Souvent, les tables contiennent un grand nombre de champs logiques, il n’existe aucun moyen de les indexer tous et l’efficacité de cette indexation est faible. Néanmoins, pour travailler avec des expressions logiques arbitraires en SQL, un mécanisme d'indexation multidimensionnelle convient, qui sera discuté sous le chat.
En SQL, les champs logiques sont utilisés principalement dans deux cas. Tout d'abord, lorsque vous avez vraiment besoin d'un attribut binaire, par exemple, 'acheter / vendre' dans la table de transaction. Ces attributs changent rarement au fil du temps.
Deuxièmement, pour enregistrer l'état de la
machine d'état qui décrit l'enregistrement. Il est entendu qu'un objet logique correspondant à un enregistrement de table passe par une série d'états, dont le nombre et les transitions entre eux sont déterminés par la logique appliquée. Un exemple simple est la technique de «suppression en douceur», lorsqu'un enregistrement n'est pas physiquement détruit, mais uniquement marqué comme supprimé.
Si la machine est complexe, il peut y avoir une bonne quantité de tels champs, dans l'un de
nos tableaux, il y a 58 (+14 obsolètes) de tels champs (y compris les ensembles d'indicateurs) et ce n'est pas quelque chose qui sort de l'ordinaire. Cela n'était pas prévu à l'origine, mais au fur et à mesure que le produit se développe et que les exigences externes changent, les machines correspondantes se développent, les développeurs vont et viennent, les analystes changent ... à un moment donné, il peut être plus sûr d'obtenir un nouveau drapeau, plutôt que de comprendre toutes les subtilités. De plus, les données historiques se sont accumulées et leurs conditions doivent rester adéquates.
hors sujetÀ certains égards, cela est similaire à un processus évolutif lorsqu'une masse d'informations / mécanismes sont stockés dans le génome qui, à première vue, ne sont pas du tout nécessaires, mais il est impossible de s'en débarrasser. D'un autre côté, il vaut la peine de respecter ces mécanismes, car ce sont eux qui ont permis aux prédécesseurs évolutionnaires de survivre (y compris pendant les
grandes extinctions ) et de gagner la course évolutionnaire. Encore une fois, qui sait où l'évolution nous mènera et ce qui s'avérera utile à l'avenir.
Mettre un drapeau signifie non seulement ajouter un champ du type correspondant, mais aussi le prendre en compte dans le fonctionnement de l'automate, quels états il affecte, à quelles transitions il participe. En pratique, cela ressemble à ceci:
- un processus ou une série de processus, appelons-les «écrivains», créons de nouveaux enregistrements dans l'état initial (éventuellement dans l'un des états initiaux)
- un certain nombre de processus, appelons-les "lecteurs", de temps en temps ils lisent des objets qui sont dans les états dont ils ont besoin
- un certain nombre de processus, appelons-les «gestionnaires», surveillons des états spécifiques et, en fonction de la logique appliquée, modifions ces états. C'est-à-dire faire fonctionner une machine d'état.
Pour sélectionner des enregistrements dans un état particulier, il est rare que le filtrage par l'un des champs booléens soit suffisant. Il s'agit généralement d'une expression entière, parfois non triviale. Il semblerait que vous ayez besoin d'indexer ces champs et le processeur SQL le découvrira. Mais pas si simple.
Premièrement, il peut y avoir de nombreux champs booléens; les indexer tous serait trop inutile.
Deuxièmement, il peut s’avérer inutile car la sélectivité pour chacun des champs sera faible et la probabilité conjointe n'est pas couverte par les statistiques du processeur SQL.
Supposons que dans la table T1, il existe deux champs booléens: F1 et F2 et la requête
select F1, F2, count(1) from T1 group by F1, F2
donne
C'est-à-dire bien que, selon F1 et F2, vrai et faux soient également probables, la combinaison (vrai, faux) ne tombe qu'une fois sur mille. Par conséquent, si nous indexons F1 et F2 séparément
et les forçons à être utilisés dans la requête , le processeur SQL devrait lire la moitié des deux indices et croiser les résultats. Il peut être moins coûteux de lire l'intégralité du tableau et de calculer l'expression pour chaque ligne.
Et même si vous collectez des statistiques sur les demandes traitées, cela ne sera pas très utile. les statistiques spécifiques aux domaines responsables de l'état de la machine flottent beaucoup. En effet, à tout moment un "handler" peut venir et transférer la moitié des lignes de l'état S1 à S2.
Pour travailler avec de telles expressions, un indice multidimensionnel se suggère, dont l'algorithme a été
présenté précédemment et s'est révélé assez bon.
Mais vous devez d'abord comprendre comment une expression logique arbitraire se transformera en requête (s) pour l'index.
Forme normale disjonctive
Une requête unique vers un index multidimensionnel est un rectangle multidimensionnel qui limite l'espace de requête. Si le champ participe à la demande, une restriction est définie pour celui-ci. Sinon, le rectangle dans cette coordonnée n'est limité que par la largeur de cette coordonnée. Les coordonnées logiques ont une capacité de 1.
Une requête de recherche dans un tel index est une chaîne de & (conjonction), par exemple, l'expression: v1 & v2 & v3 & (! V4), équivalente à v1: [1,1], v2: [1,1], v3: [1, 1], v4: [0,0]. Et tous les autres champs ont une plage: [0,1].
Compte tenu de cela, notre regard se tourne immédiatement vers le
DNF - l'une des formes canoniques d'expressions logiques. On soutient que toute expression peut être représentée comme une disjonction de conjonctions littéraires. Un littéral désigne ici un champ logique ou sa négation.
En d'autres termes, grâce à de simples manipulations, toute expression logique peut être représentée comme une disjonction de plusieurs requêtes vers un index logique multidimensionnel.
Il y a un MAIS. Une telle transformation peut dans certains cas conduire à une augmentation exponentielle de la taille de l'expression. Par exemple, la conversion de
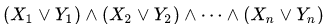
conduit à une expression de 2 ** n termes. Dans de tels cas, le développeur de l'application doit réfléchir à la signification physique de ce qu'il fait et, de la part du processeur SQL, vous pouvez toujours refuser d'utiliser l'index logique si le nombre de conjonctions dépasse les limites raisonnables.
Algorithme d'indexation multidimensionnelle
Pour l'indexation multidimensionnelle, les propriétés d'une courbe de numérotation auto-similaire basée sur des simplexes hyper-cubiques avec le côté 2.
Il s'est avéré que deux versions de ces courbes sont d'une importance pratique - la courbe Z et la courbe Hilbert.
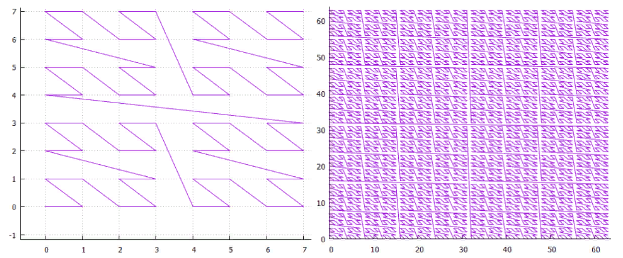 Figure 1 Courbe Z bidimensionnelle, 3 et 6 itérations
Figure 1 Courbe Z bidimensionnelle, 3 et 6 itérations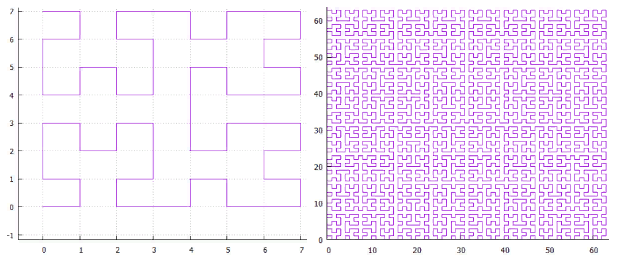 Figure 2 Courbe de Hilbert bidimensionnelle, 3 et 6 itérations
Figure 2 Courbe de Hilbert bidimensionnelle, 3 et 6 itérations- Un simplexe à N dimensions avec le côté 2 a 2 ** n sommets et (2 ** n-1) transitions entre eux.
- Une itération élémentaire d'un simplex transforme chaque sommet d'un simplex en un simplex de niveau inférieur.
- Après avoir fait le nombre d'itérations nécessaire, nous pouvons construire un réseau hyper-cubique de n'importe quelle taille.
- De plus, chaque nœud de ce réseau aura son propre numéro unique - le chemin emprunté le long de la courbe de numérotation depuis son début. De plus, chaque nœud de ce réseau a une valeur dans chacune des coordonnées. En fait, la courbe de numérotation traduit le point multidimensionnel en une valeur unidimensionnelle adaptée à l'indexation avec un arbre B régulier .
- Tous les nœuds situés à l'intérieur d'un simplex de n'importe quel niveau se trouvent dans le même intervalle et cet intervalle ne coupe aucun simplex du même niveau.
- Par conséquent, tout rectangle de recherche (case) peut être divisé en un petit nombre de sous-requêtes hyper-cubiques, dans chacune desquelles l'index peut être lu par une recherche / traversée.
- À cela, nous ajoutons la magie du travail de bas niveau avec l'arbre B afin de ne pas faire de requêtes inutiles et ... l'algorithme est prêt.
Voici comment cela fonctionne dans la pratique:
 Figure 3 Exemple de recherche dans un index bidimensionnel (courbe Z)
Figure 3 Exemple de recherche dans un index bidimensionnel (courbe Z)La figure 3 montre le partitionnement de l'étendue de recherche d'origine en sous-requêtes et les points trouvés. Un indice bidimensionnel a été utilisé, construit sur un ensemble aléatoire et uniformément réparti de 100 000 000 de points [1 000 000, 1 000 000].
Index multidimensionnel logique
Puisque nous parlons d'indexation multidimensionnelle, il est temps de penser à combien elle peut être multidimensionnelle? Y a-t-il des limites objectives?
Bien sûr, parce que l'arbre B a une organisation de page et pour être un arbre, au moins deux éléments doivent être garantis pour tenir sur la page. Si vous prenez la page pour 8K, le stockage d'un élément ne peut pas dépasser 4K. En 4K, sans compression, environ 1000 valeurs 32 bits conviennent. C'est beaucoup, au-delà des limites de toute application raisonnable, on peut dire que les limites physiques ne sont pratiquement pas disponibles.
Il y a un autre côté, chaque dimension supplémentaire n'est en aucun cas libre, elle prend de l'espace disque et ralentit le travail. Du point de vue de la «signification physique», les champs qui changent en même temps doivent être inclus dans le même index et leur recherche va également de pair. Il est inutile d'indexer tout de suite.
Les champs logiques sont différents. Comme nous l'avons vu, des dizaines de champs logiques peuvent être impliqués dans les mêmes mécanismes. Et les coûts de stockage / lecture sont assez faibles. Il y a une tentation de collecter tous les champs logiques dans un index et de voir ce qui se passe.
Certes, il y a des nuances:
- Jusqu'à présent, dans la valeur indexée, les chiffres de coordonnées différentes étaient mélangés, dans les chiffres les moins significatifs de la clé étaient les bits les moins significatifs des coordonnées ... Par conséquent, l'ordre des champs lors de l'indexation n'avait pas d'importance.
- Maintenant, un bit est dépensé pour stocker la valeur d'un champ logique. C'est-à-dire certains champs logiques iront à la fin de la clé, et certains au début. Cela signifie que le filtrage par une partie des champs sera très efficace, et par certains, il sera très inefficace. En fait, si nous effectuons une recherche dans l'ordre le plus bas, nous devrons lire l'index entier pour obtenir une réponse. Mais cela (le plus probable) est mieux que de lire le tableau entier pour répondre à la même question.
- Il y a un problème de choix - tous les champs logiques sont égaux, mais certains seront plus égaux que d'autres. De considérations générales, il est nécessaire d'examiner les distorsions des statistiques, plus le rapport vrai / faux pour un domaine particulier est élevé, plus la décharge dans laquelle sa valeur sera ancienne.
- Le partitionnement par type de courbe de numérotation disparaît, si auparavant il fallait choisir entre la courbe Z et la courbe de Hilbert, il n'y a pas de différence pratique sur les données mono-bit.
- NULLs. Étant donné que NULL n'est pas une valeur inconnue, mais l'absence de toute valeur, ces enregistrements ne doivent pas être inclus dans l'index. Dans les indices unidimensionnels, c'est ce qui se passe. Mais dans notre cas, il peut s'avérer que certains des champs logiques contiennent des valeurs, d'autres non. En conséquence, nous ne pouvons pas mettre cela dans l'indice car l'algorithme de recherche ne sait pas travailler avec la logique ternaire. Et donc, de tels enregistrements devraient être impossibles à insérer dans la table (s'il y a un index multidimensionnel, pas nécessairement logique, soit dit en passant)
Il est prévu qu'un index logique multidimensionnel peut dans certains cas ne pas fonctionner très efficacement. À strictement parler, tout index peut fonctionner de manière inefficace si trop de données tombent dans la zone de recherche. Mais pour un index multidimensionnel logique, cela est aggravé par la dépendance de l'ordre des champs décrit ci-dessus, lorsque, pour un petit résultat, vous devez lire l'index entier. Dans la mesure où il s'agit d'un problème dans la pratique, seule l'expérience peut le montrer.
Expérience numérique
Construire un index:
- l'index sera de 128 bits, c'est-à-dire construit sur 128 champs logiques
- et contiendra 2 ** 30 éléments
- la valeur de l'élément d'index sera un nombre de 0 à 2 ** 30
- la clé de l'élément d'index sera le même nombre décalé de 48 bits vers la gauche, c'est-à-dire les champs logiques 48 à 78 seront remplis avec les chiffres du nombre dans le même ordre
- en conséquence, nous obtenons 30 champs logiques significatifs au milieu de la clé, les bits restants seront remplis 0
- Chacun des champs booléens a des statistiques égales vrai / faux
- Tous sont statistiquement indépendants.
Recherche:
- Chaque expérience correspond à la sélection de plusieurs champs logiques consécutifs et à leur affectation de valeurs de recherche. Non pas parce que l'algorithme ne peut rechercher que dans des bandes, mais parce qu'il est possible de visualiser plus clairement les résultats de l'expérience, nous n'avons que deux dimensions - la largeur de la bande et sa position
- Un total de 24 séries d'expériences. Dans chaque série, nous chercherons des valeurs où la bande de champs logiques de largeur correspondante N (de 1 à 24 bits) prend la valeur true.
- Dans chaque série, il y aura une sous-série d'expériences dans laquelle une bande de champs logiques d'une largeur sélectionnée est située avec différents décalages S depuis le début de la bande en 30 champs logiques significatifs. Expériences totales (30-N) dans la sous-série.
- Dans chaque expérience, une recherche est effectuée pour tous les éléments de l'indice qui satisfont à la condition, c'est-à-dire les champs avec des nombres dans l'intervalle [48 + S, 48 + S + N -1] seront recherchés dans l'intervalle [1,1], le reste dans l'intervalle [0,1]
- La recherche se fait à partir d'un démarrage à froid
- Le résultat est le nombre de pages de disque lues, y compris la mise en cache (4096 pages cache)
- Le contrôle du bon fonctionnement se fait de deux manières - le nombre d'éléments trouvés doit être égal à 2 ** (30-N) et dans les valeurs trouvées vous pouvez vérifier les chiffres correspondants
Alors
 Figure 4 Résultats, le nombre de pages lues dans différentes séries
Figure 4 Résultats, le nombre de pages lues dans différentes sériesPar Y - le nombre de pages lues est reporté.
Au X - passage des bandes de la catégorie des plus jeunes (48) aux seniors. Des rayures de différentes largeurs sont signées et marquées de différentes couleurs.
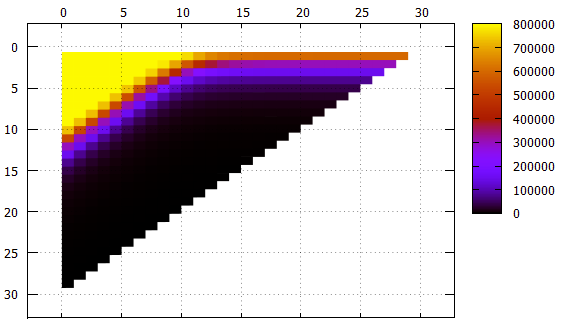 Figure 5 Les mêmes données que la figure 4, une autre vue
Figure 5 Les mêmes données que la figure 4, une autre vueX - décalage de bande
Y - bande passante
À noter:
- bien que cela ne soit pas directement visible dans les images, l'index fonctionne correctement, il est visible à la fois dans le nombre d'éléments trouvés et dans le contenu des éléments eux-mêmes
- toutes les bandes d'une largeur ne dépassant pas 10 avec un décalage de 0 nécessitent une lecture continue de l'index
- les bandes d'une largeur de 1 à 18 avec une augmentation du décalage atteignent l'asymptote 2 ** (- N) de la taille de l'index entier, ce qui est logique
- pour les bandes plus larges de l'asymptote - la hauteur de l'arbre, il ne peut pas y avoir moins de lectures
- un peu plus de 1000 éléments sont placés sur la page de feuille d'index, cela peut être vu dans une bande de largeur 10, qui lors du décalage 0 ne nécessite plus de lire l'index entier, certaines pages peuvent être sautées
- le filtrage de bas niveau fonctionne étonnamment bien. Considérez une bande d'une largeur de 10. Une option idéale pour une recherche est avec un décalage de 20 (un total de 30 champs significatifs), quand il n'y a aucun champ non défini dans le préfixe du tout, les données peuvent être trouvées avec un seul faisceau. Dans cette situation, environ 1/1000 de l'index est lu pendant la recherche - 779 pages.
Le cas intermédiaire est un décalage de 10, nous avons un préfixe et un suffixe de 10 champs inconnus. Le nombre de pages est de 2484, seulement trois fois pire que dans le cas idéal.
Et même dans le pire des cas, avec un décalage de 0 (un préfixe de 20 champs inconnus), vous pouvez ignorer certaines pages.
Dans l'ensemble, l'algorithme d'indexation multidimensionnelle peut être reconnu comme efficace même dans un cas aussi absurde.
Mais l'option la plus infructueuse du point de vue de l'index logique est considérée - des états équiprobables dans tous les champs logiques indépendants.Expérience sur des données réelles
Tableau des
métiers , total 278 479 918 lignes, données d'une des boucles de test.
Les résultats de certaines requêtes dans le tableau ci-dessous:
La lecture / le traitement d'une seule page prend en moyenne 0,8 ms.
Il n'est pas nécessaire de décrire la signification de requêtes spécifiques, elles ne sont là que pour démontrer l'opérabilité. Ce qui, soit dit en passant, est confirmé.
Mais avant que cette technique puisse être d'une utilité pratique, il reste beaucoup à faire. Donc, pour continuer.