Cube sur cube, métaclusters, cellules, allocation de ressources
Fig. 1. Écosystème Kubernetes dans Alibaba CloudDepuis 2015, Alibaba Cloud Container Service pour Kubernetes (ACK) est l'un des services cloud à la croissance la plus rapide d'Alibaba Cloud. Il sert de nombreux clients et prend également en charge l'infrastructure interne d'Alibaba et d'autres services cloud de l'entreprise.
Comme dans les services de conteneurs similaires de fournisseurs de cloud de classe mondiale, nos principales priorités sont la fiabilité et la disponibilité. Par conséquent, une plate-forme évolutive et accessible à l'échelle mondiale a été créée pour des dizaines de milliers de clusters Kubernetes.
Dans cet article, nous partagerons notre expérience de la gestion d'un grand nombre de clusters Kubernetes sur une infrastructure cloud, ainsi que l'architecture de la plateforme sous-jacente.
Entrée
Kubernetes est devenu la norme de facto pour diverses charges de travail cloud. Comme le montre la fig. 1 en haut, de plus en plus d'applications Alibaba Cloud fonctionnent désormais dans les clusters Kubernetes: ce sont des applications avec état / sans état, ainsi que des gestionnaires d'applications. La gestion de Kubernetes a toujours été un sujet de discussion intéressant et sérieux pour les ingénieurs impliqués dans la construction et la maintenance des infrastructures. En ce qui concerne les fournisseurs de cloud tels que Alibaba Cloud, la mise à l'échelle vient au premier plan. Comment gérer les clusters Kubernetes à cette échelle? Nous avons déjà parlé des meilleures pratiques pour gérer d'énormes clusters Kubernetes à 10 000 nœuds. Bien sûr, c'est un problème d'échelle intéressant. Mais il y a une autre échelle: le nombre
de clusters eux-mêmes .
Nous avons discuté de ce sujet avec de nombreux utilisateurs ACK. La plupart d'entre eux préfèrent gérer des dizaines, voire des centaines, de petits ou moyens clusters Kubernetes. Il y a des raisons raisonnables à cela: limiter les dommages potentiels, partitionner les clusters pour différentes équipes, créer des clusters virtuels pour les tests. Si ACK cherche à servir un public mondial avec ce modèle d'utilisation, il doit gérer de manière fiable et efficace un grand nombre de clusters dans plus de 20 régions.
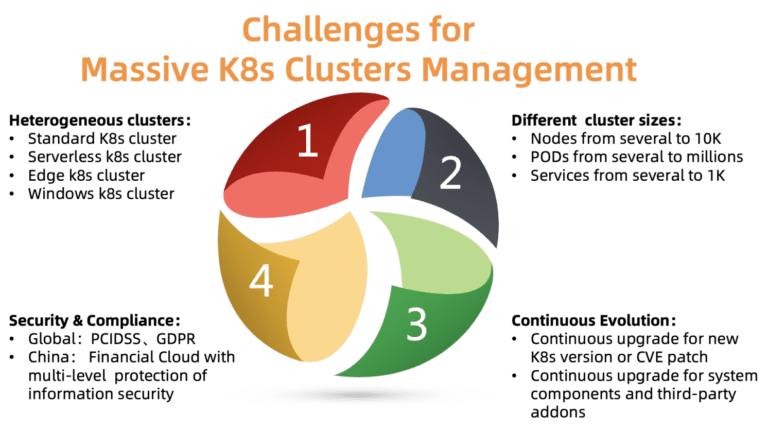 Fig. 2. Les défis de la gestion d'un grand nombre de clusters Kubernetes
Fig. 2. Les défis de la gestion d'un grand nombre de clusters KubernetesQuels sont les principaux problèmes de gestion des clusters à cette échelle? Comme le montre la figure, il y a quatre problèmes à résoudre:
ACK doit prendre en charge différents types de clusters, notamment standard, sans serveur, Edge, Windows et quelques autres. Différents clusters nécessitent différents paramètres, composants et modèles d'hébergement. Certains clients ont besoin d'aide pour la personnalisation de leurs cas spécifiques.
- Différentes tailles de cluster
Les clusters varient en taille: d'une paire de nœuds avec plusieurs pods à des dizaines de milliers de nœuds avec des milliers de pods. Les besoins en ressources sont également très différents. Une mauvaise allocation des ressources peut affecter les performances ou même conduire à l'échec.
Kubernetes se développe rapidement. De nouvelles versions sont publiées tous les quelques mois. Les clients sont toujours prêts à essayer de nouvelles fonctionnalités. Ainsi, ils veulent placer la charge de test sur les nouvelles versions de Kubernetes et la charge de travail sur les versions stables. Pour répondre à cette exigence, ACK doit continuellement fournir de nouvelles versions de Kubernetes à ses clients, tout en conservant des versions stables.
Les grappes sont réparties dans différentes régions. Par conséquent, ils doivent se conformer à diverses exigences de sécurité et réglementations officielles. Par exemple, un cluster en Europe doit se conformer au RGPD et un cloud financier en Chine doit avoir des niveaux de protection supplémentaires. Ces exigences sont obligatoires, il est inacceptable de les ignorer, car cela crée d'énormes risques pour les clients de la plateforme cloud.
La plateforme ACK est conçue pour résoudre la plupart des problèmes ci-dessus. Actuellement, il gère de manière fiable et stable plus de 10 000 clusters Kubernetes dans le monde. Voyons comment nous y sommes parvenus, notamment grâce à plusieurs principes clés de conception / architecture.
La conception
Cube-on-cube et nids d'abeille
Contrairement à une hiérarchie centralisée, l'architecture basée sur les cellules est généralement utilisée pour faire évoluer une plateforme au-delà d'un seul centre de données ou pour étendre la portée de la reprise après sinistre.
Chaque région du nuage d'Alibaba se compose de plusieurs zones (AZ) et correspond généralement à un centre de données spécifique. Dans une grande région (comme Huangzhou), des milliers de clusters de clients Kubernetes exécutant ACK sont souvent trouvés.
L'ACK gère ces clusters Kubernetes à l'aide de Kubernetes lui-même, c'est-à-dire que nous avons le métacluster Kubernetes pour gérer les clusters clients Kubernetes. Cette architecture est également appelée «cube sur cube» (kube sur kube, KoK). L'architecture KoK simplifie la gestion des clusters clients car le déploiement d'un cluster devient simple et déterministe. Plus important encore, nous pouvons réutiliser les fonctionnalités de Kubernetes natif. Par exemple, gérer des serveurs API via le déploiement, en utilisant l'opérateur etcd pour gérer plusieurs etcd. Une telle récursivité apporte toujours un plaisir particulier.
Dans la même région, plusieurs métaclusters Kubernetes sont déployés, en fonction du nombre de clients. Ces métaclusters sont appelés cellules. Pour se protéger contre l'échec d'une zone entière, ACK prend en charge les déploiements multi-actifs dans une région: le métacluster distribue les composants de l'assistant de cluster client Kubernetes dans plusieurs zones et les démarre simultanément, c'est-à-dire en mode multi-actif. Pour garantir la fiabilité et l'efficacité de l'assistant, l'ACK optimise le placement des composants et s'assure que le serveur API et etcd sont proches l'un de l'autre.
Ce modèle vous permet de gérer efficacement, de manière flexible et fiable Kubernetes.
Planification des ressources Metacluster
Comme nous l'avons déjà mentionné, le nombre de métaclusters dans chaque région dépend du nombre de clients. Mais à quel moment ajoutez-vous un nouveau métacluster? Il s'agit d'un problème typique de planification des ressources. En règle générale, il est habituel d'en créer un nouveau lorsque les métaclusters existants ont épuisé toutes leurs ressources.
Prenons l'exemple des ressources réseau. Dans l'architecture KoK, les composants Kubernetes des clusters clients sont déployés en tant que pods dans le métacluster. Nous utilisons
Terway (Fig. 3), un plugin hautes performances développé par Alibaba Cloud pour la gestion du réseau de conteneurs. Il fournit un riche ensemble de politiques de sécurité et vous permet de vous connecter à des clients de cloud privé virtuel (VPC) via l'interface Alibaba Cloud Elastic Networking Interface (ENI). Pour répartir efficacement les ressources réseau entre les nœuds, les pods et les services d'un métacluster, nous devons surveiller attentivement leur utilisation à l'intérieur d'un métacluster à partir de clouds privés virtuels. Lorsque les ressources réseau arrivent à leur fin, une nouvelle cellule est créée.
Pour déterminer le nombre optimal de clusters clients dans chaque métacluster, nous prenons également en compte nos coûts, les exigences de densité, le quota de ressources, les exigences de fiabilité et les statistiques. La décision de créer un nouveau métacluster est prise sur la base de toutes ces informations. Veuillez noter que les petits clusters peuvent se développer considérablement à l'avenir, donc la consommation de ressources augmente même avec le même nombre de clusters. Habituellement, nous laissons suffisamment d'espace libre pour la croissance de chaque cluster.
 Fig. 3. Architecture de réseau Terway
Fig. 3. Architecture de réseau TerwayMise à l'échelle des composants de l'assistant dans les clusters clients
Les composants de l'assistant ont des besoins en ressources différents. Ils dépendent du nombre de nœuds et de pods dans le cluster, du nombre de contrôleurs / opérateurs non standard interagissant avec APIServer.
Dans l'ACK, chaque cluster client Kubernetes est différent en termes de taille et d'exigences d'exécution. Il n'y a pas de configuration universelle pour l'hébergement des composants de l'assistant. Si nous fixons par erreur une limite de ressources faible pour un gros client, son cluster ne supportera pas la charge. Si vous définissez une limite conservativement élevée pour tous les clusters, les ressources seront gaspillées.
Pour trouver un subtil compromis entre fiabilité et coût, ACK utilise un système de type. À savoir, nous définissons trois types de grappes: petites, moyennes et grandes. Chaque type a un profil d'allocation de ressources distinct. Le type est déterminé en fonction du chargement des composants de l'assistant, du nombre de nœuds et d'autres facteurs. Le type de cluster peut changer avec le temps. ACK surveille constamment ces facteurs et peut en conséquence augmenter / diminuer le type. Après avoir changé le type de cluster, la distribution des ressources est mise à jour automatiquement avec une intervention minimale de l'utilisateur.
Nous travaillons à améliorer ce système en termes de mise à l'échelle plus fine et de mises à jour de types plus précises, afin que ces changements se produisent plus facilement et soient plus économiques.
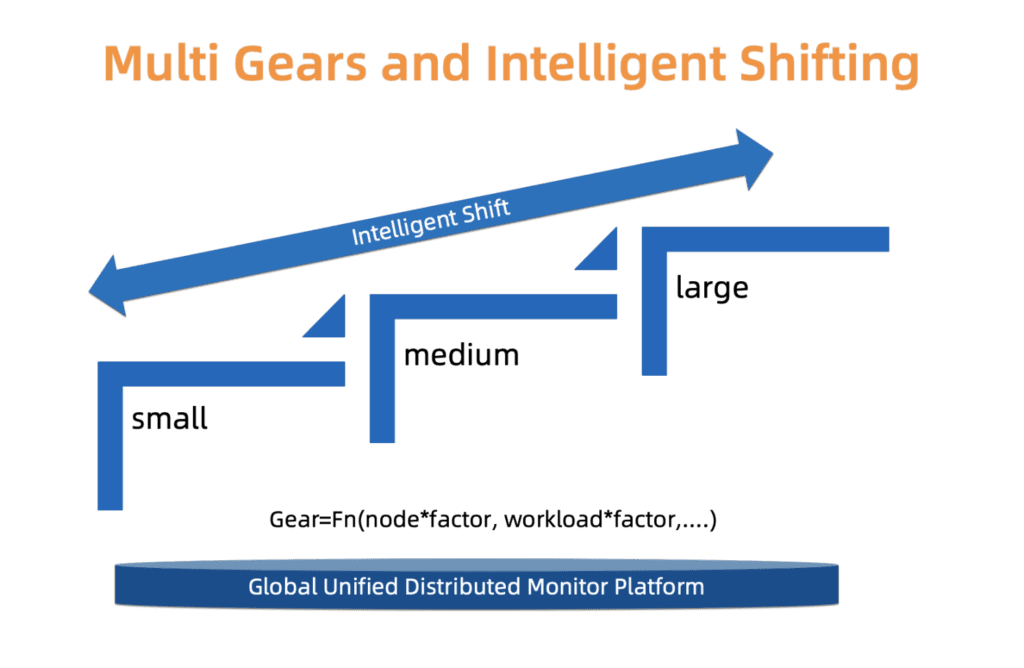 Fig. 4. Commutation intelligente à plusieurs niveaux
Fig. 4. Commutation intelligente à plusieurs niveauxL'évolution des clusters clients à l'échelle
Les sections précédentes décrivent certains aspects de la gestion d'un grand nombre de clusters Kubernetes. Cependant, il y a un autre problème à résoudre: l'évolution des clusters.
Kubernetes est Linux dans le monde du cloud. Il est constamment mis à jour et devient plus modulaire. Nous devons constamment fournir à nos clients de nouvelles versions, corriger les vulnérabilités et mettre à jour les clusters existants, ainsi que gérer un grand nombre de composants connexes (CSI, CNI, Device Plugin, Scheduler Plugin et bien d'autres).
Prenons l'exemple de la gestion des composants Kubernetes. Pour commencer, nous avons développé un système d'enregistrement et de gestion centralisé pour tous ces composants de plug-in.
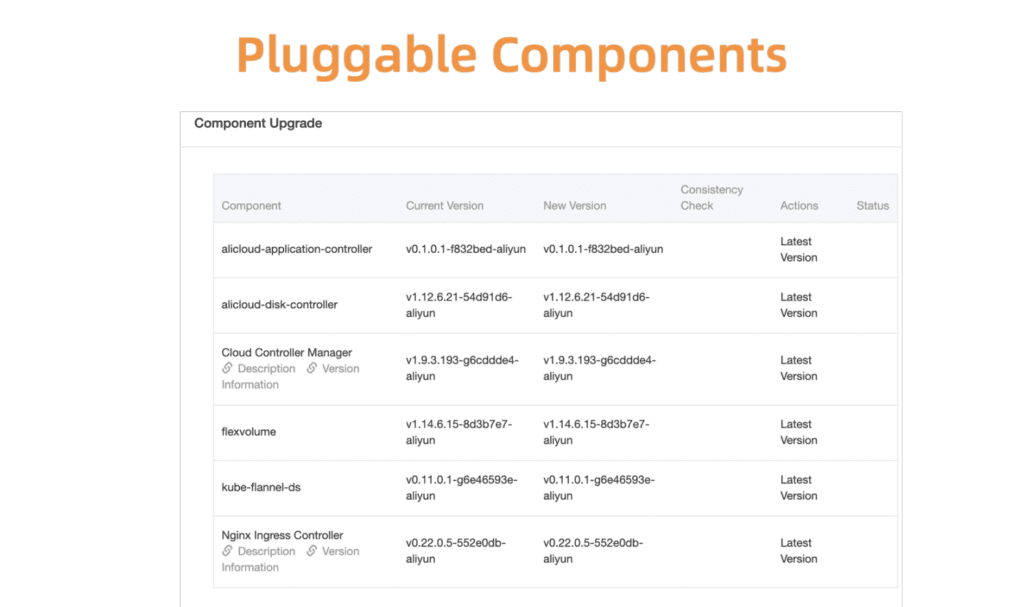 Fig. 5. Composants flexibles et enfichables
Fig. 5. Composants flexibles et enfichablesAvant de continuer, vous devez vous assurer que la mise à jour a réussi. Pour ce faire, nous avons développé un système de bilan de santé des composants. La validation est effectuée avant et après la mise à niveau.
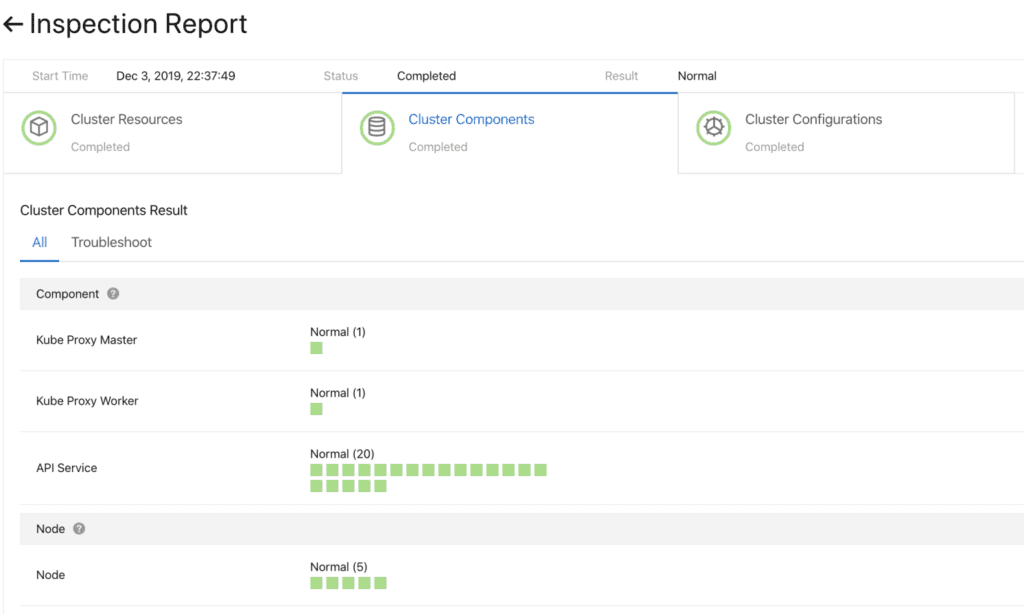 Fig. 6. Contrôle préliminaire des composants du cluster
Fig. 6. Contrôle préliminaire des composants du clusterPour mettre à jour rapidement et de manière fiable ces composants, un système de déploiement continu fonctionne avec la prise en charge de la promotion partielle (niveaux de gris), des pauses et d'autres fonctions. Les contrôleurs Kubernetes standard ne sont pas bien adaptés à cette utilisation. Par conséquent, pour gérer les composants du cluster, nous avons développé un ensemble de contrôleurs spécialisés, dont un plug-in et un module de contrôle auxiliaire (gestion du side-car).
Par exemple, le contrôleur BroadcastJob est conçu pour mettre à jour les composants sur chaque machine en fonctionnement ou pour vérifier les nœuds sur chaque machine. Le travail de diffusion exécute un pod sur chaque nœud du cluster, comme un DaemonSet. Cependant, DaemonSet prend toujours en charge le fonctionnement continu du pod, tandis que BroadcastJob le minimise. Le contrôleur de diffusion démarre également des modules sur les nœuds nouvellement connectés et initialise les nœuds avec les composants nécessaires. En juin 2019, nous avons ouvert le code source du moteur d'automatisation OpenKruise, que nous utilisons nous-mêmes au sein de l'entreprise.
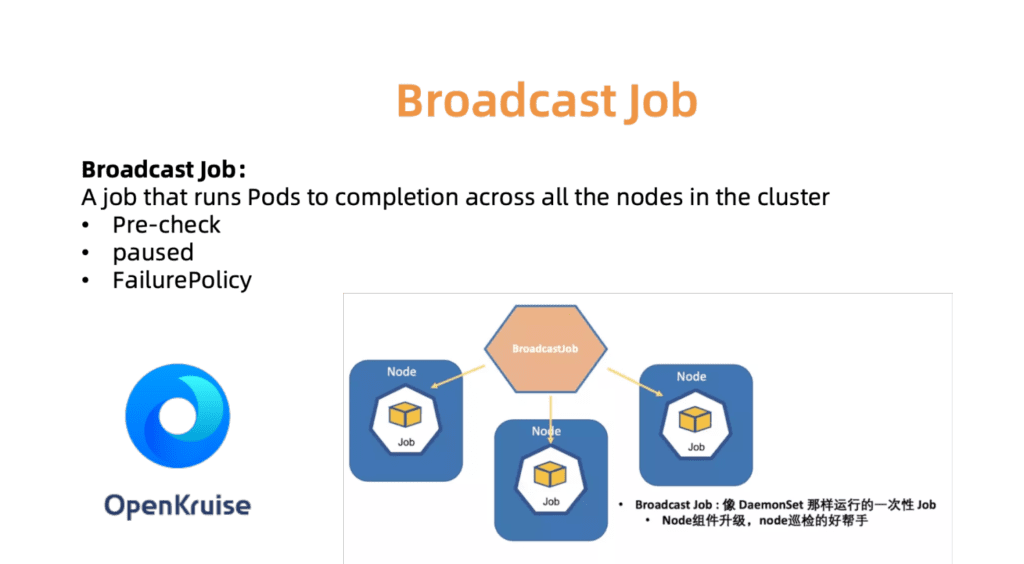 Fig. 7. OpenKurise organise des missions de diffusion sur tous les sites.
Fig. 7. OpenKurise organise des missions de diffusion sur tous les sites.Pour aider les clients à choisir les bonnes configurations de cluster, nous fournissons également un ensemble de profils prédéfinis, y compris les profils Serverless, Edge, Windows et Bare Metal. À mesure que le paysage s'élargit et que les besoins de nos clients augmentent, nous ajouterons plus de profils pour simplifier le processus de configuration fastidieux.
 Fig. 8. Profils de cluster avancés et flexibles pour différents scénarios
Fig. 8. Profils de cluster avancés et flexibles pour différents scénariosObservabilité globale du centre de données
Comme indiqué ci-dessous sur la fig. 9, Alibaba Cloud Container est déployé dans vingt régions du monde. Compte tenu de cette échelle, l'une des tâches clés d'ACK est de surveiller facilement l'état des clusters en cours d'exécution: si le cluster client rencontre un problème, nous pouvons réagir rapidement à la situation. En d'autres termes, vous devez trouver une solution qui vous permettra de collecter efficacement et en toute sécurité des statistiques en temps réel à partir de clusters de clients dans toutes les régions - et de présenter visuellement les résultats.
 Fig. 9. Déploiement mondial d'Alibaba Cloud Container Service dans vingt régions
Fig. 9. Déploiement mondial d'Alibaba Cloud Container Service dans vingt régionsComme avec de nombreux systèmes de surveillance Kubernetes, Prometheus est notre principal outil. Pour chaque métacluster, les agents Prometheus collectent les métriques suivantes:
- Métriques du système d'exploitation, telles que les ressources de l'hôte (processeur, mémoire, disque, etc.) et la bande passante réseau.
- Métriques pour le métacluster et le système de gestion de cluster client, telles que kube-apiserver, kube-controller-manager et kube-scheduler.
- Métriques de kubernetes-state-metrics et cadvisor.
- Métriques Etcd, telles que le temps d'écriture sur disque, la taille de la base de données, le débit entre les nœuds, etc.
Les statistiques globales sont collectées à l'aide d'un modèle d'agrégation multicouche typique. Les données de surveillance de chaque métacluster sont d'abord agrégées dans chaque région, puis envoyées à un serveur central, qui présente une vue d'ensemble. Tout fonctionne par le biais du mécanisme de fédération. Le serveur Prometheus de chaque centre de données collecte les métriques de ce centre de données et le serveur central Prometheus est responsable de l'agrégation des données de surveillance. AlertManager se connecte au Prometheus central et, si nécessaire, envoie des alertes via DingTalk, e-mail, SMS, etc. Visualisation - à l'aide de Grafana.
Dans la figure 10, le système de surveillance peut être divisé en trois niveaux:
La couche la plus éloignée du centre. Le serveur Edge Prometheus s'exécute sur chaque métacluster, collectant des métriques à partir des méta-clusters et des clusters clients dans le même domaine réseau.
La fonction de couche en cascade de Prometheus est de collecter des données de surveillance de plusieurs régions. Ces serveurs fonctionnent au niveau d'unités géographiques plus importantes telles que la Chine, l'Asie, l'Europe et l'Amérique. Au fur et à mesure que les clusters se développent dans une région, ils peuvent être divisés, puis un serveur Prometheus de niveau en cascade apparaîtra dans chaque nouvelle grande région. Avec cette stratégie, vous pouvez évoluer de manière transparente selon vos besoins.
Le serveur central Prometheus se connecte à tous les serveurs en cascade et effectue l'agrégation finale des données. Pour plus de fiabilité, deux instances centrales de Prometheus connectées aux mêmes serveurs en cascade ont été générées dans différentes zones.
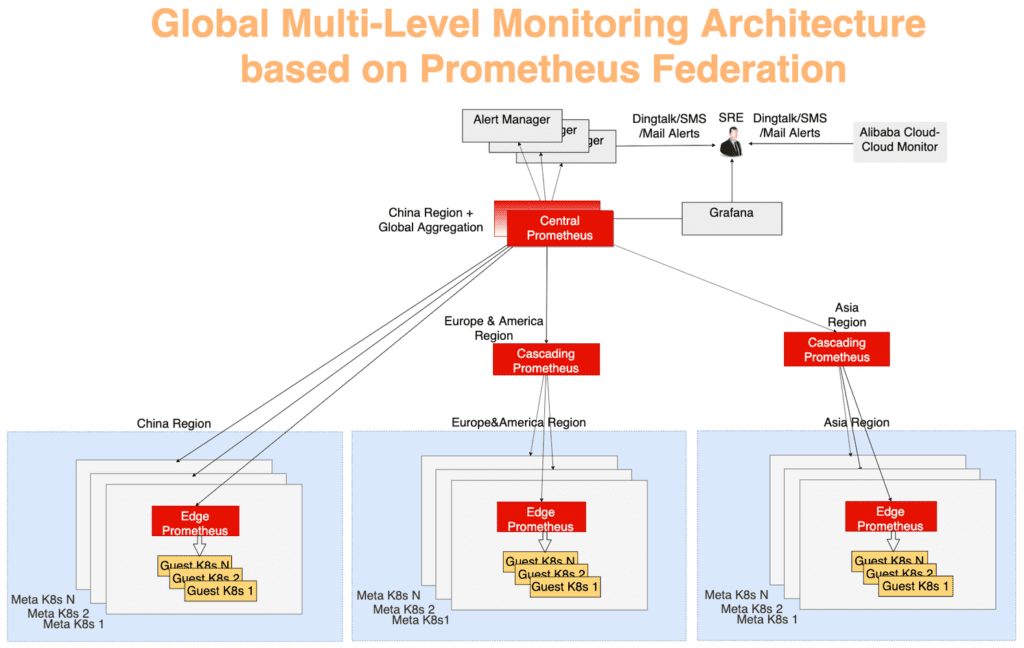 Fig. 10. Architecture de surveillance globale à plusieurs niveaux basée sur le mécanisme de fédération Prometheus
Fig. 10. Architecture de surveillance globale à plusieurs niveaux basée sur le mécanisme de fédération PrometheusRésumé
Les solutions cloud basées sur Kubernetes continuent de transformer notre industrie. Alibaba Cloud Container Service fournit un hébergement sécurisé, fiable et hautes performances - c'est l'un des meilleurs services d'hébergement cloud de Kubernetes. L'équipe d'Alibaba Cloud croit fermement aux principes de l'Open Source et de la communauté open source. Nous continuerons certainement à partager nos connaissances dans le domaine de l'exploitation et de la gestion des technologies cloud.