement (oui, je voulais avoir des informations hors ligne). Même alors, Internet a commencé à se transformer en une sorte de télévision, où toutes sortes de guirlandes étaient épinglées à un contenu utile avec des clous.
La décentralisation est devenue un cauchemar.
Que veux-tu?
Paradoxalement, en tant qu'utilisateur, je n'avais pas besoin de décentralisation! En me souvenant de mes pensées claires de cette époque, j'arrive à la conclusion que j'avais besoin ... d'une
seule base de données ! Une telle requête à laquelle donneraient tous les résultats, mais pas la plus adaptée à l'algorithme de classement. Celui dans lequel tous ces résultats seraient uniformément stylisés et stylisés par mon propre design unique, plutôt que par des designs de vyrviglaznymi faits par de nombreux Vasya Pupkin. Celui qui pourrait être gardé hors ligne et ne pas avoir peur que demain le site disparaisse et que les informations disparaissent à jamais. Celui dans lequel je pouvais entrer mes informations - par exemple, les commentaires et les balises. Celui dans lequel je pouvais rechercher, trier et filtrer avec mes algorithmes personnels.
Web 2.0 et réseaux sociaux
Pendant ce temps, le concept Web 2.0 est entré dans l'arène. Formulée en 2005 par Tim O'Reilly comme «une méthodologie pour concevoir des systèmes qui, en prenant en compte les interactions réseau, s'améliorent au fur et à mesure que les gens les utilisent» - et impliquant l'implication active des utilisateurs dans la création collective et l'édition de contenu Web. Sans exagération, les réseaux sociaux sont devenus le summum et le triomphe de ce concept. Des plateformes géantes qui rassemblent des milliards d'utilisateurs et stockent des centaines de pétaoctets de données.
Qu'avons-nous obtenu dans les réseaux sociaux?
- unification de l'interface; il s'est avéré que toutes les possibilités de création d'un design vyviglazny diversifié n'ont pas besoin des utilisateurs; toutes les pages de tous les utilisateurs ont le même design et il convient à tout le monde et est même pratique; seul le contenu est différent.
- unification fonctionnelle; toute la variété des scripts était également inutile. Lenta, amis, albums ... pendant l'existence des réseaux sociaux, leur fonctionnalité s'est plus ou moins stabilisée et est peu susceptible de changer: après tout, la fonctionnalité est déterminée par les types d'activité des gens, et les gens ne changent pratiquement pas.
- base de données unique; travailler avec une telle base de données s'est avéré beaucoup plus pratique qu'avec de nombreux sites disparates; la recherche est devenue beaucoup plus facile. Au lieu d'analyser en continu une variété de pages à couplage lâche, de mettre tout cela en cache, de les classer par des algorithmes heuristiques complexes - une requête unifiée relativement simple dans une seule base de données avec une structure connue.
- interface de rétroaction - likes et reposts; sur le Web normal, le même Google n'a pas pu obtenir de commentaires des utilisateurs après avoir cliqué sur le lien dans les résultats de la recherche. Dans les réseaux sociaux, cette connexion était simple et naturelle.
Qu'avons-nous perdu?
Nous avons perdu la décentralisation, ce qui signifie la liberté . On pense que maintenant nos données ne nous appartiennent pas. Si auparavant nous pouvions héberger une page d'accueil même sur notre propre ordinateur, maintenant nous donnons toutes nos données aux géants d'Internet.
De plus, à mesure qu'Internet évoluait, les gouvernements et les entreprises s'y sont intéressés et il y a eu des problèmes de censure politique et de restrictions du droit d'auteur. Nos pages sur les réseaux sociaux peuvent être interdites et supprimées si le contenu n'est pas conforme aux règles du réseau social; pour un poste imprudent - engager une responsabilité administrative voire pénale.
Et là, nous réfléchissons encore: est-il possible de nous restituer la décentralisation? Mais sous une forme différente, dépourvue des lacunes de la première tentative?
Réseaux d'égal à égal
Les premiers réseaux p2p sont apparus bien avant le web 2.0 et se sont développés en parallèle avec le développement du web. La principale application classique de p2p est le partage de fichiers; les premiers réseaux ont été conçus pour partager de la musique. Les premiers réseaux (comme Napster) étaient essentiellement centralisés et les titulaires de droits d'auteur les ont donc rapidement couverts. Les adeptes ont pris le chemin de la décentralisation. En 2000, les protocoles ED2K (le premier client eDokney) et Gnutella sont apparus; en 2001, le protocole FastTrack (client KaZaA) est apparu. Progressivement, le degré de décentralisation a augmenté, les technologies se sont améliorées. Les systèmes avec une «file d'attente de téléchargement» ont été remplacés par des torrents, et le concept de tables de hachage DHT distribuées est apparu. Comme les noix ont été resserrées par les États, l'anonymat des participants est devenu plus exigé. Depuis 2000, le réseau Freenet est en développement, depuis 2003 I2P, et en 2006 le projet RetroShare a été lancé. Vous pouvez mentionner les nombreux réseaux p2p qui existaient auparavant et ont déjà disparu - et sont maintenant opérationnels: WASTE, MUTE, TurtleF2F, RShare, PerfectDark, ARES, Gnutella2, GNUNet, IPFS, ZeroNet, Tribbler et bien d'autres. Il y en a beaucoup. Ils sont différents. Très différent - à la fois dans le but et dans la conception ... Probablement beaucoup d'entre vous ne connaissent même pas tous ces noms. Et c'est loin d'être tout.
Cependant, les réseaux p2p présentent de nombreux inconvénients. En plus des défauts techniques inhérents à chaque implémentation spécifique du protocole et du client, par exemple, un inconvénient assez général est la complexité de la recherche (c'est-à-dire tout ce que Web 1.0 a rencontré, mais dans une version encore plus compliquée). Google n'est pas là avec sa recherche omniprésente et instantanée. Et si pour les réseaux de partage de fichiers, vous pouvez toujours utiliser la recherche par nom de fichier ou méta-informations, alors trouver quelque chose, par exemple, dans les réseaux de superposition oignon ou i2p, est très difficile, si possible.
En général, si nous établissons des analogies avec l'Internet classique, la plupart des réseaux décentralisés sont bloqués quelque part au niveau FTP. Imaginez Internet, dans lequel il n'y a que FTP: ni sites modernes, ni web2.0, ni Youtube ... C'est à peu près dans cet état, et il y a des réseaux décentralisés. Et malgré les tentatives individuelles de changer quelque chose, il y a peu de changements.
Le contenu
Passons à une autre pièce importante de ce puzzle - le contenu. Le contenu est le principal problème de toute ressource Internet, et notamment décentralisée. D'où l'obtenir? Bien sûr, vous pouvez compter sur un tas de passionnés (comme c'est le cas avec les réseaux p2p existants), mais alors le développement du réseau sera assez long et il y aura peu de contenu.
Travailler avec l'Internet normal est la recherche et l'étude de contenu. Parfois, c'est la préservation (si le contenu est intéressant et utile, alors beaucoup, en particulier ceux qui sont venus sur le réseau pendant la période de connexion - y compris moi) le gardent hors ligne de manière sage afin de ne pas se perdre; car Internet est une chose incontrôlable pour nous, aujourd'hui il n'y a pas de site Web demain , aujourd'hui il y a une vidéo sur YouTube - demain elle a été supprimée, etc.
Et pour les torrents (que nous percevons plus comme un simple moyen de livraison que comme un réseau p2p), la conservation est généralement implicite. Et cela, en passant, est l'un des problèmes des torrents: il est difficile de déplacer le fichier téléchargé une fois où il est plus pratique de l'utiliser (en règle générale, vous devez régénérer manuellement la distribution) et il est absolument impossible de le renommer (vous pouvez créer un lien dur, mais très peu de gens le savent).
En général, de nombreux magasins stockent le contenu d'une manière ou d'une autre. Quel est son futur destin? Habituellement, les fichiers enregistrés apparaissent quelque part sur le disque, dans un dossier comme Téléchargements, dans un segment de mémoire commun, et s'y trouvent avec plusieurs milliers d'autres fichiers. C'est mauvais - et mauvais pour l'utilisateur lui-même. Si Internet a des moteurs de recherche, alors l'ordinateur local de l'utilisateur n'a rien de tel. C'est bien si l'utilisateur est soigné et utilisé pour trier les fichiers téléchargés «entrants». Mais pas tous ...
En fait, il y a maintenant beaucoup de ceux qui n'enregistrent rien, mais qui se fient entièrement à Internet. Mais dans les réseaux p2p, il est supposé que le contenu est stocké localement sur l'appareil de l'utilisateur et distribué aux autres participants. Est-il possible de trouver une solution qui permettra d'impliquer les deux catégories d'utilisateurs dans un réseau décentralisé sans changer leurs habitudes, et en plus, leur faciliter la vie?
L'idée est assez simple: que se passe-t-il si nous créons un moyen pratique et transparent pour l'utilisateur de sauvegarder du contenu à partir d'Internet normal, et de sauvegarder intelligemment avec des méta-informations sémantiques, et non pas dans un tas général, mais dans une structure spécifique avec la possibilité de structurer davantage, et en même temps distribuer le contenu enregistré à décentralisé le réseau?
Commençons par économiser
Nous ne considérerons pas l'utilisation utilitaire d'Internet pour consulter les prévisions météorologiques ou les horaires des avions. Nous nous intéressons davantage aux objets autonomes et plus ou moins immuables - articles (à partir de tweets / posts de réseaux sociaux et se terminant par de gros articles, comme ici sur Habré), livres, images, programmes, enregistrements audio et vidéo. D'où proviennent les informations? Habituellement,
- réseaux sociaux (nouvelles diverses, petites notes - «tweets», photos, audio et vidéo)
- articles sur les ressources thématiques (comme Habr); il n'y a pas beaucoup de bonnes ressources, généralement ces ressources sont également construites sur le principe des réseaux sociaux
- sites d'actualités
En règle générale, il existe des fonctions standard: aimer, republier, partager sur les réseaux sociaux, etc.
Imaginez un
plug-in de navigateur qui enregistrera de manière spéciale tout ce que nous avons aimé, republié, enregistré dans le "favori" (ou cliqué sur un bouton de plug-in spécial affiché dans le menu du navigateur au cas où le site n'aurait pas de fonction similaire / repost / bookmark). L'idée principale est que vous aimez - comme vous l'avez fait un million de fois auparavant, et le système enregistre l'article, l'image ou la vidéo dans un stockage hors ligne spécial et cet article ou cette image devient disponible - et pour une visualisation hors ligne via l'interface client décentralisée , et dans le réseau le plus décentralisé! Moi, c'est très pratique. Aucune action inutile et nous résolvons immédiatement de nombreux problèmes:
- enregistrer du contenu précieux qui peut être perdu ou supprimé
- remplissage rapide du réseau décentralisé
- agrégation de contenu provenant de différentes sources (vous pouvez être enregistré dans des dizaines de ressources Internet, et tous les likes / reposts afflueront vers une seule base de données locale)
- structurer votre contenu selon vos règles
Évidemment, le plug-in du navigateur doit être configuré sur la structure de chaque site (c'est assez réaliste - il existe déjà des plugins pour sauvegarder du contenu de Youtube, Twitter, VK, etc.). Il n'y a pas tellement de sites pour lesquels il est logique de créer des plugins personnels. Il s'agit en général de réseaux sociaux très répandus (il n'y en a guère plus d'une douzaine) et d'un certain nombre de sites thématiques de grande qualité comme Habr (il y en a aussi peu). Avec le code et les spécifications open source, le développement d'un nouveau plugin basé sur un modèle vierge ne devrait pas prendre beaucoup de temps. Pour les autres sites, vous pouvez utiliser le bouton d'enregistrement universel, qui enregistrerait la page entière en mhtml - éventuellement après avoir supprimé la page de la publicité.
Maintenant sur la structuration
Par sauvegarde «intelligente», j'entends au moins la sauvegarde avec des méta-informations: source de contenu (URL), ensemble de likes précédemment définis, tags, commentaires, leurs identifiants, etc. En effet, lors d'un stockage normal, ces informations sont perdues ... Une source peut signifier non seulement une URL directe, mais aussi un composant sémantique: par exemple, un groupe sur les réseaux sociaux ou un utilisateur qui a republié. Le plugin peut être suffisamment intelligent pour utiliser ces informations pour la structuration et le balisage automatiques. En outre, il faut comprendre que l'utilisateur lui-même peut toujours ajouter des méta-informations au contenu stocké, pour lesquelles vous devez fournir des outils d'interface masquablement pratiques (j'ai beaucoup d'idées sur la façon de le faire).
Ainsi, le problème de la structuration et de l'organisation des fichiers utilisateurs locaux est résolu. Il s'agit d'un avantage prêt à l'emploi qui peut être utilisé même sans p2p. C'est juste une sorte de base de données hors ligne qui sait quoi, où et dans quel contexte nous avons enregistré, et vous permet de mener de petites études. Par exemple, trouvez des utilisateurs d'un réseau social externe qui aiment surtout sous les mêmes messages que vous. Combien de réseaux sociaux le permettent explicitement?
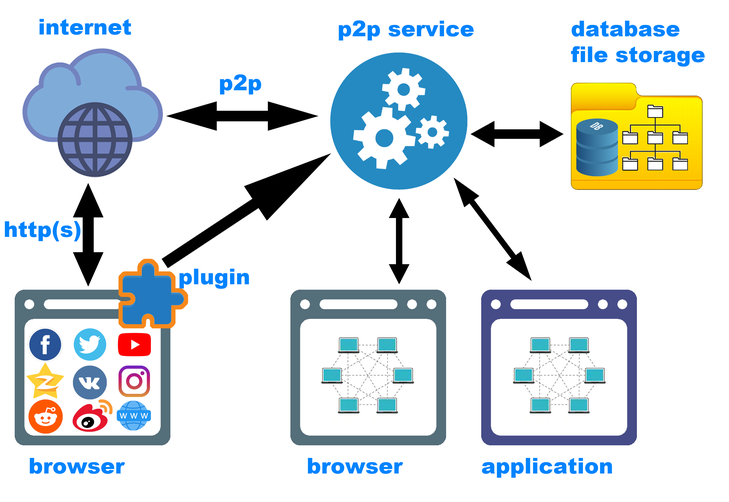
Il convient déjà de mentionner ici qu'un plugin de navigateur n'est certainement pas suffisant. Le deuxième composant le plus important du système est un service réseau décentralisé qui s'exécute en arrière-plan et dessert à la fois le réseau p2p lui-même (demandes du réseau et demandes du client), ainsi que l'enregistrement de nouveau contenu à l'aide du plug-in. Le service, en collaboration avec le plugin, placera le contenu au bon endroit, calculera les hachages (et déterminera éventuellement qu'un tel contenu a déjà été enregistré), ajoutera les méta-informations nécessaires à la base de données locale.
Ce qui est intéressant - le système serait déjà utile sous cette forme, sans p2p. De nombreuses personnes utilisent des clippers Web qui ajoutent du contenu intéressant du Web, par exemple, à Evernote. L'architecture proposée est une version étendue d'un tel clipper.
Enfin, échange p2p
La meilleure partie est que les informations et les méta-informations (à la fois capturées sur le Web et les vôtres) peuvent être échangées. Le concept de réseau social est bien porté à l'architecture p2p. On peut dire que le réseau social et le p2p semblent être faits l'un pour l'autre. Tout réseau décentralisé devrait idéalement être construit comme un réseau social, ce n'est qu'alors qu'il fonctionnera efficacement. «Amis», «Groupes» - ce sont les fêtes mêmes avec lesquelles il devrait y avoir des liens stables, et ceux qui sont tirés d'une source naturelle - les intérêts communs des utilisateurs.
Les principes de stockage et de distribution de contenu dans un réseau décentralisé sont complètement identiques aux principes de stockage (capture) de contenu à partir d'Internet ordinaire. Si vous utilisez du contenu du réseau (ce qui signifie que vous l'avez enregistré), n'importe qui peut utiliser vos ressources (disque et canal) nécessaires pour recevoir ce contenu spécifiquement.
Les likes sont l'outil le plus simple pour enregistrer et partager. Si j'aime - cela n'a pas d'importance, sur Internet externe ou à l'intérieur d'un réseau décentralisé - alors j'aime le contenu, et si oui, alors je suis prêt à le conserver localement et à le distribuer à d'autres membres du réseau décentralisé.
- Le contenu n'est pas "perdu"; il est maintenant stocké localement avec moi, je peux y revenir plus tard, à tout moment, sans craindre que quelqu'un le supprime ou le bloque
- Je peux (immédiatement ou plus tard) le catégoriser, étiqueter, commenter, associer à d'autres contenus, en général, faire quelque chose de significatif avec lui - appelons-le «formation de méta-informations»
- Je peux partager cette méta-information avec d'autres membres du réseau.
- Je peux synchroniser mes méta-informations avec les méta-informations des autres participants
Probablement, le refus des aversions semble également logique: si je n'aime pas le contenu, il est tout à fait logique que je ne veuille pas gaspiller mon espace disque pour le stockage et ma chaîne Internet pour distribuer ce contenu. Par conséquent, les aversions très organiques ne rentrent pas dans la décentralisation (même si parfois elles sont toujours
utiles ).
Parfois, vous devez également enregistrer ce que vous n'aimez pas. Il y a un tel mot "nécessaire" :)
«
Signets » (ou «Favoris») - Je n'exprime pas mon attitude envers le contenu, mais je le sauvegarde dans ma base de données de signets locale. «» (favorites) ( ), «» (bookmarks) — . «» — «» (.. «» ), «» - . ?
"
". , , , . () .
"
" — , , - , — , . , «», , — , / , .
, . — . — . , , , .
, , . , , , . , -, , ; , , .
, . , . , , , .. , . — , (, «» — , … , ).
, — ( i2p Retroshare), TOR VPN.
( ). , — , . — p2p , («backend»). , . — frontend. - ( ), GUI- (Windows, Linux, MacOS, Andriod, iOS ..). frontend'. backend'.
, . (.. , , , , — , , , ..), ( , Libgen), ( Freenet), ( ), ( — , , , , ..) .
1. — . (, ...) (, ...) —
2. , — /; p2p,
3.
4. /