 Ça fait mal seulement pour la première fois!
Ça fait mal seulement pour la première fois!Bonjour à tous! Chers amis, dans cet article, je veux partager mon expérience avec TensorRT, RetinaNet basé sur le référentiel
github.com/aidonchuk/retinanet-examples (il s'agit d'une fourchette du navet officiel
nvidia , qui nous permettra de commencer à utiliser des modèles optimisés en production dès que possible).
En parcourant les canaux de la communauté
ods.ai , je rencontre des questions sur l'utilisation de TensorRT, et la plupart du temps, les questions sont répétées, j'ai donc décidé d'écrire
un guide
aussi complet que possible pour l'utilisation de l'inférence rapide basée sur TensorRT, RetinaNet, Unet et Docker.
Description de la tâcheJe propose de définir la tâche de cette façon: nous devons marquer le jeu de données, former le réseau RetinaNet / Unet sur Pytorch1.3 +, convertir les poids reçus en ONNX, puis les convertir en moteur TensorRT et exécuter tout cela dans Docker, de préférence sur Ubuntu 18 et extrêmement de préférence sur l'architecture ARM (Jetson) *, minimisant ainsi le déploiement manuel de l'environnement. En conséquence, nous préparerons un conteneur non seulement pour l'exportation et la formation de RetinaNet / Unet, mais aussi pour le développement complet et la formation de la classification, de la segmentation avec toutes les liaisons nécessaires.
Étape 1. Préparation de l'environnementIl est important de noter ici que récemment j'ai complètement abandonné l'utilisation et le déploiement d'au moins certaines bibliothèques sur la machine de bureau, ainsi que sur devbox. La seule chose que vous devez créer et installer est l'environnement virtuel python et cuda 10.2 (vous pouvez vous limiter à un seul pilote nvidia) de deb.
Supposons que vous ayez un Ubuntu 18. fraîchement installé. Installez cuda 10.2 (deb), je ne m'attarderai pas sur le processus d'installation en détail, la documentation officielle est assez suffisante.
Maintenant, installez docker, le guide d'installation de docker est facile à trouver, voici un exemple
www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-en , la version 19+ est déjà disponible - mettez-la. Eh bien, n'oubliez pas de permettre d'utiliser docker sans sudo, ce sera plus pratique. Après tout, nous aimons ceci:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.imtqy.com/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.imtqy.com/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
Et vous n'avez même pas besoin de consulter le référentiel officiel
github.com/NVIDIA/nvidia-docker .
Maintenant, faites git clone
github.com/aidonchuk/retinanet-examples .
Cela reste juste un peu, afin de commencer à utiliser Docker avec nvidia-image, nous devons nous inscrire dans NGC Cloud et vous connecter. Nous allons ici
ngc.nvidia.com , enregistrez-vous et après être
entré dans le NGC Cloud, appuyez sur SETUP dans le coin supérieur gauche de l'écran ou suivez ce lien
ngc.nvidia.com/setup/api-key . Cliquez sur "générer une clé". Je recommande de l'enregistrer, sinon la prochaine fois que vous le visiterez, vous devrez le régénérer et, en conséquence, le déployer sur une nouvelle brouette, répéter cette opération.
Exécuter:
docker login nvcr.io Username: $oauthtoken Password: <Your Key> -
Le nom d'utilisateur suffit de copier. Eh bien, considérez, l'environnement est déployé!
Étape 2. Assemblage du conteneur DockerÀ la deuxième étape de notre travail, nous assemblerons le docker et nous nous familiariserons avec son intérieur.
Allons dans le dossier racine relatif au projet retina-examples et exécutons
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Nous collectons le docker en y jetant l'utilisateur actuel - cela est très utile si vous écrivez quelque chose sur un VOLUME monté avec les droits de l'utilisateur actuel, sinon il y aura racine et douleur.
Pendant que docker s'en va, explorons le Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3 ARG USER=alex ARG UID=1000 ARG GID=1000 ARG PW=alex RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master COPY . retinanet/ RUN pip install --no-cache-dir -e retinanet/ RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl RUN pip install tensorboardx RUN pip install albumentations RUN pip install setproctitle RUN pip install paramiko RUN pip install flask RUN pip install mem_top RUN pip install arrow RUN pip install pycuda RUN pip install torchvision RUN pip install pretrainedmodels RUN pip install efficientnet-pytorch RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch RUN pip install pytorch_toolbelt RUN chown -R ${USER}:${USER} retinanet/ RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping RUN mkdir /var/run/sshd RUN echo 'root:pass' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile CMD ["/usr/sbin/sshd", "-D"]
Comme vous pouvez le voir dans le texte, nous prenons tous nos favoris, compilons le rétinanet, distribuons les outils de base pour la commodité de travailler avec Ubuntu et configurons le serveur openssh. La première ligne est juste l'héritage de l'image nvidia, pour laquelle nous avons fait une connexion dans NGC Cloud et qui contient Pytorch1.3, TensorRT6.xxx et un tas de bibliothèques qui nous permettent de compiler le code source cpp pour notre détecteur.
Étape 3. Démarrage et débogage du conteneur DockerPassons au cas principal de l'utilisation du conteneur et de l'environnement de développement, pour commencer, exécutez nvidia docker. Exécuter:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest
Maintenant, le conteneur est disponible sur ssh <curr_user_name> @localhost. Après un lancement réussi, ouvrez le projet dans PyCharm. Ensuite, ouvrez
Settings->Project Interpreter->Add->Ssh Interpreter
Étape 1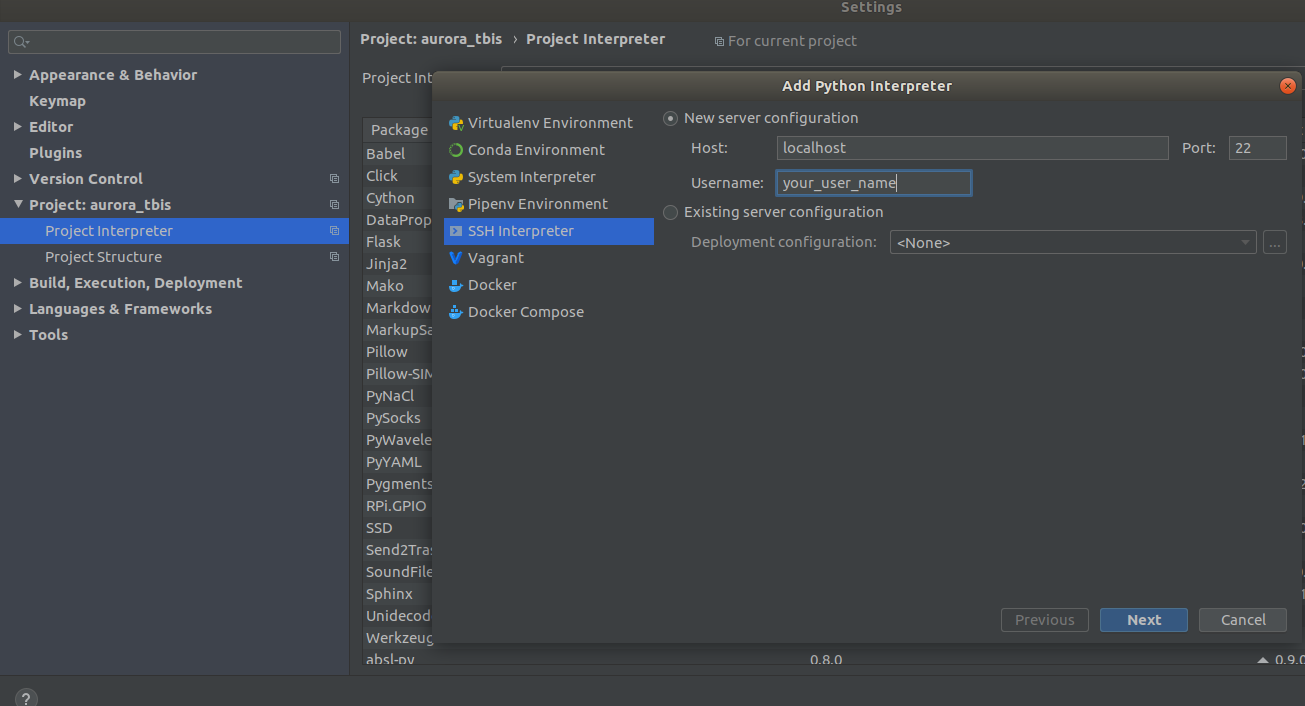 Étape 2
Étape 2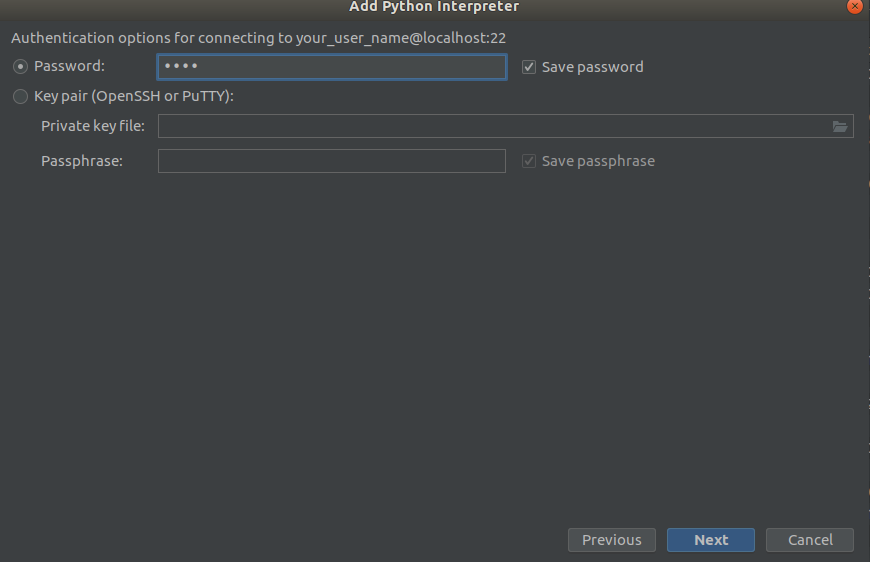 Étape 3
Étape 3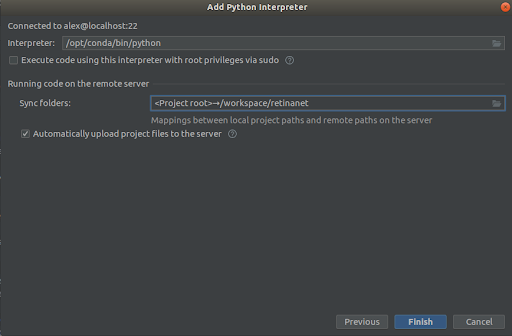
Nous sélectionnons tout comme dans les captures d'écran,
Interpreter -> /opt/conda/bin/python
- ce sera ln en Python3.6 et
Sync folder -> /workspace/retinanet
Nous pressons la ligne d'arrivée, nous attendons l'indexation, et c'est tout, l'environnement est prêt à l'emploi!
IMPORTANT !!! Immédiatement après l'indexation, extrayez les fichiers compilés pour Retinanet à partir de Docker. Dans le menu contextuel à la racine du projet, sélectionnez
Deployment->Download
Un fichier et deux dossiers de construction, retinanet.egg-info et _so apparaîtront
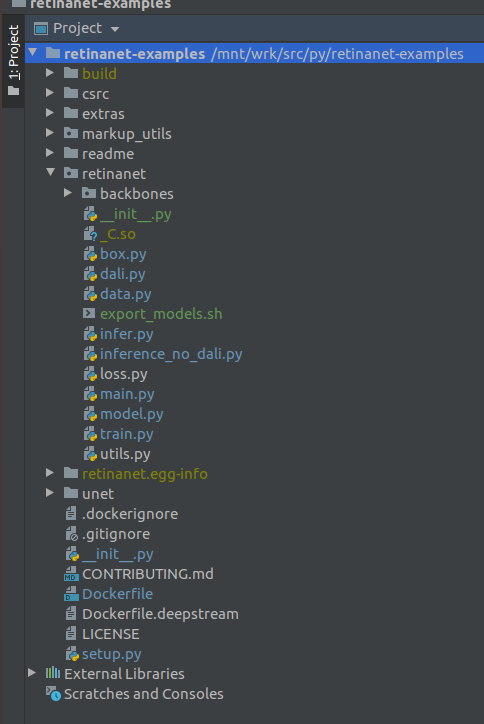
Si votre projet ressemble à ceci, alors l'environnement voit tous les fichiers nécessaires et nous sommes prêts à apprendre RetinaNet.
Étape 4. Marquage des données et apprentissage du détecteurPour le balisage, j'utilise principalement
supervise.ly - un outil agréable et pratique, la dernière fois, un tas de jambages ont été fixés et il est devenu beaucoup mieux se comporter.
Supposons que vous ayez marqué un ensemble de données et que vous l'ayez téléchargé, mais cela ne fonctionnera pas immédiatement pour le mettre dans notre RetinaNet, car il est dans son propre format et pour cela, nous devons le convertir en COCO. L'outil de conversion est dans:
markup_utils/supervisly_to_coco.py
Veuillez noter que la catégorie dans le script est un exemple et que vous devez insérer la vôtre (vous n'avez pas besoin d'ajouter la catégorie d'arrière-plan)
categories = [{'id': 1, 'name': '1'}, {'id': 2, 'name': '2'}, {'id': 3, 'name': '3'}, {'id': 4, 'name': '4'}]
Pour une raison quelconque, les auteurs du référentiel d'origine ont décidé que vous ne formeriez rien sauf COCO / VOC pour la détection, j'ai donc dû modifier légèrement le fichier source
retinanet/dataset.py
En ajoutant tutda vos augmentations préférées
albumentations.readthedocs.io/en/latest et découpez les catégories câblées de COCO. Il est également possible de saupoudrer de grandes zones de détection si vous recherchez de petits objets dans de grandes images, vous avez un petit ensemble de données =), et rien ne fonctionne, mais plus encore une autre fois.
En général, la boucle du train est également faible, au départ, elle n'a pas enregistré les points de contrôle, elle a utilisé un horrible planificateur, etc. Mais maintenant, tout ce que vous avez à faire est de sélectionner la colonne vertébrale et d'exécuter
/opt/conda/bin/python retinanet/main.py
avec paramètres:
train retinanet_rn34fpn.pth --backbone ResNet34FPN --classes 12 --val-iters 10 --images /workspace/mounted_vol/dataset/train/images --annotations /workspace/mounted_vol/dataset/train_12_class.json --val-images /workspace/mounted_vol/dataset/test/images_small --val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json --jitter 256 512 --max-size 512 --batch 32
Dans la console, vous verrez:
Initializing model... model: RetinaNet backbone: ResNet18FPN classes: 2, anchors: 9 Selected optimization level O0: Pure FP32 training. Defaults for this optimization level are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 1.0 Processing user overrides (additional kwargs that are not None)... After processing overrides, optimization options are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 128.0 Preparing dataset... loader: pytorch resize: [1024, 1280], max: 1280 device: 4 gpus batch: 4, precision: mixed Training model for 20000 iterations... [ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001 [ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001 [ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001 [ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001 [ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001 [ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001 [ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001 [ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001 [ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001 [ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001 [ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001 [ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001 [ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001 [ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Saving model: 148
Pour étudier l'ensemble des paramètres, regardez
retinanet/main.py
En général, ils sont standard pour la détection et ils ont une description. Exécutez la formation et attendez les résultats. Un exemple d'inférence peut être trouvé dans:
retinanet/infer_example.py
ou exécutez la commande:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth --images /workspace/mounted_vol/dataset/test/images --annotations /workspace/mounted_vol/dataset/val.json --output result.json --resize 256 --max-size 512 --batch 32
Focal Loss et plusieurs dorsales sont déjà intégrés dans le référentiel, et leur
retinanet/backbones/*.py
Les auteurs donnent quelques caractéristiques dans la plaque signalétique:
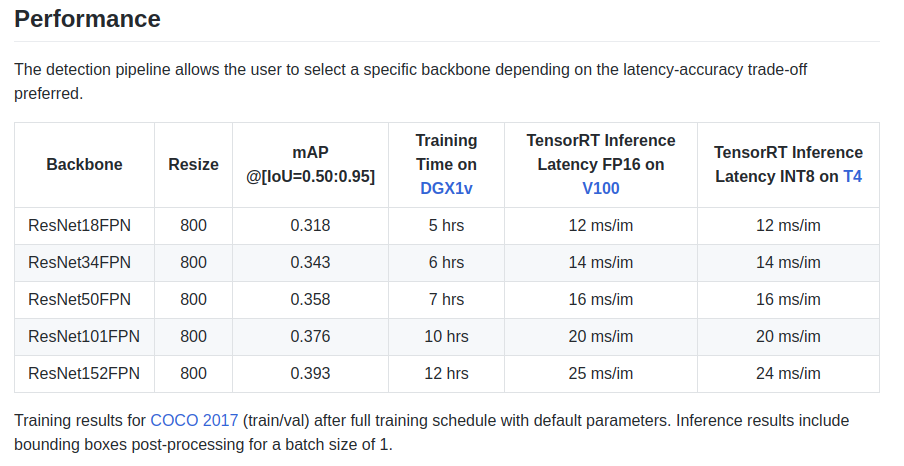
Il existe également un réseau principal ResNeXt50_32x4dFPN et ResNeXt101_32x8dFPN, provenant de torchvision.
J'espère que nous avons un peu compris la détection, mais vous devez absolument lire la documentation officielle pour
comprendre les modes d'exportation et de journalisation .
Étape 5. Exportation et inférence de modèles Unet avec l'encodeur ResnetComme vous l'avez probablement remarqué, les bibliothèques de segmentation ont été installées dans le Dockerfile, et en particulier la merveilleuse bibliothèque
github.com/qubvel/segmentation_models.pytorch . Dans le package Yunet, vous pouvez trouver des exemples d'inférence et d'exportation de points de contrôle Pytorch dans le moteur TensorRT.
Le principal problème lors de l'exportation de modèles de type Unet d'ONNX vers TensoRT est la nécessité de définir une taille d'Upsample fixe ou d'utiliser ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic def upsample_nearest2d(g, input, output_size):
En utilisant cette conversion, vous pouvez le faire automatiquement lors de l'exportation vers ONNX, mais déjà dans la version 7 de TensorRT, ce problème a été résolu, et nous avons dû attendre très peu.
ConclusionLorsque j'ai commencé à utiliser Docker, j'avais des doutes quant à ses performances pour mes tâches. Dans l'une de mes unités, il y a maintenant beaucoup de trafic réseau créé par plusieurs caméras.
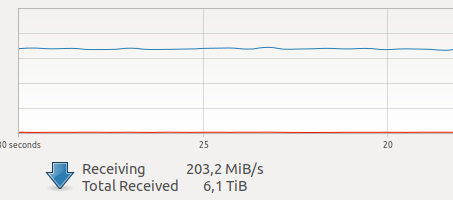
Divers tests sur Internet ont révélé un surcoût relativement important pour l'interaction réseau et l'enregistrement sur VOLUME, plus un GIL terrible et inconnu, et depuis la prise de vue d'une image, le travail d'un pilote et la transmission d'une image sur un réseau sont des opérations atomiques en mode
temps réel dur , des retards en ligne sont très critiques pour moi.
Mais rien ne s'est passé =)
PS Il reste à ajouter votre boucle de train préférée pour la segmentation et la production!
MerciGrâce à la communauté
ods.ai , il est impossible de se développer sans elle! Un grand merci à
n01z3 , DL, qui m'a souhaité de rejoindre DL, pour ses précieux conseils et son extraordinaire professionnalisme!
Utilisez des modèles optimisés en production!
Aurorai, llc