Les systèmes de contrôle de version sont depuis longtemps un outil quotidien pour les développeurs. Dans les grands monorepositoires, leurs exigences sont très spécifiques. Pour cette raison, les entreprises adaptent les solutions existantes, comme Facebook le fait avec Mercurial et Microsoft avec Git, ou développent leurs propres systèmes: Piper et CitC sur Google et Arc VCS sur Yandex.
Dans le rapport, le développeur Vladimir Kikhtenko
kikht explique pourquoi Yandex avait besoin de son propre système de contrôle de version et comment cela fonctionne. Considérez-le du côté d'un développeur ordinaire: comment accéder au code source, mettre de côté une branche pour le développement et intégrer les modifications dans une base de code commune. Nous regardons sous le capot - nous apprenons la représentation interne des données et leur affichage dans un système de fichiers virtuel avec une copie de travail. Nous discuterons des difficultés de mise en œuvre des fonctions VCS dans un système de fichiers virtuel et lors du chargement de données paresseux. Parlons de la façon de garantir la fiabilité de l'infrastructure de serveur du référentiel.
À la fin, vous pouvez voir un enregistrement non officiel du rapport.
- Bonjour tout le monde, je m'appelle Vladimir. Vous avez tous entendu des discours disant de ne pas écrire de vélos. Mon rapport sera de l'autre côté de la barricade.
En effet, Yandex possède un monorepositaire dans lequel il y a beaucoup de code. Et nous sommes arrivés à la conclusion que nous développons notre propre système de contrôle de version.

Comment en sommes-nous arrivés à une telle vie? Historiquement, ce monorepositaire a vécu avec nous dans SVN. Il pratique le développement basé sur le tronc. Il n'y a pas de succursales avec très peu d'exceptions. Tout le code doit d'abord entrer dans le coffre, puis devenir plein.
Avec la croissance du référentiel, le seul moyen possible de travailler avec lui était le paiement sélectif, car il est pris en charge dans SVN. Le téléchargement de l'ensemble du référentiel pour vous-même n'est pas entièrement impossible, mais travailler avec lui est très difficile.

Quelle est l'ampleur de notre problème? Voici quelques chiffres: 6 millions de commits, près de 2 millions de fichiers individuels. La taille totale avec l'historique complet du référentiel est de 2 To. Pour clarifier la signification de ces chiffres par rapport à d'autres référentiels typiques, voici un graphique. La médiane GitHub est la taille médiane du référentiel sur GitHub, 1 Mo. Le 90e centile sur GitHub est ce que mes collègues ont appelé le "référentiel du fils de la petite amie de ma mère". Et tout le reste, ce sont les fameux grands référentiels.
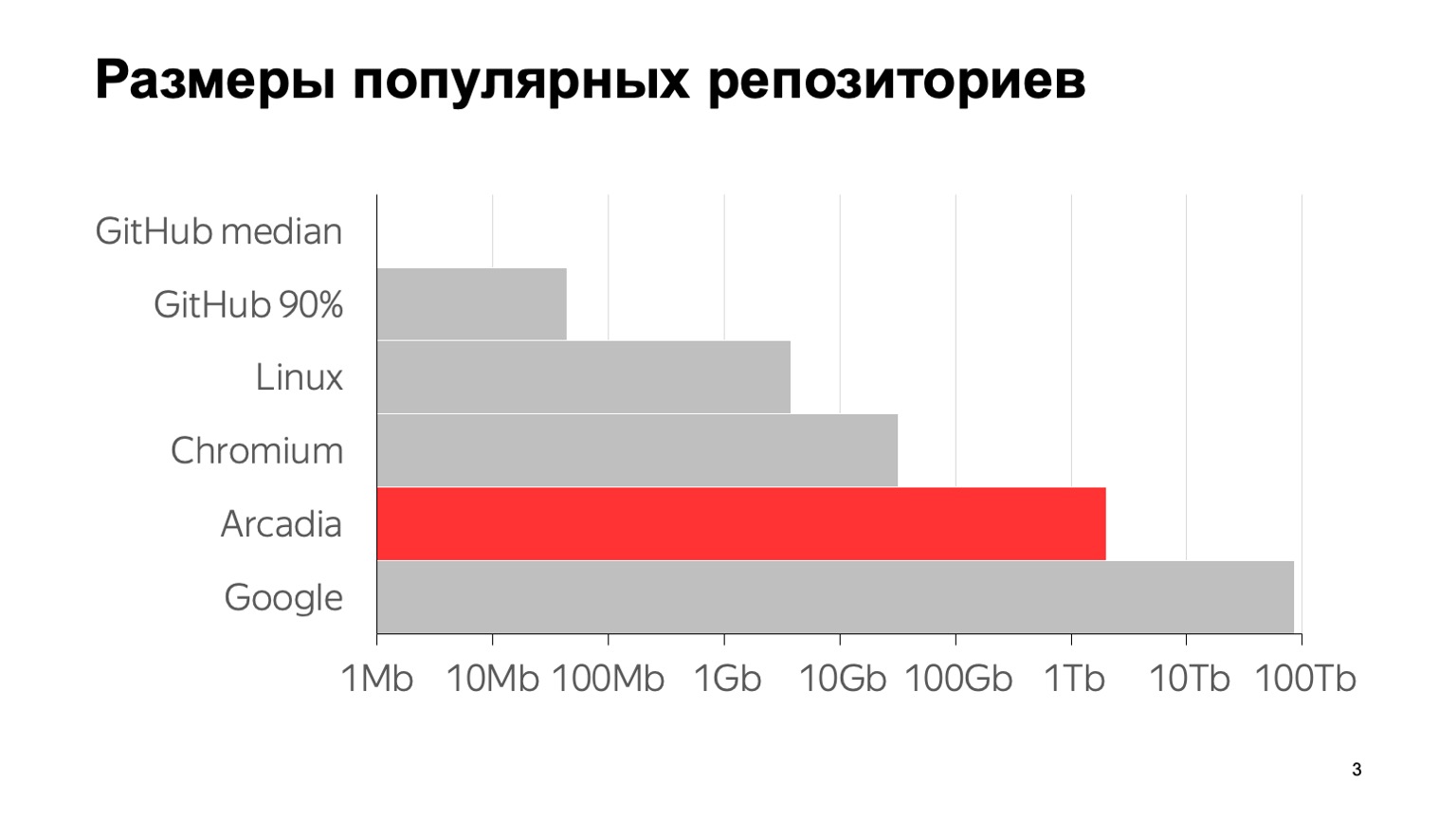
Pour autant que je sache, le plus grand référentiel au monde est avec Google. Une estimation de sa taille est donnée à partir d'un article en 2015 - probablement depuis lors, ils ont augmenté. Comme vous pouvez le voir, l'échelle est logarithmique. On peut voir que nous sommes également assez grands.
Comment fonctionnent les différents systèmes de contrôle de version lorsque vous essayez de télécharger l'intégralité de ce référentiel? Naturellement, nous n'avons pas immédiatement commencé à développer notre système de contrôle de version. Nous avons essayé de convertir notre référentiel en différents systèmes. La tentative la plus sérieuse a été faite avec Mercurial. Et les résultats de l'époque des opérations typiques ne nous conviennent toujours pas.
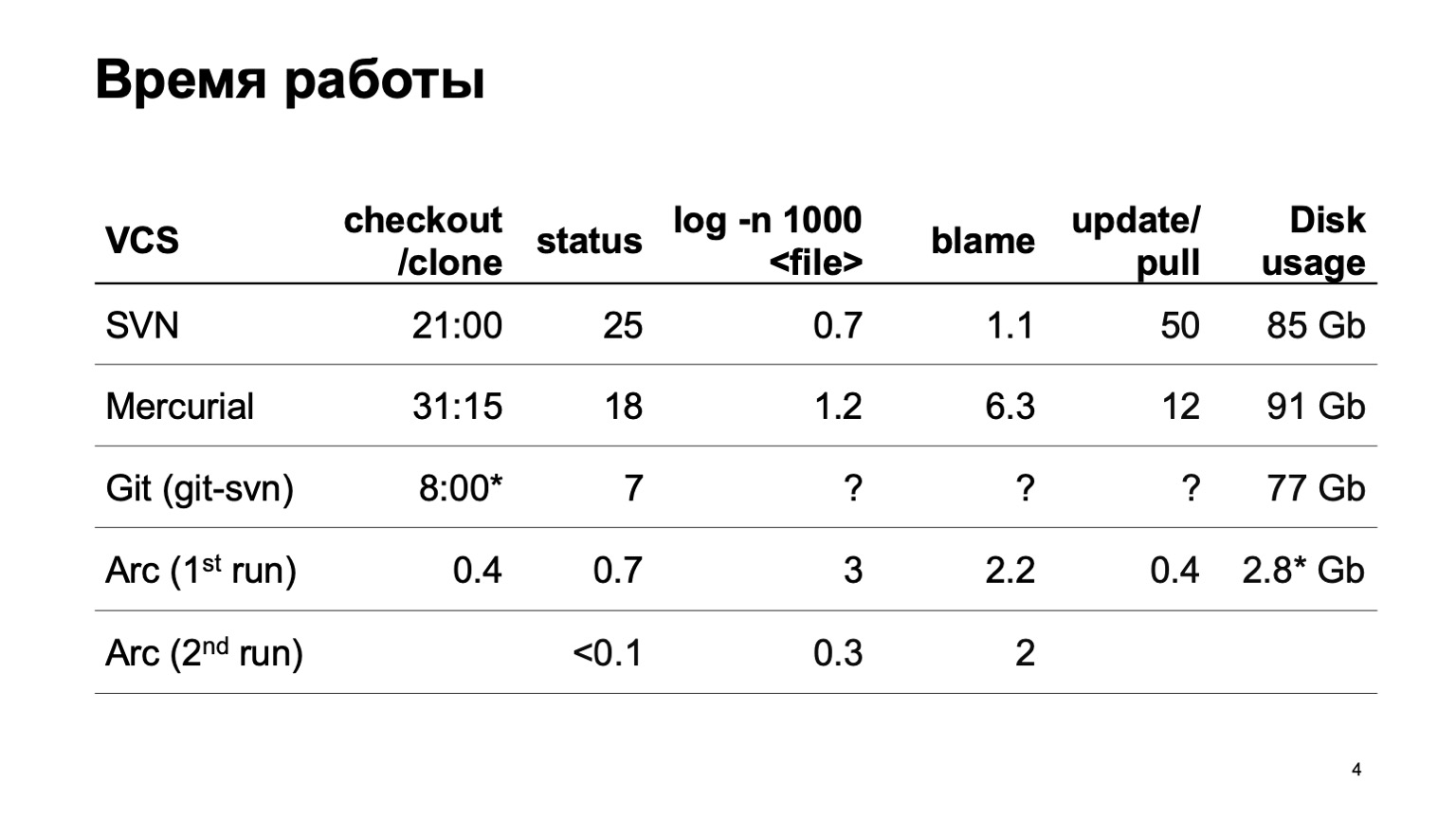
Lors de la préparation du rapport, git-svn n'a malheureusement pas pu convertir l'intégralité de notre référentiel. J'ai converti une tranche d'un petit nombre de validations, donc je ne peux pas estimer le nombre d'opérations liées à l'historique. Dans un segment, ils sont rapides, et ce que ce sera pour 6 millions de commits n'est pas très clair.
À la fin sont les numéros de notre système de contrôle de version. Vous pouvez instantanément vous procurer une copie de travail. Au premier démarrage, les opérations de journalisation sont légèrement ralenties; au deuxième démarrage, tout fonctionne rapidement.
Et le dernier chiffre. Puisque notre système de contrôle de version charge toutes les données paresseusement, seuls les codes source que nous avons vraiment élaborés, que nous avons vraiment utilisés, sont sur le disque. C'est beaucoup moins que de télécharger le tout.

Comment y sommes-nous parvenus? La principale caractéristique: la copie de travail que nous créons n'est pas un vrai fichier sur disque. Il s'agit d'un système de fichiers virtuel. Sous Linux et Mac, cela se fait avec fusible, sous Windows avec ProjFS. Nous chargeons toutes les données paresseusement, donc autant d'espace disque est utilisé que nous en avons vraiment besoin, nous n'essayons pas de tout charger à l'avance. Et nous effectuons toutes sortes d'opérations lourdes sur le serveur. En particulier - le fonctionnement du journal et quelques autres.

L'interface de notre système de contrôle de version, dans l'ensemble, répète Git, donc je ne montrerai pas à quoi ressemble un flux de travail typique. Imaginez Git. Tout est pareil: checkout pour obtenir la révision souhaitée, branche pour créer des branches, commit pour les commits, stash est également supporté de la même manière. Que donne cette approche? Nous réduisons considérablement le seuil d'entrée. La plupart des développeurs à l'intérieur et à l'extérieur de Yandex peuvent travailler avec Git. Ils n'ont rien à apprendre de nouveau.
D'un autre côté, nous n'avons aucun objectif de faire du drop en remplacement de Git. J'en parlerai plus tard plus en détail. Pour soutenir toute la variété des équipes git semble fou, nous avons à peine besoin de toutes.

Je vais vous parler un peu de l'intérieur, de la façon dont tout cela fonctionne. Commençons par le modèle de données. Notre modèle de données est très similaire au modèle géographique, avec quelques différences. De la même manière, tous les objets que nous créons à l'intérieur sont immuables, ils sont adressés par un hachage de leur contenu, et à l'intérieur ils sont stockés dans des tampons plats.

À quoi ressemble la structure? Il y a des objets commit, chaque commit a un ou plusieurs ancêtres. Et de cette façon, ils construisent des histoires DAG (graphique acyclique dirigé).
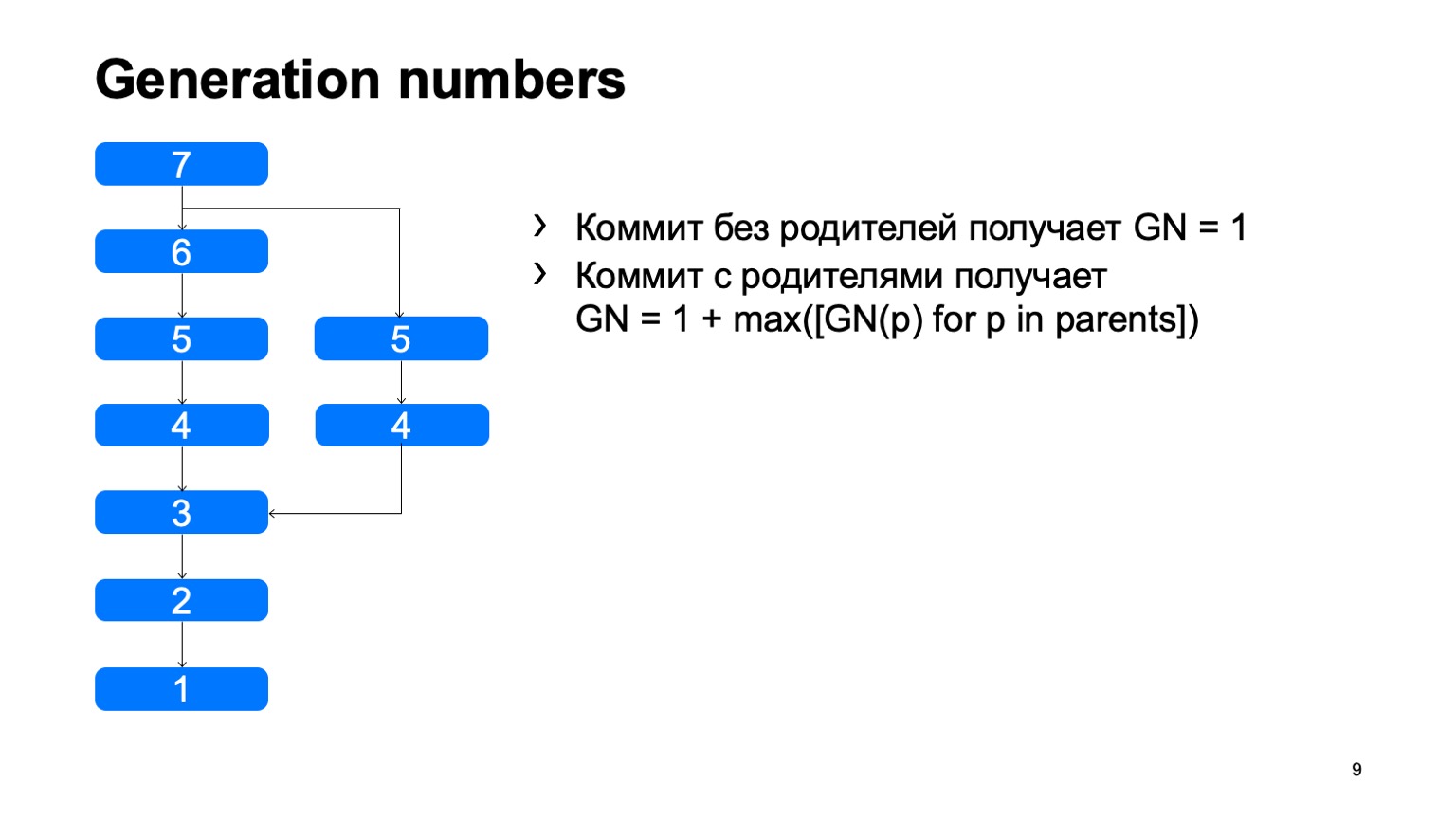
Ce que nous avons et ce qui n'est pas immédiatement apparu dans Git, ce sont les nombres de génération. En utilisant un algorithme simple, nous considérons une certaine distance de la racine de l'arbre. Pourquoi en avons-nous besoin? Tout cela est cousu dans la structure des objets, une fois fixé, et ne change plus jamais.
Une opération assez importante pour un système de contrôle de version consiste à trouver le plus petit ancêtre commun pour les deux validations. Dans la version de base, il peut être implémenté simplement en parcourant en largeur, à partir de deux points environ, en marquant tous les commits atteints avec l'un ou l'autre signe, dès qu'ils trouvent un commit qui a ces deux signes, il y a l'ancêtre le moins commun.
Comment cela fonctionnera-t-il dans une implémentation naïve? Quelque chose comme ça: faites le tour et trouvez notre engagement souhaité.
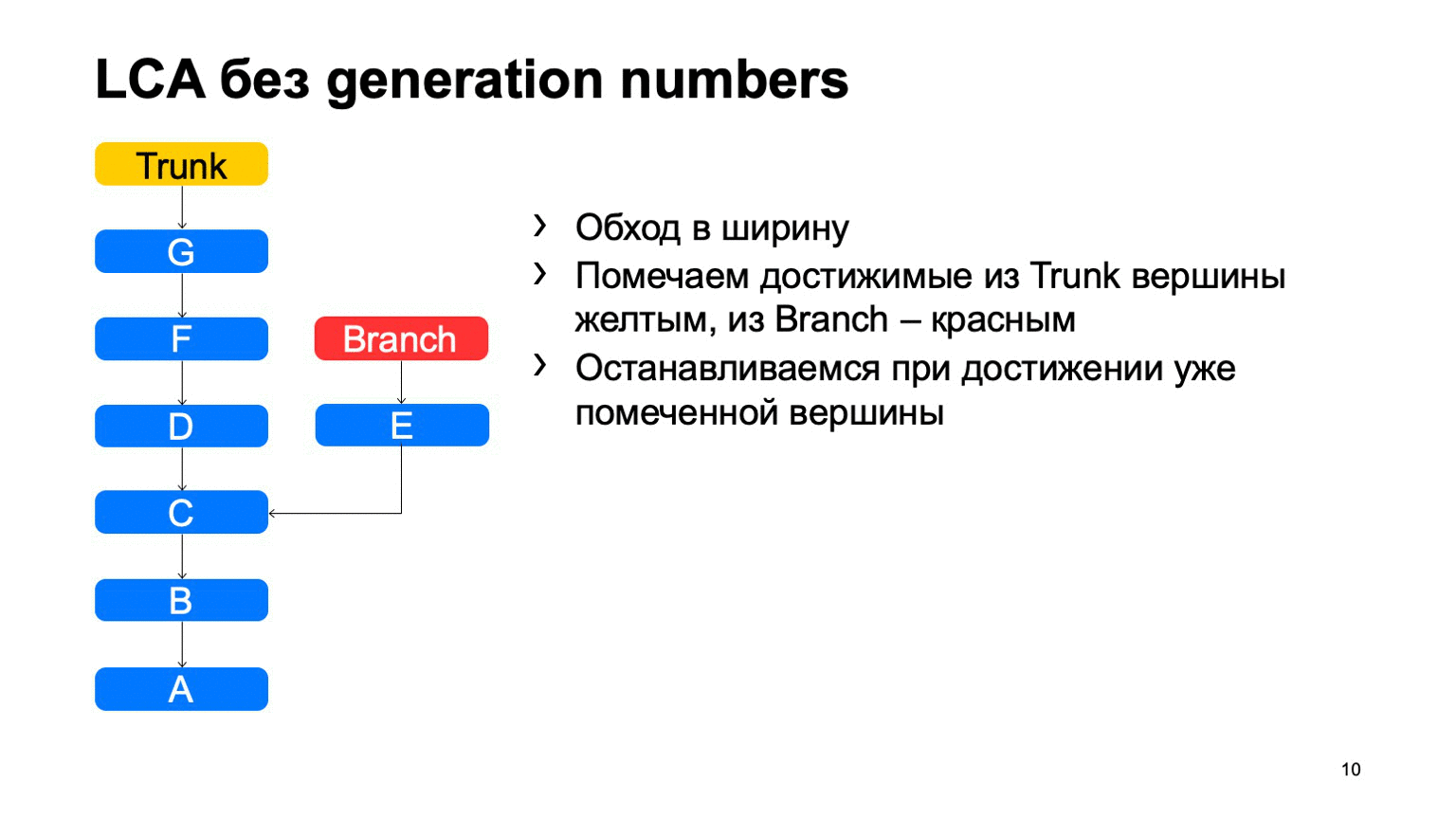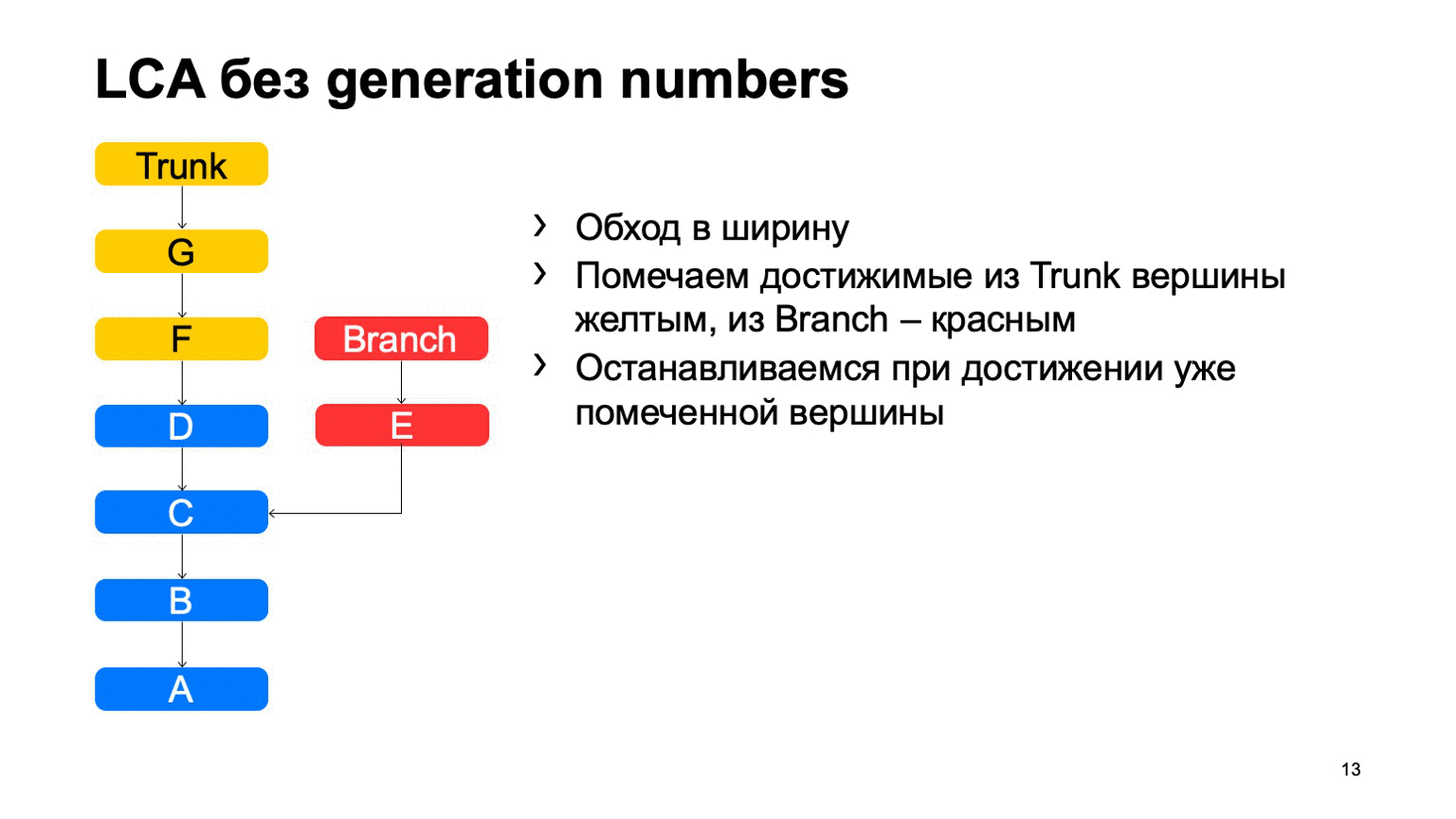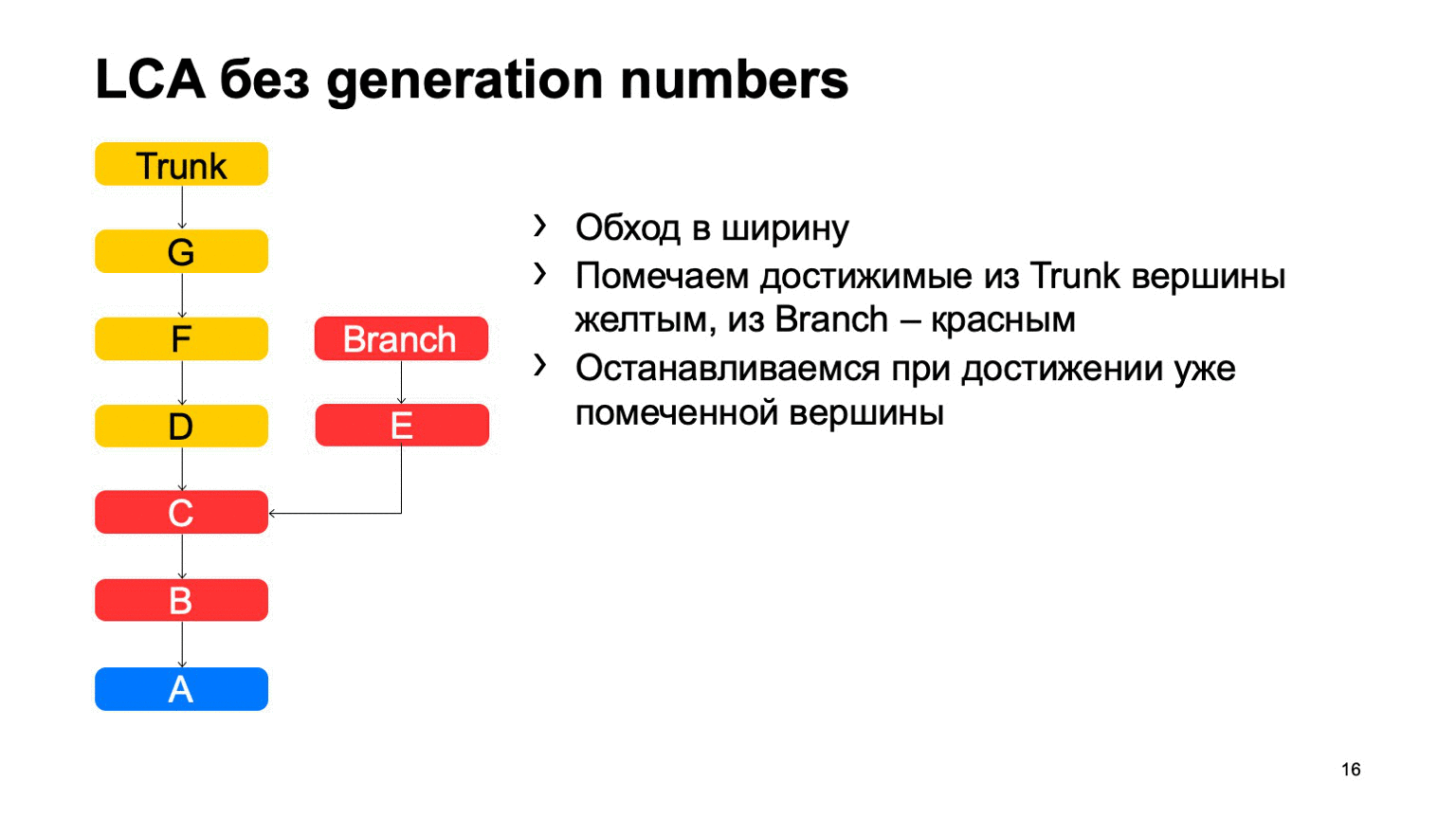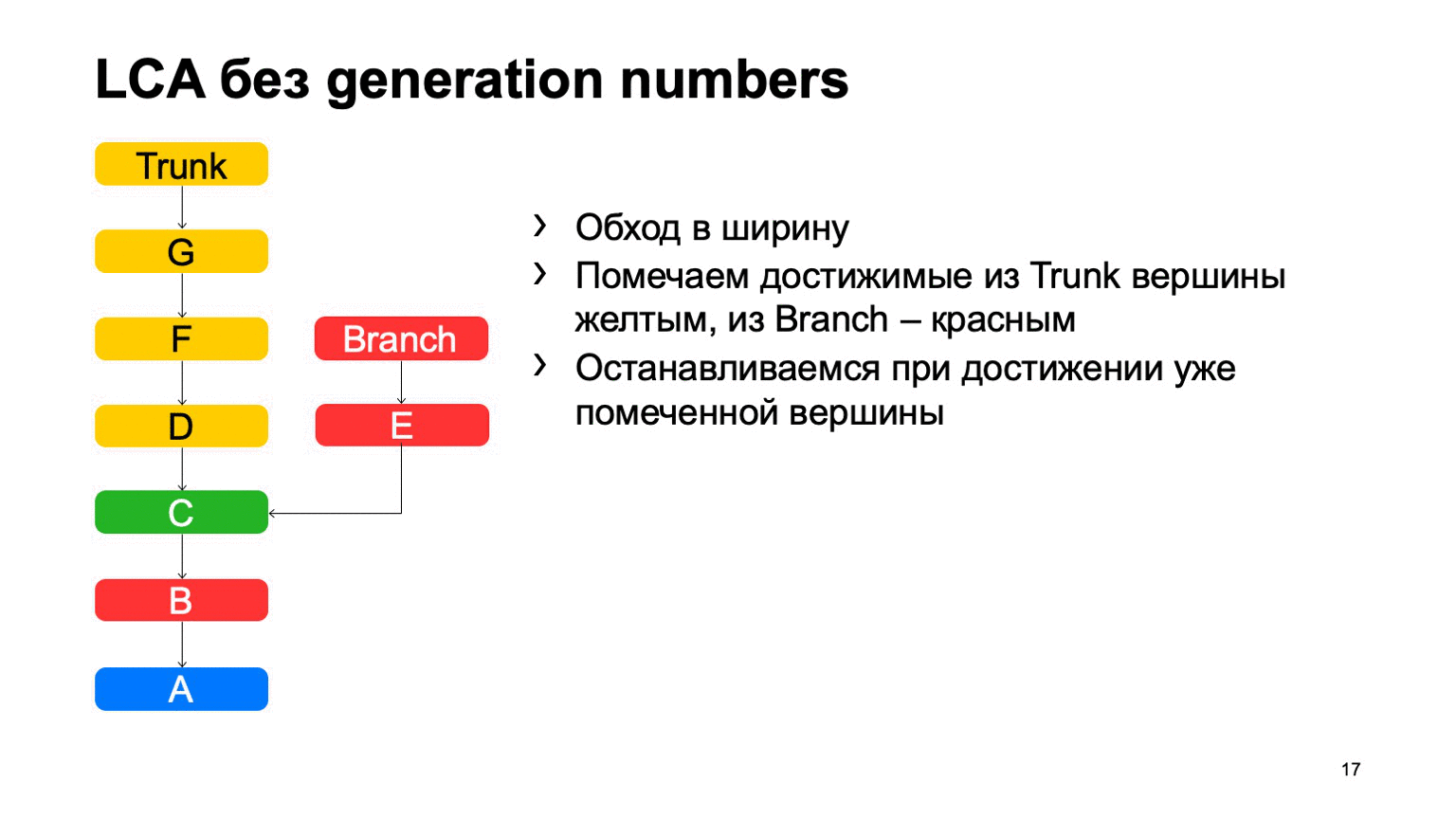
Le problème est avec B, qui est superflu. Il semble que nous ne pouvions pas y entrer, mais nous l'avons examiné. Et plus nous avons la différence entre une branche et un tronc en utilisant un exemple, plus nous trouverons de tels commits supplémentaires. Dans le cas d'un monorepositaire, lorsque le taux de commits sur un tronc est suffisamment élevé, cette distance peut être très importante. Et il y aura des dizaines de milliers de ces commits supplémentaires.


Dans le cas où il y a des numéros de génération, nous pouvons utiliser la file d'attente prioritaire lors de l'exploration, et l'analyse ressemblera à ceci: une fois - et trouvera immédiatement ce dont vous avez besoin.

Ceci est un exemple de la différence entre notre modèle. Dans Git, cette chose était précédemment prise en charge, ils utilisaient des horodatages de numéros de génération, mais cela ne fonctionnera que si les heures de création des validations sont cohérentes avec le graphique de validation.
Malheureusement, ce n'est pas le cas pour notre historique de référentiel. Il y a des commits qui résultent de la migration d'un autre référentiel, et le temps commence à y reculer. Dans Git, cette chose a été prise en charge à un moment donné, mais elle n'est pas toujours applicable ici, car dans Git, vous pouvez remplacer l'objet commit par un autre localement. L'immunité du modèle en souffre, donc ces numéros de génération qui n'enregistrent pas, ils ne sont parfois pas applicables à ce qui y est écrit, ce n'est pas vrai. Nous n'avons pas un tel problème.
Un autre avantage de cette optimisation est qu'elle est complètement locale. Pour utiliser ces chiffres, nous n'avons pas besoin d'avoir l'intégralité du graphique de validation. Et nous ne l'avons généralement pas du tout, avec nous, il est chargé paresseusement. Moins nous chargeons paresseusement, mieux nous vivons.
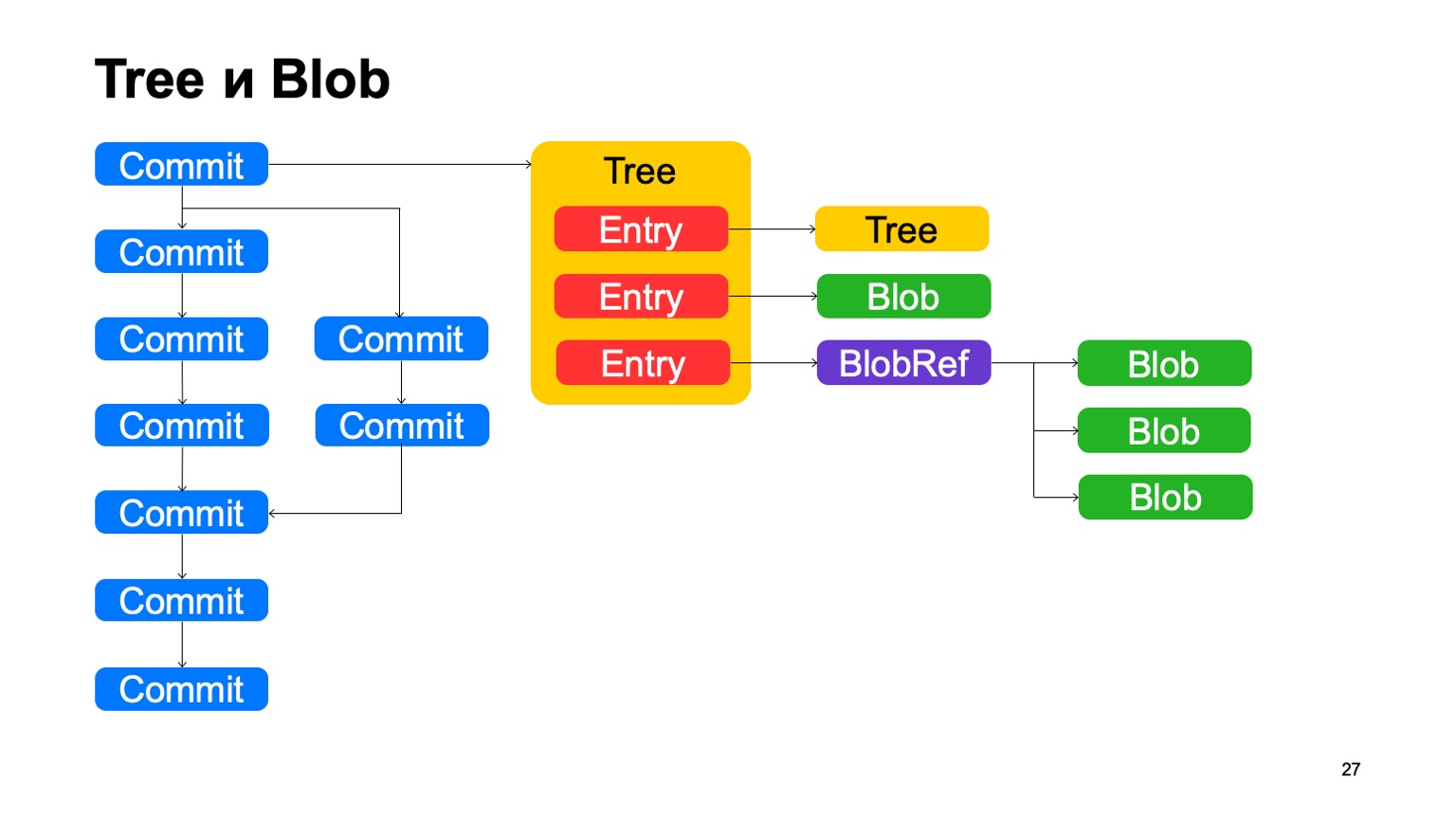
Outre les commits, le modèle est très similaire à Git. Chaque commit pointe vers un certain objet d'arborescence, l'arborescence est constituée d'enregistrements, chaque enregistrement est soit une autre arborescence, et c'est ainsi que la hiérarchie des répertoires est affichée en nous, ou c'est un blob, un fichier. De plus, nous avons une chose telle que BlobRef, lorsque le fichier est très volumineux, nous le divisons en morceaux et le présentons dans un objet spécial. C’est tout, comme dans Git.

Qu'est-ce que nous n'aimons pas dans Git? Nous appelons cette chose copy-info. Si le fichier a été copié dans une sorte de validation, Git n'enregistre pas ces informations de quelque manière que ce soit, puis essaie de le restaurer avec des heuristiques lorsqu'il vous montre des différences et des statuts. Nous enregistrons ces informations dans le graphique. Les enregistrements peuvent avoir un lien info-copie vers un autre commit, vers le chemin à l'intérieur du référentiel dans ce commit, par lequel nous savons que ce fichier a été copié dans ce commit.
Il y a aussi la déduplication, car sur le côté, ce blob est stocké une fois. Mais la déduplication serait tout de même, car le contenu du fichier n'a pas changé; il aurait été dédupliqué par hachage.
Comment sont organisés les backends? Si Git dispose d'un système de contrôle de version distribué, il n'a pas besoin de backends. Nous le ressentons particulièrement lorsque GitHub est en panne. Nous comprenons clairement que Git n'a pas besoin de backends. Notre système est client-serveur, il stocke toutes les données sur le serveur et la disponibilité du serveur est nécessaire pour télécharger les objets qui ne sont pas encore sur le client.

Toutes les données que nous stockons dans la base de données Yandex. Il s'agit d'une base de données très cool qui fournit la transaction, le niveau de fiabilité nécessaire. Il a tout ce dont nous avons besoin, et cette chose nous a sauvés de nombreux problèmes.
Grâce à cela, les backends eux-mêmes sont complètement sans état, l'état entier est dans la base de données et les backends que nous pouvons très facilement mettre à l'échelle autant que nous en avons besoin.
Et pour l'interaction avec les clients, celle des interserveurs, nous utilisons gRPC, il y avait un rapport détaillé à ce sujet aujourd'hui.
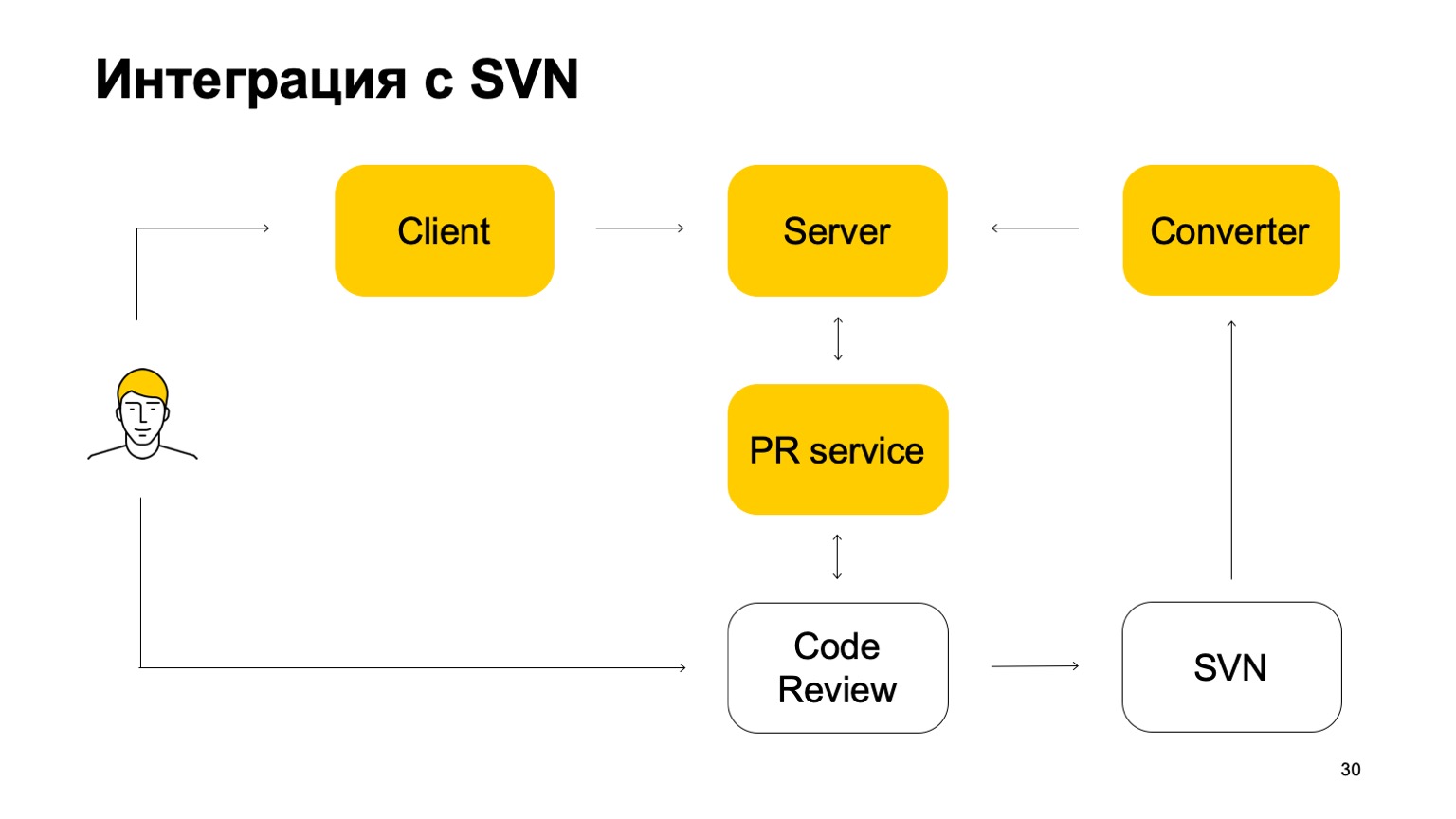
Comment notre système est-il intégré à SVN? Le référentiel SVN continue de vivre. De plus, notre système de contrôle de version n'est pas encore autosuffisant. Comment fonctionne-t-elle dans cette partie? Initialement, il existe un composant Converter qui surveille l'état du référentiel SVN et transforme les validations SVN en validations Arc - notre système de contrôle de version.
Ensuite, il y a un client qui monte une copie de travail et va au serveur pour les données. Lorsqu'un développeur valide quelque chose, il est d'abord envoyé au serveur Arc, mais pour que ces modifications soient transmises au tronc, notre branche principale, il doit passer par le système de demande de pool et le système de révision de code. Voici un autre service qui surveille les branches d'Arc et, si elles sont mises à jour, envoie une demande de pool à notre revue de code système. Ensuite, le système de révision du code, lorsqu'il est décidé que ce correctif doit être fusionné, le valide dans SVN. Pas tout à fait simple: il y ajoute une certaine quantité de métadonnées que ce commit est en fait une fusion de telle ou telle branche d'Arc. Et puis cette validation voit déjà le convertisseur, y trouve ces métadonnées et crée une validation sur le serveur Arc. C'est le cycle des commits. Par conséquent, alors que nous ne pouvons pas vivre sans SVN, parce que nous avons un tronc en SVN.
La branche principale est constamment synchronisée avec notre serveur, mais nous ne permettons pas de nous y engager directement.

À propos de la fiabilité des backends. Bien sûr, nous prévoyons que tous les développeurs Yandex utiliseront cette chose, il est donc important pour nous qu'elle ne casse pas. Il s'agit d'une telle norme intra-index: nos services doivent survivre à la défaillance de tout centre de données. Le système de contrôle de version ne fait pas exception. Ici, nous sommes grandement sauvés par le fait que YDB le supporte. Et nos backends sont sans état, différentes parties sont implémentées de manière légèrement différente. Les serveurs qui opèrent sur des objets Arc fonctionnent sur des branches, ils sont sans état, répliqués. Les convertisseurs qui convertissent constamment à partir de SVN sont répliqués selon le schéma actif-actif. Plusieurs convertisseurs fonctionnent simultanément, ils convertissent en même temps et, au moment où ils essaient de mettre à jour la branche Arc, ils résolvent les conflits. L'un a réussi, l'autre a échoué. Il essaie de convertir quelque chose de plus.
Le service de demande de pool est répliqué par maître-esclave. Il y en a un principal qui fonctionne. S'il échoue, un nouveau est sélectionné via YDB. Il y a une chose aussi merveilleuse que les sémaphores, qui ont de sérieuses garanties d'accessibilité, de fiabilité. Les accès aux sémaphores sont complètement sérialisés. Nous utilisons des sémaphores à la fois pour le service de découverte des demandes de pool et pour la sélection des leaders.
Un peu sur le fonctionnement du client. C'est la partie la plus difficile de notre système de contrôle de version, car il existe un système de fichiers virtuel. En fait, nous sommes obligés d'implémenter nous-mêmes toutes les opérations sur les fichiers. Je vais passer en revue certaines opérations de base, décrire grossièrement sur les doigts ce qui se passe à l'intérieur lorsque nous les faisons.

Par exemple, nous avons ouvert un fichier pour l'enregistrement. Lorsque nous avons ouvert le fichier pour l'écriture, nous trouvons le blob correspondant de notre modèle d'objet. Si nécessaire, téléchargez quelque chose depuis le serveur. Si nous créons physiquement un fichier dans un magasin spécial, toutes les autres demandes qui iront à ce fichier y seront transmises par proxy. Ainsi, jusqu'à ce que les modifications localisées soient validées (dans Git, cela s'appelle non organisé), elles entrent dans un stockage temporaire. Nous appelons ces fichiers matérialisés.

Si nous ouvrons le fichier en lecture, nous ne pouvons rien matérialiser, mais simplement donner des données directement à partir de notre blob.

Voici le moment où nous ajoutons le fichier à l'index. À ce stade, vous devez voir si nous avons quelque chose de concrétisé. Y a-t-il un fichier qui a changé. Si c'est le cas, créez un blob pour celui-ci et enregistrez-le dans l'index.

L'opération suivante est l'état de l'arc. C'est intéressant parce que c'est la chose qui dans les systèmes de contrôle de version conventionnels à de telles tailles est lent, car il doit parcourir toute l'arborescence des fichiers. Nous n'avons pas à parcourir toute l'arborescence des fichiers, car toutes les demandes de changement de fichiers passent par notre pilote de fusible, et nous savons immédiatement quels fichiers méritent d'être vérifiés. Nous vérifions ce que nous avons réussi à écrire dans l'index et imprimons la réponse.

Engagez le temps. Tout semble clair. Il y a un index, nous avons déjà créé des blobs pour ces objets, créer des objets arborescents qui correspondent à cet état, créer un nouvel objet commit, l'écrire dans le stockage d'objets.

Ensuite, nous basculons la copie de travail vers le nouveau commit. C'est une opération délicate, cela peut clairement être fait avec la commande de paiement. Et ici, vous pourriez penser que tous nos changements locaux semblent s'être déjà matérialisés, nous pouvons supposer que nous devons ensuite rendre les fichiers qui ne sont pas matérialisés à partir de nouveaux commits. Et c'est tout. Toutes les opérations suivantes sont simplement envoyées vers un autre arbre et des blobs.

Pourquoi cela ne fonctionnerait-il pas? La première version était à ce sujet. Le problème réside dans toutes sortes d'opérations délicates comme la réinitialisation de l'arc –soft. Ils nous changent d'arborescence, mais ne matérialisent pas les fichiers. Ils continuent d'exister dans un endroit sacré. Nous avons également des fichiers non suivis et ignorés, qui doivent également être traités de manière spéciale. À cet endroit, nous avons collecté beaucoup de râteaux et sommes finalement parvenus à la conclusion que nous devons encore prendre un arbre (maintenant une copie de travail) pendant le paiement, prendre l'arbre du commit vers lequel nous passons, prendre l'index et le nettoyer proprement attendez.
Mais en termes de complexité des algorithmes, nous n'avons rien perdu ici: tous ces arbres de changements locaux sont proportionnels aux changements que nous avons faits. Par conséquent, nous ne devons pas parcourir tout le référentiel avec ces opérations, elles fonctionnent toujours assez rapidement.
En même temps, nous faisons de la magie pour que les horodatages que nous donnons aux fichiers soient plus ou moins corrects. Si nous stockons simplement des fichiers dans le système de fichiers, il surveille cela et le temps passe toujours. Ici, nous devons nous rappeler en quelque sorte quel fichier l'utilisateur a vu à quel moment. Et s'il est passé à un commit antérieur, ne commencez pas à lui donner un temps plus tôt. Parce que les systèmes d'assemblage, tous les IDE ne sont pas prêts pour cela, ils enlèvent beaucoup de choses.

Dans notre système de contrôle de version, la prise en charge du développement basé sur le tronc est clouée. Tout d'abord, ce que j'ai déjà dit: tous les changements passent par les requêtes de pool et le tronc. Il y a encore quelques points. Nous n'avons pas de support de branche de groupe. Les branches créées dans Arc sont liées à un utilisateur spécifique, et lui seul peut s'y engager. Cela nous permet d'éviter les branches à longue durée de vie. Dans SVN, ce n'était pas particulièrement, car là, il n'est pas pratique de faire des branches. Et c'est pratique de les faire dans Arc, et si cela n'est pas contrôlé, nous avons peur que certaines parties de notre mono-référentiel partent pour leurs succursales et y conduisent leur développement. C'est contraire au modèle que nous voulons faire.

Deuxièmement, nous n'avons pas de commande de fusion. Toutes les fusions de succursales ont lieu sous notre contrôle strict. Nous développons actuellement des branches pour les versions, dans lesquelles il sera également possible de fusionner. Cela sera également réalisé non pas par une équipe d'utilisateurs, mais par des machines de serveurs, très probablement.

Quels sont nos plans? 20% des développeurs mono-dépositaires utilisent déjà notre système de contrôle de version. - , , . — . - 80% , , . , , Git.
, - , , Arc, SVN .
— , CI . , , . . .
— , CI Arc, - . , . . , ++- , , . .
. « Git». : Git. , , .
. Git . , . - . , checkout reset, . , , . : Git. « , ». Git .
. Git, git begin-wave-stash?
:
— .
— , Git ? — , , , . , . Git . , . Je vous remercie