Clickhouse est un moteur de base de données de système de gestion de base de données analytique (OLAP) open source open source créé par Yandex. Il est utilisé par Yandex, CloudFlare, VK.com, Badoo et d'autres services à travers le monde pour stocker de très grandes quantités de données (insérer des milliers de lignes par seconde ou des pétaoctets de données stockées sur le disque).
Dans le SGBD «chaîne» habituel, dont MySQL, Postgres, MS SQL Server sont des exemples, les données sont stockées dans cet ordre:
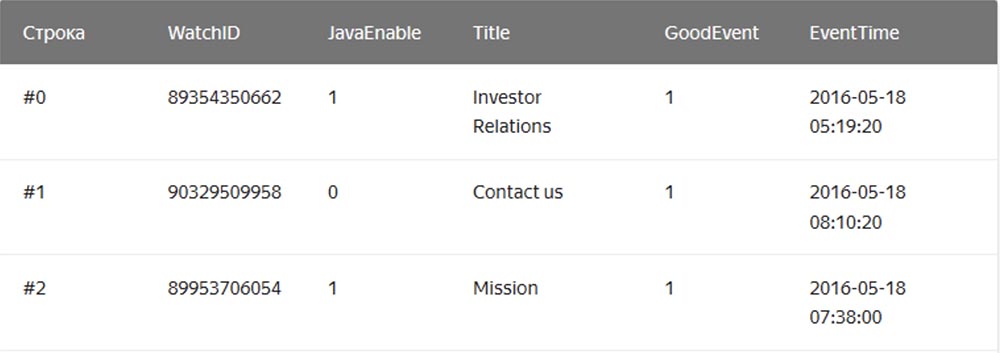
Dans ce cas, les valeurs liées à une ligne sont stockées physiquement côte à côte. Dans un SGBD en colonnes, les valeurs de différentes colonnes sont stockées séparément et les données d'une colonne sont stockées ensemble:
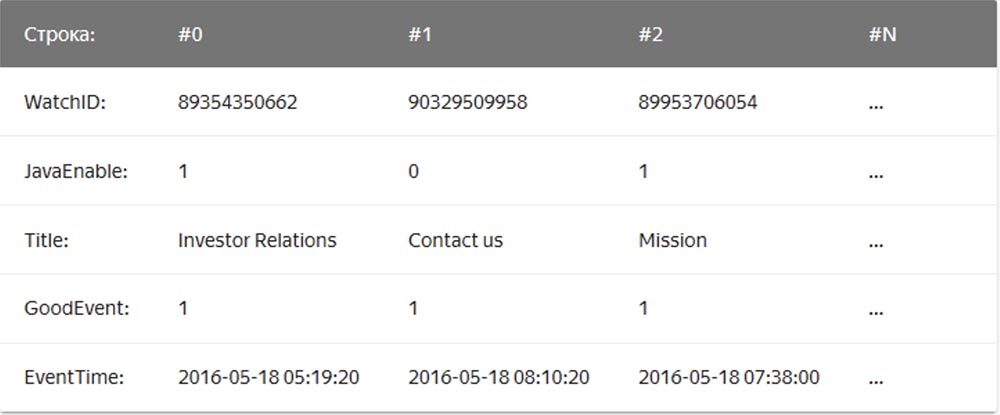
Des exemples de SGBD en colonnes sont Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb +.
La société de
transfert de courrier Qwintry a commencé à utiliser Clickhouse en 2018 pour ses rapports et a été très impressionnée par sa simplicité, son évolutivité, sa prise en charge SQL et sa vitesse. La vitesse de ce SGBD était bordée de magie.
Simplicité
Clickhouse s'installe sur Ubuntu avec une seule commande. Si vous connaissez SQL, vous pouvez immédiatement commencer à utiliser Clickhouse pour vos besoins. Cependant, cela ne signifie pas que vous pouvez exécuter "show create table" dans MySQL et copier-coller SQL dans Clickhouse.
Par rapport à MySQL, dans ce SGBD, il existe d'importantes différences de types de données dans les définitions des schémas de table, donc pour un travail confortable, vous avez encore besoin de temps pour modifier les définitions du schéma de table et étudier les moteurs de table.
Clickhouse fonctionne très bien sans aucun logiciel supplémentaire, mais si vous souhaitez utiliser la réplication, vous devrez installer ZooKeeper. L'analyse des performances des requêtes montre d'excellents résultats - les tables système contiennent toutes les informations et toutes les données peuvent être obtenues en utilisant l'ancien SQL ennuyeux.
Performances
- Benchmark comparant Clickhouse avec Vertica et MySQL sur un serveur de configuration: deux sockets CPU Intel® Xeon® E5-2650 v2 @ 2.60GHz; 128 Go de RAM; md RAID-5 sur 8 disques durs SATA de 6 To, ext4.
- Benchmark comparant Clickhouse avec le stockage de données cloud Amazon RedShift.
- Extraits du blog sur les performances de Cloudflare Clickhouse :

La base de données ClickHouse a une conception très simple - tous les nœuds du cluster ont les mêmes fonctionnalités et utilisent uniquement ZooKeeper pour la coordination. Nous avons construit un petit cluster de plusieurs nœuds et effectué des tests, au cours desquels nous avons constaté que le système avait des performances assez impressionnantes, ce qui correspond aux avantages déclarés dans les références des SGBD analytiques. Nous avons décidé d'examiner de plus près le concept derrière ClickHouse. Le premier obstacle à la recherche était le manque d'outils et la petite taille de la communauté ClickHouse, nous avons donc exploré la conception de ce système de gestion de base de données pour comprendre comment il fonctionne.
ClickHouse ne prend pas en charge la réception de données directement depuis Kafka (pour le moment, il sait déjà comment), car il ne s'agit que d'une base de données, nous avons donc écrit notre propre service d'adaptateur dans Go. Il a lu les messages codés Cap'n Proto de Kafka, les a convertis en TSV et les a insérés dans ClickHouse par lots via l'interface HTTP. Plus tard, nous avons réécrit ce service pour utiliser la bibliothèque Go en conjonction avec notre propre interface ClickHouse pour améliorer les performances. Lors de l'évaluation des performances de réception des paquets, nous avons découvert une chose importante - il s'est avéré que chez ClickHouse, ces performances dépendent fortement de la taille du paquet, c'est-à-dire du nombre de lignes insérées en même temps. Pour comprendre pourquoi cela se produit, nous avons examiné comment ClickHouse stocke les données.
Le moteur principal, ou plutôt la famille de moteurs de table utilisés par ClickHouse pour stocker des données, est MergeTree. Ce moteur est conceptuellement similaire à l'algorithme LSM utilisé par Google BigTable ou Apache Cassandra, mais il évite de construire une table de mémoire intermédiaire et écrit des données directement sur le disque. Cela lui donne un excellent débit d'écriture, car chaque paquet inséré n'est trié que par la clé primaire «clé primaire», est compressé et écrit sur le disque pour former un segment.
L'absence d'une table mémoire ou de tout concept de «fraîcheur» des données signifie également qu'elles ne peuvent être ajoutées que le système ne prend pas en charge leur modification ou leur suppression. Aujourd'hui, la seule façon de supprimer des données est de les supprimer par mois calendaires, car les segments ne franchissent jamais la limite du mois. L'équipe ClickHouse travaille activement à rendre cette fonctionnalité personnalisable. D'un autre côté, cela rend l'enregistrement et la fusion des segments sans couture, de sorte que la bande passante de réception évolue linéairement avec le nombre d'insertions parallèles jusqu'à ce que les E / S ou les cœurs soient saturés.
Cependant, ce fait signifie également que le système n'est pas adapté aux petits colis, donc les services et les inserts Kafka sont utilisés pour la mise en mémoire tampon. De plus, ClickHouse en arrière-plan continue de constamment effectuer la fusion de segments, de sorte que de nombreuses petites informations seront combinées et enregistrées plusieurs fois, augmentant ainsi l'intensité d'enregistrement. Dans ce cas, trop de pièces non liées entraîneront un étranglement agressif des inserts tant que la fusion se poursuivra. Nous avons constaté que le meilleur compromis entre la réception de données en temps réel et les performances de réception est de recevoir un nombre limité d'insertions par seconde dans la table.
La clé des performances de lecture de table est l'indexation et le positionnement des données sur le disque. Quelle que soit la vitesse du traitement, lorsque le moteur doit analyser des téraoctets de données à partir du disque et n'en utiliser qu'une partie, cela prendra du temps. ClickHouse est un magasin de colonnes, donc chaque segment contient un fichier pour chaque colonne (colonne) avec des valeurs triées pour chaque ligne. Ainsi, des colonnes entières qui ne figurent pas dans la requête peuvent être ignorées en premier, puis plusieurs cellules peuvent être traitées en parallèle avec l'exécution vectorisée. Pour éviter une analyse complète, chaque segment a un petit fichier d'index.
Étant donné que toutes les colonnes sont triées par «clé primaire», le fichier d'index ne contient que les étiquettes (lignes capturées) de chaque Nième ligne afin de pouvoir les stocker en mémoire même pour les très grandes tables. Par exemple, vous pouvez définir les paramètres par défaut "marquer chaque 8192ème ligne", puis l'indexation "maigre" de la table avec 1 billion. les lignes, qui s'intègrent facilement dans la mémoire, n'occuperont que 122 070 caractères.
Développement du système
Le développement et l'amélioration de Clickhouse peuvent être retracés jusqu'au
repo Github et s'assurer que le processus de «croissance» se déroule à un rythme impressionnant.
Popularité
Clickhouse semble croître de façon exponentielle, en particulier dans la communauté russophone. La conférence de l'an dernier, High load 2018 (Moscou, du 8 au 9 novembre 2018), a montré que des monstres tels que vk.com et Badoo utilisent Clickhouse, avec lequel ils collent des données (par exemple, des journaux) de dizaines de milliers de serveurs en même temps. Dans une vidéo de 40 minutes,
Yuri Nasretdinov de l'équipe VKontakte explique comment cela se fait . Bientôt, nous publierons la transcription sur Habr pour la commodité de travailler avec le matériel.
Domaines d'application
Après avoir passé un peu de temps à rechercher, je pense qu'il y a des domaines dans lesquels ClickHouse peut être utile ou capable de remplacer complètement d'autres solutions plus traditionnelles et populaires, telles que MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, TimescaleDB, Hadoop, MapReduce, Pinot et Druid. Voici les détails de l'utilisation de ClickHouse pour mettre à niveau ou remplacer complètement les SGBD ci-dessus.
Extension de MySQL et PostgreSQL
Plus récemment, nous avons partiellement remplacé MySQL par ClickHouse pour la
plateforme de newsletter Mautic newsletter . Le problème était que MySQL, en raison de sa conception mal conçue, journalisait chaque e-mail envoyé et chaque lien dans cet e-mail avec un hachage base64, créant une énorme table MySQL (email_stats). Après avoir envoyé seulement 10 millions de lettres aux abonnés du service, cette table occupait 150 Go d'espace fichier et MySQL a commencé à "s'émousser" sur les requêtes simples. Pour résoudre le problème d'espace fichier, nous avons utilisé avec succès la compression de table InnoDB, qui l'a réduite de 4 fois. Cependant, cela n'a toujours aucun sens de stocker plus de 20 à 30 millions de courriels dans MySQL juste pour la lecture de l'histoire, car toute simple demande qui, pour une raison quelconque, doit effectuer une analyse complète entraîne un échange et une charge importante sur les E / S, par exemple. à propos desquels nous recevons régulièrement des avertissements Zabbix.

Clickhouse utilise deux algorithmes de compression qui réduisent la quantité de données d'environ
3 à
4 fois , mais dans ce cas particulier, les données étaient particulièrement «compressibles».

Remplacement ELK
D'après notre propre expérience, la pile ELK (ElasticSearch, Logstash et Kibana, dans ce cas particulier, ElasticSearch) nécessite beaucoup plus de ressources pour s'exécuter que ce qui est nécessaire pour stocker les journaux. ElasticSearch est un excellent moteur si vous avez besoin d'une bonne recherche de journal en texte intégral (et je ne pense pas que vous en ayez vraiment besoin), mais je me demande pourquoi, de facto, il est devenu le moteur de journalisation standard. Ses performances de réception en combinaison avec Logstash ont créé des problèmes pour nous même avec des charges plutôt petites et ont nécessité l'ajout d'une quantité croissante de RAM et d'espace disque. En tant que base de données, Clickhouse est meilleur qu'ElasticSearch pour les raisons suivantes:
- Prise en charge du dialecte SQL;
- Le meilleur taux de compression des données stockées;
- Prise en charge des recherches d'expressions régulières regex au lieu de recherches en texte intégral;
- Planification des requêtes améliorée et performances globales supérieures.
Actuellement, le plus gros problème qui se pose lors de la comparaison de ClickHouse avec ELK est le manque de solutions pour l'envoi des journaux, ainsi que le manque de documentation et d'aides à la formation sur ce sujet. Dans le même temps, chaque utilisateur peut configurer ELK à l'aide du Digital Ocean Guide, qui est très important pour la mise en œuvre rapide de ces technologies. Il y a un moteur de base de données ici, mais il n'y a pas encore de Filebeat pour ClickHouse. Oui, il existe
fluentd et un système pour travailler avec les journaux de
loghouse , il existe un outil
clicktail pour entrer les données des fichiers journaux dans ClickHouse, mais tout cela prend plus de temps. Cependant, ClickHouse mène toujours en raison de sa simplicité, donc même les débutants l'installent de manière élémentaire et commencent à l'utiliser pleinement en seulement 10 minutes.
Préférant des solutions minimalistes, j'ai essayé d'utiliser FluentBit, un outil pour envoyer des journaux avec une très petite quantité de mémoire, avec ClickHouse, tout en essayant d'éviter d'utiliser Kafka. Cependant, des incompatibilités mineures, telles que des
problèmes de format de date , doivent être corrigées avant de pouvoir le faire sans une couche proxy qui convertit les données de FluentBit en ClickHouse.
Comme alternative à Kibana, vous pouvez utiliser
Grafana comme
backend ClickHouse. Si je comprends bien, cela peut entraîner des problèmes de performances lors du rendu d'une énorme quantité de points de données, en particulier avec les anciennes versions de Grafana. Chez Qwintry, nous n'avons pas encore essayé, mais des plaintes à ce sujet apparaissent de temps en temps sur le canal de support ClickHouse dans Telegram.
Remplacement de Google Big Query et Amazon RedShift (solution pour les grandes entreprises)
Le cas d'utilisation idéal pour BigQuery est de télécharger 1 To de données JSON et d'effectuer des requêtes analytiques sur celles-ci. Big Query est un excellent produit dont l'évolutivité est difficile à surestimer. C'est un logiciel beaucoup plus complexe que ClickHouse, fonctionnant sur un cluster interne, mais du point de vue du client, il a beaucoup en commun avec ClickHouse. BigQuery peut rapidement augmenter le prix dès que vous payez pour chaque SELECT, c'est donc une véritable solution SaaS avec tous ses avantages et ses inconvénients.
ClickHouse est le meilleur choix lorsque vous effectuez de nombreuses requêtes coûteuses en calcul. Plus vous exécutez de requêtes SELECT chaque jour, plus il est logique de remplacer Big Query par ClickHouse, car un tel remplacement vous fera économiser des milliers de dollars en termes de téraoctets de données traitées. Cela ne s'applique pas aux données stockées, ce qui est assez bon marché à traiter dans Big Query.
L'article du cofondateur d'Altinity, Alexander Zaitsev,
«Switching to ClickHouse», parle des avantages d'une telle migration de SGBD.
Remplacement de TimescaleDB
TimescaleDB est une extension PostgreSQL qui optimise le travail avec les séries temporelles de séries chronologiques dans une base de données régulière (
https://docs.timescale.com/v1.0/introduction ,
https://habr.com/en/company/zabbix/blog/458530 / ).
Bien que ClickHouse ne soit pas un concurrent sérieux dans le créneau des séries temporelles, mais la structure des colonnes et l'exécution vectorielle des requêtes, dans la plupart des cas de traitement des requêtes analytiques, il est beaucoup plus rapide que TimescaleDB. Dans le même temps, les performances de réception des données de paquets ClickHouse sont environ 3 fois plus élevées, en outre, elles utilisent 20 fois moins d'espace disque, ce qui est vraiment important pour le traitement de grandes quantités de données historiques:
https://www.altinity.com/blog/ClickHouse-for -série temporelle .
Contrairement à ClickHouse, la seule façon d'économiser de l'espace disque dans TimescaleDB est d'utiliser ZFS ou des systèmes de fichiers similaires.
Les prochaines mises à jour de ClickHouse introduiront probablement une compression delta, ce qui la rendra encore plus adaptée au traitement et au stockage des données de séries chronologiques. TimescaleDB peut être un meilleur choix qu'un ClickHouse nu dans les cas suivants:
- petites installations avec une très petite quantité de RAM (<3 Go);
- un grand nombre de petits INSERT que vous ne souhaitez pas mettre en tampon dans de grands fragments;
- meilleure cohérence, uniformité et exigences ACID;
- Prise en charge de PostGIS;
- fusion avec les tables PostgreSQL existantes, car Timescale DB est essentiellement PostgreSQL.
Concurrence avec les systèmes Hadoop et MapReduce
Hadoop et d'autres produits MapReduce peuvent effectuer de nombreux calculs complexes, mais ils fonctionnent généralement avec des retards énormes. ClickHouse résout ce problème en traitant des téraoctets de données et en fournissant des résultats presque instantanément. Ainsi, ClickHouse est beaucoup plus efficace pour effectuer des recherches analytiques rapides et interactives, ce qui devrait être intéressant pour les spécialistes du traitement des données.
Compétition avec Pinot et Druide
Les concurrents les plus proches de ClickHouse sont Pinot et Druid, un produit open source linéairement évolutif en colonnes. Un excellent travail de comparaison de ces systèmes a été publié dans un article de
Roman Leventov daté du 1er février 2018.
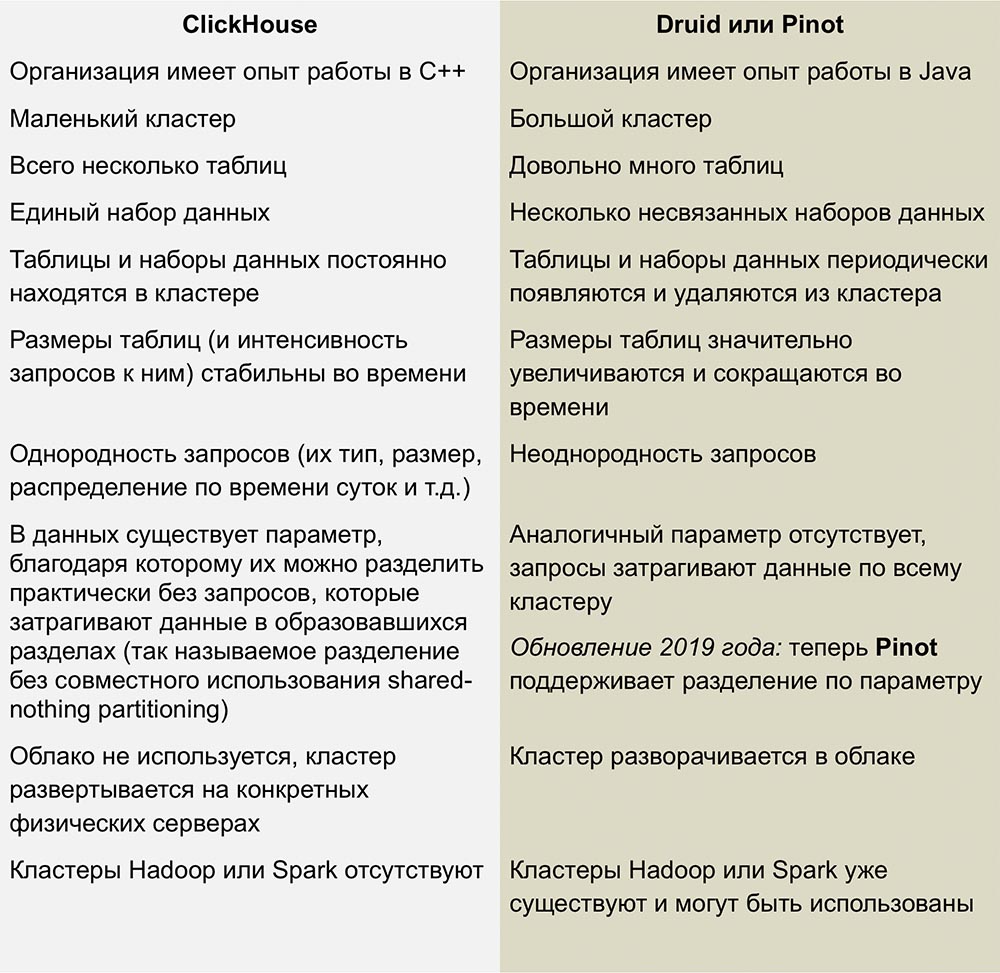
Cet article nécessite une mise à jour - il indique que ClickHouse ne prend pas en charge les opérations UPDATE et DELETE, ce qui n'est pas entièrement vrai pour les dernières versions.
Nous n'avons pas assez d'expérience avec ces SGBD, mais je n'aime pas la complexité de l'infrastructure utilisée pour exécuter Druid et Pinot - c'est tout un tas de «pièces mobiles» entourées de Java de tous les côtés.
Druid et Pinot sont des projets d'incubateur Apache, dont le développement est couvert en détail par Apache dans les pages de ses projets GitHub. Le pinot est apparu dans l'incubateur en octobre 2018, et le druide est né 8 mois plus tôt - en février.
Le manque d'informations sur le fonctionnement d'AFS me pose quelques questions, et peut-être stupides. Je me demande si les auteurs de Pinot ont remarqué que la Fondation Apache est plus disposée envers le druide, et cette attitude envers le concurrent a-t-elle fait envie? Le développement de Druid va-t-il ralentir et Pinot va-t-il s'accélérer si des sponsors soutenant les premiers s'intéressent soudainement aux seconds?
Inconvénients de ClickHouse
Immaturité: Évidemment, ce n'est toujours pas une technologie ennuyeuse, mais en tout cas, rien de semblable n'est observé dans d'autres SGBD en colonnes.
Les petits inserts ne fonctionnent pas bien à grande vitesse: les inserts doivent être divisés en gros morceaux, car les performances des petits inserts diminuent proportionnellement au nombre de colonnes de chaque ligne. C'est ainsi que ClickHouse stocke les données sur le disque - chaque colonne signifie 1 fichier ou plus, donc pour insérer 1 ligne contenant 100 colonnes, vous devez ouvrir et écrire au moins 100 fichiers. C'est pourquoi un intermédiaire est nécessaire pour mettre en mémoire tampon les insertions (sauf si le client lui-même fournit la mise en mémoire tampon) - il s'agit généralement de Kafka ou d'une sorte de système de gestion de file d'attente. Vous pouvez également utiliser le moteur de table Buffer pour copier ultérieurement de gros morceaux de données dans des tables MergeTree.
Les jointures de table sont limitées par la RAM du serveur, mais au moins elles sont là! Par exemple, Druid et Pinot n'ont pas de telles connexions du tout, car ils sont difficiles à implémenter directement dans les systèmes distribués qui ne prennent pas en charge le déplacement de grandes données entre les nœuds.
Conclusions
Dans les années à venir, nous prévoyons d'utiliser largement ClickHouse dans Qwintry, car ce SGBD offre un excellent équilibre de performances, une faible surcharge, une évolutivité et une simplicité. Je suis à peu près sûr qu'il commencera à se propager rapidement dès que la communauté ClickHouse proposera de nouvelles façons de l'utiliser sur les petites et moyennes installations.
Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis
des VPS basés sur le cloud pour les développeurs à partir de 4,99 $ , un
analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur les VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?