Aujourd'hui, je vais vous expliquer comment j'ai appliqué des algorithmes d'apprentissage en profondeur par renforcement pour contrôler un robot. En bref, je vais vous dire comment créer une "boîte noire avec des réseaux de neurones", qui accepte l'architecture du robot en entrée et génère un algorithme qui peut la contrôler en sortie.
Le cœur de la solution est l'algorithme Advantage Actor Critic (A2C) avec des scores Advantage via le Generalized Advantage Estimation (GAE).
Sous la coupe, les mathématiques, une implémentation de TensorFlow et beaucoup de démos de ce type d'algorithmes de marche.
Contenu:
-
défi-
Pourquoi l'apprentissage par renforcement?-
Déclaration d'apprentissage par renforcement-
gradient politique-
Politiques diagonales gaussiennes-
Réduisez la variance en ajoutant des critiques-
Pièges- Conclusion
Défi
Dans cet article, nous apprendrons au robot à marcher dans la simulation MuJoCo. Nous allons sauter la description de l'étape de création d'un modèle du robot et de l'interface Python à l'environnement, car il n'y a rien d'intéressant là-bas. Pour comprendre, il suffit de regarder les démos dans MuJoCo lui-même et les sources des environnements MuJoCo dans Gym OpenAI .
En entrée, l'agent aura de nombreux nombres issus de MuJoCo: positions relatives, angles de rotation, vitesse, accélération de parties du corps du robot, etc. Au total, l'ordre de ~ 800 fonctionnalités. Nous utilisons l'approche Deep Learning et ne comprendrons pas ce qu'ils signifient réellement. L'essentiel est que dans cet ensemble de chiffres, il y aura suffisamment d'informations pour que l'agent puisse comprendre ce qui lui arrive.
À la sortie, nous nous attendons à 18 nombres - le nombre de degrés de liberté du robot, ce qui signifie les angles de rotation des charnières sur lesquelles les membres sont fixés.
Enfin, l'objectif de l'agent est de maximiser la récompense totale pour l'épisode. Nous mettrons fin à l'épisode si le robot plante ou si 3000 pas se sont écoulés (15 secondes). Chaque étape récompensera l'agent selon la formule suivante:
n e w c o m m a n d e m a t h o p m a t h b b E n e w c o m m a n d R m a t h o p m a t h b b R r t = D e l t a x ∗ 1000 + 0 ,5
C'est-à-dire l'objectif de l'agent augmentera ses coordonnées x et ne tombez pas avant la fin de l'épisode.
Donc, la tâche est définie: trouver la fonction pi: R800 à R18 pour laquelle la récompense de l'épisode sera la plus grande . Cela ne sonne pas très bien? :) Voyons comment Deep Reinforcement Learning gère cette tâche.
Pourquoi l'apprentissage par renforcement?
Les approches modernes pour résoudre le problème du mouvement des robots ambulants consistent en des pratiques de robotique classique issues des sections contrôle optimal et optimisation de trajectoire : LQR, QP, optimisation convexe. En savoir plus: publication de l'équipe Boston Dynamics sur Atlas .
Ces techniques sont une sorte de «codage en dur» car elles nécessitent l'introduction de nombreux détails de la tâche directement dans l'algorithme de contrôle. Il n'y a pas de systèmes d'apprentissage en eux - l'optimisation a lieu «sur place».
D'autre part, l'apprentissage par renforcement (ci-après RL) ne nécessite pas d'hypothèses dans l'algorithme, ce qui rend la solution au problème plus générale et évolutive.
Déclaration d'apprentissage par renforcement

Source
Dans le problème RL, nous considérons l'interaction de l'agent et de l'environnement comme une séquence de paires (état, récompense) et les transitions entre elles - action .
(s0) xrightarrowa0(s1,r1) xrightarrowa1... xrightarrowan−1(sn,rn)
Définissez la terminologie:
- pi(at|st) - politique , stratégie de comportement des agents, probabilité conditionnelle,
- at sim pi( cdot|st) - l' action est considérée comme une variable aléatoire de la distribution pi ,
Nous pourrions considérer la politique comme une fonction pi:States toActions , mais nous voulons rendre les actions des agents stochastiques, ce qui facilite l' exploration . C'est-à-dire avec une certaine probabilité, nous ne faisons pas tout à fait les actions que l'agent choisit. - tau - trajectoire tracée par l'agent, séquence (s1,s2,...,sn) .
La tâche de l'agent est de maximiser le rendement attendu :
J( pi)= E tau sim pi[R( tau)]= E tau sim pi left[ sumnt=0rt right]
Maintenant, nous pouvons formuler le problème RL, trouver:
pi∗=arg mathopmax piJ( pi)
où pi∗ Est la politique optimale.
En savoir plus dans le matériel d'OpenAI: OpenAI Spinning Up .
Gradient politique
Il est à noter qu'un énoncé rigoureux du problème RL en tant que problème d'optimisation nous donne l'opportunité d'utiliser les méthodes d'optimisation déjà connues, par exemple, la descente de gradient . Imaginez à quel point ce serait cool si nous pouvions prendre le gradient de retour attendu par les paramètres du modèle : nabla thetaJ( pi theta) . Dans ce cas, la règle de mise à jour des échelles serait simple:
theta= thetaold+ alpha nabla thetaJ( pi theta)
C'est précisément l'idée de toutes les méthodes de gradient politique . La conclusion stricte de ce gradient est quelque peu inconditionnelle. Nous ne l'écrirons pas ici, mais laisserons un lien vers le merveilleux matériel d'OpenAI . Le dégradé ressemble à ceci:
nabla thetaJ( pi theta)= E tau sim pi theta left[ sumTt=0 nabla theta log pi theta(at|st)R( tau) droite]
Ainsi, la perte de notre modèle sera la suivante:
loss=− log( pi theta(at|st))R( tau)
Rappelez-vous que R( tau)= sumTt=0rt et pi theta(at|st) - c'est la sortie de notre modèle au moment où elle était en st . Le moins est apparu du fait que nous voulons maximiser J . Lors de la formation, nous considérerons le gradient sur les lots et les ajouterons afin de réduire la variance (bruit de données dû à l'environnement stochastique).
Il s'agit d'un algorithme de travail appelé REINFORCE . Et il sait trouver des solutions pour certains environnements simples. Par exemple, "CartPole-v1" .
Considérez le code d'agent:
class ActorNetworkDiscrete: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=20, activation=tf.nn.relu) output_linear = tf.layers.dense(l1, units=action_space) output = tf.nn.softmax(output_linear) self.action_op = tf.squeeze(tf.multinomial(logits=output_linear,num_samples=1), axis=1)
Nous avons un petit perceptron de cette architecture: (observation_space, 10, action_space) [pour CartPole c'est (4, 10, 2)]. tf.multinomial vous permet de choisir une action pondérée aléatoirement. Pour obtenir une action, vous devez appeler:
action = sess.run(actor.action_op, feed_dict={actor.state_ph: observation})
Et donc nous allons le former:
batch_generator = generate_batch(environments, batch_size=batch_size) for epoch in tqdm_notebook(range(epochs_number)): batch = next(batch_generator)
Le générateur de lots exécute l'agent dans l'environnement et accumule des données pour la formation. Les éléments du lot sont des tuples de ce type: (st,at,R( tau)) .
L'écriture d'un bon générateur est une tâche distincte, où la principale difficulté est le coût relativement élevé de l'appel à sess.run () par rapport à une seule étape de simulation (même MuJoCo). Pour accélérer le travail, vous pouvez exploiter le fait que les réseaux de neurones fonctionnent par lots et utilisent de nombreux environnements parallèles. Même leur lancement séquentiel dans un thread donnera une accélération significative par rapport à un environnement unique.
Code de générateur utilisant DummyVecEnv à partir des lignes de base OpenAI L'agent résultant peut jouer dans des environnements avec un espace limité d'actions . Ce format ne convient pas à notre tâche. L'agent contrôlant le robot doit émettre un vecteur de Rn où n - le nombre de degrés de liberté. ( ou vous pouvez diviser l'espace d'action en espaces et obtenir une tâche avec une sortie discrète )
Politiques gaussiennes diagonales
L'essence de l'approche des politiques diagonales gaussiennes est que le modèle produise des paramètres de la distribution normale à n dimensions, à savoir mu theta - mat. attendre et sigma theta - écart type. Dès que l'agent doit entreprendre une action, nous demanderons ces paramètres au modèle et prendrons une variable aléatoire de cette distribution. Nous avons donc fait sortir l'agent Rn et l'a rendu stochastique. La chose la plus importante est qu'après avoir fixé la classe de distribution à la sortie, nous pouvons calculer log( pi theta(at|st)) et donc gradient politique.
Remarque: peut être corrigé sigma theta comme hyperparamètre, réduisant ainsi la dimension de sortie. La pratique montre que cela ne cause pas beaucoup de mal, mais au contraire stabilise l'apprentissage.
En savoir plus sur la politique stochastique .
Code d'agent:
epsilon = 1e-8 def gaussian_loglikelihood(x, mu, log_std): pre_sum = -0.5 * (((x - mu) / (tf.exp(log_std) + epsilon))**2 + 2 * log_std + np.log(2 * np.pi)) return tf.reduce_sum(pre_sum, axis=1) class ActorNetworkContinuous: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=100, activation=tf.nn.tanh) l2 = tf.layers.dense(l1, units=50, activation=tf.nn.tanh) l3 = tf.layers.dense(l2, units=25, activation=tf.nn.tanh) mu = tf.layers.dense(l3, units=action_space) log_std = tf.get_variable(name='log_std', initializer=-0.5 * np.ones(action_space, std = tf.exp(log_std) self.action_op = mu + tf.random.normal(shape=tf.shape(mu)) * std
La partie formation n'est pas différente.
Nous pouvons enfin voir comment REINFORCE fera face à notre tâche. Ci-après, l'objectif de l'agent est de se déplacer vers la droite.
Lentement mais sûrement, rampant vers son objectif.
Récompense à emporter
Notez qu'il y a des membres supplémentaires dans notre dégradé. À savoir à chaque étape t lors de la pesée du gradient du logarithme, nous utilisons la récompense totale pour toute la trajectoire . Ainsi, évaluer les actions de l'agent par ses réalisations du passé. Ça ne va pas, non? C'est pourquoi
nabla thetaJ( pi theta)= E tau sim pi theta left[ sumTt=0 nabla theta log pi theta(at|st) sumTt′=0rt′ right]
deviendra ceci
nabla thetaJ( pi theta)= E tau sim pi theta left[ sumTt=0 nabla theta log pi theta(at|st) sumTt′=trt′ right]
Trouvez 10 différences :)
Si la présence de ces membres ne gâche rien mathématiquement, elle nous fait beaucoup de bruit. Maintenant, pendant la formation, l'agent ne fera attention qu'aux récompenses qu'il a reçues après une action spécifique .
En raison de cette amélioration, la récompense moyenne a augmenté. L'un des agents reçus a appris à utiliser les membres antérieurs pour atteindre son objectif:
Réduisez la variance en ajoutant des critiques
L'essence d'autres améliorations est la réduction du bruit (variance) résultant des transitions stochastiques entre les états du milieu.
Cela nous aidera à ajouter un modèle qui prédira le montant moyen des récompenses reçues par l'agent, à partir de l'état s à la fin de la trajectoire, c'est-à-dire Fonction de valeur.
V pi(s)= E tau sim pi left[R( tau)|s0=s right] text−Fonctiondevaleur
Q pi(s,a)= E tau sim pi left[R( tau)|s0=s,a0=a right] text−FonctionAction−Value
A pi(s,a)=Q pi(s,a)−V pi(s) text−FonctionAvantage
La fonction Valeur affiche le retour attendu si notre politique démarre le jeu à partir d'un état spécifique. La même chose avec la fonction Q, il suffit de corriger la toute première action.
Ajouter des critiques
Voici à quoi ressemble le dégradé lors de l'utilisation de la récompense à emporter:
nabla theta log pi theta(at|st) sumTt′=trt′
Maintenant, le coefficient du gradient du logarithme n'est rien de plus qu'un échantillon de la fonction Valeur.
sumTt′=trt′ simV pi(st)
Nous pesons le gradient du logarithme avec un échantillon d'une trajectoire particulière, ce qui n'est pas bon. Nous pouvons approximer la fonction Valeur avec un modèle, par exemple un réseau de neurones, et lui demander la valeur nécessaire, réduisant ainsi la variance. Nous appellerons ce modèle un critique (Critique) et l'étudierons en parallèle avec la politique. Ainsi, la formule du gradient peut s'écrire:
nabla theta log pi theta(at|st) sumTt′=trt′ approx nabla theta log pi theta(at|st)V pi( tau)
Nous avons réduit la variance, mais en même temps, nous avons introduit un biais dans notre algorithme, car les réseaux de neurones peuvent faire des erreurs d'approximation. Mais le compromis dans cette situation est bon. De telles situations dans l'apprentissage automatique sont appelées compromis biais-variance .
Le critique enseignera la régression valeur-fonction sur des échantillons de récompense à emporter collectés dans l'environnement. En tant que fonction d'erreur, nous prenons MSE. C'est-à-dire la perte ressemble à ceci:
loss=(V pi psi(st)− sumTt′=trt′)2
Code critique:
class CriticNetwork: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=100, activation=tf.nn.tanh) l2 = tf.layers.dense(l1, units=50, activation=tf.nn.tanh) l3 = tf.layers.dense(l2, units=25, activation=tf.nn.tanh) output = tf.layers.dense(l3, units=1) self.value_op = tf.squeeze(output, axis=-1)
Le cycle de formation ressemble maintenant à ceci:
batch_generator = generate_batch(envs, batch_size=batch_size) for epoch in tqdm_notebook(range(epochs_number)): batch = next(batch_generator)
Maintenant, le lot contient une autre valeur, valeur, calculée par le critique dans le générateur.
C'est-à-dire le type de lot est le suivant: (st,at,V pi psi(st), sumTt′=trt′) .
Dans le cycle, rien ne nous empêche de former le critique à la convergence , nous prenons donc plusieurs étapes de descente de gradient, améliorant ainsi l'approximation de la fonction Valeur et réduisant le biais. Cependant, cette approche nécessite une grande taille de lot pour éviter de se recycler. Une affirmation similaire sur la politique d'apprentissage n'est pas vraie. Il devrait avoir un retour instantané de l'environnement d'apprentissage, sinon nous pouvons nous retrouver dans une situation où nous amendons la politique pour des actions qu'il n'aurait pas déjà prises. Les algorithmes avec cette propriété sont appelés on-policy .
Baselines in Gradient Policy
On peut montrer que dans le gradient, il est permis de mettre une large classe d'autres fonctions utiles de t . Ces fonctions sont appelées lignes de base . ( Conclusion de ce fait ) Les fonctions suivantes fonctionnent bien comme références:

Source: papier GAE .
Différentes lignes de base donnent des résultats différents selon la tâche. En règle générale, le plus grand profit est donné par la fonction Avantage et ses approximations.
Il y a même un peu d'intuition derrière cela. Lorsque nous utilisons Advantage, nous infligeons une amende à l'agent proportionnellement à ce qui est bien meilleur ou pire que la moyenne que l'agent considère l'action qu'il a effectuée. Et plus l'agent joue mieux dans l'environnement, plus ses standards sont élevés . L'agent idéal jouera bien et évaluera toutes ses actions comme ayant un avantage égal à 0 et, par conséquent, un gradient égal à 0.
Évaluation des avantages via la fonction Value
Rappelez-vous la définition de l'avantage:
A pi(s,a)=Q pi(s,a)−V pi(s) text−FonctionAvantage
Il n'est pas clair comment apprendre explicitement une telle fonction. Une astuce viendra à la rescousse, ce qui réduira le calcul de la fonction Avantage au calcul de la fonction Valeur.
Définir deltaVt=rt+V(st+1)−V(st) - Différence temporelle résiduelle ( TD-résiduelle ). Il n'est pas difficile de déduire qu'une telle fonction se rapproche d'Avantage:
E left[ deltaVt right]= E left[rt+V(st+1)−V(st) right]= E left[Q(st,at)−V(st) right]=A(st,at)
Un tel changement conceptuellement complexe provoque un changement moins important dans le code. Maintenant, au lieu d'évaluer la fonction Valeur, le critique soumettra une évaluation Avantage pour la formation sur les politiques.
L'algorithme résultant est appelé Advantage Actor-Critic .
def estimate_advantage(states, rewards): values = sess.run(critic.value_op, feed_dict={critic.state_ph: states}) deltas = rewards - values deltas = deltas + np.append(values[1:], np.array([0])) return deltas, values
Les agents obtenus peuvent être observés avec une démarche confiante et une utilisation synchrone des membres:
Estimation des avantages généralisés
Un article relativement récent (2018), « Contrôle continu à haute dimension utilisant l'estamation généralisée des avantages », propose une évaluation encore plus efficace d'Advantage grâce à la fonction Valeur. Il réduit encore plus la variance:
AGAE( gamma, lambda)t= sum l=0infty( gamma lambda)l deltaVt+l
où:
- deltaVt=rt+V(st+1)−V(st) - TD résiduel,
- gamma - facteur d'actualisation (hyperparamètre),
- lambda - hyperparamètre.
L'interprétation se trouve dans la publication elle-même.
Réalisation:
def discount_cumsum(x, coef):
Lors de l'utilisation d'une petite taille de lot, l'algorithme a convergé vers certains optima locaux. Ici, l'agent utilise une patte comme canne, et le reste repousse:
Ici, l'agent n'est pas venu à l'utilisation de sauts, mais simplement à se doigter rapidement avec les membres. Et vous pouvez également voir comment il se comporte, s'il hésite, il se retournera et continuera à courir:
Le meilleur agent, il est au tout début de l'article. Saut stable, au cours duquel tous les membres sortent de la surface. La capacité développée d'équilibrage permet à l'agent de corriger la trajectoire à pleine vitesse en cas d'erreur:
Pièges
L'apprentissage automatique est réputé pour la dimension de l'espace des erreurs qui peuvent être commises et pour obtenir un algorithme complètement non fonctionnel. Mais RL prend le problème à un tout autre niveau.
Source
Voici quelques-unes des difficultés rencontrées lors du développement.
- L'algorithme est étonnamment sensible aux hyperparamètres. Il y a eu un changement dans la qualité de l'apprentissage lors du changement du taux d'apprentissage de 3e-4 à 1e-4. Et l'image a radicalement changé - d'un algorithme complètement non convergent au meilleur qui soit dans la vidéo.
- La taille du lot n'est pas du tout la même que dans les autres zones de DL. Si dans la classification d'images, vous pouvez vous permettre de choisir la taille du lot 32-256 et que le résultat ne changera pas spécialement en l'augmentant, alors il vaut mieux prendre quelques milliers, 3000 œuvres pour notre tâche. Et encore une fois, du manque de convergence à un bon algorithme.
- Il est préférable d'apprendre à exécuter plusieurs fois, parfois avec des graines aléatoires n'est pas chanceux.
- Apprendre dans un environnement aussi complexe prend beaucoup de temps et les progrès ne sont pas uniformes. Par exemple, le meilleur algorithme appris pendant 8 heures, dont 3 ont montré un résultat pire qu'une ligne de base aléatoire. Par conséquent, lors du test des algorithmes, il est préférable de commencer par un petit, comme les environnements de jouets du gymnase.
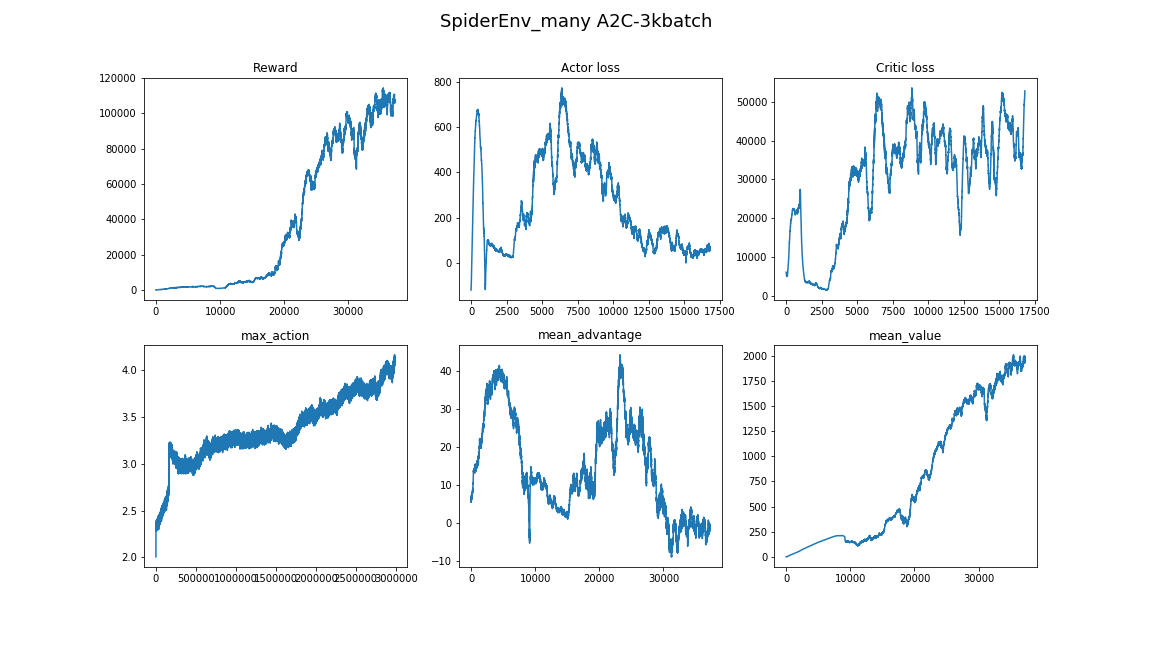
- Une bonne approche pour trouver des hyperparamètres et des architectures de modèle serait de jeter un œil aux articles et implémentations connexes. (l'essentiel est de ne pas se recycler)
Vous pouvez en savoir plus sur les nuances de Deep RL dans cet article: L'apprentissage par renforcement profond ne fonctionne pas encore .
Conclusion
L'algorithme résultant résout le problème de manière convaincante. Fonction trouvée pi: R800 à R18 , contrôlant agilement et en toute confiance le robot.
Une suite logique sera l'étude des proches parents des algorithmes A2C, PPO et TRPO. Ils améliorent l' efficacité des échantillons , c'est-à-dire temps de convergence de l'algorithme, et ils sont capables de résoudre des problèmes plus complexes. C'est PPO + Automatic Domain Randomization qui a récemment assemblé le Rubik's Cube sur un robot .
Ici vous pouvez trouver le code de l'article: référentiel .
J'espère que vous avez apprécié l'article et que vous avez été inspiré par ce que l'apprentissage par renforcement profond peut faire aujourd'hui.
Merci de votre attention!
Liens utiles:
Merci à pinkotter , Vambala , andrey_probochkin , pollyfom et suriknik pour leur aide avec le projet.
En particulier, Vambala et andrey_probochkin pour créer un environnement MuJoCo cool.