
Présentation
J'aime beaucoup la programmation, je suis amateur et la première et dernière fois que j'ai gagné de l'argent en 1996. Mais parfois j'écris quelque chose pour automatiser les tâches quotidiennes. Il y a environ un an, le golang a été découvert. En tant qu'outil de création d'utilitaires, le golang s'est avéré très pratique. Alors.
Il y avait un besoin de traiter un grand nombre (plus d'un millier, et je vois les sourires d'un pro) de fichiers d'archives avec des informations géophysiques spéciales. Le format de fichier est texte, simple. Si vous êtes soudainement intéressé, il s'agit d'un format LAS .
Le fichier LAS contient un en-tête et des données.
Les données sont pratiquement CSV, uniquement des délimiteurs de tabulation ou des espaces.
Et l'en-tête contient une description des données et ici, il contient généralement du texte russe. Il peut s'agir du nom du domaine, du nom des études enregistrées dans un fichier, etc.
Ces fichiers ont été créés à différents moments et dans différents programmes, il s'agit du fait que dans un fichier une partie est codée en CP1251 et une partie en CP866. J'ai besoin de traiter ces fichiers, ce qui signifie comprendre. Il était donc nécessaire de déterminer automatiquement l'encodage du fichier.
En conséquence, il a inventé un vélo sur golang et, en conséquence, une petite bibliothèque est née avec la capacité de détecter une page de codes.
À propos des encodages. Il n'y a pas si longtemps sur habr, il y avait un bon article sur les encodages Comment fonctionnent les encodages de texte. D'où viennent les "crocodiles"? Les principes de codage. Généralisation et analyse détaillée Si vous voulez comprendre ce qu'est un "os" ou un "os", alors cela vaut la peine d'être lu.
Au début, j'ai jeté ma décision. Ensuite, j'ai essayé de trouver une solution de travail prête à l'emploi sur Golang, mais j'ai échoué. Il y avait deux solutions, mais les deux ne fonctionnent pas.
- Le premier «prêt à l'emploi» est la fonction golang.org/x/net/html/charset DetermineEncoding ()
- Deuxième bibliothèque - Saintfish / Chardet sur Github
Les deux se trompent sûrement sur certains encodages. Le standard ne peut presque pas déterminer quoi que ce soit à partir de fichiers texte, c'est compréhensible, cela a été fait pour les pages html.
Lors de la recherche, j'ai souvent rencontré des utilitaires prêts à l'emploi du monde Linux - enca . Trouvé sa version compilée pour WIN32, version 1.12. Je vais aussi y réfléchir, il y a des choses amusantes là-bas. Je m'excuse tout de suite pour mon ignorance totale de linux, ce qui signifie qu'il y a probablement plus de solutions que vous pouvez également essayer de visser au code golang, je n'ai plus regardé.
Comparaison des solutions trouvées pour l'encodage de la détection automatique
Préparé un catalogue softlandia \ cpd test data avec des fichiers dans différents encodages. Le contenu des fichiers est très court et identique. Une ligne «Russe dans le codage CodePageName». J'ai ajouté des fichiers avec un mélange d'encodages et de cas complexes et j'ai essayé de déterminer.
Je pense que ça s'est avéré drôle.
Observation 1
enca n'a pas déterminé l'encodage du fichier UTF-16LE sans la nomenclature - c'est étrange, d'accord. J'ai essayé d'ajouter plus de texte, mais je n'ai pas obtenu le résultat.
Observation 2. Problèmes avec les codages CP1251 et KOI8-R
Lignes 15 et 16. La commande enca a des problèmes.
Je vais ici faire une explication, le fait est que les encodages CP1251 (alias Windows 1251) et KOI8-R sont très proches si l'on considère uniquement les caractères alphabétiques.
Tableau CP 1251
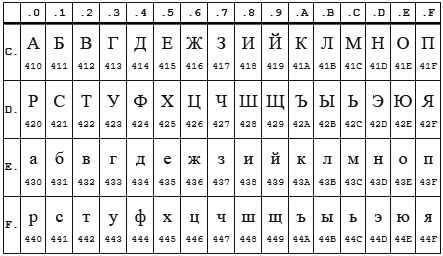
Table KOI8-r

Dans les deux encodages, l'alphabet est situé de 0xC0 à 0xFF , mais là où un encodage a des lettres majuscules, l'autre a des minuscules. Apparemment, l' enca fonctionne en lettres minuscules. Il s'avère donc que si vous envoyez la ligne «STP» encodée dans CP1251 au programme enca , alors il décidera que c'est une ligne «sauvagement» encodée dans KOI8-r , qui sera signalée. L'inverse fonctionne également.
Observation 3
La bibliothèque standard html / charset ne peut être approuvée qu'avec une définition UTF-8 , mais attention! Il doit être utilisé exactement charset.DetermineEncoding () , car la méthode utf8.Valid (b [] octet) sur les fichiers encodés utf-16be renvoie true .
Propre vélo

La détection automatique de l'encodage n'est possible que par des méthodes heuristiques, inexactes. Si nous ne savons pas dans quelle langue et dans quel encodage le fichier texte est écrit, alors il est possible de déterminer l'encodage avec une grande précision, mais ce sera difficile ... et vous aurez besoin de beaucoup de texte.
Pour moi, cet objectif n'était pas fixé. Il me suffit de déterminer les encodages en supposant qu'il y a du russe. Et deuxièmement, vous devez déterminer par un petit nombre de caractères - 10 caractères devraient avoir une définition assez sûre, et de préférence 5-6 caractères en général.
Algorithme
Quand j'ai découvert la coïncidence des encodages KOI8-r et CP1251 par l'emplacement de l'alphabet, j'étais triste pendant quelques jours ... il est devenu clair que je devais réfléchir un peu. Cela s'est avéré comme ça.
Décisions clés:
- Nous travaillerons avec une tranche d'octets, pour la compatibilité avec charset.DetermineEncoding ()
- Le codage UTF-8 et les cas de nomenclature sont vérifiés séparément
- Les données d'entrée sont transmises tour à tour à chaque codage. Chacun calcule lui-même deux critères entiers. Dont la somme de deux critères est supérieure, il a gagné.
Critères de conformité
Premier critère
Le premier critère est le nombre des lettres les plus populaires de l'alphabet russe.
Les lettres les plus courantes sont: o, e, a et, n, t, s, p, b, l, k, m, d, p, y . Ces lettres donnent une couverture de 82%. Pour tous les encodages sauf KOI8-r et CP1251, j'ai utilisé uniquement les 9 premières lettres: o, e, a et, n, t, s, p, c. Cela suffit pour une détermination fiable.
Mais pour KOI8-r et CP1251, j'ai dû modifier le fichier. Les codes de certaines de ces lettres coïncident, par exemple, la lettre o a le code 0xEE dans CP1251, tandis que dans KOI8-r ce code a la lettre n . Les lettres populaires suivantes ont été prises pour ces encodages. Pour CP1251, j'ai utilisé a, et, n, c, p, b, l, k, i. Pour KOI8-r - o, a, u, t, s, b, l, k, m.
Deuxième critère
Malheureusement, pour les cas très courts (la longueur totale du texte russe est de 5 à 6 caractères), l'occurrence des lettres populaires est au niveau de 1 à 3 pièces et il y a un chevauchement des encodages KOI8-r et CP1251. J'ai dû introduire un deuxième critère. Comptage des consonnes + voyelles .
De telles combinaisons devraient se produire le plus souvent dans la langue russe et, par conséquent, dans le codage dans lequel le nombre de telles paires est plus grand, ce codage a un critère plus large.
Les deux critères sont calculés, additionnés et le montant reçu est le critère final.
Le résultat est indiqué dans le tableau ci-dessus.
Caractéristiques que j'ai rencontrées
Une petite touche sur les charmes et les problèmes associés au golang. La section peut être intéressante uniquement pour les débutants pour écrire en golang.
Les problèmes
J'ai personnellement parcouru certains des cailloux sous-marins des 50 nuances de Go: pièges, pièges et erreurs courantes pour les débutants .
Trop inquiet et essayant de souffler dans l'eau, entendant parler des terribles brûlures du lait, est allé trop loin avec la vérification du paramètre d'entrée du type io.Reader. J'ai vérifié une variable comme io.Reader avec réflexion.
Mais comme il s'est avéré dans mon cas, il suffit de vérifier zéro. Maintenant, tout est plus facile
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
un appel à bufio.NewReader (r) .Peek (ReadBufSize) passe discrètement le test suivant:
var data *os.File res, err := CodePageDetect(data)
Dans ce cas, Peek () renvoie une erreur.
Une fois monté sur un râteau avec le transfert de tableaux en valeur. Un peu stupide d'essayer de changer les éléments stockés dans la carte, de les parcourir à portée ...
Délices
Il est difficile de dire exactement si la constante poignée de main du linter et du compilateur ou l'utilisation active de range, ou tous ensemble, mais il n'y a pratiquement aucune incursion pour sortir l'index des limites.
Bien sûr, c'est très agréable de vivre avec le garbage collector. Je suppose que je dois encore maîtriser le rake de l'automatisation de l'allocation / libération de la mémoire, mais jusqu'à présent, le sourire idiot ne quitte pas mon visage.
Une frappe forte est aussi un bonheur.
Les variables ayant un type de fonction sont, par conséquent, une implémentation facile de divers comportements pour des objets du même type.
Étrange peu devait s'asseoir dans le débogueur, relire le code donne généralement le résultat.
Puppy se réjouit d'avoir beaucoup d'outils prêts à l'emploi, c'est un sentiment merveilleux lorsque le compilateur, le langage, la bibliothèque et le code IDE Visual Studio fonctionnent pour vous ensemble, harmonieusement.
Merci Falconandy pour les conseils constructifs et utiles.
Merci à lui
- traduit des tests sur témoigner et ils sont vraiment devenus plus lisibles
- tests corrigés des chemins de fichiers de données pour la compatibilité avec Linux
- parcouru par un linter - pourtant il a trouvé une vraie erreur (putain de copie / passé)
Je continue d'ajouter des tests, un cas de non définition de l'UTF16 a été révélé. Mis à jour. Maintenant UTF16 et LE et BE sont détectés même en l'absence de lettres russes